部署條件準備
需要3臺虛擬機master(192.138.137.161),slaver01(192.138.137.162),slaver02(192.138.137.163)
系統centos8,配置1核CPU,2G記憶體,20G硬碟
軟體包:hadoop-3.2.2.tar.gz,jdk-8u191-linux-x64.tar.gz
安裝虛擬機和設定靜態ip聯網可以參考如下:
安裝虛擬機Centos8:https://blog.csdn.net/dp340823/article/details/112056146
宿主機連接wifi,centos8靜態IP聯網:https://blog.csdn.net/dp340823/article/details/112056911
一、安裝jdk和hadoop
這些操作是在master(192.138.137.161)進行的,
后續將檔案scp到slaver01(192.138.137.162)和slaver02(192.138.137.163)即可
1.上傳軟體包到指定目錄下

2.將jdk解壓到指定目錄/opt下
tar zxvf jdk-8u191-linux-x64.tar.gz -C /opt
3.將hadoop解壓到指定目錄/opt下
tar zxvf hadoop-3.2.1.tar.gz -C /opt
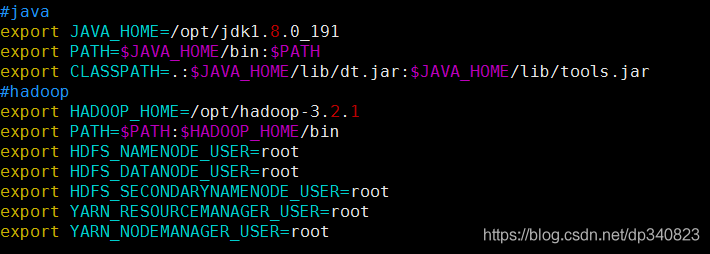
4.修改環境變數并使之生效
vim /etc/profile
#java
export JAVA_HOME=/opt/jdk1.8.0_191
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#hadoop
export HADOOP_HOME=/opt/hadoop-3.2.1
export PATH=$PATH:$HADOOP_HOME/bin
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
source /etc/profile
5.驗證jdk和hadoop安裝是否正確
java -version
hadoop version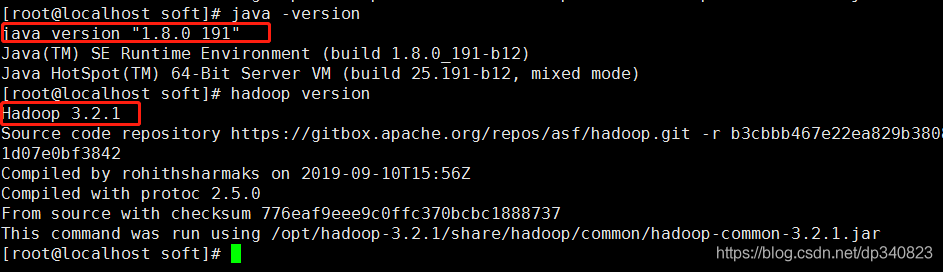
二、設定ssh免密登錄
3臺虛擬機都要做
1.關閉防火墻
systemctl stop firewalld
firewall-cmd --state
2.修改 hosts
vim /etc/hosts
192.168.137.161 master
192.168.137.162 slaver01
192.168.137.163 slaver02

