本文主要對Facebook最近提出來的DeiT模型進行閱讀分析,

一、動機:DeiT解決什么問題?
現有的基于Transformer的分類模型ViT需要在海量資料上(JFT-300M,3億張圖片)進行預訓練,再在ImageNet資料集上進行fune-tuning,才能達到與CNN方法相當的性能,這需要非常大量的計算資源,這限制了ViT方法的進一步應用,
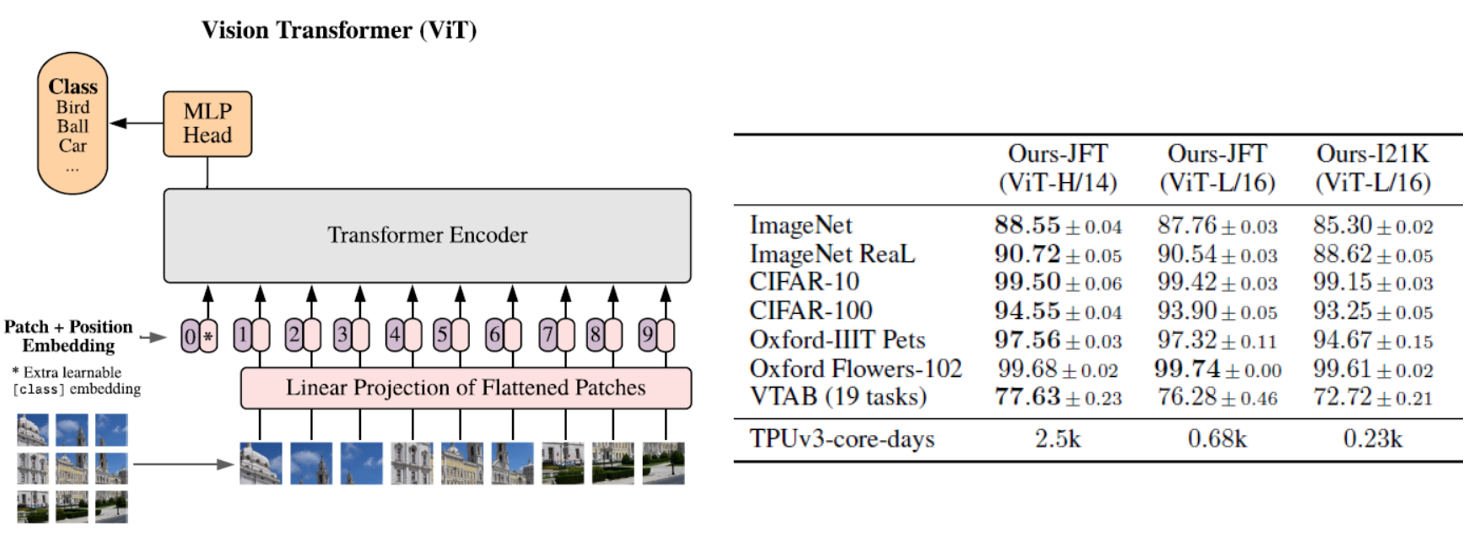
Data-efficient image transformers (DeiT) 無需海量預訓練資料,只依靠ImageNet資料,便可以達到SOTA的結果,同時依賴的訓練資源更少(4 GPUs in three days),
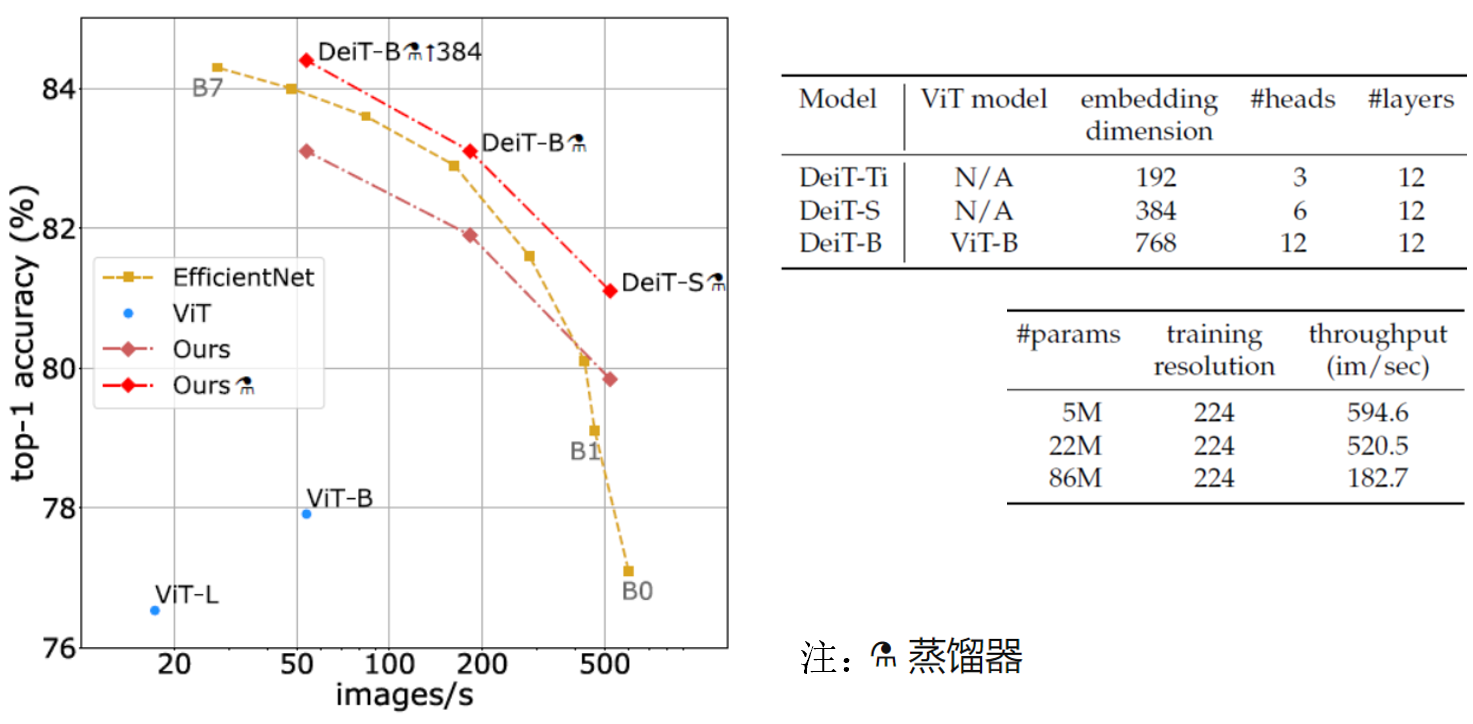
上圖左邊是DeiT與ViT, EfficientNet的結果對比圖,右邊是幾種DeiT模型采用的結構,
二、方法
DeiT如何實作前面介紹的結果呢?主要是以下兩個方面:
1) 采用合適的訓練策略包括optimizer, data augmentation, regularization等,這一塊該文主要是在實驗部分介紹;
2)采用蒸餾的方式,結合teacher model來引導基于Transformer的DeiT更好地學習(這個論文的方法部分主要是介紹的這個);
假設已經獲取得到一個較好的分類模型(teacher),采用蒸餾的方式也很簡單,相對于ViT主要是增加了一個distillation token,其對應的token輸出值與teacher model的輸出值盡可能接近,下圖表示DeiT方法的示意圖,
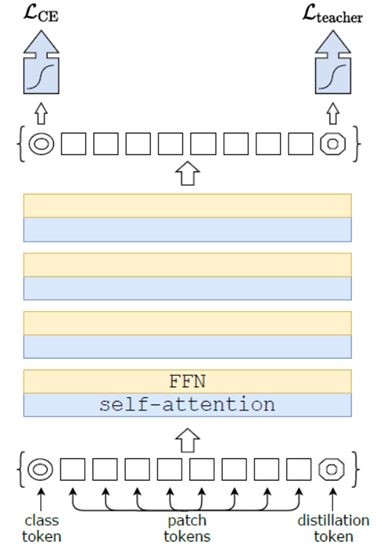
針對distillation的型別,主要有兩種方式,soft distillation和hard distillation,本質區別是,soft是限制student和teacher模型輸出的類別分布盡可能接近,hard是限制兩種模型輸出的類別標簽盡可能接近,
——soft distillation

這里用的KL散度計算分布之間的相似性,
