學習課程:斯坦福大學密碼學公開課
課件鏈接:https://pan.baidu.com/s/1vogTE2Flpzi9DmoclLPGQw
提取碼:1mrp
Stream ciphers
- The One Time Pad
- 學到此處的一些思考:熵與密碼
- Pseudorandom Generators
- Negligible vs. non-negligible
- Attacks on OTP and stream ciphers
- Real-world Stream Ciphers
- PRG Security Defs
- Semantic security
- Stream ciphers are semantically secure
- 知識梳理
- 統計測驗的作用是隨機性檢測
- 不可預測的PRG就是安全的PRG
- 語意安全性檢測模型也是一個統計測驗
- 統計測驗中的優勢和語意安全性中的優勢
The One Time Pad

如何定義cipher,
cipher由通常由五元組構成:密鑰空間K、明文空間M、密文空間C、加密演算法E、解密演算法D,
加密演算法E通常是隨機演算法,它會自己生成隨機序列,加入到密文的生成中;而解密演算法D往往是確定演算法,沒有亂數的加入,

The One Time Pad:一次性密碼本
明文密文空間都是長度為n的二進制序列,密鑰空間也是,密鑰是和明文等長的隨機的二進制序列,

加密解密都是逐位異或,

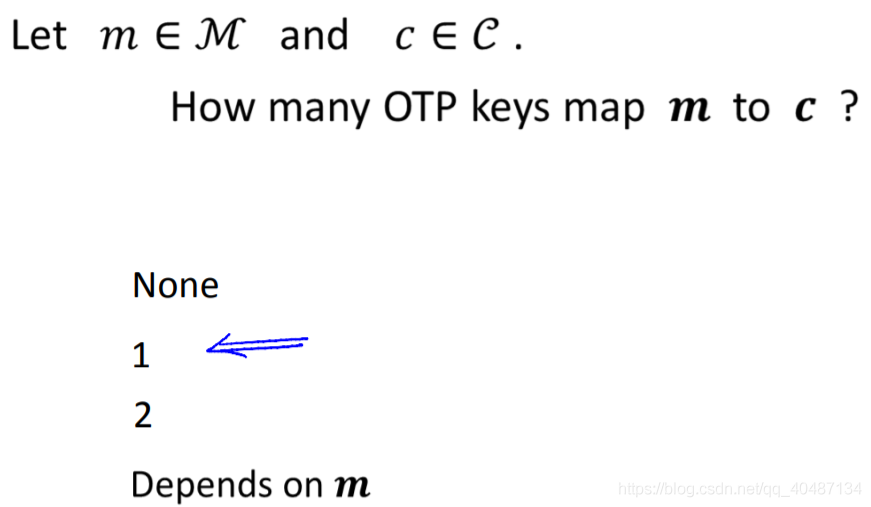
簡單的課堂小問題,

一次性密碼本并不能在真實場景中運用,因為Alice必須把密鑰K也安全地傳給Bob,但如果Alice有這種方法,她完全可以安全地直接把訊息傳送過去,初次之外,因為密鑰k必須和明文等長,因此在傳輸程序中存在著嚴重的資料冗余(k就是那個冗余資訊,因為原來的目的只是把明文資訊傳輸過去),使資訊傳輸效率下降,
為什么一次性密碼本是安全的呢,或者說什么是安全的密碼,什么使密碼安全,看下文,

攻擊者只能發動唯密文攻擊,
我們想通過加密方案,使攻擊者不能還原密鑰或者明文,
如果是完美的加密方案,那么會使攻擊者不能獲得任何與明文相關的資訊,

Shannon關于完美加密方案的解釋:任意兩個等長的不同明文m0和m1經過加密后,結果為密文c的概率是一樣的,這樣的話,如果攻擊者截獲了一段密文,他就無法獲取任何一點明文資訊,因為不同明文經過加密變成密文c的概率是一樣的,
這就很容易解釋為什么一次一密是完美的加密方案,因為密鑰是隨機的,根據異或的性質,密文也是隨機的,因此從密文中無法獲取任何有關明文的資訊,
因此唯密文攻擊對一次一密的加密方式是無效的,
簡單的課堂小問題,

要實作完美的安全性,密鑰的長度必須不小于明文的長度,這在實際運用中很難實作,
學到此處的一些思考:熵與密碼
在前面的學習中會發現,“隨機”這個詞經常出現,什么是隨機?在數學中,通常用熵來衡量事物的隨機性,
香農提出,完美的加密方案就是從密文中不能獲取任何有關明文的知識,這是從密文到明文的一種闡述,換個角度,完美的加密方案就是一個明文有相同的概率變成任意一種密文,在明文變成密文的程序中,不確定性增加了,也就是熵增加了,
由此可見:好的加密方案就是通過加密盡可能地把明文的熵增大,
那么加密的程序中明文的熵為什么會增大呢?對于一個函式來說,輸出的熵是不肯能大于輸入的熵的,這時我們就會意識到,亂數和異或在加密程序中的重要性,
亂數的引入使函式的輸入熵增大,而異或可以把亂數的熵傳遞給明文,這樣函式的輸出熵,也就是密文的熵就會增大,
由此可見一個好的亂數生成演算法,在加密程序中是十分關鍵的,事實上,要想通過演算法生成真正的隨機序列是不可能的,
Pseudorandom Generators

上一章節的回顧,

引入偽亂數生成器G,G可以把種子空間映射到比種子空間{0,1}s大得多的偽隨機序列空間{0,1}n,
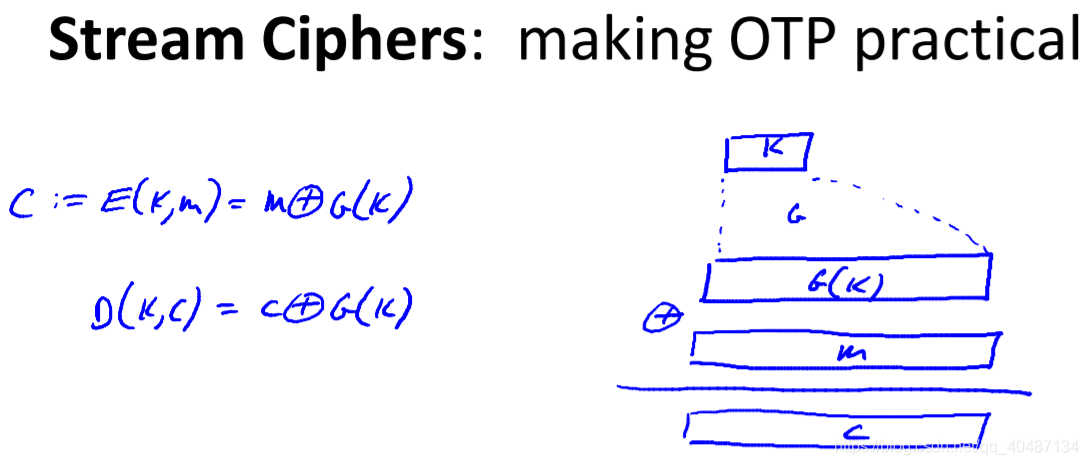
明文和G生成的偽隨機序列進行異或,
 簡單的課堂小問題,
簡單的課堂小問題,

