前言:本文為資料結構之基本概念,根據陳越姥姥的網課而整合的筆記,
一、什么是資料結構
我們以幾個栗子展開解釋:
栗子1:如何在書架上擺放圖書?——如何在空間中儲存資料?
圖書的擺放需要有2個相關操作來實作
操作1:新書怎么插入? 操作2:怎么找到指定的某本書?
方法1:隨便放(操作1實作簡易,操作2實作困難)
方法2:按照書名的拼音字母順序排放,二分法查找書(操作1實作困難,操作2 實作簡易)
方法3:把書分成類別劃分書架區域,按照書名的拼音字母順序排放(操作1,操作2 均實作容易)
總結:解決問題方法的效率跟資料的組織方式有關,
栗子2:寫程式實作一個函式PrintN,使得傳入一個正整數為N的引數后,能順序列印從1到N的全部正整數
方法一:回圈實作
void PrintN(int N)
{
int i;
for(i=1;i<=N'i++){
printf("%d\n",i);
}
return;
}
方法二:遞回實作
void PrintN(int N)
{
if(N){
PrintN(N-1);
printf("%d\n",N);
}
return;
}
當代入N為100,1000,10000,10000…時,會發現N過于大時,方法二因記憶體過大不執行,
總結:解決問題方法的效率,跟空間的利用效率有關,
栗子3:寫程式計算給定多項式在給定點x處的值
方法一:f(x)=a(0)+a(1)x+…+a(n)x**(n)
double f(int n,double a[],double x)
{
int i;
double p=a[0];
for(i=1;i<=n;i++)
p+=(a[i]*pow(x,i));
return p;
}
方法二:f(x)=a(0)+x(a(1)+x(…(a(n-1)+x(a(n)))…))
double f(int n,double a[],double x)
{
int i;
double p=a[n];
for(i=n;i>0;i--)
p=a[i-1]+x*p;
return p;
}
呼叫clock()計算程式運行時間,發現方法二單次運行的時間較長,
總結:解決問題方法的效率,跟演算法的巧妙程度有關,
所以什么是資料結構?
1.資料物件在計算機中的組織方式
(1)邏輯結構
- 同屬一個集合,沒有關系——集合結構
- 一對一——線性結構
- 一對多——樹型結構
- 多對多——圖形結構
(2)物理存盤結構
以陣列儲存還是以鏈表儲存
2.資料物件必定與一系列加在其上的操作相關聯
3.完成這些操作所用的方法就是演算法
怎么描述資料結構?
抽象資料型別
資料型別
- 資料物件集
- 資料集合相關聯的操作集
抽象:描述資料型別的方法不依賴于具體實作
- 與存放資料的機器無關
- 與資料存盤的物理結構無關
- 與實作操作的演算法和編程語言均無關
只描述資料物件集合相關操作機”是什么“,并不涉及“如何做到”的問題
總結:沒有完美的資料結構,只有最合適的資料結構,應該因地制宜,不同的用途(查找、插入…)采用不同的資料結構來提高效率
二、什么是演算法
演算法
1.一個有限指令集
2.接受一些輸入(有些情況下不需要輸入)
3.產生輸出
4.一定在有限步驟之后終止
5.每一條指令必須
- 有充分明確的目標,不可以有歧義
- 計算機能處理的范圍之內
- 描述應不依賴于任何一種計算機語言以及具體的實作手段
什么是好的演算法?
