時間序列及其預測是日常作業中建模,分析,預測的重要組成部分,本系列我們將從0開始介紹時間序列的含義,模型及其分析,本篇為第一部分,我們主要介紹時間序列,與其常用的預測模型,
時間序列定義:
時間序列是按照一定的時間間隔排列的一組資料,其時間間隔可以是任意的時間單位,如小時、日、周月等,比如,每天某產品的用戶數量,每個月的銷售額,這些資料形成了以一定時間間隔的資料,
通過對這些時間序列的分析,從中發現和揭示現象發展變化的規律,并將這些知識和資訊用于預測,比如銷售量是上升還是下降,銷售量是否與季節有關,是否可以通過現有的資料預測未來一年的銷售額是多少等,
對于時間序列的預測,由于很難確定它與其他變數之間的關系,這時我們就不能用回歸去預測,而應使用時間序列方法進行預測,
采用時間序列分析進行預測時需要一系列的模型,這種模型稱為時間序列模型,
時間序列預測模型與方法
注:本部分只關注相關模型與分析的方法,模型的選擇,調參與優化會放在后續文章中詳細講解
原始資料
本文所使用原始資料與代碼,可以在公眾號:Smilecoc的雜貨鋪 中回復“時間序列”獲取,可直接掃描文末二維碼關注!
樸素法
樸素法就是預測值等于實際觀察到的最后一個值,它假設資料是平穩且沒有趨勢性與季節性的,通俗來說就是以后的預測值都等于最后的值,
這種方法很明顯適用情況極少,所以我們重點通過這個方法來熟悉一下資料可視化與模型的評價及其相關代碼,
#樸素法
dd = np.asarray(train['Count'])#訓練組資料
y_hat = test.copy()#測驗組資料
y_hat['naive'] = dd[len(dd) - 1]#預測組資料
#資料可視化
plt.figure(figsize=(12, 8))
plt.plot(train.index, train['Count'], label='Train')
plt.plot(test.index, test['Count'], label='Test')
plt.plot(y_hat.index, y_hat['naive'], label='Naive Forecast')
plt.legend(loc='best')
plt.title("Naive Forecast")
plt.show()
得到結果:
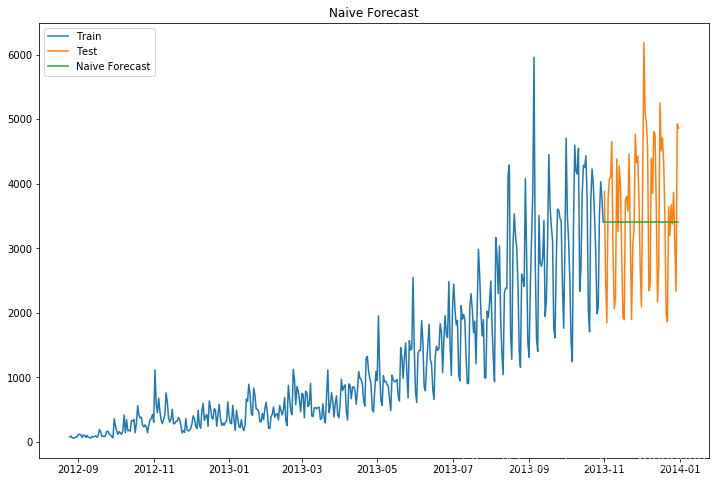
我們通過計算均方根誤差,檢查模型在測驗資料集上的準確率,
其中均方根誤差(RMSE)是各資料偏離真實值的距離平方和的平均數的開方
#計算均方根誤差RMSE
from sklearn.metrics import mean_squared_error
from math import sqrt
# mean_squared_error求均方誤差
rmse = sqrt(mean_squared_error(test['Count'], y_hat['naive']))
print(rmse)
得到均方根誤差為1053
簡單平均法
簡單平均法就是預測的值為之前過去所有值的平均.當然這不會很準確,但這種預測方法在某些情況下效果是最好的,
#簡單平均法
y_hat_avg = test.copy()
y_hat_avg['avg_forecast'] = train['Count'].mean()
