本文作者:李博文 - CODING 后端開發工程師
前言
六七年前,我機緣巧合進入了代碼托管行業,做過基于 Git 支持 SVN 客戶端接入、Git 代碼托管平臺分布式、Git 代碼托管讀寫分離、Git 代碼托管高可用等作業,所幸學到了一些知識,積累了一些經驗,本次分享我的一點經驗之談,希望對即將進入或者已在代碼托管行業的朋友有所幫助,
Git 的發展歷史
版本控制系統的發展歷史
版本控制系統歷史悠久,最早的開源的版本控制系統可以追溯到幾乎與 C 語言同時誕生的 Source Code Control System (SCCS),作者Marc J. Rochkind來自著名的貝爾實驗室,他于 1973 年發布了 SCCS 的初始版本,SCCS 的壽命悠久,直到 2007 年再沒有人維護而終結,SCCS 本質上是一種 Local Only 版本控制系統,如今網路快速發展,無法跟上時代的腳步只能消亡,同型別的 RCS 雖然維護至今,也鮮有人問津,
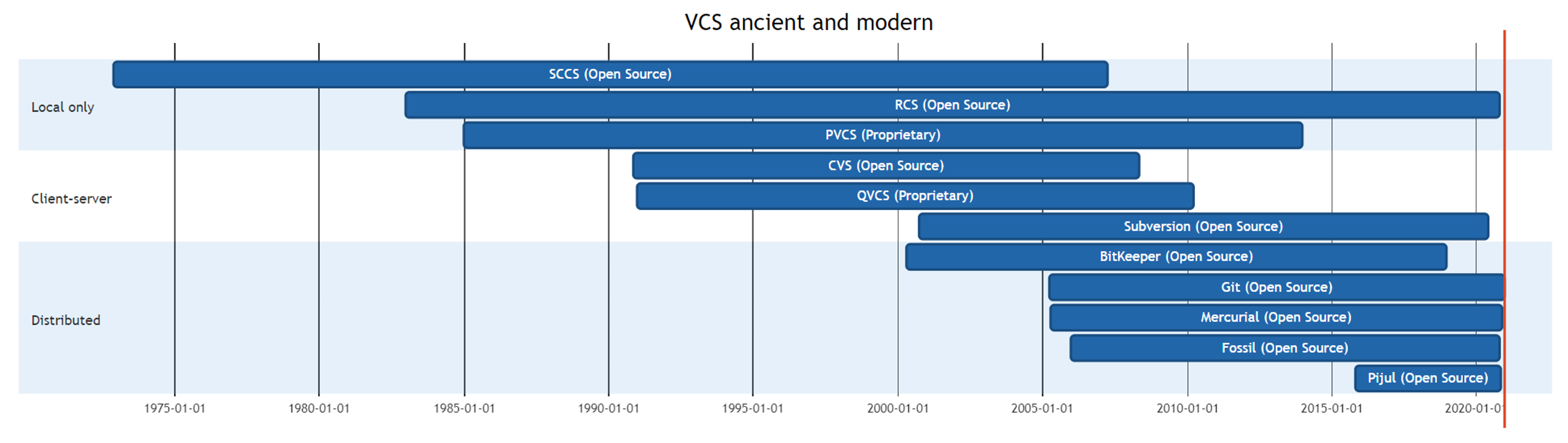
1986 年誕生的 CVS 是一款真正的自由軟體,使用 GPL 協議發布,一個有趣的事實是:CVS 是 RCS 的前端,也就是說 CVS 將 RCS 從 Local Only 變成了 Client-Server 版本控制系統,隨著 2000 年 Apache Subversion 誕生,CVS 的市場快速萎縮,到了 2008 年 CVS 不再維護,集中式版本控制系統漸漸也只剩 Subversion 在維護了,
最早的分布式版本控制系統是 1992 年誕生的 Sun WorkShop TeamWare,但它并沒有發展的很好,從 2000 年到 2007 年,分布式版本控制系統如雨后春筍一樣冒了出來,2005 年誕生的 Git 和 Mercurial 幸運流傳開來,時至今日,Git 終于在版本控制領域獨占鰲頭,
Git 的發展史
2005 年,開發 BitKeeper 的商業公司結束與 Linux 內核開源社區的合作關系,他們識訓了 Linux 內核社區免費使用 BitKeeper 的權利,Linus Torvalds 花了十天時間撰寫了 Git 的第一個版本,Git 的故事由此展開,
Git 原本只能在 Linux 上運行,隨著開源社區的參與,逐漸能在各個平臺上運行,在 Windows 上,最初有兩個方案,一個是讓 Git 在 Cygwin 的環境下編譯,Cygwin 是 Windows 上的 POSIX 兼容層,但缺陷是需要帶一大堆 DLL,另一個方案是 msysgit,基于 MSYS 運行時,MYSY 是更小的 POSIX 兼容環境,到了 2015 年,msysgit 不再維護,主要開發者基于 MSYS2 環境推出了 Git for Windows,而 MSYS2 的核心運行時基于 Cygwin 進行了定制,值得一提的是,在 Git for Windows 中,Git 命令并不是基于 MSYS2 運行時,而是原生的 Windows 程式,到今天我們已經可以使用 Visual C++ 編譯 Git 原始碼了,Git for Windows 的維護者 Johannes Schindelin 加入微軟后,在 Windows 上使用 Git 的體驗也越來越好,
2008 年 11 月 Shawn O. Pearce 寫下了 libgit2 的第一個提交;2009 年 9 月,Shawn 寫下了 JGit 的第一個提交,Libgit2/jgit 被代碼托管平臺,Git 客戶端廣泛使用,比如 GitHub 使用 libgit2 的 Ruby 系結 rugged 提供頁面讀寫存盤庫能力,遺憾的是 Shawn 已經離開這個世界兩年多了,
再來回顧 Git 的一些大事件:2008 年 GitHub 誕生,是最成功的代碼托管平臺,幾乎以一己之力帶來了 Git 的繁榮;2008 年 BitBucket 誕生,最初 BitBucket 還支持 Mercurial,到了 2020 年已不再支持;2011 年 GitLab 誕生,而國內的 Gitee 也是基于 GitLab 發展而來的;2014 年 CODING 成立,國內國外代碼托管平臺百花齊放;2018 年,微軟花費 75 億美元收購 GitHub,大家才猛然發現,基于 Git 的代碼托管平臺已經有了這樣大的價值,
Git 是一個充滿活力的版本控制系統,每一年,Git 的開發者們都在將他們新的知識、經驗實踐到 Git 中,2018 年 5 月,在谷歌作業的 Git 開發者們發布了 Git Wire Protocol,這解決了 Git 協議中最低效的部分;到了 2020 年 10 月,Git 實驗性地支持 SHA256 哈希演算法,在 SHA1 被破解幾年后,我們終于可以在 Git 中嘗試淘汰 SHA1 了,
Git 的發展必然會擠占其他版本控制系統份額,隨著 Git 越來越流行,更多的專案也從其他的版本控制系統遷移到 Git 上來:
- 編譯器基礎設施 LLVM 從 SVN 遷移到 Git
- FreeBSD 從 SVN 遷移到 Git
- GCC(仍處于遷移程序中)從 SVN 遷移到 Git
- Windows 原始碼(已經遷移到 Git,使用 VFS for Git 技術)
- VIM 遷移到 GitHub
- OpenJDK 從 Mercurial 遷移到 Git
2016 年,Git 誕生11年之后,BitKeeper 宣布采用 Apache 2.0 許可協議開源,如果再回到 2005 年,BitKeeper 又會做出怎樣的抉擇呢?