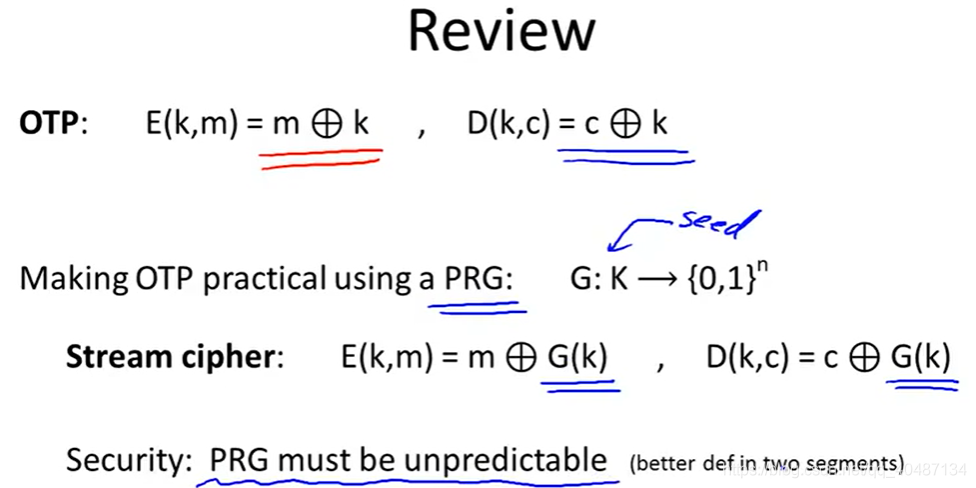
流密碼是安全的,但不是香農定義的完美安全,我們需要一個新的關于安全的定義,流密碼的安全性依賴于PRG,

PRG的生成必須是不可預測的,否則:網路一些協議往往有特定的前綴,攻擊者可以通過這些前綴和其對應的密文,來算出PRG生成序列的前幾位,進而預測整個序列,

給任意前綴都不能預測下一位,ε是可忽略值,表示可以接受的范圍,如果預測正確的概率超過1/2+ε,那么就認為這個PRG不能用,
 簡單的課堂小問題,
簡單的課堂小問題,

幾個弱PRG,容易被預測,以及,永遠不要用glibc庫里的隨機函式做加密,
Negligible vs. non-negligible




用數學語言簡單地解釋了一下,
Attacks on OTP and stream ciphers
上節的回顧,
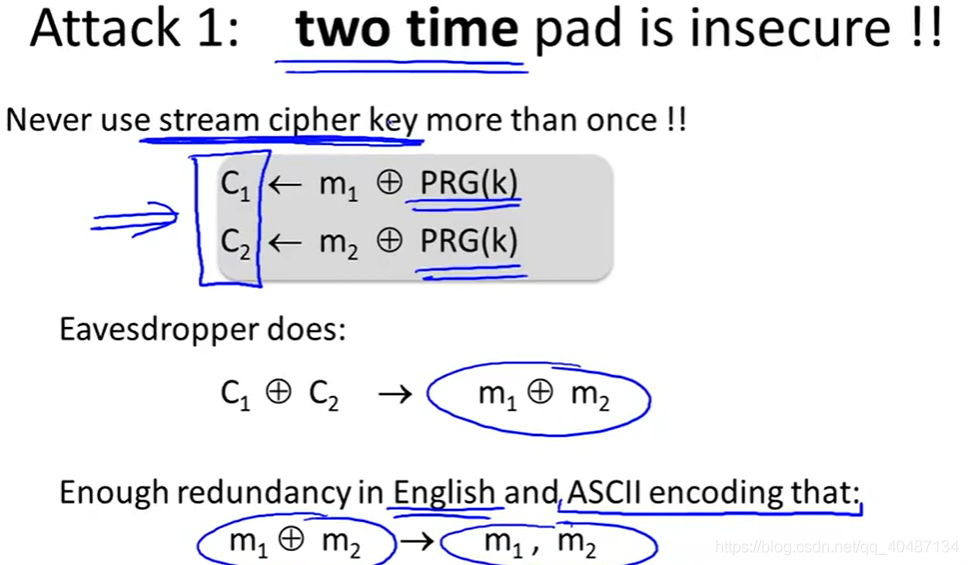
一次一密的安全性在于每次加密都用不同的密鑰,如果一個密碼本加密了兩次不同的明文,就很容易導致資訊的泄露,
例如:英文文本一般是用ASCII碼編排的,而且英文本身就有規律可循,因此兩個明文異或后的結果,還是有很大可能被解密,