——hard distillation
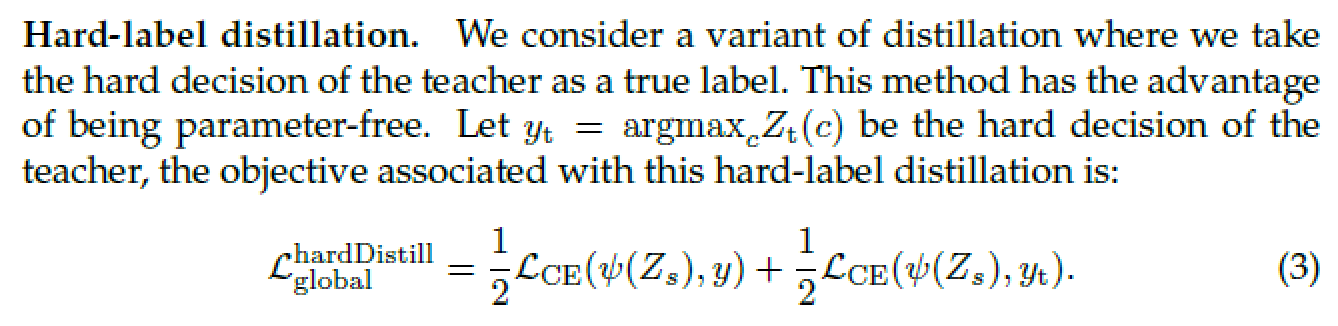
這里需要用
a
r
g
m
a
x
argmax
argmax函式,從后面的實驗可以看出hard distillation效果會更好一些,但因為使用了
a
r
g
m
a
x
argmax
argmax函式,teacher model模型輸出的資訊會丟失很多資訊,為什么hard要比soft好,本文里沒有展開解釋,
三、實驗效果
3.1 關于模型蒸餾(Distillation)的實驗
下面是在ImageNet上的實驗結果:
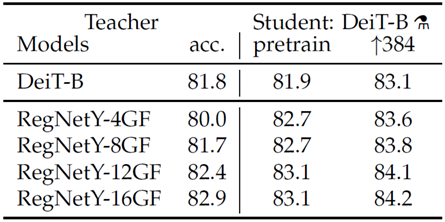
其中符號
↑
384
\uparrow 384
↑384表示采用本文作者NIPS2019的作業[2],在224x224的影像上進行預訓練,在384x384影像上進行finetune.
一個有意思的現象是,使用性能相對較差的RegNetY-4/8GF為Teacher,蒸餾后DeiT-B的結果比Teacher還要高;其中相對RegNetY-4GF提升了2.7個點,最為明顯,對此,本文作者如下解釋:
The fact that the convnet is a better teacher is probably due to the inductive bias inherited by the transformers through distillation, as explained in Abnar et al [3].
換句話講就是,CNN是有inductive bias的,例如區域感受野,引數共享等,這些設計比較適應于影像任務,這里將CNN作為teacher,可以通過蒸餾,使得Transformer學習得到CNN的inductive bias,從而提升Transformer對影像任務的處理能力,
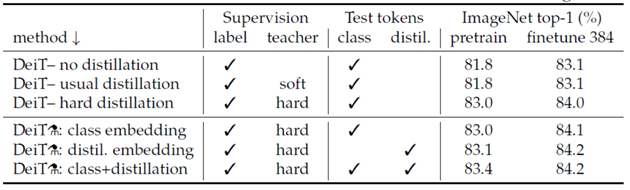
以下是采用不同的distillation方式,在ImageNet中的結果,實驗表明hard distillation 效果好于soft的方式,而在測驗時,同時使用class和distil embedding,效果會更好,
