1.哈希表
2.ConcurrentHashMap與HashMap、HashTable的區別
3.ConcurrentHashMap在JDK1.7和JDK1.8版本的區別
一:哈希表
1.介紹
哈希表就是一種以 鍵-值(key-indexed) 存盤資料的結構,我們只要輸入待查找的鍵即key,即可查找到其對應的值,
哈希的思路很簡單,如果所有的鍵都是整數,那么就可以使用一個簡單的無序陣列來實作:將鍵作為索引,值即為其對應的值,這樣就可以快速訪問任意鍵的值,這是對于簡單的鍵的情況,我們將其擴展到可以處理更加復雜的型別的鍵的情況,
2.鏈式哈希表
鏈式哈希表從根本上說是由一組鏈表構成,每個鏈表都可以看做是一個“桶”,我們將所有的元素通過散列的方式放到具體的不同的桶中,插入元素時,首先將其鍵傳入一個哈希函式(該程序稱為哈希鍵),函式通過散列的方式告知元素屬于哪個“桶”,然后在相應的鏈表尾部插入元素,查找或洗掉元素時,用同樣的方式先找到元素的“桶”,然后遍歷相應的鏈表,直到發現我們想要的元素,因為每個“桶”都是一個鏈表,所以鏈式哈希表并不限制包含元素的個數,然而,如果表變得太大,它的性能將會降低,
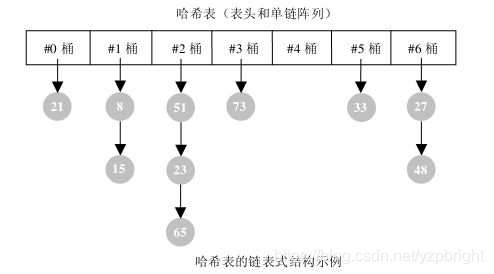
3.應用場景
我們熟知的快取技術(比如redis、memcached)的核心其實就是在記憶體中維護一張巨大的哈希表,還有大家熟知的HashMap、CurrentHashMap等的應用,
二:ConcurrentHashMap與HashMap等的區別
1.HashMap
我們知道HashMap是執行緒不安全的,在多執行緒環境下,使用Hashmap進行put操作會引起死回圈,導致CPU利用率接近100%,所以在并發情況下不能使用HashMap,
2.HashTable
HashTable和HashMap的實作原理幾乎一樣,差別無非是:
- HashTable不允許key和value為null
- HashTable是執行緒安全的
但是HashTable執行緒安全的策略實作代價卻太大了,簡單粗暴,get/put所有相關操作都是synchronized的,這相當于給整個哈希表加了一把大鎖,如下圖所示:
