養成習慣,先贊后看!!!
你的點贊與關注真的對我非常有幫助.如果可以的話,動動手指,一鍵三連吧!!!
十大經典排序演算法-堆排序,計數排序,桶排序,基數排序
前言
這是十大經典排序演算法詳解的最后一篇了.
還沒有看多之前兩篇文章的小伙伴可以先去看看之前的兩篇文章:
十大經典排序演算法詳解(一)冒泡排序,選擇排序,插入排序
十大經典排序演算法詳解(二)希爾排序,歸并排序,快速排序
這一篇文章真的耗費了我巨大的時間和精力,由于 堆排序是基于二叉樹 的,所以寫的篇幅比較大并且由于是關于樹的,所以畫圖動態演示的工程量就進一步增加,其次就是因為計數排序,桶排序以及基數排序并不是基于比較的,所以演算法的思想講解相對于之前的基于比較的演算法而言會稍微難一點.
其次就是這次的除錯程序也比之前多了很多需要注意的地方,這些我都會在下面的代碼中通過注釋的方式提醒大家.
最后如果大家覺得我的文章寫得還可以或者覺得文章對你有幫助的話,可以選擇關注我的公眾號:萌萌噠的瓤瓤,或者你也可以幫忙給文章來個一鍵三連吧.你的支持對我真的很有用.

1-堆排序
演算法思想:
在介紹演算法之前我們首先需要了解一下下面這些概念:什么是二叉樹,什么是完全二叉樹,什么是大根堆,什么是小根堆.
二叉樹
學過資料結構的小伙伴肯定知道什么是二叉樹,這部分主要是為那些可能還不太了解資料結構的小伙伴們說的.
二叉樹的定義就是每個結點至多能有兩個子樹,二叉樹是一種最簡單的樹,下面我們舉幾個樹的例子:
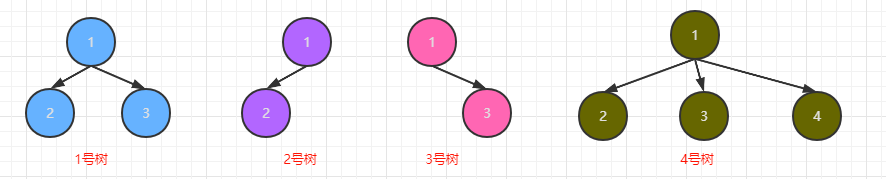
我們可以來哦稍微區分一下,很明顯只有4號樹并不是我們所說的二叉樹,因為它的1號結點下有三棵子樹,所以4號樹并不是我們所說的二叉樹.到這里,相信大家也已經基本了解二叉樹得出概念了,那么接下來我們再來了解一下另一個概念完全二叉樹.
完全二叉樹
說到完全二叉樹,就應該知道它首先應該滿足二叉樹的一些條件,就比如說每個節點至多只能有兩個子樹,那么除了這個條件以外,還需要什么條件才能稱得上是完全二叉樹呢.
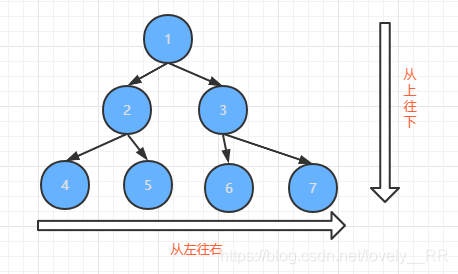
官方是這樣說的: 一棵深度為k的有n個結點的二叉樹,對樹中的結點按從上至下、從左到右的順序進行編號,如果編號為i(1≤i≤n)的結點與滿二叉樹中編號為i的結點在二叉樹中的位置相同,則這棵二叉樹稱為完全二叉樹,
但是很明顯說的太官方了,我們肯定需要簡化一下概念.其實說白了就是在二叉樹的基礎上,所有的節點順序必須要按照下面這樣的順序進行排列,否則就不能說是完全二叉樹
并且每次必須是已經放滿2的冪數之后才能放到下一層,并且必須是從每層最左邊的節點開始添加節點,并且必須是先添加左節點在添加右節點.否則就不能稱為是完全二叉樹,這里呢,我們舉幾個反例,大家就知道我說的是什么意思了:
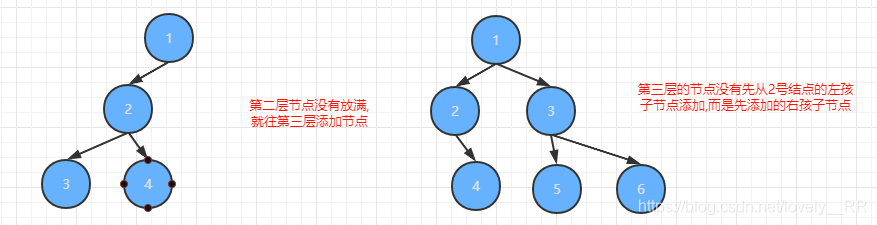
上面的這兩棵樹就是最明顯的反例,看完這兩棵樹之后,相信大家就能更加了解什么是完全二叉樹了.
大根堆
大根堆其實很容易理解,大根堆在完全二叉樹的基礎上就一條判定條件就是:每個根節點的值必須大于它的左孩子節點已經右孩子節點的值.滿足這樣條件的二叉樹,我們就稱這個二叉樹是大根堆.當然了只要有一個節點不滿足這樣的情況,那么就不能稱這是大根堆.
舉個例子,下面這棵二叉樹就是一個大根堆:
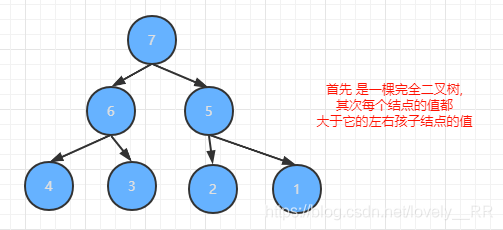
舉完正確的例子之后,我們當然也需要來舉幾個反例來幫助我們更好的理解什么是大根堆:
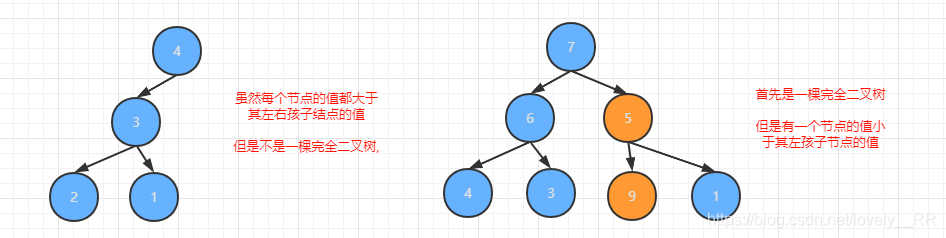
看完這兩個反例之后相信大家就能更加理解什么是大根堆了.
小根堆
當然了,理解完什么是大根堆了之后,大家就能舉一反三的了解什么叫做小根堆了.這里就不再給大家廢話.
在了解完上面的這些概念之后,我們就可以來講解什么是堆排序了.
堆排序的演算法步驟其實很簡單,總共就三步.
-
1.將陣列重構成大根堆
-
2.將陣列的
隊頭元素與隊尾元素交換位置 -
3.對去除了隊尾元素的陣列進行重構,再次重構成大根堆
之后重復上述2,3步驟,直到需要重構成大根堆的陣列為空為止.
演算法的步驟的確簡潔明了,其實大家看了也應該已經懂了.
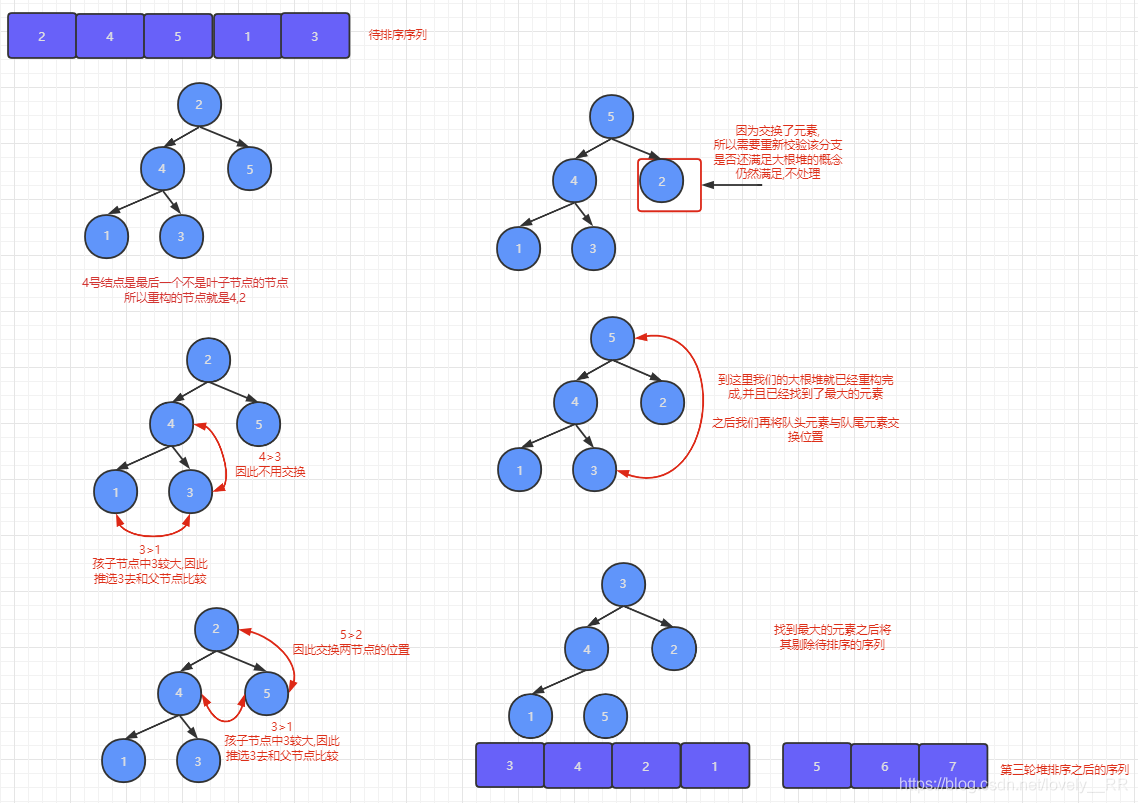
因為每次重構成大根堆之后,根據大根堆的特性,每個節點的值一定大于左右孩子節點的值,所以很明顯大根堆的根節點就是二叉樹中值最大的值同時也就是陣列中最大的值.所以重構成大根堆之后交換陣列隊頭與隊尾元素的操作就是在將最大的元素進行定位.也就意味著這一輪結束之后,陣列中已經確定了一個元素的最終位置了.
演算法的思想就是這樣,誰都能說的出來,但是呢,堆排序的難點就是在于我們如何將陣列重構成我們大根堆.這個就是堆排序的難點.
那么接下來,我們就著重講解一下重構大根堆的程序是怎么樣的.
首先我們需要明白一點就是我們一開始構建二叉樹的時候遵循的是這樣的原則: 從上往下,從左往右 .但是到了將二叉樹重構成大根堆的時候我們的原則就必須要反過來了:從下往上,從右往左.這個大家動動小腦瓜應該就能理解了.
顯然我們每次對小子樹進行重構成大根堆的操作時,最后都會使得最大的元素上移,對不對,既然大的元素是在上移的,那么很顯然我們就應該從下往上開始構建.
既然我們已經知道重構的順序是什么樣的之后,我們就需要再明白一點,那就是我們應該對哪些元素進行重構的操作呢?上面我們已經說過了,大根堆的一個硬性條件就是每個節點必需要大于它的左右孩子節點,那么很顯然如果節點本身沒有孩子節點的話,就不需要進行重構了.所以我們需要進行重構的元素必定包含孩子節點.并且結合我們上面所說重構順序基本就可以得出一個結論:重構的元素就是最后一個非葉子節點之前的所有節點,包括該節點本身.,就比方下面這張圖中紅色圈圈的元素.
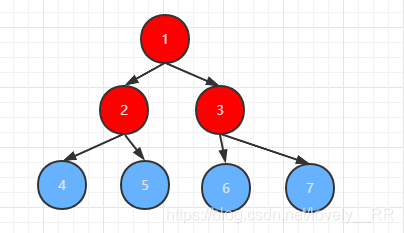
之后我們只需要通過回圈,依次進行下面的操作:
比較節點及其左右孩子節點,如果有孩子節點的值大于該節點,那么就交換兩者的位置.
這里需要大家特別注意!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
這里需要大家特別注意!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
這里需要大家特別注意!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
交換兩者的位置之后我們還需要進行一個步驟 重新校驗
特別注意!!!特別注意!!!重復這個程序,直到最后一個元素為止.