幾個例子(根據名字自行百度吧):
Windows NT告訴我們,不同方向發送的資訊流,需要不同的密碼本,
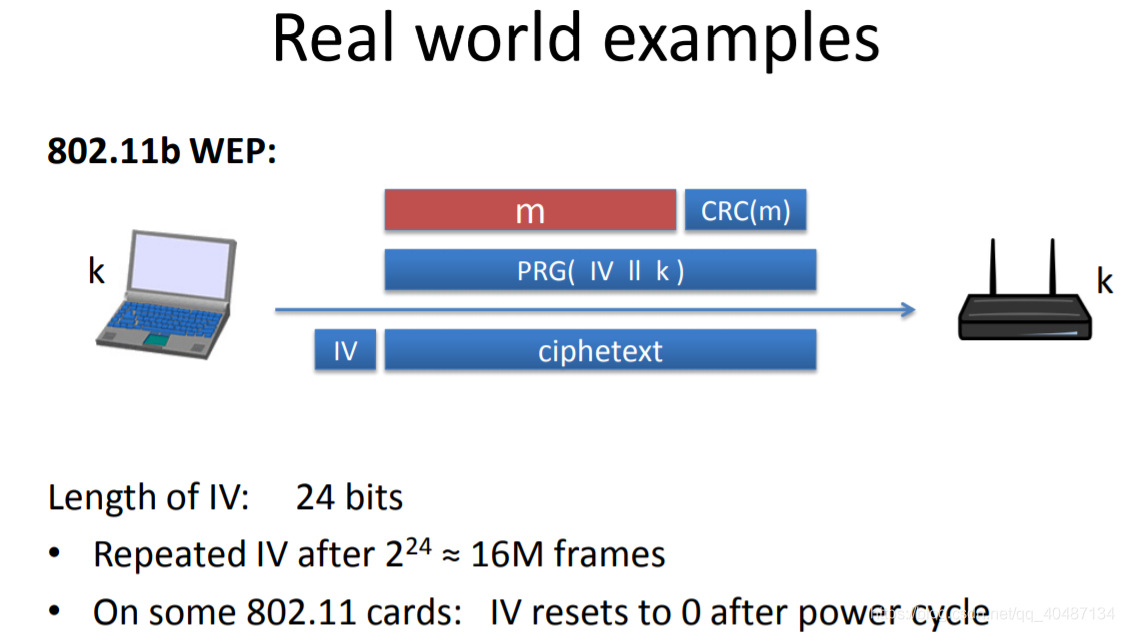
WEP是個很糟糕的協議,圖中,k是固定不變的,IV會在每個幀發送后+1,但IV是24位的,不能無限增長,在發送了大量幀后,又會歸零,這相當于密碼本復用了,而且每次重啟設備后,IV都是從0開始的,這個也很不好,
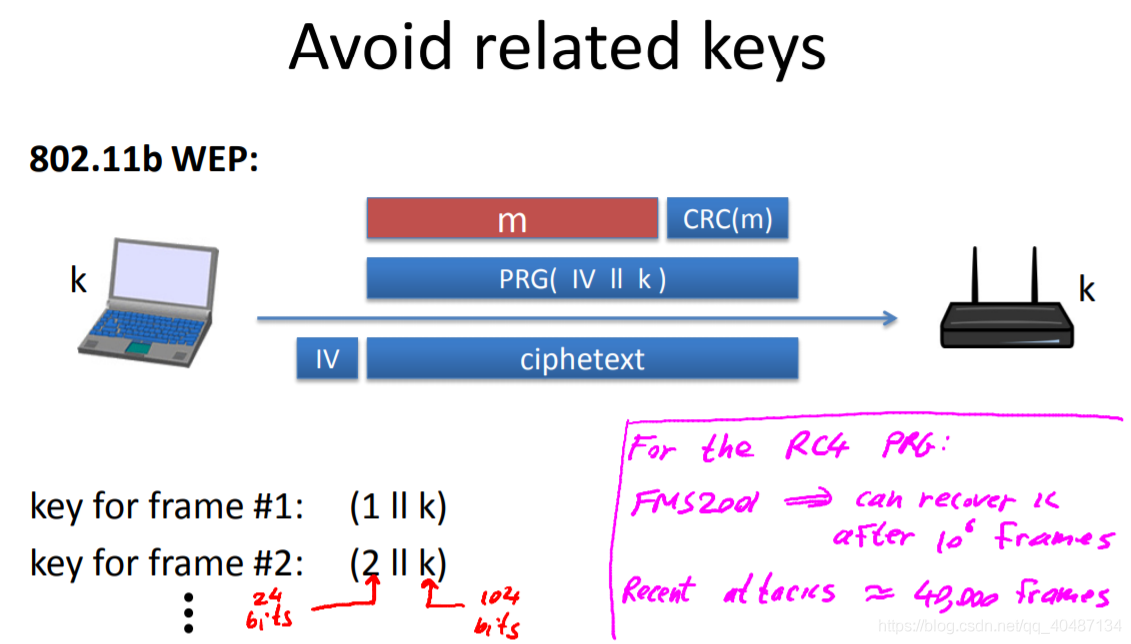
WEP所使用的key是經過簡單拼接而生成的,因此每個key都十分接近,這也很不安全,
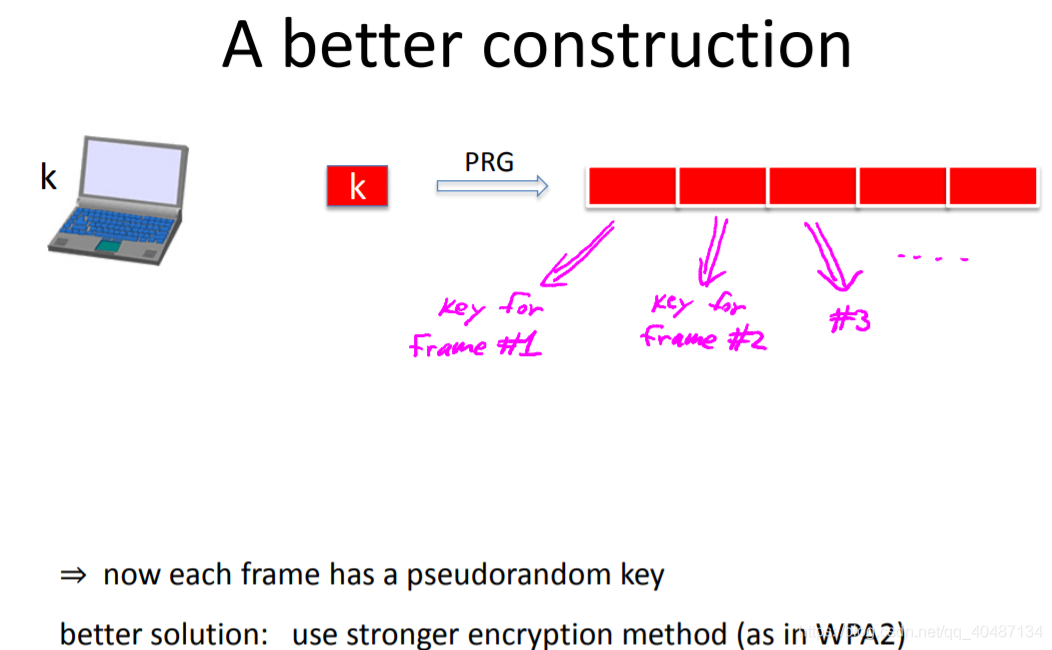
一個更好的方案是用PPG為每一幀都生成一個key,
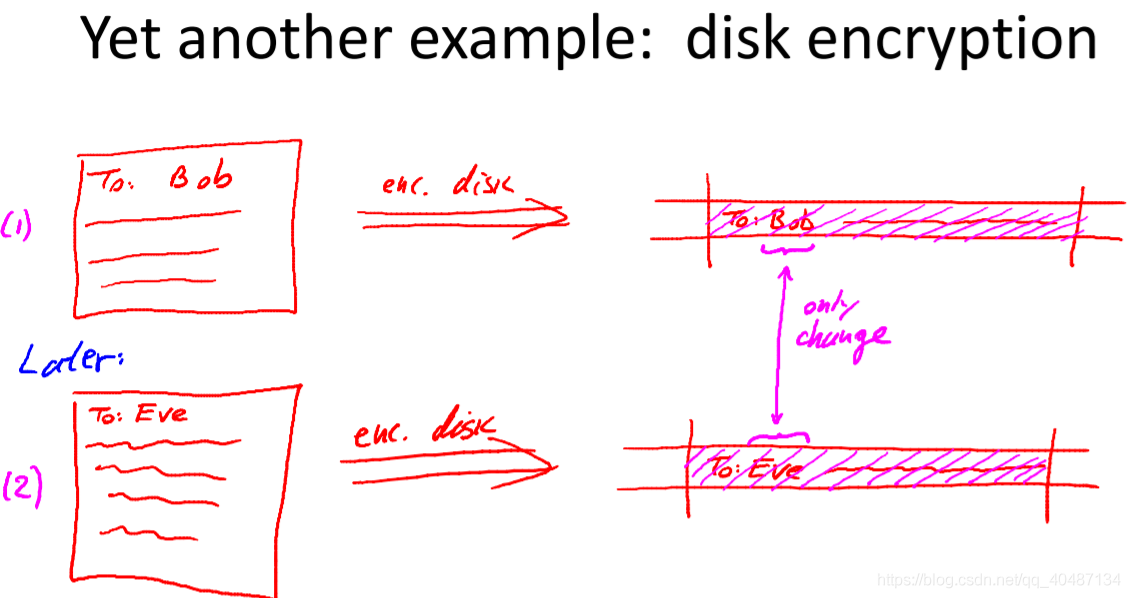
當用一次性密碼本加密硬碟檔案時,如果更改了明文某個地方,那么對應地方的密文也被更改了,攻擊者就能通過密文更改的位置判斷出明文更改的位置,但我們不想把這個資訊泄漏給攻擊者,一個好的加密方案應該是這樣的:明文只要稍微改動一點,密文就有很大的變化,這樣攻擊者就無法從密文的改變推斷出明文的哪個地方做了修改,

