Docker搭建Hadoop集群踩坑指南
- 制作鏡像
- 1、拉取ubuntu鏡像
- 2、使用Dockerfile構建包含jdk的ubuntu鏡像
- 3、進入映像
- 4、升級apt-get
- 5、安裝vim
- 6、更新apt-get鏡像源
- 7、重新升級apt-get
- 8、安裝wget
- 9、創建并進入安裝hadoop的檔案目錄
- 10、通過wget下載hadoop安裝包
- 11、解壓hadoop
- 12、配置環境變數并重啟組態檔
- 13、創建檔案夾并修改組態檔
- 14、修改hadoop環境變數
- 15、安裝SSH
- 修改ssh配置
- 16、匯出鏡像
- 17、集群測驗
- 修改master中slaves檔案
- 啟動hadoop
- 18、使用wordCount測驗集群
本人由于畢業設計選題,開始接觸Hadoop,預期搭建一個具有分布式存盤與高性能處理資料的框架,技術選型初步采用Docker進行分布式集群搭建,并且使用Docker封裝出一個靈活添加使用的演算法層, 環境搭建中踩坑多次,特此記錄分享,有需求的小伙伴可以參考一下,
作業系統:Ubuntu20.04 默認Docker環境已經搭建完成
制作鏡像
1、拉取ubuntu鏡像
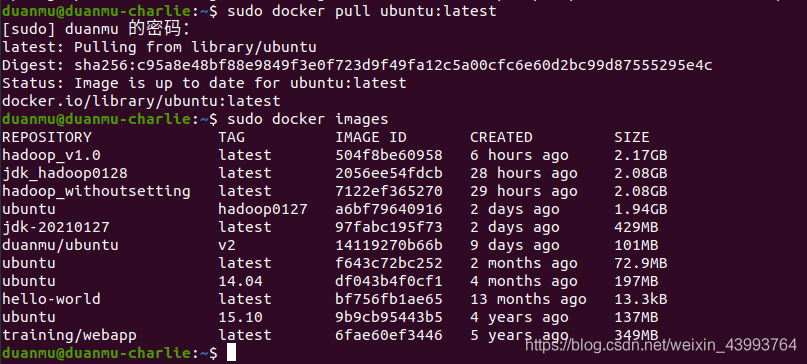
首先拉取一個ubuntu最新的鏡像作為基礎映像docker pull ubuntu:latest,我這里已經拉取過了,如果第一次pull會開始下載,下載后可以看一下docker images已經有一個ubuntu版本號為latest的了,
2、使用Dockerfile構建包含jdk的ubuntu鏡像
去jdk官網下載jdk包,我下載的jdk1.8 jdk-8u281-linux-x64.tar.gz,在下載好的tar.gz檔案所在的目錄,新建一個Dockerfile檔案,并進入編輯狀態
vim Dockerfile
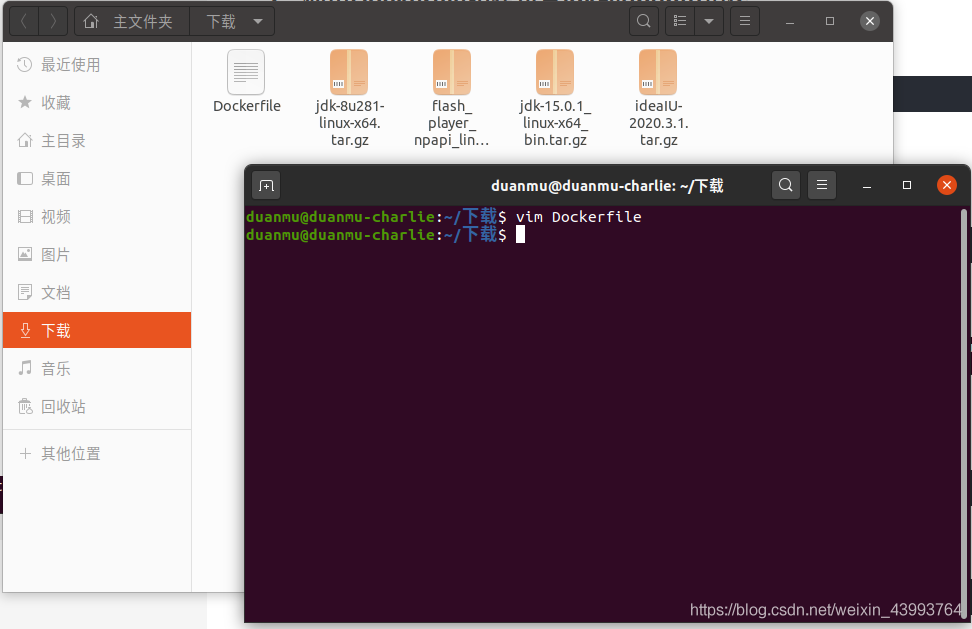
輸入下面的檔案內容,其中jdk的版本號要根據你下載的版本適當修改:
FROM ubuntu:latest
MAINTAINER duanmu
ADD jdk-8u281-linux-x64.tar.gz /usr/local/
ENV JAVA_HOME /usr/local/jdk1.8.0_281