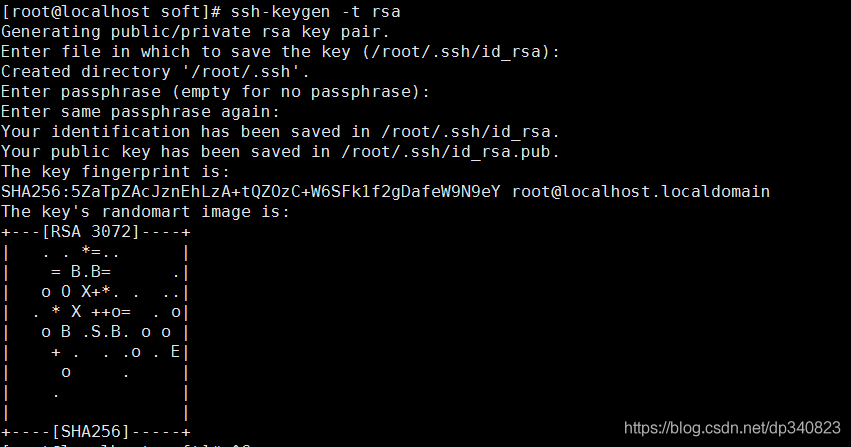
3.生成公鑰
ssh-keygen -t rsa一直回車即可
4.公鑰復制到其他機器上
ssh-copy-id master
ssh-copy-id slaver01
ssh-copy-id slaver02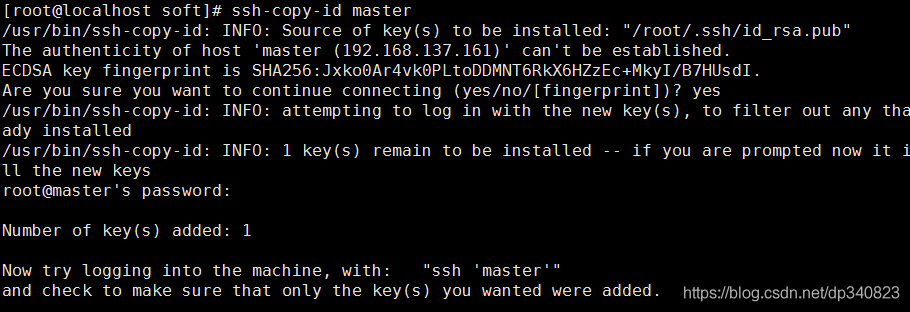
5.驗證登錄
ssh master
三、修改hadoop組態檔
組態檔都在/opt/hadoop-3.2.1/etc/hadoop/目錄下
1.修改組態檔hadoop-env.sh(在末尾添加已下內容)
vim /opt/hadoop-3.2.1/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/jdk1.8.0_191
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root

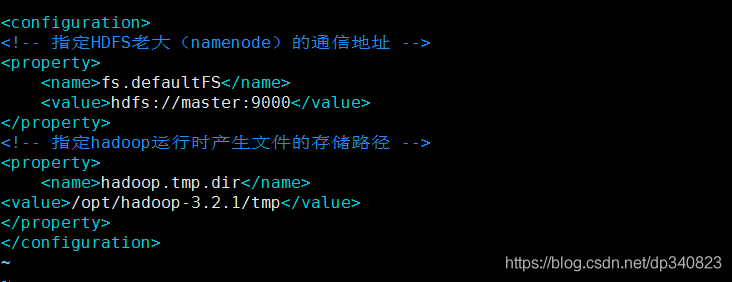
2.修改組態檔core-site.xml
vim /opt/hadoop-3.2.1/etc/hadoop/core-site.xml
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定hadoop運行時產生檔案的存盤路徑 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-3.2.1/tmp</value>
</property>
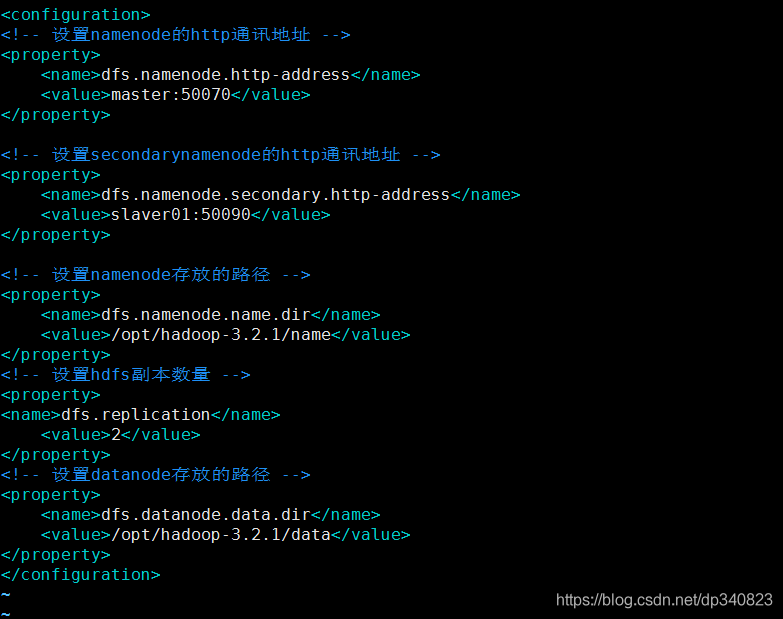
3.修改組態檔hdfs-site.xml
vim /opt/hadoop-3.2.1/etc/hadoop/hdfs-site.xml
<!-- 設定namenode的http通訊地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<!-- 設定secondarynamenode的http通訊地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slaver01:50090</value>
</property>
<!-- 設定namenode存放的路徑 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop-3.2.1/name</value>
</property>
<!-- 設定hdfs副本數量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 設定datanode存放的路徑 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop-3.2.1/data</value>
</property>
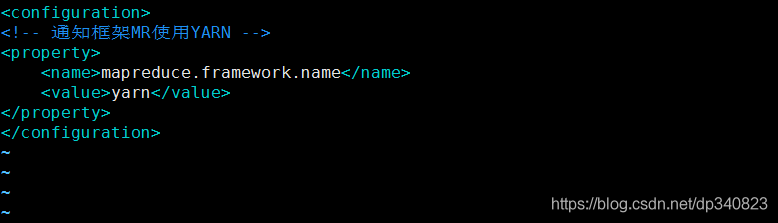
4.修改組態檔mapred-site.xml
vim /opt/hadoop-3.2.1/etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
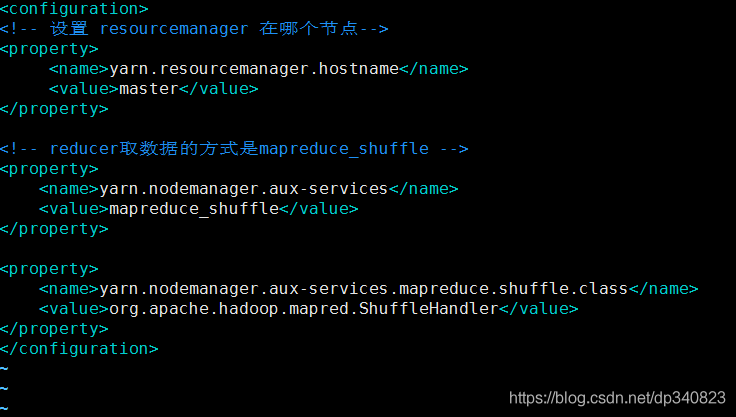
5.修改組態檔yarn-site.xml
vim /opt/hadoop-3.2.1/etc/hadoop/yarn-site.xml
<!-- 設定 resourcemanager 在哪個節點-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- reducer取資料的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
6.新建masters檔案(/opt/hadoop-3.2.1/etc/hadoop/目錄下)
vim masters