- 空間復雜度S(n)——根據演算法寫成的程式在執行時占用存盤單元的長度,這個長度往往與輸入資料的規模有關,空間復雜度過高的演算法可能導致記憶體超限,造成程式非正常中斷,如栗子二,
- 時間復雜度T(n)——根據演算法寫成的程式在執行時耗費時間的長度,這個長度往往也與輸入資料的規模有關,時間復雜度過高的低效演算法可能導致我們在有生之年都等不到運行結果,如栗子三,
總結:好的演算法應該占用記憶體小,耗費時間短,
復雜度分析小竅門
- 若兩段演算法分別有復雜度T1(n)=O(f1(n))和T2(n)=O(f2(n)),則
- T1(n)+T2(n)=max(O(f1(n),O(f2(n)))
- T1(n)xT2(n)=O(f1(n)x(f2(n))
- 若T(n)是關于n的k階多項式,那么T(n)=o(n**k)
- 一個for回圈的時間復雜度等于回圈次數乘以回圈體代碼的復雜度
- if-else結構的復雜度取決于if的條件判斷復雜度和兩個分支部分的復雜度,總體復雜度取三者中最大的
三、應用實體
題目:給定N個整數的序列{A1,A2,…,AN},求函式f(i,j)=max{0,{Ai+A(i+1)+…+Aj}}的最大值,
演算法1:
int MaxSubseqSum1(int A[],int N)
{
int ThisSum, MaxSum = 0;
int i,j,k;
for(i=0;i<N;i++){ /*i是子列左端位置*/
for(j=i;j<N;j++){ /*j是子列右端位置*/
ThisSum=0; /*ThisSum是從A[i]到A[j]的子列和*/
for(k=i;k<=j;k++)
ThisSum+=A[k];
if(ThisSum>MaxSum) /*如果剛得到的這個子列和更大*/
MaxSum=ThisSum; /*則更新結果*/
}/*j回圈結束*/
}/*i回圈結束*/
return MaxSum;
}
T(N)=O(N**3)
演算法2:
int MaxSubseqSum2(int A[],int N)
{
int ThisSum, MaxSum = 0;
int i,j;
for(i=0;i<N;i++){ /*i是子列左端位置*/
ThisSum=0; /*ThisSum是從A[i]到A[j]的子列和*/
