1.在生產環境下,如何處理組態檔 && 表的資料處理
組態檔,或者配置表,一般是放在在線db,比如mysql等關系型資料庫,或者后臺rd直接丟給你一份檔案,資料量比起整個離線資料倉庫的大表來說算很小,所以這種情況下,一般的做法是將小表,或者小檔案廣播出去,那么下面一個例子來看,廣播表的使用解決ip地址映射問題
資料地址:鏈接:https://pan.baidu.com/s/1FmFxSrPIynO3udernLU0yQ提取碼:hell
2.日志分析案例1
2.1 資料說明
http.log:
用戶訪問網站所產生的日志,日志格式為:時間戳、IP地址、訪問網址、訪問資料、瀏覽器資訊等,樣例如下:

ip.dat:ip段資料,記錄著一些ip段范圍對應的位置,總量大概在11萬條,資料量也算很小的,樣例如下

檔案位置:data/http.log、data/ip.dat
鏈接:https://pan.baidu.com/s/1FmFxSrPIynO3udernLU0yQ提取碼:hell
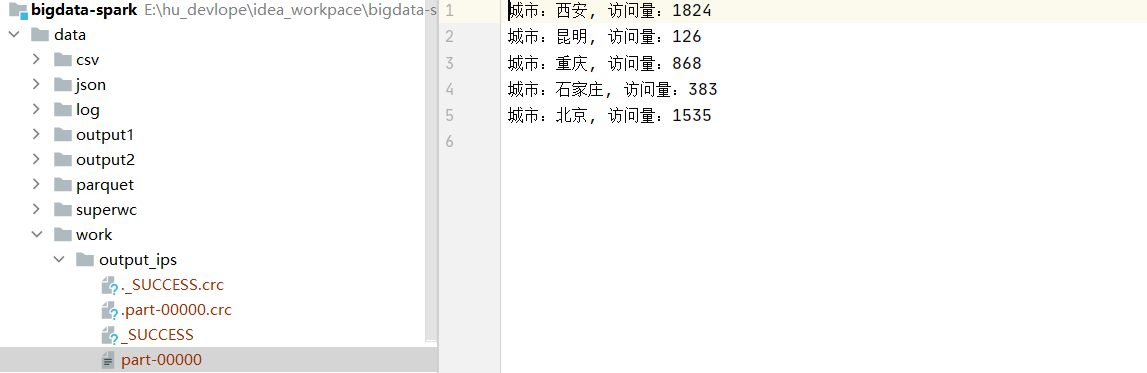
要求:將 http.log 檔案中的 ip 轉換為地址,如將 122.228.96.111 轉為溫州,并統計各城市的總訪問量
2.2.實作思路和代碼如下
有三個關鍵點,http.log的關鍵資訊是ip地址,所以根據資料的精簡原則,只讀取ip即可,另外ip映射比對的時候 ,ip地址映射檔案是排序的,所以為了提高查找效率,采用將ip地址轉為long型別,然后再用二分法來查找,找到地址后映射為地址,
package com.hoult.work
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
/**
* 資料源:1.ip地址的訪問日志 2.ip地址映射表
* 需要把映射表廣播,地址轉換為long型別進行比較
*/
object FindIp {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local[*]")
.appName(this.getClass.getCanonicalName)
.getOrCreate()
val sc = spark.sparkContext
import spark.implicits._
val ipLogsRDD = sc.textFile("data/http.log")
.map(_.split("\\|")(1))
val ipInfoRDD = sc.textFile("data/ip.dat").map {
case line: String => {
val strSplit: Array[String] = line.split("\\|")
Ip(strSplit(0), strSplit(1), strSplit(7))
}
}
val brIPInfo = sc.broadcast(ipInfoRDD.map(x => (ip2Long(x.startIp), ip2Long(x.endIp), x.address))collect())
//關聯后的結果rdd
ipLogsRDD
.map(x => {
val index = binarySearch(brIPInfo.value, ip2Long(x))
if (index != -1 )
brIPInfo.value(index)._3
else
"NULL"
}).map(x => (x, 1))
.reduceByKey(_ + _)
.map(x => s"城市:${x._1}, 訪問量:${x._2}")
.saveAsTextFile("data/work/output_ips")
}
//ip轉成long型別
def ip2Long(ip: String): Long = {
val fragments = ip.split("[.]")