Git 的存盤原理
對于代碼托管從業人員來說,只了解 Git 的使用并不足以參與代碼托管平臺服務開發和架構優化等作業,所以了解 Git 的一些原理非常必要,
Git 的目錄結構
首先需要了解 Git 存盤庫的目錄結構,Git 存盤庫分為常規存盤庫和 Bare (裸)存盤庫,普通用戶從遠程克隆下來的存盤庫,或者本地初始化的存盤庫大多是常規存盤庫,這類存盤庫和特定的作業區相關聯;另一類是沒有作業區的存盤庫,就是裸存盤庫,在代碼托管平臺的服務器上,存盤庫幾乎都是以裸存盤庫的方式存盤的,對于常規存盤庫而言,其存盤庫真正的路徑是作業區根目錄下的 .git 檔案夾,或者 .git 檔案指向的目錄,后者通常用于 Git 子模塊,
知道了 Git 存盤庫的位置,就可以查看存盤庫的目錄結構,下面是一個查看存盤庫的截圖,
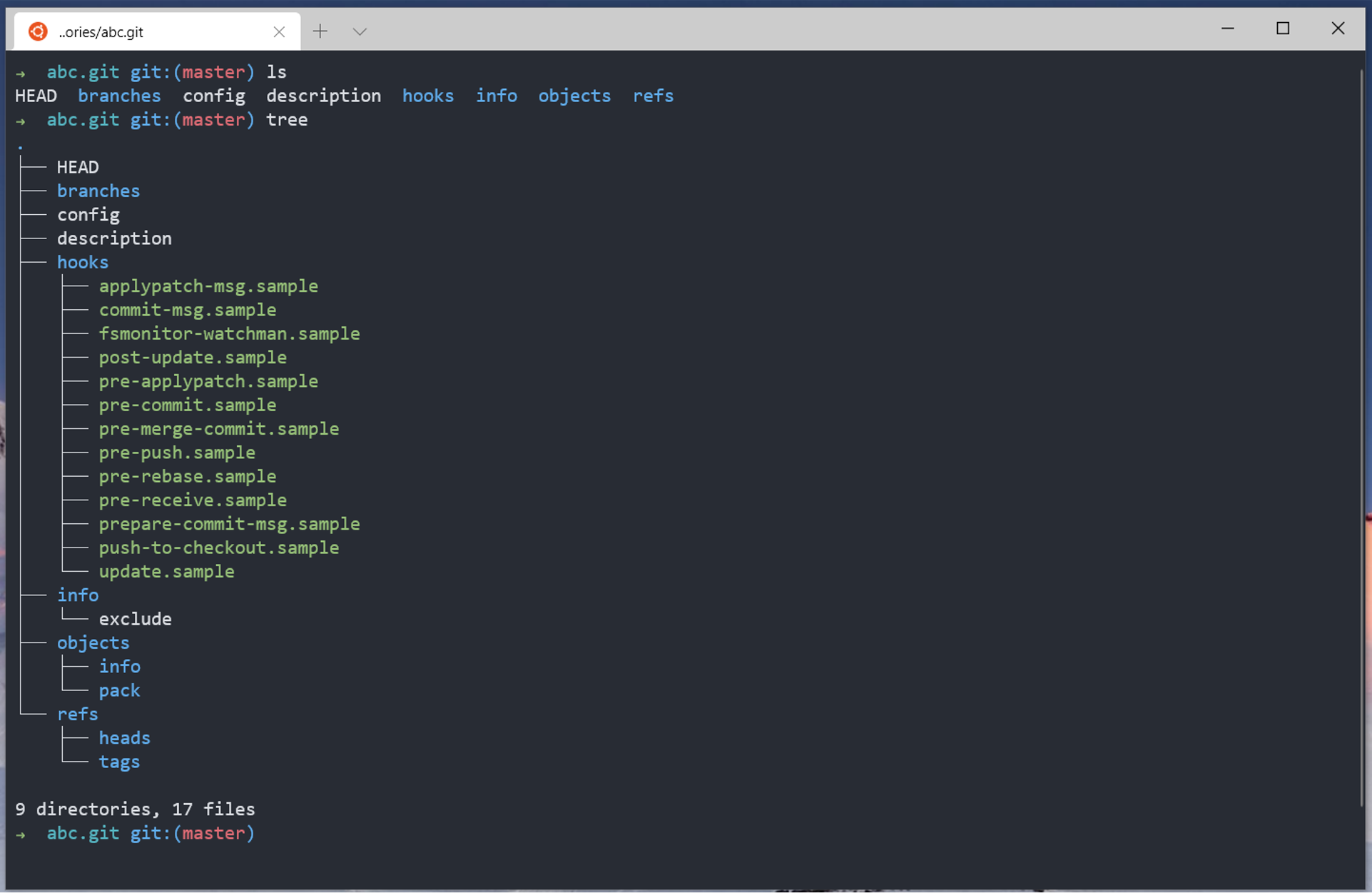
不同的目錄具備不同的作用,大致如下:
| 路徑 | 屬性 | 作用 | 備注 |
|---|---|---|---|
| HEAD | R |
存盤當前檢出的參考或者提交 ID | 在遠程服務器上用于展示默認分支 |
| config | R |
存盤庫配置 | 存盤庫配置優先級高于用戶配置,用戶配置優先級高于系統配置 |
| branches | D |
deprecated |
|
| description | R |
depracated |
|
| hooks | D |
Git 鉤子目錄,包括服務端鉤子和客戶端鉤子 | 當設定了 core.hooksPath 時,則會從設定的鉤子目錄查找鉤子 |
| info | D |
存盤庫資訊 | dump 協議依賴,但目前 dump 協議已無人問津 |
| objects | D |
存盤庫物件存盤目錄 | |
| refs | D |
存盤庫參考存盤目錄 | |
| packed-refs | R |
存盤庫打包參考存盤檔案 | 該檔案可能不存在,運行 git pack-refs 或者 git gc 后出現 |
在這些目錄或者檔案中,最重要的是 objects 和 refs ,只需要兩個目錄的資料就可以重建存盤庫了,在 objects 目錄下,Git 物件可能以松散物件也可能以打包物件的形式存盤:
| 路徑 | 描述 |
|---|---|
objects/[0-9a-f][0-9a-f] |
松散物件存盤目錄,最多有 256 個這樣的子目錄 |
objects/pack |
打包物件目錄,除了打包物件,還有打包物件索引,多包索引等 |
objects/info |
存盤存盤庫擴展資訊 |
objects/info/packs |
啞協議依賴 |
objects/info/alternates |
存盤庫物件借用技術 |
objects/info/http-alternates |
存盤庫物件借用,用于 HTTP fetch |
Git 在實作其復雜功能的時候還會創建一些其他目錄,更詳細的細節可以查閱:Git Repository Layout,
Git 物件的存盤
Git 的物件可以按照松散物件的格式存盤,也可以按照打包物件的格式存盤,用戶將檔案納入版本控制時,Git 會將檔案的型別標記為 blob,將檔案長度和 \x00 以及檔案內容合并在一起計算 SHA1 哈希值后,使用 Deflate 壓縮,存盤到存盤庫的 objects 目錄下,路徑匹配正則為 objects\/[0-9a-f]{2}\/[0-9a-f]{38}$,當然如果使用 SHA256 則應該匹配 objects\/[0-9a-f]{2}\/[0-9a-f]{62}$,松散物件的空間布局如下:
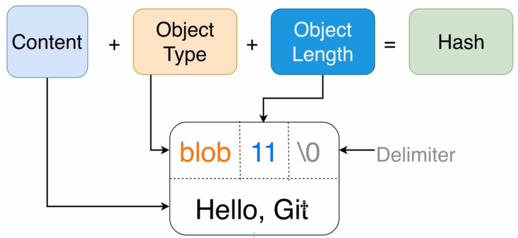
Git 使用的 Deflate 是 Phil Katz 為 PKZIP 創建的壓縮演算法,也是使用最廣泛的壓縮演算法之一,其變體 GZIP 也被廣泛用于 POSIX 檔案壓縮和 HTTP 壓縮,Git 命令列,libgit2 目前依賴 zlib 提供 deflate 演算法,jgit 則使用 Java 提供的 deflate 實作,Golang 則在 compress/zlib 包中提供 deflate 支持,但演算法實作在 compress/flate,嚴格來說 Git 使用的是 deflate 的 zlib 包裝,比如我們使用 zlib 創建 zip 壓縮包時會使用 -15 作為 WindowBits,而在創建 GZIP 時會使用 31 作為 WindowBits,在 Git 中,則會使用 15 作為 WindowBits,
