目錄
前言:
1. 下載最新的hadoop 安裝包
2. 安裝hadoop
2.1 查看java環境位置
2.2 修改hadoop-env.sh檔案
2.3 修改core-site.xml
2.4 組態檔系統 hdfs-site.xml
2.5 配置計算框架 mapred-site.xml
2.6 組態檔系統 yarn-site.xml
2.7 Hadoop namenode 格式化
3. 啟動hadoop集群
3.1 如果Connection refused配置ssh
3.2 util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
3.3 發現http://localhost:50070啟動之后打不開,其實hadoop3.0之后變成了http://localhost:9870
3.4 18088 yarn正常
前言:
Hadoop運行環境基于Java,必須要有jdk環境
修改組態檔,用圖形化的就好,不用非得vim,右鍵要打開的檔案,選擇打開方式-文本編輯,
注意建立檔案夾,給與最高權限哈,否則可能會出問題,
1. 下載最新的hadoop 安裝包
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
也可以用brew安裝
brew install hadoop
brew下載的話,會在/usr/local/Cellar/ 這個目錄下面,
那么去找:
/usr/local/Cellar/hadoop/直接下下來:
我選擇直接下下來,放在我常用的環境目錄,(因為brew好慢)
下下來直接用圖形化的拷貝到想放的目錄,然后雙擊解壓即可,
我放在了用戶根目錄建了一個environment的檔案夾,常用的環境變數都放在那了
/Users/dk/environment/hadoop/hadoop-3.2.2
2. 安裝hadoop
這個是解壓縮hadoop所在的檔案夾目錄
HADOOP_HOME=/Users/dk/environment/hadoop/hadoop-3.2.2
先編輯
vim ~/.bash_profile添加下述內容,注意 HADOOP_HOME要更改為你自己的安裝環境目錄
vim 按i 進行插入編輯,按esc然后:wq!保存
# hadoop
export HADOOP_HOME=/Users/dk/environment/hadoop/hadoop-3.2.2
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin-
退出編輯模式,使用 :wq! 保存修改
-
使環境變數生效 source ~/.bash_profile
終端輸入檢查是否配置成功:
hadoop versionHadoop 3.2.2
Source code repository Unknown -r 7a3bc90b05f257c8ace2f76d74264906f0f7a932
Compiled by hexiaoqiao on 2021-01-03T09:26Z
Compiled with protoc 2.5.0
From source with checksum 5a8f564f46624254b27f6a33126ff4
This command was run using /Users/dk/environment/hadoop/hadoop-3.2.2/share/hadoop/common/hadoop-common-3.2.2.jar
2.1 查看java環境位置
終端輸入:
/usr/libexec/java_home結果:
/Library/Java/JavaVirtualMachines/jdk1.8.0_261.jdk/Contents/Home
接下來修改etc/hadoop/下面的sh檔案和xml組態檔(我直接在圖形化界面找的)
2.2 修改hadoop-env.sh檔案
command+f 搜索
# export JAVA_HOME=
然后填充上面的java環境位置