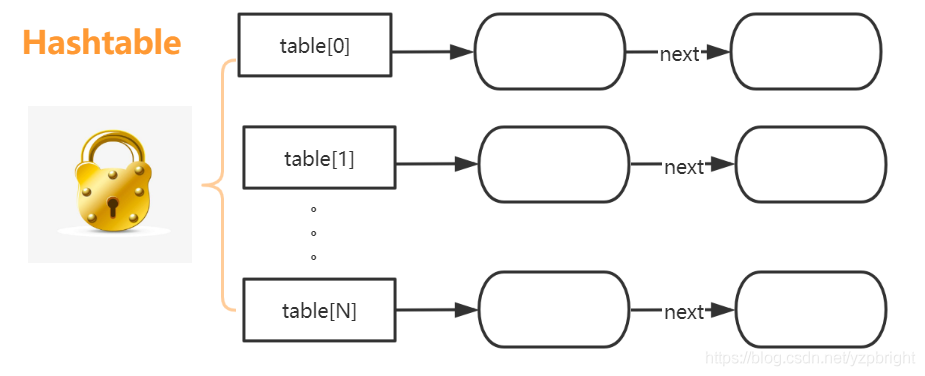
多執行緒訪問時候,只要有一個執行緒訪問或操作該物件,那其他執行緒只能阻塞,相當于將所有的操作串行化,在競爭激烈的并發場景中性能就會非常差,
3.ConcurrentHashMap
主要就是為了應對HashMap在并發環境下不安全而誕生的,ConcurrentHashMap的設計與實作非常精巧,大量的利用了volatile,final,CAS等lock-free技術來減少鎖競爭對于性能的影響,
我們都知道Map一般都是陣列+鏈表結構(JDK1.8該為陣列+紅黑樹),
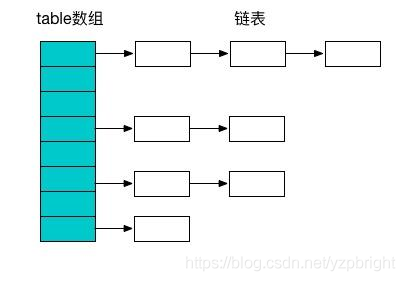
ConcurrentHashMap避免了對全域加鎖改成了區域加鎖操作,這樣就極大地提高了并發環境下的操作速度,由于ConcurrentHashMap在JDK1.7和1.8中的實作非常不同,接下來我們談談JDK在1.7和1.8中的區別,
三:JDK1.7版本的ConcurrentHashMap的實作原理
在JDK1.7中ConcurrentHashMap采用了陣列+Segment+分段鎖的方式實作,
1.Segment(分段鎖)
ConcurrentHashMap中的分段鎖稱為Segment,它即類似于HashMap的結構,即內部擁有一個Entry陣列,陣列中的每個元素又是一個鏈表,同時又是一個ReentrantLock(Segment繼承了ReentrantLock),
2.內部結構
ConcurrentHashMap使用分段鎖技術,將資料分成一段一段的存盤,然后給每一段資料配一把鎖,當一個執行緒占用鎖訪問其中一個段資料的時候,其他段的資料也能被其他執行緒訪問,能夠實作真正的并發訪問,如下圖是ConcurrentHashMap的內部結構圖:
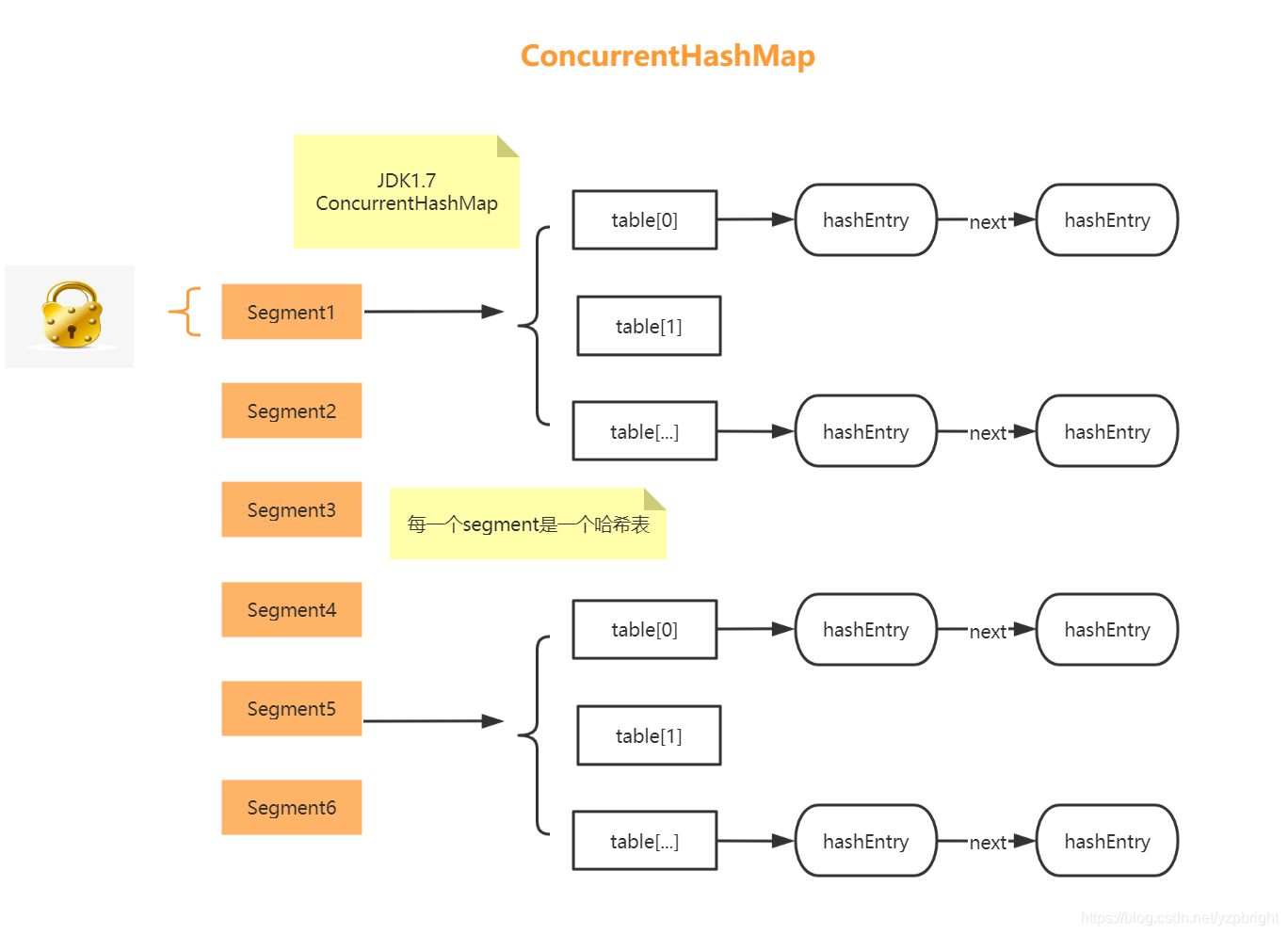
上面的結構我們可以了解到,ConcurrentHashMap定位一個元素的程序需要進行兩次Hash操作,
第一次Hash定位到Segment,第二次Hash定位到元素所在的鏈表的頭部,
3.該結構的優劣勢
壞處