ENV CLASSPATH $JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
ENV PATH $PATH:$JAVA_HOME/bin
編輯好后保存,開始build鏡像
docker build -t jdk-20210127 .
構建一個包含jdk的ubuntu鏡像命名為jdk-20210127 ,注意最后的“.”
3、進入映像
新建一個以jdk-20210127為基礎鏡像的容器命名為ubuntu_hadoop并指定容器的hostname為charlie,并進入容器,
docker run -it --name=ubuntu_hadoop -h charlie jdk-20210127
下圖為進入容器后:
此時輸入
java -version
已經可以顯示jdk的版本號了,

4、升級apt-get
apt-get update
5、安裝vim
apt-get install vim
6、更新apt-get鏡像源
默認的apt-get下載源速度太慢,更換下載源可以提升速度,進入下載源串列檔案,按a進入insert模式
vim /etc/apt/sources.list
將其中內容全部替換為以下內容
deb-src http://archive.ubuntu.com/ubuntu focal main restricted #Added by software-properties
deb http://mirrors.aliyun.com/ubuntu/ focal main restricted
deb-src http://mirrors.aliyun.com/ubuntu/ focal main restricted multiverse universe #Added by software-properties
deb http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted
deb-src http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted multiverse universe #Added by software-properties
deb http://mirrors.aliyun.com/ubuntu/ focal universe