其后續可視化與模型效果評估方法與上述一致,這里不再贅述,需要詳細代碼可以查看相關原始碼,得到RMSE值為2637
移動平均法
我們經常會遇到這種資料集,比如價格或銷售額某段時間大幅上升或下降,如果我們這時用之前的簡單平均法,就得使用所有先前資料的平均值,但在這里使用之前的所有資料是說不通的,因為用開始階段的價格值會大幅影響接下來日期的預測值,因此,我們只取最近幾個時期的價格平均值,很明顯這里的邏輯是只有最近的值最要緊,這種用某些視窗期計算平均值的預測方法就叫移動平均法,
#移動平均法
y_hat_avg = test.copy()
#利用時間窗函式rolling求平均值u
y_hat_avg['moving_avg_forecast'] = train['Count'].rolling(60).mean().iloc[-1]
其后續可視化與模型效果評估方法與上述一致,這里不再贅述,需要詳細代碼可以查看相關原始碼,得到RMSE值為1121
指數平滑法
在做時序預測時,一個顯然的思路是:認為離著預測點越近的點,作用越大,比如我這個月體重100斤,去年某個月120斤,顯然對于預測下個月體重而言,這個月的資料影響力更大些,假設隨著時間變化權重以指數方式下降——最近為0.8,然后0.8**2,0.8**3…,最終年代久遠的資料權重將接近于0,將權重按照指數級進行衰減,這就是指數平滑法的基本思想,
指數平滑法有幾種不同形式:一次指數平滑法針對沒有趨勢和季節性的序列,二次指數平滑法針對有趨勢但沒有季節性的序列,三次指數平滑法針對有趨勢也有季節性的序列,“
所有的指數平滑法都要更新上一時間步長的計算結果,并使用當前時間步長的資料中包含的新資訊,它們通過”混合“新資訊和舊資訊來實作,而相關的新舊資訊的權重由一個可調整的引數來控制,
一次指數平滑
一次指數平滑法的遞推關系如下:
s i = α x i + ( 1 ? α ) s i ? 1 , 其 中 0 ≤ α ≤ 1 s_{i}=\alpha x_{i}+(1-\alpha)s_{i-1},其中 0 \leq \alpha \leq 1 si?=αxi?+(1?α)si?1?,其中0≤α≤1
其中, s i s_{i} si?是時間步長i(理解為第i個時間點)上經過平滑后的值, x i x_{i} xi? 是這個時間步長上的實際資料, α \alpha α可以是0和1之間的任意值,它控制著新舊資訊之間的平衡:當 α \alpha α 接近1,就只保留當前資料點;當 α \alpha α 接近0時,就只保留前面的平滑值(整個曲線都是平的),我們展開它的遞推關系式:
我們展開它的遞推關系式:
s
i
=
α
x
i
+
(
1
?
α
)
s
i
?
1
=
α
x
i
+
(
1
?
α
)
[
α
x
i
?
1
+
(
1
?
α
)
s
i
?
2
]
=
α
x
i
+
(
1
?
α
)
[
α
x
i
?
1
+
(
1
?
α
)
[
α
x
i
?
2
+
(
1
?
α
)
s
i
?
3
]
]
=
α
[
x
i
+
(
1
?
α
)
x
i
?
1
+
(
1
?
α
)
2
x
i
?
2
+
(
1
?
α
)
3
s
i
?
3
]
=
.
.
.
=
α
∑
j
=
0
i
(
1
?
