文章目錄
- 題目分析
- 題目分析三步驟
- 題目翻譯
- 解讀
- 題干
- 問題
- 第1部分
- 第2部分
- 第3部分
- 第4部分
- 題目切入點及模型選擇
- 針對第一問
- 資料清洗
- 可能出現的位置
- 文章撰寫
題目分析
題目分析三步驟
- 這是個什么樣的題
- 需要我們干什么
- 我們需要做什么
美賽的問題可能說的很模糊,很籠統,這就要我們自己去消化理解,
題目翻譯


資料附件可在這里下載:2019美賽C題資料+O獎論文
解讀
題干
他就是說在美國有個毒品叫阿片,然后給了我們兩種資料,
一種資料是聯邦、州和地方法醫實驗室分析的毒品案件的毒品鑒定結果和相關資訊,就是給了五個州,然后這五個州下面有很多個縣,每個縣出現了毒品問題會有法醫進行鑒定,然后將結果進行統計,比如有海洛因、大麻啥的,每出現一次就多一次計數,
第二種是7個zip檔案為2010-2016年間每年人口普查時為這五個州的縣收集的一些社會因素,包含了幾百個因素指標,
問題
第1部分
讓我們根據阿片這個毒品在美國五個州之間傳播的特點,建立一個模型進而確定每個州開始使用特定阿片的任何可能位置,
如果阿片會按我們模型發展,這時美國政府應該特別關注哪些具體問題?在什么藥物識別的閾值水平會發生這些問題?根據我們模型預測他將在何時何地發生?
第2部分
