腦瓜子嗡嗡的小劉煉丹之路—YOLOV1 paper Analysis
嘿嘿嘿!腦瓜子嗡嗡的小劉又來了哦,這節課我們講YOLO1,拿小本本記一下筆記哇,
老夫掐指一算YOLO(You Only Look Once)從2016-2020,都從V1到V5了,YOLO在眾多的開源網路中,屬實耐打并且是非常nice的一個網路架構,從YOLO的名字都可以得出作者的強勢You Only Look Once,你只需看一次!emmmm,現在對于我來說看YOLOV1的paper是不是有點晚了🦆…
(一)、雜七雜八的前言(preface)
目前主流的object detection分為:
(1) one stage(一步到位):
one stage 可以理解為就是分類回歸一步到位,只需要一個神經網路就ojbk了,不像RCNN那樣需要先使用RPN提取ROI,然后在輸入其他網路中做卷積運算,如:YOLO SSD就是這樣的網路,
one stage 速度非常的快,如在YOLO1 的paper里面,Fast-YOLO最快可以達到150frame pre second,但是不可否定的是,魚和熊掌不能兼得,速度快了,那么魯棒、泛化能力和精度可能會有所損失,這也是one stage的痛處,但在目前的object detection task 還是可以接受的(現在的目標檢測基本上是:資料驅動型別的,半監督型別的),
(2) two stage(兩步到位):
可以理解為先采用特殊的方法選出一些相似的分類,這樣的程序叫做區域方法(Region Proposal),然后在針對選出來的類別再次進行分類回歸,Fast R-CNN就是two-stage,
假設一張圖片上有一千個類別,網路就需要做一千次匹配或者更多,這樣的網路開銷十分的巨大,因此誕生了one stage,
在看論文的時候,糾結了半天的end to end 是什么意思,(看來對一些名詞概念的知曉確實也是欠缺的,學了后面的忘了前面的,過幾天寫一篇筆記專門記這些),
(3) end to end(端到端):
在object detection(目標檢測)中輸入為原始資料,輸出則是圖片類別與置信度結果,這就是end to end(端到端),
書面一點解釋就是:端到端的演算法應用在特征學習時,無需單獨處理,而傳統模型,需要先提取出特征值再做分類回歸任務,如果特征值較多,人工去提取會出現維度災難,因此就衍生出了端到端的思,(有時候會感覺ML的比DL更加實用),
簡單來說,就是深度神經網路處理問題不需要像傳統模型那樣,如同生產線般一步步去處理輸入資料,直到輸出最后的結果(其中每一步處理程序都是經過人為考量設定好的(“hand-crafted ” function),
end to end 提取特征的程序不再需要人工,而且交給了機器,可以理解為半監督吧!!!(因為還是需要人工去掌控一些特征值,以及引數),其在不同的地方有不同的詮釋,有端到端的訓練,端到端的模型,端到端的自動駕駛等,這僅只是一個思想,充分理解就好了,
神經網路的特征如同一個黑盒子一樣,你無法去干預,只能調整引數、濾波器和輸入的資料特征(input data feature map),因此得到一個魯棒和泛化能力好的模型,往往考驗著演算法攻城獅🦁的經驗與能力,(而人工智能只是一個概念名詞,并不只有DL才是,合理審視好了!)
