大資料最全面試題整理-hive篇
- 導語
- 基礎問題:
- hive與傳統資料庫的區別
- hive的資料型別
- 元資料保存方式
- 內部表和外部表的區別
- 磁區表和分桶表的區別
- 簡述hive的存盤格式
- hive如何將Hql轉化為MapReduce
- hive排序函式的區別
- UDF相關內容
- 故障排查與調優
- 資料傾斜與優化
- 性能優化
導語
本專欄博文會整理日常作業與面試中最常用到的大資料相關組件與Java語言的架構、概念、知識點,方便大家進行查閱,
涉及到的面試題以及答案均為博主搜羅整理,并加上自己的理解撰寫而成,同時博主會在部分題目的下方添加管遇此題深入理解的博文連接,方便讀者的深入理解,
希望大家可以通過此篇博文對于大資料相關概念有一個更深入的理解
還有哪些想看的面試題,讀者可以在評論區補充,博主會在一天內進行更新!!!
最后預祝大家新的一年升職加薪,工資漲漲漲!
基礎問題:
hive與傳統資料庫的區別
-
表資料驗證:傳統資料庫是寫模式,hive是讀模式,傳統資料庫在寫入資料的時候就去檢查資料格式,hive在讀取資料的時候檢查,因此,寫時模式,查詢快,讀時模式資料加載快,
-
hive不支持實時處理,并且對索引支持較弱,
-
hive不支持行級插入、更新、洗掉和事務,
-
索引,Hive沒有,資料庫有
-
執行,Hive是MapReduce,資料庫是Executor
-
可擴展性,Hive高,資料庫低
-
資料規模,Hive大,資料庫小
-
資料存盤位置,Hive是建立在Hadoop之上的,所有的Hive的資料都是存盤在HDFS中的,而資料庫則可以將資料保存在塊設備或本地檔案系統中,
-
資料格式,Hive中沒有定義專門的資料格式,由用戶指定,需要指定三個屬性:列分隔符,行分隔符,以及讀取檔案資料的方法,資料庫中,存盤引擎定義了自己的資料格式,所有資料都會按照一定的組織存盤,
-
資料更新,Hive的內容是讀多寫少的,因此,不支持對資料的改寫和洗掉,資料都在加載的時候中確定好的,資料庫中的資料通常是需要經常進行修改,
-
執行延遲,Hive在查詢資料的時候,需要掃描整個表(或磁區),因此延遲較高,只有在處理大資料是才有優勢,資料庫在處理小資料是執行延遲較低,
hive的資料型別
原始資料型別
- 整型
TINYINT — 微整型,只占用1個位元組,只能存盤0-255的整數,
SMALLINT– 小整型,占用2個位元組,存盤范圍–32768 到 32767,
INT– 整型,占用4個位元組,存盤范圍-2147483648到2147483647,
BIGINT– 長整型,占用8個位元組,存盤范圍-263到263-1, - 布爾型
BOOLEAN — TRUE/FALSE - 浮點型
FLOAT– 單精度浮點數,
DOUBLE– 雙精度浮點數, - 字串型
STRING– 不設定長度,
復合資料型別
- Structs:一組由任意資料型別組成的結構,比如,定義一個欄位C的型別為STRUCT {a INT; b STRING},則可以使用a和C.b來獲取其中的元素值;
- Maps:一組無序的鍵/值對,鍵的型別必須是原子的,值可以是任何型別,同一個映射的鍵的型別必須相同,值得型別也必須相同
- Arrays:一組有序欄位,欄位的型別必須相同
深入閱讀:hive資料型別有哪些?
