背景:
目前公司業務需要統計超過7天以上的特征統計,但是kafka只存7天的資料,如果只想通過flink sql去計算30天的用戶特征要求當天生效,這是完不成的,但是看到下面的分享,感覺未來的方向有了,
一、2021 Apache Flink Meetup - Hosted by Netflix 的youtobe視頻分享
目前這是Netflix的分享,目前還未將backfilling 的功能貢獻回 iceberg 社區
https://www.youtube.com/watch?v=rtz3p_iijP8&feature=youtu.be(第45分鐘開始)
二、簡單的截圖分享(重點看第四點)
1、標題

2、提高流利用資料的存活時間
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-gDutKmBv-1612260316010)(https://secure-static.wolai.com/static/gYWsDLFqQtkk91zogvqQ8Y/image.png)]
3、對比kafka和第三方存盤的價格優勢

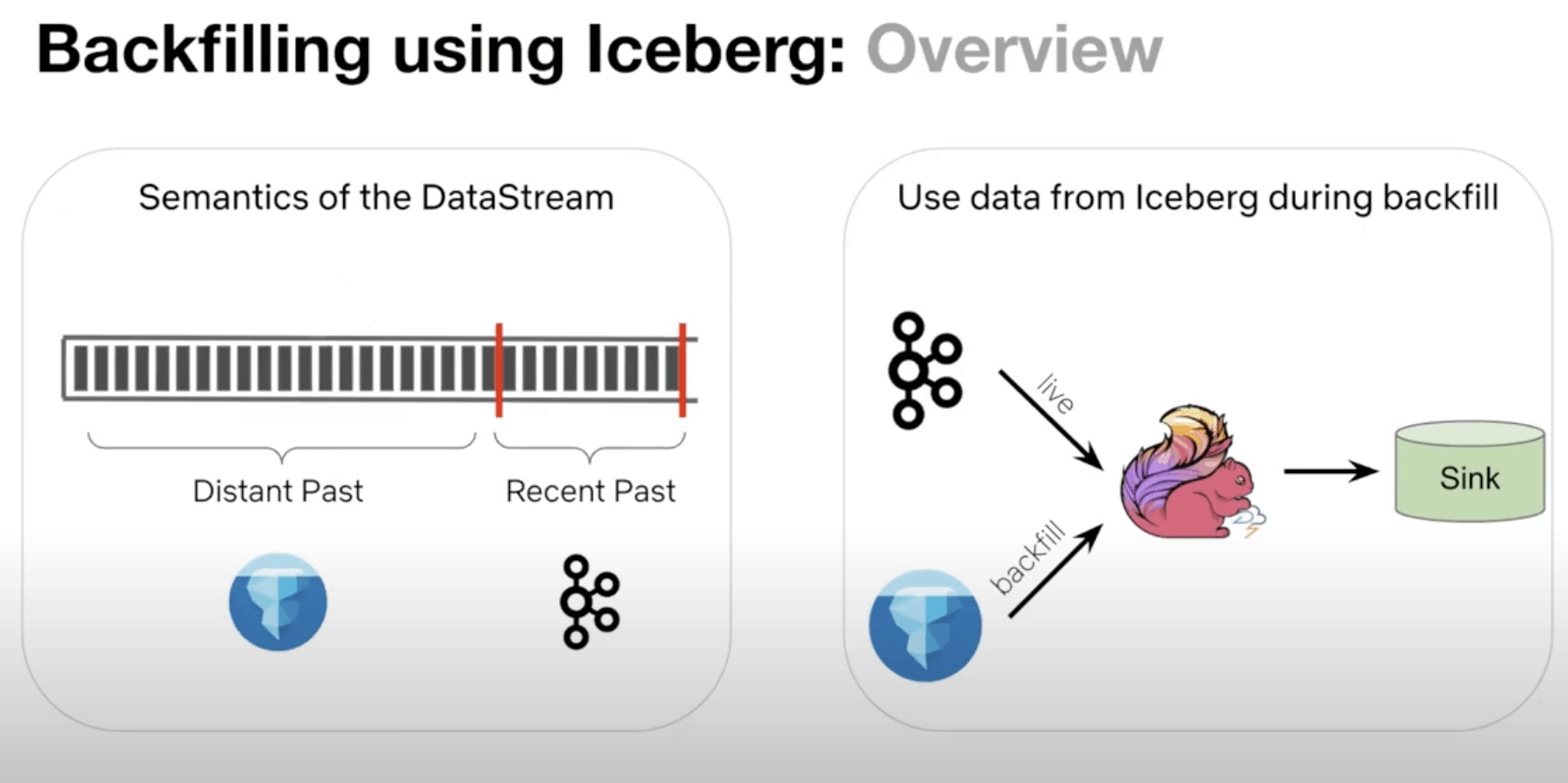
4、Backfilling在Iceberg的使用,這個是重點,能夠替代kafka存更多之前的資料,同時又能
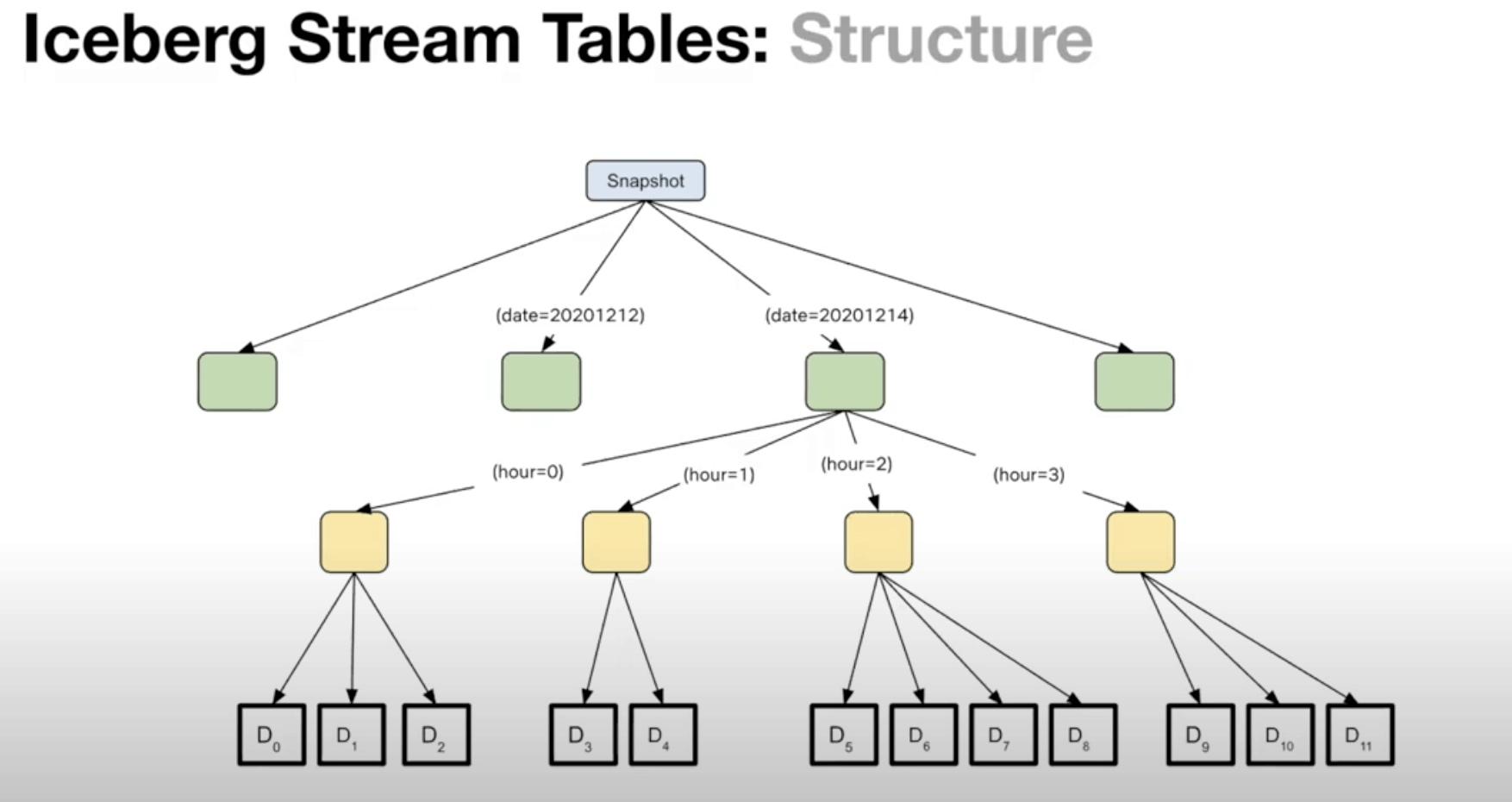
5、Iceberg的流表結構
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/255876.html
標籤:其他
上一篇:【PhotoScan精品教程】任務一:新建工程、匯入照片、設定坐標系、匯入控制點(POS)、自由空三
下一篇:Linux--常見指令操作