在 Git 中,除了有 blob 物件,還有 commit ,tag,以及 tree ,commit 物件存盤了用戶的提交資訊,tree 顧名思義,存盤的是目錄結構,下面是一個 commit 物件的內容:
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author Scott Chacon <[email protected]> 1243040974 -0700
committer Scott Chacon <[email protected]> 1243040974 -0700
First commit
下面是 tree 物件的內容:
100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 lib
決議松散物件非常容易,我們只需要使用能夠決議 zlib 的庫就可以完成這一操作,這里有一個例子可以參考 https://gist.github.com/fcharlie/2dde5a491d08dbc45c866cb370b9fa07,
想要了解更多的 Git 物件的細節可以參考: Git Internals - Git Objects,
站在檔案系統的角度上看,數量巨大的小檔案性能通常會急劇下降,而松散物件就是這樣的小檔案,Git 的解決方案是引入了打包檔案,打包檔案就是將多個松散物件依次存盤到打包檔案的存盤空間之中,相關的布局如下:
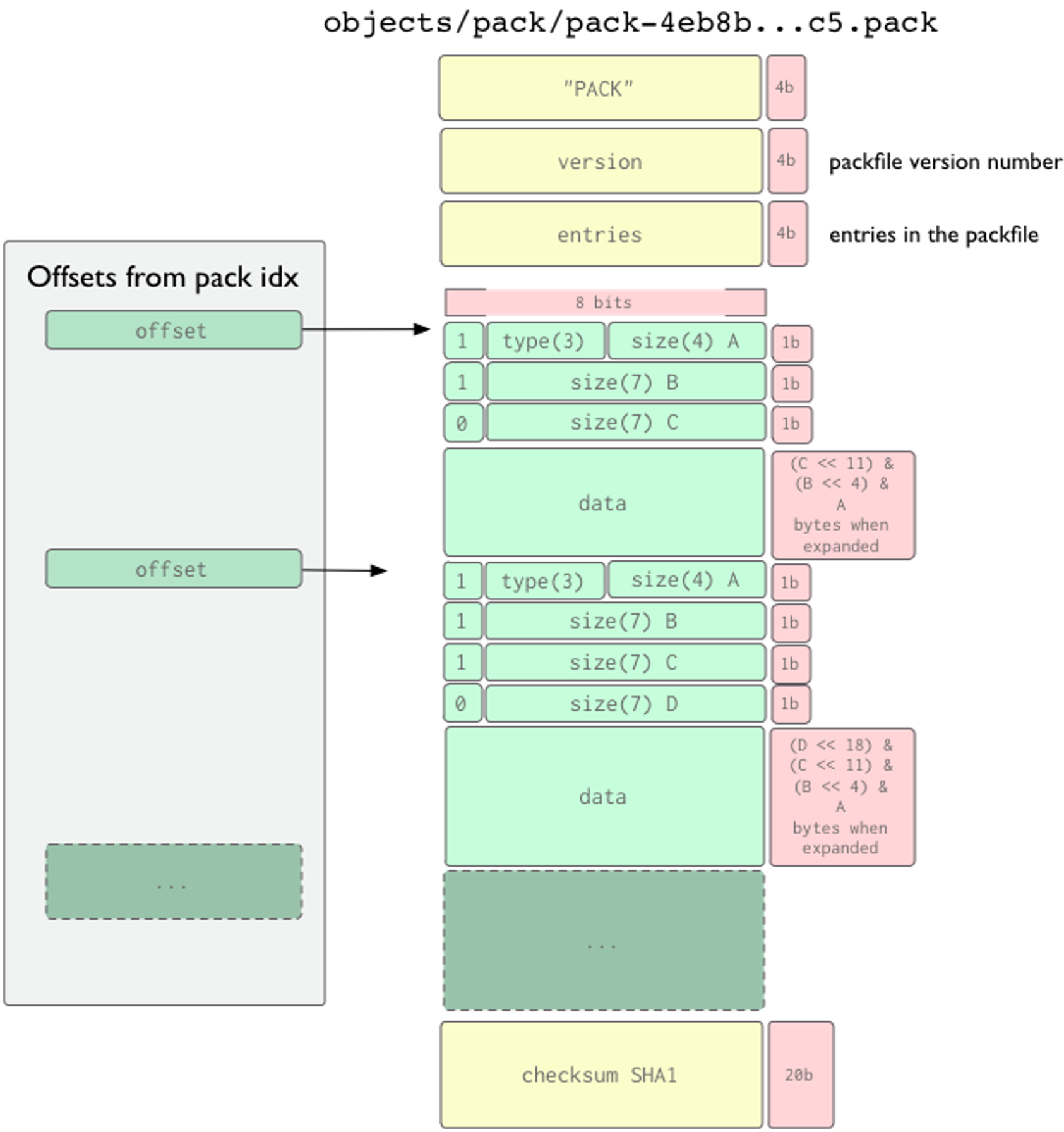
Pack 檔案的路徑正則為 objects\/pack\/pack-[0-9a-f]{40}.pack$,當存盤庫使用 SHA256 哈希演算法時,相應的路徑正則為objects\/pack\/pack-[0-9a-f]{64}.pack$,Pack 檔案的魔數是 'P','A','C','K',隨后的 4 位元組是版本資訊,版本可以為 2,也可以為 3,后者是 SHA256 支持的前提,我們在讀取 Pack 檔案版本的時候需要注意,Git 使用網路位元組序存盤資料,也就是常說的大端,目前 Windows 全部使用小端位元組序,macOS/iOS 等也是這樣,Linux x86/AMD64 也是小端,ARM/ARM64 事實上也使用小端,使用大端的平臺非常少,版本后緊接著是 4 位元組的數字,用于表示這個包中有多少個 Git 物件,4 位元組意味著單個 Pack 中最多只能有 232-1 個 Git 物件,接下來的事情就稍微復雜一些,Git 存盤物件時使用 3-bit表示物件型別,(n-1)*7+4 bit 表示檔案長度,這種機制主要是支持大于 4G 的檔案和支持 OBJ_OFS_DELTA ,也就是說,盡管 Git 是基于快照的,但是在 pack 檔案中,我們依然可以看到一些物件使用差異存盤,這樣的好處是節省空間,壞處就是查看物件復雜度上升,因此,Git 會傾向于將歷史久遠的用 OBJ_OFS_DELTA 存盤,以降低影響,不管怎么說,都是權衡利弊,保證存盤和讀取的平衡,最后是 20 位元組的 checksum SHA1,當然如果是 SHA-256 存盤庫,則需要使用 SHA-256 計算 checksum,
上圖一目了然,如果沒有其他措施,我們要在 Pack 檔案中查找某個物件是非常難的,所幸這個問題一開始就被重視了,在 Pack 檔案的同級目錄下存在檔案后綴名為 .idx 的檔案,就是 Pack Index,其布局如下:
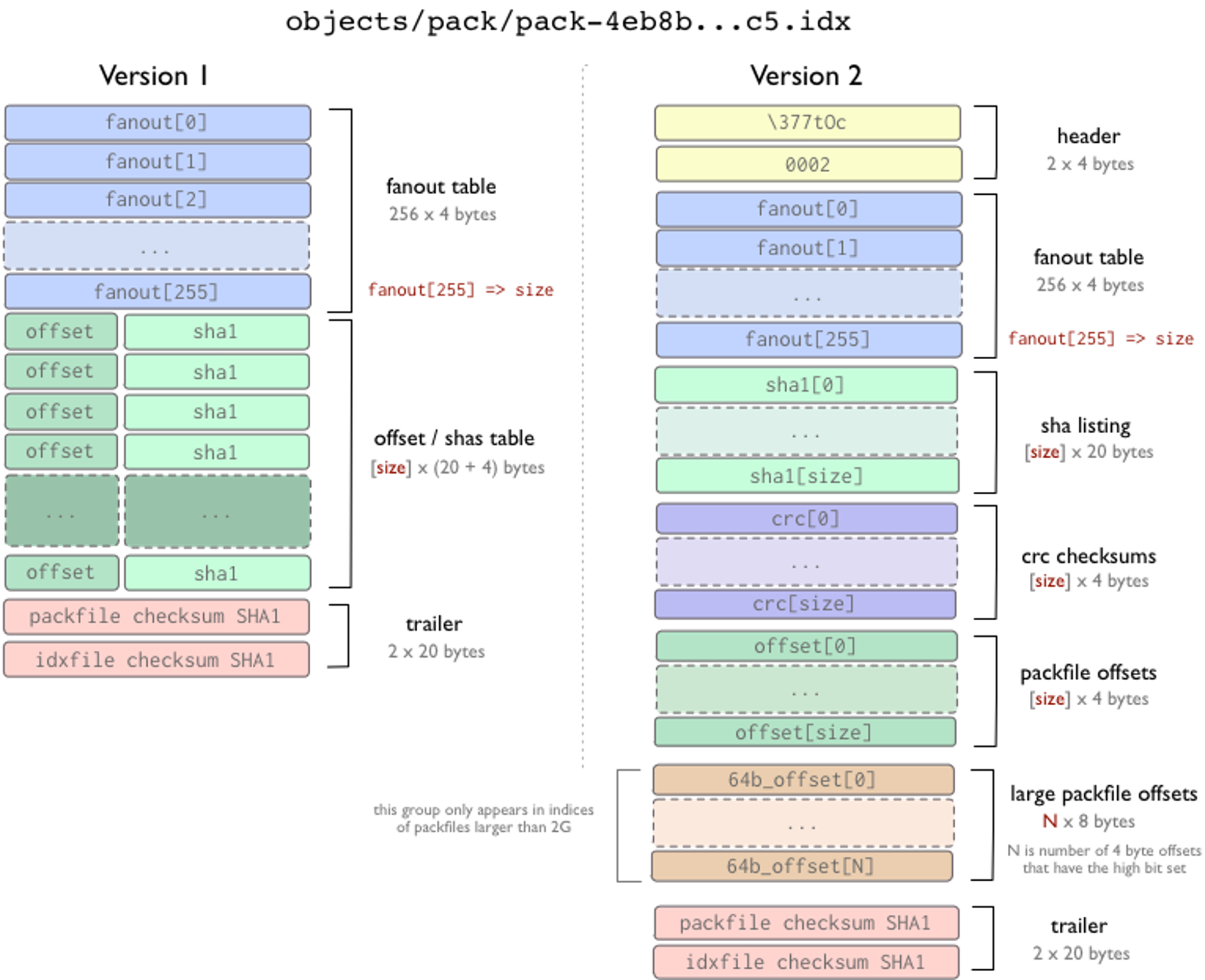
版本 1 的 Pack-Index 現在已經很難見到,原因很簡單,不支持 Pack 檔案大于 4 GB,版本 2 格式非常有趣,魔數為 '\377','t','O','c',第二個 4 位元組就是版本資訊,隨后是 256 * 4 的扇區表,0~254 分別表示前綴從 0x00~0xFE 的物件數量,而 fanout[255] 則表示所有物件的數量,隨后物件 ID 按字典排序到 sha listing,緊接著是相應的 crc checksums,然后是 packfile offsets,packfile offsets 是 4 位元組的,這并不能支持 Pack 大于 4 GB,而后續的 large packfile offsets 則支持了 Pack 大于 4 GB,當 4byte offset 最高位是 1 時說明需要從 large packfile offsets 讀取長度,
Pack Index 檔案很好的解決了 Pack 檔案的隨機讀取的問題,按照其特性,我們在查找 Git 物件時,使用二分法查找,最多 8 次就可以在找到物件在 Pack 中的偏移,進一步讀取檔案,
