今年10-11月份參加了EDA2020(第二屆)集成電路EDA設計精英挑戰賽,通過了初賽,并參加了總決賽,最后拿了一個三等獎,雖然成績不是很好,但是想把自己做的分享一下,我所做的題目是概倫電子出的F題-快速電路仿真器(FastSPICE)中的高性能矩陣向量運算實作,下面我將給出自己的實作方案,僅供參考,
1、題目描述與分析
1.1、賽題敘述
首先先把題目寫出來:
在晶體管級電路瞬態仿真程序中,仿真器需要根據電路連接關系并結合 KCL、KVL 定理建立微分方程,然后求解離散化的方程,中間每個步長輸出電壓和電流的仿真結果,在瞬態仿真中的每個步長都會涉及到大量的矩陣向量運算,例如電流輸出的計算,需要計算很多條支路電流并求和,矩陣向量運算在整個仿真中占據了相當比例的仿真時間,尤其是針對存盤器(memory)電路的快速電路仿真器(FastSPICE),因此,加速矩陣向量運算可以直接提高電路的仿真速度, 電路方程的矩陣大小與電路的節點個數成正比,比如,大型的存盤器電路(DRAM, Flash,SRAM 等等),其維度可達到 1000 萬以上,如此高維度的矩陣以普通二維陣列的方式存盤會消耗巨大的記憶體,由于電路的每個節點通常只與少數節點有連接關系,因此電路方程矩陣通常是稀疏度很高的稀疏矩陣,稀疏矩陣特有的存盤方式僅包含矩陣中的非零元素,可大大減少記憶體的消耗量,為存盤高維度的矩陣提供可能,稀疏矩陣的矩陣向量運算與普通的矩陣向量運算略有不同,對整體運算速度有較明顯的影響,希望參賽者能夠開發一種針對電路方程的高效矩陣向量運算方案和實作,減少運算時間,從而提高電路仿真速度, 本賽題要求參賽隊完成快速電路仿真器 (FastSPICE)中的相關支路電流計算任務,其中電路元件的電導將構成 N×N 階稀疏矩陣,節點電壓組成 N×1 階矩陣,其計算過 程包含以下矩陣運算: ????×1 = ????×??????×1 (1) ????×1 = ????×1 ? ????×??????×1 (2) ????×?? = ????×?? + ????×?? (3) 其中稀疏矩陣的存盤方式采用 Compressed Sparse Row(CSR)格式,由 3 個陣列??????_????????????、????????????_??????????????和????????????組成(如圖 1 所示),CSR 格式僅對稀疏矩陣中非零元進行存盤,其中????????????_??????????????和????????????兩個陣列分別按行依次存盤矩陣中非零元的列值和數值,??????_????????????表示某一行的第一個非零元在????????????陣列里的偏移位置,??????_????????????陣列的長度為矩陣行數+1,????????????_??????????????和????????????兩個陣列的長度相同,為矩陣中非零元的個數,設稀疏矩陣第??行(?? = 0, 1, 2, … , ??)的第一個零元的偏移位置為??????_????????????[??] = ????,第?? + 1行的第一個非零元的偏移位置為??????_????????????[?? + 1] = ????+1 , 則 第 ?? 行 的 非 零 元 的 列 值 和 數 值 分 別 為????????????_??????????????[??], ????????????[??], ?? ∈ [????, ????+1),且第??行的非零元的個數為????+1 ? ????,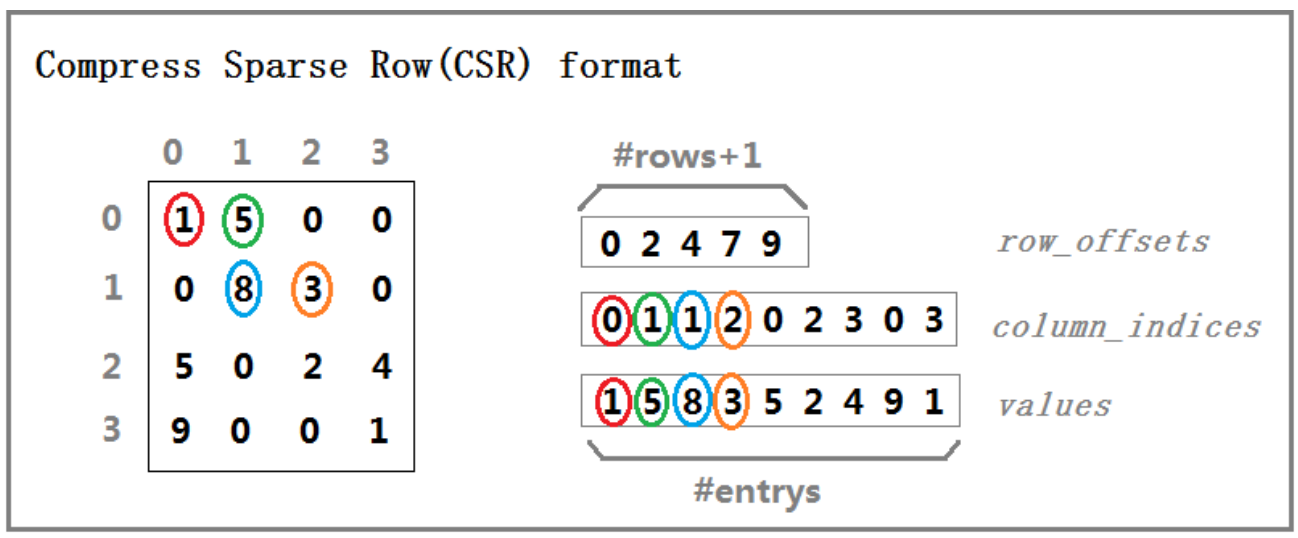
圖1 CSR結構
1.2 、賽題分析
本賽題的描述十分簡單,要求完成一個矩陣-向量相乘的計算程式,選手們的程式的輸入是一系列大小不一的矩陣和與矩陣尺寸匹配的向量,程式需要在保證準確性的情況下,用最短的時間把矩陣與向量相乘的結果寫到記憶體指定的位置,
(1).API會一次性給定多個矩陣(數量<1024),每個矩陣會有一個對應的向量,選手的任務就是計算每個矩陣和向量的乘積,
(2).給定的每一個稀疏矩陣,其規模都不是特別大,最大的矩陣不會超過10000x10000,
個人思路:這道題目,需要實作double精度,且評分標準為60%看效率,30%看程式運行記憶體占有量,10%創新點,因此我們需要搞清楚CSR格式的結構,利用結構體指標實作double精度;而提高程式性能,可以從并行、指令集和快取優化角度進行優化,
1)并行計算
并行計算大家都比較容易理解,所謂三個臭皮匠頂一個諸葛亮,一個大任務如果能夠切分成若干個子任務,每人完成一個,那么總的時間一般都能夠減少,并行計算的關鍵訣竅,在于【盡可能減少不同子任務之間的依賴性】,一個極端的例子,如果N個子任務之間完全不存在依賴性,各自獨立同時進行,那么這N個子任務完成的總時間與一個子任務完成的時間相同,這種情況下,我們可以認為并行的加速比為N,這個加速比是相對不并行的情況而言的,另外一個極端的例子,如果第2個子任務所需要的資料需要等第1個子任務完成才能得到,第3個子任務所需要的資料需要等第2個子任務完成才能得到,依次類推,那么這種情況,哪怕再多的人來參與這個任務,大部分的人,在大部分時間都只是在等待,這樣就無法從并行得到任何好處,一個良好的并行計算程式,需要去挖掘問題中的并行性,也就是設計并行計算方法,減少子任務之間的依賴性,那么這個題目中,你覺得怎樣的并行是最優的呢?
