TCP進行擁塞控制的演算法有四種:
- 慢開始
- 擁塞避免
- 快重傳
- 快恢復
首先我們需要知道一個概念就是擁塞視窗cwnd和慢開始門限ssthresh和傳輸輪次,
- 擁塞視窗即為發送方的發送視窗,每次可以發送的資料量大小,擁塞視窗大小主要取決于網路的擁塞程度,最開始為1.
- 慢開始門限主要作用是起一個界定作用,當擁塞視窗大于慢開始門限后,就需要停止慢開始演算法,大部分都設定為16,具體原因不詳,
- 傳輸輪次就是一個往返時間RTT(非恒定),比如如果擁塞視窗是4,那么RTT就是發送4個報文段,并收到這四個報文段總共的時間,RTT也可以理解為一次發送接收總共時間,
一,慢開始
慢開始:
最開始發送資料時,由于不清楚網路的負載情況,所以如果立即把大量資料自己注入網路,那么就可能引發網路擁塞,
因此需要慢慢注入,即由小到大逐漸增大發送視窗
經過一個RTT時間,擁塞視窗翻一倍但是這個慢并不是指由小到大的速率慢,而是指最開始為1,然后再逐漸增加,
如下圖:
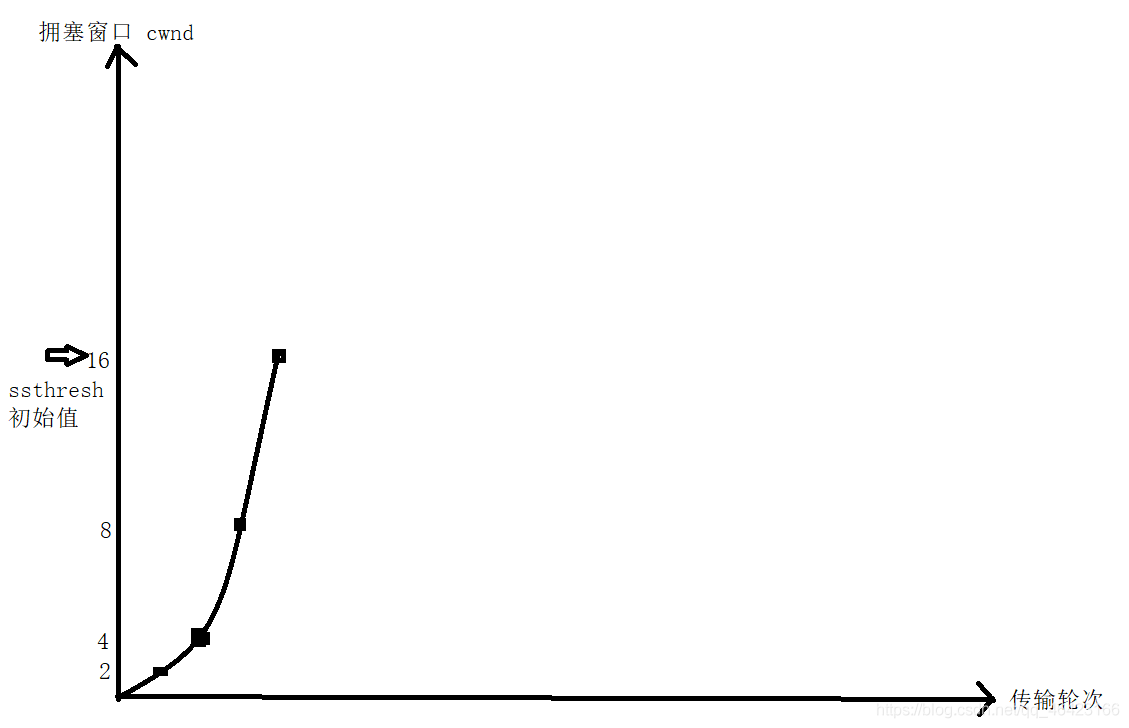
最開始的這一段即為慢開始,等到增加到16時,碰到了慢開始門限,然后就用到了擁塞避免演算法