到這里堆排序的基本思想也就已經基本講解完畢了,接下來就是通過圖來動態的演示一下堆排序的程序,這樣能夠讓大家更好的理解堆排序:
這是第一輪堆排序:
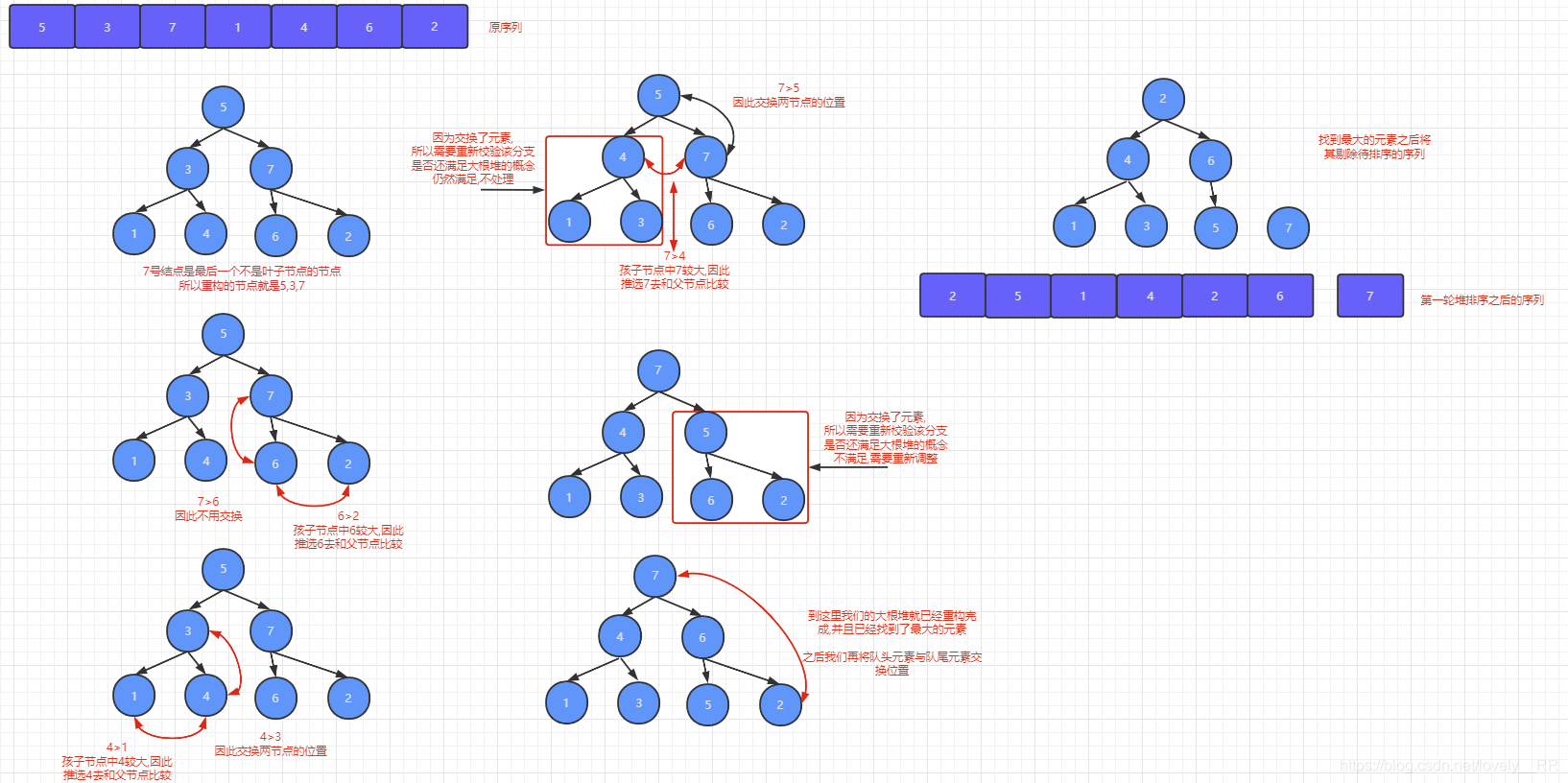 )
)
第二次堆排序:
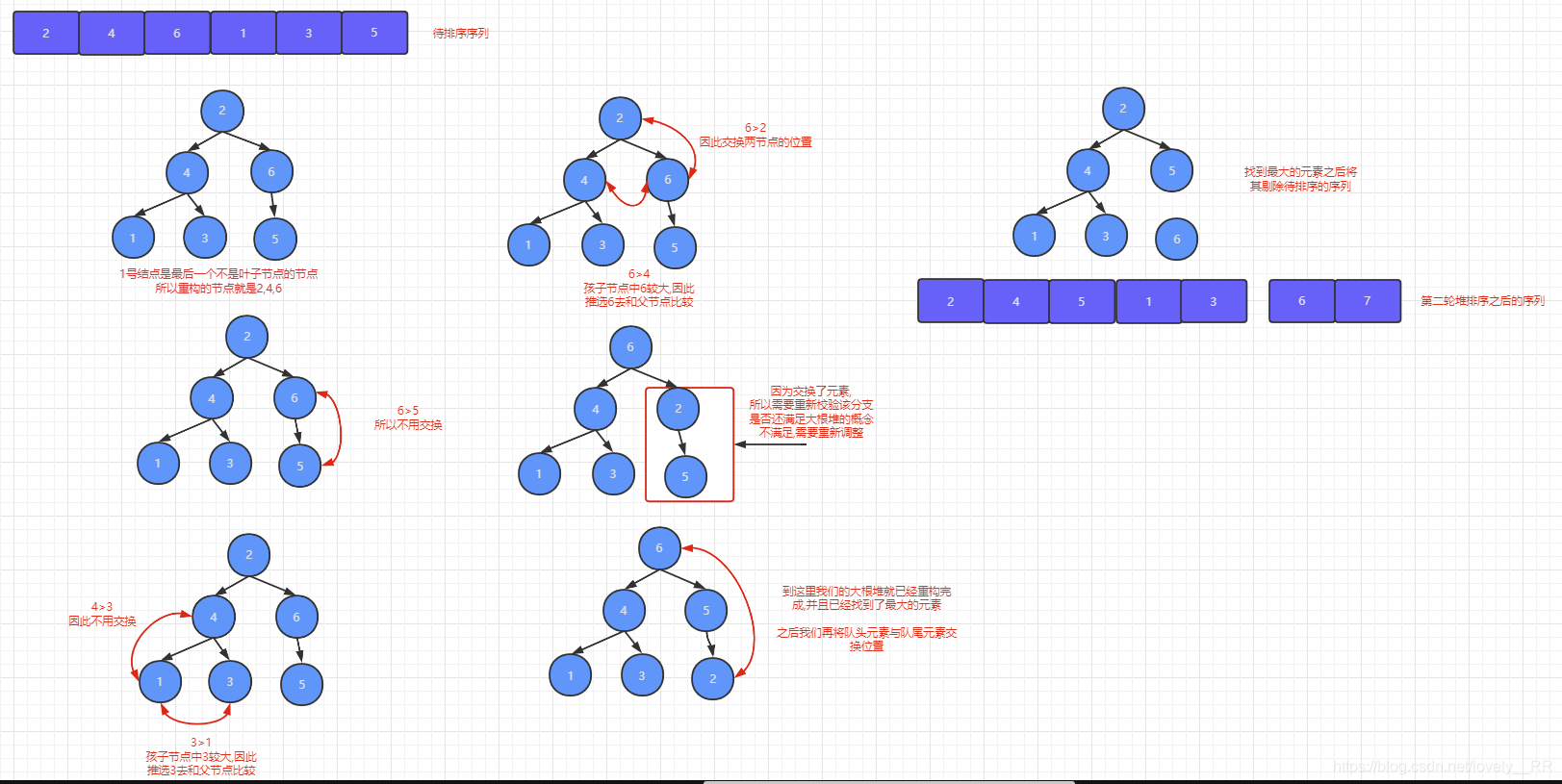 )
)
第三次堆排序:
 )
)
這里給大家模擬三次,大家應該就差不多懂這個流程了.主要是這圖圖畫起來實在是太麻煩了.能力有限就只畫這三次的了.在下面的代碼里面,我還會著重講重新校驗的程序,大家如果這里還沒理解的,也可以接著往下面看.
演算法的基本思想大家應該基本上就能理解了.那么我們再來稍微聊聊堆排序的一些特點:
-
堆排序是
不穩定的,這個其實還是比較好理解的.因為我們在進行小分支的調整時時有序的,但是之后可能會出現小分支擴大到大分支進行重新的調整,那么這時候就有可能會出現元素的相對位置混亂的情況.這個混亂的程序其實有點像我們之前所說的
希爾排序,希爾排序也是小區間內的插入排序是有序的,但是一旦擴散到更大的區間進行二次的插入排序時就有可能造成相對位置混亂的情況.說的差不多了,那么我們接下來還是舉一個例子來幫助大家更好的理解:
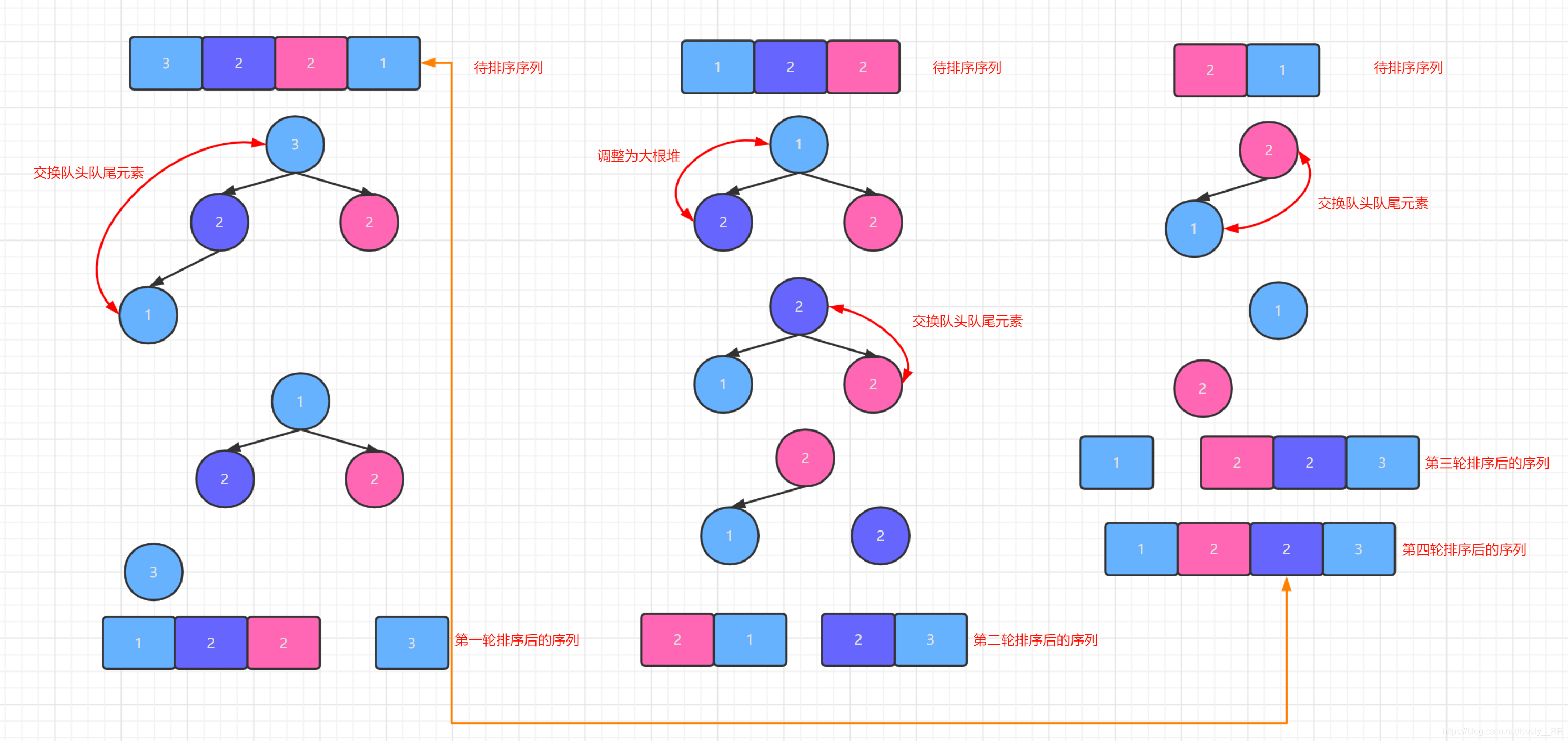
通過上面這張圖,相信大家就能更好的理解堆排序為啥是不穩定的了. -
堆排序每輪排序都可以確定
一個元素的最終位置,這個大家看我上面的演示圖也能看出來.
演算法圖解:

示例代碼:
這是我寫的第一版的代碼:
//交換陣列中的元素
public static void swap(int[]num ,int i,int j) {
int temp=num[i];
num[i]=num[j];
num[j]=temp;
}
//將待排序的陣列構建成大根堆
public static void buildbigheap(int []num,int end) {
//從最后一個非葉子節點開始構建,依照從下往上,從右往左的順序
for(int i=end/2;i>=0;i--) {
int left=2*i+1;
int right=2*i+2;
int big=i;
//判斷小分支那個是大元素
if(left<end&&num[i]<num[left])
// swap(num, i, left);
i=left;
if(right<end&&num[i]<num[right])
// swap(num, i, right);
i=right;
swap(num, i, big);
}
}
public static void main(String[] args) {
int []num ={7,4,9,3,2,1,8,6,5,10};
long startTime=System.currentTimeMillis();
//第一次構建大根堆
buildbigheap(num, num.length);
for(int j=num.length-1;j>0;j--) {
//交換隊頭已經排序得到的最大元素與隊尾元素
swap(num, 0, j);
System.out.print("第"+(num.length-j)+"次排序: ");
for(int k=0;k<num.length;k++) {
System.out.print(num[k]+" ");
}
System.out.println();
//交換結束之后,大根堆已經內破壞,需要開始重新構建大根堆
buildbigheap(num,j);
}
long endTime=System.currentTimeMillis();
System.out.println("程式運行時間: "+(endTime-startTime)+"ms");
}
一開始我覺得我的代碼是對的,并且運行出來的結果也和我預期的一樣,但是當我自己畫圖以后畫到這張圖的時候我就知道演算法還是有BUG的,這個BUG就是每次構建大根堆的時候:我們的確能夠在每次構建大根堆的時候將最大的元素挑選出來,但是,我們在挑選出當前最大的元素之后,我們的大根堆真的還是大根堆嗎,這里用上面畫的圖,我們就能看出來了:
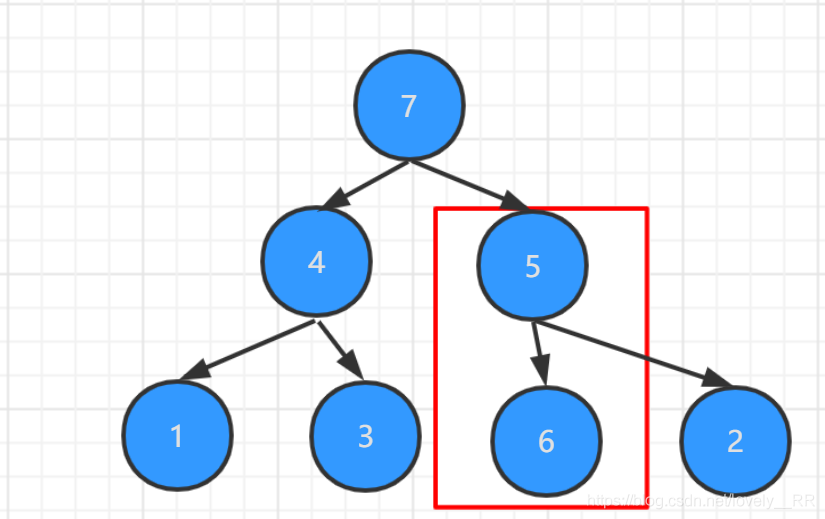
很明顯這個這一步我們的確已經將最大的元素挑選出來了,但是我們當前的已經不是大根堆了,所以我就在想我到底是哪一步做錯了呢.之后我參考了網上的資料發現,該演算法還有一個重點就是:如果我們發現根節點與孩子節點交換順序之后,我們就需要重新檢查交換之后的孩子節點以下的所有節點是否還滿足大根堆的定義,因為可能我們交換后的孩子節點的值還是比他的孩子節點要小的.就比方上面那張圖里我們所看到的.所以修改后的代碼主要就是加上了重新校驗的程序.
修改后的第二版代碼:
//交換陣列中的元素
public static void swap(int[]num ,int i,int j) {
int temp=num[i];
num[i]=num[j];
num[j]=temp;
}
//將待排序的陣列構建成大根堆
public static void buildbigheap(int []num,int end) {
//從最后一個非葉子節點開始構建,依照從下往上,從右往左的順序
for(int i=end/2;i>=0;i--) {
adjustnode(i, end, num);
}
}
//調整該節點及其以下的所有節點
public static void adjustnode(int i,int end,int []num) {
int left=2*i+1;
int right=2*i+2;
int big=i;
//判斷小分支那個是大元素
if(left<end&&num[i]<num[left])
i=left;
if(right<end&&num[i]<num[right])
i=right;
if(i!=big) {
//交換順序之后需要繼續校驗
swap(num, i, big);
//重新校驗,防止出現交換之后根節點小于孩子節點的情況
adjustnode(i, end, num);
}
}
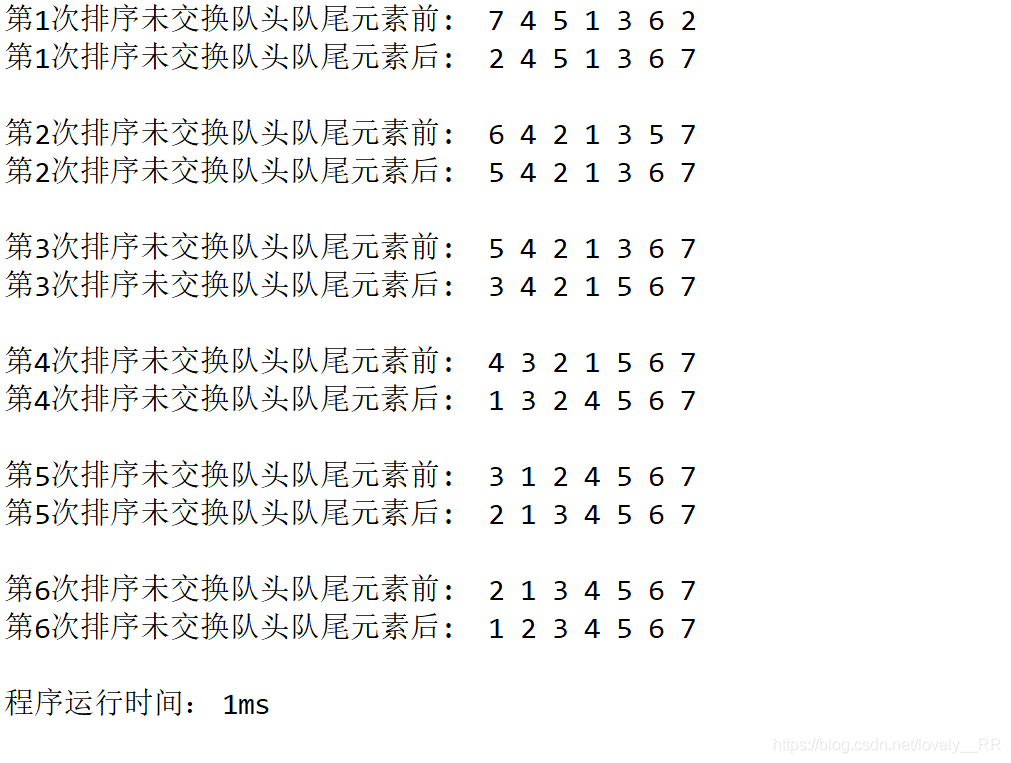
public static void main(String[] args) {
int []num ={5,3,7,1,4,6,2};
long startTime=System.currentTimeMillis();
//第一次構建大根堆
buildbigheap(num, num.length);
for(int j=num.length-1;j>0;j--) {
System.out.print("第"+(num.length-j)+"次排序前: ");
for(int k=0;k<num.length;k++) {
System.out.print(num[k]+" ");
}
//交換隊頭已經排序得到的最大元素與隊尾元素
swap(num, 0, j);
System.out.print("第"+(num.length-j)+"次排序后: ");
for(int k=0;k<num.length;k++) {
System.out.print(num[k]+" ");
}
System.out.println();
//交換結束之后,大根堆已經被破壞,需要開始重新構建大根堆
buildbigheap(num,j);
}
long endTime=System.currentTimeMillis();
System.out.println("程式運行時間: "+(endTime-startTime)+"ms");
}
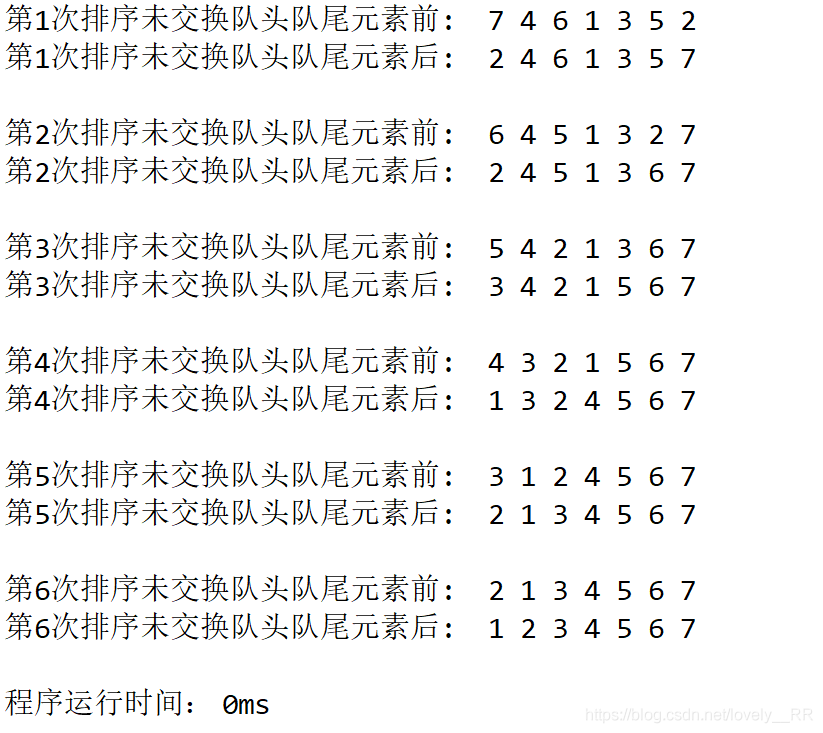
這里我們將這兩個排序結果對比一下,大家就更加能了解重新校驗步驟的重要性了.