2)指令集優化
我們平時寫程式的時候,一般情況不會涉及到極致的性能要求,這種情況下一般不需要考慮在指令集層面進行優化,遇到像矩陣運算這一類十分底層的計算,就需要想盡一切辦法,榨干CPU的最后一點算力來提高我們程式的性能,現代的CPU中,都有SIMD的指令集,例如x86體系的SSE/AVX指令集等,所謂SIMD(Single Instruction Multiple Data)指令集指的是同一條指令,同時作用在不同的資料上,這樣可以實作指令集意義上的并行計算,需要注意的事情是,SIMD指令集并不能夠自動的讓你的程式實作加速,他需要你先將你的資料用規則的方式準備好,而稀疏矩陣的資料,本身是不規則的,也就是說非0元素有可能在任意位置,那么怎么把這些資料處理成規則的,使得SIMD指令集可以同時處理多個資料,需要各位選手自己去琢磨了,還有一點需要注意的是,將非規則的資料處理成規則的,這件事情本身也是需要額外消耗時間的,如果處理的不好,SIMD得到的收益,說不定都被這個額外消耗的時間抵消掉了,此外,除了SIMD之外,是否還有其他的指令集,可以用于稀疏矩陣運算的優化呢?這個是個開放的問題,需要大家自己調研,嘗試,
3)快取優化
除了并行計算和指令集優化這兩個賽題中給了提示的方向,其實還有一個方向,各位同學有必要去考慮,那就是快取優化,在計算機中,CPU與DRAM記憶體之間存取資料,速度是很慢的,因此現代的CPU一般都具有多級快取,快取的使用是CPU內部的事情,我們在程式中多數情況下不會直接操作快取,然而,這并不意味著我們無法對快取進行優化,如果能夠了解CPU對快取的存取策略,我們就可以設計良好的程式,使得快取的命中率提高,這樣就可以提高程式的性能,
1.3、實作思路
快速電路仿真器(FastSPICE)中的高性能矩陣向量運算實作演算法主要分為兩個實作演算法,分別為 matrix_calc_taskA 和 matrix_calc_taskB,演算法實作主要由電路元件電導構成的 N*N 階稀疏矩陣和節點電壓構成的 N*1 階矩陣,計算程序主要由三個矩陣運算構成,分別為: Rn*1=An*nSn*1(1) Hn*1=Ln*1-Gn*nSn*1 (2) En*n=Gn*n+Cn*n(3) 對于 matrix_calc_taskA 演算法,主要實作針對于式(1)計算內容中的其中計算方法: Idn*1=An*nSn*1(6) 而對于 matrix_calc_taskB 實作主要有式(1)以及式(2)、式(3)匯出的計算任務: IGn*1=Gn*nSn*1(4) ICn*1=Cn*nSn*1(5) Rn*1=Dn*1-Gn*nSn*1(7) Hn*1=D’n*1-Cn*nSn*1(8) An*n=Gn*n+aCn*n(9) 通過制作生成 matrix_calc_taskA、matrix_calc_taskB 元件.so,給出電路方程的高效矩陣向量運算方案、具體實作及測驗結果,實作了減少運算時間,提高電路仿真速度的目標,2、技術路線和實作方式
2.1、matrix_calc_taskA 演算法實作 外層回圈指向所要計算的矩陣,通過矩陣階數引數來劃分執行緒數,呼叫 future 頭檔案實作多執行緒機制,使用特殊的 provider 進行資料的異步訪問,從而實作執行緒間的通信,第一內層回圈開始就逐漸添加到執行緒當中,每一個執行緒的開始索引地址為矩陣階數/執行緒數*執行緒索引(第幾個執行緒所要作業的起始地址),計算矩陣行數而不在回圈當中計算索引數,第二個內層回圈計算矩陣行索引,并計算索引行在偏移量陣列當中的偏移數,第三層回圈則通過偏移量回圈與另一個目標向量計算得出結果,最終實作 Idn*1=An*nSn*1(6) 式,完成任務A,流程圖如圖2 所示,每一個執行緒都分攤一定作業量,并呼叫每一個執行緒的 wait 方法并發執行,每一個執行緒執 行 的 過 程 中 , 在 計 算 (6)過 程 中 用 到 了 AVX 指 令 集 , 通 過 使 用 AVX 指 令 集 中__mm256__loadu__pd、__mm256__mul__pd 等函式一步進行運算,加速實作 Idn*1=An*nSn*1,不需要等待普通回圈中回圈執行同樣的操作,部分實作代碼如下,1 std::future<void> ft1 = async(std::launch::async,[&](){ 2 int count_maxtrix = 0; ////to store ---->size 3 4 5 unsigned it = 0; //to store ---->rowArraySize 6 7 int node = 0; //to store ---->rowArray[] 8 int j = 0; //to store ---->rowOffset[] 9 10 // add here to enhance the speed 11 int my_rowArraysize = 0; 12 int my_rowOffset = 0; 13 14 int maxtrix_begin = size/16; 15 int maxtrix_end = size/16*2; 16 17 18 __m256d ID_m; 19 __m256d ID_mm; 20 __m256d NormalMatrix_m; 21 __m256d columnIndice_m; 22 __m256d mux_m; 23 24 //double S_array[4]; 25 int S_count; 26 double ID_array[4]; 27 28 bool ready = 0; 29 30 for (count_maxtrix = maxtrix_begin; count_maxtrix < maxtrix_end; ++count_maxtrix) 31 { 32 33 my_rowArraysize = (*(ptr+count_maxtrix))->rowArraySize; 34 //for (it = 0; it < (*(ptr+count_maxtrix))->rowArraySize; ++it) 35 for (it = 0; it < my_rowArraysize; ++it) 36 { 37 node = (*(ptr+count_maxtrix))->rowArray[it]; 38 39 //for (j = (*(ptr+count_maxtrix))->rowOffset[node]; j < (*(ptr+count_maxtrix))->rowOffset[node + 1]; ++j) 40 my_rowOffset = (*(ptr+count_maxtrix))->rowOffset[node + 1]; 41 42 43 44 j = (*(ptr+count_maxtrix))->rowOffset[node]; 45 46 47 48 while((int)((my_rowOffset-j)/4) > 1) 49 { 50 columnIndice_m =_mm256_set_pd((*(ptr+count_maxtrix))->S[(*(ptr+count_maxtrix))->columnIndice[j+3]], 51 (*(ptr+count_maxtrix))->S[(*(ptr+count_maxtrix))->columnIndice[j+2]], 52 (*(ptr+count_maxtrix))->S[(*(ptr+count_maxtrix))->columnIndice[j+1]], 53 (*(ptr+count_maxtrix))->S[(*(ptr+count_maxtrix))->columnIndice[j]] ); 54 //ID_m = _mm256_load_pd((*(ptr+count_maxtrix))->Id+j); 55 NormalMatrix_m = _mm256_loadu_pd((*(ptr+count_maxtrix))->valueNormalMatrix+j); 56 57 58 59 mux_m = _mm256_mul_pd(NormalMatrix_m, columnIndice_m); 60 61 //ID_mm = _mm256_add_pd(ID_m, mux_m); 62 63 _mm256_storeu_pd(ID_array, mux_m); 64 65 for(S_count = 0; S_count < 4; S_count++) 66 { 67 (*(ptr+count_maxtrix))->Id[node] += ID_array[S_count]; 68 } 69 70 ready = 1; 71 72 j += 4; 73 } 74 75 if(ready == 1) 76 { 77 //for (; j < my_rowOffset; ++j) 78 while(j < my_rowOffset) 79 { 80 (*(ptr+count_maxtrix))->Id[node] += (*(ptr+count_maxtrix))->valueNormalMatrix[j] * (*(ptr+count_maxtrix))->S[(*(ptr+count_maxtrix))->columnIndice[j]]; 81 ++j; 82 } 83 ready = 0; 84 } 85 else 86 { 87 //for (; j < my_rowOffset; ++j) 88 while(j < my_rowOffset) 89 { 90 (*(ptr+count_maxtrix))->Id[node] += (*(ptr+count_maxtrix))->valueNormalMatrix[j] * (*(ptr+count_maxtrix))->S[(*(ptr+count_maxtrix))->columnIndice[j]]; 91 ++j; 92 } 93 } 94 95 } 96 } 97 });
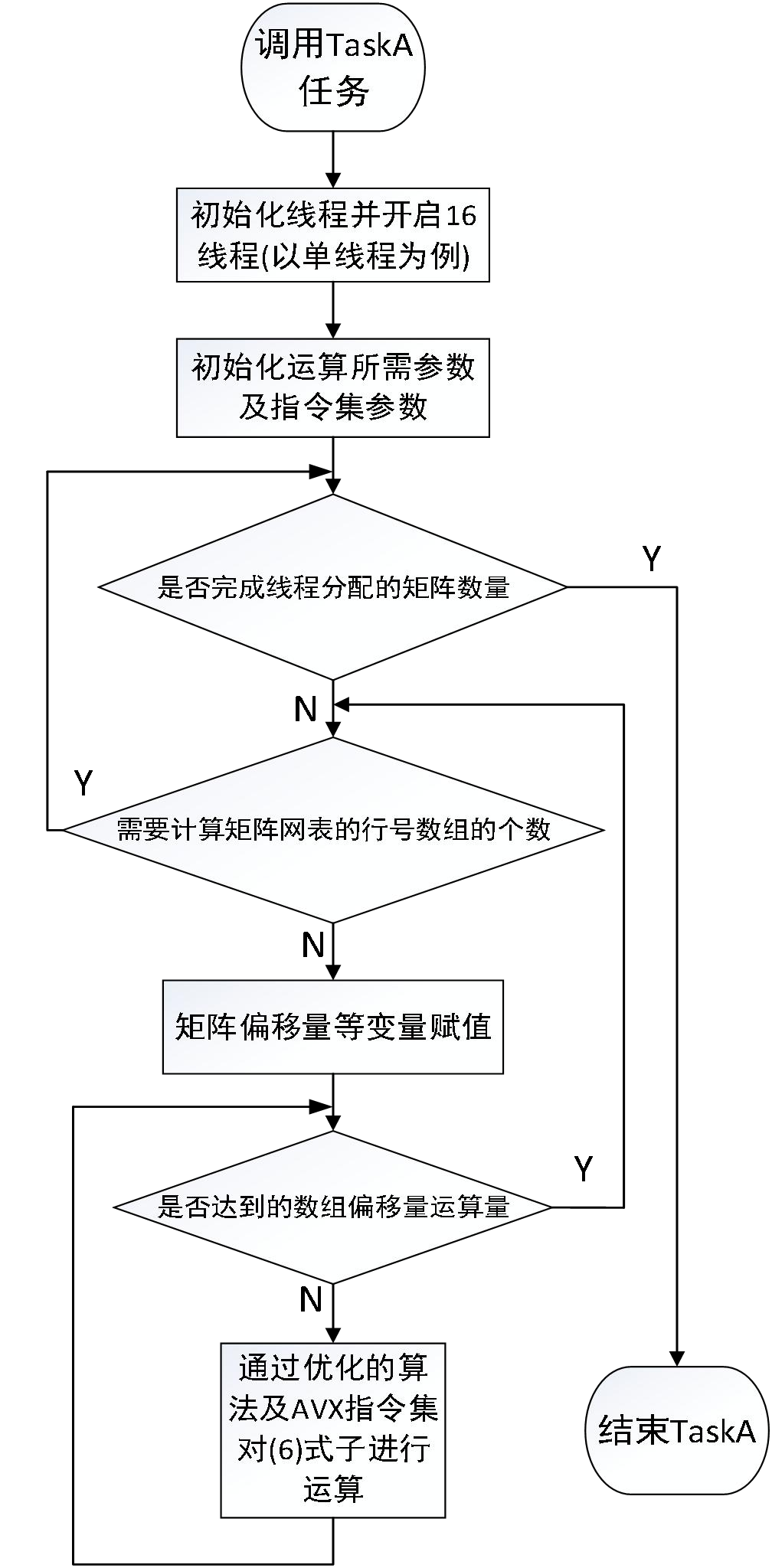
圖2 TaskA實作流程圖
1 std::future<void> ft16 = async(std::launch::async,[&](){ 2 3 int count_maxtrix = 0; ////to store ---->size 4 5 int it = 0; //to store ---->rowArraySize 6 int p = 0; //to store ---->rowOffset 7 8 int row = 0; //to store ---->rowArray[x] 9 int k = 0; //to store ---->rowOffset*2 10 11 int col = 0; //to store ---->columnIndice 12 13 double cond = 0; //to store ---->valueSpiceMatrix[k] 14 double cap = 0; //to store ---->valueSpiceMatrix[k+1] 15 16 17 