2.3 修改core-site.xml
放在<configuration>里面</configuration>
默認情況下,Hadoop 將資料保存在/tmp 下,當重啟系統時,/tmp 中的內容將被自動清空, 所以我們需要指定自己的一個 Hadoop 的目錄,用來存放資料,
另外需要配置 Hadoop 所使用的默認檔案系統,以及 Namenode 行程所在的主機,
注意更改 file的位置,換成自己建立的一個快取目錄
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!--用來指定hadoop運行時產生檔案的存放目錄 自己創建-->
<property>
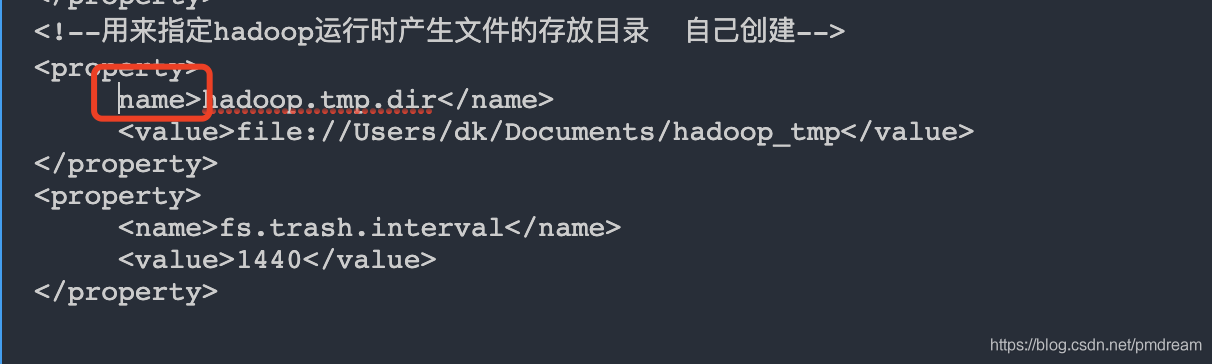
<name>hadoop.tmp.dir</name>
<value>file:/Users/dk/Documents/hadoop_tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
2.4 組態檔系統 hdfs-site.xml
該檔案指定與 HDFS 相關的配置資訊,需要修改 HDFS 默認的塊的副本屬性,因為 HDFS 默認 情況下每個資料塊保存 3 個副本,而在偽分布式模式下運行時,由于只有一個資料節點,所 以需要將副本個數改為 1;否則 Hadoop 程式會報錯,
注意更換目錄,自己建立dfs/name檔案夾
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--不是root用戶也可以寫檔案到hdfs-->
<property>
<name>dfs.permissions</name>
<value>false</value> <!--關閉防火墻-->
</property>
<!-- name node 存放 name table 的目錄 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/Users/dk/Documents/hadoop_tmp/dfs/name</value>
</property>
<!-- data node 存放資料 block 的目錄 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/Users/dk/Documents/hadoop_tmp/dfs/data</value>
</property>2.5 配置計算框架 mapred-site.xml
可能歷史版本,沒有mapred-site.xml,提供了模板 mapred-site.xml.template 將其重命名為 mapred-site.xml 即可,
該版本存在,直接編輯,
<property>
<!--指定mapreduce運行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>2.6 組態檔系統 yarn-site.xml
<!-- Site specific YARN configuration properties -->
<property>
<!-- mapreduce 執行 shuffle 時獲取資料的方式 -->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>localhost:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>localhost:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>localhost:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>localhost:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>localhost:18088</value>