(二)、推理全文的摘要(Abstract)
作者設計了一個新的目標檢測網路,端到端(end to end)的檢測模式,直接將object detection作為回歸問題,由一個神經網路去評測整張影像上的bbox和預測的類別的概率,與2016年最先進的檢測系統(state-of-the-art detection systems)來比較的話,YOLO在背景預測上有著更少的在假陽性(False positives),并且YOLO在自然影像和實時性等性能優于R-CNN和DPM,
備注:(模型評估的知識)
False Positive (FP假陽性) : False(檢測模型不能成功的)Positive(判定出結果是Positive);
False Negative(FN假陰性) : False(檢測模型不能成功的) Negative (判定出結果是Negative的);
True Positive(TP真正例) : True(檢測模型成功的) Positive (判定出結果是Positive的);
True Negative(TN真偽例) : True(檢測模型成功的) Negative (判定出結果是Negative的)
(三)、吹牛皮的介紹(Introduction)
無論是在簡單和復雜的情況時候,人們在看見影像的時候,也能夠快速準確的分辨的出影像中存在的物體,以及位置資訊,人類的感官系統是如此的準確和快速,允許人們執行復雜的任務,如:駕駛與有意識的想法,而準確的目標檢測演算法能夠在計算機在沒有傳感器的情況下也能實習自動駕駛,并且能使用輔助設備能夠向人類用戶傳達實時場景資訊,其為通用的機器人系統釋放潛力,
2016年的大多數的檢測系統多采用的采用的是分類器來做,如HOG+SVM演算法,當然那個時候也涌現了像SSD、Fast R-CNN等網路模型,然而,大多數演算法為了檢測出目標,都沒有采用DL,而是采用ML中的分類器在測驗影像不同的位置進行評估,如DMP(Demoucron Malgrange Pertuiset)采用滑動視窗法(sliding window approach)&SVM,通過設定stride(步長)均勻滑動,
后面提出了與R-CNN的區別以及YOLO的🐂,概括如下:
1). RCNN采用Region Proposal的方法作為第一階段來得到bounding box,然后在這些bbox上做classification,之后在細化bbox,消除重復的檢測,
2). YOLO將object detection當作一個Regression問題,直接從影像像素到邊界框坐標和類別概率,這里會出現邊界框中心坐標的loss和類別的loss,其并不需要,如同DMP演算法等設定一些管道,以及對管道優化,
3). YOLO會對圖片進行全面的推理,與Sliding Window & Region Proposal 不同,YOLO訓練和測驗時候會看見整個影像,神經網路的通性-黑盒-只能看見結果與輸入,
4). YOLO在背景的誤檢率上比Fast R-CNN少了一半,但是YOLO在小目標的識別定位上明顯較差,
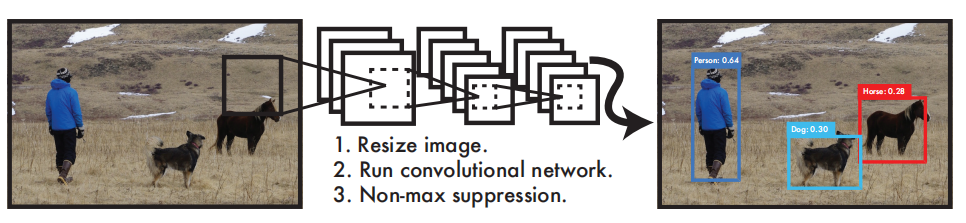
圖1. The YOLO Detection System
如圖一所示,YOLO處理影像非常的簡單直接,先將輸入影像調整為448×448,后在影像上運行單個卷積網路,最后將由模型的置信度對所得到的檢測進行閾值處理,得出結果,其可以實作端到端的檢測,
其他:!!!
HOG(Histogram of Oriented Gradients)通過計算和統計區域區域的梯度方向直方圖來構成特征,SVM(support vector machine)分類演算法非常🐂的一個演算法了(面試題!!!),其是一種二分類模型,基本的思想就是求解能夠正確劃分訓練資料并且幾何間隔最大的分離超平面,(HOG 在opencv中似乎封裝好了)
R-CNN(Region Convolution Neural Network):R-CNN采樣區域提案網路(Region Proposal Network)的方式來篩選bbox,當一張圖輸入到RPN網路時候,會得到一個二進制(binary)的值P, P∈[0,1],在通過人為設定一個閾值(threshold),來判斷P與threshold之間的關系,從而將bounding box與類別初步篩選出來,這些被篩選出來的bbox區域稱為感興趣區域(ROI),再將這些ROI輸入到主干(backbone)或者其他網路中,進行分類定位等程序,
(四)、通俗易懂的檢測框架(Unified Detection)
YOLO將目標檢測網路看成一個神經網路,輸入圖片輸出結果(bbox和label資訊),其將輸入的圖片劃分為
S
?