deb http://mirrors.aliyun.com/ubuntu/ focal-updates universe
deb http://mirrors.aliyun.com/ubuntu/ focal multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-updates multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse #Added by software-properties
deb http://archive.canonical.com/ubuntu focal partner
deb-src http://archive.canonical.com/ubuntu focal partner
deb http://mirrors.aliyun.com/ubuntu/ focal-security main restricted
deb-src http://mirrors.aliyun.com/ubuntu/ focal-security main restricted multiverse universe #Added by software-properties
deb http://mirrors.aliyun.com/ubuntu/ focal-security universe
deb http://mirrors.aliyun.com/ubuntu/ focal-security multiverse
其中focal是ubuntu20.04的版本號,其他版本諸如xenial等修改版本號即可,
7、重新升級apt-get
apt-get update
8、安裝wget
apt-get install wget
9、創建并進入安裝hadoop的檔案目錄
mkdir -p soft/apache/hadoop/
cd soft/apache/hadoop
10、通過wget下載hadoop安裝包
wget http://mirrors.ustc.edu.cn/apache/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
本人使用的是比較新的hadoop3.3.0版本,其他版本也可以訪問這個網站的目錄樹去找,(3.3.0在后續配置中有一步驟略有差別,之后會提,)
11、解壓hadoop
tar -xvzf Hadoop-3.3.0.tar.gz
12、配置環境變數并重啟組態檔
vim ~/.bashrc
新增以下環境變數:
export JAVA_HOME=/usr/local/jdk1.8.0_281
export HADOOP_HOME=/soft/apache/hadoop/hadoop-3.3.0
export HADOOP_CONFIG_HOME=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
并重啟組態檔
source ~/.bashrc
13、創建檔案夾并修改組態檔
cd $HADOOP_HOME
mkdir tmp
mkdir namenode
mkdir datanode
修改組態檔:
cd $HADOOP_CONFIG_HOME
vim core-site.xml
將下面內容替換:
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/soft/apache/hadoop/hadoop-3.3.0/tmp</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
<final>true</final>
</property>
</configuration>
更改hdfs-site.xml
vim hdfs-site.xml
用下面配置替換:
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/soft/apache/hadoop/hadoop-3.3.0/namenode</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.name.dir</name>
<value>/soft/apache/hadoop/hadoop-3.3.0/datanode</value>
<final>true</final>
</property>
</configuration>
接下來
cp marred-site.xml.template marred-site.xml