小結:永遠不要重復使用流密鑰,
網路中,每次會話應該協商新的密鑰,
磁盤加密時,不要使用流密碼方案加密,
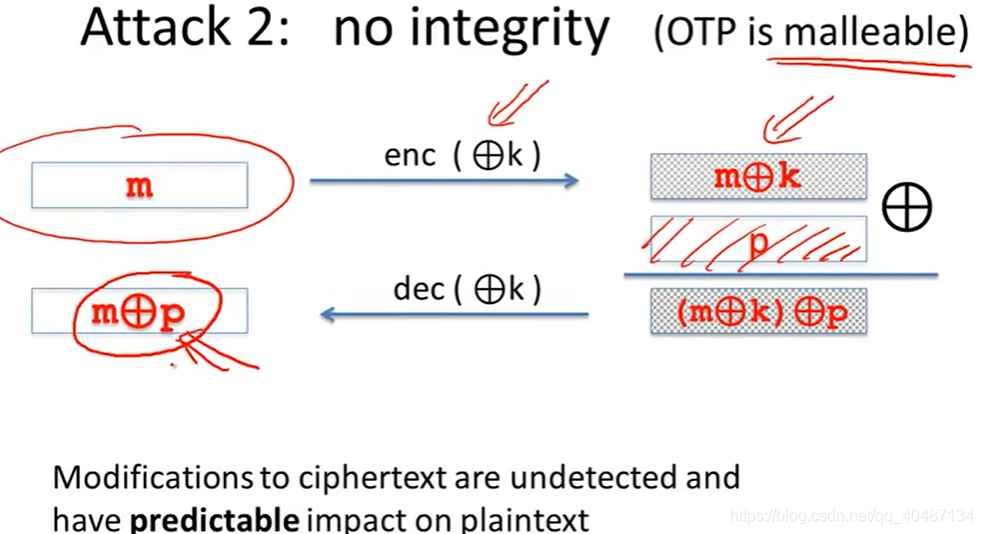
流密碼加密方案也不提供完整性支持,攻擊者很容易篡改明文,
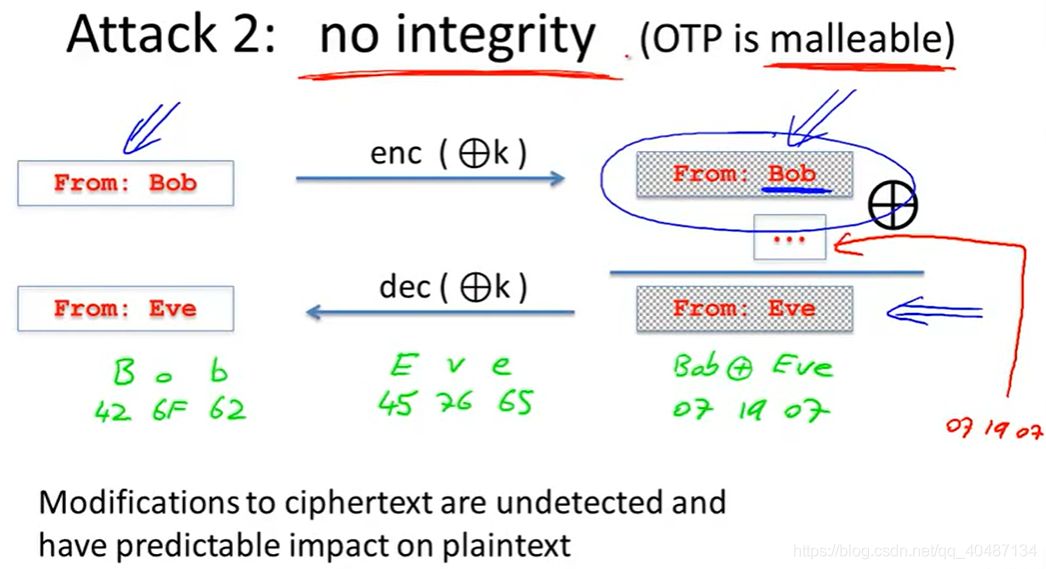
例如:加入攻擊者知道一封郵件是由Bob寄來的,那么他可以通過修改密文的方式影響明文,把Bob修改為Eve,
Real-world Stream Ciphers
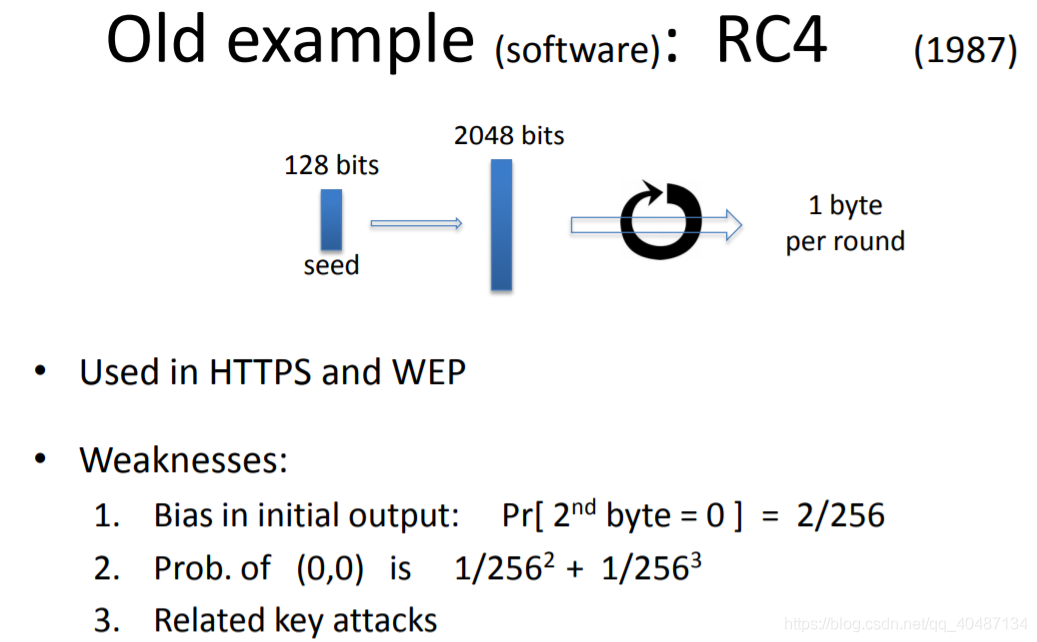
RC4生成的序列隨機性不夠,
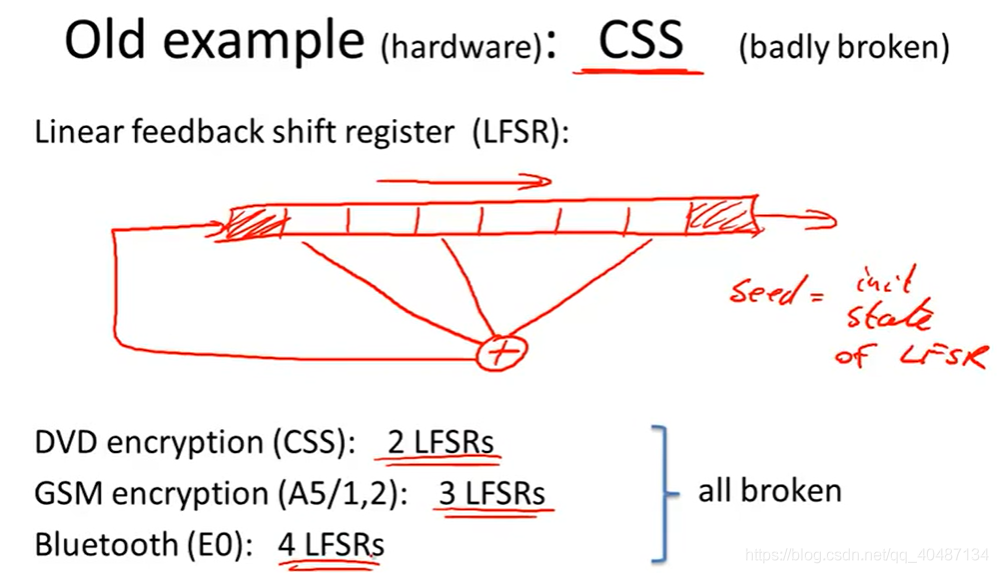
用于硬碟加密的CSS加密方案,它的key由線性反饋移位暫存器生成(LFSR),其原理如下:
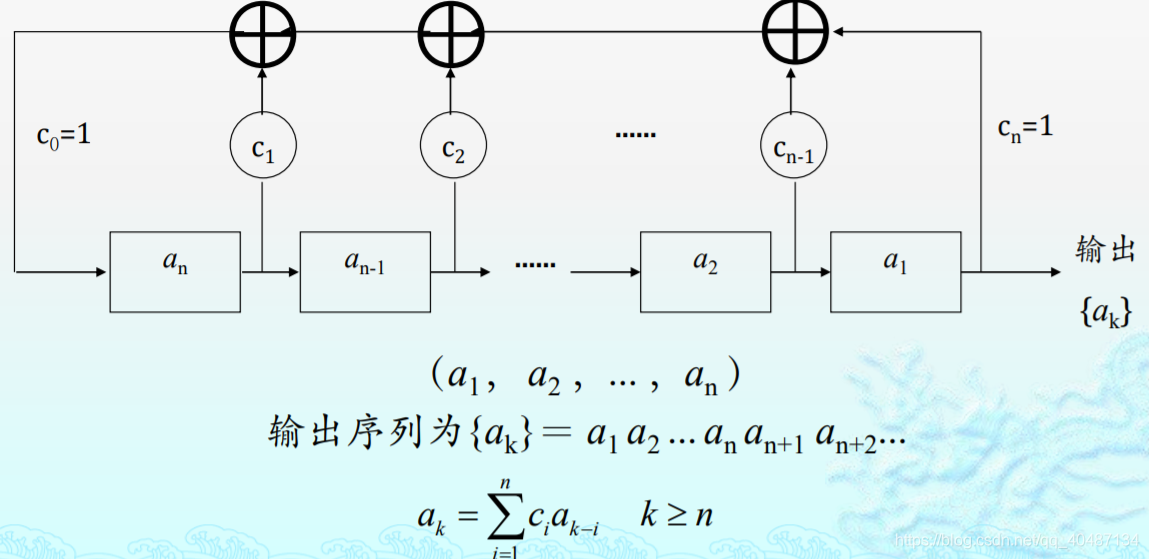
LFSR的初始態就是這個PRG的seed(密鑰種子),
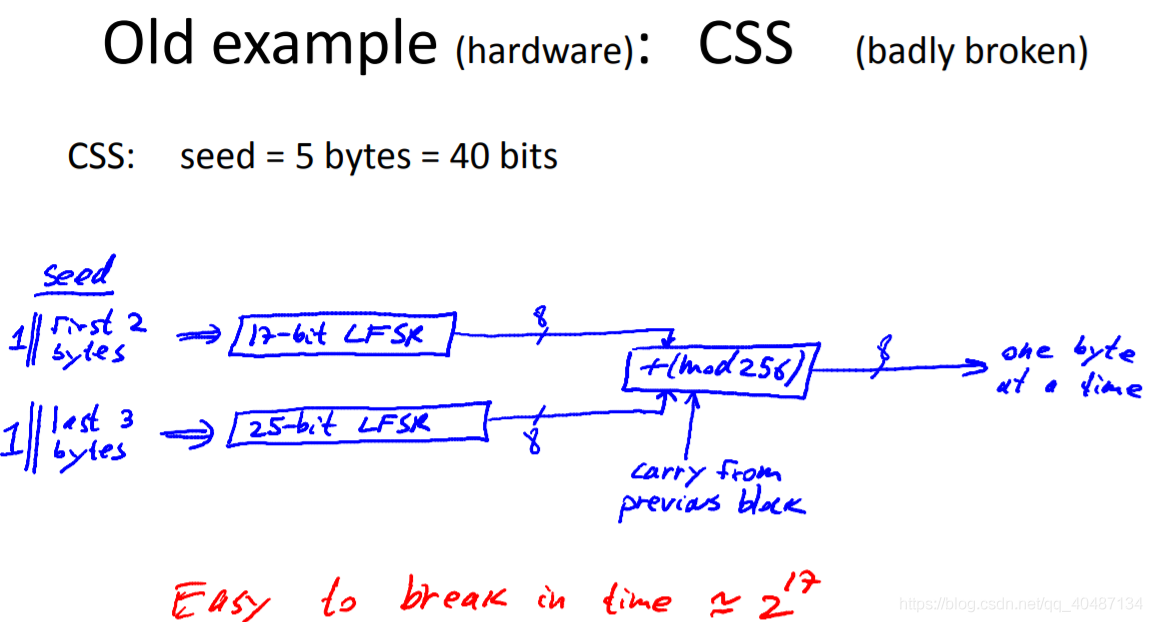
CSS的原理:
首先CSS的seed是40位(美國法律規定),這40位分別用在兩個LFSR上,LFSR1是17位,LFSR2是25位,40=16+24,16位給LSFR1,并在這16位前添一個1構成17位,這17位就是LFSR1的初始態,LFSR2同理,LFSR1和LFSR2每次會運行8輪,產生的序列,會和上一次計算產生的進位三者相加,產生的值mod256,生成一個8位的序列,也就是一個位元組的密鑰,產生的8位序列和明文異或產生密文,
LFSR運行8輪和后面的mod256是呼應的,
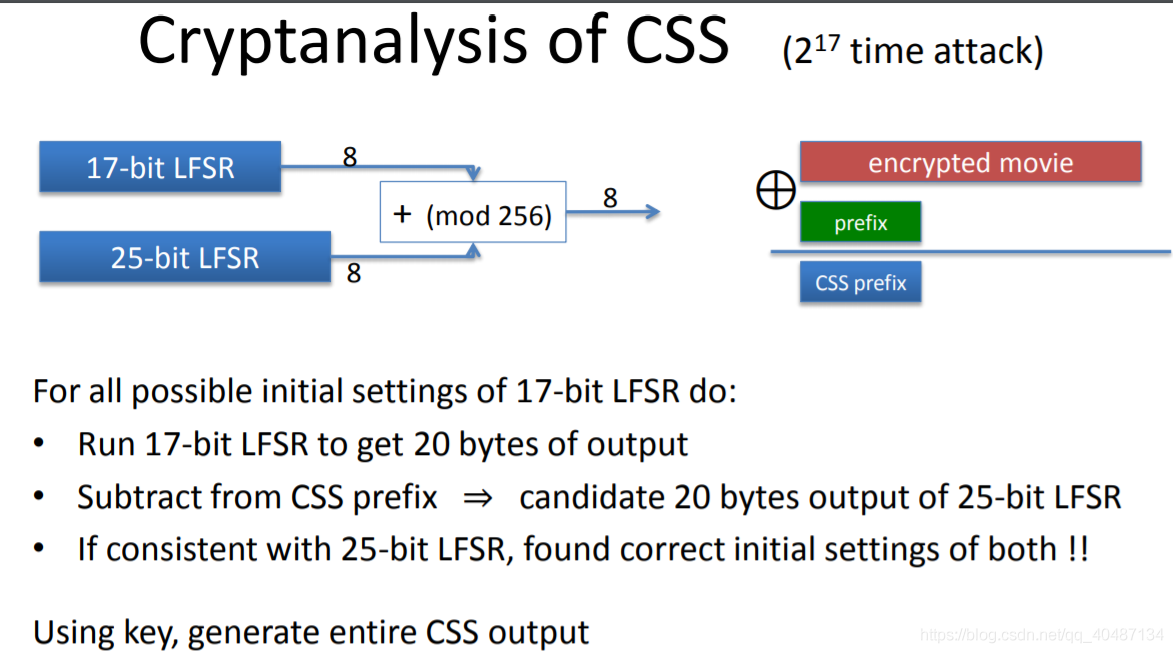
CSS的破解:
DVD的加密使用了MPEG檔案,如果知道明文的前綴,例如前二十個位元組,這樣就可以與密文的前二十個位元組異或,得到PRG輸出的前二十個位元組,
如圖:LFSR1生成的前幾位序列記為直線1,LFSR2生成的前幾位序列記為直線2,因為是選取的序列前幾位,1+2等于1異或2,得到的序列記為直線3,在加密時,每次選取直線三的8位,即一個位元組和明文異或來得到密文,
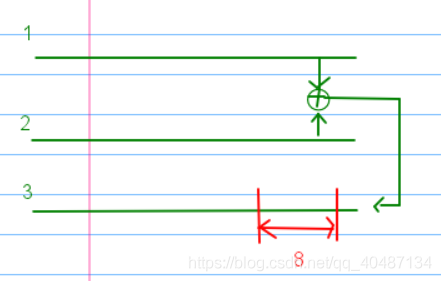
因此上文得到的PRG輸出的前幾位就是直線3,窮舉LFSR1的初始狀態,得到直線1的所有可能,就可以通過1異或3得到直線2的所有可能,20位元組,可以用前50位計算出LFSR2的抽頭序列,在用剩下的資料驗證,驗證成功后再用GVG中剩下的密文進行進一步驗證,
如何計算抽頭序列