α
)
j
x
i
?
j
\begin{aligned} s_{i}&=\alpha x_{i}+(1-\alpha)s_{i-1} \\ &=\alpha x_{i}+(1-\alpha)[\alpha x_{i-1}+(1-\alpha)s_{i-2}]\\ &=\alpha x_{i}+(1-\alpha)[\alpha x_{i-1}+(1-\alpha)[\alpha x_{i-2}+(1-\alpha)s_{i-3}]]\\ &=\alpha[x_{i}+(1-\alpha)x_{i-1}+(1-\alpha)^{2}x_{i-2}+(1-\alpha)^{3}s_{i-3}]\\ &=... \\ &=\alpha\sum_{j=0}^{i}(1-\alpha)^{j}x_{i-j} \end{aligned}
si??=αxi?+(1?α)si?1?=αxi?+(1?α)[αxi?1?+(1?α)si?2?]=αxi?+(1?α)[αxi?1?+(1?α)[αxi?2?+(1?α)si?3?]]=α[xi?+(1?α)xi?1?+(1?α)2xi?2?+(1?α)3si?3?]=...=αj=0∑i?(1?α)jxi?j??
可以看出,在指數平滑法中,所有先前的觀測值都對當前的平滑值產生了影響,但它們所起的作用隨著引數 α \alpha α 的冪的增大而逐漸減小,那些相對較早的觀測值所起的作用相對較小,同時,稱α為記憶衰減因子可能更合適——因為α的值越大,模型對歷史資料“遺忘”的就越快,從某種程度來說,指數平滑法就像是擁有無限記憶(平滑視窗足夠大)且權值呈指數級遞減的移動平均法,一次指數平滑所得的計算結果可以在資料集及范圍之外進行擴展,因此也就可以用來進行預測,預測方式為:
x i + h = s i x_{i+h}=s_{i} xi+h?=si?
s i s_{i} si?是最后一個已經算出來的值,h等于1代表預測的下一個值,
我們可以通過statsmodels中的時間序列模型進行指數平滑建模,官方檔案地址為:
https://www.statsmodels.org/stable/generated/statsmodels.tsa.holtwinters.SimpleExpSmoothing.html
具體代碼如下:
#一次指數平滑
from statsmodels.tsa.api import SimpleExpSmoothing
y_hat_avg = test.copy()
fit = SimpleExpSmoothing(np.asarray(train['Count'])).fit(smoothing_level=0.6, optimized=False)
y_hat_avg['SES'] = fit.forecast(len(test))
之后同樣進行資料可視化并查看模型效果
plt.figure(figsize=(16, 8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['SES'], label='SES')
plt.legend(loc='best')
plt.show()
可視化結果為:
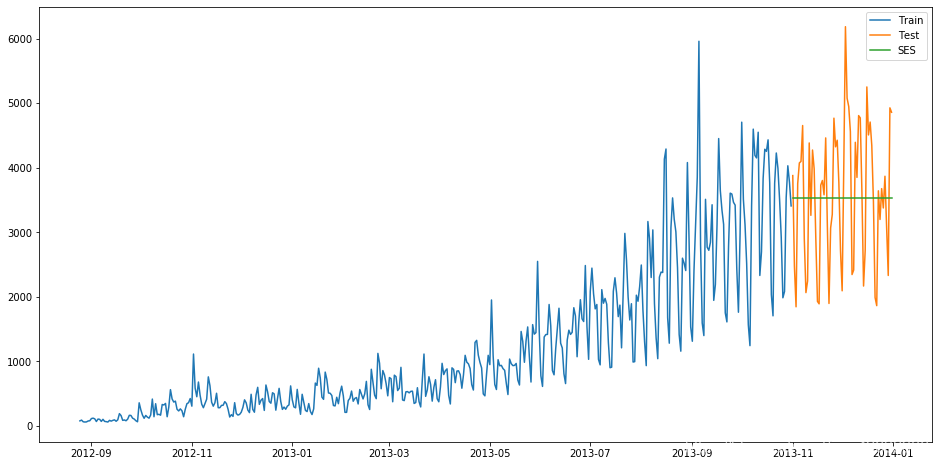
RMSE結果為1040
二次指數平滑
在介紹二次指數平滑前介紹一下趨勢的概念,
趨勢,或者說斜率的定義很簡單:
b
=
Δ
y
/
Δ
x
b=Δy/Δx
b=Δy/Δx,其中
Δ
x
Δx
Δx為兩點在x坐標軸的變化值,所以對于一個序列而言,相鄰兩個點的
Δ
x
=
1
Δx=1
Δx=1,因此
b
=
Δ
y
=
y
(
x
)
?
y
(
x
?