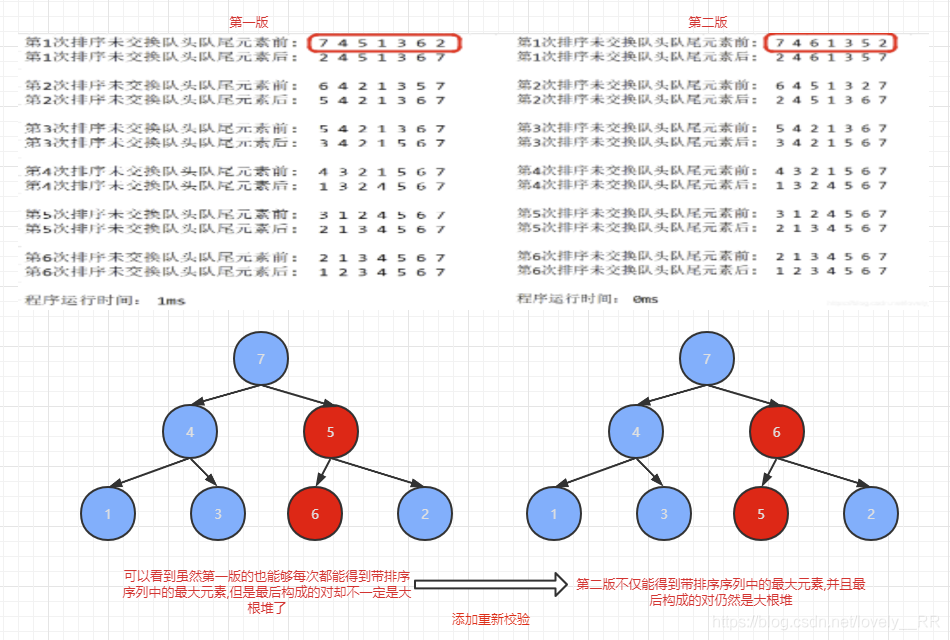
相信經過我這樣的講解之后,大家一定能夠更好的理解堆排序了.
復雜度分析:
理解完堆排序的基本思想之后,我們就需要來分析一下他的時間復雜度,空間復雜度.
-
時間復雜度
堆排序的本質思想也是利用了二叉樹的特性,所以根據他的遍歷次數以及二叉樹的層數可以得到堆排序的時間復雜度為
O(N*logn),不僅僅是平情況是這樣最好與最壞的情況都是如此. -
空間復雜度
這個我們可以看到我們整個排序的程序中只增加一個存盤交換元素的
temp,所以堆排序的空間復雜是常量級別的僅為O(1).
2-計數排序
演算法思想:
計數排序最核心的思想就是計數序列中每個元素出現的次數,我們將每個元素的數量都記錄下來之后.我們就可以通過按
了解完計數排序的基本思想之后,我們就來看看看這個演算法的實作步驟又是怎么樣的呢?主要就是下面這幾個步驟:
-
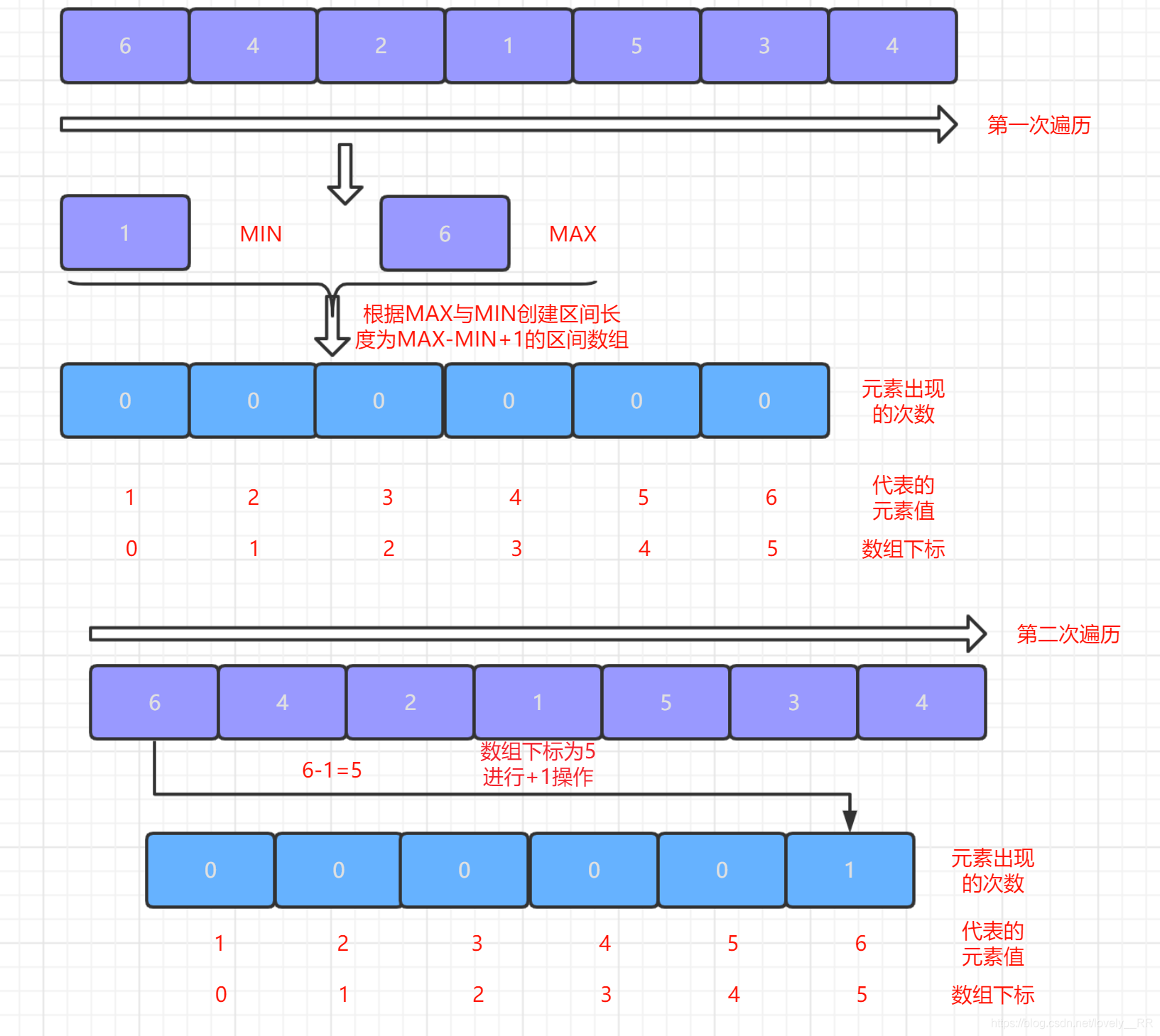
1.第一次遍歷序列,找出序列中的最大值以及最小值,然后根據
最大值MAX與最小值MIN創建一個MAX-MIN+1長度的陣列.為什么創建這樣長度的陣列呢,因為只有創建了這樣長度的陣列,MIN-MAX區間內的每個元素才有對應的位置進行存放,如下圖所示:
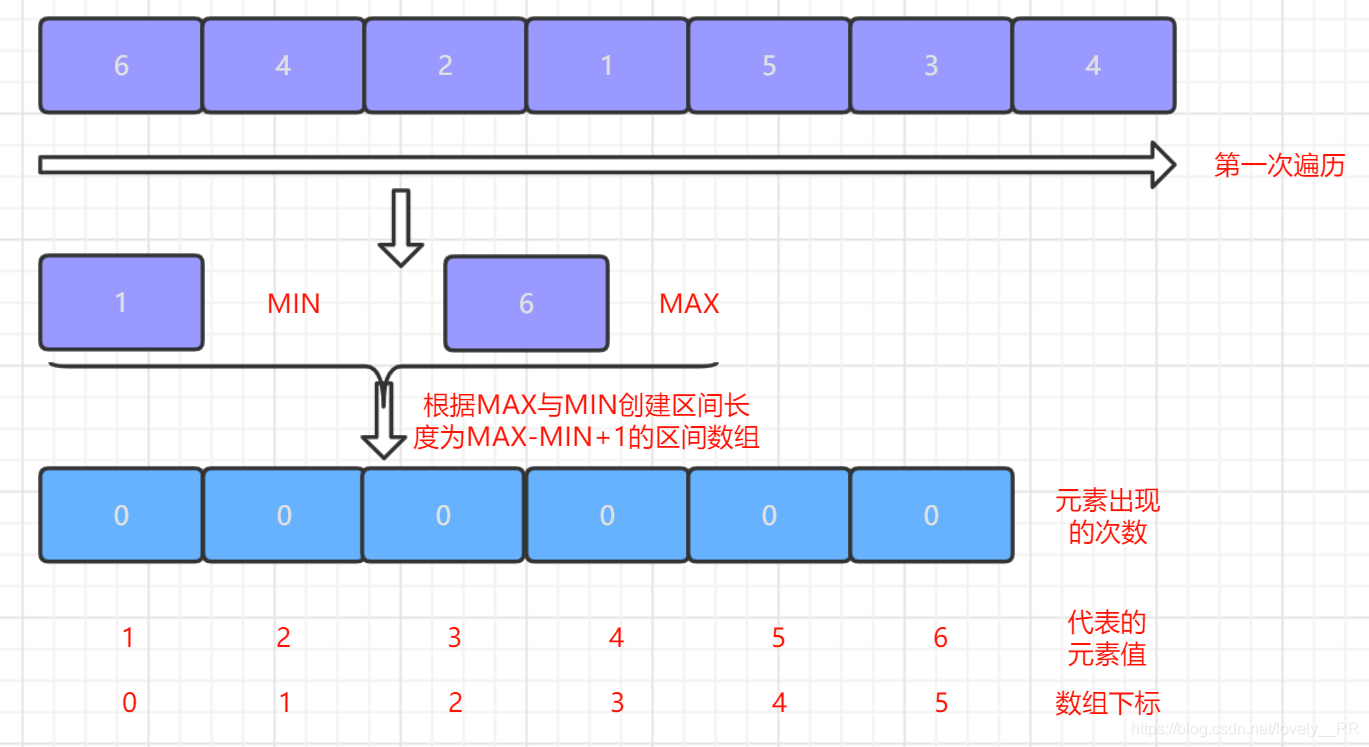
-
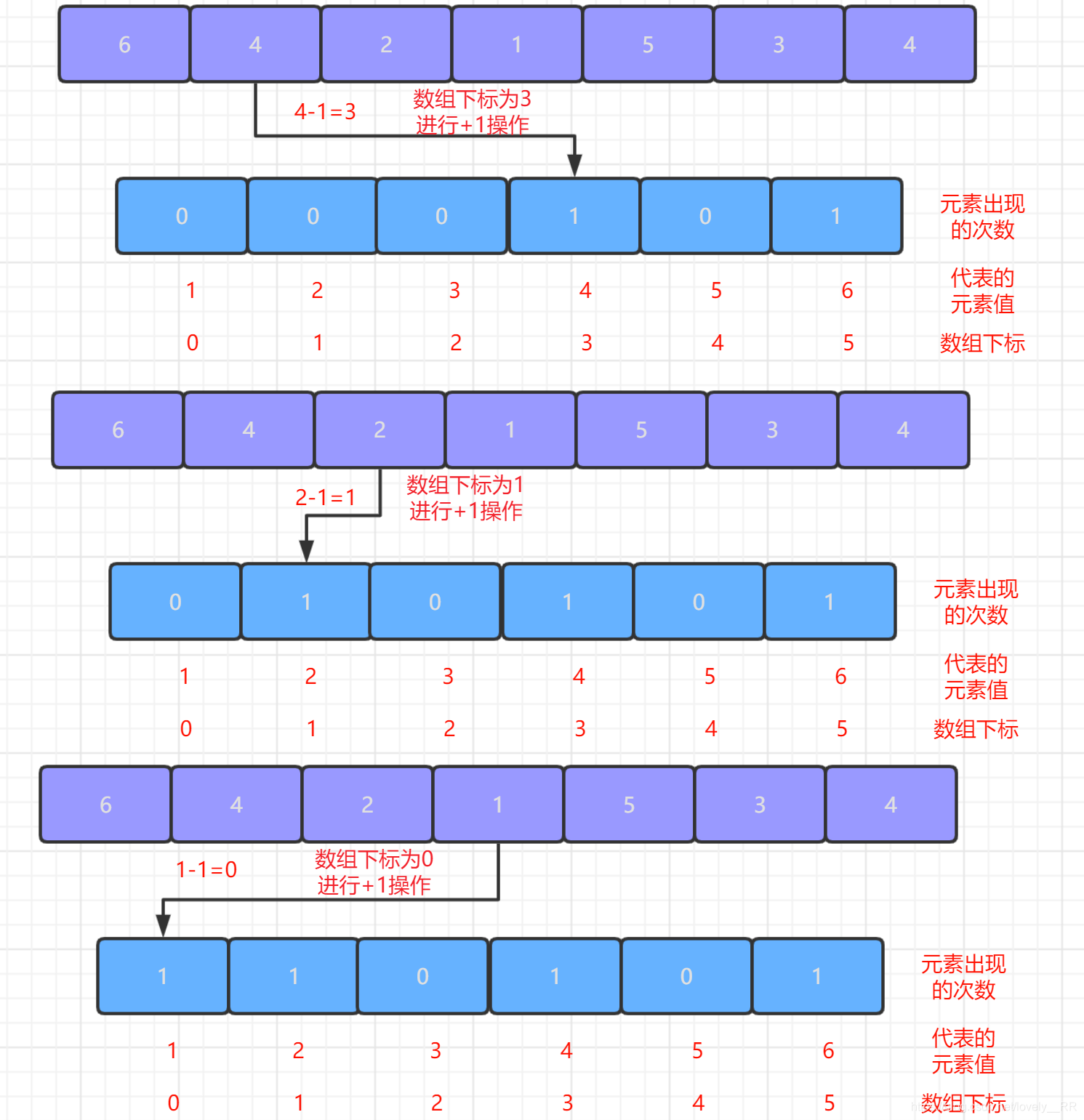
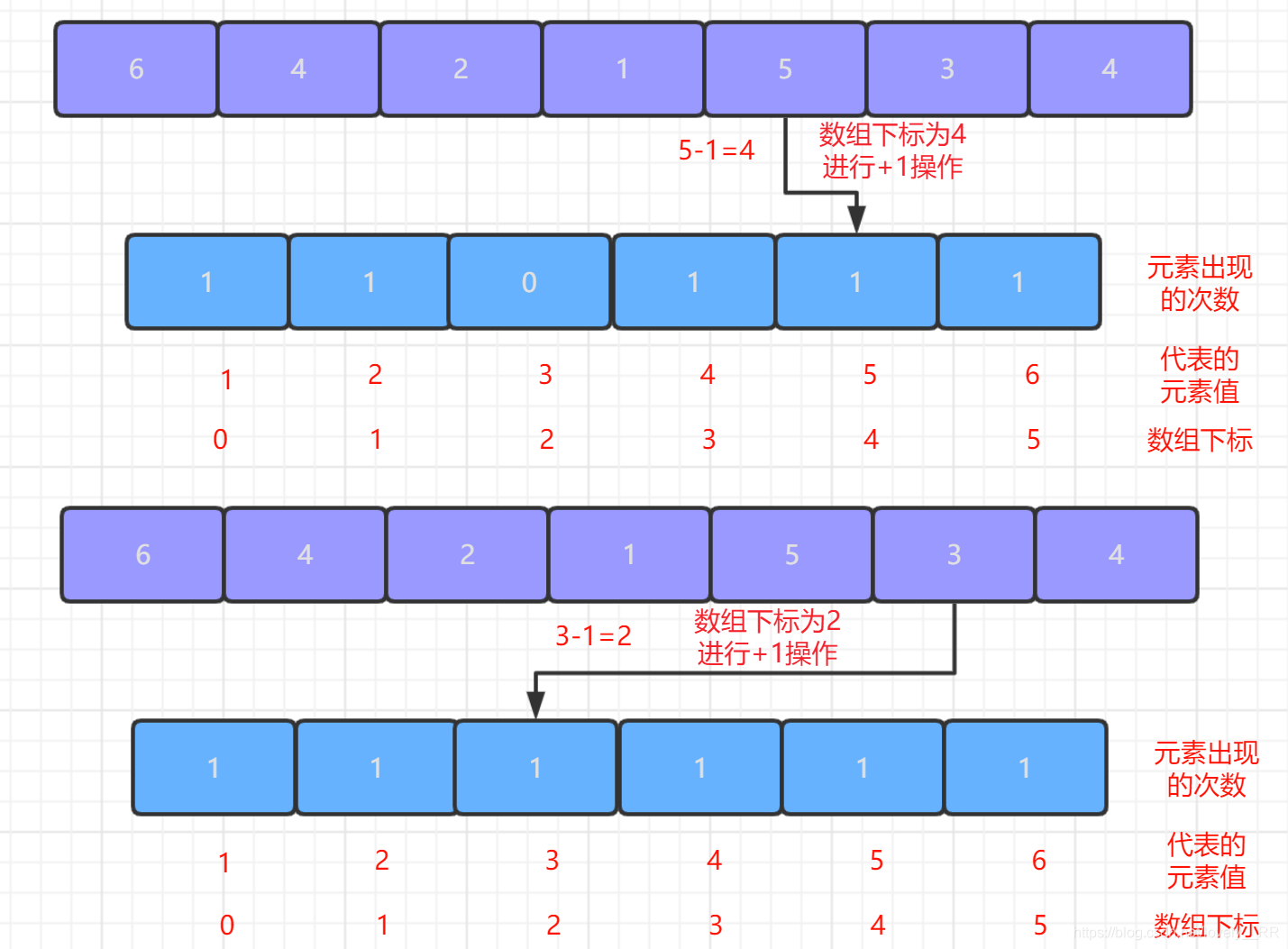
2.第二次遍歷序列,我們每次遍歷一個元素都將該元素所對應的區間陣列對應的位置進行
+1操作,這個步驟其實就是我們計數排序的核心----計數了.遍歷結束之后,區間陣列中的元素值就代表相應元素出現的次數,如下圖所示:
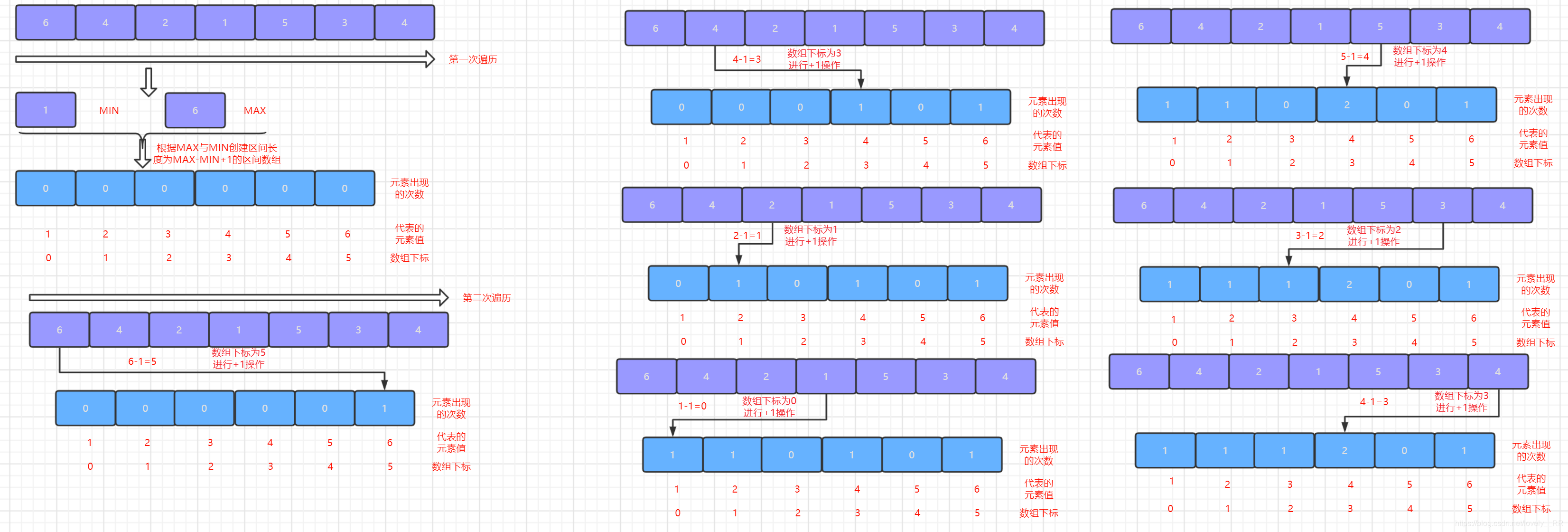
-
3.最后一步就只需要按照區間陣列中的次數一次將該元素列印出來即可.如下圖所示:
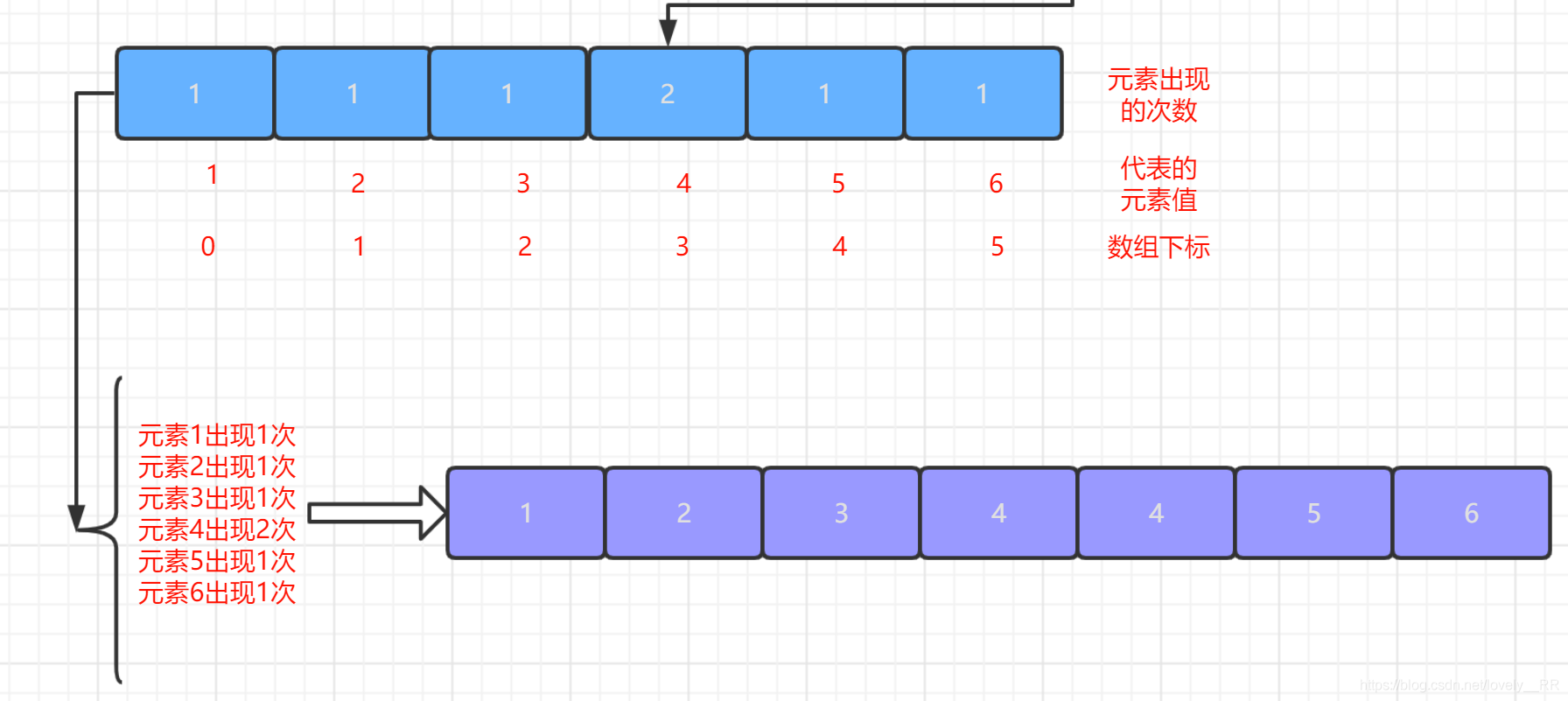
計數排序的基本思想基本就是這樣,按照慣例,還是通過下面的圖來幫助大家更好的理解計數排序的基本思想:
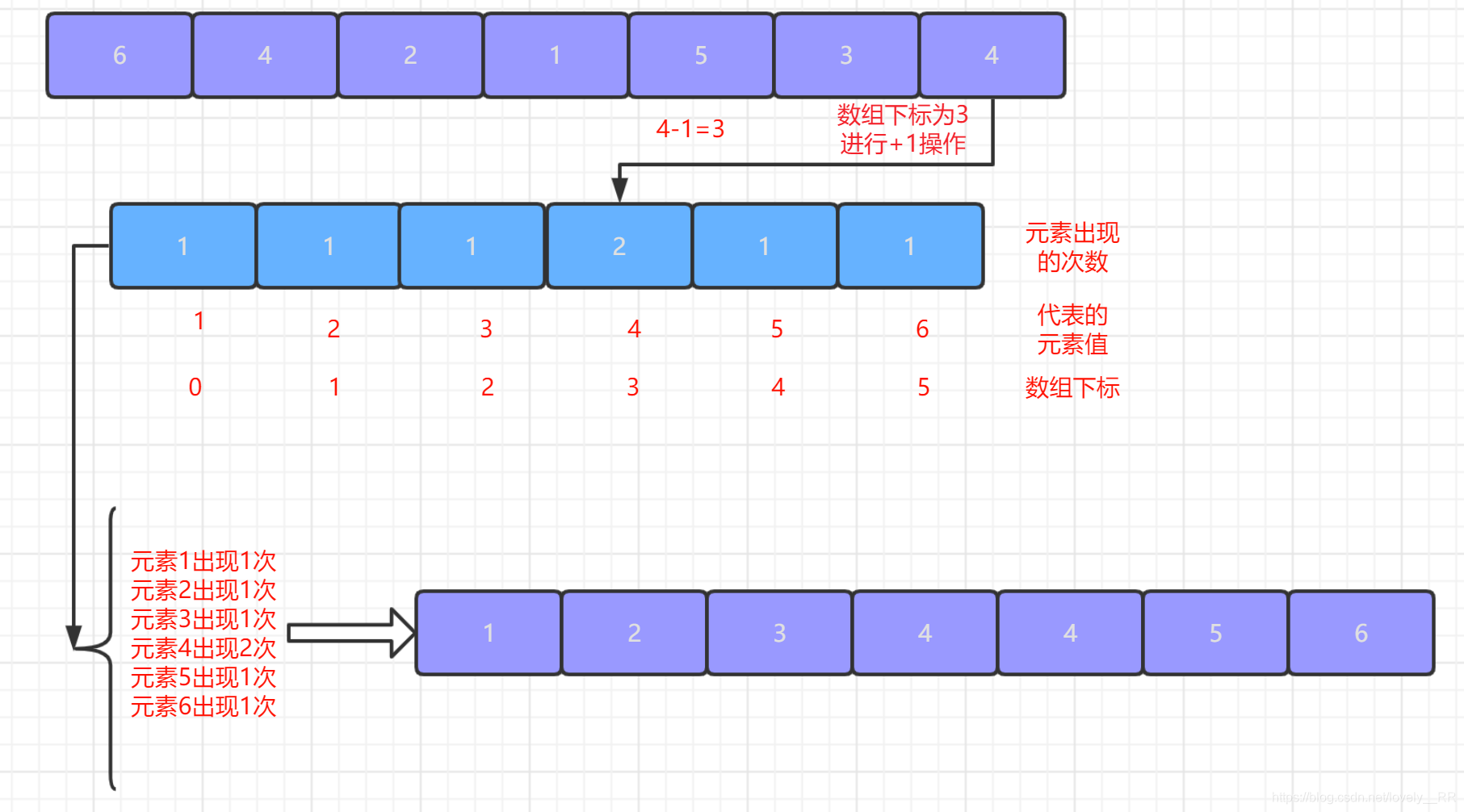
了解完計數排序的基本思想之后,我們還是按照慣例分析一下計數排序演算法的一些特點:
-計數排序是穩定的 ,這個大家應該能很明顯的看出來,因為計數排序本身并不是基于比較的演算法.