元資料保存方式
hive是建立在hadoop之上的資料倉庫,一般用于對大型資料集的讀寫和管理,存在hive里的資料實際上就是存在HDFS上,都是以檔案的形式存在,不能進行讀寫操作,所以我們需要元資料或者說叫schem來對hdfs上的資料進行管理,主要有以下三種方式:
-
內嵌模式:將元資料保存在本地內嵌的derby資料庫中,內嵌的derby資料庫每次只能訪問一個資料檔案,也就意味著它不支持多會話連接,
-
本地模式:將元資料保存在本地獨立的資料庫中(一般是mysql),這可以支持多會話連接,
-
遠程模式:把元資料保存在遠程獨立的mysql資料庫中,避免每個客戶端都去安裝mysql資料庫,
深入閱讀:Hive的架構及元資料三種存盤模式
內部表和外部表的區別
- 內部表: 未被external修飾的是內部表,建表時默認創建內部表,內部表資料由Hive自身管理,洗掉內部表會直接洗掉元資料(metadata)及存盤資料;對內部表的修改會將修改直接同步給元資料,
- 外部表:被external修飾的為外部表(external table);外部表資料由HDFS管理;洗掉外部表僅僅會洗掉元資料,HDFS上的檔案并不會被洗掉;
深入閱讀:Hive內部表和外部表的區別詳解
磁區表和分桶表的區別
-
磁區表,Hive 資料表可以根據某些欄位進行磁區操作,細化資料管理,讓部分查詢更快,不同磁區對應不同的目錄;
-
分桶表:表和磁區也可以進一步被劃分為桶,分桶是相對磁區進行更細粒度的劃分,分桶將整個資料內容按照某列屬性值的hash值進行區分,不同的桶對應不同的檔案,
深入閱讀:Hive的磁區表和分桶表的區別
簡述hive的存盤格式
- TextFile
TextFile檔案不支持塊壓縮,默認格式,資料不做壓縮,磁盤開銷大,資料決議開銷大, - SequenceFile格式
SequenceFile是Hadoop API 提供的一種二進制檔案,它將資料以的形式序列化到檔案中,這種二進制檔案內部使用Hadoop 的標準的Writable 介面實作序列化和反序列化,它與Hadoop API中的MapFile 是互相兼容的,Hive 中的SequenceFile 繼承自Hadoop API 的SequenceFile,不過它的key為空,使用value 存放實際的值, 這樣是為了避免MR 在運行map 階段的排序程序, - RCFile
Record Columnar的縮寫,是Hadoop中第一個列檔案格式,能夠很好的壓縮和快速的查詢性能,但是不支持模式演進,通常寫操作比較慢,比非列形式的檔案格式需要更多的記憶體空間和計算量,
RCFile是一種行列存盤相結合的存盤方式,首先,其將資料按行分塊,保證同一個record在一個塊上,避免讀一個記錄需要讀取多個block,其次,塊資料列式存盤,有利于資料壓縮和快速的列存取, - ORCFile
存盤方式:資料按行分塊 每塊按照列存盤 ,壓縮快 快速列存取,效率比rcfile高,是rcfile的改良版本,相比RC能夠更好的壓縮,能夠更快的查詢,但還是不支持模式演進,
深入閱讀:hive四種存盤格式介紹與分析比較
hive如何將Hql轉化為MapReduce
- 解釋器完成詞法、語法和語意的分析以及中間代碼生成,最終轉換成抽象語法樹;
- 編譯器將語法樹編譯為邏輯執行計劃;
- 邏輯層優化器對邏輯執行計劃進行優化,由于Hive最終生成的MapReduce任務中,Map階段和Reduce階段均由OperatorTree組成,所以大部分邏輯層優化器通過變換OperatorTree,合并運算子,達到減少MapReduce Job和減少shuffle資料量的目的;
- 物理層優化器進行MapReduce任務的變換,生成最終的物理執行計劃;
- 執行器呼叫底層的運行框架執行最終的物理執行計劃,
hive排序函式的區別
-
order by
order by 會對資料進行全域排序,和oracle和mysql等資料庫中的order by 效果一樣,它只在一個reduce中進行所以資料量特別大的時候效率非常低,