1
)
b=Δy=y(x)-y(x-1)
b=Δy=y(x)?y(x?1), 除了用點的增長量表示,也可以用二者的比值表示趨勢,比如可以說一個物品比另一個貴20塊錢,等價地也可以說貴了5%,前者稱為可加的(addtive),后者稱為可乘的(multiplicative),在實際應用中,可乘的模型預測穩定性更佳,但是為了便于理解,我們在這以可加的模型為例進行推導,
指數平滑考慮的是資料的baseline,二次指數平滑在此基礎上將趨勢作為一個額外考量,保留了趨勢的詳細資訊,即我們保留并更新兩個量的狀態:平滑后的信號和平滑后的趨勢,公式如下:
基準等式
s
i
=
α
x
i
+
(
1
?
α
)
(
s
i
?
1
+
t
i
?
1
)
s_{i}=\alpha x_{i}+(1-\alpha)(s_{i-1}+t_{i-1})
si?=αxi?+(1?α)(si?1?+ti?1?)
趨勢等式
t
i
=
β
(
s
i
?
s
i
?
1
)
+
(
1
?
β
)
t
i
?
1
t_{i}=\beta (s_{i}-s_{i-1})+(1-\beta)t_{i-1}
ti?=β(si??si?1?)+(1?β)ti?1?
第二個等式描述了平滑后的趨勢,當前趨勢的未平滑“值”( t i t_{i} ti? )是當前平滑值( s i s_{i} si? )和上一個平滑值( s i ? 1 s_{i-1} si?1?)的差;也就是說,當前趨勢告訴我們在上一個時間步長里平滑信號改變了多少,要想使趨勢平滑,我們用一次指數平滑法對趨勢進行處理,并使用引數 β \beta β (理解:對 t i t_{i} ti? 的處理類似于一次平滑指數法中的 s i s_{i} si? ,即對趨勢也需要做一個平滑,臨近的趨勢權重大),
為獲得平滑信號,我們像上次那樣進行一次混合,但要同時考慮到上一個平滑信號及趨勢,假設單個步長時間內保持著上一個趨勢,那么第一個等式的最后那項就可以對當前平滑信號進行估計,
若要利用該計算結果進行預測,就取最后那個平滑值,然后每增加一個時間步長就在該平滑值上增加一次最后那個平滑趨勢:
x i + h = s i + h t i x_{i+h}=s_{i}+ht_{i} xi+h?=si?+hti?
之后使用二次指數平滑進行預測:
from statsmodels.tsa.api import Holt
y_hat_avg = test.copy()
fit = Holt(np.asarray(train['Count'])).fit(smoothing_level=0.3, smoothing_slope=0.1)
y_hat_avg['Holt_linear'] = fit.forecast(len(test))
結果如圖:
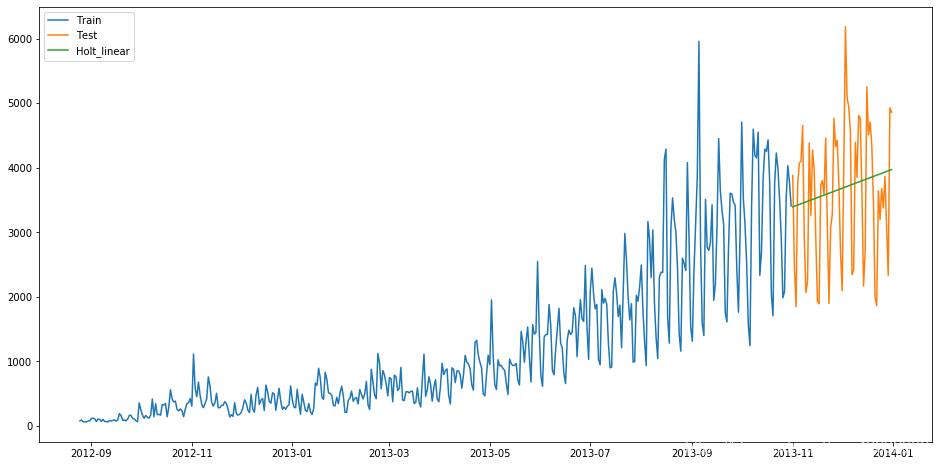
得到對應的RMSE為1033
三次指數平滑
在應用這種演算法前,我們先介紹一個新術語,假如有家酒店坐落在半山腰上,夏季的時候生意很好,顧客很多,但每年其余時間顧客很少,因此,每年夏季的收入會遠高于其它季節,而且每年都是這樣,那么這種重復現象叫做“季節性”(Seasonality),如果資料集在一定時間段內的固定區間內呈現相似的模式,那么該資料集就具有季節性,
