??CS231n是非常經典的計算機視覺課程,為了方便新手學習,尤其是英文不好的同學,特意將該課程親自翻譯成中文,希望能對大家學習CV有一定的幫助,
??CS231n每一年都有課程,最早的是2015年(http://cs231n.stanford.edu/2015),其中包括視頻的分別為2016年(http://cs231n.stanford.edu/2016)和2017年(http://cs231n.stanford.edu/2017),教學大綱為子域名syllabus,如http://cs231n.stanford.edu/2016/syllabus,兩者最大的變化是,使用的深度學習框架是不同的,前者使用的是Tensorflow,而后者使用的是Pytorch,另外一個變化是,2016年的授課老師包括Andrej Karpathy(特斯拉AI高級總監,具體資訊可參考https://cs.stanford.edu/people/karpathy/),所以綜上所述,最終選擇了2016年版本的CS231n,

??本門課主要的學習內容是神經網路,尤其是CNN(卷積神經網路),
1. 計算機視覺的簡要歷史

??2016年,思科統計得出,在網路空間中超過85%的資料均是多媒體資料(圖片、視頻等),這是由于作為資料載體的互聯網和資料采集器的爆炸式增長,具體的資料采集器(手機、攝像頭等)如上圖所示,
??隨著CV資料量的急劇增加,對應的資料處理能力也是不可或缺的,以Youtube為例,每一分鐘所有的視頻創作者就會上傳總時長為150小時的視頻,如此大的資料量,完全通過人工標注是不現實的,
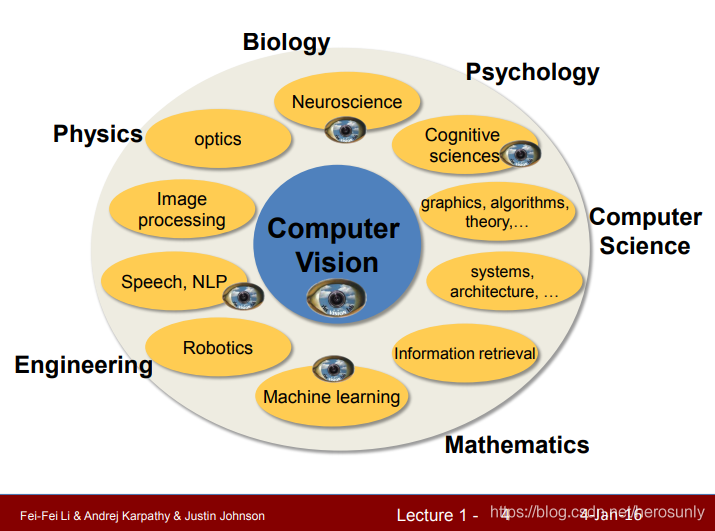
??CV是一門交叉學科,我們可以利用CV的方法,去解決各行各業的問題,而我們從事于認知科學、神經科學之間以及NLP和語音之間的交集,

??基礎較差的同學可以先學習CS131,學習地址為(http://vision.stanford.edu/teaching/cs131_fall2021/syllabus.html 和 https://github.com/StanfordVL/cs131_release),
??CS231a vs CS231n,CS231a中學習的工具和話題的覆寫面更廣(如3D機器人的視覺識別),所以它是一門更通用的課程,而CS231n更專注于神經網路和視覺識別,
??CS331和CS431是更深入的CV課程,

??之所以介紹計算機視覺的簡要歷史,是因為如果沒有對問題域是深入理解的話,就很難創造出解決問題的新模型,也就是說問題域和模型域并不是相互獨立的,而是相互依托、相互推動的,例如,CNN的網路架構來自于解決視覺問題的實際需求,而視覺的實際問題幫助深度學習演算法進化更新,