-計數排序需要的額外空間比較大,這個大家很明顯的看出來,并且空間浪費的情況也會比較嚴重,因為一旦序列中MAX與MIN的差距過大,那么需要的記憶體空間就會非常大.并且假如序列中的元素都是散布在一個特定的區間內,那么記憶體空間浪費的情況也會非常明顯.
演算法圖解:
示例代碼:
public static void main(String[] args) {
int []num ={7,4,9,3,2,1,8,6,5,10};
long startTime=System.currentTimeMillis();
int min=Integer.MAX_VALUE;
int max=Integer.MIN_VALUE;
//先找出陣列中的最大值與最小值
for(int i=0;i<num.length;i++) {
if(num[i]<min)
min=num[i];
if(num[i]>max)
max=num[i];
}
//創建一個長度為max-min+1長度的陣列來進行計數
int []figure=new int [max-min+1];
for(int i=0;i<num.length;i++) {
//計算每個資料出現的次數
figure[num[i]-min]++;
}
int begin=0;
//創建一個新的陣列來存盤已經排序完成的結果
int []num1=new int [num.length];
for(int i=0;i<figure.length;i++) {
//回圈將資料pop出來
if(figure[i]!=0) {
for(int j=0;j<figure[i];j++) {
num1[begin++]=min+i;
}
}
}
System.out.println("資料范圍:"+min+"~"+max);
System.out.println("計數結果: ");
for(int i=0;i<num.length;i++)
System.out.println(" "+num[i]+"出現"+figure[num[i]-min]+"次");
System.out.print("排序結果: ");
for(int i=0;i<num1.length;i++)
System.out.print(num1[i]+" ");
System.out.println();
long endTime=System.currentTimeMillis();
System.out.println("程式運行時間: "+(endTime-startTime)+"ms");
}

復雜度分析:
理解完計數排序的基本思想之后,我們就需要來分析一下他的時間復雜度,空間復雜度.