引入了nonce,
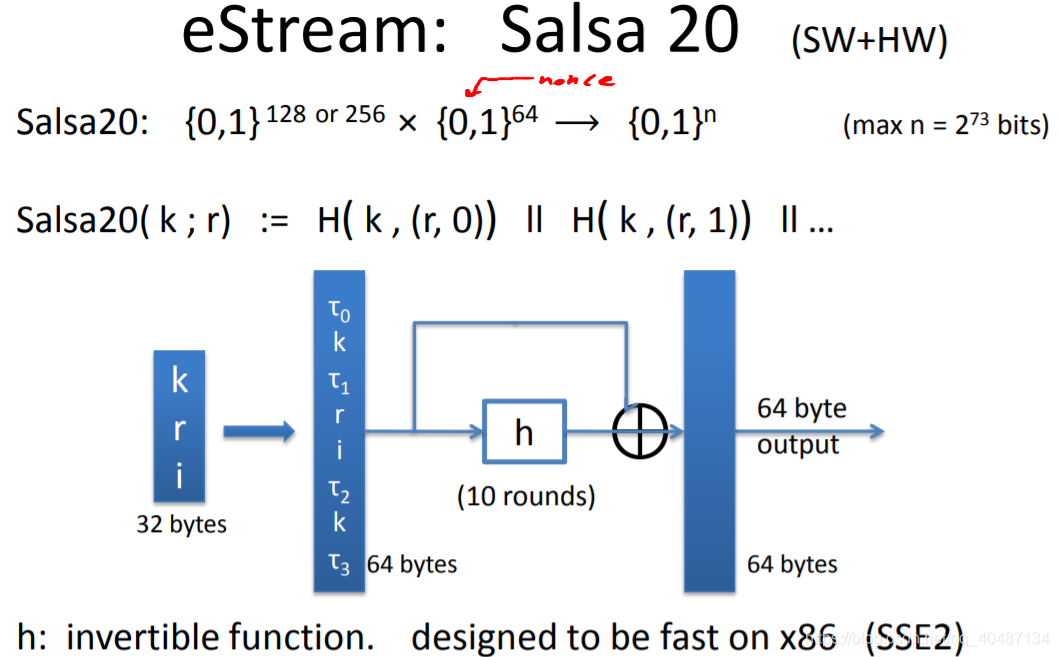
eStream的一種,Salsa20,其關鍵在于h函式,但教程里沒有細講,