二次指數平滑考慮了序列的基數和趨勢,三次就是在此基礎上增加了一個季節分量,類似于趨勢分量,對季節分量也要做指數平滑,比如預測下一個季節第3個點的季節分量時,需要指數平滑地考慮當前季節第3個點的季節分量、上個季節第3個點的季節分量…等等,詳細的有下述公式(累加法):
s i = α ( x i ? p i ? k ) + ( 1 ? α ) ( s i ? 1 + t i ? 1 ) t i = β ( s i ? s i ? 1 ) + ( 1 ? β ) t i ? 1 p i = γ ( x i ? s i ) + ( 1 ? γ ) p i ? k \begin{aligned} s_{i}&=\alpha (x_{i}-p_{i-k})+(1-\alpha)(s_{i-1}+t_{i-1}) \\ t_{i} &=\beta (s_{i}-s_{i-1})+(1-\beta)t_{i-1}\\ p_{i}&=\gamma (x_{i}-s_{i})+(1-\gamma)p_{i-k} \end{aligned} si?ti?pi??=α(xi??pi?k?)+(1?α)(si?1?+ti?1?)=β(si??si?1?)+(1?β)ti?1?=γ(xi??si?)+(1?γ)pi?k??
其中, p i p_{i} pi? 是指“周期性”部分,預測公式如下:
x i + h = s i + h t i + p i ? k + h x_{i+h}=s_{i}+ht_{i}+p_{i-k+h} xi+h?=si?+hti?+pi?k+h?
k 是這個周期的長度,
在使用二次平滑模型與三次平滑模型前,我們可以使用sm.tsa.seasonal_decompose分解時間序列,可以得到以下分解圖形——從上到下依次是原始資料、趨勢資料、周期性資料、隨機變數(殘差值)
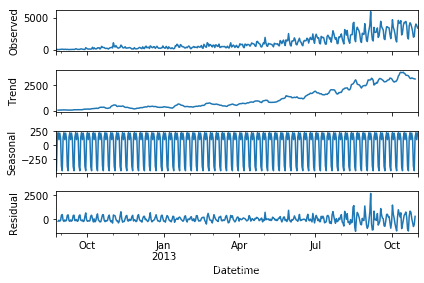
根據分析圖形和資料可以確定對應的季節引數
具體代碼為:
#三次指數平滑
from statsmodels.tsa.api import ExponentialSmoothing
y_hat_avg = test.copy()
fit1 = ExponentialSmoothing(np.asarray(train['Count']), seasonal_periods=7, trend='add', seasonal='add', ).fit()
y_hat_avg['Holt_Winter'] = fit1.forecast(len(test))
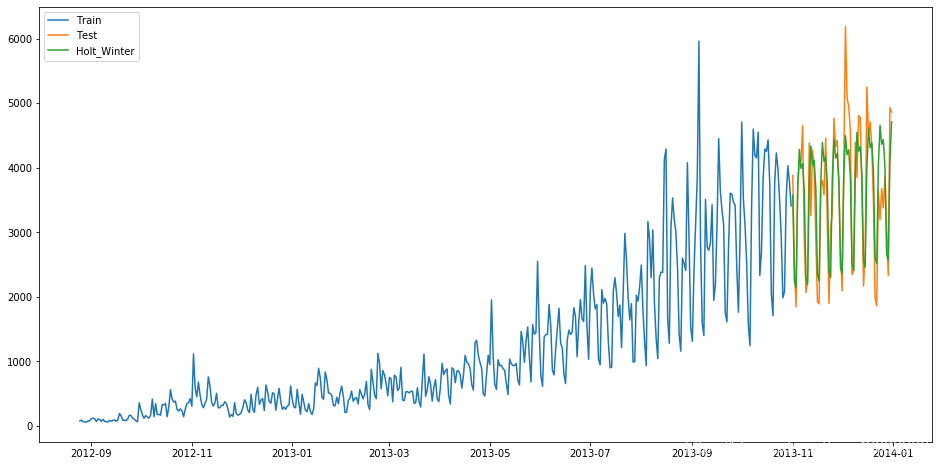
得到的RMSE為575,我們可以看到趨勢和季節性的預測準確度都很高,你可以試著調整引數來優化這個模型,
AR模型
AR(Auto Regressive Model)自回歸模型是線性時間序列分析模型中最簡單的模型,通過自身前面部分的資料與后面部分的資料之間的相關關系(自相關)來建立回歸方程,從而可以進行預測或者分析,服從p階的自回歸方程運算式如下:
x t = ? 1 x t ? 1 + ? 2 x t ? 2 + ? + ? p x t ? p + μ t x_{t}=\phi_{1}x_{t-1}+\phi_{2}x_{t-2}+\cdots+\phi_{p}x_{t-p}+\mu_{t} xt?=?1?xt?1?+?2?xt?2?+?+?p?xt?p?+μt?
表示為 A R ( p ) AR(p) AR(p),,其中, μ t \mu_{t} μt?表示白噪聲,是時間序列中的數值的隨機波動,但是這些波動會相互抵消,最終是0, ? \phi ?表示自回歸系數,
所以當只有一個時間記錄點時,稱為一階自回歸程序,即AR(1),其運算式為:
x
t
=
?
1
x
t
?
1
+
μ
t
x_{t}=\phi_{1}x_{t-1}+\mu_{t}
xt?=?1?xt?1?+μt?
利用Python建立AR模型一般會用到我們之后會說到的ARIMA模型(AR模型中的p是ARIMA模型中的引數之一,只要將其他的引數設定為0即為AR模型),您可以先閱讀后續ARIMA模型的內容并參考檔案中的代碼查看具體的內容
MA模型
MA(Moving Average Model)移動平均模型通過將一段時間序列中白噪聲(誤差)進行加權和,可以得到移動平均方程,如下模型為q階移動平均程序,表示為MA(q),
x t = μ + μ t + θ 1 μ t ? 1 + θ 2 μ t ? 2 + ? + θ q μ t ? q x_{t}=\mu+\mu_{t}+\theta_{1}\mu_{t-1}+\theta_{2}\mu_{t-2}+\cdots+\theta_{q}\mu_{t-q} xt?=μ+μt?+θ1?μt?1?+θ2?μt?2?+?+θq?μt?q?
其中 x t x_{t} xt?表示t期的值,當期的值由前q期的誤差值來決定, μ μ μ值是常數項,相當于普通回歸中的截距項, μ t \mu_{t} μt?是當期的隨機誤差,MA模型的核心思想是每一期的隨機誤差都會影響當期值,把前q期的所有誤差加起來就是對t期值的影響,
同樣,利用Python建立MA模型一般會用到我們之后會說到的ARIMA模型,您可以先閱讀后續ARIMA模型的內容并參考檔案中的代碼查看具體的內容
ARMA模型
ARMA(Auto Regressive and Moving Average Model)自回歸移動平均模型是與自回歸和移動平均模型兩部分組成,所以可以表示為ARMA(p, q),p是自回歸階數,q是移動平均階數,
x t = ? 1 x t ? 1 + ? 2 x t ? 2 + ? + ? p x t ? p + μ t + θ 1 μ t ? 1 + θ 2 μ t ? 2 + ? + θ q μ t ? q x_{t}=\phi_{1}x_{t-1}+\phi_{2}x_{t-2}+\cdots+\phi_{p}x_{t-p}+\mu_{t}+\theta_{1}\mu_{t-1}+\theta_{2}\mu_{t-2}+\cdots+\theta_{q}\mu_{t-q} xt?=?1?xt?1?+?2?xt?2?+?+?p?xt?p?+μt?+θ1?μt?1?+θ2?μt?2?+?+θq?μt?q?