-
時間復雜度
計數排序很明顯是一種通過空間來換時間的演算法,因為我們可以很明顯的看到計數排序需要三次遍歷,兩次遍歷我們的原序列,第三次是遍歷我們的區間陣列.那么很明顯
時間復雜度一定是線性級別的但是因為第三次遍歷的并不是我們的原序列,而是我們的區間陣列,所以時間復雜度并不是我們的平常的O(n),而是應該加上我們遍歷區間陣列的時間,假設我們的區間陣列長度為k的話,那么我們的時間復雜度就是O(n+k) -
空間復雜度
上面我們已經說過了,計數排序本身就是一個通過空間來換取時間的演算法,所以很明顯他的空間復雜度就會很高.并且這個空間復雜度主要就取決于我們區間陣列的長度,所以假設我們的區間陣列長度為k的話,那么我們的空間復雜度就為
O(k)
3-桶排序
演算法思想:
大家第一眼看到這個演算法的名字時相信大家的反應應該和我是一樣的,桶排序?排序怎么還需要用到桶呢?桶排序里的桶又是主要是干什么的呢?
其實這個大家類比到我們平常生活中就能基本知道桶排序的桶是干嘛的呢?在我們的日常生活中,我們的桶一般都是用來裝東西的,我們可能是用來裝水,又或者是裝錢的反正不管怎么樣,我們的桶最后都是一個容器,是用來存盤相應的物質的.

顯然我們當前存在的只有我們的待排序的序列,那么我們的桶就是用來存盤我們的序列中的元素的.就像下圖所示:
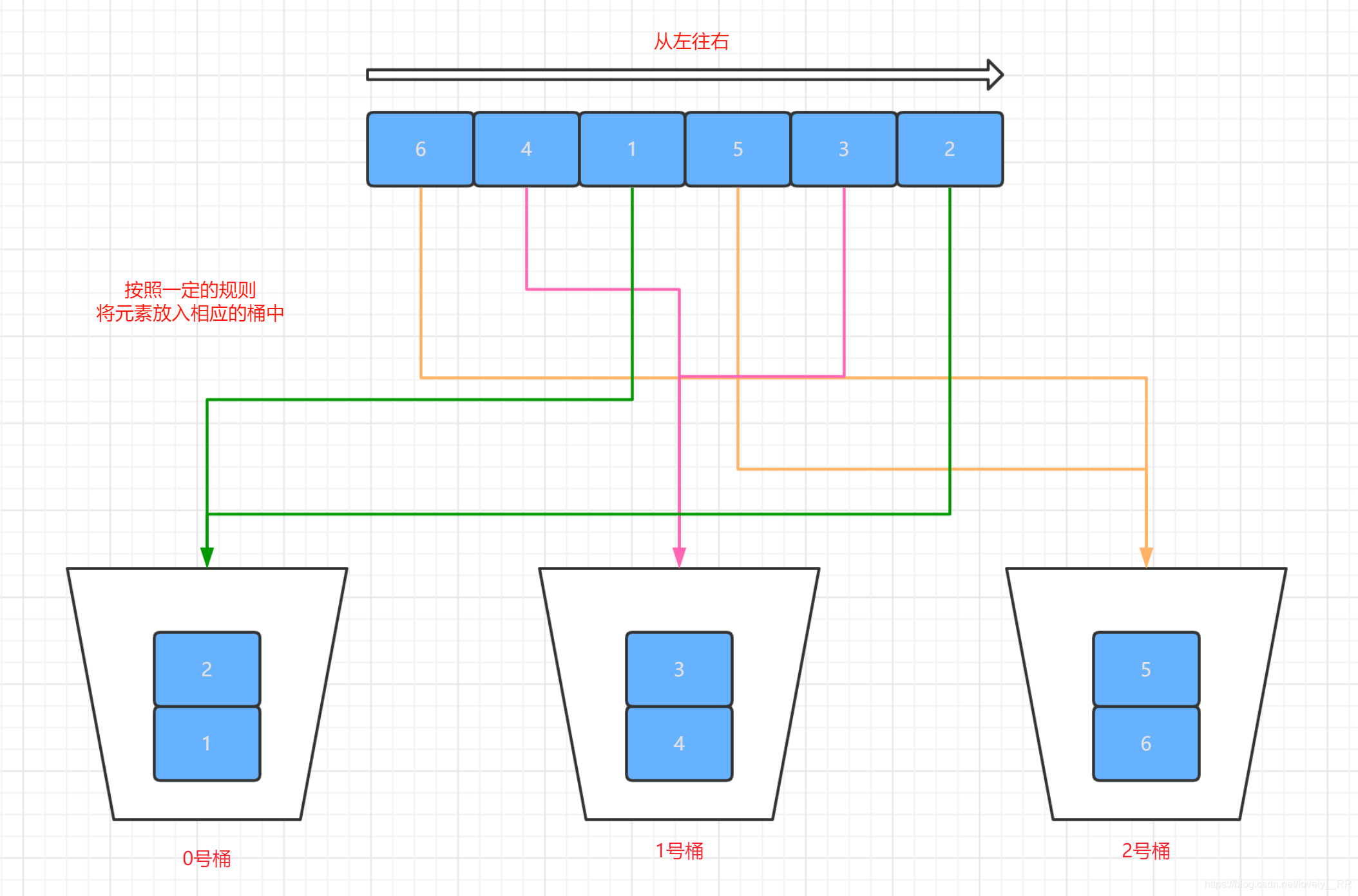
可以看到我們把相應的元素放入相應的桶里面了.這個放入的規則是這樣的:桶是從大到小排列的,并且每一個桶都會有一個資料范圍,意思就是0號桶存放是1~ 2資料范圍的資料,1號桶存放3~4資料范圍的資料,2號桶存放吧5 ~6資料范圍內的資料.詳細的放入規則我會在下面的實作步驟里面說.這里大家先簡單了解一下.
這里大家要注意的一點就是,我們在把元素放入各自相應的桶里面的時候,是需要對桶內的序列進行排序的,意思就是等到每個元素都放入相應的桶里面之后,桶里面相應的序列本身也已經有序了.就如下圖所示:
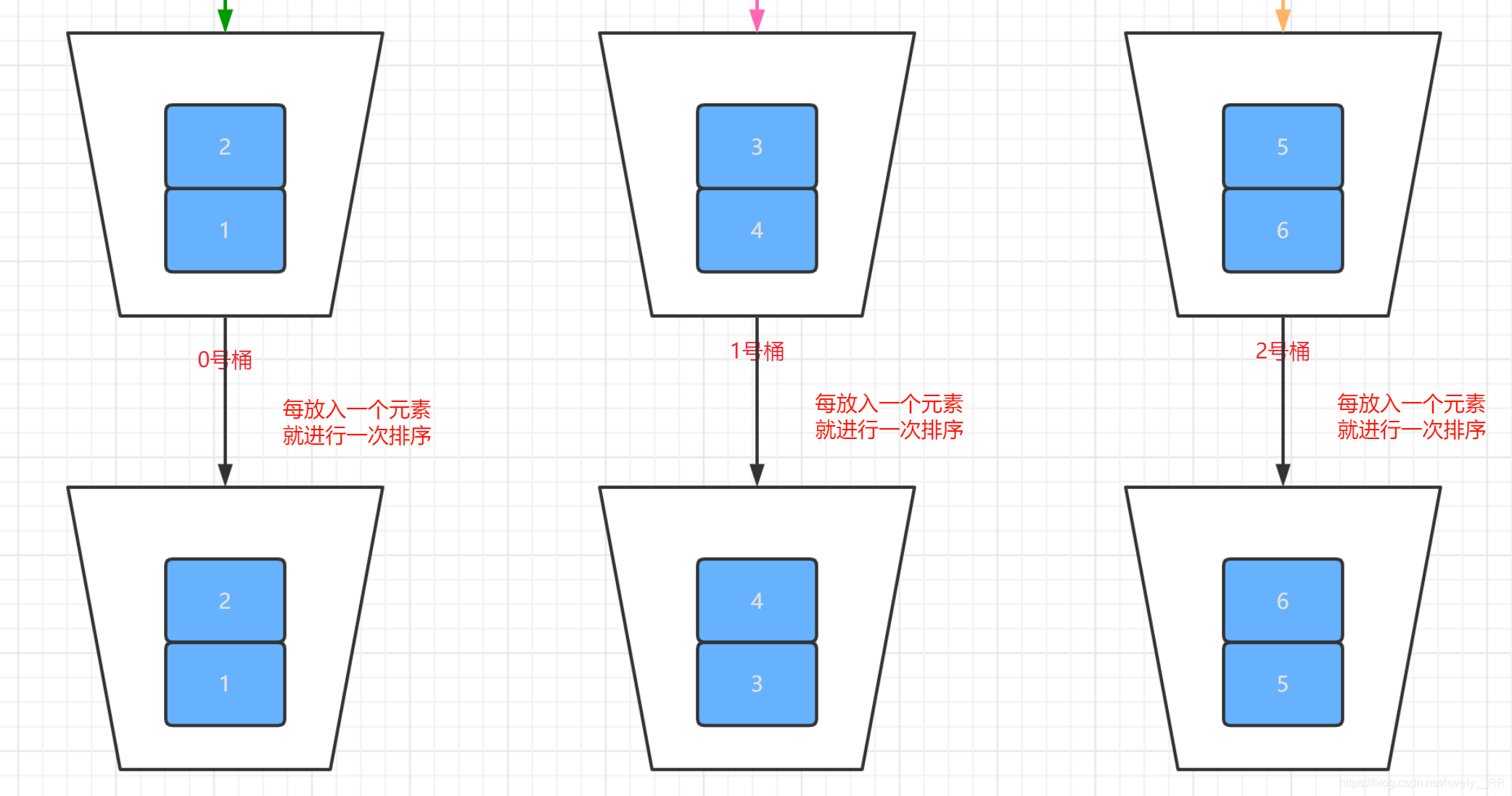
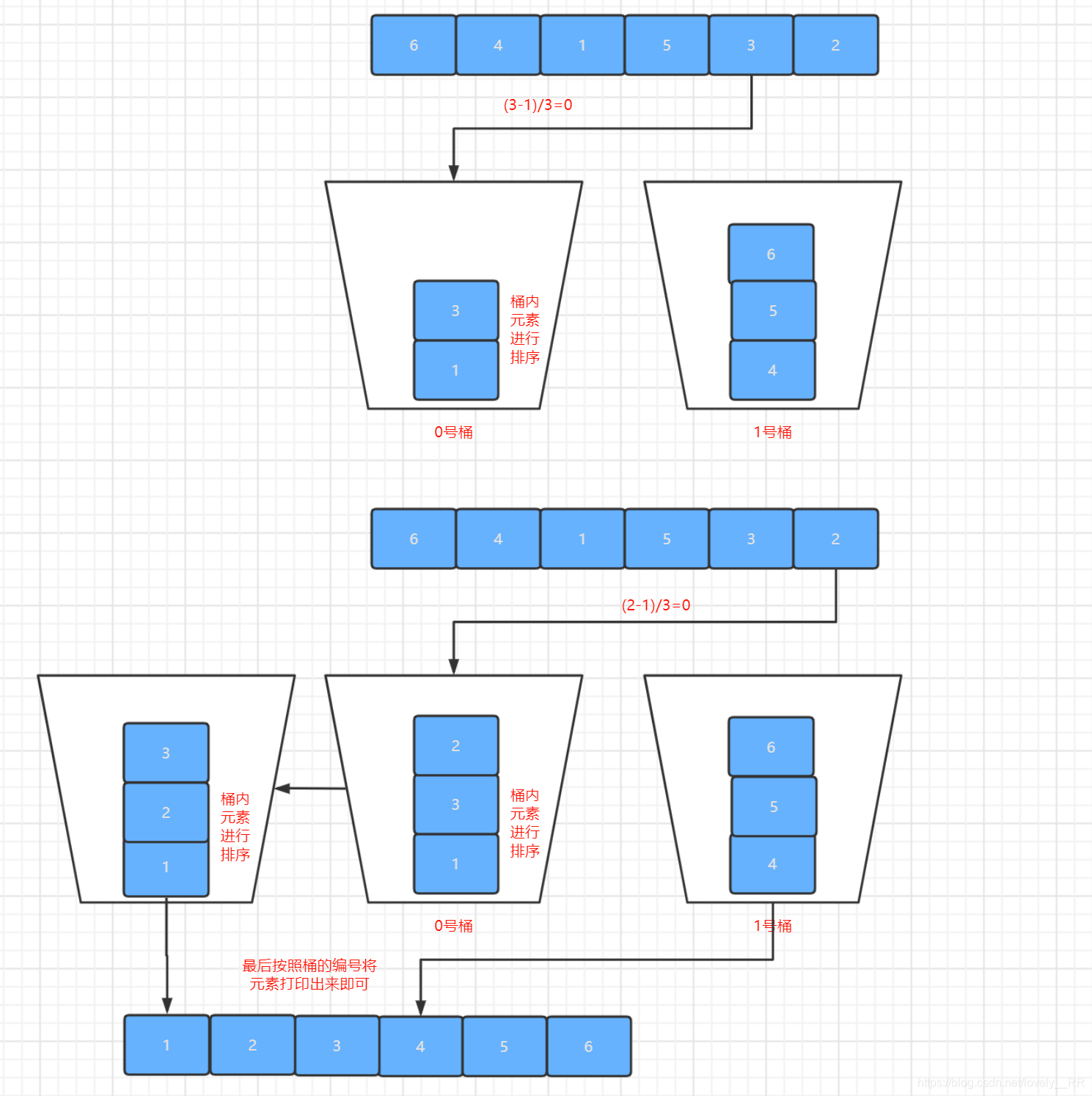
可以看到上面,每個桶內的序列都已經排好序了,那么很顯然我們最后就只需要按照桶的序號大小將桶內的元素列印出來,那么我們的序列就已經排好序了.