這一種結構的帶來的副作用是Hash的程序要比普通的HashMap要長
好處
寫操作的時候可以只對元素所在的Segment進行加鎖即可,不會影響到其他的Segment,這樣,在最理想的情況下,ConcurrentHashMap可以最高同時支持Segment數量大小的寫操作(剛好這些寫操作都非常平均地分布在所有的Segment上),
所以,通過這一種結構,ConcurrentHashMap的并發能力可以大大的提高,
四:JDK1.8版本的ConcurrentHashMap的實作原理
JDK8中ConcurrentHashMap參考了JDK8 HashMap的實作,采用了陣列+鏈表+紅黑樹的實作方式來設計,如下圖所示:
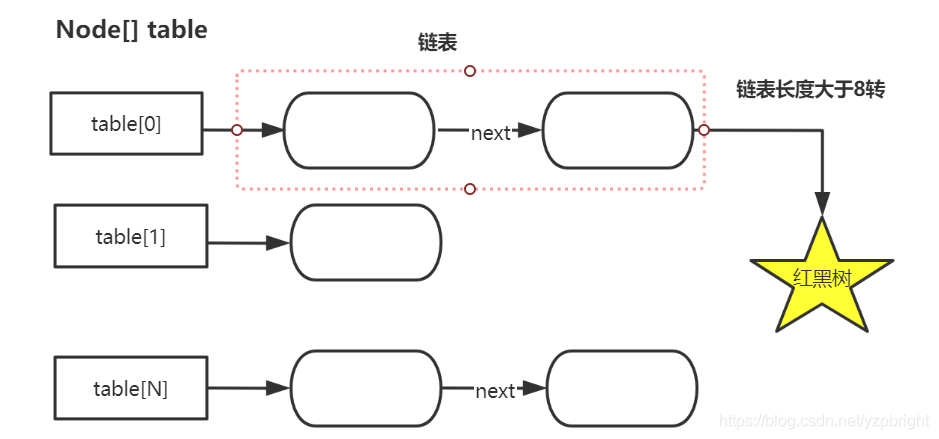
內部大量采用CAS操作,這里我簡要介紹下CAS,
CAS是compare and swap的縮寫,即我們所說的比較交換,cas是一種基于鎖的操作,而且是樂觀鎖,在java中鎖分為樂觀鎖和悲觀鎖,悲觀鎖是將資源鎖住,等一個之前獲得鎖的執行緒釋放鎖之后,下一個執行緒才可以訪問,而樂觀鎖采取了一種寬泛的態度,通過某種方式不加鎖來處理資源,比如通過給記錄加version來獲取資料,性能較悲觀鎖有很大的提高,
CAS 操作包含三個運算元 —— 記憶體位置(V)、預期原值(A)和新值(B),如果記憶體地址里面的值和A的值是一樣的,那么就將記憶體里面的值更新成B,CAS是通過無限回圈來獲取資料的,如果在第一輪回圈中,a執行緒獲取地址里面的值被b執行緒修改了,那么a執行緒需要自旋,到下次回圈才有可能機會執行,
JDK8中徹底放棄了Segment轉而采用的是Node,其設計思想也不再是JDK1.7中的分段鎖思想,
Node:保存key,value及key的hash值的資料結構,其中value和next都用volatile修飾,保證并發的可見性,
class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
//... 省略部分代碼
}
Java8 ConcurrentHashMap結構基本上和Java8的HashMap一樣,不過保證執行緒安全性,