7.新建workers檔案(/opt/hadoop-3.2.1/etc/hadoop/目錄下)
vim workers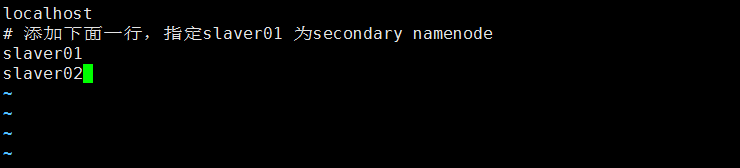
8.新建tmp、name、data檔案夾(/opt/hadoop-3.2.1目錄下)
mkdir tmp name data
9.將master機上的復制檔案到slaver01、slaver02
scp /etc/profile slaver01:/etc/
scp /etc/profile slaver02:/etc/
scp -r /opt slaver01:/
scp -r /opt slaver02:/需要在slaver01、slaver02執行source /etc/profile 使用組態檔生效
java -version和hadoop version驗證slaver01和slaver02 上的jdk和hadoop是否安裝成功
四、啟動hadoop
3臺虛擬機都要做
1.第一次啟動需要格式化namenode(/opt/hadoop-3.2.1)
./bin/hdfs namenode -format
2.啟動dfs
./sbin/start-dfs.sh
3.啟動yarn
./sbin/start-yarn.sh 
4.用jps驗證
master

