文章目錄
- 1.為什么要使用volatile
- 2.volatile如何解決可見性問題
- 2.1.CPU與記憶體互動
- 2.2.1.可見性問題產生的原因
- 2.3.volatile的實作——匯編指令lock
- 2.3.1.lock指令做了什么
- 2.3.2.總線鎖
- 2.3.3.快取一致性協議
- 2.3.4.Store Bufferes帶來的問題
- 3.volatile如何解決有序性問題
- 3.1.記憶體屏障
- 3.1.1.volatile記憶體屏障代碼示例及其圖示
- 4.volatile讀寫的記憶體語意
- 5.總結
1.為什么要使用volatile
volatile是作用是保證被修飾變數的可見性和有序性,但是之前提到的synchronized已經可以保證多執行緒并發情況下的執行緒安全,其中就包括了保證可見性和有序性,為什么還要(或者還需要)使用volatile呢?
synchronized是將修飾的代碼塊變成了同步代碼塊,在執行緒退出同步塊的時候,會將同步塊中的所有共享變數副本從執行緒的作業記憶體同步到主記憶體中的共享變數中,這是synchronized保證可見性的方式,同時,一個執行緒進入同步塊后會阻塞其它的執行緒進入,知道解鎖了其它執行緒競爭搶占資源后再進入同步塊,這種依次進入同步塊的特性天然的滿足了有序性,
但是,synchronized畢竟涉及到了執行緒的阻塞和執行緒的背景關系切換,在某些簡單的原子性操作中,這樣的處理方式必然帶來了額外的性能開銷,
所以JVM在面對這些簡單的原子性操作時,引入了更輕量級的處理方式——volatile,以此來保證某些變數在并發且不加鎖的情況下保證可見性和有序性,
2.volatile如何解決可見性問題
2.1.CPU與記憶體互動
JMM是JDK為了屏蔽不同硬體和不同作業系統中指令執行的差異性,在作業系統的CPU與記憶體的互動機制上抽象出了一套供Java使用的記憶體模型,我們使用這套模型進行研究和學習可以更好的幫助我們清楚的認知執行緒之間的同步和通信問題,上面提到得作業記憶體和主記憶體就屬于這個模型的一部分,
JMM圖示如下:
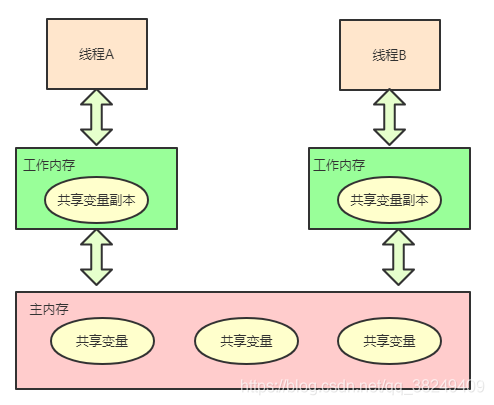
同理,將JMM抽象模型套用在CPU和記憶體之間,就得到了一個CPU與記憶體互動的簡圖,我們可以通過這個簡圖去研究可見性問題:
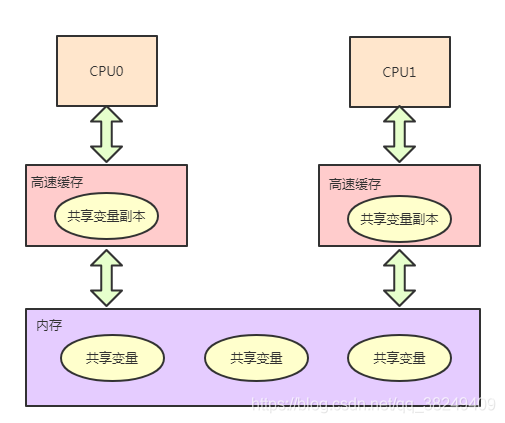
2.2.1.可見性問題產生的原因