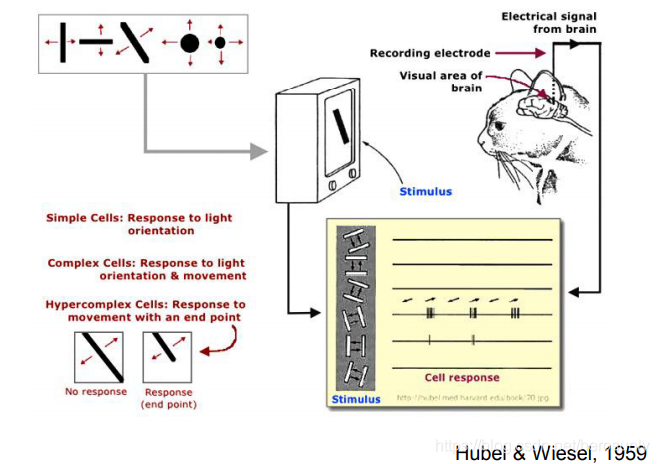
??生物大腦如何處理視覺呢?哈佛博士后通過生物實驗來進行探索,他對一只意識清晰、但被麻醉的貓進行實驗,把一根針插入它腦部的基礎視覺皮層,給貓播放各種圖片(老鼠、魚、花等),但是神經元都沒有產生激活,但是在切換圖片的時候,貓的神經元產生了激活,說明切換幻燈片的動作刺激了貓的神經元,實驗證明,不管圖片是正方形還是矩形的,移動的邊緣都驅動了神經元的激活,基礎視覺區的神經元是按一列一列的組織起來,每一列神經元只“喜歡”某一種特定簡單的形狀,例如條紋,邊界,最終說明視覺的最初處理物件,不是整個形狀,而是定向的邊緣,該發現對神經生理學和神經科學都有非常深遠的影響,
??之后,對人腦的神經網路進行可視化,會發現出現了簡單的邊緣狀結構,即使發現是在50年代后期和60年代初,這項作業贏得了1981年的諾貝爾醫學獎,
??有趣的是視覺皮層和眼睛之間的距離是比較遠的,另外視覺涉及到大腦中大約50%的區域,所以視覺是大腦中最復雜的感知系統(耗費了很長的時間去演變進化),

??1963年Larry Roberts發表的 Block world是最早的計算機視覺的博士論文之一,他的觀點是說,如上圖所示兩個相同的blocks,即使方向和光照發生了變化,人們也會認為是相同的blocks,而他的假設是說,結構是由邊緣定義的,只要它們不被改變,則人們就會認為是不變的,

??在1966年,MIT開啟了一個著名的暑期專案即The Summer Vision Project,該專案企圖用一個夏天的時間來解決大部分視覺系統的問題,該目標的確是野心勃勃,如今50多年已經過去了,計算機視覺領域也從一個單調的暑期專案發展成了在全世界擁有數以千記研究者的領域,雖然我們目前為止,還是沒有徹底解決,但是計算機視覺仍是人工智能中最重要發展最快的領域之一(CV頂會包括CVPR、ICCV、ECCV等),