但如果 Pack 檔案數量特別多時,還是會遇到查找物件性能較多,微軟在將 Windows 原始碼遷移到 Git 后也遇到了這個問題,后來在微軟工程師的努力下,multi-pack-index(MIDX)出現了,存在多個 Pack 檔案時,MIDX 便可以加快 Git 物件的查找,
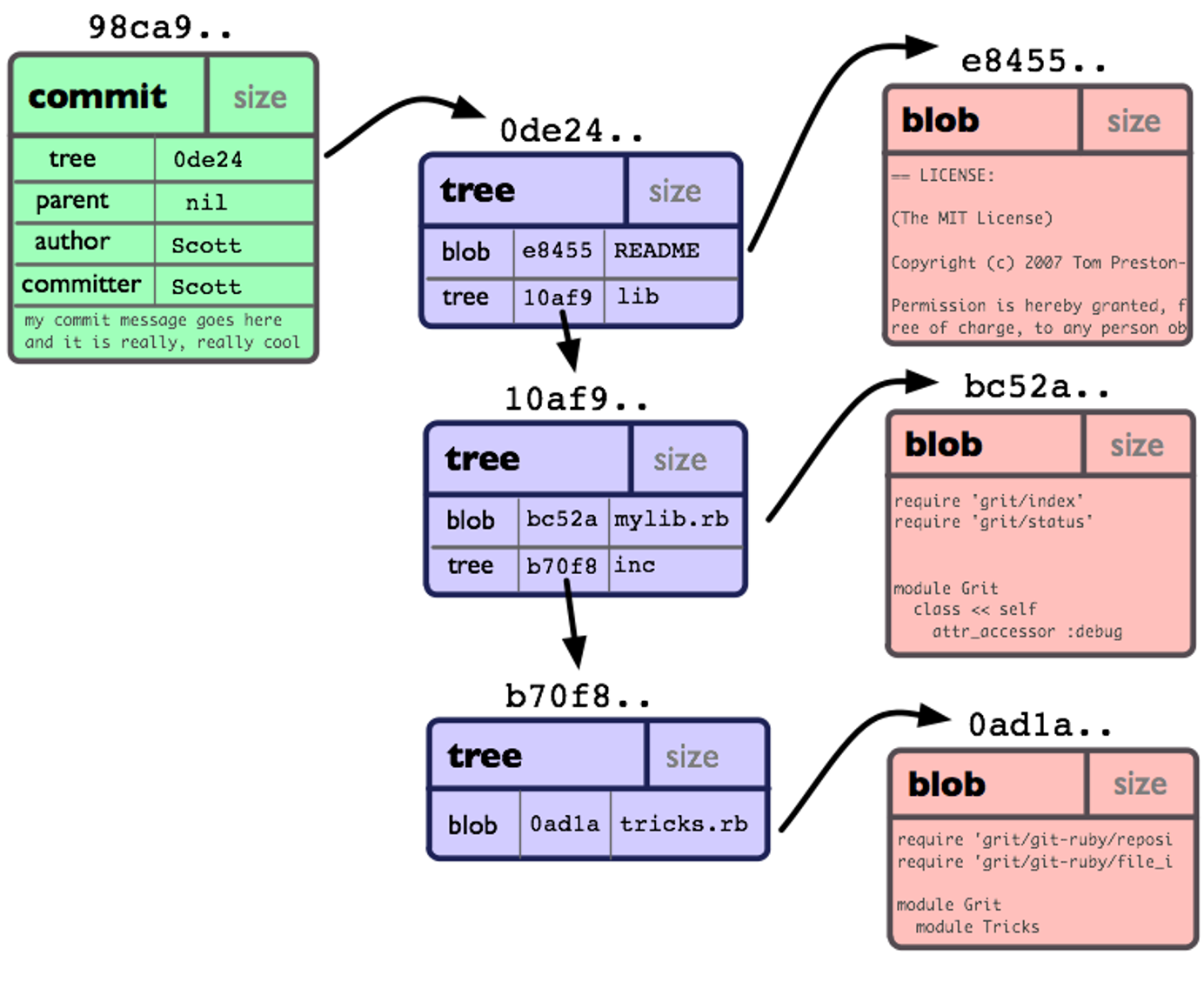
既然我們已經對 Git 的存盤有了個簡單的認識,那么要找到某個檔案也不在話下,分支對應了一個提交,提交有一個 ID,我們可以在松散物件或者打包物件中找到該 ID,然后獲得提交的內容,找到 tree 后,按照路徑一級級往下找,找到路徑匹配的 blob,該 blob 解壓后的內容就是檔案的原始內容,一個簡單的流程如下:
對于參考而言,通常存盤在 refs 目錄下,和松散物件一樣,這種機制可能存在性能問題,因此,在運行 git gc 后,參考會被打包到 packed-refs 檔案中集中管理,為了加快參考的查詢,參考名會使用字典排序,Git 同樣會使用二分法查找在 packed-refs 中查找參考,盡管查找參考的速度非常快,但面對 Android 這樣參考數量巨大的專案,Git 依然會顯得心有余而力不足,這就需要設計一個好的方案解決其性能問題,
Git 存盤原理的運用
了解到 Git 的存盤原理后,我們可以基于其原理做一些有趣的事情,比如要快速找到存盤庫中存在哪些大檔案,我們可以通過分析 Pack Index,將檔案的偏移按照遞減的順序排列,依次相減就可以知道某一物件在 Pack 中占據的大致大小,這樣就可以實作大檔案的檢測,這種機制要比從 Pack 中依次讀取檔案大小高效的多,同時對于平臺而言,盡管存在一些誤差,但這種方案卻是十分經濟有效的,
另外,在實作代碼托管平臺存盤庫快照的功能時,可以通過研究存盤庫參考的存盤機制,利用參考名稱空間實作存盤庫的快照,相對于直接克隆快照的方案,該方案節省了非常大的存盤空間,
Git 的傳輸協議
對于現代版本控制系統而言,傳輸協議與代碼托管平臺的關系更為密切,只要支持了該版本控制系統的傳輸協議才意味著平臺支持這個版本控制系統,要支持 Git,代碼托管平臺也就需要了解 Git 的傳輸協議,
傳輸協議的發展
和版本控制系統的不斷發展類似,Git 的傳輸協議也是在不斷發展以適應新的情況,談到 Git 傳輸協議,我們最常用的是智能協議,除了智能協議,Git 還有本地協議,啞協議(Dump Protocol),以及有線協議(Wire Protocol/v2 Protocol),本地協議通常指通過檔案系統路徑或者 file:// 協議路徑訪問本機上的存盤庫的協議,該協議本質上是通過命令呼叫將其他目錄的存盤庫拷貝到指定目錄,這類協議的用處較少,其中有一個細節需要講清楚,基于檔案系統路徑的克隆,也就是非 file:// 協議克隆,會將源存盤庫的物件,這里通常是 .pack 檔案通過硬鏈接的方式共享,這實際上是利用了 Git 物件的只讀特性,也就是只能洗掉和新增而不能修改,另外,兩個目錄并不在同一個磁區則不支持硬鏈接,也就不能使用硬鏈接共享物件,
啞協議旨在為服務端沒有 Git 服務時提供只讀的 Git Over HTTP 訪問支持,正因為不支持寫操作,目前幾乎所有的公共代碼托管平臺均已經不在支持啞協議了,
既然啞協議不堪重任,那么也只能另起爐灶設計一個好的協議了,這就有了智能協議,但隨著 Git 被廣泛使用,智能協議也有一些先天性缺陷,于是就產生了有線傳輸協議,
智能傳輸協議
Git 目前主要支持的網路協議有三種,分別是 http(s)://,ssh://,git:// 無論哪種協議,拉取實質上都是 git-fetch-pack/git-upload-pack 的資料交換,推送都是 git-send-pack/git-receive-pack 的資料交換,在 2018 年以前,均是采用智能傳輸協議,我們可以使用 Wireshark 這樣的工具抓包分析其傳輸流程,也可以使用 GIT_CURL_VERBOSE=2 GIT_TRACE_PACKET=2 這樣設定環境變數后運行相關命令除錯 Git,在 Windows 中可以使用我撰寫的包管理器 baulk 中的命令運行器 baulk-exec 運行相關命令,如:
baulk-exec GIT_CURL_VERBOSE=1 GIT_TRACE_PACKET=2 git ls-remote https://github.com/baulk/baulk.git