上圖可見,每個CPU對共享變數的操作都是將記憶體中的共享變數復制一份副本到自己高速快取中,然后對這個副本進行操作,如果沒有正確的同步,即使CPU0修改了某個變數,這個已修改的值還是只存在于副本中,此時CPU1需要使用到這個變數,從記憶體中讀取的還是修改前的值,這就是其中一種可見性問題,
還有一種可見性問題,CPU0和CPU1都讀取了變數a到自己的副本中,CPU0對變數a 做了寫操作并同步到了記憶體,但是CPU1在后面的操作中沒有從記憶體更新變數值,而是直接使用了之前快取的值,這樣也會導致資料結果不正確,
2.3.volatile的實作——匯編指令lock
Java代碼的運行是先將Java代碼編譯成位元組碼,然后JVM加載位元組碼最終轉換成匯編指令在CPU上運行,被volatile修飾的欄位會在其對應的匯編操作指令上加個lock前綴指令,這個指令就可以解決上述的兩種可見性問題,
2.3.1.lock指令做了什么
處理器在接收到lock指令的時候會做兩件事:
1.將快取行快取的資料寫回到系統記憶體中,
2.這個寫回到系統記憶體中的資料,如果在其他CPU的快取行中存在相同的資料,則將其置為失效狀態,
而lock指令更底層的實作主要有兩種方式:總線鎖和快取鎖,在談這兩種方式之前先解釋下快取行是什么,
快取行(cache line)是什么?
因為CPU和記憶體之間運行速度的差異,為了保證CPU的運行速度不被記憶體給“拖垮”,CPU在對記憶體中的資源進行操作的時候不會直接去操作記憶體,而是將記憶體中的資源先加載到CPU的高速快取中,在使用的時候就直接從高速快取中去取,
快取行就是高速緩沖中用于分配的最小存盤單位,也就是說CPU加載高速快取中的資源,最少也會加載一整個快取行,
2.3.2.總線鎖
在一些比較“古老”的處理器中可能還會使用的總線鎖的方式,CPU與記憶體資料的互動是通過總線來“運輸的”,某個處理器使用了總線鎖就表示這段時間就只有它能與記憶體發生資料互動,其它的處理器都無法訪問到系統記憶體,這種方式必然會導致開銷比較大,
所以現代的處理器一般不會使用總線鎖,而是使用快取鎖作為替代方案,
2.3.3.快取一致性協議
快取鎖嚴格來鎖并不是鎖,而是基于快取一致性協議,實作對快取行資料的狀態轉換的控制,以此來完成對可見性的保證,
快取一致性協議(MESI),將快取行中的資料劃分成了4個狀態:修改、獨占、共享、失效
- M(Modified): 當前快取行中的資料與記憶體中不一致,且只有當前一個快取行存盤了這個資料,
- E(Exclusive):快取行和記憶體資料一致,且只有當前一個快取行存盤了這個資料,
- S(Shared):快取行和記憶體資料一致,資料存在于多個快取行中,
- I(Invalid):當前快取行失效,
快取一致性協議是如何使用的呢?