阿片的泛濫是什么導致的?為什么人們明明知道阿片有毒會上癮,但仍然堅持使用?阿片的使用是否與人口普查中某些社會經濟資料有關?如果是,請修改你的模型,以包含人口普查資料集中的任何重要因素,
第3部分
結合1、2部分的結果,找出對應阿片藥物危機的可能策略,使用你的模型測驗此策略的有效性,
第4部分
除了主報告外,還需要想組委會提交一份1-2頁的備注,以總結你在DEA\NFLIS資料庫總結發現的任何重要見解或結果,
題目切入點及模型選擇
針對第一問

資料清洗
首先對己知資料進行篩選,觀察附件中資料,對Drug Reports列進行主成分分析,不妨設小于等于5的事件為小概率事件,運用Exdal操作除去小概率事件,重新生成新的可靠資料,然后對合成阿片類藥物x和事件總數的影響度y進行相關性分析,分別求出各種合成阿片類藥物和y之間的線性關系,
根據熵權法在MATLAB環境下確定綜合權系數 y = w 1 x 1 + w 2 x 2 + w 3 x 3 + w 4 x 4 + w 5 x 5 y=w1x1+w2 x2+w3 x3+w4 x4+w5 x5 y=w1x1+w2x2+w3x3+w4x4+w5x5,然后利用藥物傳播預測模型求解確定性微分方程,之后建立藥物傳播預測模型,從而建立確定性微分方程,
最后利用元胞自動機進行仿真處理,建立基于元胞自動機的藥物傳播預測模型,得出仿真曲線,從而求出合成阿片類藥物和海洛因事件在給定五個州及其縣之間的傳播和特點,特定阿片類藥物在給定五個州中任何可能開始使用的位置,以及按上述模型確定的特點和模式條件下未來可能出現的問題和藥物鑒定閾值水平,最后利用上述模型預測它們發生的時間地點,