S
S*S
S?S的網格,如果object落入中心網格,則該Grid Cell就負責檢測它,YOLO一張圖最多可以產生98個bbox,而選擇性搜索的存在著2000,
總結來說可以分為以下4點:
1). 每個網格預測
B
B
B個邊界框(bounding box)和置信度(confidence
scores),這些置信度反應了模型在邊界上的準確率,置信度(confidence)定義公式為:
P
r
(
O
b
j
e
c
t
)
?
I
O
U
p
r
e
d
t
r
u
t
h
Pr(Object)*IOU^{truth}_{pred}
Pr(Object)?IOUpredtruth?,當目標不在在網格當中,則置信度為
0
0
0,除此之外,作者希望置信度等于bbox和ground truth的聯合交集(
I
O
U
=
A
∩
B
A
∪
B
IOU=\frac{A∩B}{A∪B}
IOU=A∪BA∩B?(Intersection Over Union))(寫到這里,聞到外面一股炸雞的香味,哭了!凌晨0點了)
2). bounding box的介紹:其包含5個部分
x
,
y
,
w
,
h
x, y, w, h
x,y,w,h和置信度(
c
c
c),
(
x
,
y
)
(x,y)
(x,y)代表bbox的中心點,其在Grid Cell的位置,
w
w
w和
h
h
h表示該bbox的長和寬相對于input image長寬(448)的比例,這四個元素可以還原圖中的一個bbox,最后,以預測的置信度來表示預測框(predicted box)與實際邊界框(ground truth box)之間的IOU,

圖2. Grid division
3). 同時每一個網格同樣還會預測出
C
C
C個可能的類別概率:
P
r
(
C
l
a
s
s
i
∣
(
O
b
i
e
c
t
)
)
Pr(Class_i|(Obiect))
Pr(Classi?∣(Obiect)),這些概率以包含目標的網格單元為條件,每個網格單元只預測的一組類別概率(Grid Cell其是針對類別概率的),而不管邊界框的的數量
B
B
B是多少,
在測驗的時候,作者將分類概率和單個盒子的置信度概率進行乘積公式如下:
P
r
(
C
l
a
s
s
i
∣
O
b
j
e
c
t
)
?
P
r
(
O
b
j
e
c
t
)
?
I
O
U
p
r
e
d
t
r
u
t
h
=
P
r
(
C
l
a
s
s
i
)
?
I
O
U
p
r
e
d
t
r
u
t
h
Pr(Class_i|Object) * Pr(Object) * IOU^{truth}_{pred} = Pr(Class_i) * IOU^{truth}_{pred}
Pr(Classi?∣Object)?Pr(Object)?IOUpredtruth?=Pr(Classi?)?IOUpredtruth?
該公式為每個框提高了置信度分數,這些score編碼了該類出現在框中的概率以及預測擬合目標的程度,即理解為每個bounding box的confidence和每個類別的score相乘,得到每個bounding box屬于哪一類的confidence score一般是是會設定threshold或者NMS來濾除一些低概率的框,如下圖所示,每個單元格需要預測
(
B
?
5
+
C
)
(B*5+C)
(B?5+C)個值,而圖片劃分為
S
?
S
S*S
S?S,那么最終的預測值就是
(
S
×
S
×
(
B
?
5
+
C
)
)
(S×S×(B*5+C))
(S×S×(B?5+C))個大小的tensor,
作者在論文中給出了PASCAL VOC dataset的計算方法,該資料集總共有20個類別,其讓
S
=
1
,
B
=
2
S=1,B=2
S=1,B=2則為
7
×
7
×
(
2
?