從式子中就可以看出,自回歸模型結合了兩個模型的特點,其中,AR可以解決當前資料與后期資料之間的關系,MA則可以解決隨機變動也就是噪聲的問題,
ARIMA模型
ARIMA(Auto Regressive Integrate Moving Average Model)差分自回歸移動平均模型是在ARMA模型的基礎上進行改造的,ARMA模型是針對t期值進行建模的,而ARIMA是針對t期與t-d期之間差值進行建模,我們把這種不同期之間做差稱為差分,這里的d是幾就是幾階差分,ARIMA模型也是基于平穩的時間序列的或者差分化后是穩定的,另外前面的幾種模型都可以看作ARIMA的某種特殊形式,表示為ARIMA(p, d, q),p為自回歸階數,q為移動平均階數,d為時間成為平穩時所做的差分次數,也就是Integrate單詞的在這里的意思,
具體步驟如下:
x t = ? 1 w t ? 1 + ? 2 w t ? 2 + ? + ? p w t ? p + μ t + θ 1 μ t ? 1 + θ 2 μ t ? 2 + ? + θ q μ t ? q x_{t}=\phi_{1}w_{t-1}+\phi_{2}w_{t-2}+\cdots+\phi_{p}w_{t-p}+\mu_{t}+\theta_{1}\mu_{t-1}+\theta_{2}\mu_{t-2}+\cdots+\theta_{q}\mu_{t-q} xt?=?1?wt?1?+?2?wt?2?+?+?p?wt?p?+μt?+θ1?μt?1?+θ2?μt?2?+?+θq?μt?q?
上面公式中的 w t w_{t} wt?表示t期經過d階差分以后的結果,我們可以看到ARIMA模型的形式基本與ARMA的形式是一致的,只不過把 X X X換成了 w w w
使用ARIMA進行預測代碼如下:
from statsmodels.tsa.arima_model import ARIMA
ts_ARIMA= train['Count'].astype(float)
fit1 = ARIMA(ts_ARIMA, order=(7, 1, 4)).fit()
y_hat_ARIMA = fit1.predict(start="2013-11-1", end="2013-12-31", dynamic=True)
并畫出預測值與實際值圖形:
plt.figure(figsize=(16, 8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_ARIMA, label='ARIMA')
plt.legend(loc='best')
plt.show()
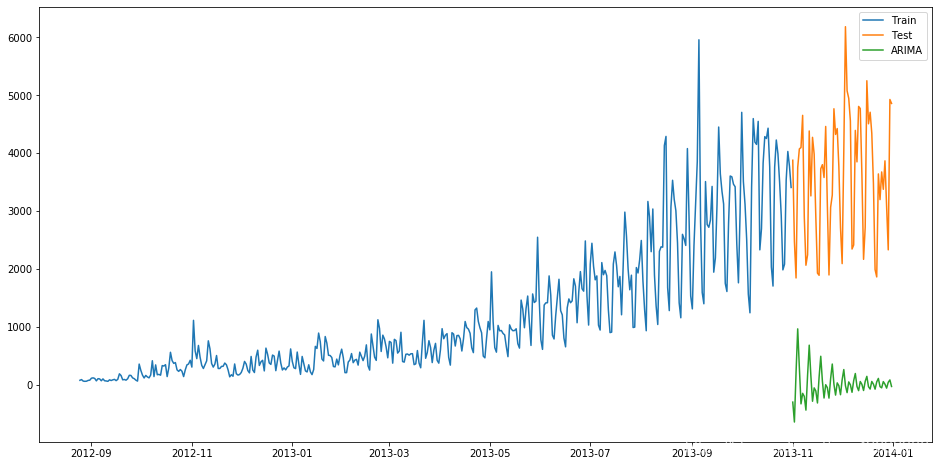
并計算RMSE:
from sklearn.metrics import mean_squared_error
from math import sqrt