vim mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tarcker</name>
<value>master:9001</value>
</property>
</configuration>
14、修改hadoop環境變數
在hadoop的安裝目錄下,找到hadoop-env,sh檔案
vim hadoop-env.sh
在最后添加
export JAVA_HOME=/usr/local/jdk1.8.0_281
重繪
hadoop namenode -format
15、安裝SSH
hadoop的環境必須滿足ssh免密登陸,先安裝ssh
apt-get install net-tools
apt-get install ssh
創建sshd目錄
mkdir -p ~/var/run/sshd
生成訪問密鑰
cd ~/
ssh-keygen -t rsa -P '' -f ~/.ssh/id_dsa
cd .ssh
cat id_dsa.pub >> authorized_keys
這一步驟提示安裝路徑與設定密碼時全布直接按回車即可設定成免密,
修改ssh配置
vim /etc/ssh/ssh_config
添加,將下面這句話直接添加即可,也可以在檔案中找到被注釋的這句話去修改,
StrictHostKeyChecking no #將ask改為no
vim etc/ssh/sshd_config
在末尾添加:
#禁用密碼驗證
PasswordAuthentication no
#啟用密鑰驗證
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
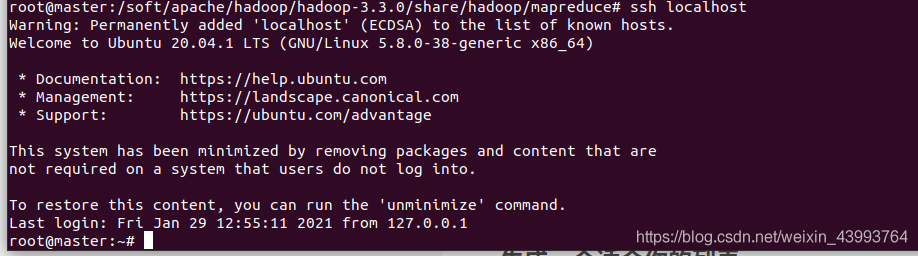
最后使用下面陳述句測驗是否免密登陸,
ssh localhost
出現下圖即免密配置成功,
最后在在高版本hadoop配置程序中,最后啟動時常常報如下的錯:
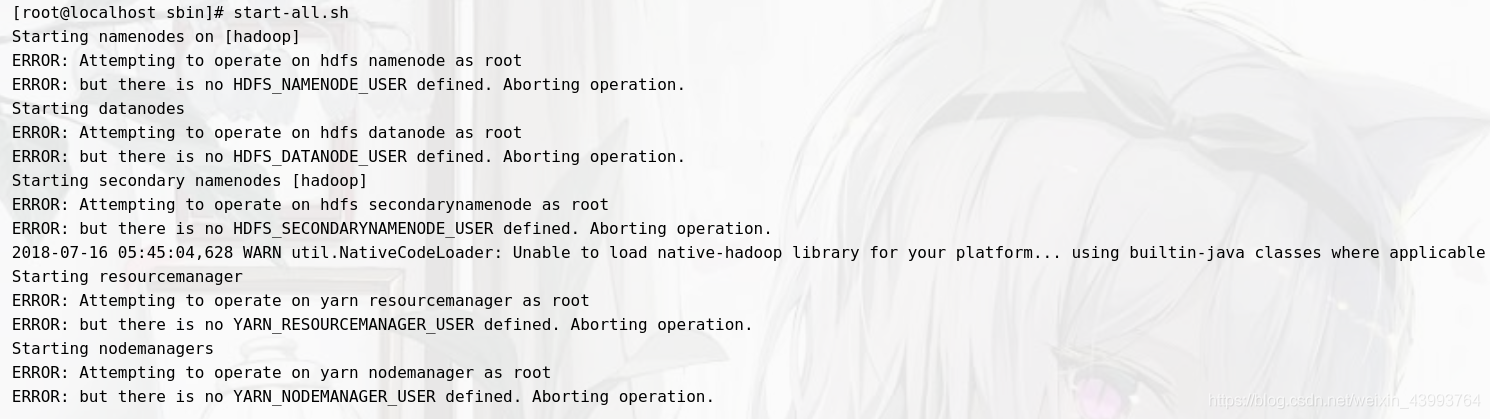 為了避免踩坑,先提前設定,進入環境變數
為了避免踩坑,先提前設定,進入環境變數
vim /etc/profile
增加如下內容并保存:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
使配置生效
source /etc/profile