分析協議的方法已經有了,我們就可以輕易的知道智能協議的流程,以 http(s):// 為例,我們把傳輸的第一個步驟叫做參考發現,客戶端根據存盤庫的 URL 使用 GET 請求到 /repo.git/info/refs?service=git-upload-pack 這樣的地址,服務端則以 --advertise-refs --stateless-rpc 這樣的引數啟動 git-upload-pack,該命令啟動后將存盤庫目前的 HEADcommitID,存盤庫支持的 capabilities,以及 HEAD 對應的 symref 以及所有的參考名及其 commitID 回傳給客戶端,客戶端根據這些資訊,以及本地的存盤庫已經存在的物件清點出需要的 want 和存在的 have commitID,然后通過 POST /repo,git/git-upload-pack 發送給服務端,服務端通過執行 git-upload-pack --stateless-rpc /path/to/repo.git 將打包好的物件回傳給客戶端,待客戶端清點好物件,傳輸就結束了,對于 git pull 請求還需要將更新的檔案檢出到作業目錄,
這里需要注意,實施 Git Over HTTP 服務器時,Git 客戶端需要在 POST 請求回應最開始添加 001e# service=git-upload-pack\n0000,另外我們還需要正確的設定 Content-Type,服務端處理POST 請求時,請求體可能使用 gzip 編碼,需要解壓縮處理,
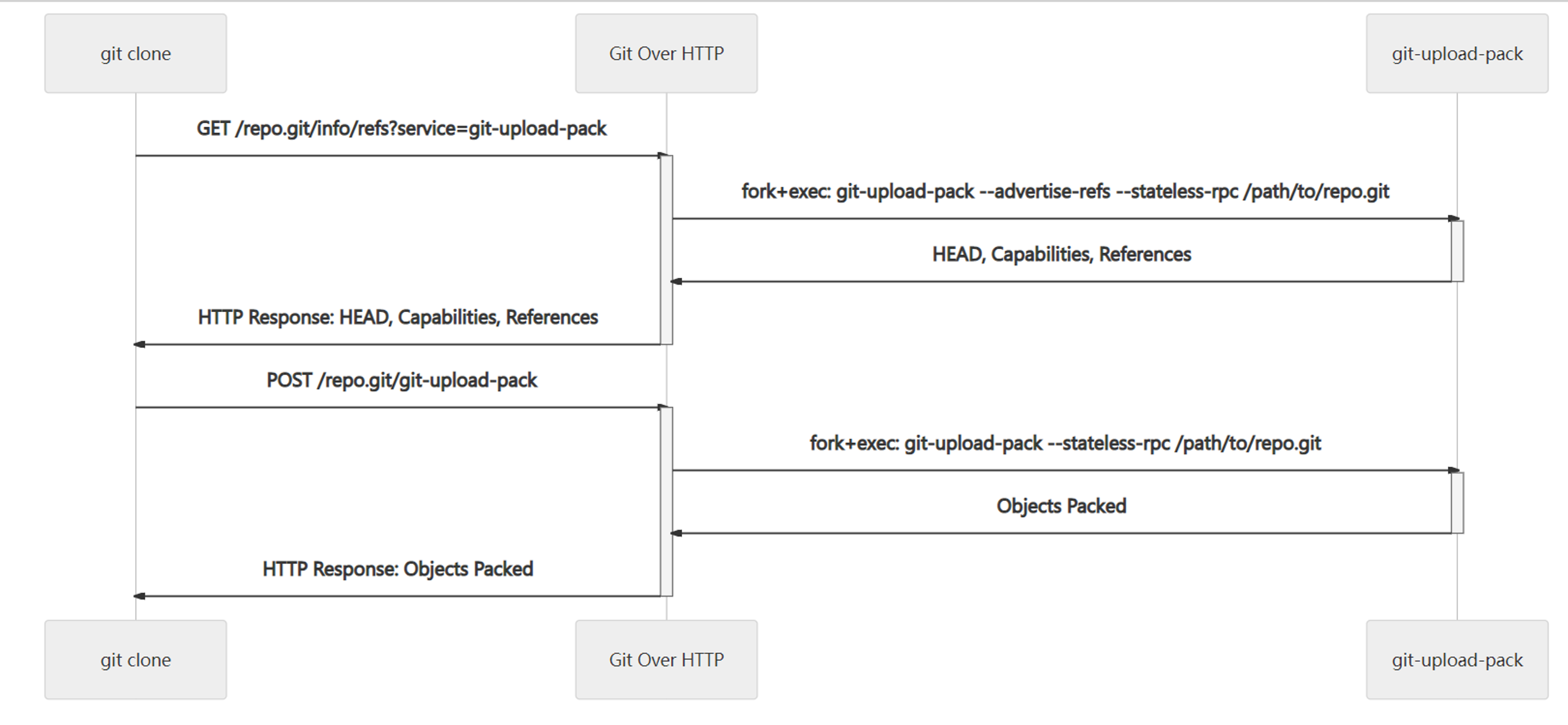
推送的傳輸協議流程類似,但服務變為 git-receive-pack,相關的流程如下:
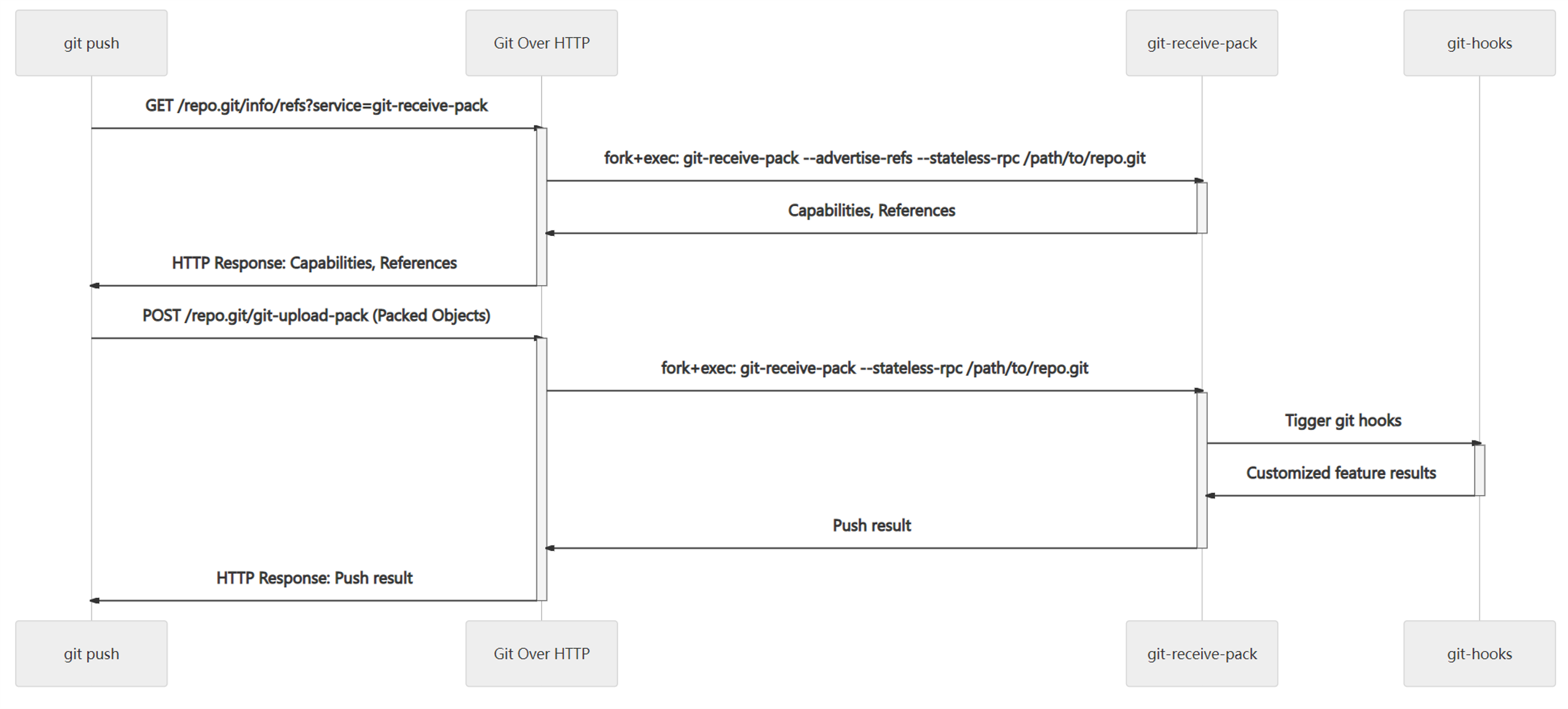
在推送時,Git 協議本身的權限驗證機制極其有限,一些分支權限控制等安全功能基本上只能通過鉤子實作,而鉤子的標準錯誤實際上也會被 Git 命令列捕獲作為回應回傳給客戶端,如果客戶端的 Git 恰好運行在 Windows Terminal、Mintty、iTerm 等等終端中,那么我們就可以將一些資訊以彩色的形式輸出給用戶,這些資訊使用 ANSI 轉義的,
ssh:// 協議和 git:// 協議同樣支持智能傳輸協議,實作起來只需要把為客戶端連接和 git-upload-pack/git-receive-pack 的標準輸入和輸出建立資料交換的通道即可,在實施 Git Over SSH SSH 服務器時,像 GitLab 會直接使用 OpenSSH,但 OpenSSH 可定制性有限,在分布式 Git 平臺上需要實作模擬的 git-upload-pack/git-receive-pack 這樣的命令,效率較低,像 GitHub 早期使用了 libssh 實作了 Git Over SSH 服務,BitBucket 使用了 Apache Mina SSHD,還有一些平臺使用了 Golang crypto/ssh,無論采用什么樣的技術,都應該經過慎重考慮,是否契合平臺的架構,維護成本是否合適等等,在實施 Git Over TCP (git://) 服務器時,只需要決議第一個 pktline 資料包即可,git:// 協議簡單,表達能力有限,沒有足夠的權限驗證,公有云除了 GitHub 其他平臺使用的較少,但我在設計讀寫分離和高可用時,會優先考慮使用 git:// 協議作為內部傳輸協議以降低內部負載,
ssh:// 協議和 git:// 協議可以支持資料的多次往返,而 http(s):// 協議只能是 Request-->Response 這樣的一個來回,不同的來回實際上狀態已經丟失,所以需要指定為 State Less 也就是無狀態,
智能協議雖然非常簡單,但我們在 Git Over HTTP 上支持 shallow clone 時卻不得不注意一些細節,在協商 commit deepin 時,客戶端和服務端都在等待對方的回應,這時我們只能通過提前關閉服務端的標準輸入中斷一方的等待,這就是智能傳輸協議的大問題,HTTP 傳輸實作復雜,不支持擴展,另外隨著 VFS for Git 這樣技術的誕生,使得一個問題浮現在公眾面前:“巨型存盤庫如何優化克隆”,VFS for Git 重新設計了傳輸協議更顯得智能傳輸協議在這上面尤為不足,
有線傳輸協議
Google 開發者的思路是,通過一個特殊的環境變數開關控制協議的切換,從外表看,傳輸協議仍然是幾組命令的輸入輸出交換,但從內在看,新的傳輸協議更像是利用低級別的命令實作功能的擴展,我們依然可以使用上面的除錯方法分析 Git 有線協議的傳輸流程,在新的協議中,服務端先回傳了版本資訊,支持的命令,過濾器,物件格式等等,客戶端再次發送請求需要使用 ls-refs 發現參考,然后是 fetch 命令(以下截圖中沒有這一操作)獲得資料,