slaver01

slaver02

五、訪問應用
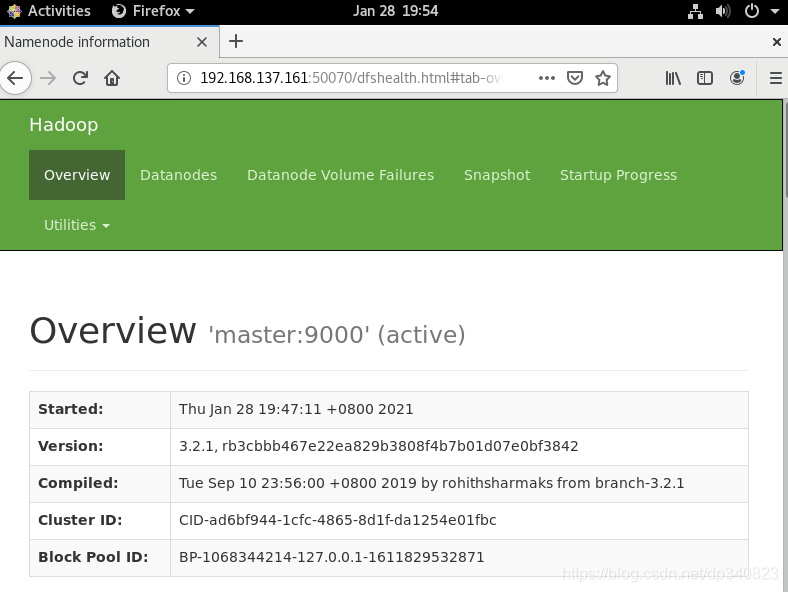
1.瀏覽器輸入192.168.137.161:50070
2.瀏覽器輸入192.168.137.161:8088
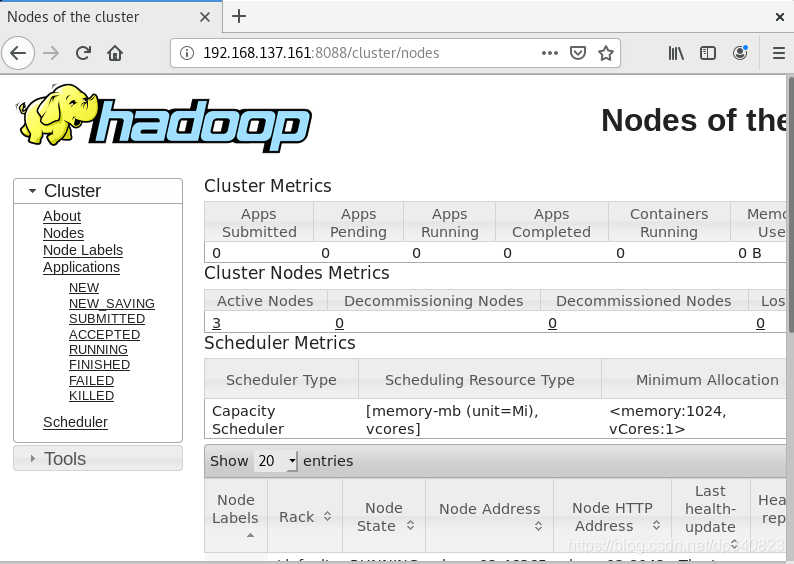
點擊nodes查看
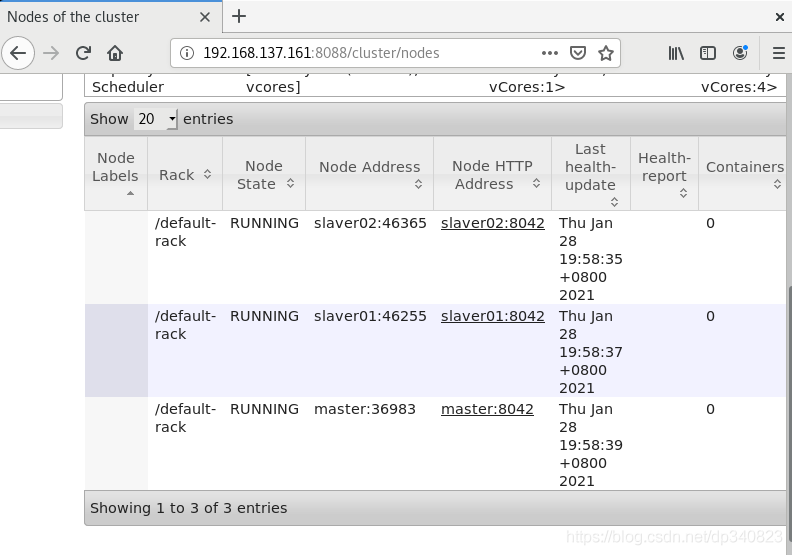
完成!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/254044.html
標籤:其他
上一篇:OpenStack 是什么?