5
+
20
)
7×7×(2*5+20)
7×7×(2?5+20)個tensor,
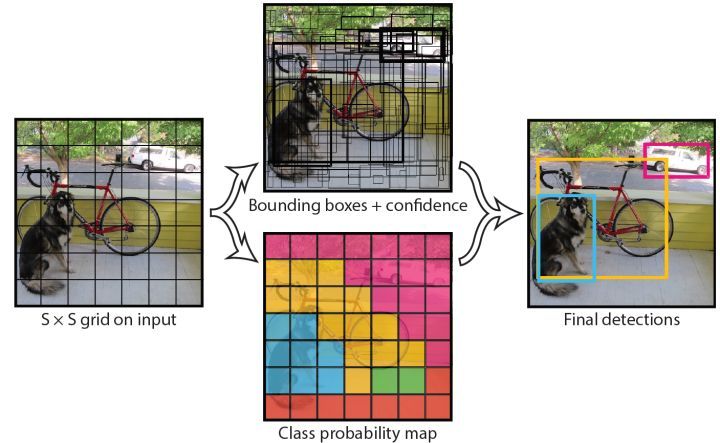
圖3. Model Prediction Structure
4.1、 普普通通的網路結構(Network Design)
YOLO的模型受到了Google Net影像分類模型的啟發,其結構分為24個Conv層(提取image feature)和2個FC層(predict label),卷積層主要使用 1 ? 1 1*1 1?1的卷積來做降維層,然后緊跟著 3 ? 3 3*3 3?3的卷積,對于卷積層和全連接層都采用Leaky ReLU激活函式: M a x ( x , 0.1 x ) Max(x,0.1x) Max(x,0.1x)(修正線性單元,使其變得非線性),但是在最后的一層采用了Linear激活函式,然后reshape輸出(本來這里我是想在圖片上畫出來的,但是算了,這里面在YOLO后面的修改版中,作者加入了batch_normalization),
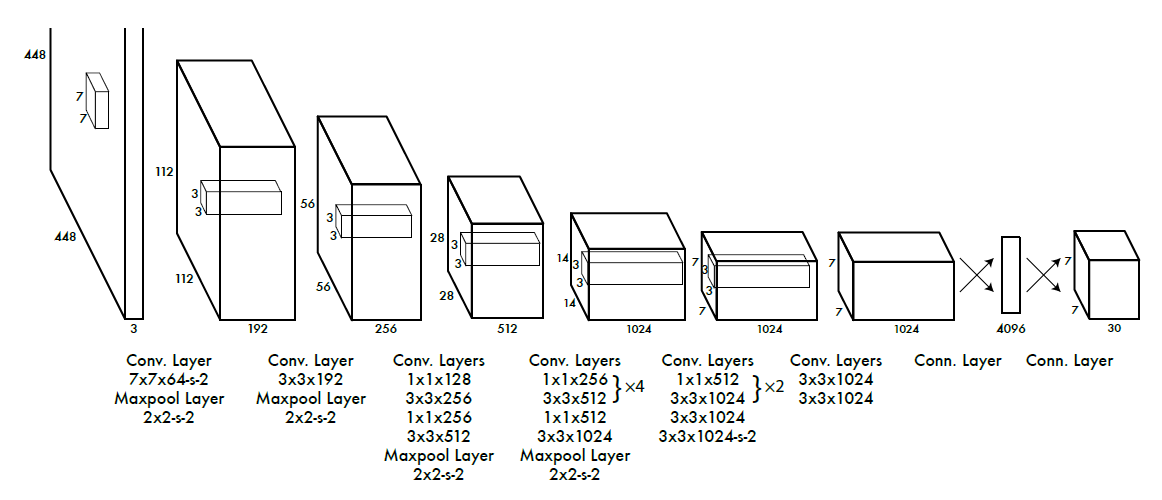
圖4. The Architecture
小小的細節(detail):
1). 網路的輸出為
7
×
7
×
(
2
?
5
+
20
)
7×7×(2*5+20)
7×7×(2?5+20)的二維的tensor,其shape為(沒有anchors機制垃圾):
[
b
a
t
c
h
,
7
×
7
×
(
2
?
5
+
20
)
]
[batch,7×7×(2*5+20)]
[batch,7×7×(2?5+20)],我們可以通過索引切片的方式訪問置信度、類別概率和邊界框預測結構,對于每一個單元格,前20個元素是類別概率,后面兩個是邊界框的置信度,兩者相乘得到類別置信度,最后的8個元素是邊界框的
(
x
,
y
,
w
,
h
)
(x,y,w,h)
(x,y,w,h),而
c
c
c不考慮進去純粹是為了計算方便,
2). YOLO在ImageNet的進行了預訓練,主要采用了預訓練的分類模型的前20層卷積層,后面添加了4個average-pooling layer和2個fully connected layer(FC層),并且隨機初始化了權重,因為檢測需要細微的資訊,因此將
224
?