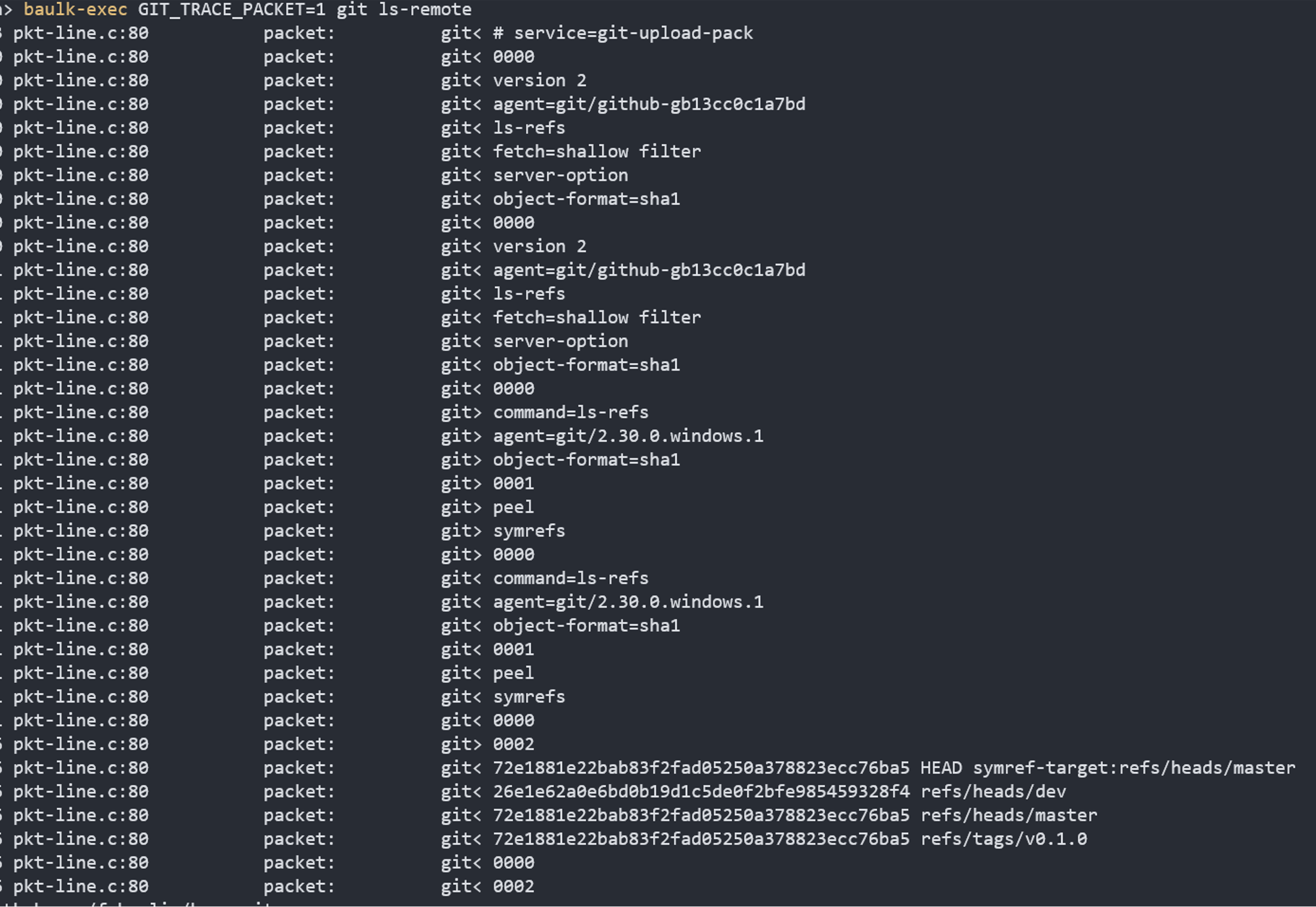
實施 Git 有線傳輸協議非常簡單,只需要升級 Git 命令,檢測客戶端請求是否為 GIT_PROTOCOL=2,然后以環境變數 GIT_PROTOCOL=2 啟動上述命令即可,在我們的博客《Git Wire 協議雜談》 中也有介紹,
Git Wire 協議是 Git 的一次大的改變,在協議中添加了命令、filter 等機制,有效解決了傳輸協議中最低效的部分,增強了可擴展性,比如我們使用部分克隆時,需要添加 blob filter,即我不需要我就可以不下載檔案;支持 SHA256 時,告訴服務端,我需要 object-format=sha256,這為 Git 增加了無限可能,目前 Git 的部分克隆,SHA256 存盤庫都依賴有線傳輸協議,
實際上集中式版本控制系統 SVN 早就利用子命令擴展了協議能力,SVN 協議使用 ABNF 描述協議,要比 Git 的有線協議決議起來復雜一些,
Git 資料的交換
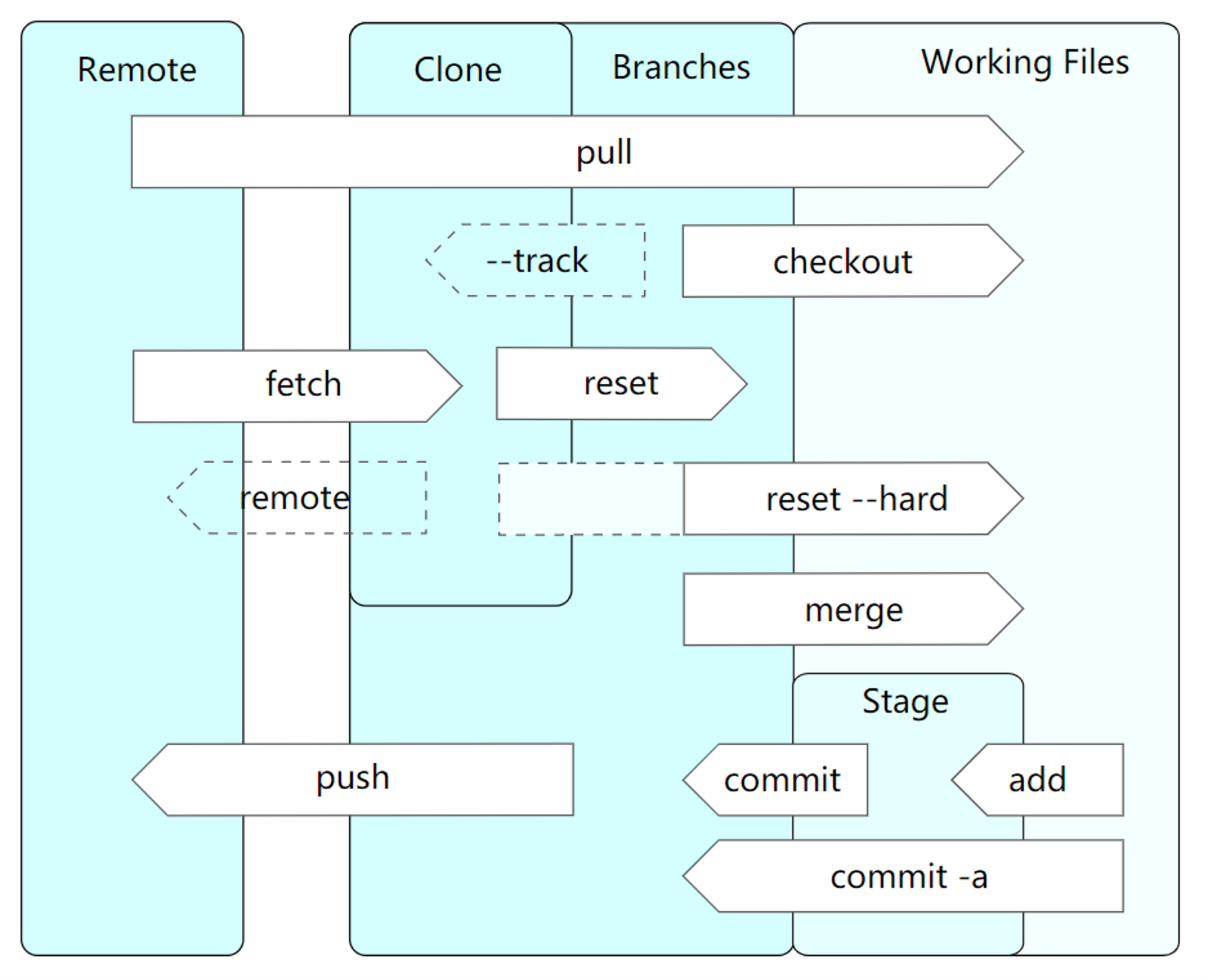
了解了 Git 的存盤結構和傳輸協議后,再建立宏觀上的 Git 資料交換映像就容易得多,對 Git 的操作實際上是發生在三個區域,工作區是我們實質上修改,添加,洗掉檔案的地方,通過 git add/commit/checkout 等命令,我們就將作業區的檔案納入版本管理了,通過 git push/fetch 等命令,就將本地存盤庫和遠程建立了關聯,這里需要注意,git pull 實際 上是 git fetch+ git checkout(沒有 merge 的情況下),大致如下圖:
大型 Git 代碼托管平臺的關鍵問題
隨著平臺規模的增長,代碼托管從業人員也會遇到一些問題難以解決,在我職業生涯中同樣如此,解決問題的程序是艱辛的,去年年底,我曾經寫過一篇文章:《性能,可擴展性和高可用 - 大型 Git 代碼托管平臺的關鍵問題》,文章的內容與本節內容相似,這里帶領讀者重新回顧一下,
大型存盤庫的優化
目前國內 IT 行業版本控制系統都在往 Git 遷移,一些大型企業,軟體原始碼歷史悠久,存盤的檔案各種各樣,在遷移到 Git 時,體積巨大的存盤庫給代碼托管平臺帶來了壓力,首當其沖的問題就是從其他版本控制系統遷移到 Git 耗時太長,
Git 在安裝了 SVN 的前提下,支持 git svn 命令訪問 SVN 倉庫,從 SVN 倉庫遷移到 Git 的邏輯很簡單,就是從 Rev0 開始,遞回的創建 Git 提交,如果這個存盤庫歷史悠久,提交特別多,檔案特別多,那么轉換耗時將非常長,網路上也有一種優化方案,直接在 SVN 中央存盤庫,通過決議存盤庫元資料,直接在上面創建 Git 提交,這種方案的耗時可能是原本的數十分之一,KDE 團隊維護的 svn-all-fast-export aka svn2git 就是其中一款,
轉移到 Git 后,如果存盤庫包含很多的二進制檔案,存盤庫體積巨大,那么用戶拉取的時間還是會很長,一種解決方案是將不同的資料分離,也就是將體積大的二進制檔案,通過 Git 擴展 git lfs 追蹤,從原始碼中排除,通過這種措施存盤庫的體積減小,平臺的壓力降低,而這些大檔案可以存盤到其他的設備上,比如物件存盤,利用 CDN 優化,就能提升用戶的體驗.實作 Git LFS 服務器可以參考我之前的博客《Git LFS 服務器實作雜談》,
如果存盤庫小檔案特別多,這個時候 Git LFS 的作用反而沒有那么大了,Git LFS 并不存在打包機制,也沒有壓縮,如果大量檔案使用 Git LFS 跟蹤,那么 HTTP 請求數會變得非常多,傳輸時間也會特別長,微軟在將 Windows 原始碼遷移到 Git 做技術選型便遇到了問題,Windows 原始碼數百 GB,參考數量數十萬,這些傳統方案和 Git LFS 完全不能解決,于是微軟的開發者推出了 VFS for Git 用來解決這個問題,簡單來說,VFS for Git 的手段是只獲得淺表 commit 以及相應的 tree 物件,然后在檔案系統建立虛擬檔案,也就是用戶空間檔案系統 Filesystem in Userspace (FUSE) 創建占位符檔案,但向這種檔案發起 IO 操作時,驅動會觸發 VFS for Git 客戶端取請求遠程服務器,獲得這些檔案,在 Windows 上 FUSE 使用了 NTFS 重決議點,其 TAG 為 IO_REPARSE_TAG_PROJFS,微軟前員工 Saeed Noursalehi(現已加入 Facebook)曾寫過一些 VFS for Git 的文章,比如 《Git at Scale》以及《Git Virtual File System Design History》,大家有興趣可以看一下,VFS for Git 驚艷的架構也吸引了 GitHub 的注意,當時 GitHub 還未被 Microsoft 收購,GitHub 創建了 Linux projected filesystem library 專案試圖在 Linux 上創建類似 Windows 平臺的 projfs,以支持 VFS for Git 在 Linux 上運行,但該專案一直沒有被完成,