??David Marr也是MIT的視覺科學家,他曾經寫了一本很有影響力的書叫做《VISION》,之前Hubel和Wiesel的研究表明,視覺系統初始對簡單結構進行處理,而David Marr更進一步,提出了如何認識一個三維物體,上述的兩個研究成果促使了視覺深度學習的開始,
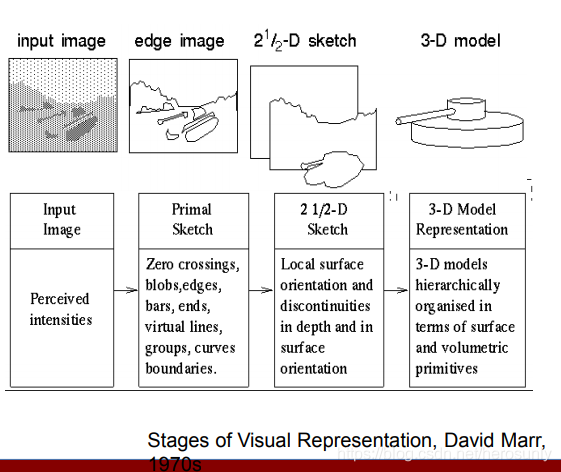
??認識三維物體的程序如下所示:
- 基元圖:由于影像的密度變化可能與物體邊界這類具體的物理性質相對應,因此它主要描述影像的密度變化及其區域幾何關系,(Zero crossings, blobs, edges, bars, ends, virtual lines, groups, curves, boundaries)
- 2.5維圖:以觀察者為中心,描述可見表面的方位、輪廓、深度及其他性質,(Local surface orientation and dis continuities in depth and in suface orientation)
- 3-D模型表示:以物體為中心,是用來處理和識別物體的三維形狀表象,(3-D models hierarchically organized in terms of surface and volumetric primitives)
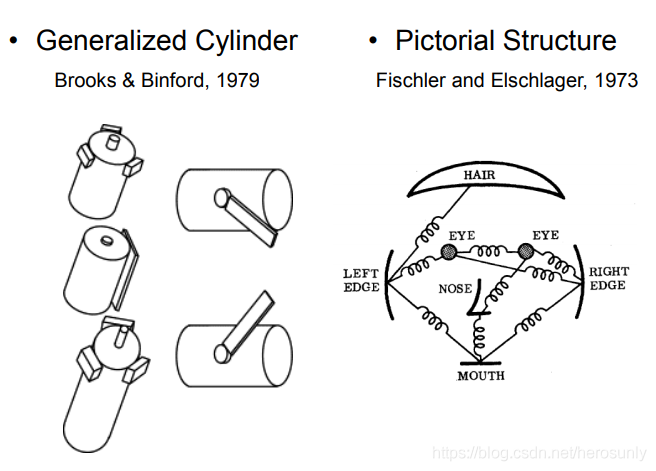
??Rodney Brooks提出了第一個所謂的廣義圓柱模型,他的觀點是說,世界是由簡單的形狀(如圓柱)構成的,任何現實的物體都是由不同角度下簡單形狀的組合,
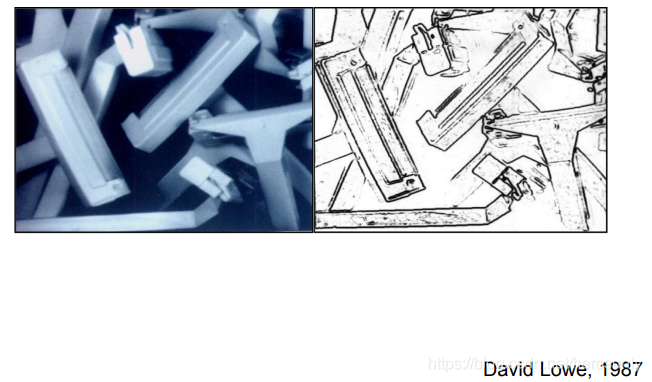
??20世紀80年代,David Lowe使用邊緣和簡單形狀的組合來識別物體(如剃須刀),