224
224*224
224?224的影像輸入增加到了
448
?
448
448*448
448?448,
3). YOLO其最后一層為預測概率和邊界框的坐標,通過影像寬度和高度對bbox寬度和高度進行歸一化,使其落在[0,1)之間,并且其將邊界框的x和y坐標引數,為特定網路單元位置的偏移量,因此其邊界也在[0,1)之間,
(五)、損失函式(Loss Function)
因為YOLO將目標檢測當作回歸問題,所以采用的是均方差損失函式,但是分類誤差和定位誤差是權重一樣的,會導致模型訓練早期發散,因此添加了邊界框坐標損失,去減少不包含目標邊界框的置信度損失,
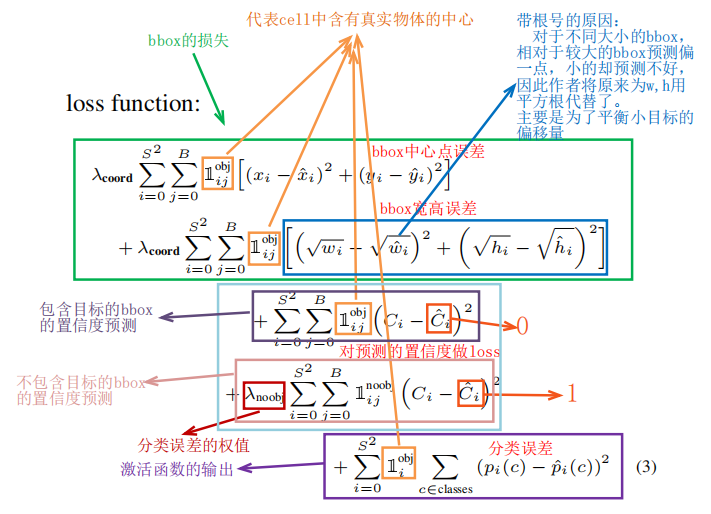
圖5. Loss Function
其中表示目標是否出現在網格單元
1
i
j
obj
\mathbb{1}_{ij}^{\text{obj}}
1ijobj?表示網格單元
i
i
i中的第
j
j
j個邊界框預測器“負責”該預測
對于定位誤差,即邊界框坐標預測誤差,采用較大的權重,
λ
c
o
o
r
d
=
5
λ_{coord}=5
λcoord?=5發,然后其區分不包含目標的邊界框與含有目標的邊界框的置信度,對于前者,采用較小的權重
λ
n
o
o
b
j
λ_{noobj}
λnoobj?其它權重值均設為1,然后采用均方誤差計算不同大小的box,但是對于較大bbox預測較好,對于小的box預測較差,因此將網路的邊界框的寬與高預測改為對其平方根的預測,即預測值變為
(
x
,
y
,
w
,
h
)
(x,y,\sqrt[]{w}, \sqrt[]{h})
(x,y,w
?,h
?),
由于每個單元格預測多個邊界框,但是其對應類別只有一個,那么在訓練時,如果該單元格內確實存在目標,那么只選擇與ground truth的IOU最大的那個邊界框來負責預測該目標,而其它邊界框認為不存在目標(這里會輸出兩個bbox進行交并運算),
這樣設定的雖然將會使一個單元格對應的邊界框更加專業化,其可以分別適用不同大小,不同高寬比的目標,從而提升模型性能,可是如果一個單元格記憶體在多個目標怎么辦,這時候YOLO演算法就只能選擇其中一個來訓練,這也是YOLO演算法的缺點之一,因此檢測多目標屬性,遮擋屬性時,YOLOV1的效果不佳,并且要注意的一點,對于不存在對應目標的邊界框,其誤差項就是只有置信度,坐標項誤差是沒法計算的,而只有當一個單元格內確實存在目標時,才計算分類誤差項,否則該項也是無法計算的,
YOLO在Pascal VOC 2007&2012上訓練設定部分引數為:
e
p
o
c
h
s
=
135
,
b
a
t
c
h
s
i
z
e
=
64
,
m
o
m
e
n
t
u
m
=
0.9
,
d
e
c
a
y
=
0.0005
epochs = 135,batch_size = 64,momentum =0.9,decay = 0.0005
epochs=135,batchs?ize=64,momentum=0.9,decay=0.0005,第一個周期的
l
r
=
1
0
?