效率,
PRG Security Defs

PRG產生的序列是很有限的,是{0,1}n的子集,
如何判斷PRG產生的序列隨機性的好壞呢?
 引入一個A函式來判斷PRG產生序列隨機性的好壞,A的定義有很多種,
引入一個A函式來判斷PRG產生序列隨機性的好壞,A的定義有很多種,
如何評估A的好壞,定義了一個概念叫advantage如圖,值越接近1性能越好,

簡單的課堂小問題,

如何定義一個安全的PRG:對于任意的有效(efficient)統計測驗A,A對于PRG的優勢為0,efficient是一個十分重要的限定,因為有些A可能在多項式時間內無法求解,如果去掉這個限定的話是無法得出一個結論的,
我們無法證明一個PRG是安全的,因為我們無法窮舉出所有A,

不可預測是安全的必要條件,

可以把之前關于不可預測性的知識,用在定義一個統計測驗中,
 姚證明了不可預測的PRG就是安全的PRG,
姚證明了不可預測的PRG就是安全的PRG,
 姚氏定理十分好用,例如上圖的例子,用姚氏定理解釋的話就是,因為這個PGR是不安全的(因為它的性質,很容易構造出一個統計測驗來區分這個PRG產生的序列和隨機序列),所以肯定是可預測的,
姚氏定理十分好用,例如上圖的例子,用姚氏定理解釋的話就是,因為這個PGR是不安全的(因為它的性質,很容易構造出一個統計測驗來區分這個PRG產生的序列和隨機序列),所以肯定是可預測的,