因為慢開始的增長速率是指數級增長,速度很快,所以需要用慢開始門限加以限制,慢開始門限的用法:
- 當擁塞視窗 < 慢開始門限時,使用上述的慢開始演算法
- 當擁塞視窗 > 慢開始門限時,停止使用慢開始演算法而改用擁塞避免演算法
- 當擁塞視窗 = 慢開始門限時,即可以使用慢開始演算法也可以使用擁塞避免演算法
二,擁塞避免演算法
擁塞避免演算法:
這個地方是讓擁塞視窗緩慢增加,沒經過一個往返時間RTT,就把擁塞視窗加1,而不是成倍增加,
因此在擁塞避免階段就有“加法增大”的特點,擁塞視窗按線性規律緩慢增長,
如下圖:
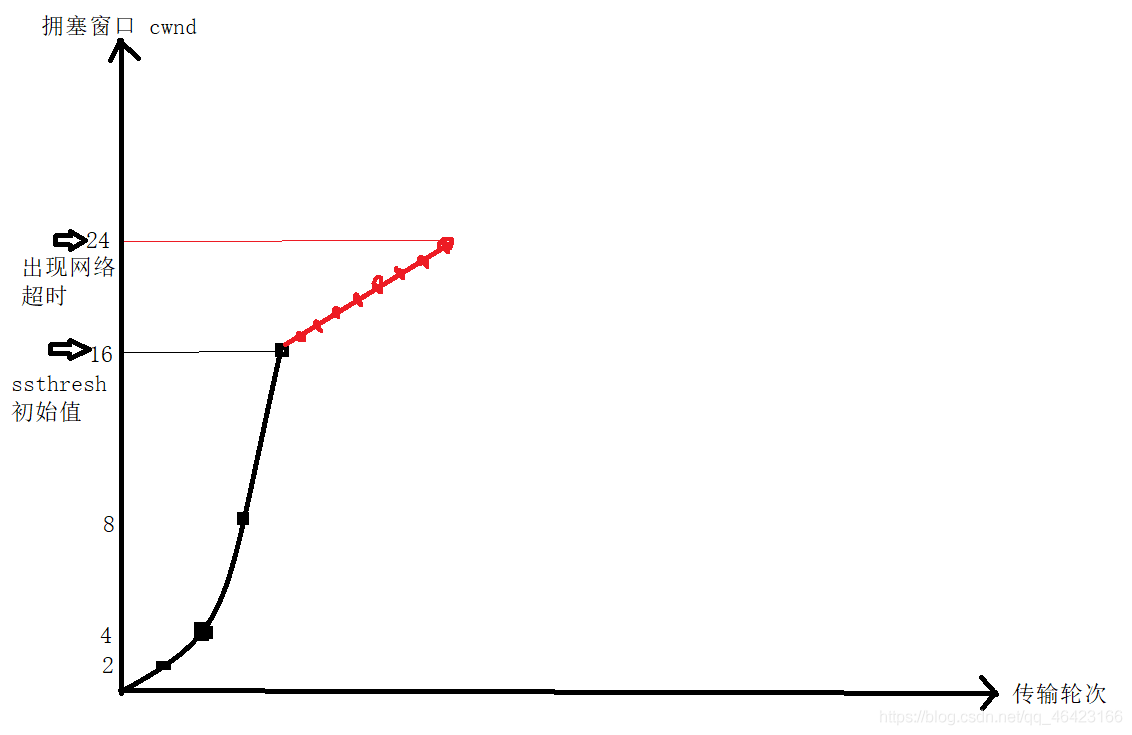
紅色這一部分就是擁塞避免演算法,每次擁塞視窗僅僅增加一個大小,當增加到一定大小時,就碰到了網路超時,即出現網路擁塞,
三,出現阻塞后調整
當出現阻塞之后,會調整慢開始門限ssthresh以及擁塞視窗的值:
新的慢開始門限的值:ssthresh=cwnd/2,
如上圖所示,此時cwnd已經增長到了24大小,所以此時ssthresh=24/2=12,擁塞視窗則再次變為1..