18 /* 19 function:Just for example ,for formula(7 8) 20 Rnx1 = Dnx1 - Gnxn*Snx1 21 Hnx1 = D'nx1 - Cnxn*Snx1 22 */ 23 int kl = 0; //to store ---->rowArray[]*2 24 double current = 0; //to store ---->D[kl] 25 double charge = 0; //to store ---->D[kl+1] 26 27 28 // add here to enhance the speed 29 int my_rowArraysize = 0; 30 int my_rowOffset = 0; 31 double my_s = 0; 32 33 int maxtrix_begin = size/16*7; 34 int maxtrix_end = size/16*8; 35 36 37 __m256d cond_m; 38 __m256d cap_m; 39 __m256d IG_Curr_m; 40 __m256d IC_Char_m; 41 __m256d A_m; 42 43 double IG_Curr_array[4]; 44 double IC_Char_array[4]; 45 double A_m_array[4]; 46 int u_count; 47 bool ready = 0; 48 49 for (count_maxtrix = maxtrix_begin; count_maxtrix < maxtrix_end; ++count_maxtrix) 50 { 51 52 //for (it = 0; it < (*(ptr+count_maxtrix))->rowArraySize; ++it) 53 my_rowArraysize = (*(ptr+count_maxtrix))->rowArraySize; 54 for (it = 0; it < my_rowArraysize; ++it) 55 { 56 //…………………………………………formula(4 5)、(7 8)、(9) Share a for Loop……………………………………………………………… 57 /* 58 Function:Just for example ,for formula(4 5) 59 IGnx1 = Gnxn*Snx1 60 ICnx1 = Cnxn*Snx1 61 */ 62 row = (*(ptr+count_maxtrix))->rowArray[it]; //share 63 64 65 66 67 /* 68 function:Just for example ,for formula(7 8) 69 Rnx1 = Dnx1 - Gnxn*Snx1 70 Hnx1 = D'nx1 - Cnxn*Snx1 71 */ 72 kl = row * 2; 73 74 current = (*(ptr+count_maxtrix))->D[kl]; 75 charge = (*(ptr+count_maxtrix))->D[kl + 1]; 76 77 78 79 //for (p = (*(ptr+count_maxtrix))->rowOffset[row]; p < (*(ptr+count_maxtrix))->rowOffset[row + 1]; ++p) 80 my_rowOffset = (*(ptr+count_maxtrix))->rowOffset[row + 1]; 81 82 83 p = (*(ptr+count_maxtrix))->rowOffset[row]; 84 //for (p = (*(ptr+count_maxtrix))->rowOffset[row]; p < my_rowOffset; ++p) 85 while((int)((my_rowOffset-p)/4) > 1) 86 { 87 //col = (*(ptr+count_maxtrix))->columnIndice[p]; 88 k = p * 2; 89 //cond = (*(ptr+count_maxtrix))->valueSpiceMatrix[k]; 90 //cap = (*(ptr+count_maxtrix))->valueSpiceMatrix[k + 1]; 91 92 93 94 /* 95 Function:Just for example ,for formula(4 5) 96 IGnx1 = Gnxn*Snx1 97 ICnx1 = Cnxn*Snx1 98 */ 99 100 //my_s = (*(ptr+count_maxtrix))->S[col]; 101 102 //_mm256_blend_pd (__m256d a, __m256d b, const int imm8); 103 104 cond_m = _mm256_set_pd((*(ptr+count_maxtrix))->valueSpiceMatrix[k+6], 105 (*(ptr+count_maxtrix))->valueSpiceMatrix[k+4], 106 (*(ptr+count_maxtrix))->valueSpiceMatrix[k+2], 107 (*(ptr+count_maxtrix))->valueSpiceMatrix[k]); 108 109 110 cap_m = _mm256_set_pd((*(ptr+count_maxtrix))->valueSpiceMatrix[k + 7], 111 (*(ptr+count_maxtrix))->valueSpiceMatrix[k + 5], 112 (*(ptr+count_maxtrix))->valueSpiceMatrix[k + 3], 113 (*(ptr+count_maxtrix))->valueSpiceMatrix[k + 1]); 114 /* 115 alpha_m = _mm256_set_pd((*(ptr+count_maxtrix))->alpha, 116 (*(ptr+count_maxtrix))->alpha, 117 (*(ptr+count_maxtrix))->alpha, 118 (*(ptr+count_maxtrix))->alpha); 119 120 my_s_m = _mm256_set_pd((*(ptr+count_maxtrix))->S[(*(ptr+count_maxtrix))->columnIndice[p+3]] 121 ,(*(ptr+count_maxtrix))->S[(*(ptr+count_maxtrix))->columnIndice[p+2]] 122 ,(*(ptr+count_maxtrix))->S[(*(ptr+count_maxtrix))->columnIndice[p+1]] 123 ,(*(ptr+count_maxtrix))->S[(*(ptr+count_maxtrix))->columnIndice[p]]); */ 124 125 IG_Curr_m = _mm256_mul_pd(cond_m 126 ,_mm256_set_pd((*(ptr+count_maxtrix))->S[(*(ptr+count_maxtrix))->columnIndice[p+3]] 127 ,(*(ptr+count_maxtrix))->S[(*(ptr+count_maxtrix))->columnIndice[p+2]] 128 ,(*(ptr+count_maxtrix))->S[(*(ptr+count_maxtrix))->columnIndice[p+1]] 129 ,(*(ptr+count_maxtrix))->S[(*(ptr+count_maxtrix))->columnIndice[p]])); 130 IC_Char_m = _mm256_mul_pd(cap_m 131 ,_mm256_set_pd((*(ptr+count_maxtrix))->S[(*(ptr+count_maxtrix))->columnIndice[p+3]] 132 ,(*(ptr+count_maxtrix))->S[(*(ptr+count_maxtrix))->columnIndice[p+2]] 133 ,(*(ptr+count_maxtrix))->S[(*(ptr+count_maxtrix))->columnIndice[p+1]] 134 ,(*(ptr+count_maxtrix))->S[(*(ptr+count_maxtrix))->columnIndice[p]])); 135 136 A_m = _mm256_add_pd(cond_m, _mm256_mul_pd(_mm256_set_pd((*(ptr+count_maxtrix))->alpha, 137 (*(ptr+count_maxtrix))->alpha, 138 (*(ptr+count_maxtrix))->alpha, 139 (*(ptr+count_maxtrix))->alpha) 140 ,cap_m)); 141 142 143 _mm256_storeu_pd(IG_Curr_array, IG_Curr_m); 144 _mm256_storeu_pd(IC_Char_array, IC_Char_m); 145 _mm256_storeu_pd(A_m_array, A_m); 146 147 148 for(u_count = 0; u_count < 4; u_count++) 149 { 150 //(*(ptr+count_maxtrix))->Id[node] += ID_array[S_count]; 151 152 (*(ptr+count_maxtrix))->IG[row] += IG_Curr_array[u_count]; 153 (*(ptr+count_maxtrix))->IC[row] += IC_Char_array[u_count]; 154 155 /* 156 current -= (*(ptr+count_maxtrix))->valueSpiceMatrix[k] * (*(ptr+count_maxtrix))->S[col]; 157 charge -= (*(ptr+count_maxtrix))->valueSpiceMatrix[k + 1] * (*(ptr+count_maxtrix))->S[col]; 158 */ 159 current -= IG_Curr_array[u_count]; 160 charge -= IC_Char_array[u_count]; 161 162 163 /* 164 function:Just for example ,for formula(9) 165 Anxn = Gnxn + alpha*Cnxn 166 */ 167 (*(ptr+count_maxtrix))->A[p+u_count] = A_m_array[u_count]; 168 } 169 170 171 ready = 1; 172 p += 4; 173 174 } 175 176 if(ready == 1) 177 { 178 //for (; j < my_rowOffset; ++j) 179 while(p < my_rowOffset) 180 { 181 col = (*(ptr+count_maxtrix))->columnIndice[p]; 182 k = p * 2; 183 cond = (*(ptr+count_maxtrix))->valueSpiceMatrix[k]; 184 cap = (*(ptr+count_maxtrix))->valueSpiceMatrix[k + 1]; 185 186 187 188 /* 189 Function:Just for example ,for formula(4 5) 190 IGnx1 = Gnxn*Snx1 191 ICnx1 = Cnxn*Snx1 192 */ 193 194 my_s = (*(ptr+count_maxtrix))->S[col]; 195 (*(ptr+count_maxtrix))->IG[row] += cond * my_s; 196 (*(ptr+count_maxtrix))->IC[row] += cap * my_s; 197 198 199 200 201 /* current -= (*(ptr+count_maxtrix))->valueSpiceMatrix[k] * (*(ptr+count_maxtrix))->S[col]; 202 charge -= (*(ptr+count_maxtrix))->valueSpiceMatrix[k + 1] * (*(ptr+count_maxtrix))->S[col]; 203 */ 204 current -= cond * my_s; 205 charge -= cap * my_s; 206 207 208 /* 209 function:Just for example ,for formula(9) 210 Anxn = Gnxn + alpha*Cnxn 211 */ 212 (*(ptr+count_maxtrix))->A[p] = cond + (*(ptr+count_maxtrix))->alpha * cap; 213 ++p; 214 } 215 ready = 0; 216 } 217 else 218 { 219 //for (; j < my_rowOffset; ++j) 220 while(p < my_rowOffset) 221 { 222 col = (*(ptr+count_maxtrix))->columnIndice[p]; 223 k = p * 2; 224 cond = (*(ptr+count_maxtrix))->valueSpiceMatrix[k]; 225 cap = (*(ptr+count_maxtrix))->valueSpiceMatrix[k + 1]; 226 227 228 229 /* 230 Function:Just for example ,for formula(4 5) 231 IGnx1 = Gnxn*Snx1 232 ICnx1 = Cnxn*Snx1 233 */ 234 235 my_s = (*(ptr+count_maxtrix))->S[col]; 236 (*(ptr+count_maxtrix))->IG[row] += cond * my_s; 237 (*(ptr+count_maxtrix))->IC[row] += cap * my_s; 238 239 240 241 242 /* current -= (*(ptr+count_maxtrix))->valueSpiceMatrix[k] * (*(ptr+count_maxtrix))->S[col]; 243 charge -= (*(ptr+count_maxtrix))->valueSpiceMatrix[k + 1] * (*(ptr+count_maxtrix))->S[col]; 244 */ 245 current -= cond * my_s; 246 charge -= cap * my_s; 247 248 249 /* 250 function:Just for example ,for formula(9) 251 Anxn = Gnxn + alpha*Cnxn 252 */ 253 (*(ptr+count_maxtrix))->A[p] = cond + (*(ptr+count_maxtrix))->alpha * cap; 254 255 ++p; 256 } 257 } 258 259 260 /* 261 function:Just for example ,for formula(7 8) 262 Rnx1 = Dnx1 - Gnxn*Snx1 263 Hnx1 = D'nx1 - Cnxn*Snx1 264 */ 265 (*(ptr+count_maxtrix))->R[row] = current; 266 (*(ptr+count_maxtrix))->H[row] = charge; 267 268 269 270 271 } 272 } 273 });