3
到
1
0
?
2
lr=10^{-3}到10^{-2}
lr=10?3到10?2,后面就是
l
r
=
1
0
?
3
lr=10^{-3}
lr=10?3,再到
1
0
?
4
10^{-4}
10?4,YOLO并沒有做太多的資料增強,僅僅只將20%的資料進行了HSV色彩空間轉換,并且對圖片進行了下采樣,而為了避免過擬合,YOLO在第一個FC層后添加了一個dropout層(0.5 rate),YOLO最后的輸出,為了消除重復出現的框,采用了非極大值抑制法(Non-maximum suppression: NMS),
這里提一個小問題,為什么batch_size要為2的冪?這樣做的好處是什么?
(六)、那一年YOLO評估(assessment)
YOLO剛剛出的時候并沒有鋒芒畢露,在當時YOLO與許多的目標檢測演算法進行了對比,大多數的都是停留在傳統上,基本上采用:sliding window,haar ,sift,hog,卷積來提取魯班特征,再輸入分類器或定位器中去,以達到識別的效果,而隨著神經網路和硬體(GPU&CPU 等)發展越來的的檢測采用了DL的方式,作者在paper介紹了許多種方式,有興趣的可以去讀一下原文!(在提升英語水平的同時,也可以熟悉寫論文的規則,)
如下4張圖可知(ps:只能在當時這樣說啦:):
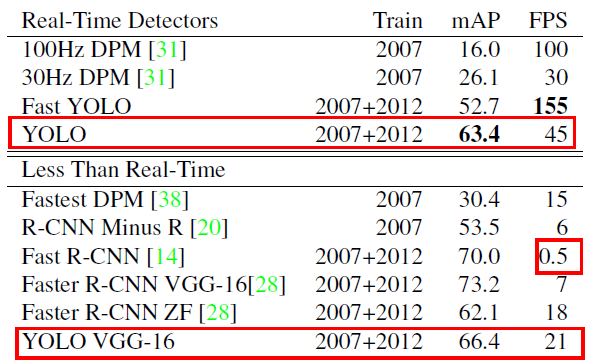
圖6: 實時性檢測,可以的得出Fast YOLO是PASCAL VOC 上速度最快的檢測器,而且檢測精度是其他系統的兩倍,YOLO比Fast YOLO的mAP高10,而且速度遠高于實時系統的速度要求,
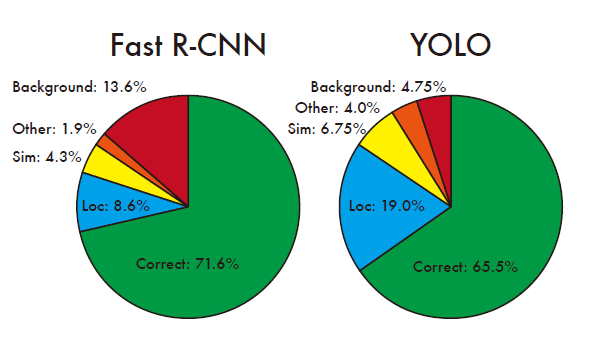
圖7: 錯誤分析 Fast R-CNN vs. YOLO ,反映了在各個類別的得分最高的前N個預測中定位錯誤和背景錯誤的比例,
|
|
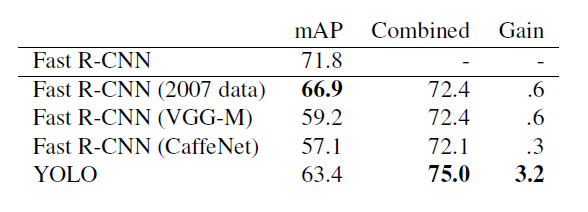
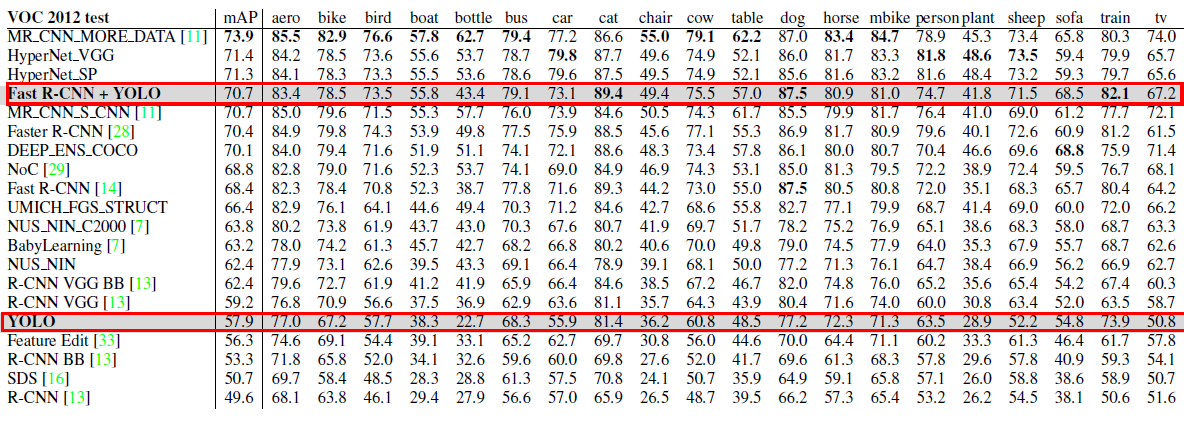
圖9: PASCAL VOC 2012排行榜, YOLO是Fast R-CNN + YOLO得分第四高的方法,比快速R-CNN提高2.3%