引入一個符號來表示兩個序列在計算上是不可區分的(computationally indistinguishable),、
Semantic security

如何定義安全,在香農的定義上做了寫改動,只要攻擊者無法用現有的技術計算出有關明文的資訊就行,
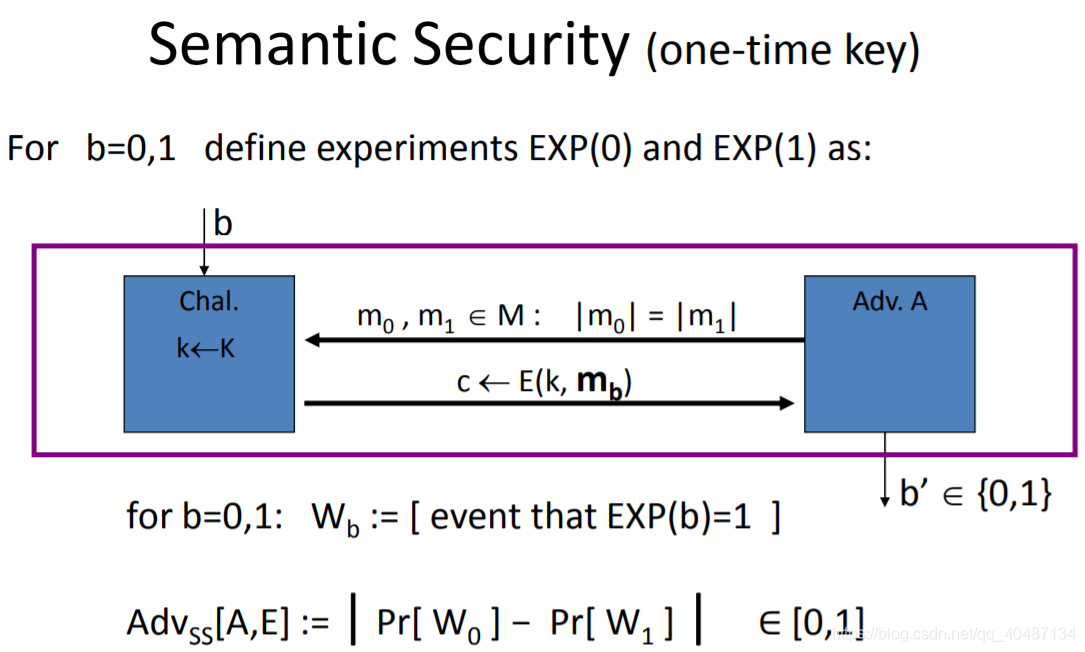
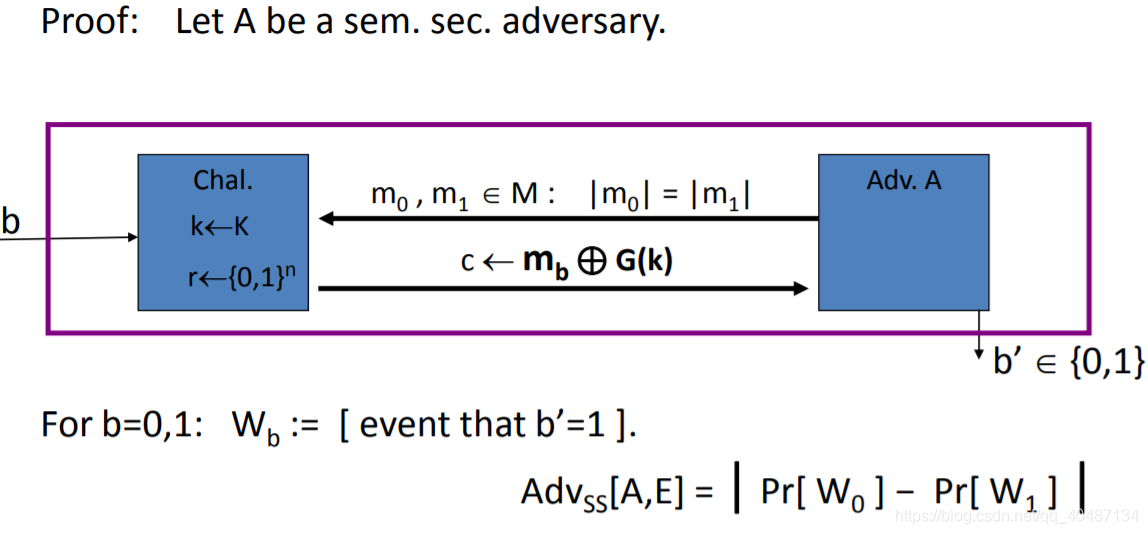
定義了語意安全性,在密碼學中,這叫攻擊者挑戰者模型,
W0對應收到M0的密文,輸出1;
W1對應收到M1的密文,輸出1,
可以參考我下面這篇博客第三章 可證明安全性中的內容,
https://blog.csdn.net/qq_40487134/article/details/103875373
 語意安全性的定義,
語意安全性的定義,
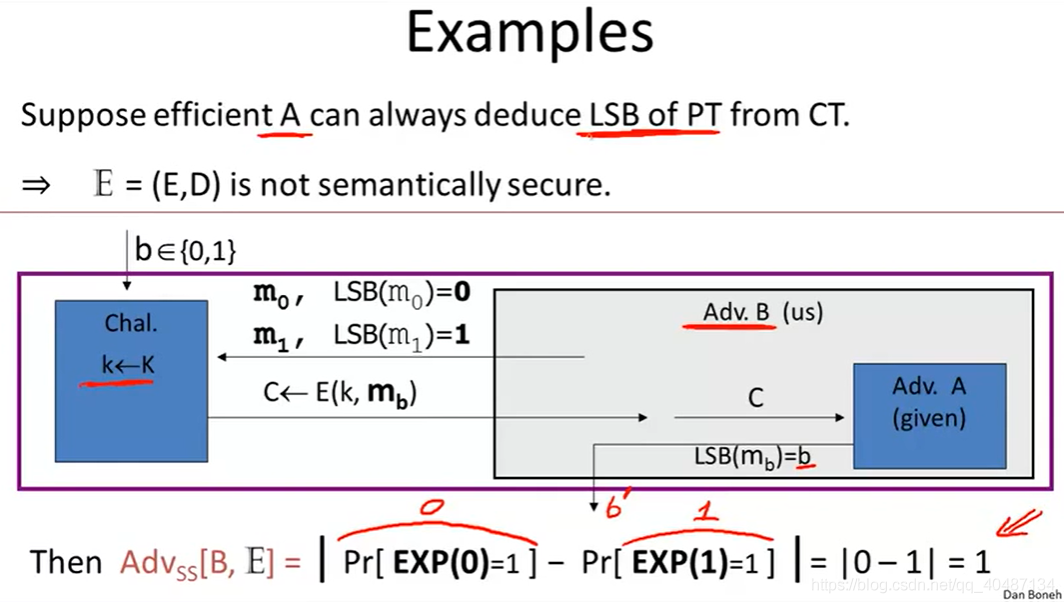
簡單的小例子,
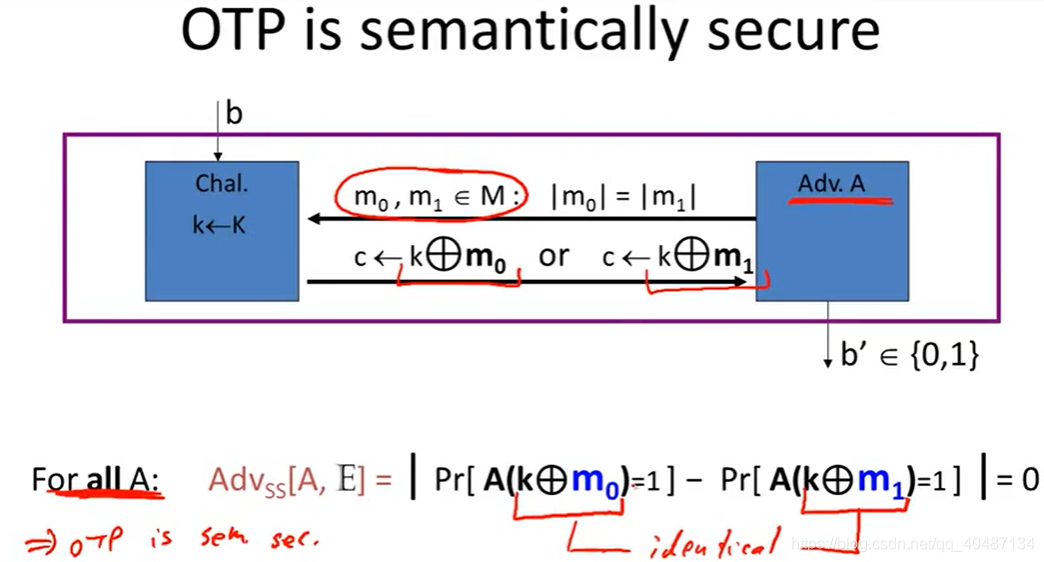 OPT是語意安全的,
OPT是語意安全的,
Stream ciphers are semantically secure
Goal: secure PRG ? semantically secure stream cipher