說完桶排序的基本思想之后,我們接下來就說一下桶排序在代碼上是如何實作的,大致有下面這幾步:
-
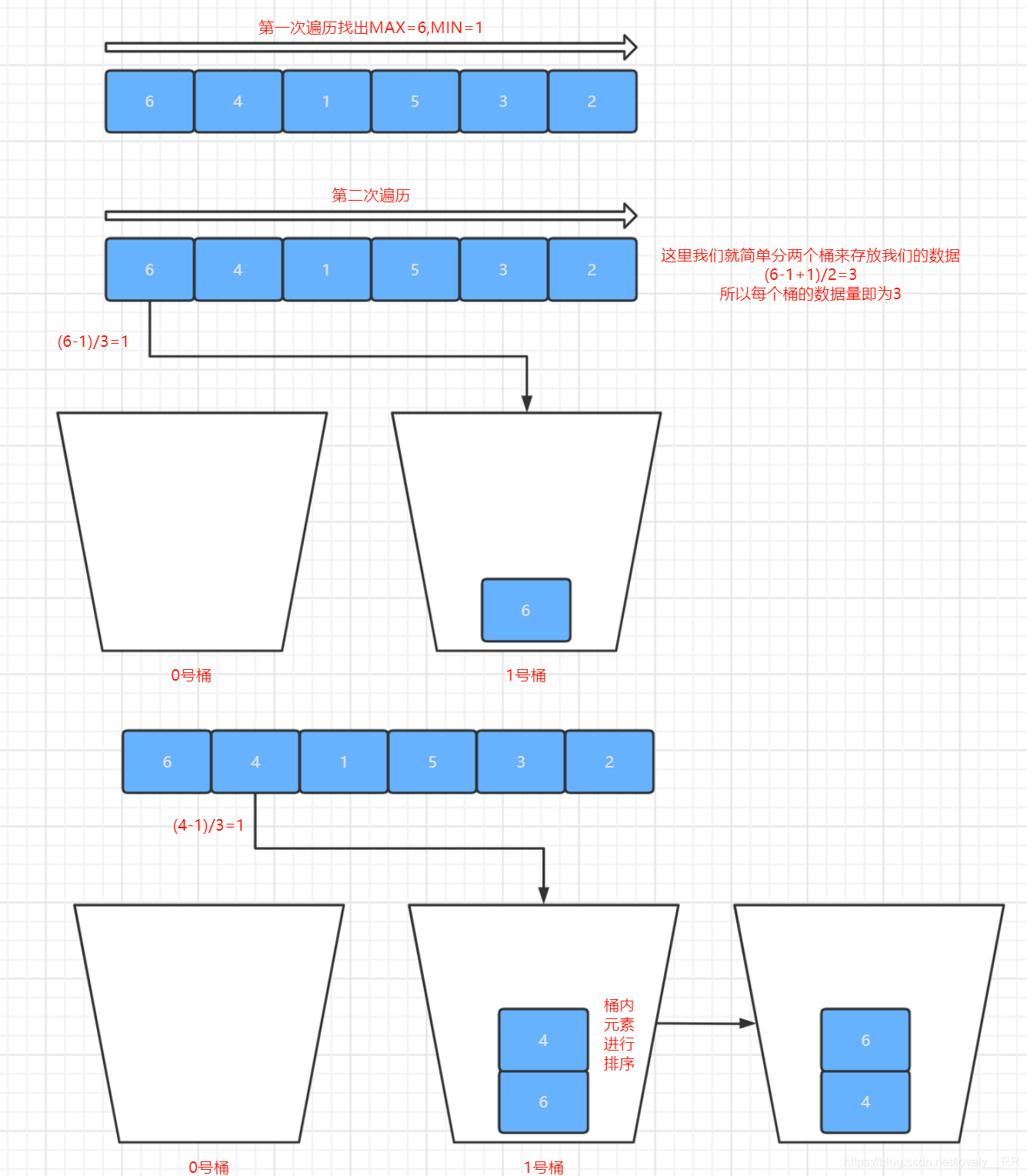
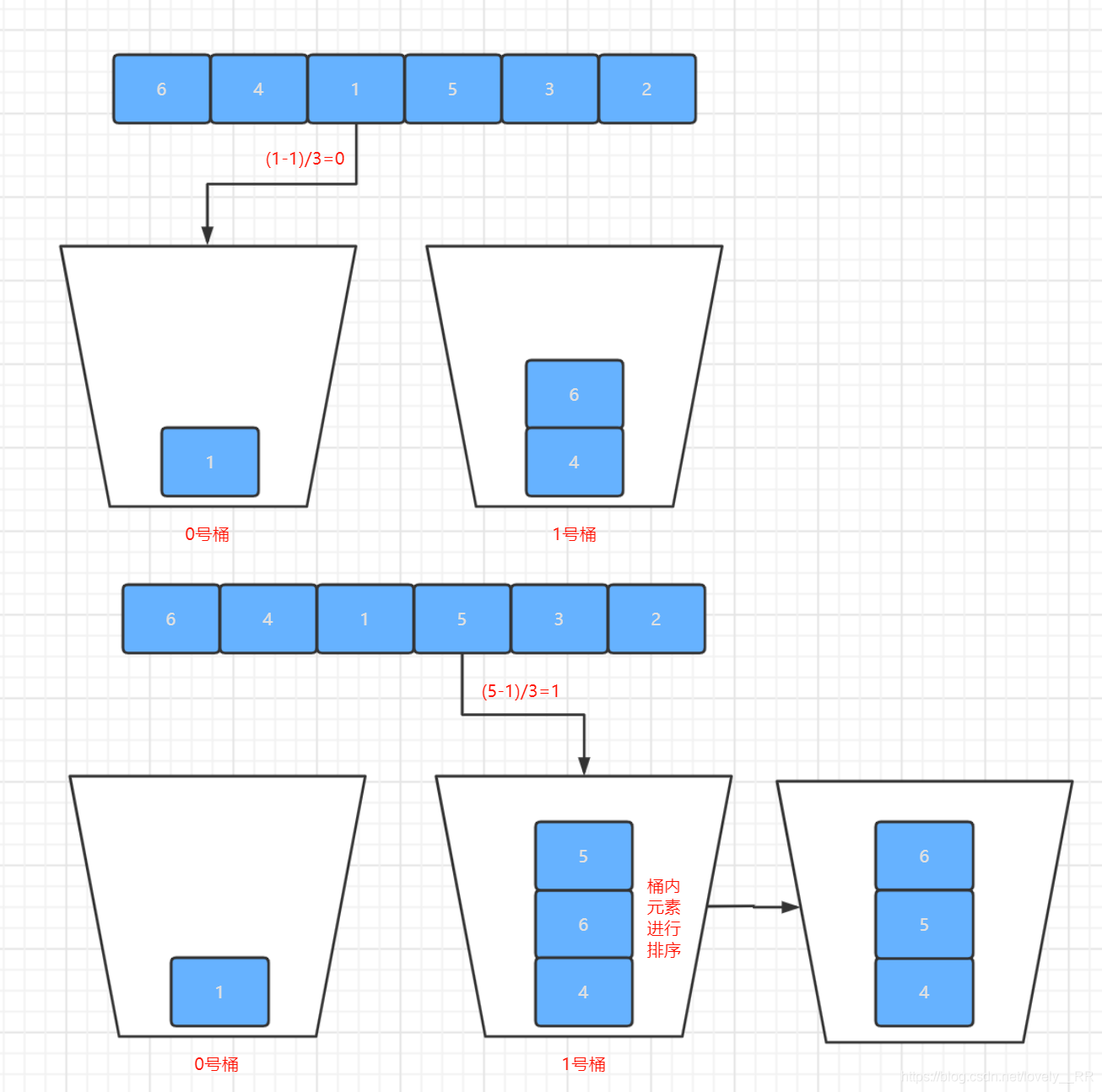
1.我們首先需要第一次遍歷我們的序列,得到我們序列中的最大值
MAX以及序列中的最小值MIN,找到我們序列中的最大值與最小值之后,那么我們就可以確定序列中的所有都是在MIN~MAX這個資料范圍區間之中. -
2.第二步我們就是需要根據序列的資料范圍來確定我們到底需要幾個桶來存放我們的元素,這一步其實是比較關鍵的,因為桶的數量太多或者太少都會降低桶排序的效率.
我們舉兩個例子:
假設我們桶的數量太少,就比如說只有一個桶:
那么很顯然我們的桶排序就又重新退化成我們前兩篇內容里介紹的比較演算法了.又假設我們桶的數量太多,就比如說有
MAX-MIN+1個桶:

那么很顯然這時候的桶排序又重新退化成了我們上面剛剛講解過的計數排序了.所以說我們需要確定好一個適中的桶的數量,不然回就會出現我們上面所說到的幾種情況.但是有沒有一個特定的公式來確定桶的數量.所以我們還是只能自己確定桶的數量.但是有一個規則我們還是可以考慮進去的,那就是
最好讓元素平均的分散到每一個桶里. -
3.確定完桶的數量之后,我們就可以給每個桶來劃分資料范圍了.一般是這樣劃分的,
(MAX-MIN+1)/桶的數量,得到的結果就是桶長.之后每個桶的資料范圍就通過桶的編號以及桶長就可以確定每個桶的資料范圍.就如下面的公式:左閉右開
桶的資料范圍=[MIN+(桶的編號-1)*桶長,MIN+桶的編號 *桶長)
有了每個桶的資料范圍時候,我們第二次遍歷序列將每個元素存到相應的桶里面了.這個程序我們要注意,在往桶里面添加元素的時候,就需要在每個桶里面將元素排好序. -
4.當我們第二次遍歷結束之后,我們就只需要按照桶的編號,在將該編號的桶里面的元素列印出來,桶排序就已經完成了.
接下來我們還是通過下面的圖來動態演示一下桶排序的程序:
了解完桶排序的基本思想之后,按照慣例我們還是來簡單分析一下他的一些特點:
- 桶排序是
穩定的,原因和上面計數排序的理由是一樣的. - 桶排序也是一個
通過空間換取時間的演算法,但是他的空間復雜度是可以控制的.就像我們上面說的主要就是控制桶的數量.如果桶的數量設定的合理,既能降低時間復雜度,也能降低空間復雜度.
演算法圖解:

示例代碼:
//在鏈表中添加元素的同時需要進行元素的排序
public static void sort(ArrayList<Integer>list,int i) {
if(list==null)
list.add(i);
//這里采用的排序方式為插入排序
else {
int flag=list.size()-1;
while(flag>=0&&list.get(flag)>i) {
if(flag+1>=list.size())
list.add(list.get(flag));
else
list.set(flag+1, list.get(flag));
flag--;
}
if(flag != (list.size()-1))
//注意這里是flag+1,自己可以嘗試將這里換成flag看看,會出現陣列越界的情況
list.set(flag+1, i);
else
list.add(i);
}
}
public static void Bucketsort(int []num,int sum) {
//遍歷得到陣列中的最大值與最小值
int min=Integer.MAX_VALUE;
int max=Integer.MIN_VALUE;
for(int i=0;i<num.length;i++) {
min = min <= num[i] ? min: num[i];
max = max >= num[i] ? max: num[i];
}
//求出每個桶的長度,這里必須使用Double
double size=(double)(max-min+1)/sum;
ArrayList<Integer>list[]=new ArrayList[sum];
for(int i=0;i<sum;i++) {
list[i]=new ArrayList<Integer>();
}
//將每個元素放入對應的桶之中同時進行桶內元素的排序
for(int i=0;i<num.length;i++) {
System.out.println("元素:"+String.format("%-2s", num[i])+", 被分配到"+(int)Math.floor((num[i]-min)/size)+"號桶");
sort(list[(int)Math.floor((num[i]-min)/size)], num[i]);
}
System.out.println();
for(int i=0;i<sum;i++) {