下面針對1.1提到的第二種可見性問題來分析執行流程,
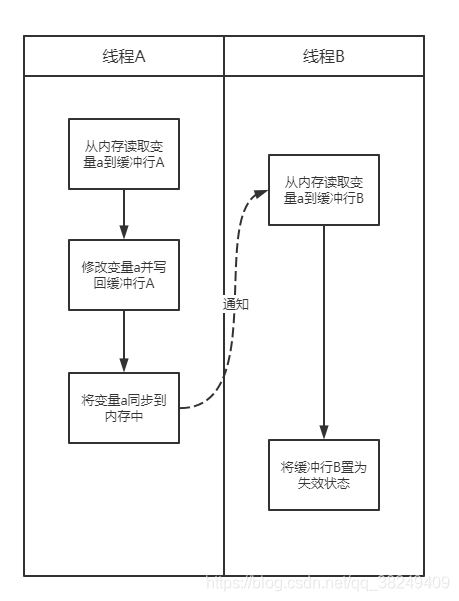
失效的快取行會在下次使用到的時候,重新從記憶體中獲取資料,這么一來執行緒A對共享變數做出了修改,對執行緒B就立即可見了,
再看一下執行緒A在將快取行中的變數同步到的記憶體時,會通知其他的執行緒將這個變數所在快取行置為失效狀態的動作,這個動作實際上是一個同步阻塞的動作,A向B發起一個失效通知,然后阻塞等待B回應結果,圖示如下:
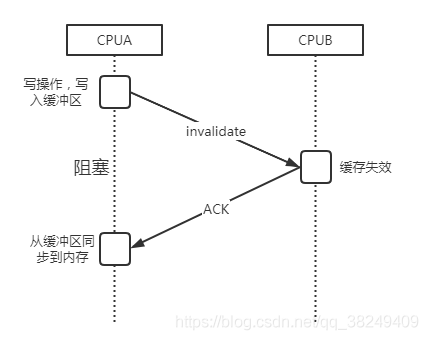
這里阻塞的時間可能會遠大于CPU執行每條指令的時間,可以想到的是,如果這種阻塞操作過多必然會導致CPU運行性能降低,
為了解決CPU算力浪費的問題,引入了Store Bufferes這樣一個緩沖區域,把將要同步回記憶體的資料的放入Store Buffers中,然后當前CPU發送失效通知,發送后不再阻塞等待,而是去執行其它的指令,直到所有失效通知都回應回來后,再將Store Buffers中的資料取出同步到記憶體,
2.3.4.Store Bufferes帶來的問題
引入Store Buffers對快取一致性協議的阻塞問題做了優化,但是這個優化可能會導致后面的指令先于前面的指令執行完畢,這種順序流入、亂序流出的現象,屬于指令重排序,
3.volatile如何解決有序性問題
造成有序性問題的其中一個原因是處理器的指令重排序,指令重排序實際上是處理器的優化方案,讓CPU能發揮更好的性能,嚴格的說不能算是一個問題,
在單執行緒的情況下,一個方法內的代碼對應的CPU指令即使是亂序執行的,對結果來說也不會有影響(除非是后面的指令依賴前面的結果,這種情況由Happen-Before規則禁止重排序),但是對于并發條件下的程式,亂序修改共享變數就可能導致其他的執行緒讀取到的變數值不正確,
作為一個優化來講,指令重排序是有其存在的必要性的,但是處理器并不知道什么時候應該禁止這種重排序優化來保證程式執行的正確性,于是將禁用的時機拋給了使用者,
針對兩種不同的重排序,編譯器的重排序和處理器的重排序,JMM統一制定了重排序的管理規則,通過插入記憶體屏障來標識什么時候是禁止重排序優化的,而插入記憶體屏障時機,就是volatile修飾的變做讀寫操作的時候,
3.1.記憶體屏障
JMM定義的記憶體屏障一共有4種:
| 屏障型別 | 指令說明 |
|---|---|
| StoreStore | 寫寫屏障,插入兩個寫之間,volatile寫之前,禁止前面的普通寫或volatile寫與當前的volatile寫發生重排序 |
| StoreLoad | 寫讀屏障,插入volatile寫之后,禁止當前的volatile寫與后面的volatile讀發生重排序 |
| LoadLoad | 讀讀屏障,插入 volatile讀之后,禁止當前的volatile讀與后面普通讀或volatile讀發生重排序 |