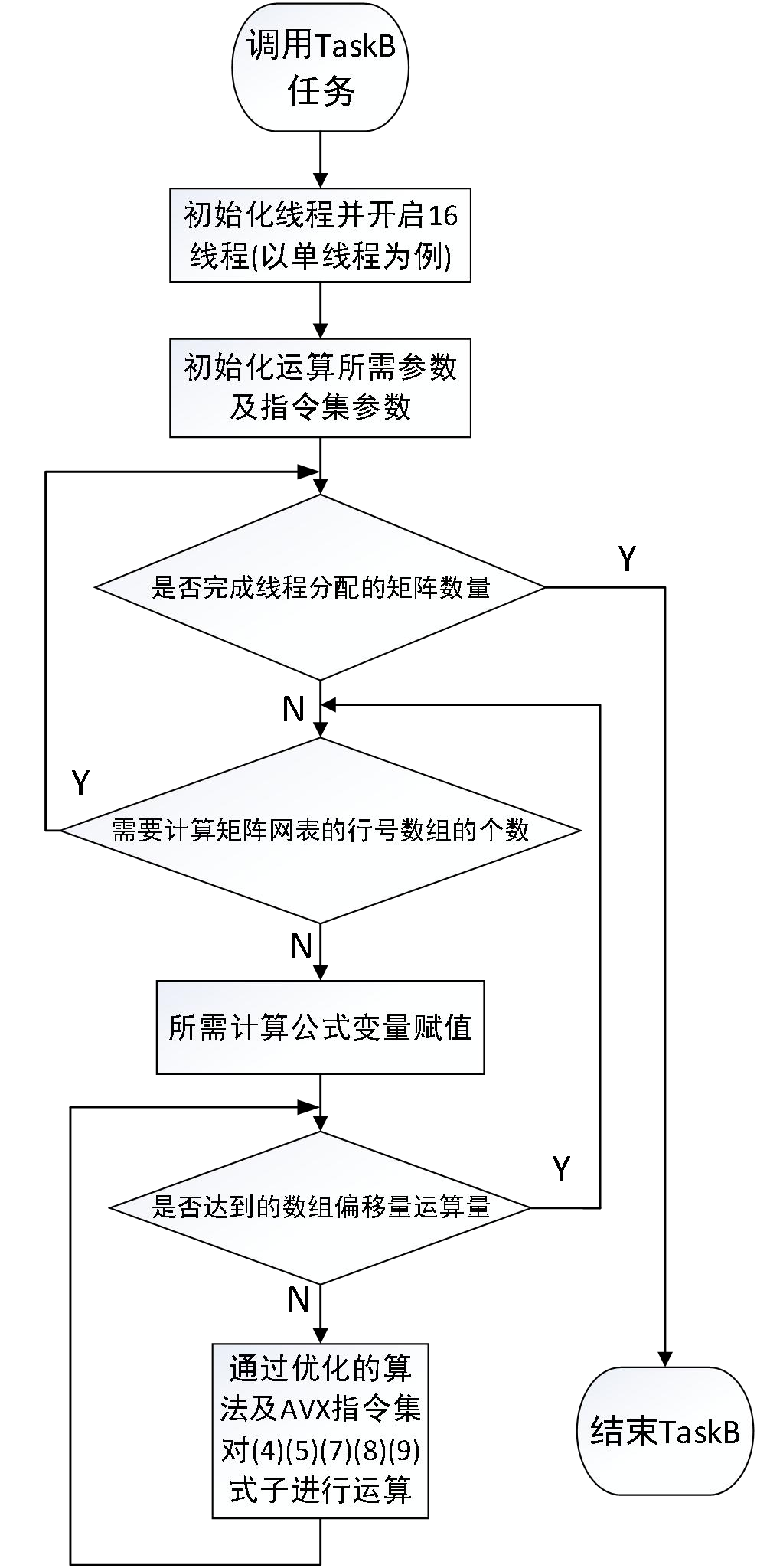
圖3 TaskB程式實作流程圖
2.3、執行緒加速仿真網表計算實作 實驗通過創建多執行緒來加速仿真網表的計算,本專案中,使用了 C++ 11 支持多執行緒機制,通常想要在 C++程式中添加多執行緒則需要借助作業系統的 API 來實作,但是對于需要運行在不同平臺上的底層程式,傳統的實作并發功能的方法顯得十分短板,future 頭檔案中聲 明 了 std::promise,std::package_task 兩 個 provider 類 , 以 及 std::future 和std::shared_future 兩個 future 類,另外還有一些相關的型別變數定義和函式,作為一種類模板的定義介面,std:: future 頭檔案中的各個類可以有效的獲取每一個異步執行緒的結果,同時也為執行緒之間異步通信提供了手段,執行緒實作函式部分代碼如圖 4 所示: 圖 4 執行緒實作函式部分代碼
舉個例子,如果 N 個執行緒的子任務之間,各自獨立同時進行,那么這 N 個子任務完成的總時間 Ts 與一個子任務完成的時間相同,這種情況下,可以認為并行的加速比為 N,這個加速比是相對不并行的情況而言的,而另外一個串行的例子,如果第 2 個子任務所需要的資料需要等第 1 個子任務完成才能得到,第 3 個子任務所需要的資料需要等第 2 個子任務完成才能得到,依次類推,所需時間為NTs,具體如圖5及圖 6所示:
圖 4 執行緒實作函式部分代碼
舉個例子,如果 N 個執行緒的子任務之間,各自獨立同時進行,那么這 N 個子任務完成的總時間 Ts 與一個子任務完成的時間相同,這種情況下,可以認為并行的加速比為 N,這個加速比是相對不并行的情況而言的,而另外一個串行的例子,如果第 2 個子任務所需要的資料需要等第 1 個子任務完成才能得到,第 3 個子任務所需要的資料需要等第 2 個子任務完成才能得到,依次類推,所需時間為NTs,具體如圖5及圖 6所示:
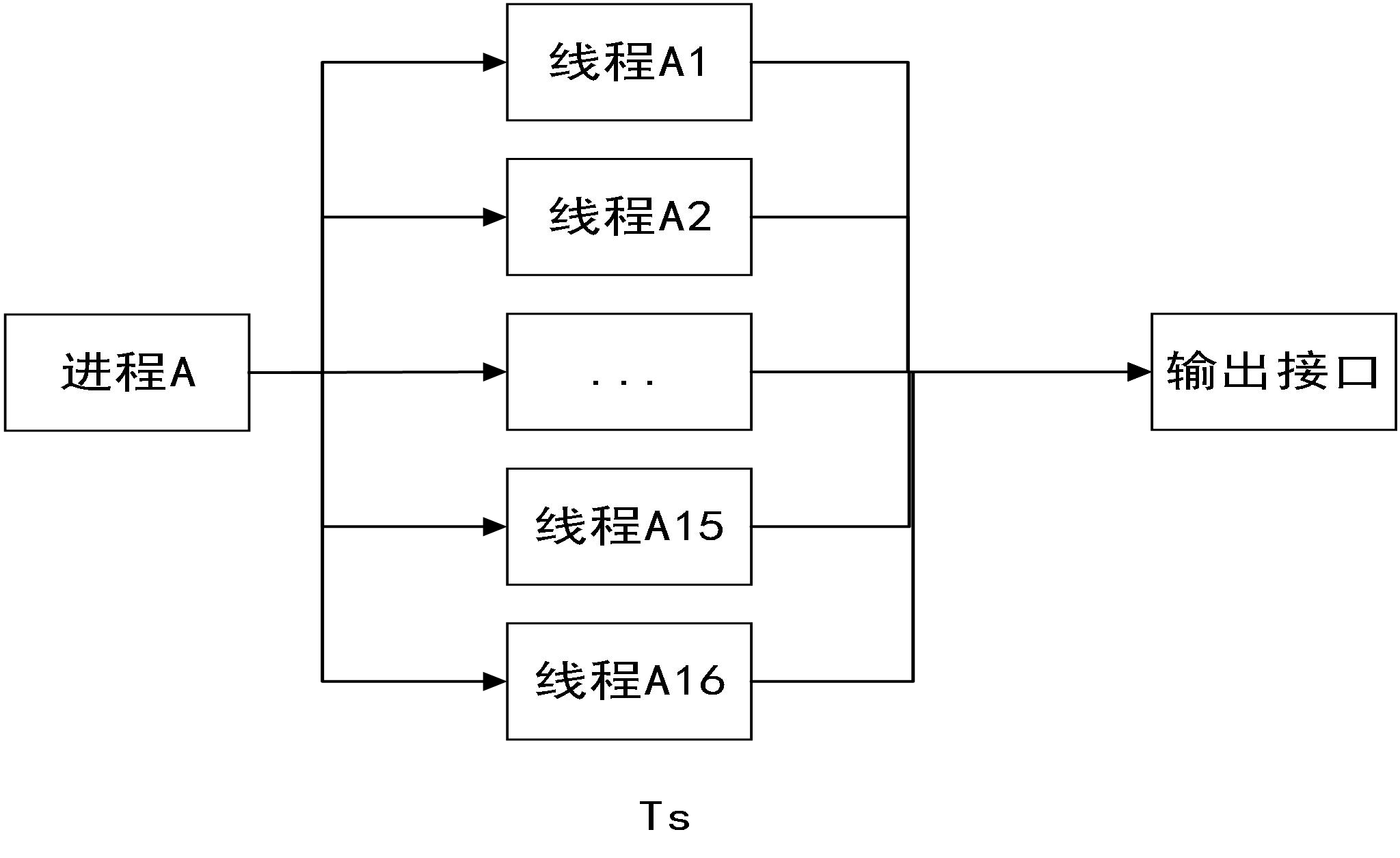
圖 5執行緒加速示意圖

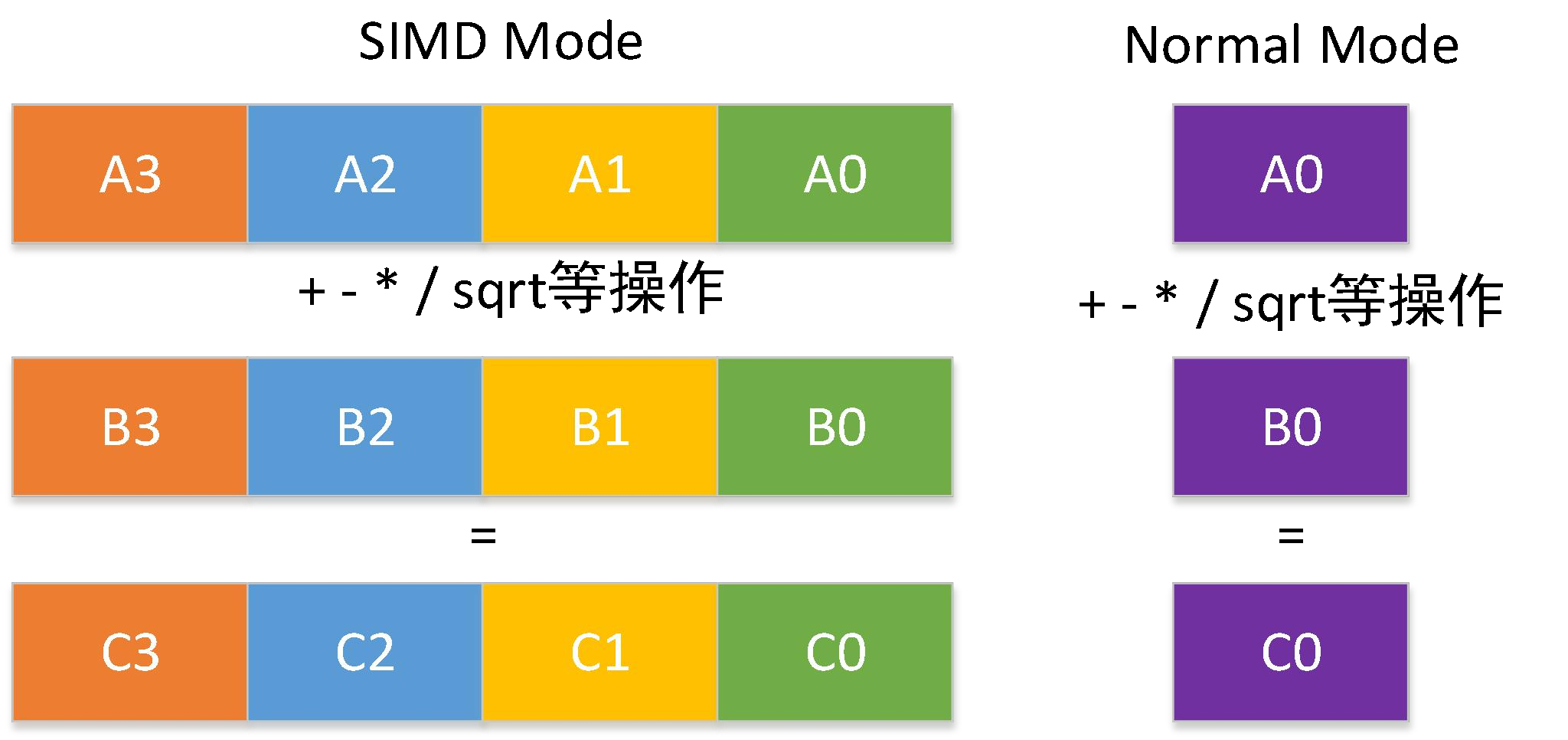 圖 7 SIMD 實作計算加速
具體實作依據了 Intel 公司的技術檔案,定義對應的變數如__mm256d 等,對所需的指令集命令如_mm256_mul_pd 實作單指令多資料流乘法運算,具體實作如下所示:
圖 7 SIMD 實作計算加速
具體實作依據了 Intel 公司的技術檔案,定義對應的變數如__mm256d 等,對所需的指令集命令如_mm256_mul_pd 實作單指令多資料流乘法運算,具體實作如下所示:
1 columnIndice_m =_mm256_set_pd((*(ptr+count_maxtrix))->S[(*(ptr+count_maxtrix))->columnIndice[j+3]], 2 (*(ptr+count_maxtrix))->S[(*(ptr+count_maxtrix))->columnIndice[j+2]], 3 (*(ptr+count_maxtrix))->S[(*(ptr+count_maxtrix))->columnIndice[j+1]], 4 (*(ptr+count_maxtrix))->S[(*(ptr+count_maxtrix))->columnIndice[j]] ); 5 //ID_m = _mm256_load_pd((*(ptr+count_maxtrix))->Id+j); 6 NormalMatrix_m = _mm256_loadu_pd((*(ptr+count_maxtrix))->valueNormalMatrix+j); 7 8 9 10 mux_m = _mm256_mul_pd(NormalMatrix_m, columnIndice_m); 11 12 //ID_mm = _mm256_add_pd(ID_m, mux_m); 13 14 _mm256_storeu_pd(ID_array, mux_m);3、TaskA 與 TaskB 任務 testApp 版本資料測驗 3.1、matrix_calc_taskA 任務的實作與測驗資料 首先是展示 matrix_calc_taskA 任務的 testApp 版本的測驗結果(以-loop 1000-matrixnum 1024 相同條件),通過修改及提高演算法來實作性能的優越性,最初實作 matrix_calc_taskA 計算式(6)時 version1 版本主要通過簡單 for 回圈遍歷二級指標指向的矩陣向量,通過三層 for 回圈計算出 Id 陣列與兩個引數指標指向的向量之間的數量關系,并分別計算相關任務,雖然 verison1 方法在精度上并無任何差錯,但是version1 版本動態庫在服務器上時 taskA 耗時 20s,見圖8所示,
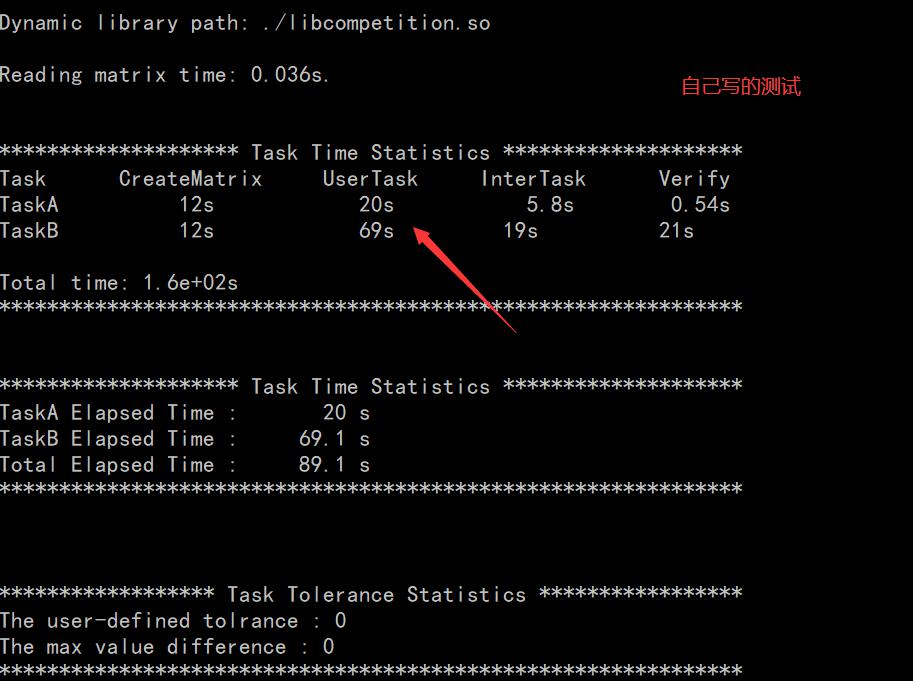 圖8 TaskA-version1測驗
Version5 版本修改將在之前的 for 回圈上運用 C++語言的執行緒機制,將原本三個 for循環要實作的計算作業量裁分為 16 個獨立執行緒作業量,充分利用執行緒的并發性來提升整體的計算效率,且在原有的 16 執行緒前提下增加了 AVX 指令集,提升了加速效果, 時間減少到 5.19s,
圖8 TaskA-version1測驗