利用提供的美國人口普查社會經濟資料,解決以下問題:
阿片類藥物的使用如何達到目前的水平,誰在使用/濫用阿片類藥物,是什么導致阿片類藥物使用和成癮的增長,以及為什么人們知道使用阿片類藥物的危險,但仍然持續使用,人們提出了大量相互矛盾的假說來解釋這些問題,該藥物的使用或使用趨勢是否與提供的某些美國人口普查的社會經濟資料有關?如果是這樣,請修改第1部分的模型以包含此資料集中的任何重要因素,
針對問題二,對附件中資料進行分析,通過觀察每一- 年的人口普查資料,得到與題目相關的有效資料,將資料分類,再根據附件7個壓縮包中所給的資料篩出規則,將相似型別的大類進行篩選合并,最終得到與社會經濟相關的資料,對分析得到的資料和合成阿片類藥物和海洛因事件進行相關性分析,分析后再利用熵權法以及負反饋的原理在MATLAB環境下對所有相關因素和海洛因事件的影響度y進行綜合熵權,對問題二的結果進行仿真同時與問題一的仿真結果進行對比,觀察改行程度,
可能出現的位置
根據NFLIS資料中阿片類毒品在美國五個州之間傳播的特點,建立一個模型進而確定每個州開始使用特定阿片的任何可能位置,
- step1
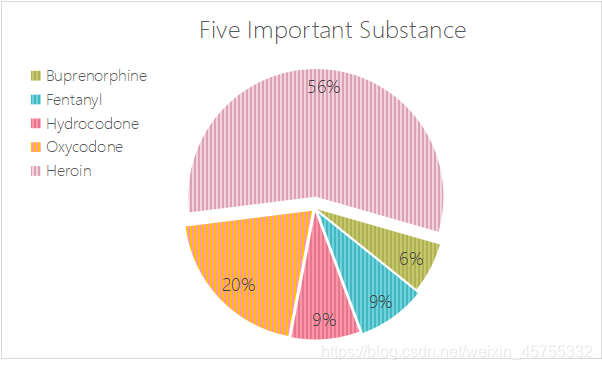