調整后的運行程序如下圖所示:
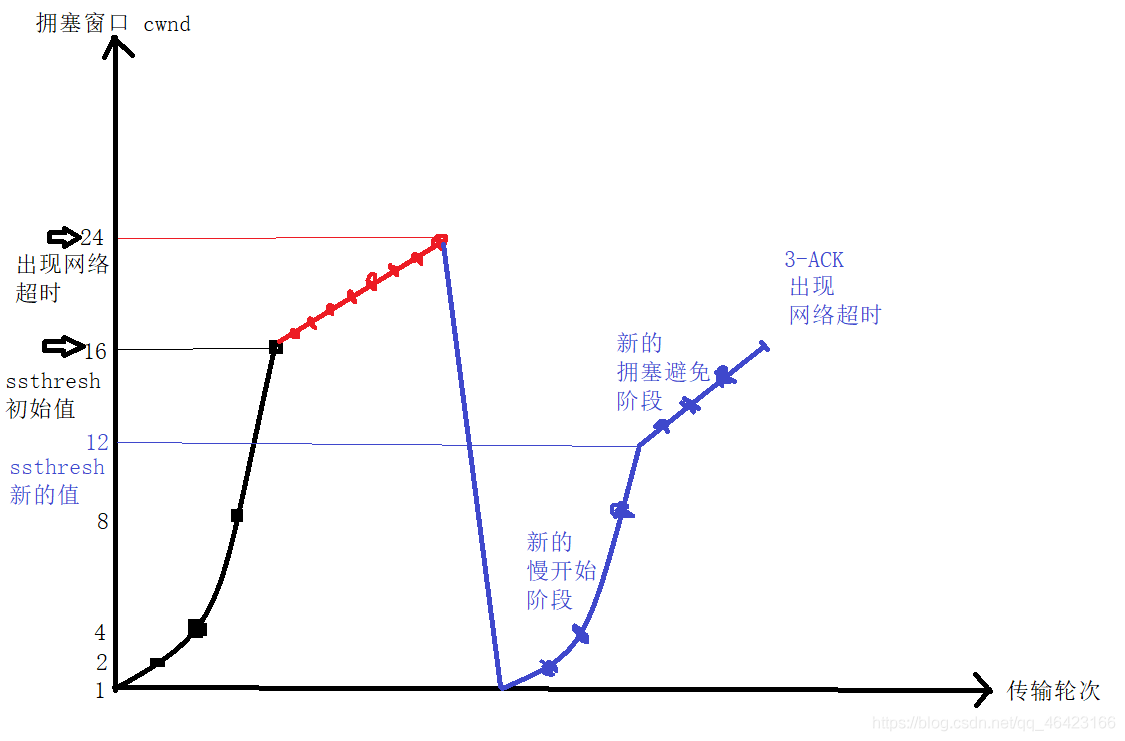
如上圖所示,當在24出現阻塞后,將cwnd變為了1,將ssthresh變為了12
然后在12之前依舊是進行慢開始演算法,在12之后進行擁塞避免演算法,直到16發生了3個ACK情況(這個后面講)又一次出現了網路阻塞,
上面三步就展示了普通情況下傳輸的方法以及調整
四,快重傳+快恢復
從上面可知,在16的時候又一次出現了擁塞,而這次擁塞出現的原因就是這3個ACK,這個也就是快重傳,
快重傳:
當發生包文丟失時,為了讓發送方盡早知道發生了個別報文段的丟失,因此立即發送確認,怎樣讓發送方知道是哪個報文段丟失的方法就是連讀發送三個確認,