var ipNum = 0L
for (i <- 0 until fragments.length) {
ipNum = fragments(i).toLong | ipNum << 8L
}
ipNum
}
//二分法匹配ip規則
def binarySearch(lines: Array[(Long, Long, String)], ip: Long): Int = {
var low = 0
var high = lines.length - 1
while (low <= high) {
val middle = (low + high) / 2
if ((ip >= lines(middle)._1) && (ip <= lines(middle)._2))
return middle
if (ip < lines(middle)._1)
high = middle - 1
else {
low = middle + 1
}
}
-1
}
}
case class Ip(startIp: String, endIp: String, address: String)
結果截圖如下:
3.日志分析案例2
3.1 資料說明
日志格式:IP命中率(Hit/Miss)回應時間請求時間請求方法請求URL請求協議狀態碼回應大小referer 用戶代理
日志檔案位置:data/cdn.txt
資料case:

任務:
2.1、計算獨立IP數
2.2、統計每個視頻獨立IP數(視頻的標志:在日志檔案的某些可以找到 *.mp4,代表一個視頻檔案)
2.3、統計一天中每個小時的流量
分析:剛開始去找格林時間的jod-time決議,找了一圈不知道該怎么寫, 后面發現只需要小時即可,使用正則來提取, 注意在求video的訪問ip時候,可以用aggregateByKey來提高性能
3.2 實作代碼
package com.hoult.work
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
/**
* 讀取日志表到rdd
* 拿到需要的欄位:ip, 訪問時間:小時即可, 視頻名video_name (url中的xx.mp4),
* 分析:
* 1.計算獨立IP數
* 2.統計每個視頻獨立IP數(視頻的標志:在日志檔案的某些可以找到 *.mp4,代表一個視頻檔案)
* 3.統計一天中每個小時的流量
*/
object LogAnaylse {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local[*]")
.appName(this.getClass.getCanonicalName)
.getOrCreate()
val sc = spark.sparkContext
val cdnRDD = sc.textFile("data/cdn.txt")
//計算獨立ips
// aloneIPs(cdnRDD.repartition(1))
//每個視頻獨立ip數
// videoIPs(cdnRDD.repartition(1))
//每小時流量
hourPoor(cdnRDD.repartition(1))
}
/**
* 獨立ip數
*/
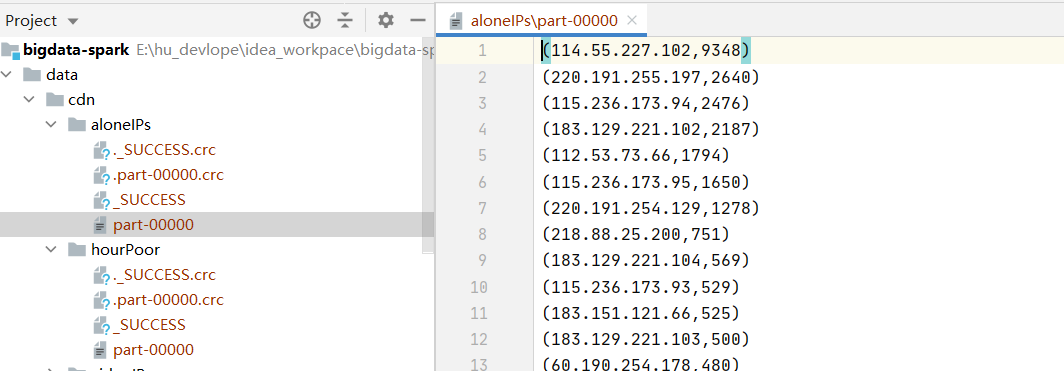
def aloneIPs(cdnRDD: RDD[String]) = {
//匹配ip地址
val IPPattern = "((?:(?:25[0-5]|2[0-4]\\d|((1\\d{2})|([1-9]?\\d)))\\.){3}(?:25[0-5]|2[0-4]\\d|((1\\d{2})|([1-9]?\\d))))".r
val ipnums = cdnRDD
.flatMap(x => (IPPattern findFirstIn x))