定理,用安全的PRG產生的流密鑰進行流加密是語意安全的,
注意是語言安全,不是香農定義的完美安全,用PRG做流加密是不可能完美安全的,
想證明這個定理的話,可以證明它的逆否命題,
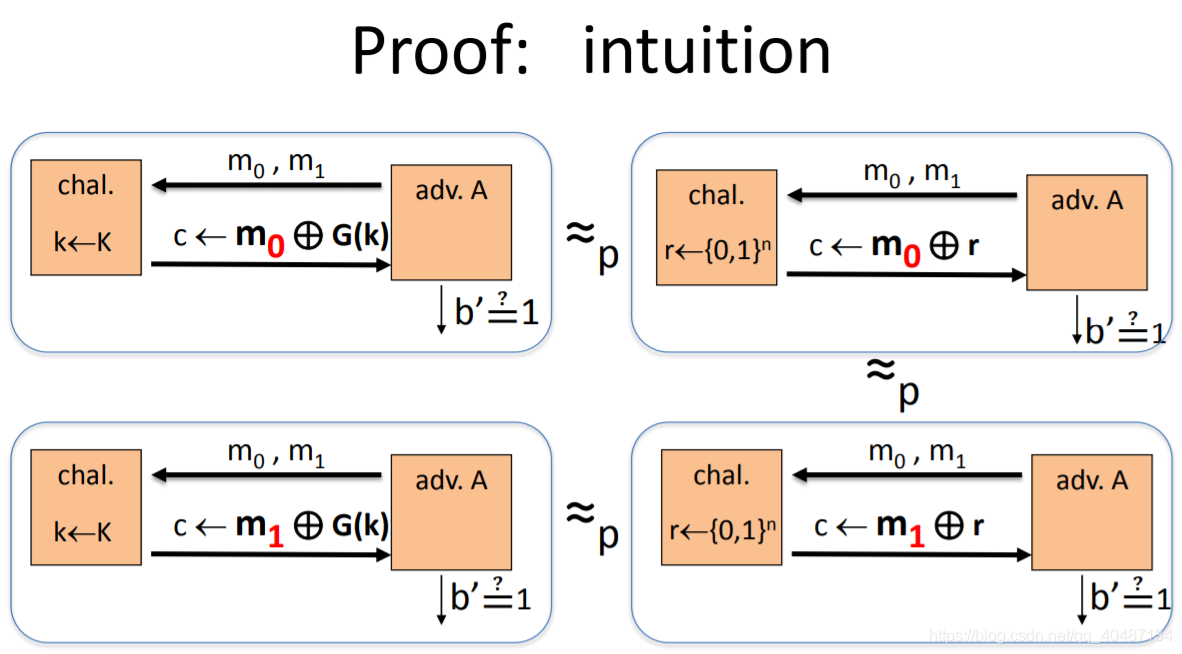
一個直觀的證明,其中r是隨機序列,G(k)是PRG產生的序列,如果PRG是安全的,那么攻擊者無法區分,挑戰者到呼叫的是r還是G(k),
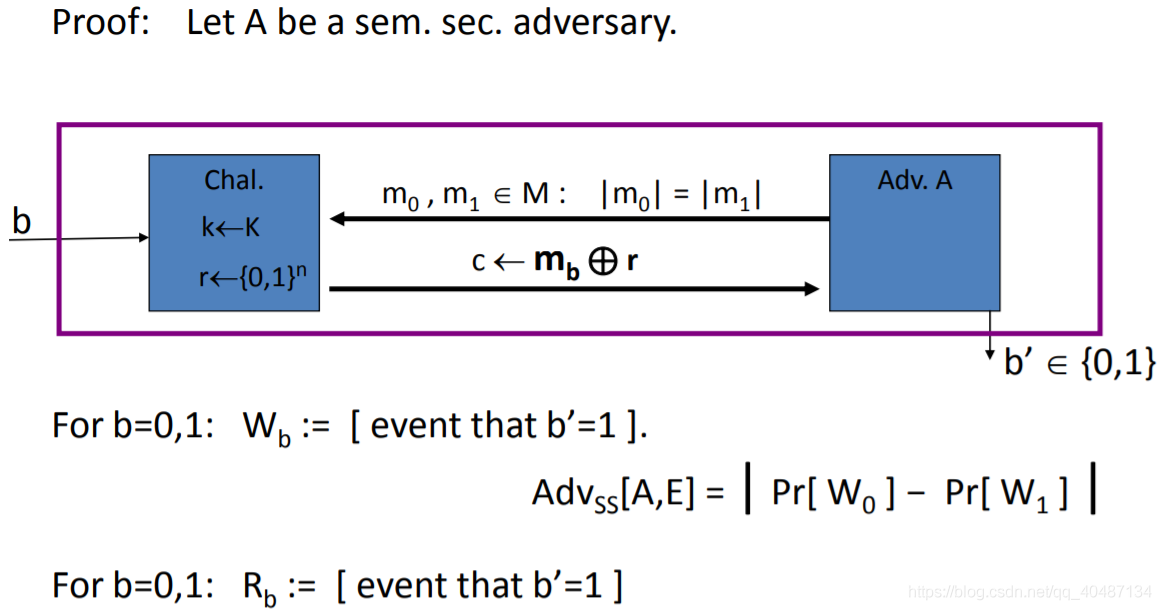
W0對應收到M0的密文,輸出1;
W1對應收到M1的密文,輸出1,
R0對應收到M0的密文,輸出1;
R1對應收到M1的密文,輸出1,

接下來要證明Claim2

對這一套證明的理解在下面的知識梳理里,
知識梳理
統計測驗的作用是隨機性檢測
統計測驗是為了判斷一個PRG是否能產生好的偽隨機序列,若一個PRG產生的偽隨機序列和真隨機序列難以區分,那么就說這是一個安全的PRG,
不可預測的PRG就是安全的PRG
定義一個統計測驗B,和一個有效的預測演算法集合A,如果A預測到了結果,B就輸出0,否則輸出1,若B的優勢接近于1,就說明序列隨機性強,同樣的,若B的優勢接近于1,還說明A是不可預測的(因為預測到了結果回輸出0),
語意安全性檢測模型也是一個統計測驗
語意安全性檢測模型是一個特殊的統計測驗,在經典的統計測驗中,輸出的結果是我們自己定義的演算法計算出來的,但在語意安全性檢測模型中,統計測驗的輸出是就是攻擊者的輸出,
統計測驗輸出的含義是:這個PRG產生的序列隨機性如何,
語意安全性檢測中攻擊者輸出的含義是:攻擊者對密文所對應的明文的判斷,即判斷challenger做了EXP(0)還是EXP(1),
但二者并沒有本質的區別,因為攻擊者的優勢還是與PRG產生序列的隨機性有關,
歸根到底,隨機性越好,語意安全性越好,這也就是章節末的證明,
統計測驗中的優勢和語意安全性中的優勢
雖然都是優勢,但二者的區別還是很大的,
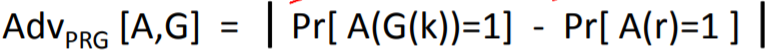
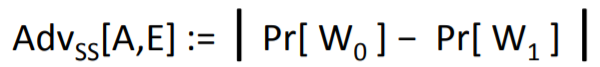
可以看到在PRG中左邊輸入是G(k),右邊輸入是r,
但在SS中,W0和W1其實輸入的都是G(k),
這樣說或許更明白,如果PRG中的優勢是這樣定義:
AdvPRG [A,G] = | Pr[ A(G(k))=0] - Pr[ A(G(k))=1] |
那么可以認為這兩個情景中對優勢的定義是等價的,
或許結合這個圖會理解得更明白:

這也就是這個命題中2的由來

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/255643.html
標籤:其他