在講解K近鄰分類器之前,我們先來看一下最近鄰分類器(Nearest Neighbor Classifier),它也是K = 1時的K近鄰分類器,
- 最近鄰分類器
- 定義
- 存在問題
- K近鄰分類器(KNN)
- 定義
- 距離測量
- 引數選擇
- 存在問題
- 源代碼
最近鄰分類器
定義
最近鄰分類器是在最小距離分類的基礎上進行擴展的,將訓練集中的每一個樣本作為判斷依據,尋找距離待分類樣本中最近的訓練集中的樣本,以此依據進行分類,
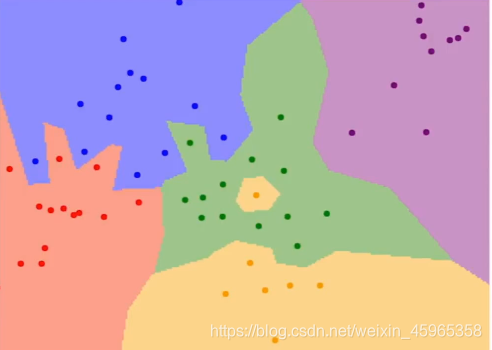
如上圖所示,我們的訓練集代表了二維平面上的點,而不同的顏色代表了不同的類別(標簽).
存在問題
噪聲(影像噪聲是指存在于影像資料中的不必要的或多余的干擾資訊,)我們從上面的圖中可以看出,綠色的區域內還有一個黃色區域,此時這個區域應該是綠色,因為黃色的點很有可能是噪聲,但我們使用最近鄰演算法就有可能出現上面的問題,
K近鄰分類器(KNN)
定義
與最近鄰分類器類不同的是,k近鄰分類器是幾個測驗的樣本共同抉擇屬于哪一個樣本,如下所示,當k = 1(也就是最近鄰分類器),3,5時的分類器抉擇結果,
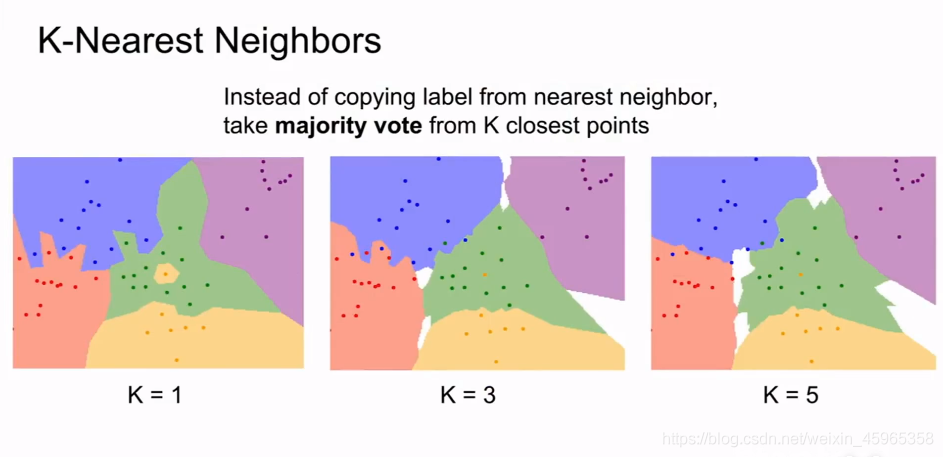
為了幫助大家更好地理解,我們引入下面一個示例:
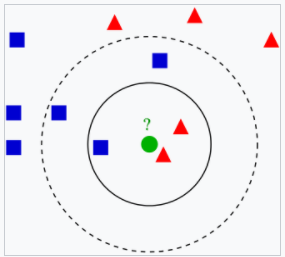
k近鄰演算法例子,測驗樣本(綠色圓形)應歸入要么是第一類的藍色方形或是第二類的紅色三角形,如果k=3(實線圓圈)它被分配給第二類,因為有2個三角形和只有1個正方形在內側圓圈之內,如果k=5(虛線圓圈)它被分配到第一類(3個正方形與2個三角形在外側圓圈之內),
距離測量
現在有一個問題,那就是我們如何比較相對近鄰距離值,下面給出兩種方法
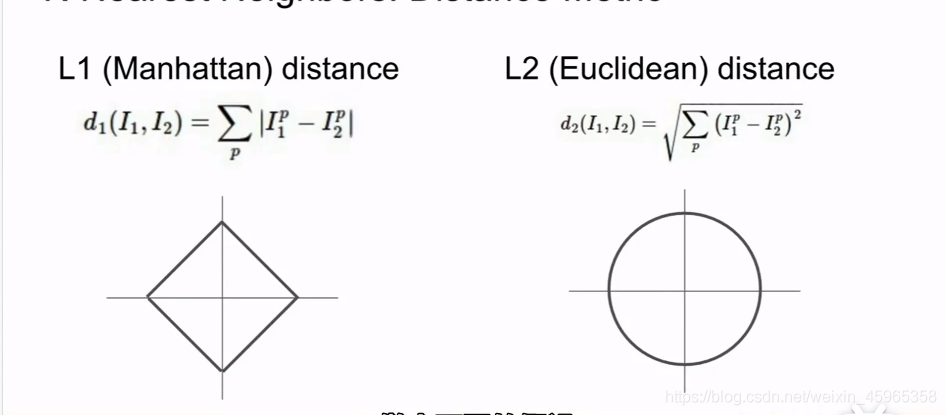
對于這兩種方法,大家可以參考下面的博文:歐氏距離,曼哈頓距離,余弦距離,漢明距離
L1距離:它上面的點的橫坐標的絕對值與縱坐標的絕對值之和總是相等,也就是到原點在坐標軸度量上是相等的,
L2距離:它上面的每一個點的坐標到原點的距離都相等,
大家有興趣的可以在斯坦福大學的實驗平臺上除錯資料進行試驗
附:cs231n-demo實驗
引數選擇
我們通過試驗,可以找出最優值k,當然,在CS231n當中,我們也看到了一種新的方法,在有限資料集的情況之下進行的實驗:K折交叉驗證
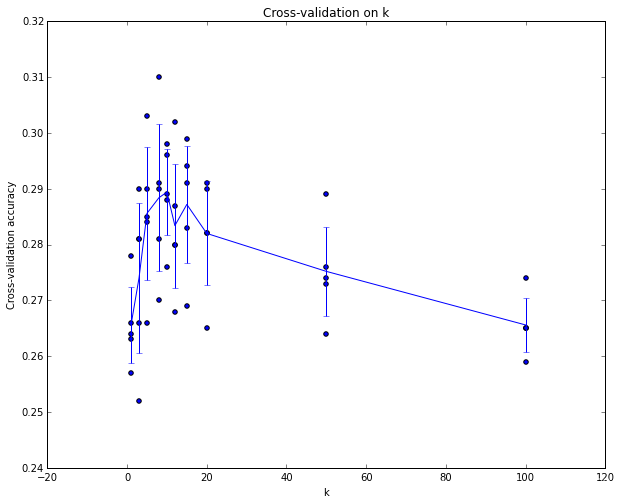
從實驗的結果,大約在k = 7時,我們能得到最優的解,
存在問題
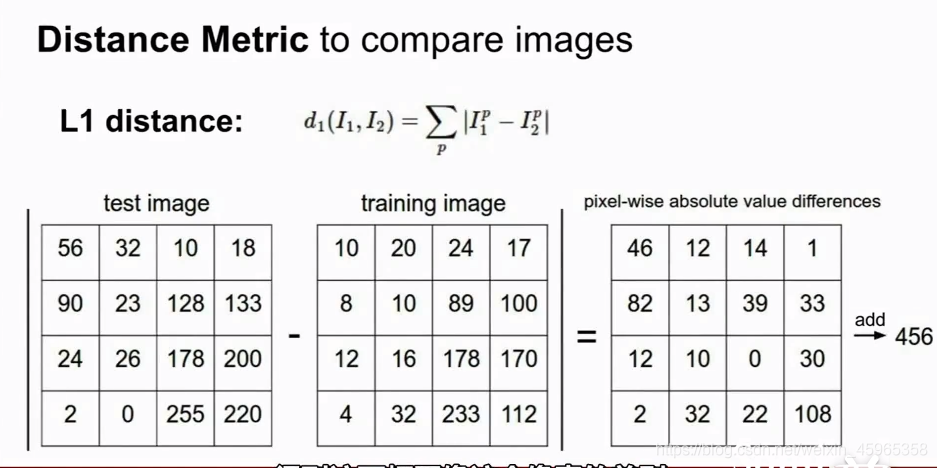
(1)Distance Matrix
我們假定使用L1距離,則計算程序如下:
但是計算標尺與鄰近特定距離標尺之間的關系并不會給我們帶來什么太有用的訊,如下,

Boxed,Shifted,Tinted與Original不同,但是 K-Nearest Neighbor 結果出來的確實一樣的,
(2)計算時間過長,
源代碼
import pickle
import os
import numpy as np
n = 2
def unpickle_as_array(filename):
with open(filename, 'rb') as f:
dic = pickle.load(f, encoding='latin1')
dic_data = https://www.cnblogs.com/2021WGF/p/dic['data']
dic_labels = dic['labels']
dic_data = https://www.cnblogs.com/2021WGF/p/np.array(dic_data).astype('int')