| LoadStore | 讀寫屏障,插入volatile讀之后,禁止當前的volatile讀與后面的普通寫或volatile寫發生重排序 |
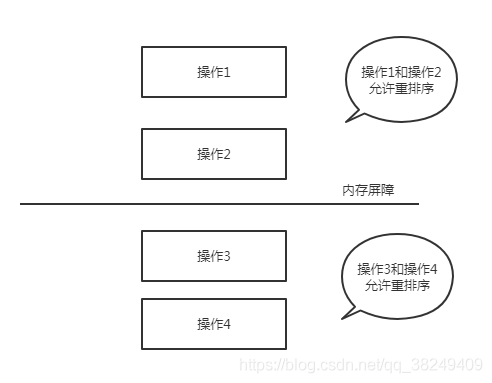
記憶體屏障就是將代碼劃分為多個區域,區域與區域之間按照順序執行,各個區域中的代碼可以重排序,如下圖所示:
3.1.1.volatile記憶體屏障代碼示例及其圖示
先看一個代碼示例,對四個成員變數的記憶體操作:
public class VolatileBarrierDemo {
int i1;
int i2;
volatile int v1;
volatile int v2;
void readAndWrite() {
int a1 = i1; // 操作一
int a2 = i1; // 操作二
int b1 = v1; // 操作三
int b2 = v2; // 操作四
i1 = i1 + 1; // 操作五
v1 = i1 * 2; // 操作六
v2 = i1 * 3; // 操作七
i2 = i2 + 1; // 操作八
}
}
在readAndWrite方法中,四種記憶體屏障都用到了,具體流程如下圖所示:
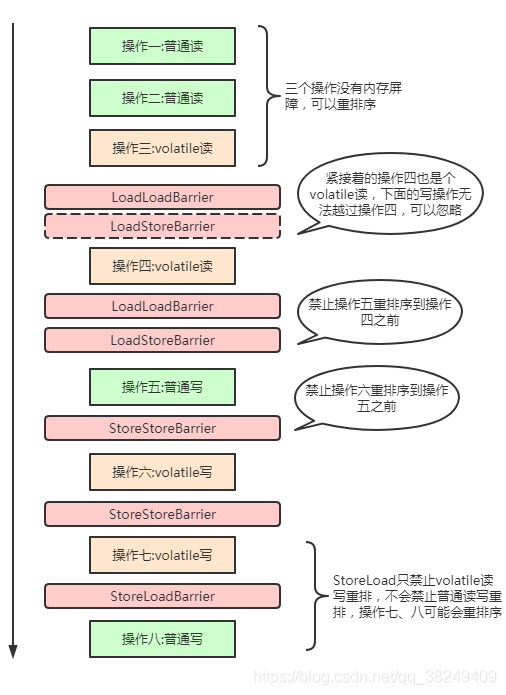
JMM通過在各個指令之間插入不同記憶體屏障,來達到在某些問題禁用重排序優化的效果,以此來保證并發環境下由有序性造成的執行緒安全問題,
4.volatile讀寫的記憶體語意
在2.3.3快取一致性協議中提到了CPU通過“快取鎖”來解決可見性問題,JMM通過對底層實作的抽象,將3.1中提到的volatile讀/寫操作,分別定義了其記憶體語意,更方便與理解和使用,
- volatile寫:將當前執行緒的作業記憶體中的共享變數副本,同步到主記憶體中,
- volatile讀:將當前執行緒的作業記憶體中的共享變數副本置為無效,下次使用的時候重新從主記憶體讀取,
如果將讀寫的記憶體語意連起來看,就是一個做volatile寫操作的執行緒A,和一個做volatile讀操作的執行緒B,A對這個volatile修飾的共享變數的修改,對執行緒B可見,
5.總結
volatile的作用是并發環境下,在一定的作用范圍內解決共享變數的可見性和有序性問題,相對于synchronized和顯示的加鎖,volatile在性能上根據優勢,可以盡可能的以更細的粒度來保證執行緒安全,
可見性:
- 通過JMM提供的lock指令,來使用CPU底層的提供的總線鎖或快取鎖來保證共享資源的實事同步和更新,
- 總線鎖在加鎖后會阻塞CPU訪問記憶體,所以大多數CPU是通過快取一致性協議對快取行狀態的控制來達到多個執行緒之間的共享變數值同步,
有序性:
- JMM提供了四種記憶體屏障,插入到各個指令之間,讓各個指令不能越過屏障改變執行的順序,通過這種主動禁用重排序優化的方式來屏蔽掉并發環境下,因為重排序導致的有序性問題,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/252632.html
標籤:其他