VFS for Git 的設計是獨樹一幟的,也很難推廣開來,目前除了 Microsoft 的 Azure,其他平臺幾乎都沒有支持,核心就是 Git 客戶端支持難度高,后來 Git 的一些開發者提議在 Git 中實作部分克隆,經過幾年的努力,終于支持部分克隆,該方案和 VFS for Git 類似,使用有線傳輸協議的 filter 機制,實作一個 blob filter 過濾掉 blob,與 VFS for Git 存在差異的是,沒有 FUSE 加成,最終使用有限,是否能夠有其他手段提升部分克隆的實用性,還得 Git 貢獻者們進一步的努力了,
最近,Git 貢獻者還增加了 Packfile URIs 設計,該方案旨在將物件通過 CDN 存盤,然后客戶端根據回傳的地址請求到合適的 CDN 下載存盤庫物件,該方案仍處于早期,還有許多細節要處理,最終能做到什么程度有待觀察,
代碼托管平臺伸縮性
大型代碼托管平臺面臨的另一個問題則是系統的伸縮性,在架構上具備良好的伸縮性則意味著平臺能做到多大的規模,比如 Gitea/Gogs 這種傾向于單節點的開源代碼托管平臺要做到大型分布式代碼托管平臺就麻煩得多,而 GitLab 則更容易搭建分布式可擴展的代碼托管平臺,
在討論伸縮性之前,我們要解釋一下分布式檔案系統為什么不適合大型代碼托管平臺,
- Git 的計算壓力并沒有隨著分布式檔案系統的擴展性而分攤,
- 分布式檔案系統很難解決 Git 小檔案的問題,特別是小檔案帶來的系統呼叫,IO 問題,
- 分布式檔案系統反而會帶來平臺內部網路資料的消耗,比如檔案的元資料,以及檔案的資料,
- 國內外廠商的生產事故歷歷在目,
當了解到分布式檔案系統不合適之后,我們也就只能采用笨辦法,分片,將存盤庫分布在不同的存盤節點,Git 命令也在這個節點上運行,這樣無論是計算還是 I/O 都能夠通過存盤節點的擴展實作擴容,這就是 Git 目前最主要的分布式解決方案,
通過這樣的方案實作平臺的伸縮性時,還需要解決一些分布式環境常見的問題,比如存盤庫的分布,存盤庫佇列等等,當然這些都有可用的方案,在本文就不展開細說,
主從同步,讀寫分離和多寫高可用架構探討
無論是公共代碼托管平臺還是私有化部署的代碼托管服務,當代平臺發展到一定程度,高可用這個問題就會被反復提及,分布式系統的架構設計難度較高,與傳統的單機服務有很大的差別,而 Git 代碼托管平臺分布式系統與普通的分布式系統有更大的差異,高可用的設計不僅要吸納主流的分布式系統的架構經驗,還需要迎合 Git 的特性,另外還需要考慮到架構的經濟性,
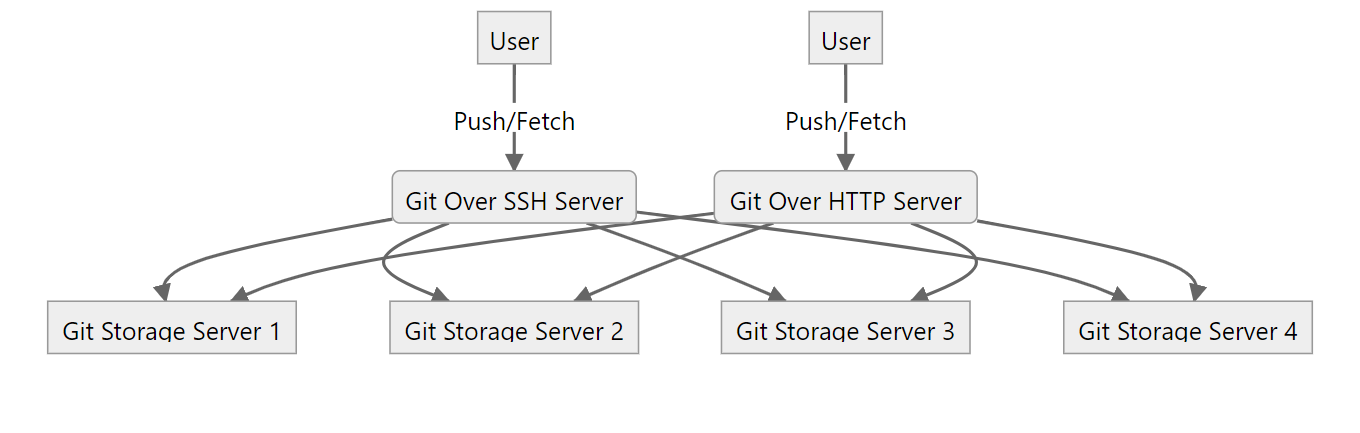
首先我們看一下分布式大型代碼托管平臺的簡易架構(下圖的架構是精簡版本,與實際架構存在差距),從下圖我們可以看到,用戶的 Git 請求實際上并不是直接請求到存盤節點上的 Git 服務,而是通過代理服務轉發過去,這些代理服務通過路由模塊獲得存盤庫位于那個存盤節點,從架構上講,這些代理服務都可以做到無狀態,通過部署多個服務副本再在前端入口添加負載均衡健康檢查,可以很好地做到這些代理服務的高可用,但這個架構也意味著存盤節點上的存盤庫并不能支持高可用,
存盤庫要支持高可用,應該在不同的存盤節點上都存在副本,在一個副本所在的節點無法正常提供服務時,需要其他副本所在的節點能夠頂上來提供服務,這些副本要始終保持一致,如果不一致,在切換的時候就會出現資料紊亂,這顯然是不符合用戶期望的,高可用可分為主從同步高可用,以及讀寫分離高可用,還有同時多寫高可用(多寫高可用),設計一個簡單的主從同步高可用系統,我們首先需要保證存盤庫的一致性,這里可以通過 git hooks 觸發存盤庫實時同步,存盤庫副本分布在不同的節點,在用戶推送代碼后,被更新的存盤庫副本及時將資料通過內部傳輸協議同步到其他副本,早期 GitHub 使用 DRDB 實作同步,目前大多使用 Git 傳輸協議實作同步,我個人更偏好于實作自定義的 git:// 提供存盤庫同步功能,
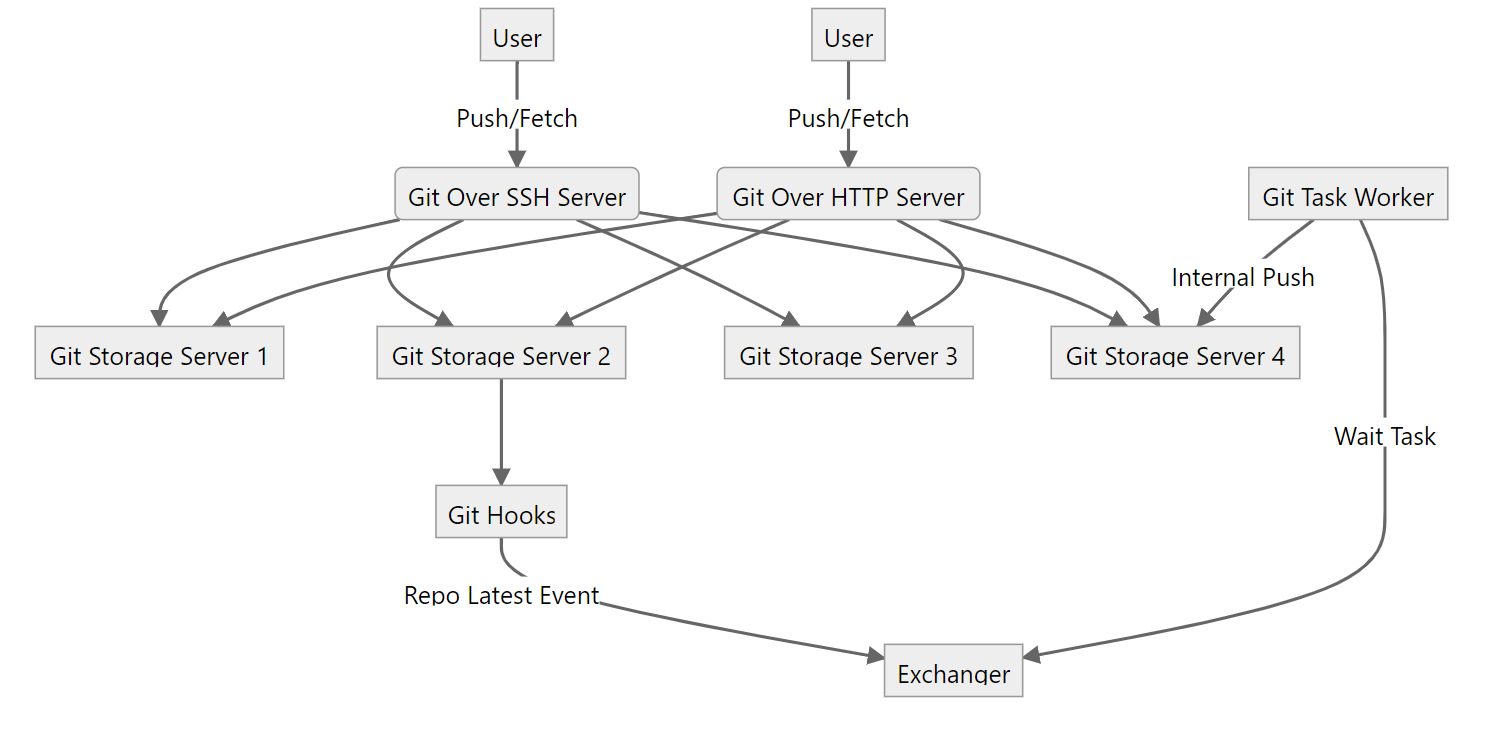