dic_labels = np.array(dic_labels).astype('int')
return dic_data, dic_labels
def load_batches(root, n):
train_data = https://www.cnblogs.com/2021WGF/p/[]
train_labels = []
for i in range(1, n + 1, 1):
f = os.path.join(root,'data_batch_%d' % i)
data, labels = unpickle_as_array(f)
train_data.append(data)
train_labels.append(labels)
train_data_r = np.concatenate(train_data)
train_labels_r = np.concatenate(train_labels)
del train_data, train_labels
test_data, test_labels = unpickle_as_array(os.path.join(root, 'test_batch'))
return train_data_r, train_labels_r, test_data, test_labels
def knn_classification(train_d, test_d, train_l, k):
count = 0
result = np.zeros(10000)
for i in range(10000):
d_value = https://www.cnblogs.com/2021WGF/p/test_d[i] - train_d
distance = np.sum(np.abs(d_value), axis=1)
dis_sort = np.argsort(distance)
vote_label = np.zeros(10)
for j in range(k):
vote_label[train_l[dis_sort[j]]] += 1
result[i] = np.argmax(vote_label)
print('the %dth image\'s label: %d' % (count, result[i]))
count = count + 1
return result
train_data, train_labels, test_data, test_labels = load_batches('D:/data/cifar-10-python/cifar-10-batches-py', n)
result = knn_classification(train_data, test_data, train_labels, 3)
print('the algorithm\'s accuracy: %f' % (np.mean(result == test_labels)))
CIFAR的下載:https://www.cs.toronto.edu/~kriz/cifar.html
大家進入官網后,可以選擇CIFAR-10 python進行下載,然后修改
train_data, train_labels, test_data, test_labels = load_batches('D:/data/cifar-10-python/cifar-10-batches-py', n)
中的路徑,
大家也可以參考我的GitHub:-cifar-10-KNN
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/253432.html
標籤:其他
上一篇:計算虛擬化