而且當設定 :set hive.mapred.mode=strict的時候不指定limit,執行select會報錯,如下:
LIMIT must also be specified, -
sort by
sort by 是單獨在各自的reduce中進行排序,所以并不能保證全域有序,一般和distribute by 一起執行,而且distribute by 要寫在sort by前面,
如果mapred.reduce.tasks=1和order by效果一樣,如果大于1會分成幾個檔案輸出每個檔案會按照指定的欄位排序,而不保證全域有序,
sort by 不受 hive.mapred.mode 是否為strict ,nostrict 的影響, -
distribute by
DISTRIBUTE BY 控制map 中的輸出在 reducer 中是如何進行劃分的,使用DISTRIBUTE BY 可以保證相同KEY的記錄被劃分到一個Reduce 中, -
cluster by
distribute by 和 sort by 合用就相當于cluster by,但是cluster by 不能指定排序為asc或 desc 的規則,只能是升序排列,
UDF相關內容
UDF(User-Defined Functions)即是用戶自定義的hive函式,當 Hive 自帶的函式并不能完全滿足業務的需求,這時可以根據具體需求自定義函式,UDF 函式可以直接應用于 select 陳述句,對查詢結構做格式化處理后,再輸出內容,
Hive 自定義函式包括三種:
- UDF: one to one ,進來一個出去一個,row mapping, 如:upper、substr函式;
- UDAF(A:aggregation): many to one,進來多個出去一個,row mapping,如sum/min;
- UDTF(T:table-generating):one to mang,進來一個出去多行,如 lateral view 與 explode ,
深入閱讀:【Hive】Hive UDF
故障排查與調優
資料傾斜與優化
什么是資料傾斜?
資料傾斜就是資料的分布不平衡,某些地方特別多,某些地方又特別少,導致在處理資料的時候,有些很快就處理完了,而有些又遲遲未能處理完,導致整體任務最終遲遲無法完成,這種現象就是資料傾斜,
發生資料傾斜的原因
-
key分布不均勻;
-
資料本身的特性,原本按照日期進行磁區,如果在特定日期資料量劇增,就有可能造成傾斜;
-
建表時考慮不周,磁區設定不合理或者過少;
-
某些 HQL 陳述句本身就容易產生資料傾斜,如 join,
以下操作可能會導致資料傾斜
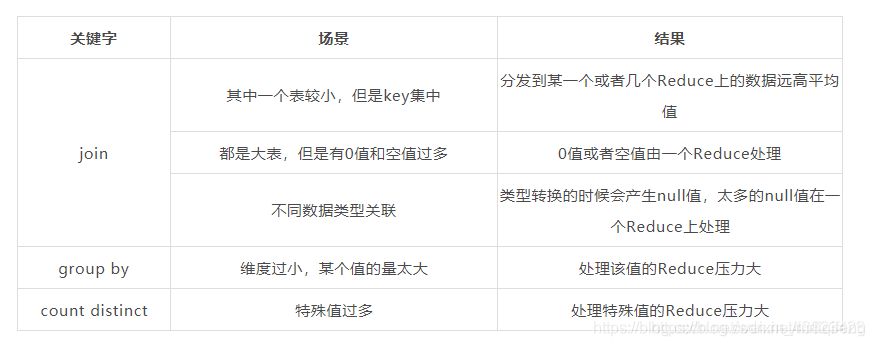
-
join
大小表join的時候,其中一個較小表的key集中,這樣分發到某一個或者幾個的Reduce上的資料就可能遠高于平均值;
兩張大表join的時候,如果有很多0值和空值,那么這些0值或者空值就會分到一個Reduce上進行處理;
join的時候,不同資料型別進行關聯,發生型別轉換的時候可能會產生null值,null值也會被分到一個Reduce上進行處理;
-
group by
進行分組的欄位的值太少,造成Reduce的數量少,相應的每個Reduce的壓力就大;
-
count distinct
count distinct的時候相同的值會分配到同一個Reduce上,如果存在特殊的值太多也會造成資料傾斜,
解決方法

深入閱讀:hive資料傾斜原因和解決方法
性能優化
深入閱讀:hive優化大全-一篇就夠了
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/255654.html
標籤:其他
上一篇:云版 Android 系統來了?
下一篇:Ubuntu下搭建第一臺hadoop輸入start-dfs.sh出現Permission denied (publickey,password)的問題