微積分
- 導數:當函式y=f(x)的自變數x在一點x0上產生一個增量Δx時,函式輸出值的增量Δy與自變數增量Δx的比值在Δx趨于0時的極限a如果存在,a即為在x0處的導數,記作f'(x0)或df(x0)/dx,其影像表示為如下:
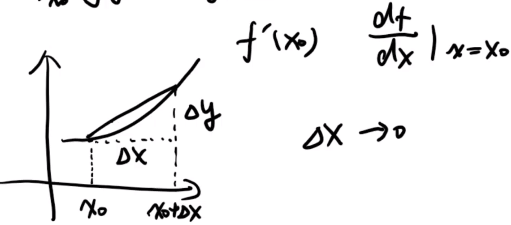
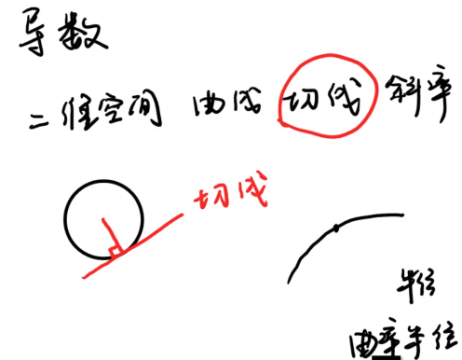
類似的概念還有:二維空間中的“切線”,
- 偏導數:當需要讓其他變數不變,只有某一個變數發生變化,這種情況下的求導,其實際上表示的是函式在不同方向(坐標軸)上的變化率,
- 梯度:函式的所有偏導數構成的向量,梯度是一個向量,其向量的方向即為函式值增長最快的方向,
資訊論
- 熵:也稱資訊熵,熵越大,不確定性越大,更多關于熵的解釋請參看另一篇博客《機器學習 - 相關概念與實作流程》
- KL 散度:也稱為相對熵,它衡量了兩個分布之間的差異,若結合如下事實:
-
真實事件的資訊熵就是 p(xi) log p(xi);
-
理論擬合的事件的資訊量就是 log q(xi);
-
真實事件的概率就是 p(xi),
-
在模型優化、資料分析和統計等場合,就可以使用 KL 散度衡量選擇的近似分布與資料原分布有多大差異 -- 當擬合事件和真實事件一致的時候 KL 散度就成了 0,不一樣的時候就大于 0,
- 交叉熵:它也衡量了兩個分布之間的差異,但是與 KL 散度的區別在于,交叉熵代表用擬合分布來表示實際分布的困難程度,
- 三者(熵、KL散度、交叉熵)的關系如下:

- 資訊論的具體運用包括:函式中的交叉熵損失、機器學習中構建決策樹使用到的資訊增益、NLP 和語音演算法中的維特比演算法等,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/254721.html
標籤:其他