|
|
(七)、YOLO1的小小終結(summary)
優點:
1)、速度快,YOLO1在測驗階段,每張影像只預測772=98個box,所以非常快,
2)、背景誤檢率低,因為其是整張圖全域進行編碼,我感覺比太好,
3)、在藝術品的檢測中效果也好,
缺點:
1)、YOLO模型檢測小目標效果不佳,其IOU對大的bbox小誤差通常是良性的,但是小的bbox小誤差就不是很友好,主要原因是不能正確的定位,目標較小,其需要的感受野就可能越小,而YOLO后面是較大的感受野,因此小物體檢測效果不佳,
2). YOLO的每個網格都只能預測兩個格子,只能存在一個類別,從而使得YOLO在預測的鄰近目標的時候的效果也不好,因為只取置信度大的box,
3). 泛化能力偏弱,
YOLOV1存在的問題,作者在后續的網路中都進行了修改,研究演算法的魅力往往在他的資料處理,匹配策略和loss函式上,深度學習模型搭建對大哥們來說較為簡單,但是這些對我這小菜雞來說可以喝幾壺了,所以大哥們,要是我有什么不對的地方請指正!!!ps:今天又被老師打電話,糾結一個問題:是否實地測驗過?其實EI審核都過了,就只要修改幾點了,但是這幾點屬實非常的重要,加油吧,騷年藍!🐱?🚀,
參考文獻(literature):
YOLO(You Only Look Once)
R-CNN(Region Convolution Neural Network)
Fast R-CNN
HOG(Histogram of Oriented Gradients)
SVM(support vector machine)
關于感受野的計算
模型評估
目標檢測|YOLO原理與實作
腦瓜子嗡嗡的小劉,是某造車新勢力🚗的一名自動駕駛影像演算法實習生🐱?🏍,同時小劉也是一枚熱衷于人工智能技術的萌新小白🌏,小劉在校期間也參加過許許多多的國內比賽(主要是嵌入式與物聯網相關的),要是大哥們有什么問題,可以隨時Call me,希望能和大哥們共同進步!!!同時也希望大哥們看文章的時候也能抽空點個贊!謝謝大哥們了!!!(づ ̄ 3 ̄)づ
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/254880.html
標籤:AI