Version5 版本修改將在之前的 for 回圈上運用 C++語言的執行緒機制,將原本三個 for循環要實作的計算作業量裁分為 16 個獨立執行緒作業量,充分利用執行緒的并發性來提升整體的計算效率,且在原有的 16 執行緒前提下增加了 AVX 指令集,提升了加速效果, 時間減少到 5.19s,
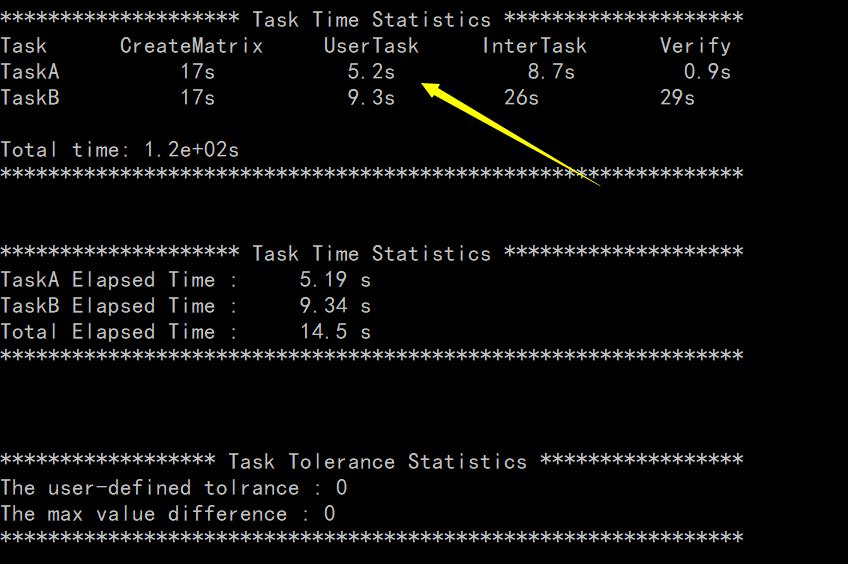 圖9 TaskA-vesion5測驗
3.2、TaskA 與 TaskB 任務 nanospice 電路仿真器和網表資料測驗
因為服務器后期 cpu 占有率及個人電腦配置等問題,case1 及 case2 的每次測驗時間較長,現以加速效果最好的 16 執行緒并行+AVX 指令集 version5 版本與官方的元件進行
測驗比對,case1 網表測驗:使用 16 執行緒并行+AVX 指令集技術,精度無誤差,(測驗用例已改變,并與官方的元件進行比對)
圖9 TaskA-vesion5測驗
3.2、TaskA 與 TaskB 任務 nanospice 電路仿真器和網表資料測驗
因為服務器后期 cpu 占有率及個人電腦配置等問題,case1 及 case2 的每次測驗時間較長,現以加速效果最好的 16 執行緒并行+AVX 指令集 version5 版本與官方的元件進行
測驗比對,case1 網表測驗:使用 16 執行緒并行+AVX 指令集技術,精度無誤差,(測驗用例已改變,并與官方的元件進行比對)
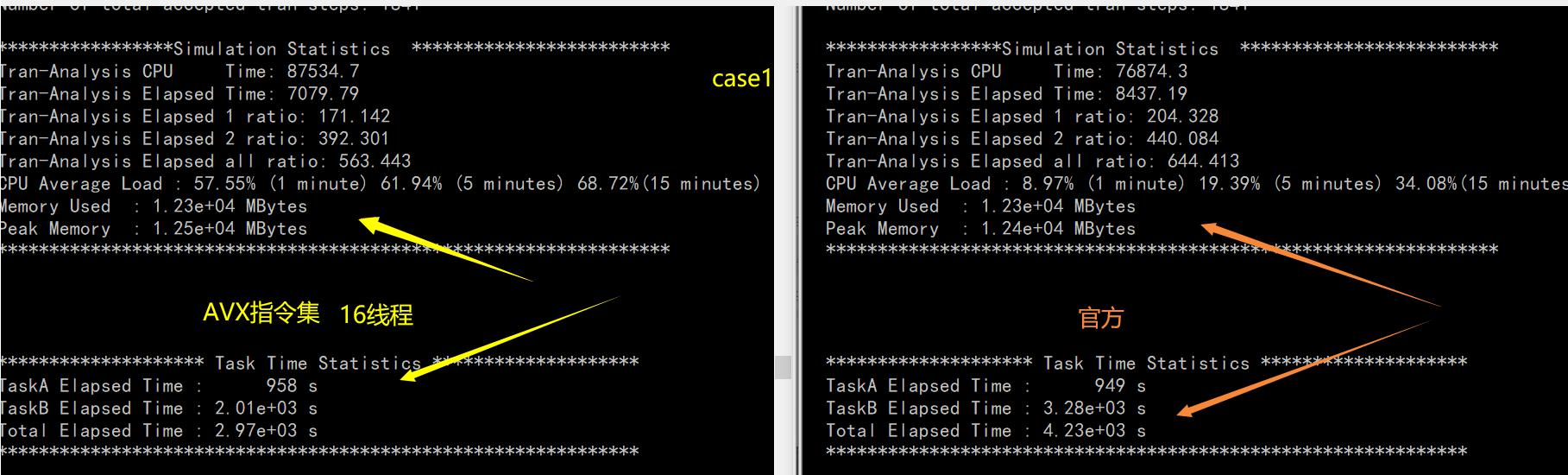 圖 8 case1 網表 16 執行緒并行+AVX 指令集技術與官方庫測驗對比
4、設計總結及擴展
在設計解決 matrix_calc_taskA 以及 matrix_calc_taskB 兩種實作演算法時,不斷的在探索優質的解決演算法,同時兼顧精度、時間、記憶體消耗等三個評判指標,在第五版本的設計中,加上了多執行緒及 AVX 指令集,通過 testApp 測驗,可以發現 16 執行緒+AVX 指令集提升的速度是最快的,而在 nanospice 電路仿真器和網表資料測驗中,可以看出 16 執行緒+AVX 指令集實作的元件比官方的元件有明顯的加速效果,但二者在記憶體使用上相差無幾,這是對賽題的演算法實作最優的并行加速效果,
總的來說,自己感覺設計沒有弄的很好,希望完善一下,具體可以參考F組第一名的答辯,可以吸收吸收.
重難點分析:
(1)隨機性
稀疏矩陣非零值位置沒有規律;矩陣向量規律龐大且不固定;運算行號與行數計算任務變化
(2)資料調度
矩陣與向量在記憶體上分布形式已確定為CSR;任務粒度小,突發性執行次數多,對模塊相應要求高;不連續訪問所造成的不規律訪存,造成cache missing,帶寬利用率低
解決方案:
(1)代碼優化:空間區域優化;回圈效率優化;訪存效率優化
(2)多執行緒并行:固定任務非加鎖多執行緒;跳躍任務非加鎖多執行緒;基于任務佇列的多執行緒;基于矩陣索引的執行緒池(最后采用)
(3)親和性設定:CBT(core banding thread)(最后采用);SBT(socket banding thread)------------從結果影響巨大,提高效能非常多
總優化程序:基礎代碼--------->經過回圈效率優化、空間區域優化、訪存優化------>基礎優化代碼------>經過基于矩陣索引的執行緒池----->CBT------>基于矩陣索引的CBT執行緒池
圖 8 case1 網表 16 執行緒并行+AVX 指令集技術與官方庫測驗對比
4、設計總結及擴展
在設計解決 matrix_calc_taskA 以及 matrix_calc_taskB 兩種實作演算法時,不斷的在探索優質的解決演算法,同時兼顧精度、時間、記憶體消耗等三個評判指標,在第五版本的設計中,加上了多執行緒及 AVX 指令集,通過 testApp 測驗,可以發現 16 執行緒+AVX 指令集提升的速度是最快的,而在 nanospice 電路仿真器和網表資料測驗中,可以看出 16 執行緒+AVX 指令集實作的元件比官方的元件有明顯的加速效果,但二者在記憶體使用上相差無幾,這是對賽題的演算法實作最優的并行加速效果,
總的來說,自己感覺設計沒有弄的很好,希望完善一下,具體可以參考F組第一名的答辯,可以吸收吸收.
重難點分析:
(1)隨機性
稀疏矩陣非零值位置沒有規律;矩陣向量規律龐大且不固定;運算行號與行數計算任務變化
(2)資料調度
矩陣與向量在記憶體上分布形式已確定為CSR;任務粒度小,突發性執行次數多,對模塊相應要求高;不連續訪問所造成的不規律訪存,造成cache missing,帶寬利用率低
解決方案:
(1)代碼優化:空間區域優化;回圈效率優化;訪存效率優化
(2)多執行緒并行:固定任務非加鎖多執行緒;跳躍任務非加鎖多執行緒;基于任務佇列的多執行緒;基于矩陣索引的執行緒池(最后采用)
(3)親和性設定:CBT(core banding thread)(最后采用);SBT(socket banding thread)------------從結果影響巨大,提高效能非常多
總優化程序:基礎代碼--------->經過回圈效率優化、空間區域優化、訪存優化------>基礎優化代碼------>經過基于矩陣索引的執行緒池----->CBT------>基于矩陣索引的CBT執行緒池
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/256223.html
標籤:其他
上一篇:我憑借這份999頁Java面試pdf!拿下了美團、螞蟻金服、騰訊、位元組跳動offer
下一篇:MATLAB中FFT_HDL_Optimized模塊定點(IEEE754單精度float格式)二進制與十進制轉換實作