??感知分組(perceptual group是視覺中最重要的問題之一,
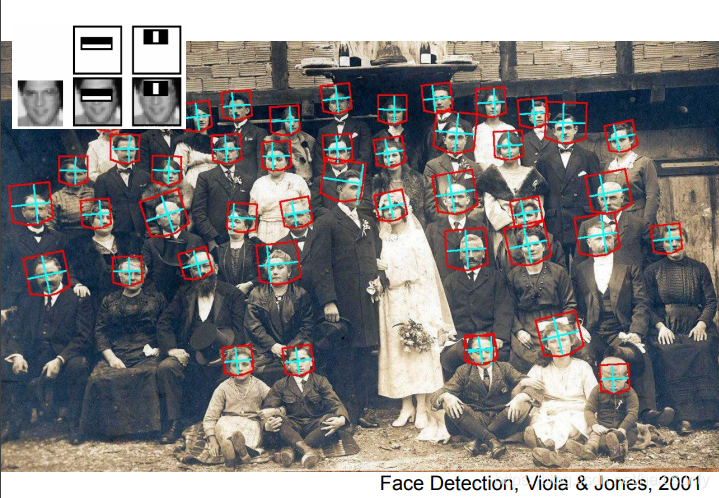
??人臉識別技術在2006年被使用在富士相機上,人臉識別演算法是比較早成功應用于產品中的演算法,
??隨著時間的推移,計算機視覺從構建3D形狀的物體到物體識別,
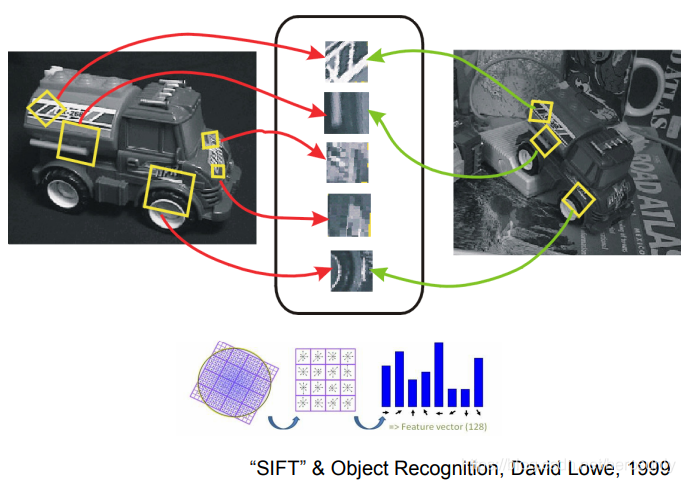
??人們逐漸發現通過描述整個物體來進行識別是非常困難的,而通過重要的特征進行識別是可行的,David Lowe提出了基于:SIFT算子特征的影像識別演算法,在2000~2010年的時間里,CV領域聚焦于提取特征對物體進行識別,
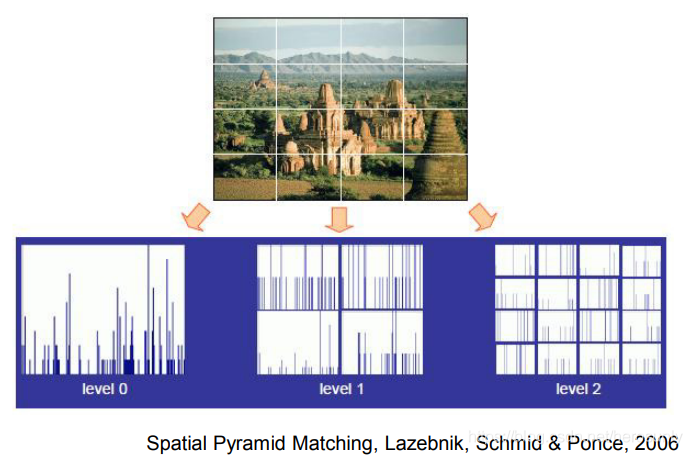
??空間金字塔匹配也是通過提取特征+SVM分類的方法進行場景識別,
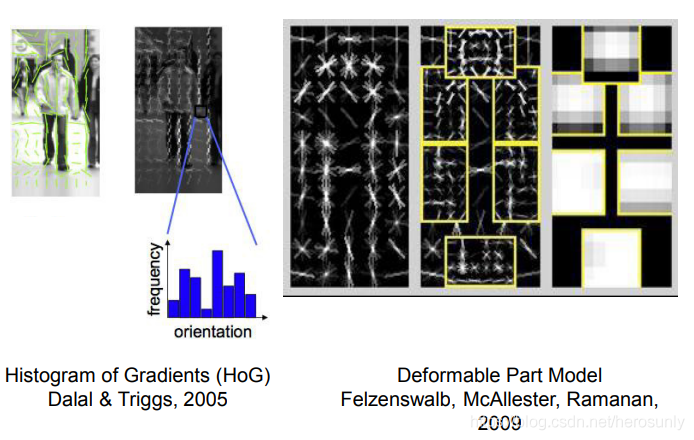
?&esmp;在深度學習之前的最后一個模型是deformable part model(是一種基于組件的檢測演算法),該演算法借鑒使用了之前的HOG演算法,
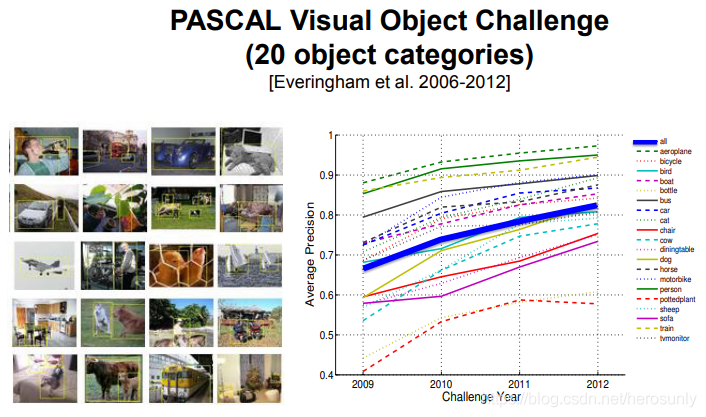
??PASCAL Visual Object Challenge,該資料集包括總共10000張圖片,圖片分為20個類別:火車、飛機、人等等