首先對已知資料進行篩選,觀察附件中的資料,對Grug Reports這一列進行主成分分析,不妨設小于等于5的事件危機小概率事件,重新生成新的可靠資料,確定影響比較顯著的五種阿片,分別為:Buprenorphine、Fentanyl、Hydrocodone、Oxycodone、Heroin
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = pd.read_excel('MCM_NFLIS_Data.xlsx',sheet_name='Data')
data
name = set(data['SubstanceName'])
name = list(name)
# 創建一個字典保存SubstanceName的DrugReports所有值,
DrugReports_dick = { }
for i in name:
DrugReports_dick[i] = sum(data[data['SubstanceName'] == i]['DrugReports'])
# print(DrugReports_dick)
# 然后進行排序提取前五個的值
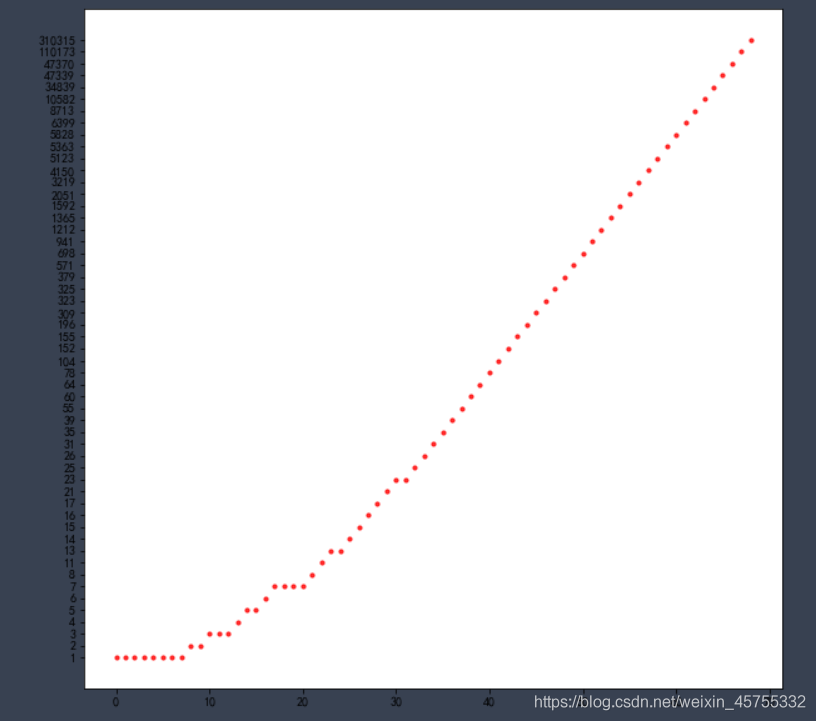
DrugReports_dick = sorted(DrugReports_dick.items(), key=lambda item:item[1])