for(j=i;j<N;j++){ /*j是子列右端位置*/
ThisSum+=A[j]; /*對于相同的i,不同的j,只要在j-1次回圈的基礎上累加1項即可*/
if(ThisSum>MaxSum) /*如果剛得到的這個子列和更大*/
MaxSum=ThisSum; /*則更新結果*/
}/*j回圈結束*/
}/*i回圈結束*/
return MaxSum;
T(N)=O(N**2)
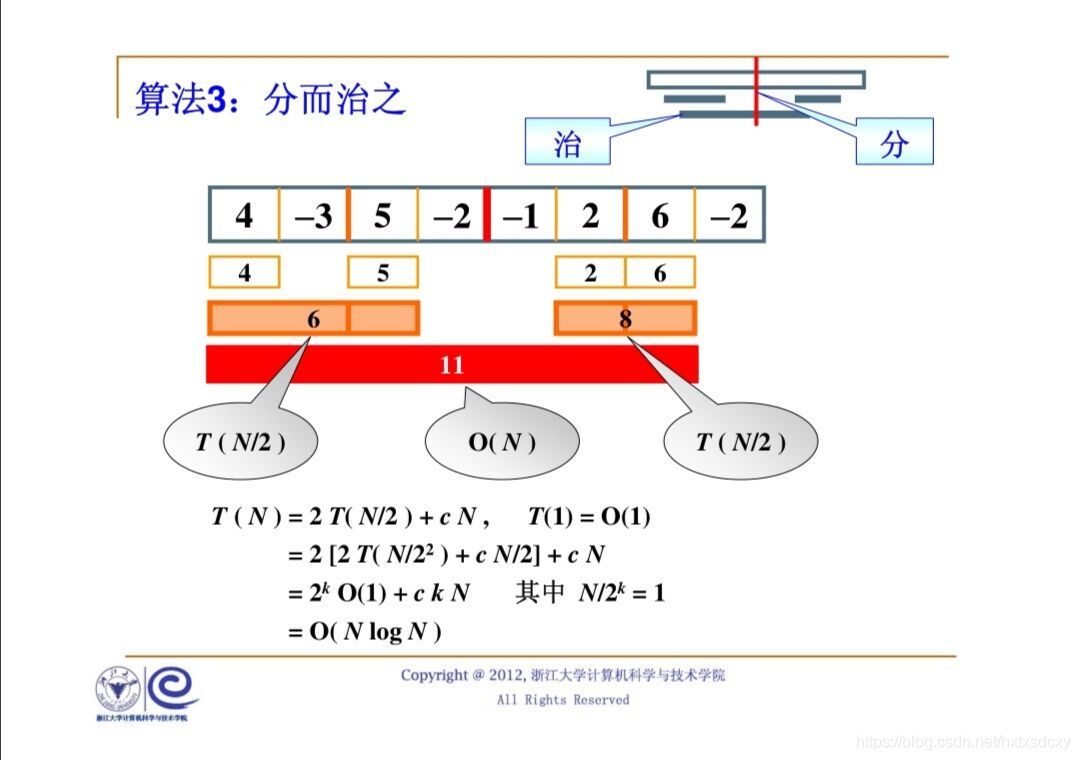
演算法3:分而治之
把一個比較大的復雜的問題切分成小的塊,然后分頭去解決它們,最后再把結果合并起來,這就是“分而治之”
對于此問題,假設該問題是放在一個陣列里面,首先第一步是”分“,也就是把這個陣列從中間一分為二,然后遞回地去解決左右兩邊的問題,遞回地去解決左邊的問題,我們會得到左邊的一個最大子列和;遞回地去解決右邊的問題,我們會得到右邊的一個最大子列和,還有一種情況時跨越邊界的最大子列和,把這三個結果合成起來就叫做“治”,
我們來用個圖舉個栗子以供理解:
演算法4:在線處理
int MaxSubseqSum4(int A[],int N)
{
int ThisSum, MaxSum;
int i;
for(i=0;i<N;i++){
ThisSum+=A[i]; /*向右累加*/
if(ThisSum>MaxSum)
MaxSum=ThisSum; /*發現更大和則更新當前結果*/
else if(ThisSum<0) /*如果當前子列和為負*/
ThisSum=0; /*則不可能使后面的部分和增大,拋棄之*/
}
return MaxSum;
}
T(N)=O(N)
"在線"的意思是指每輸入一個資料就進行即時處理,在任何一個地方中止輸入,演算法都能正確給出當前的解,
四種演算法運行時間相比較如下:
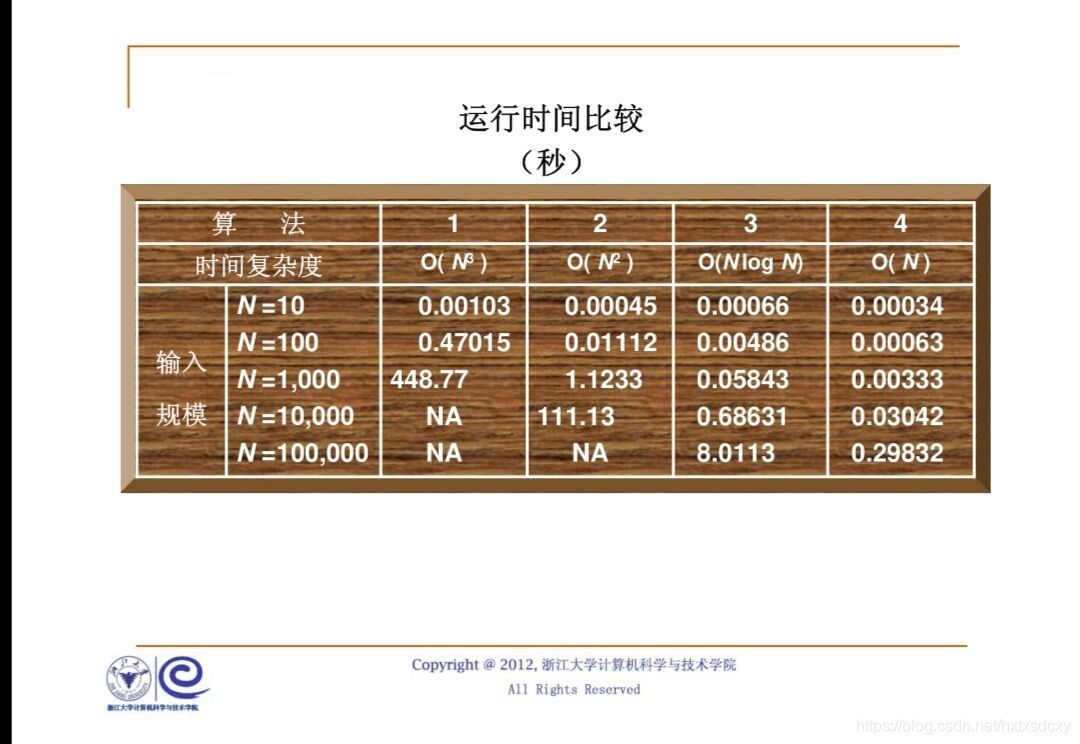
可知第四種演算法更為優解,
宣告:部分資料源自網路,如有侵權,請聯系我洗掉!
文中如存在謬誤、混淆等不足,歡迎批評指正!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/253095.html
標籤:其他
上一篇:資料結構——順序表(定義詳解及建立順序表與實作其操作)
下一篇:淺談時間復雜度和空間復雜度