??由于現實生活遠不止20個類別,所以李飛飛開創了ImageNet專案,該專案專注于構建影像分類的資料集,ImageNet 不僅是計算機視覺發展的重要推動者,也是這一波深度學習熱潮的關鍵驅動力之一,
??ImageNet包括了1500 萬由人工標注的圖片,該圖片庫包括了超過 2.2 萬個類別,其中,至少有 100 萬張里面提供了邊框(bounding box),

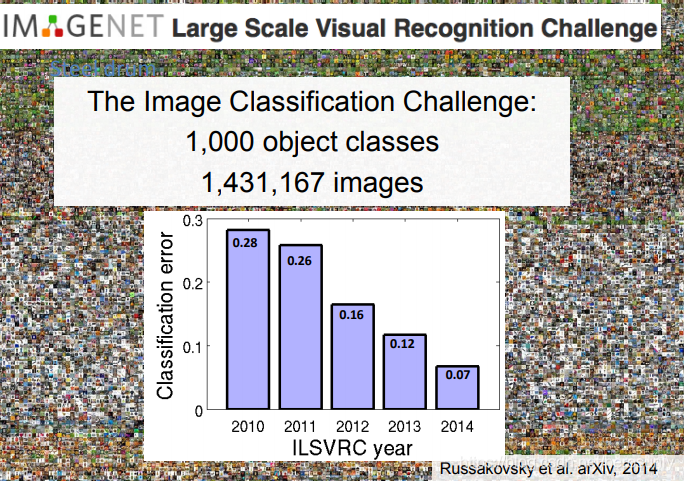
??需要注意的是,y軸表示的是錯誤率,20120年的冠軍使用了CNN網路,所以錯誤率急劇下降,最初的CNN網路是深度學習的開始,
2. 課程概述
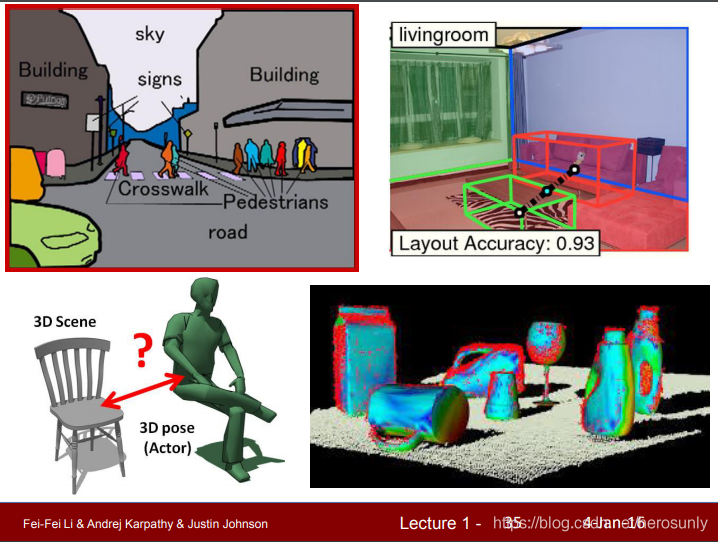
??CS231n聚焦于影像識別中最重要的問題之一:影像分類,影像識別包括了很多子領域,例如影像分類、3D建模、感知分組、影像分割,

??影像分類的應用場景非常廣泛,
??以下是影像分類以外的其他視覺任務:

??CNN成為了目標識別的重要工具,
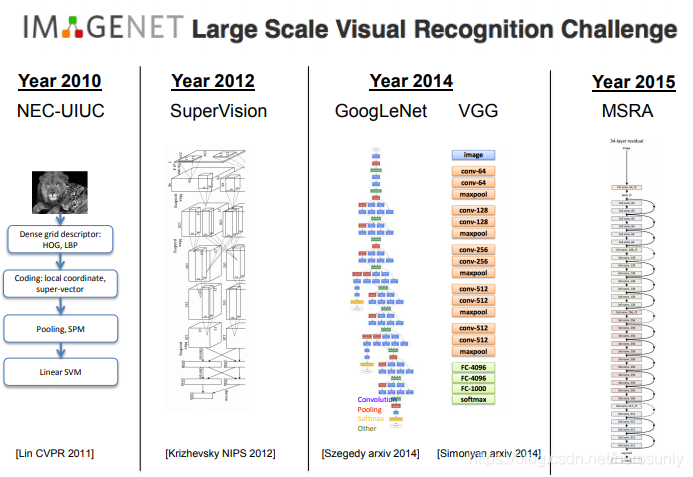
??在各種影像識別的方法中,卷積神經網路(CNN)是目前最為成功的一類方法,自從2012年Alex krizhevsky和其導師Geoff Hinton提出的7層卷積神經網路獲得Imagenet冠軍之后,每屆的冠軍都是CNN網路架構,如2014年的GoogleNet和VGG,2015年的Resnet(該網路結構具有152層),

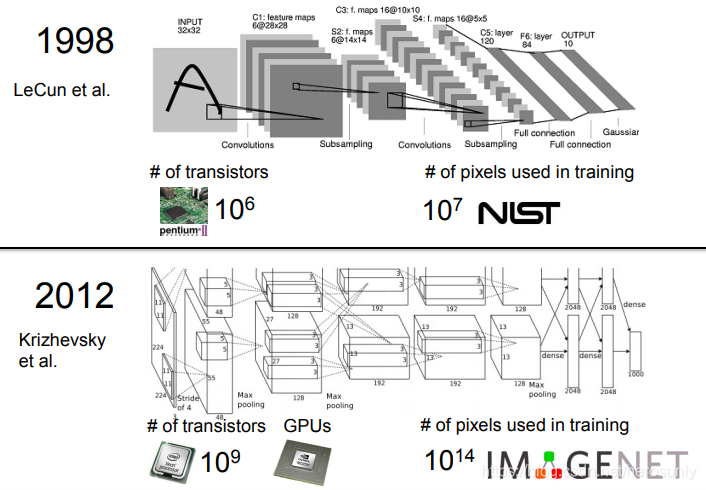
??卷積神經網路并不是在一夜之間發明的,它是在研究神經網路程序中,多人智慧結晶的一個成果,其中最早作出貢獻的是日本學者Kunihiko Fukushima,他建立了一個其稱為Neocognitron的模型結構,Yann LeCun在90年代發表的用于手寫數字識別的神經網路,其實與2012年Alex提出的模型是十分相似的,由于算力的大幅度增長,模型結構也變得越來越復雜,與此同時,模型的識別能力也逐漸增加,
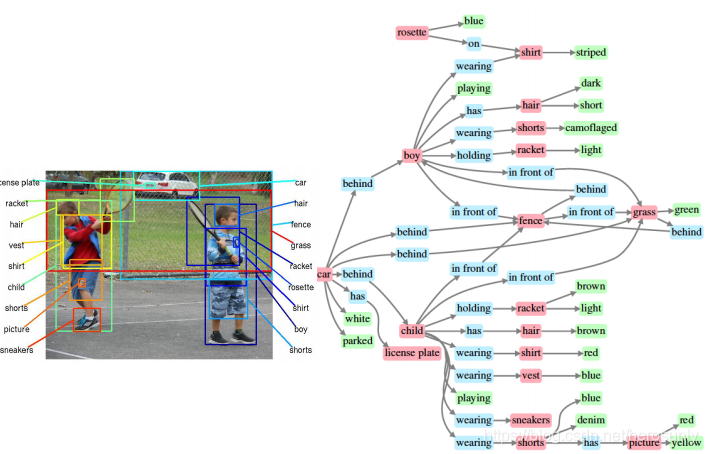
??圖片的語意理解也是重要的研究方向,例如上圖所示,理解圖中的人物之間的關系,他們在做什么,

??人們觀察圖片500ms就可以寫出一篇短文用來描述其中的物體和發生的事件,所以我們也希望機器學習也能達到同樣的效果,


 CSDN認證博客專家
演算法研究員
天池冠軍
CSDN簽約作者
CSDN認證博客專家
演算法研究員
天池冠軍
CSDN簽約作者
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/254024.html
標籤:AI