如下圖所示:
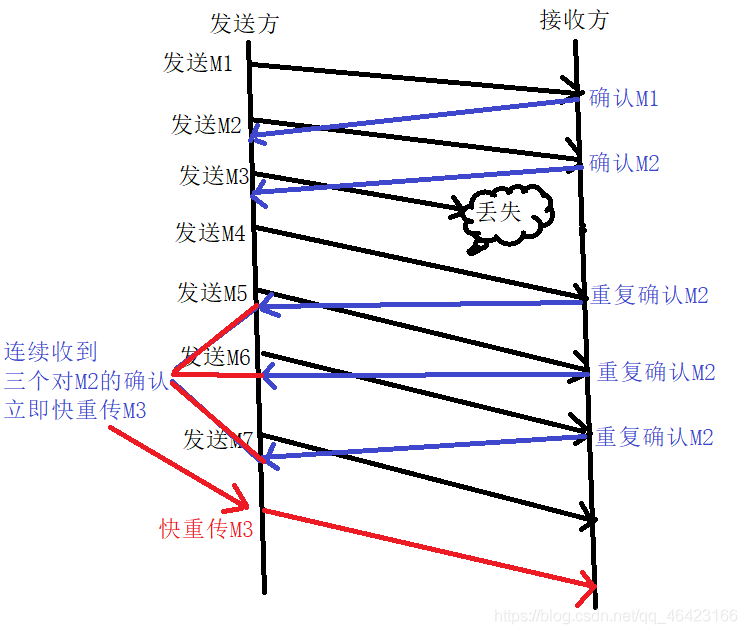
當丟失某個資料包時,連續發送三個確認,則發送方就知道某個包丟失了,然后立即啟動快重傳,
快恢復:
發送方知道現在只是丟失了個別的報文段,于是不執行慢開始,而是執行快恢復演算法,
新的慢開始門限的值:ssthresh=cwnd/2,
如上圖所示,此時新的cwnd已經增長到了16大小,所以此時ssthresh=16/2=8,擁塞視窗不是變為1,而是和門限值一樣,此時cwnd=ssthresh=8,然后開始執行擁塞避免演算法
如下圖所示:
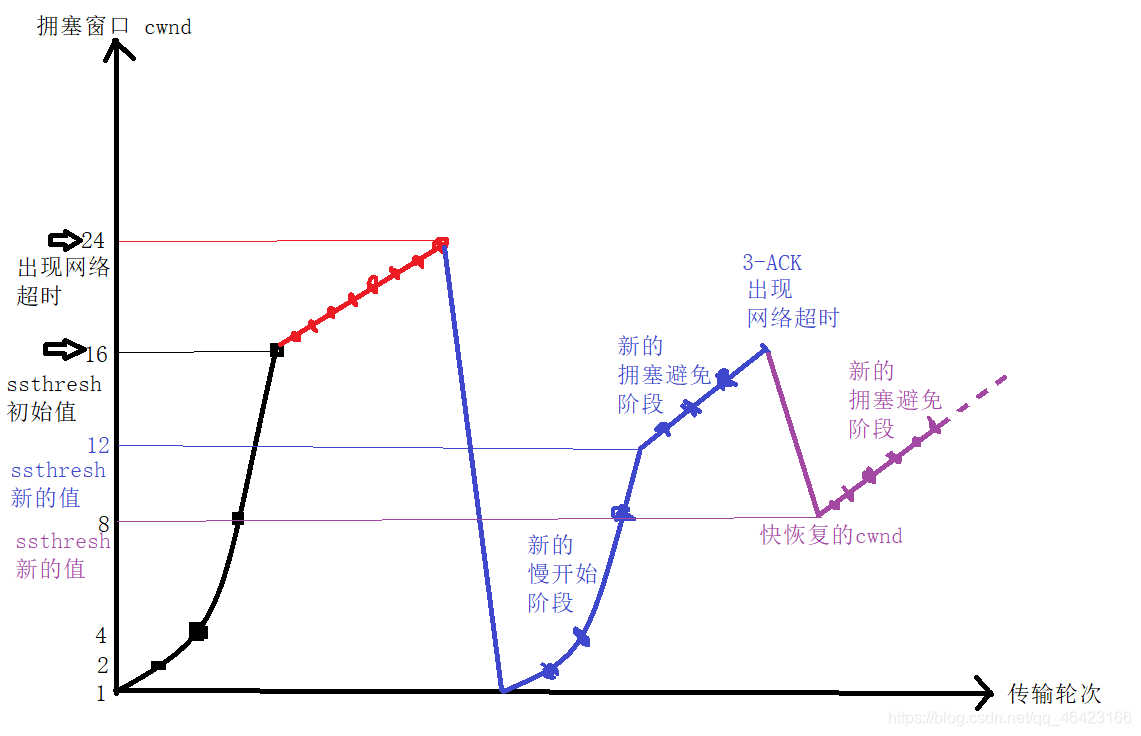