.map(y => (y,1))
.reduceByKey(_+_)
.sortBy(_._2,false)
ipnums.saveAsTextFile("data/cdn/aloneIPs")
}
/**
* 視頻獨立ip數
*/
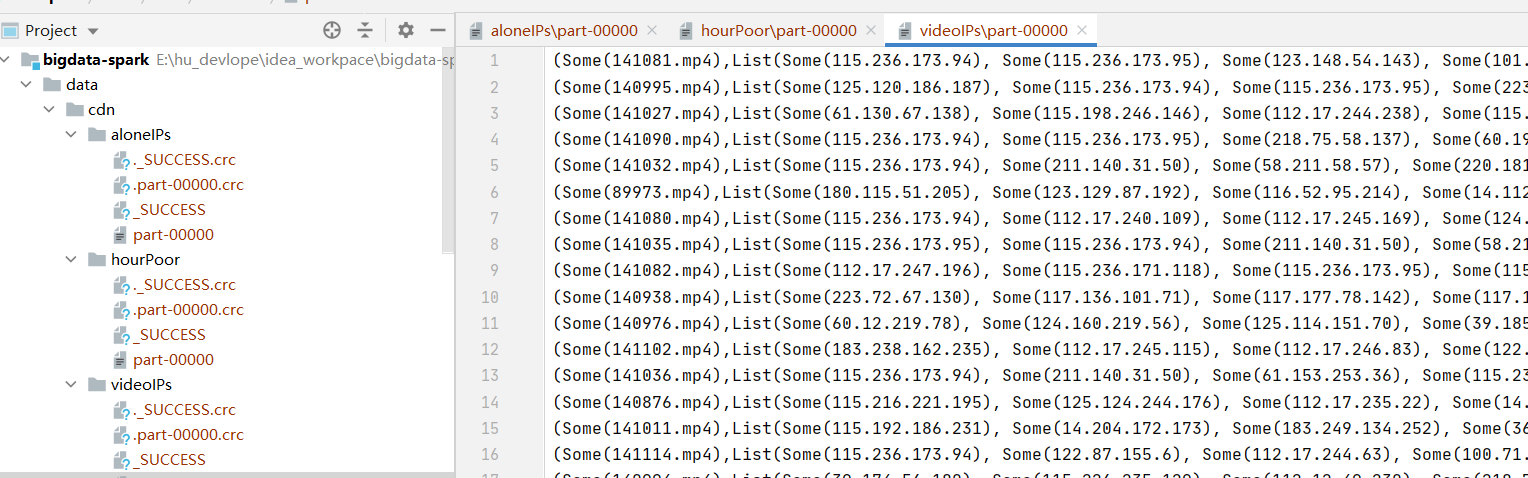
def videoIPs(cdnRDD: RDD[String]) = {
//匹配 http 回應碼和請求資料大小
val httpSizePattern = ".*\\s(200|206|304)\\s([0-9]+)\\s.*".r
//[15/Feb/2017:11:17:13 +0800] 匹配 2017:11 按每小時播放量統計
val timePattern = ".*(2017):([0-9]{2}):[0-9]{2}:[0-9]{2}.*".r
import scala.util.matching.Regex
// Entering paste mode (ctrl-D to finish)
def isMatch(pattern: Regex, str: String) = {
str match {
case pattern(_*) => true
case _ => false
}
}
def getTimeAndSize(line: String) = {
var res = ("", 0L)
try {
val httpSizePattern(code, size) = line
val timePattern(year, hour) = line
res = (hour, size.toLong)
} catch {
case ex: Exception => ex.printStackTrace()
}
res
}
val IPPattern = "((?:(?:25[0-5]|2[0-4]\\d|((1\\d{2})|([1-9]?\\d)))\\.){3}(?:25[0-5]|2[0-4]\\d|((1\\d{2})|([1-9]?\\d))))".r
val videoPattern = "([0-9]+).mp4".r
val res = cdnRDD
.filter(x => x.matches(".*([0-9]+)\\.mp4.*"))
.map(x => (videoPattern findFirstIn x toString,IPPattern findFirstIn x toString))
.aggregateByKey(List[String]())(
(lst, str) => (lst :+ str),
(lst1, lst2) => (lst1 ++ lst2)
)
.mapValues(_.distinct)
.sortBy(_._2.size,false)
res.saveAsTextFile("data/cdn/videoIPs")
}
/**
* 一天中每個小時的流量
*
*/
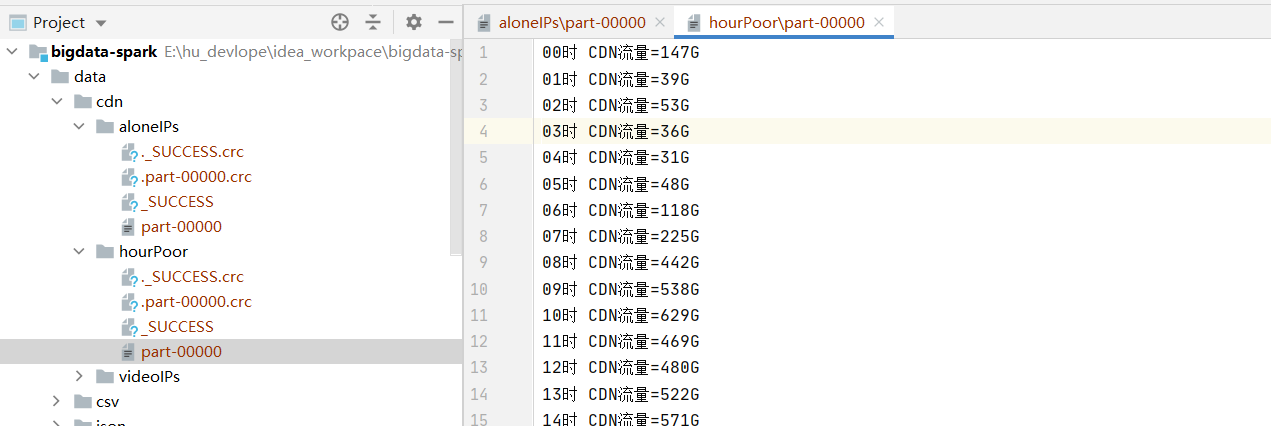
def hourPoor(cdnRDD: RDD[String]) = {
val httpSizePattern = ".*\\s(200|206|304)\\s([0-9]+)\\s.*".r
val timePattern = ".*(2017):([0-9]{2}):[0-9]{2}:[0-9]{2}.*".r
import scala.util.matching.Regex
def isMatch(pattern: Regex, str: String) = {
str match {
case pattern(_*) => true
case _ => false
}
}
def getTimeAndSize(line: String) = {