System.out.println(String.format("%-1s", i)+"號桶內排序:"+list[i]);
}
System.out.println();
//順序遍歷各個桶,得出我們 已經排序號的序列
for(int i=0;i<list.length;i++) {
if(list[i]!=null){
for(int j=0;j<list[i].size();j++) {
System.out.print(list[i].get(j)+" ");
}
}
}
System.out.println();
System.out.println();
}
public static void main(String[] args) {
int []num ={7,4,9,3,2,1,8,6,5,10};
long startTime=System.currentTimeMillis();
//這里桶的數量可以你自己定義,這里我就定義成了3
Bucketsort(num, 3);
long endTime=System.currentTimeMillis();
System.out.println("程式運行時間: "+(endTime-startTime)+"ms");
}

這里的時間是不準確的,因為我需要將每輪排序的結果列印出來給大家看,所以會多花費一些時間,如果大家想要看真實的時間的話,大家可以把我列印結果的代碼注釋掉再看看演算法的執行時間.
復雜度分析:
理解完桶排序的基本思想之后,我們就需要來分析一下他的時間復雜度,空間復雜度.
-
時間復雜度
桶排序的時間復雜度和上面的計數排序是一樣的,同樣也是線性級別的,但是也是增加了桶的時間,所以也是
O(n+k) -
空間復雜度
上面我們已經說過了,桶排序本身也是一個通過空間來換取時間的演算法,所以很明顯他的空間復雜度就會很高.并且這個空間復雜度主要就取決于桶的數量以及桶的范圍,所以假設有k個桶的話,那么空間復雜度就為
O(n+k)
4-基數排序
演算法思想:
基數排序的實作步驟非常好理解,但是想要真正理解他的演算法思想就稍微有點難度了.那么接下來就來講解基數排序的演算法思想.
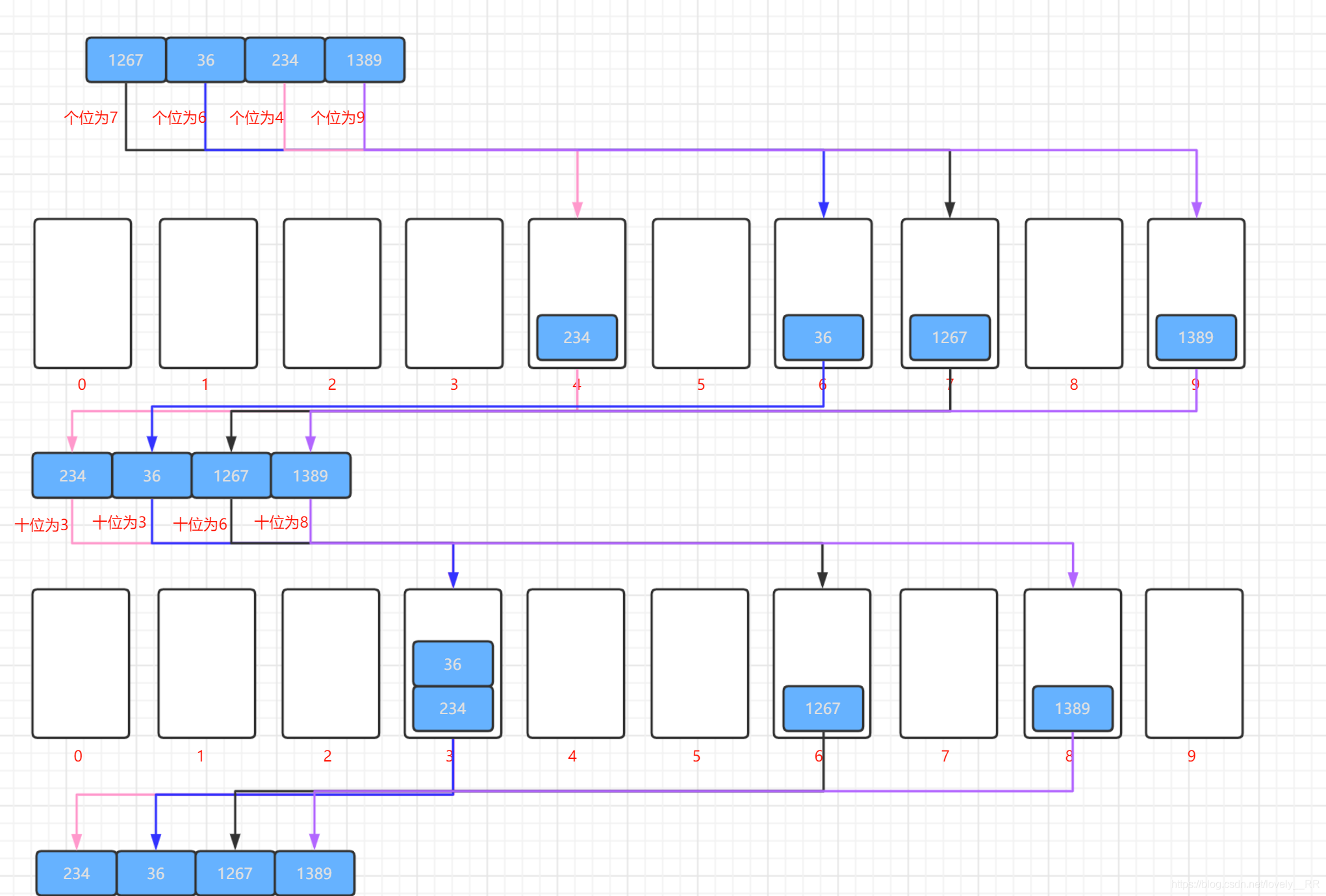
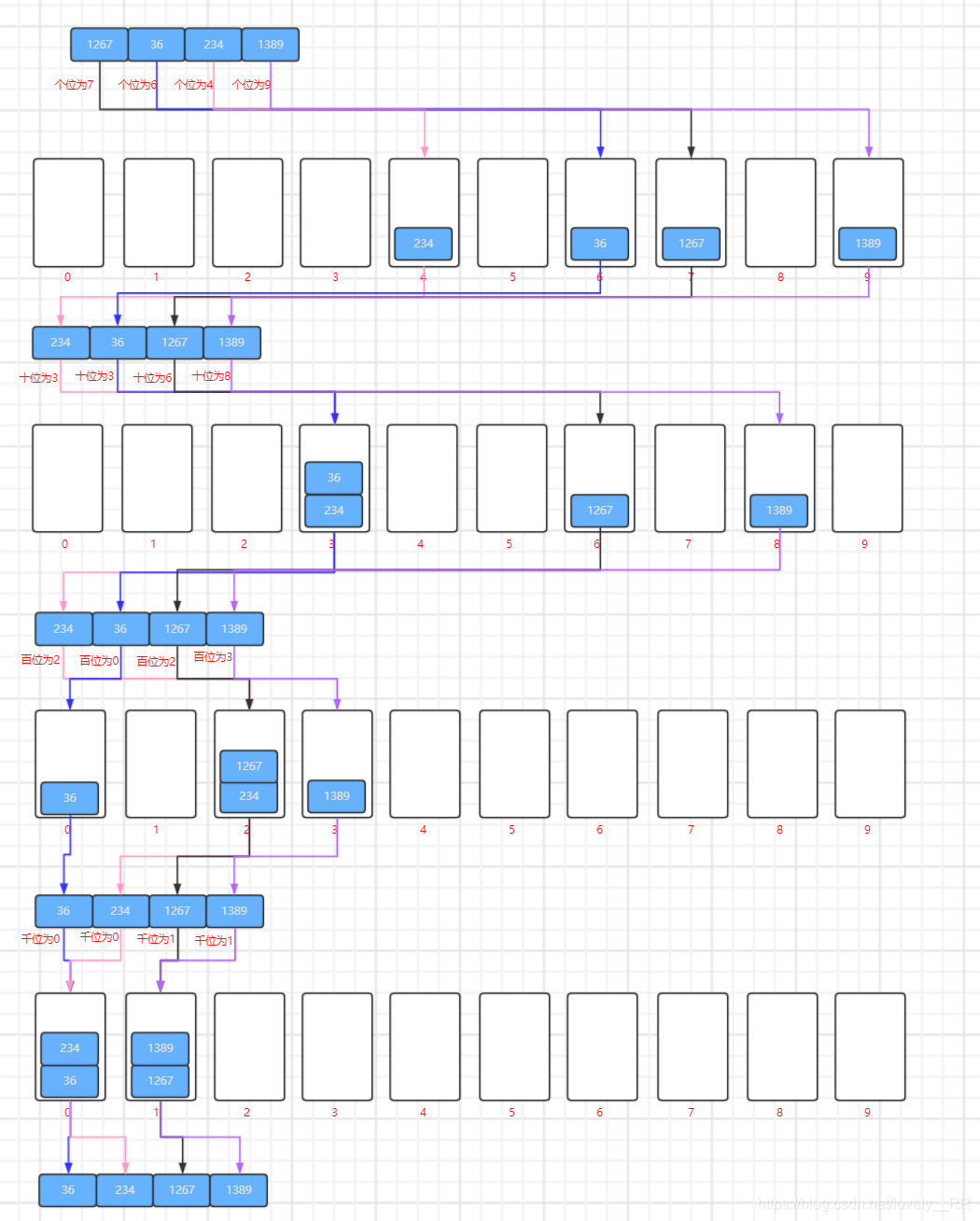
首先基數排序是根據數位來進行排序的.他是從個位開始,然后按照每一位的數進行排序,如下圖所示:
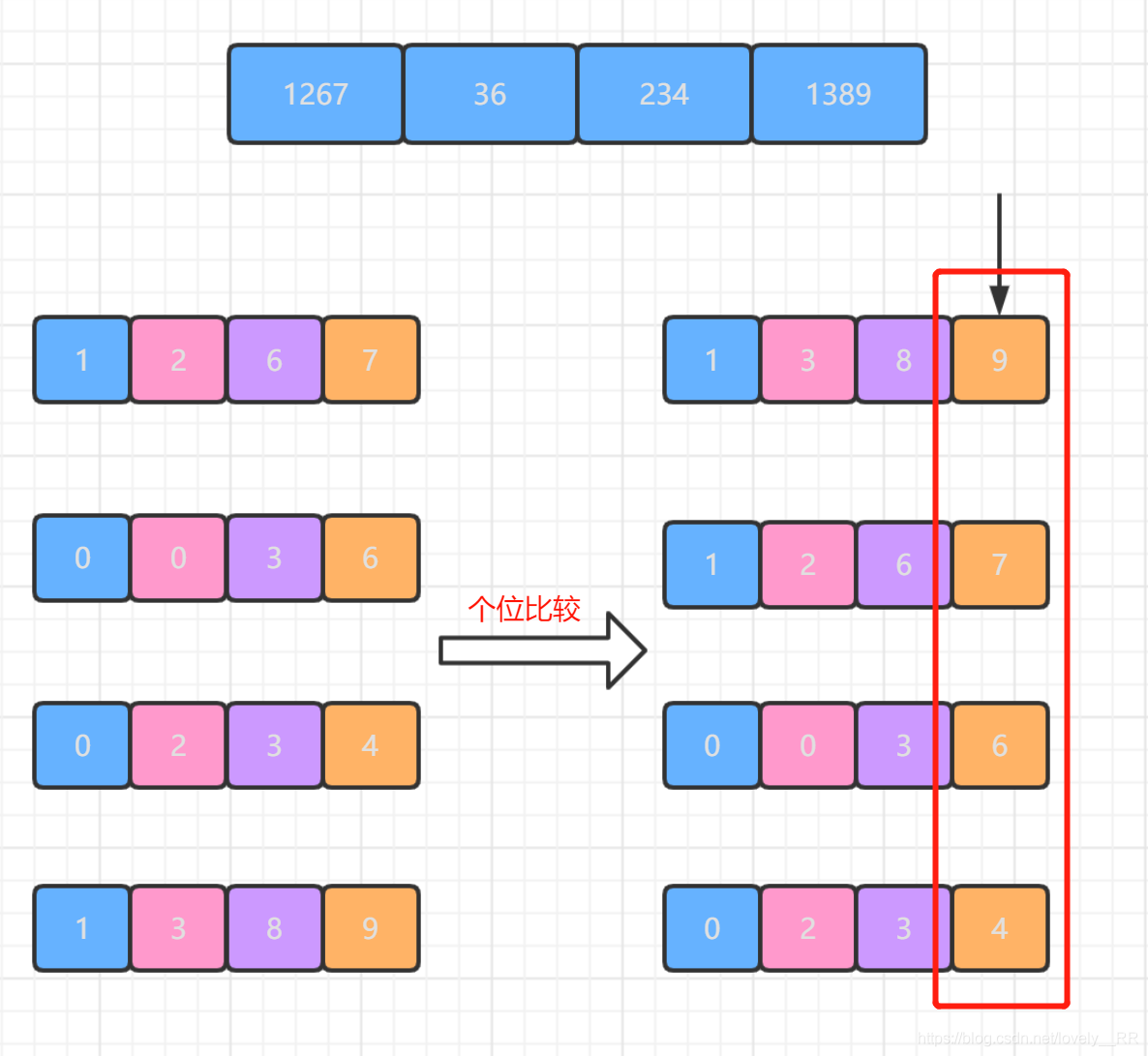
排完序之后就往前進一位,然后再將所有的數按照這一位所在的數進行排序,如下圖所示:
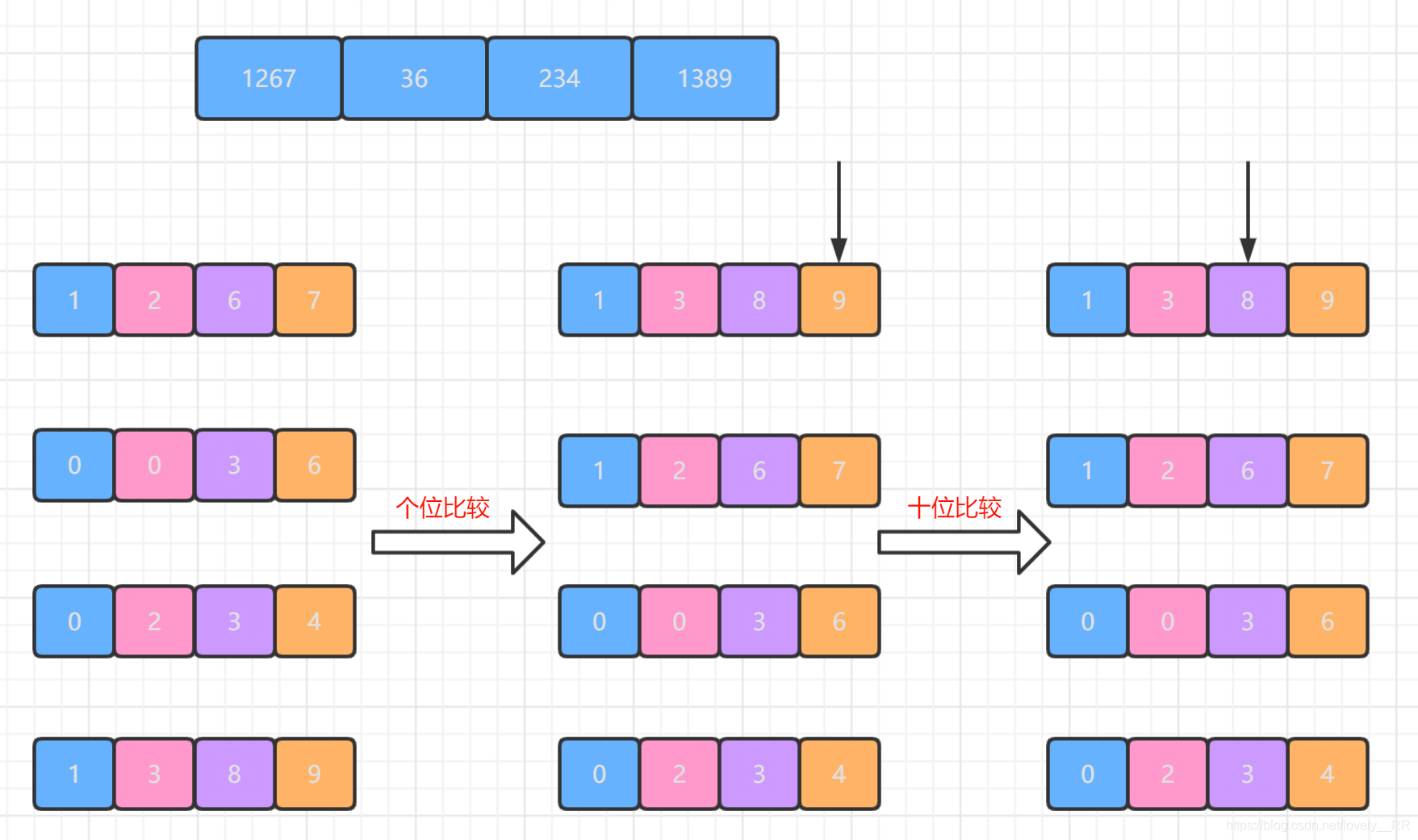
重復這個程序直到所有的位數都已經被排過序了.如下圖所示:
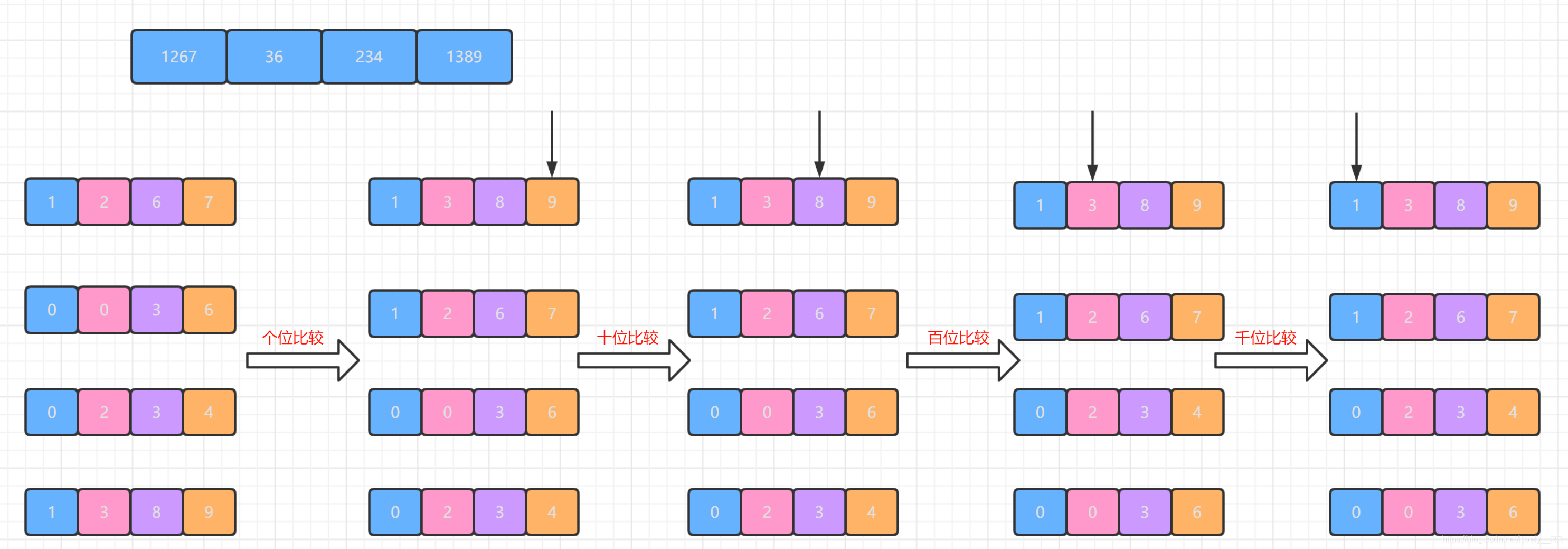
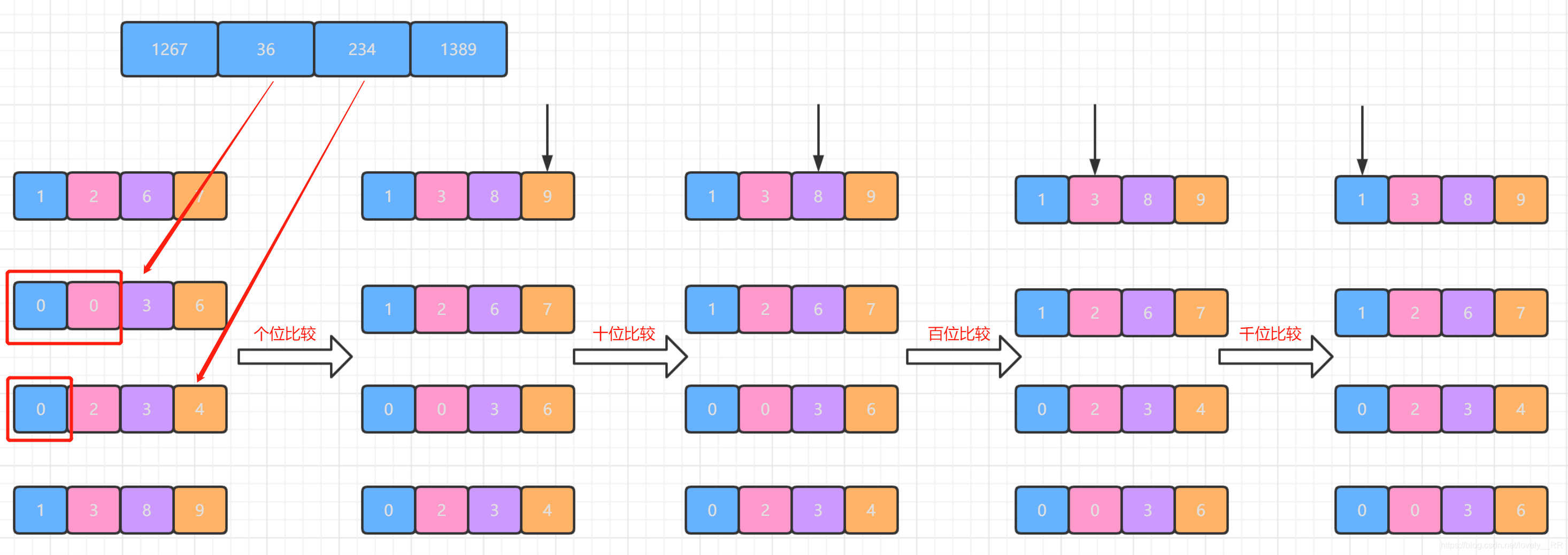
并且如果這個程序中碰到某個數在這個為上沒有數的話就進行補零操作,將該位看成是0.就比方下圖我用紅框圈出來的部分:
等到所有的位數都已經排序完畢之后,我們就可以看到我們已經排序好的序列了.
這個程序相信大家肯定都很好理解,但是相信大家如果是第一次看這個演算法的肯定會有和我當初一樣的困惑,那就是為什么基數排序選擇的是從低位到高位來進行排序的呢,而不是像我們平常比較資料的大小一樣,從高位到低位來比較呢?
這里呢我們先不講為什么,我們先看下面這兩個案例:
- 從高位到低位進行比較
| 原序列 | 百位排好序后 | 十位排好序后 | 個位排好序后 |
|---|---|---|---|
| 329 | 839 | 657 | 839 |
| 457 | 720 | 457 | 329 |
| 657 | 657 | 355 | 657 |
| 839 | 457 | 839 | 457 |
| 436 | 436 | 436 | 436 |
| 720 | 329 | 720 | 355 |
| 355 | 355 | 329 | 720 |
- 從低位到高位進行比較
| 原序列 | 個位排好序后 | 十位排好序后 | 百位排好序后 |
|---|---|---|---|
| 329 | 720 | 720 | 329 |
| 457 | 355 | 329 | 355 |
| 657 | 436 | 436 | 436 |
| 839 | 457 | 839 | 457 |
| 436 | 657 | 355 | 657 |
| 720 | 329 | 451 | 720 |
| 355 | 839 | 657 | 839 |
對比看了上面兩個例子之后相信大家就知道了,很明顯我們看到如果是從該我到低位來進行比較的話,我們會發現比較到最后之后序列仍然是無序的,但是從低位到高位進行比較的話,我們就會發現序列到最后已經排好序了.