在JDK8中ConcurrentHashMap的結構,由于引入了紅黑樹,使得ConcurrentHashMap的實作非常復雜,我們都知道,紅黑樹是一種性能非常好的二叉查找樹,其查找性能為O(logN),但是其實作程序也非常復雜,而且可讀性也非常差,Doug Lea的思維能力確實不是一般人能比的,早期完全采用鏈表結構時Map的查找時間復雜度為O(N),JDK8中ConcurrentHashMap在鏈表的長度大于某個閾值的時候會將鏈表轉換成紅黑樹進一步提高其查找性能,
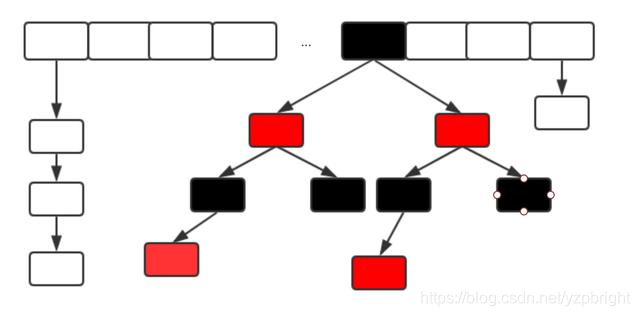
五:ConcurrentHashMap總結
其實可以看出JDK1.8版本的ConcurrentHashMap的資料結構已經接近HashMap,相對而言,ConcurrentHashMap只是增加了同步的操作來控制并發,從JDK1.7版本的ReentrantLock+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+紅黑樹,
1.資料結構:取消了Segment分段鎖的資料結構,取而代之的是陣列+鏈表+紅黑樹的結構,
2.保證執行緒安全機制:JDK1.7采用segment的分段鎖機制實作執行緒安全,其中segment繼承自ReentrantLock,JDK1.8采用CAS+Synchronized保證執行緒安全,
3.鎖的粒度:原來是對需要進行資料操作的Segment加鎖,現調整為對每個陣列元素加鎖(Node),
4.鏈表轉化為紅黑樹:定位結點的hash演算法簡化會帶來弊端,Hash沖突加劇,因此在鏈表節點數量大于8時,會將鏈表轉化為紅黑樹進行存盤,
5.查詢時間復雜度:從原來的遍歷鏈表O(n),變成遍歷紅黑樹O(logN),
參考:
CurrentHashMap的實作原理
徹底搞清楚ConcurrentHashMap的實作原理(含JDK1.7和JDK1.8的區別)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/254032.html
標籤:其他
上一篇:資訊安全實驗——點擊劫持技術