var res = ("", 0L)
try {
val httpSizePattern(code, size) = line
val timePattern(year, hour) = line
res = (hour, size.toLong)
} catch {
case ex: Exception => ex.printStackTrace()
}
res
}
cdnRDD
.filter(x=>isMatch(httpSizePattern,x))
.filter(x=>isMatch(timePattern,x))
.map(x=>getTimeAndSize(x))
.groupByKey()
.map(x=>(x._1,x._2.sum))
.sortByKey()
.map(x=>x._1+"時 CDN流量="+x._2/(102424*1024)+"G")
.saveAsTextFile("data/cdn/hourPoor")
}
}
運行結果截圖:
4. 廣告曝光分析案例
假設點擊日志檔案(click.log)和曝光日志imp.log, 中每行記錄格式如下
//點擊日志
INFO 2019-09-01 00:29:53 requestURI:/click?app=1&p=1&adid=18005472&industry=469&adid=31
INFO 2019-09-01 00:30:31 requestURI:/click?app=2&p=1&adid=18005472&industry=469&adid=31
INFO 2019-09-01 00:31:03 requestURI:/click?app=1&p=1&adid=18005472&industry=469&adid=32
INFO 2019-09-01 00:31:51 requestURI:/click?app=1&p=1&adid=18005472&industry=469&adid=33
//曝光日志
INFO 2019-09-01 00:29:53 requestURI:/imp?app=1&p=1&adid=18005472&industry=469&adid=31
INFO 2019-09-01 00:29:53 requestURI:/imp?app=1&p=1&adid=18005472&industry=469&adid=31
INFO 2019-09-01 00:29:53 requestURI:/imp?app=1&p=1&adid=18005472&industry=469&adid=34
用Spark-Core實作統計每個adid的曝光數與點擊數,思路較簡單,直接上代碼
代碼:
package com.hoult.work
import org.apache.spark.sql.SparkSession
object AddLog {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local[*]")
.appName(this.getClass.getCanonicalName)
.getOrCreate()
val sc = spark.sparkContext
val clickRDD = sc.textFile("data/click.log")
val impRDD = sc.textFile("data/imp.log")
val clickRes = clickRDD.map{line => {
val arr = line.split("\\s+")
val adid = arr(3).substring(arr(3).lastIndexOf("=") + 1)
(adid, 1)
}}.reduceByKey(_ + _)
val impRes = impRDD.map { line =>