如上圖是怎樣判斷出現了丟包現象,以及出現丟包情況下進行快恢復的流程,
在擁塞避免階段,擁塞視窗時按照線性規律增大的,這通常稱為"加法增大"
而一旦出現超時或者3個重復的確認,就要把門限變為當前的一半,這個稱為”乘法減小“
最后一張流程圖表示TCP的擁塞控制流程圖
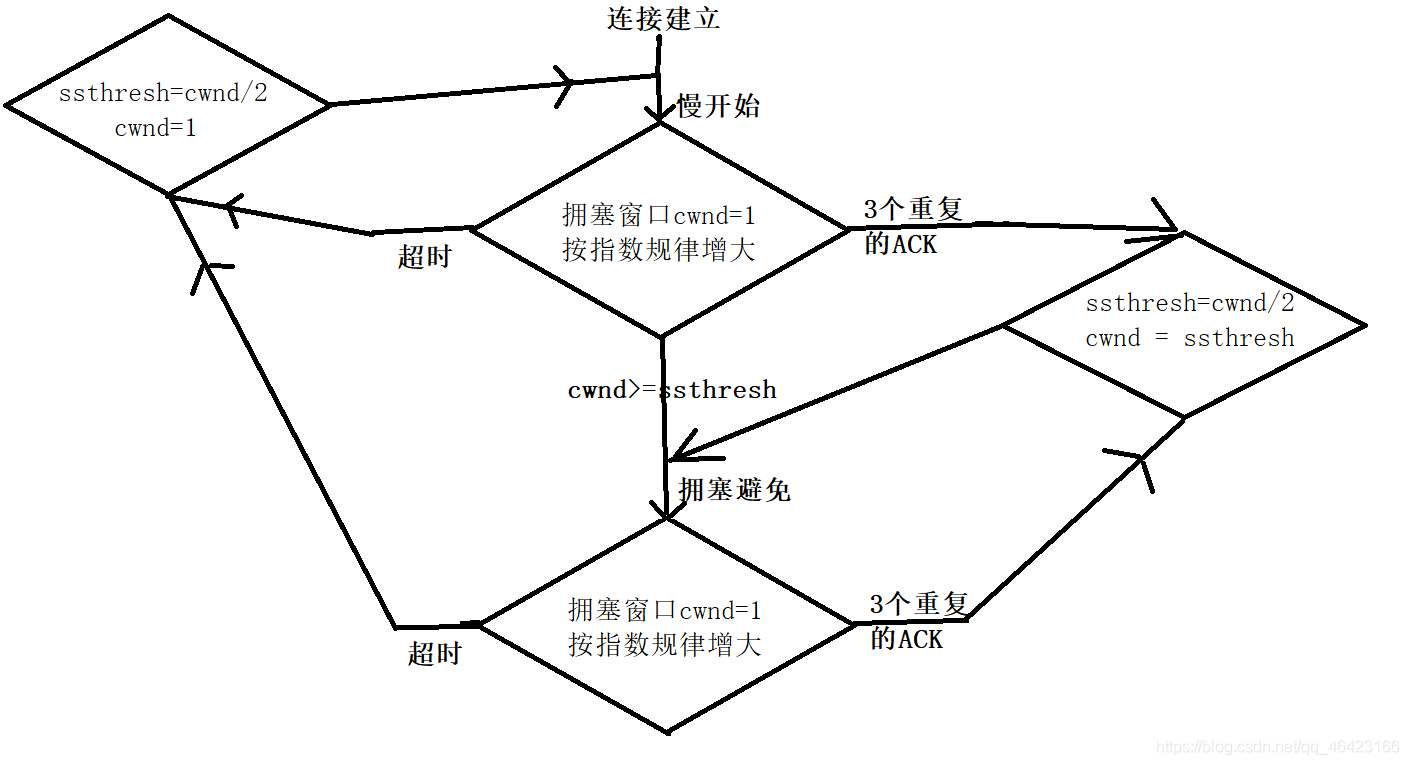
只要上面幾張圖都能夠理解,大概就知道了擁塞避免控制的方法,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/255213.html
標籤:其他
上一篇:常見排序演算法總結