存盤庫實作了實時同步,還需要有一種機制保證存盤庫資料一致,GitHub 的方案是回圈哈希校驗和,而我的方案是使用 BLAKE3 計算參考哈希,原理很簡單,就是將存盤庫的參考按字典排序計算哈希值,哈希值一致意味著兩個存盤庫的參考一致,參考一致存盤庫克隆獲得的資料也就是一致的,兩個存盤庫肯定一致,
這里主從同步高可用如果支持將讀取請求轉發到其他副本而不僅是主副本,那么這種情況就叫讀寫分離高可用(簡稱讀寫分離),讀寫分離的好處就是對于特別活躍的存盤庫能夠提供更高的并發,當然無論是看似簡單的主從同步,還是復雜的讀寫分離,內里考慮的細節并不少,環環相扣,需要對整個代碼托管架構有一個清晰的認識,
實施類似 Github Spokes (DGit is now Spokes) 一樣的多寫高可用要復雜一些,主要難點是要支持同時寫入到多個副本,要做到這一點需要實作一些約束性條件:
- 寫入到多個副本的前提是多個副本的資料是一致的,GitHub 使用了三階段提交協議先判斷是否可以寫入,寫入的前提就是服務正常,存盤庫一致,
- 存盤庫的參考更新應該是事務的,也就是說可以回滾事務,這樣在寫入到其中一個節點失敗后,其他的節點上實時回滾,這一點可以考慮使用原子更新參考,可以修改 git receive-pack 原始碼增強實作該功能,
- 代碼托管平臺常常使用 Git 鉤子實作一些功能,這些鉤子的操作是否等冪,也就是說,鉤子的執行結果在不同的副本上退出碼必須一致,如果不同副本中執行鉤子不做區別,我們要保證鉤子中請求 API 授權的結果一致,避免內部服務故障照成影響,執行 post-receive 鉤子產生動態或者觸發 WebHook 時需要進行訊息去重,避免多次執行,當然還有一種方案就是只執行一次鉤子,然后使用協調機制將鉤子的結果廣播到其他副本,共同進退,
- 存盤庫在不一致,或者從停機中恢復后,多寫高可用依然需要考慮存盤庫的同步,以保證不同節點的一致性,
要設計好高可用,應該實作一套良好的故障檢測機制,合理的方案有多種,可以用專門的服務檢測磁盤是否可用,服務是否聯通,出現故障時標記不可用,恢復后直接標記為正常即可;還可以通過學習,將前端服務與存盤節點通信的錯誤采集分離,進行健康評估,在節點故障時將其下線,兩者都需要不斷的汲取經驗,故障的錯誤標記往往是災難性的,GitHub 就出現過這樣的事故,給其聲譽帶來了一定的影響,
無論是主從同步還是讀寫分離以及實時多寫架構,都需要給存盤庫創建多個副本,這就意味著存盤空間的消耗加倍,每個存盤庫有一個副本,存盤空間的消耗就要增加一倍,兩個副本就增加兩倍,所以在設計高可用系統的時候還需要考慮到經濟因素對架構的影響,這也是國內代碼托管行業高可用架構發展并不順利的原因之一,
多寫系統如果能修改 Git 原始碼實作一些細節的優化,這在架構上有更好的設計余地,比如我們可以修改 Git 原始碼支持主動非侵入資料流的原子更新,我們也可以在 receive-pack 中修改執行鉤子的邏輯,使其更符合讀寫系統的設計,而現實并不令人滿意,沒有足夠的人手能夠參與 Git 的研究,這阻礙了國內代碼托管行業的創新,很容易陷入只能苦苦追隨前人的困境,
思考
代碼托管早期有 SourceForge,我剛剛作業時,構建的 Clang On Windows 便是發布在 SourceForge 上分發的,現在已經好幾年沒登錄 SourceForge 了,Git 的發展不快不慢,但終歸是流行起來了,GitHub 把其他平臺徹底碾壓,有點所向披靡的樣子,不過國內得益于政策環境,GitHub 想進來并不容易,國內也就有了另一番天地,但是做到 GitHub 那樣的規模并不容易,做到 GitHub 那樣的技術更不容易,羅馬不是一天建成的,這仍需要同行們的持續努力,
參考資料
- Git Repository Layout
- Git Internals - Git Objects
- Git Virtual File System Design History
- Git at Scale
- 《性能,可擴展性和高可用 - 大型 Git 代碼托管平臺的關鍵問題》
- 《探討 Git 版本控制系統的若干問題 - 2020 版》
- 《探討 Git 代碼托管平臺的若干問題 - 2019 版》
- 《服務端 Git 鉤子的妙用》
- 《基于 Git Namespace 的存盤庫快照方案》
- 《構建恰當的 Git SSH Server》
- 《Git 原生鉤子的深度優化》
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/252957.html
標籤:其他
上一篇:Linux LVM管理的小練習