val arr = line.split("\\s+")
val adid = arr(3).substring(arr(3).lastIndexOf("=") + 1)
(adid, 1)
}.reduceByKey(_ + _)
//保存到hdfs
clickRes.fullOuterJoin(impRes)
.map(x => x._1 + "," + x._2._1.getOrElse(0) + "," + x._2._2.getOrElse(0))
.repartition(1)
// .saveAsTextFile("hdfs://linux121:9000/data/")
.saveAsTextFile("data/add_log")
sc.stop()
}
}
分析:共有兩次shuffle, fulljon可以修改為union + reduceByKey,將shuffle減少到一次
5.使用spark-sql完成下面的轉換
A表有三個欄位:ID、startdate、enddate,有3條資料:
1 2019-03-04 2020-02-03
2 2020-04-05 2020-08-04
3 2019-10-09 2020-06-11
寫SQL(需要SQL和DSL)將以上資料變化為:
2019-03-04 2019-10-09
2019-10-09 2020-02-03
2020-02-03 2020-04-05
2020-04-05 2020-06-11
2020-06-11 2020-08-04
2020-08-04 2020-08-04
分析:觀察,可以得到,第一列實際上是startdate 和 enddate兩列疊加的結果,而第二列是下一個,可以用lead
視窗函式
代碼如下:
package com.hoult.work
import org.apache.spark.sql.{DataFrame, SparkSession}
object DataExchange {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("DateSort")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("warn")
// 原資料
val tab = List((1, "2019-03-04", "2020-02-03"),(2, "2020-04-05", "2020-08-04"),(3, "2019-10-09", "2020-06-11"))
val df: DataFrame = spark.createDataFrame(tab).toDF("ID", "startdate", "enddate")
val dateset: DataFrame = df.select("startdate").union(df.select("enddate"))
dateset.createOrReplaceTempView("t")
val result: DataFrame = spark.sql(
"""
|select tmp.startdate, nvl(lead(tmp.startdate) over(partition by col order by tmp.startdate), startdate) enddate from
|(select "1" col, startdate from t) tmp
|""".stripMargin)
result.show()
}
}
運行結果:

吳邪,小三爺,混跡于后臺,大資料,人工智能領域的小菜鳥,
更多請關注

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/255098.html
標籤:其他