# 畫一下所有資料
plt.figure(figsize=(10,10))
plt.scatter(np.arange(len(DrugReports_dick)),np.array(DrugReports_dick)[:,1],s=10,c="r",alpha=0.8)
DrugReports_five = np.array(DrugReports_dick)[-5:]
plt.figure(figsize=(10,10))
plt.pie(DrugReports_five[:,1],
autopct='%1.1f%%',
shadow=False,
startangle=150)
plt.title("Substance")
plt.savefig("Substance.png")
plt.legend(labels=DrugReports_five[:,0])
plt.show()
plt.savefig('five_pie.jpg')
2. Step2:
然后對合成阿片類藥物和海洛因x和事件總數的影響度y進行相關性分析,分別求出各種合成阿片類藥物和y之間的線性關系,根據 熵權法 在MATLAB環境下確定綜合權系數
y
=
w
1
x
1
+
w
2
x
2
+
w
3
x
3
+
w
4
x
4
+
w
5
x
5
y=w1x1+w2x2+w3x3+w4x4+w5x5
y=w1x1+w2x2+w3x3+w4x4+w5x5
得出綜合權系數
y
=
0.78
x
1
?
1.41
x
2
+
0.58
x
3
+
0.49
x
4
+
0.56
x
5
y=0.78x_1-1.41x_2+0.58x_3+0.49x_4+0.56x_5
y=0.78x1??1.41x2?+0.58x3?+0.49x4?+0.56x5?;發現合成阿片類藥物和海洛因事件的影響度y與x2呈負相關,且.x2相對 于其他四種因素對y影響程度大,
但我算的并沒有-值,而且五個的權重幾乎相同,
# 提取5個特征的 DrugReports所有值
five = []
for i in range(len(DrugReports_five)):
five.append(np.array(data[data['SubstanceName'] == DrugReports_five[:,0][i]]['DrugReports']))
p_ij = []
for i in five:
a = [x/sum(i) for x in i ]
print(a)
p_ij.append(a)
e_j = [- sum(i*np.log(i)) for i in p_ij]
w_j = [i/sum(e_j) for i in e_j]