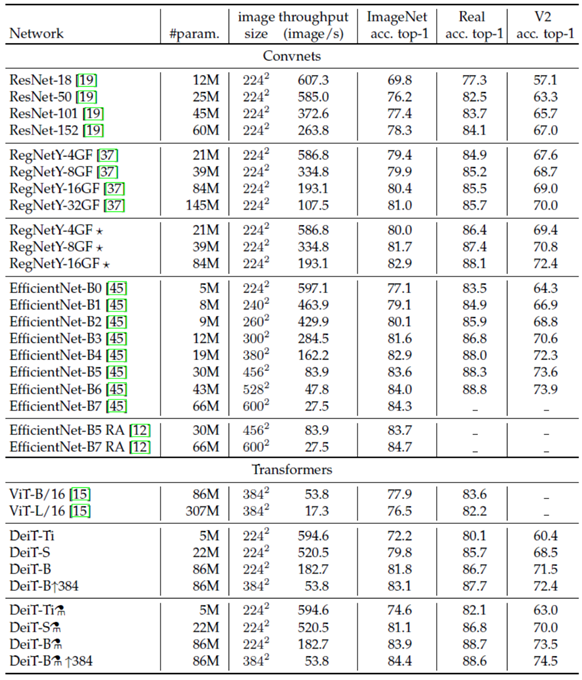
3.2 在ImageNet上的結果
下圖表示DeiT在ImageNet最終的結果,注意這里面列的ViT的效果是只用ImageNet進行訓練的結果,并沒有用到JFT-300M資料集,整體上效果還是不錯的,
3.3 Training details & ablation
這部分就是在方法部分講的第一點,本文詳細闡述了采用怎樣的方式能夠將Transformer訓練好,
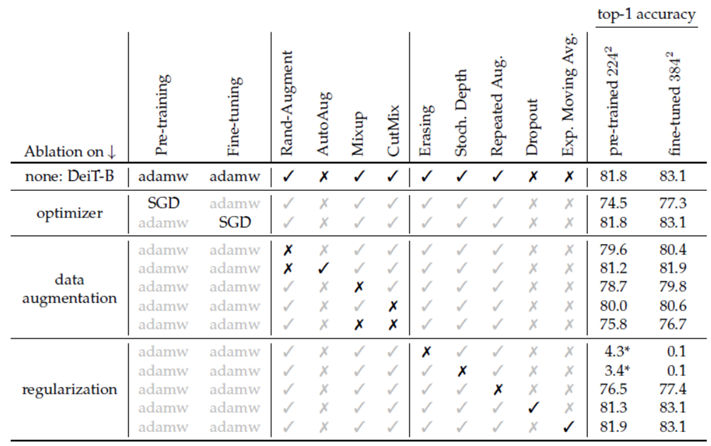
1)optimizer
采用的是adamw,即帶weight decay的adam,這里它做了與SGD的對比,但沒有與adam對比,
2) data augmentation
本文指出,相對于引入先驗的模型來說,如CNN,transformers一般都需要一個更加大的資料集,對此就依賴于大量的資料擴充操作,這里重點采用的資料擴充方式是Rand-Augment, Mixup, CutMix,下圖是一些相關操作的示意圖,
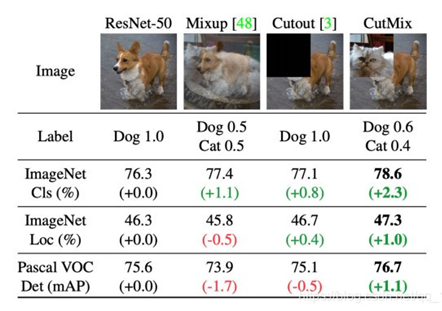
3) regularization
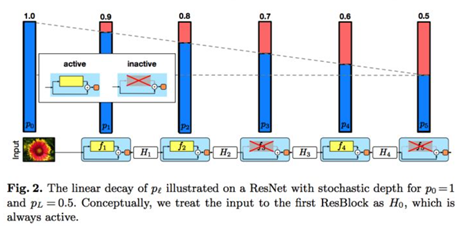
這里指出采用Random Erasing和Stochastic depth等方式有助于模型的收斂,尤其是采用較深的模型時,
Random Erasing[4]:隨機選擇一個區域,然后采用隨機值進行覆寫,

Stochastic depth[5]: 隨機失活一些卷積層,只保留 shortcut 通路的方式隨機跳過 一些 Residual Blocks
四、總結
DeiT核心思想是采用蒸餾的方式,使得基于transformer的模型能夠學習得到基于CNN模型的一些inductive bias,從而提升對影像型別資料的處理能力,蒸餾的相關操作是值得學習和借鑒的,
此外,實驗部分中的Training details也非常值得借鑒,如何將transformer進行有效訓練,在其他任務是也是可以利用的,
五、參考資料
[1] Touvron H, Cord M, Douze M, et al. Training data-efficient image transformers & distillation through attention[J]. arXiv preprint arXiv:2012.12877, 2020.
[2] Touvron H, Vedaldi A, Douze M, et al. Fixing the train-test resolution discrepancy[J]. arXiv preprint arXiv:1906.06423, 2019.
[3] Samira Abnar, Mostafa Dehghani, and Willem Zuidema. Transferring inductive biases through knowledge distillation. arXiv preprint arXiv:2006.00555, 2020.
[4] Zhun Zhong, Liang Zheng, Guoliang Kang, Shaozi Li, and Yi Yang. Random erasing data augmentation. In AAAI, 2020.
[5] Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra, and Kilian Q. Weinberger. Deep networks with stochastic depth. In European Conference on Computer Vision, 2016.
[6] 知乎文章,《想讀懂YOLOV4,你需要先了解下列技術(一)》,《想讀懂YOLOV4,你需要先了解下列技術(二)》:詳細系統地總結了很多資料增強/擴充、特征增強、歸一化、網路感受野增強技巧、注意力機制和特征融合技巧等方法,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/255295.html
標籤:其他
上一篇:01 MQTT小例子-連接