</property>2.7 Hadoop namenode 格式化
hdfs namenode -format 成功則會看到”successfully formatted”和”Exitting with status 0”的提示,若為 “Exitting with status 1” 則是出錯,
報錯
2021-01-26 15:26:37,331 ERROR conf.Configuration: error parsing conf core-site.xml
因為,少了個 <
可以用https://www.runoob.com/xml/xml-validator.html來進行xml校驗,已改正,
見到了successfully成功:
2021-01-26 15:30:30,464 INFO common.Storage: Storage directory /Users/dk/Documents/hadoop_tmp/dfs/name has been successfully formatted.
3. 啟動hadoop集群
正常啟動:
Web UI 查看集群是否成功啟動,瀏覽器中打開http://localhost:50070/,以及http://localhost:18088/;檢查 namenode 和 datanode 是否正常,檢查 Yarn 是否正常,
檢查:
終端輸入jps
遇到了:Connection refused
Starting resourcemanager
Starting nodemanagers
localhost: ssh: connect to host localhost port 22: Connection refused
3.1 如果Connection refused配置ssh
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# 驗證ssh
ssh localhost如果已經配置過git
直接用
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# 驗證ssh
ssh localhost驗證結果:
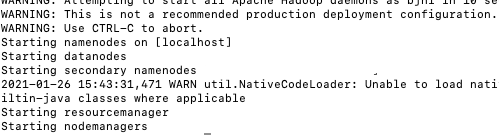
Last login: Tue Jan 26 15:37:56 2021 from 127.0.0.13.2 util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
查詢得到,暫時無視
對后續操作比如
hadoop fs和hive等不影響,不是強迫癥的可以暫時無視它,哈哈),無法為平臺加載本地hadoop庫…可使用合適的內置java類,
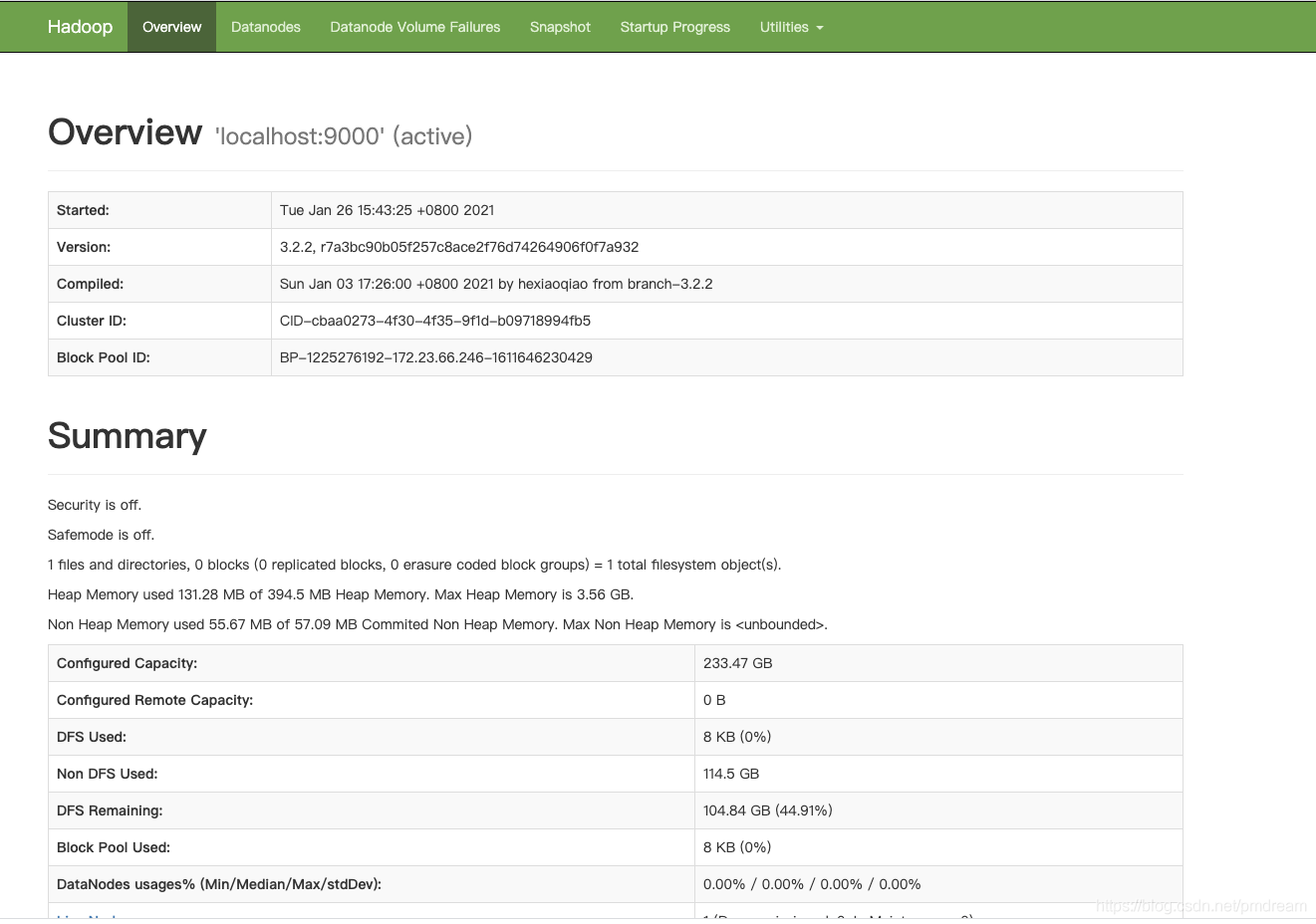
3.3 發現http://localhost:50070啟動之后打不開,其實hadoop3.0之后變成了http://localhost:9870
解決:
自Hadoop 3.0.0 - Alpha 1以來,埠配置發生了變化:
http://localhost:50070
已移至
http://localhost:9870
請參閱 https://issues.apache.org/jira/browse/HDFS-9427
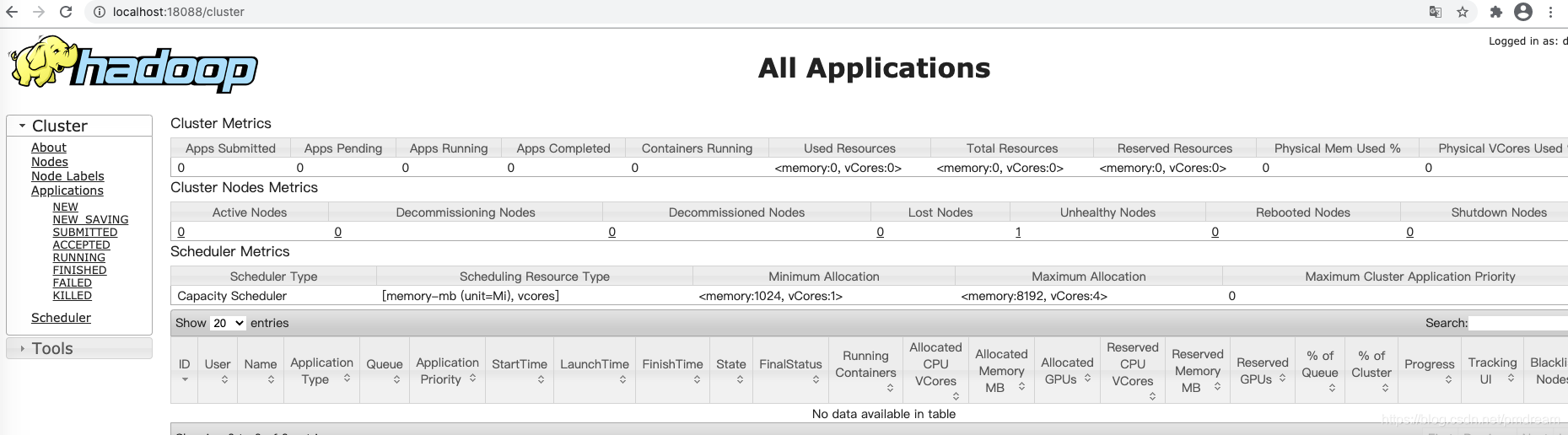
3.4 18088 yarn正常
完整走了一遍安裝配置~下面開始wordcount
參考:https://blog.csdn.net/b_aihe/article/details/96650866
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/253061.html
標籤:其他
上一篇:Flink本地Web UI報錯:Could not start rest endpoint on any port in port range 8081