[0.21362155593657947,
0.1580864454826483,
0.2208284846678793,
0.21451323648805518,
0.19295027742483767]
將人群分為五種,
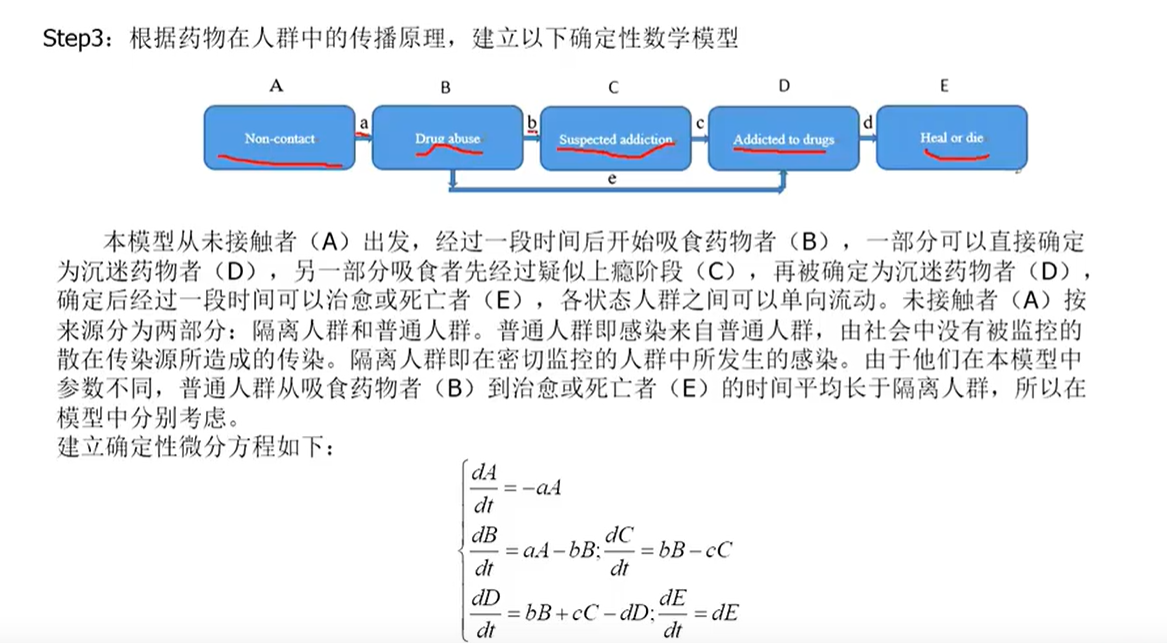
a是單位時間的感染率

元胞自動機傳染病模型
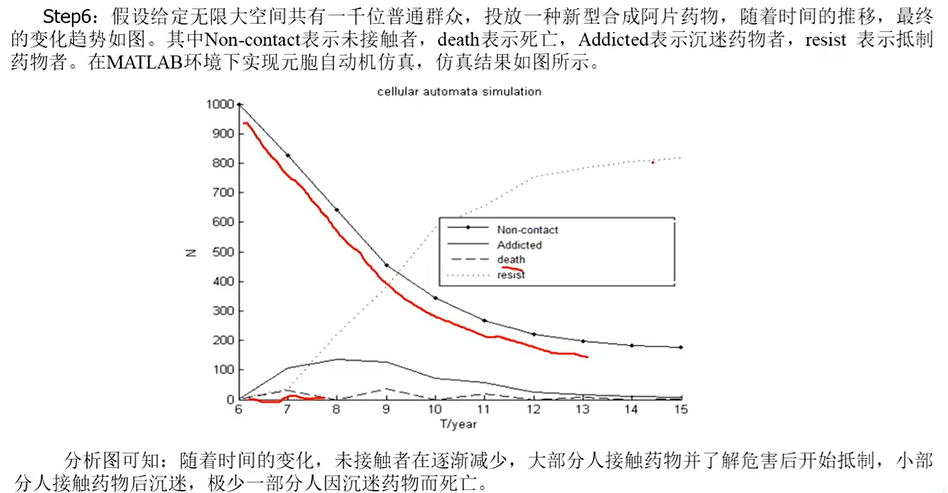
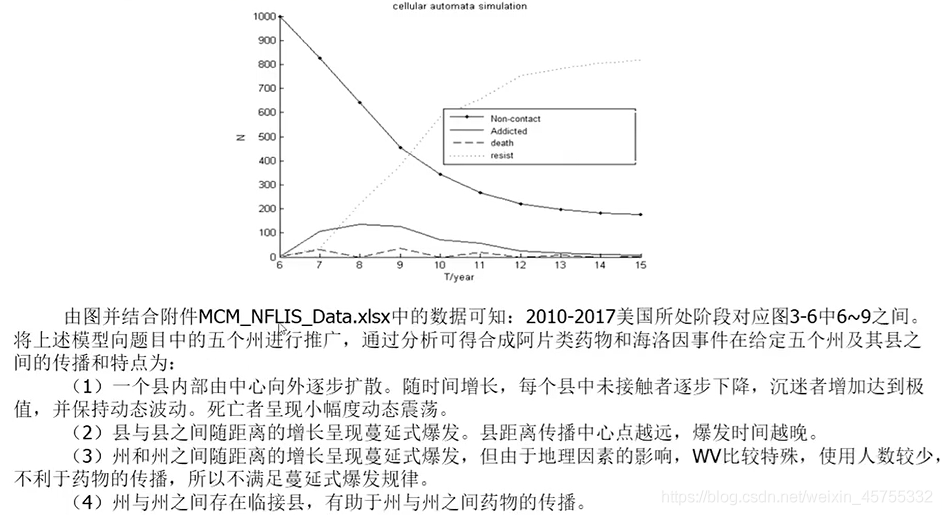
用較大的權重確定影響度Y的位置
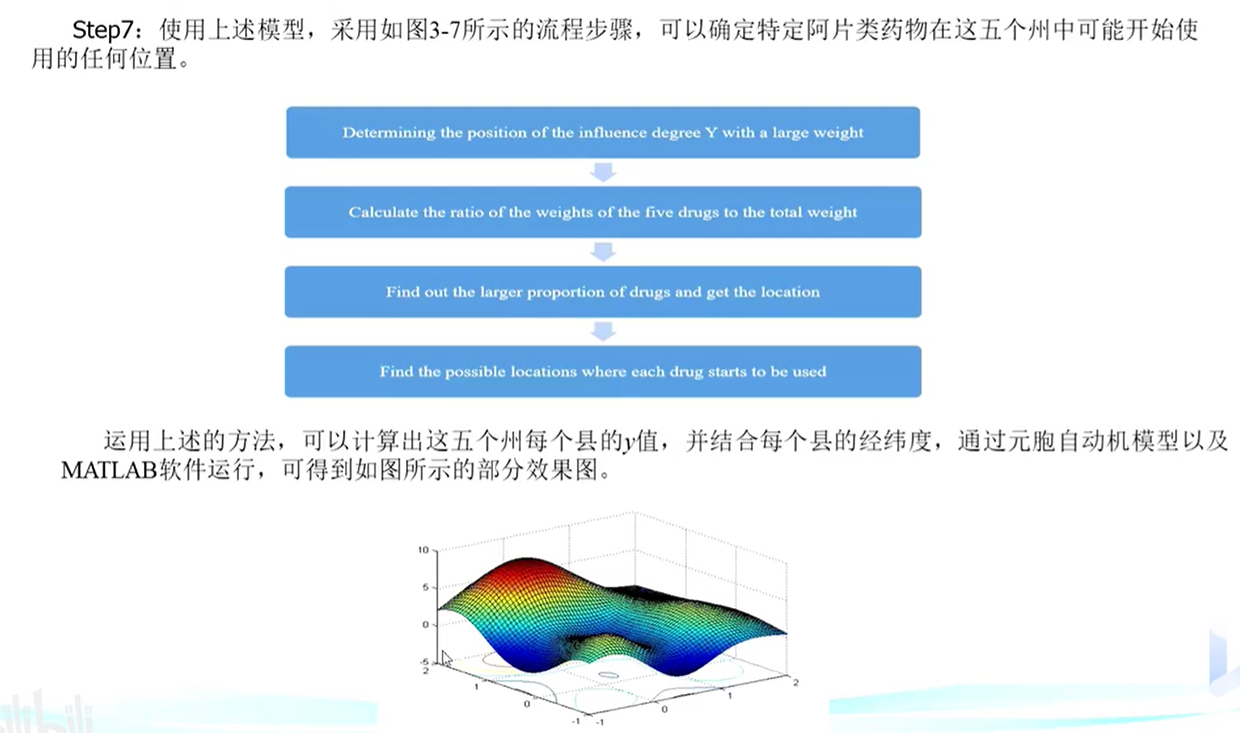
計算五種藥物的權重與總權重的比率
找出更大比例的毒品,找出位置
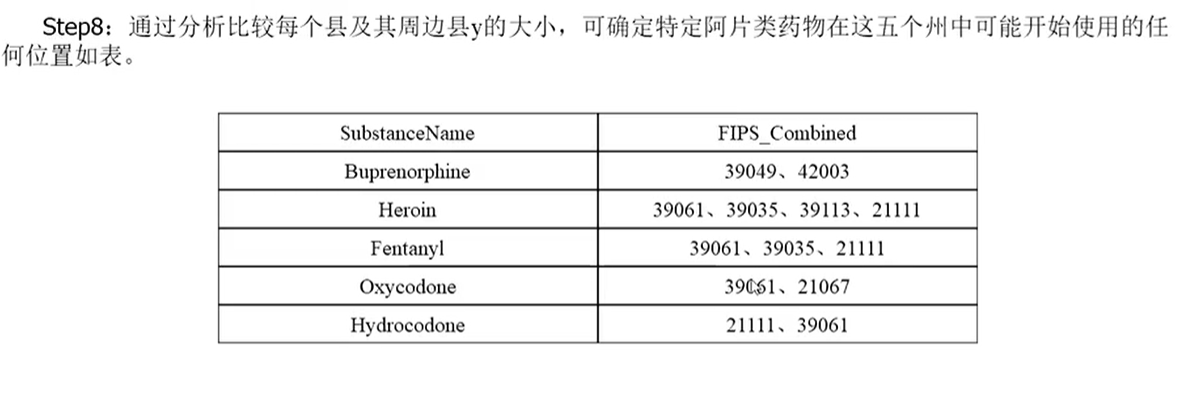
找出每種藥物可能開始使用的位置

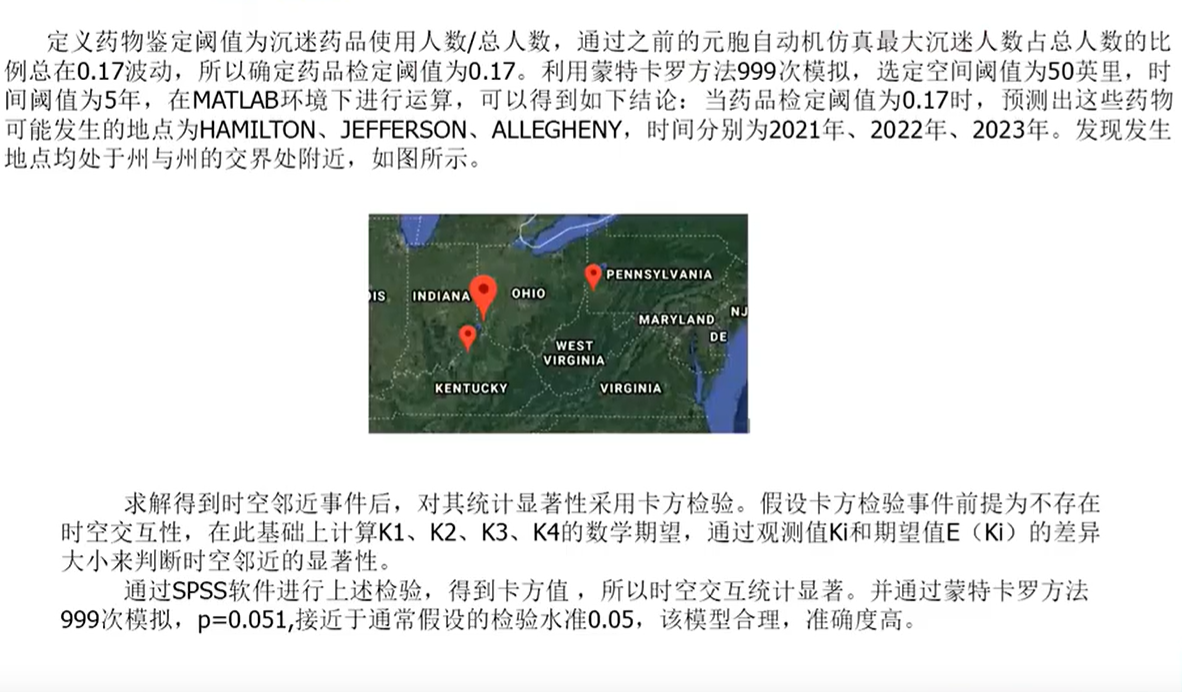

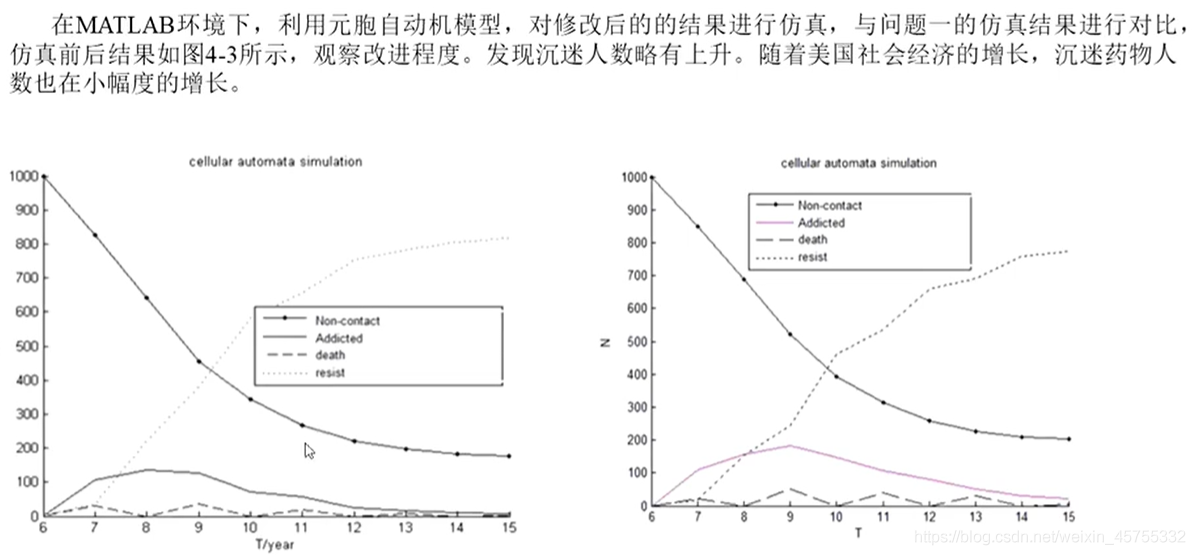

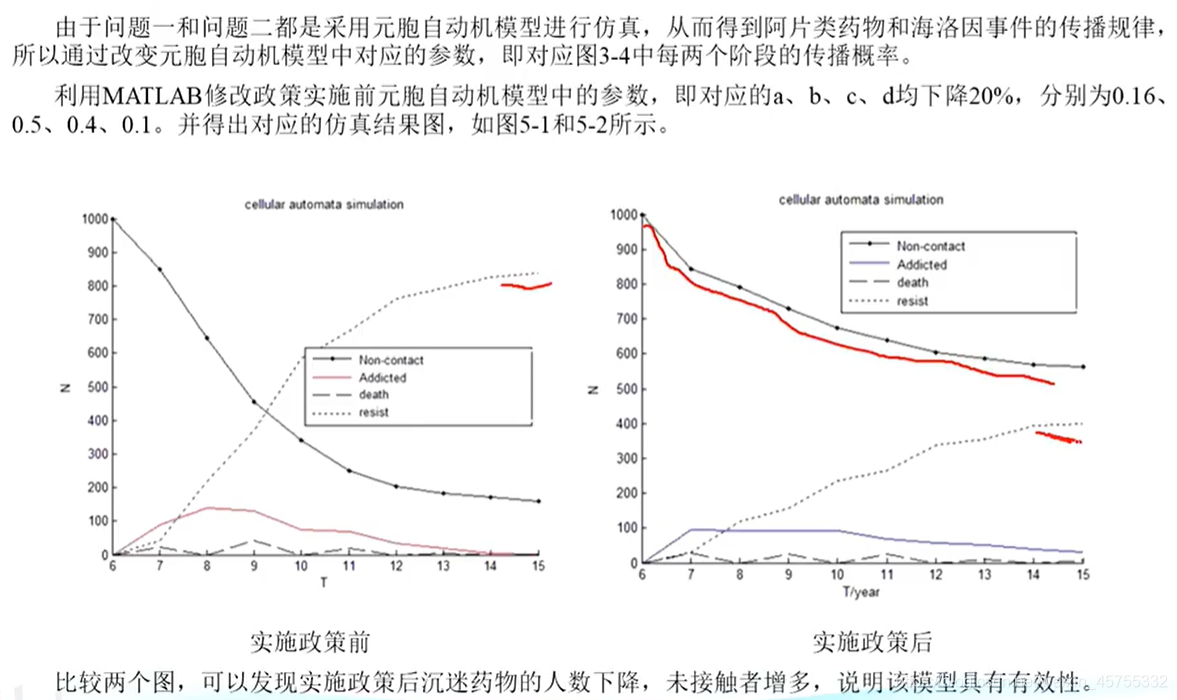

文章撰寫


轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/253590.html
標籤:其他