16、匯出鏡像
至此鏡像已經配置完成,退出容器,將配置好的鏡像保存,其中xxxx為剛剛操作的容器的id,可以使用docker ps -a查看
docker commit xxxx ubuntu:hadoop
此時ubuntu_hadoop就是最終配置好的包含hadoop的鏡像,
17、集群測驗
依次構建并啟動三個以剛剛生成的鏡像為基本鏡像的容器,依次命名為master 、slave1、slave2,并將master做埠映射(提示:容器要處于運行狀態,生成容器后使用ctrl+P+Q退出可以使容器保持后臺運行,)
docker run -it -h master --name=master -p 9870:9870 -p 8088:8088 ubuntu:hadoop
docker run -it -h slave1 --name=slave1 ubuntu:hadoop
docker run -it -h slave2 --name=slave2 ubuntu:hadoop
修改每個容器的host檔案
對matser、slave1、slave2里的host檔案,分別加入其他兩個容器的ip
vim /etc/hosts
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
172.17.0.2 master
172.17.0.3 slave1
172.17.0.4 slave2
修改master中slaves檔案
注意,在hadoop3.3.0版本中并不是修改slaves檔案,而是修改workers檔案,此處為3.3.0版本的一些變化,
老版本(自行查找hadoop版本中已存在檔案是slaves還是iworkers)
cd $HADOOP_CONFIG_HOME/
vim slaves
3.3.0
cd $HADOOP_CONFIG_HOME/
vim workers
將其他兩個節點名稱加入檔案
slave1
slave2
啟動hadoop
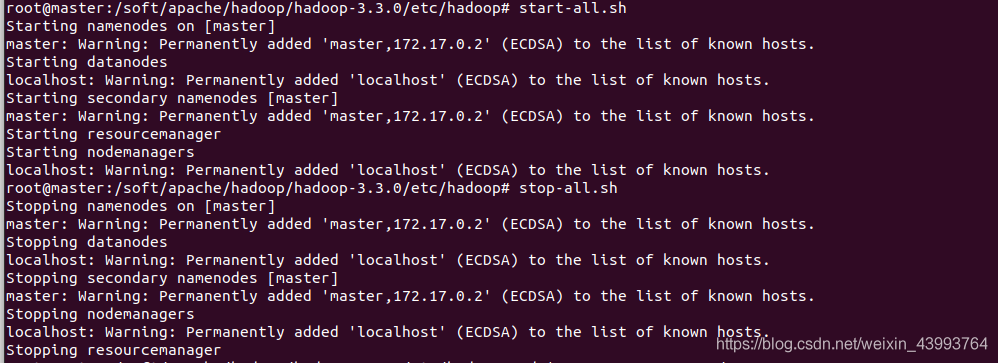
start-all.sh
出現下圖即為配置成功,
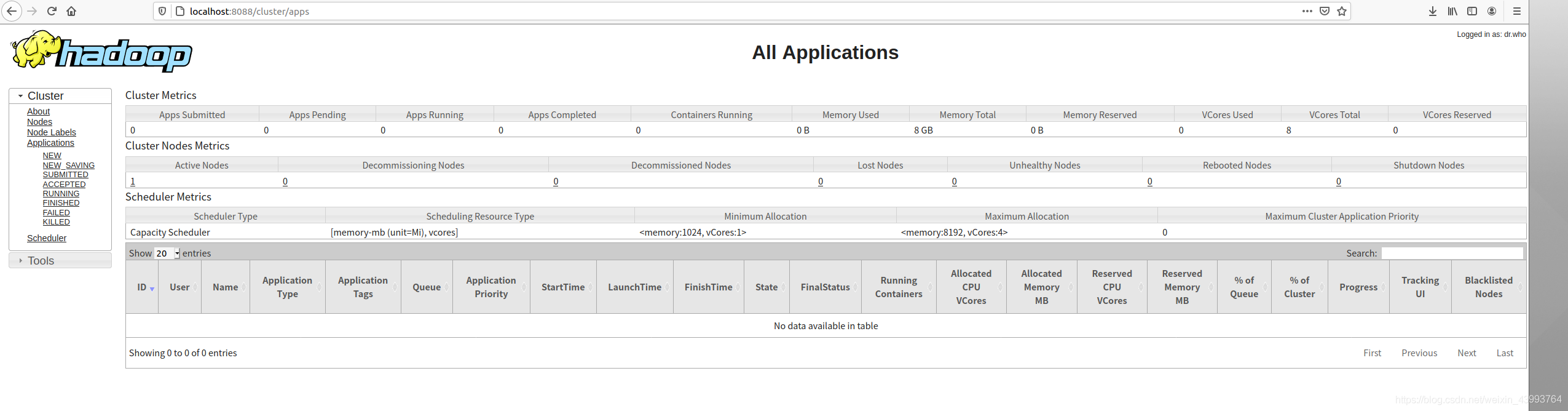
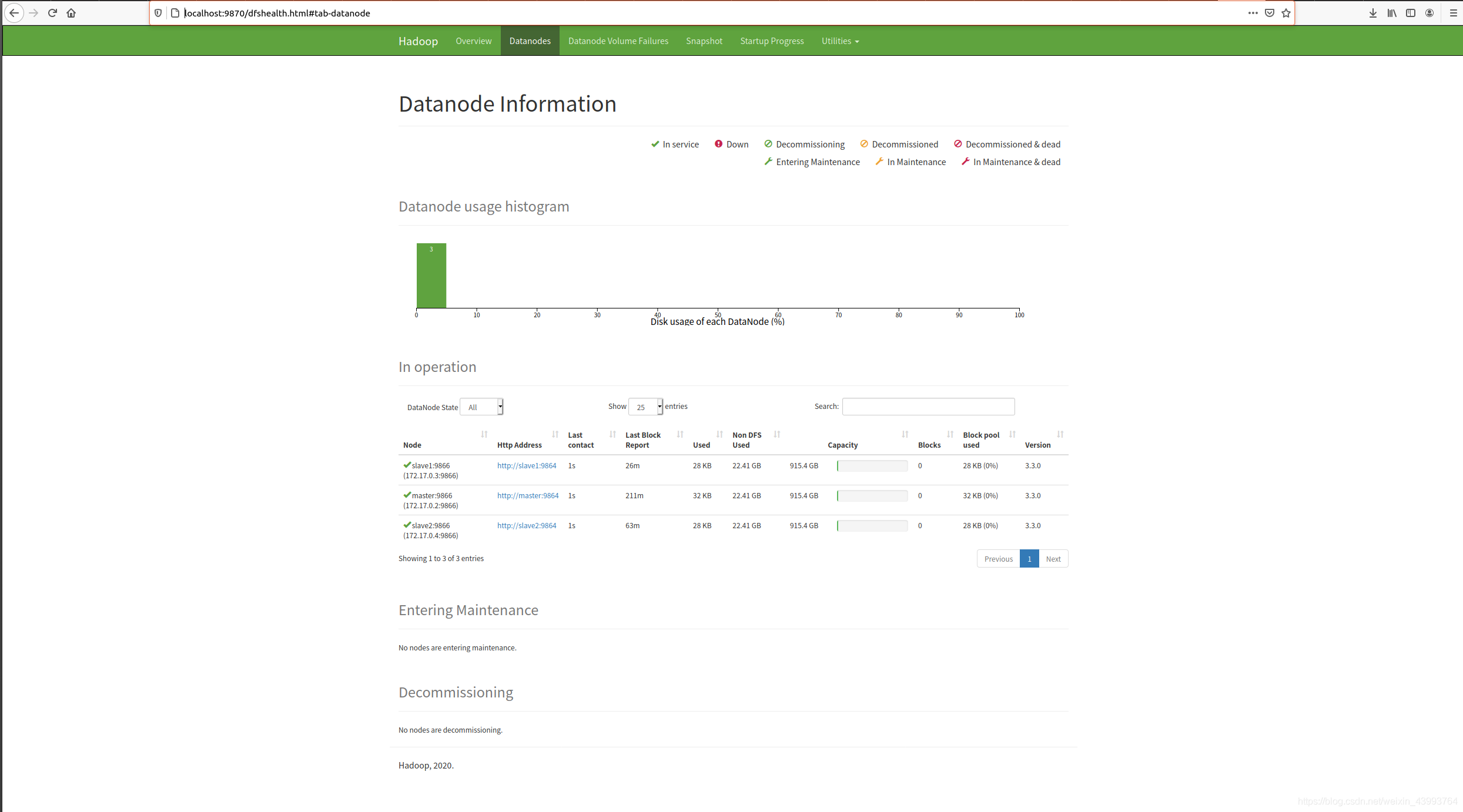
