一、 背景
在問題檢索中,依賴文本相似度給用戶做推薦問題,假設1.0分為滿分,那么:
1.0分表示完全匹配:可以將問題準確推送給用戶
0.8分表示高度相似:可以將問題推薦給用戶
0.6分表示低度相似:......
根據這樣的規則對用戶的檢索做出回應,其實Lucene基于TF-IDF改造的相關度排序演算法也有分值,但是和業務所需要的相似度不貼合,所以其得分只作為第一步結果篩選依據,關于Lucene打分公式可以看看這篇文章,Lucene的原始碼也做過詳細決議,Lucene檢索原始碼決議(上)和Lucene檢索原始碼決議(下),感興趣的朋友可以研究一下,
二、萊文斯坦距離
文本相似度演算法有很多,我這里選擇的是編輯距離演算法-萊文斯坦距離(Levenshtein),它表示的是將一個字串a變換為另一個字串b,所需要的字符插入、洗掉、替換的次數,
對于字串a和b,分別用|a|和|b|代表其長度,那么他們的萊文斯坦距離表示為:,它符合:
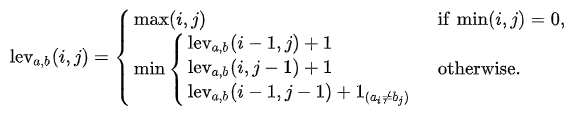
它表示,若a或b有一個是空串,那么距離為非空串的長度(max運算);否則,進入min運算,三個公式從上到下分別表示,從a中洗掉一個字符、往a中添加一個字符、字符替換,
第三個公式中的 ,是一個指示函式,它表示當
時為1,反之等于0,意思就是如果字符相同,則不用替換,如果字符不同,則需要1次替換,
比如將“kitten”一字轉成“sitting”的萊文斯坦距離為3(例子來自維基):
- kitten → sitten (k→s)
- sitten → sittin (e→i)
- sittin → sitting (插入g)
關于萊文斯坦距離的詳細內容,可以看看維基定義,這里就不贅述了,
三、相似度計算
結合業務之后,計算距離就不再是字符變更,而是詞,對于兩個文本,要先對內容做分詞,去除停頓詞等操作,分詞是詞法分析中最基本的任務,它把一個陳述句拆分為多個詞,特征提取一般也要建立在分詞的基礎上,其可以基于詞典、基于統計或者基于規則等,演算法也比較多,比如最大匹配、隱馬爾科夫模型等,不過分詞不是本章節的重點,
在分詞之后,萊文斯坦距離的計算目標就變成了:將一個詞串列變換為另一個詞串列,所需要的詞洗掉、添加、替換的次數(操作從字符變成了詞),但是這里要注意的是分詞結果的順序問題,在一些情況下,詞的順序是在一定程度上代表了語意的,比如:
分詞1:我 吃飯 后 回家
分詞2:我 回家 后 吃飯
字串本身是一個整體,按照字符拼接順序處理即可,但是分詞結果本身是一個詞的串列,所以要注意這個問題,
結合分詞之后,加入同義詞的邏輯就是:判斷需要一次替換操作的條件為:!item1.equals(items2) && 不是同義詞(item1,item2),即指示函式變更為:,
得到距離之后,按照要求做一個歸一化處理即可,所以我們需要考慮的問題就是如何歸一化處理和在兼容記憶體消耗下較高效率的判斷兩個詞是否為同義詞,
四、同義詞判定
出于對存盤和讀取效率的考慮,主要就是找到一個適合的資料結構實作字典功能,主要實作有:有序串列(查詢時使用二分法查找)、二叉排序樹、跳表、HashMap、FST等,出于多方面因素考慮,專案中使用的lucene中也有開源的FST實作,FST對于記憶體壓縮優勢較大,而查詢效率也較高,所以選擇使用FST作為字典實作比對同義詞,
注:FST,即Finite State Transducer,有窮狀態轉換器,其通過單詞前后綴的重復利用,最終生成一個無環圖,在很大的程度上減少了記憶體消耗,FST表示為字典結構:FST<key,value>時,只需要O(lengthOf(key))的時間復雜度,關于FST的細節,可自行查閱,
在當前實作中,我們已經根據同義詞庫創建好了FST,每個都詞有一個hash id,在初始化同義詞庫時,對于一個詞,使用幾個位元組存盤其同義詞的數量,然后將它們的hash id按照規則存盤在一起,方便讀取,這樣對于一個輸入詞,我們能快速獲取到其同義詞的hash id串列(多個同義詞),然后根據目標詞的hash id進行比對即可,查詢同義詞hash id串列的相關代碼片段如下:
ByteArrayDataInput reader = new ByteArrayDataInput(bytesRef.bytes, bytesRef.offset, bytesRef.length);
//獲取長度,如果多個位元組存盤了長度,在readVInt的時候自動遞增position
int size = reader.readVInt();
size >>= 1;
if (logger.isDebugEnabled()) {
logger.debug("[FST跟蹤]text:{},同義詞數量:{}", text, size);
}
//獲取所有同義詞的hash id
int[] results = new int[size];
int index = 0;
while (!reader.eof()) {
results[index++] = reader.readVInt();
}
return results;注:同義詞庫記錄了同義詞關系,可以是檔案或者資料表等等,其表征了哪些詞互為同義詞,比如在檔案中,將屬于同義詞的詞列在同一排:
晚上 黑夜 夜間
吃飯 進食 干飯
在指示函式的實作中,根據hash id進行比對就可以了:
private boolean isSynonyms(int[] outputs, int hash) {