rmse = sqrt(mean_squared_error(test['Count'],y_hat_ARIMA.to_frame()))
print(rmse)
得到對應的RMSE為3723
SARIMA模型
SARIMA季節性自回歸移動平均模型模型在ARIMA模型的基礎上添加了季節性的影響,結構引數有七個:SARIMA(p,d,q)(P,D,Q,s)
其中p,d,q分別為之前ARIMA模型中我們所說的p:趨勢的自回歸階數,d:趨勢差分階數,q:趨勢的移動平均階數,
P:季節性自回歸階數,
D:季節性差分階數,
Q:季節性移動平均階數,
s:單個季節性周期的時間步長數,
import statsmodels.api as sm
y_hat_avg = test.copy()
fit1 = sm.tsa.statespace.SARIMAX(train.Count, order=(2, 1, 4), seasonal_order=(0, 1, 1, 7)).fit()
y_hat_avg['SARIMA'] = fit1.predict(start="2013-11-1", end="2013-12-31", dynamic=True)
得到實際值與預測值如下:
plt.figure(figsize=(16, 8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['SARIMA'], label='SARIMA')
plt.legend(loc='best')
plt.show()
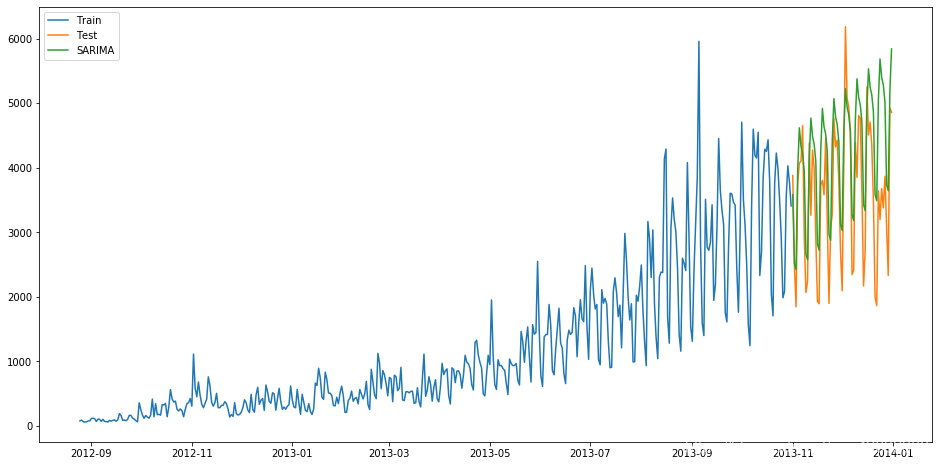
并計算RMSE:
from sklearn.metrics import mean_squared_error
from math import sqrt
rmse = sqrt(mean_squared_error(test['Count'], y_hat_avg['SARIMA']))
print(rmse)
結果為933
其他時間序列預測的模型還有SARIMAX模型(在ARIMA模型上加了季節性的因素),Prophet模型,ARCH模型,LSTM神經網路模型等,限于篇幅,感興趣的同學可以自行查看相關模型資料
在后續的文章中我們將講解如何確定資料的平穩性與資料預處理,為后續時間序列的建模做準備
參考文章:
https://www.analyticsvidhya.com/blog/2018/02/time-series-forecasting-methods/
https://blog.csdn.net/anshuai_aw1/article/details/82499095
相關代碼與資料可關注公眾號并回復:時間序列獲取

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/255167.html
標籤:其他
上一篇:第五次總結
下一篇:MySQL8安裝及配置教程