 此時可以訪問localhost:9870和localhost:8088 ,去監控集群運行狀態了,如下圖
此時可以訪問localhost:9870和localhost:8088 ,去監控集群運行狀態了,如下圖
18、使用wordCount測驗集群
進入hadoop目錄,查看一下所有檔案,以檔案中的LICENSE.txt為輸入檔案,來統計其中單詞出現頻率作為測驗,
cd $HADOOP_HOME
ll
首先在HDFS檔案存盤系統中新建一個inputs檔案夾,
hadoop fs -mkdir /input
可以使用下面命令看到檔案夾創建成功
hadoop fs -ls /
把license.txt放進input檔案夾
hadoop fs -put LICENSE.txt /input
查看已經放入
hadoop fs -ls /input
使用示例程式進行統計(mapreduce示例包不同版本路徑不同需要自行查找,下面是3.3.0版本)
hadoop jar /soft/apache/hadoop/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /input /output
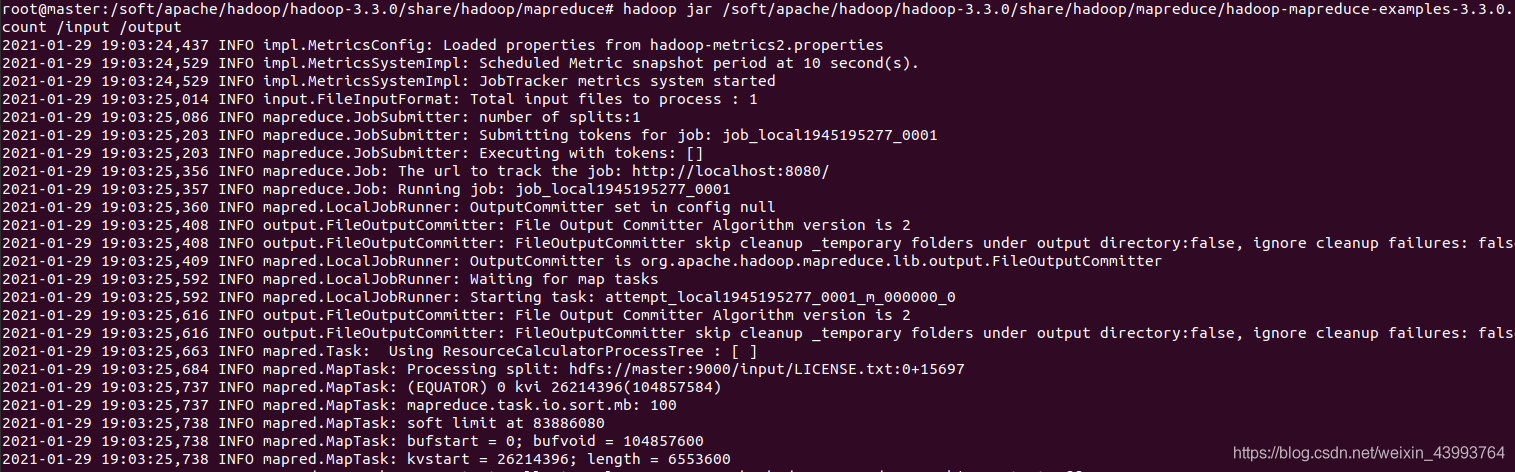
運行后查看檔案夾,發現多了一個output檔案夾,打開output檔案夾,多了兩個檔案,_SUCCESS和part-r-00000,說明運行成功,
hadoop fs -ls /
hadoop fs -ls /output
 打開part -r-00000
打開part -r-00000
hadoop fs -cat /output/part-r-00000
詞頻已經統計完畢了:
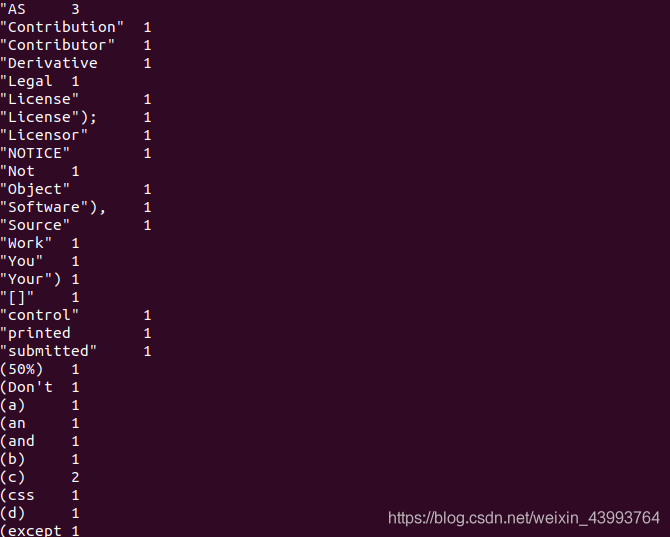
至此,已經完成了基本的Docker搭建hadoop分布式集群,并進行簡單的測驗,接下來我也會在學習程序中持續更新,兄弟萌覺得有用點個贊奧!!!
20210129 duan
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/254906.html
標籤:其他
上一篇:計算機考研408真題(全國統考2009--2020)、985高校計算機考研資料(清北+北理+北郵+武大+華科+浙大+復旦+哈工大+西安交大+華南理工)、王道四件套、天勤四件套---百度網盤免費下載