//如果同義詞較多的話,可以優化匹配方式,這里演示就直接遍歷,O(n)
if (outputs != null && hash > 0) {
for (int output : outputs) {
if (output == hash) {
return true;
}
}
}
return false;
}五、歸一化演算法
編輯距離的結果是距離,表征為一個數值,但是我們需要的是一個分值score(0.0<=score<=1.0)來表征相似度,所以需要做歸一化處理,這里首先考慮使用線性函式進行歸一化處理,標準的線性歸一化處理公式為:,將原始資料進行等比例縮放,
在此處的距離中,簡化處理為:,其中cost為消耗步數,maxSize(word)為最長詞串列長度,對于兩個陳述句,變換距離(cost)越大,就代表越不相似,所以最終得分公式為:
,
現在需要考慮另外一個問題,編輯距離是一個量化的結果,其本身表征的意義和我們的直觀感受結果可能有所不同,特別是在極端情況下,比如以下兩個陳述句:
陳述句:回家吃飯 分詞結果:回家 吃飯
陳述句:回家種花 分詞結果:回家 種花
根據編輯距離演算法,他們的相似度得分為0.5分,從理性上講,他們有一半的詞是相同的,那么0.5分可以理解,工程化后,從感性上講,如果陳述句很長(分詞串列很長),0.5分的相似度似乎并不足以我們推薦給用戶,但是對于上面這種情況,雖然是0.5分,但是由于陳述句本身很短,也是值得我們推薦給用戶的,也就需要對這種情況特殊處理(提高其分值),但是不能影響其它情況,所以需要設計貼合業務的歸一化演算法,由于新演算法業務強相關,這里就不貼出來了,
六、實作
@Override
public double similarScore(List<String> words1, List<String> words2, Long companyId) throws Exception {
if (words1 == null || words2 == null) {
return 0.0D;
}
double costs;
double maxLength;
//首先判斷極端情況的距離
if (words1 == null) {
costs = words2.size();
maxLength = costs;
} else if (words2 == null) {
costs = words1.size();
maxLength = costs;
} else {
//都不為空
String[] s_segs = words1.toArray(new String[]{});
words1.clear();
String[] t_segs = words2.toArray(new String[]{});
words2.clear();
maxLength = Math.max(s_segs.length, t_segs.length);
//使用兩個一維陣列迭代實作
if (s_segs.length < t_segs.length) {
// 為了節約記憶體,將元素較少的串列當做目標串列
String[] tmp = s_segs;
s_segs = t_segs;
t_segs = tmp;
}
int s_length = s_segs.length;
int t_length = t_segs.length;
int pre[] = new int[t_length + 1]; //保存前一行記錄
int current[] = new int[t_length + 1]; //當前行記錄
int[] tmp;//用以交換pre和current
//初始化第一行
for (int i = 0; i < pre.length; i++) {
pre[i] = i;
}
//迭代計算
String s_w;
String t_w;
int cost;
for (int i = 1; i <= s_length; i++) {
//第一列的值設定為j
current[0] = i;
s_w = s_segs[i - 1];
//計算一行的值
for (int j = 1; j <= t_length; j++) {
t_w = t_segs[j - 1];
//指示函式的實作
if (s_w.equals(t_w) || isMutualSynonyms(companyId, s_w, t_w)) {
cost = 0;
} else {
cost = 1;
}
//從新增、洗掉、替換中選取最小值
current[j] = Math.min(Math.min(current[j - 1] + 1, pre[j] + 1), pre[j - 1] + cost);
}
//將當前行設定為前一行的值,為下次做準備
tmp = pre;
pre = current;
current = tmp;
}
costs = pre[t_length];
}
return normalization(costs, maxLength);
}
private double normalization(double costs, double max) {
return 1 - (costs / max);
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/255878.html
標籤:其他
上一篇:Linux--常見指令操作