是不是很奇怪,同樣的執行程序,只不過執行的順序發生了改變,為什么結果就回產生這樣的結果呢?產生這個差異的重點就是在我們忽略了一個問題,那就是我們在進行高位到低位比較的時候,高位的權重是高于低位的.就比方下圖所示:
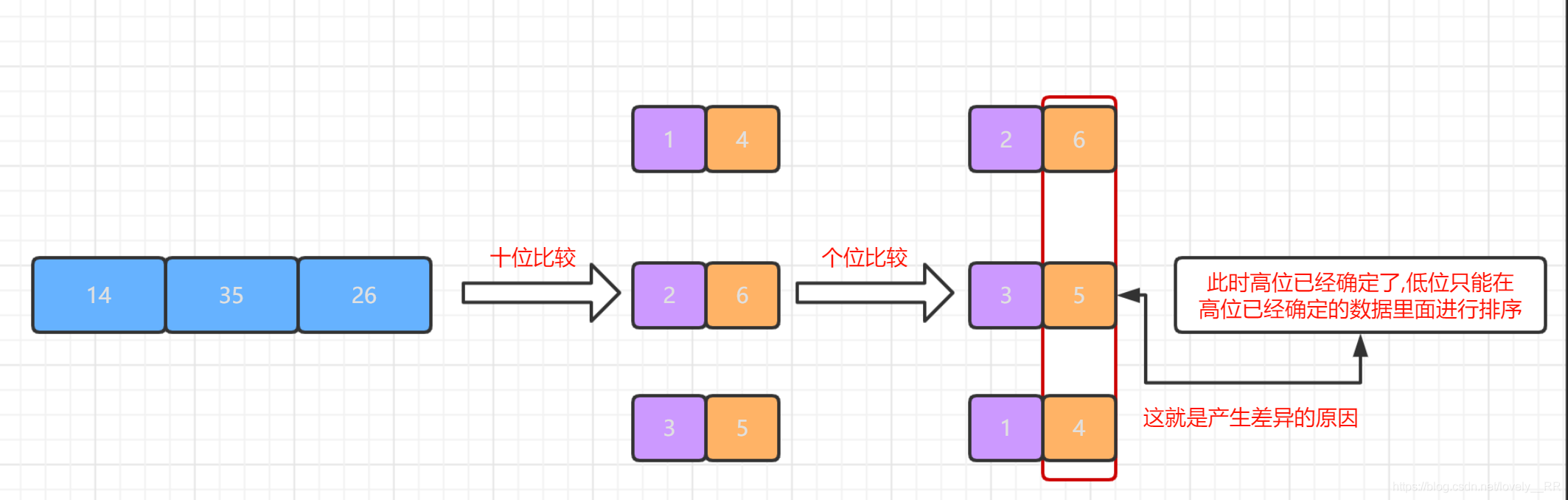
正是因為這個原因,所以我們采取的是從低位到高位比較的程序.
說完基本思想之后,我們來說一下演算法的實作步驟:
-
1.我們第一次遍歷序列.找出序列中的最大值MAX,找到MAX之后我們可以確定我們需要比較多少數位了.
-
2.這時候我們就需要按照元素在該位數對應的數字將元素存入到相應的容器之中.如下圖所示:
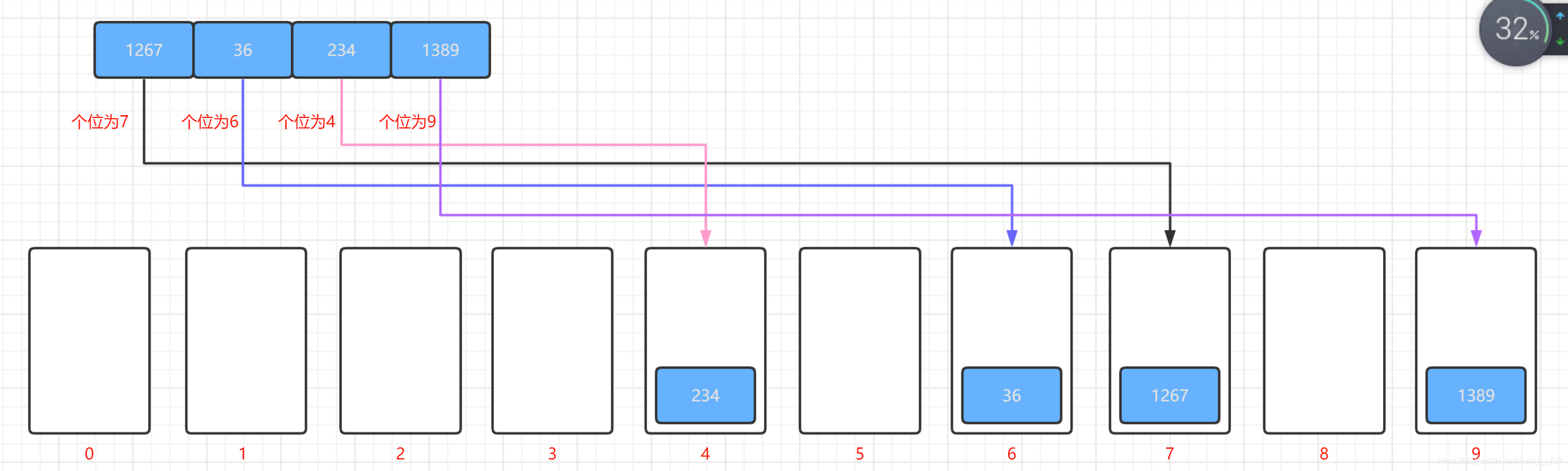
-
3.之后我們再按照容器的順序將元素重新彈出構成我們接下來需要排序的序列,如下圖所示:
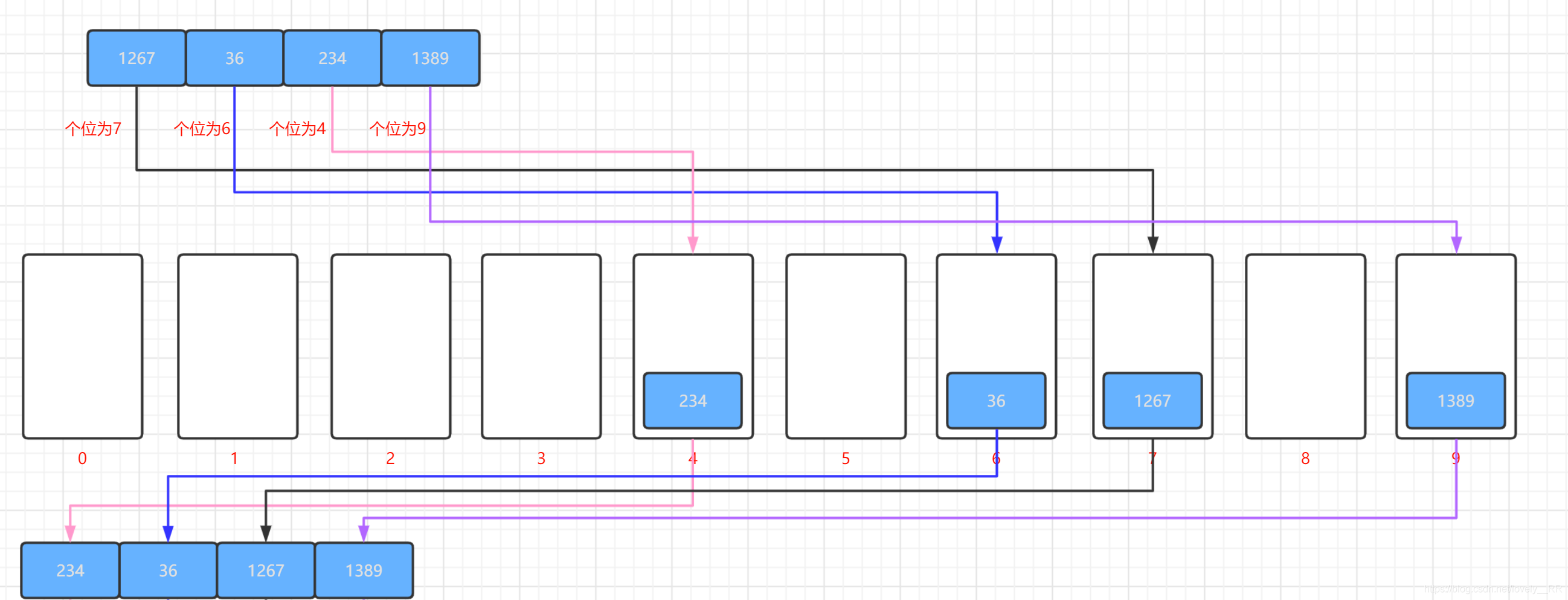
這個從容器彈出的程序需要注意一點,那就是遵循先進先出的原則,所以這個容器選擇佇列或者是鏈表比較合適,不能選擇堆疊,因為堆疊是先進后出,拿取元素的時候回非常麻煩. -
4.最后只需要
重復2,3步驟,直到最高位也比較完畢,那么整個基數排序就已經完成了.
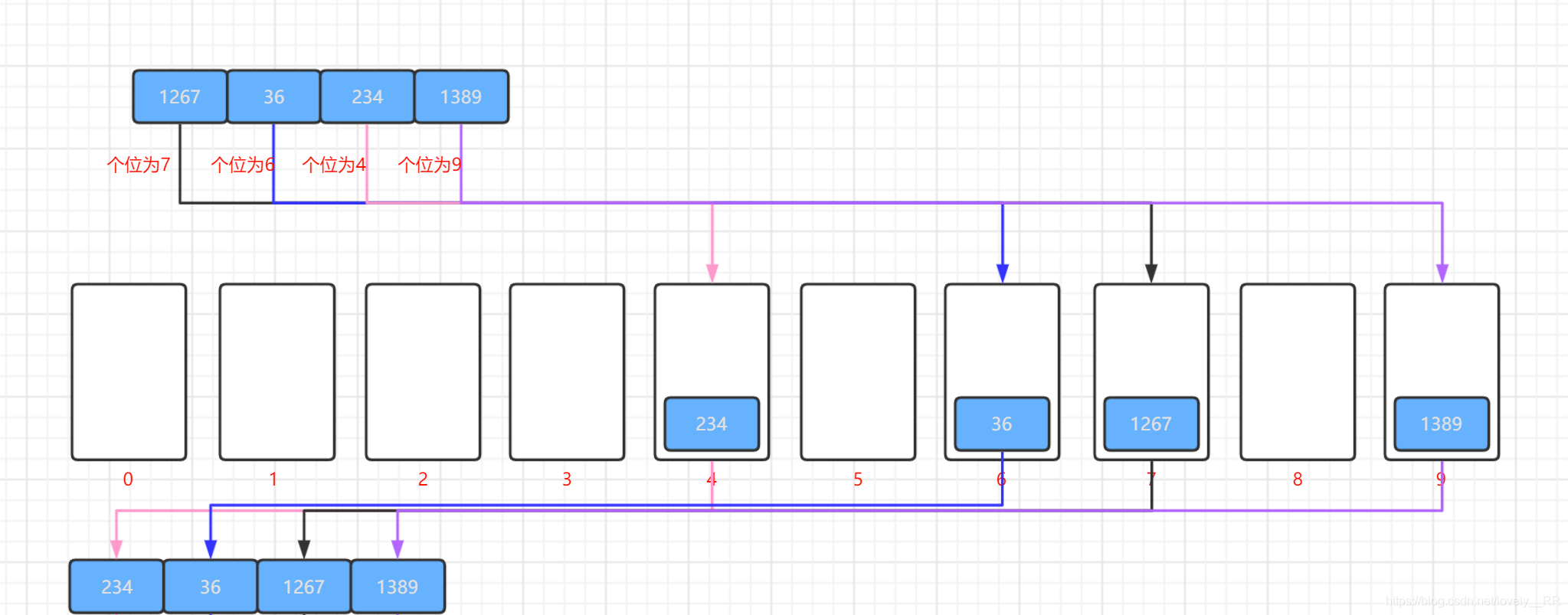
接下來我們還是通過下面的圖來動態演示一下基數排序的程序:
個位排序:
十位排序:
百位排序:
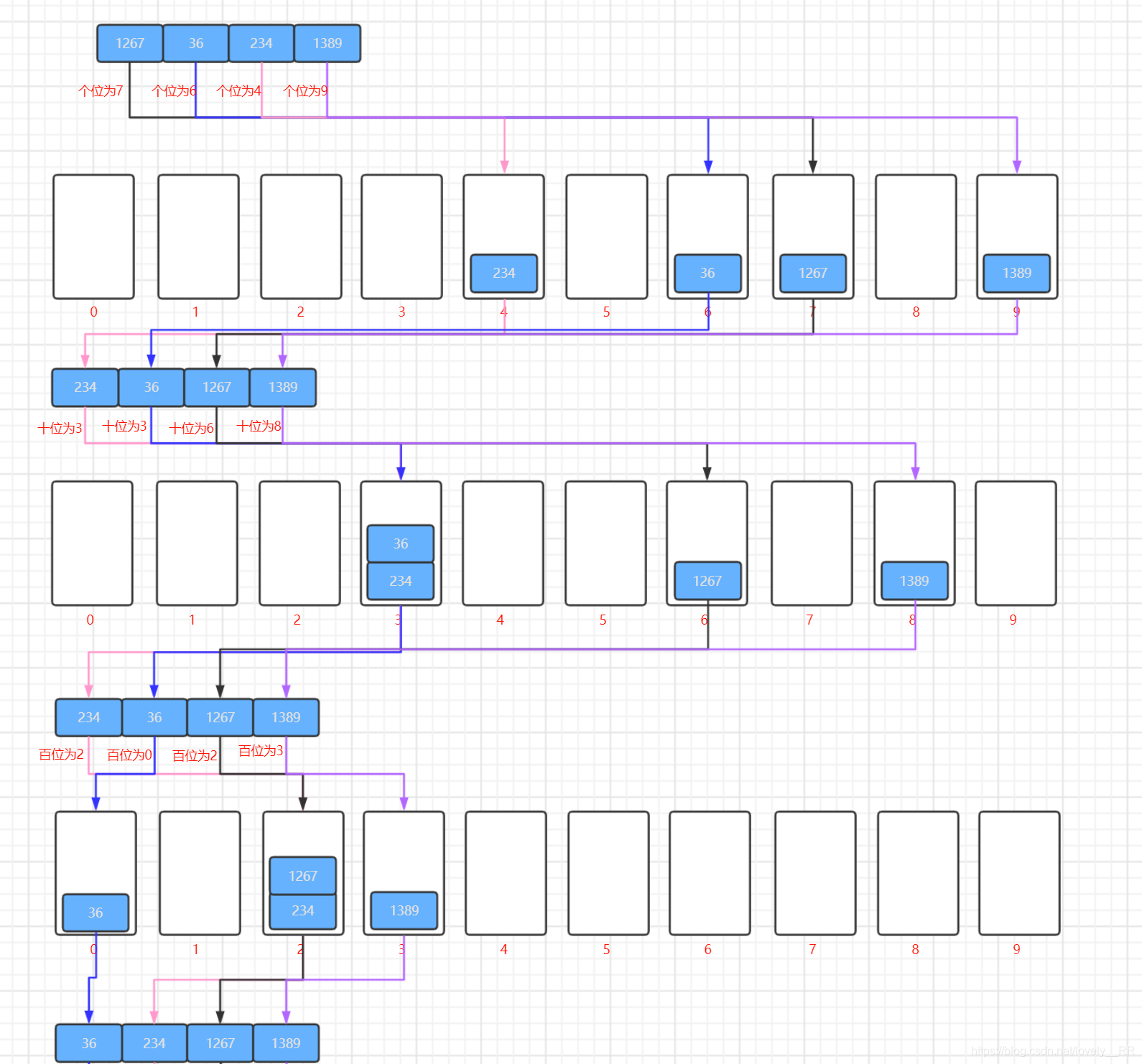
千位排序:
在了解完基數排序的基本思想之后,按照慣例我們還是來簡單分析一下基數排序的特點:
- 基數排序是
穩定的,原因和桶排序以及計數排序的原因一樣.
演算法圖解:

示例代碼:
//將所有的陣列合并成原來的陣列
public static void merge(ArrayList<Integer> list[],int num[]) {
int k=0;
for(int i=0;i<list.length;i++) {
if(list[i]!=null) {
for(int j=0;j<list[i].size();j++) {
num[k++]=list[i].get(j);
System.out.print(num[k-1]+" ");
}
}
//合并完成之后需要將鏈表清空,否則元素會越來越多
list[i].clear();
}
System.out.println();
}
//將所有的元素分散到各個鏈表之中
public static void split(ArrayList<Integer> list[],int num[],int k) {
for(int j=0;j<num.length;j++) {
list[num[j]/k%10].add(num[j]);
}
System.out.println("-----------------------------------------------------------------------");
System.out.println("個位開始數,第"+(String.valueOf(k).length())+"位排序結果:");
for(int j=0;j<10;j++) {
System.out.println((String.valueOf(k).length())+"號位,數值為"+j+"的鏈表結果:"+list[j]);
}
}
public static void main(String[] args) {
ArrayList<Integer>list[]=new ArrayList [10];
for(int i=0;i<10;i++) {
list[i]=new ArrayList<Integer>();
}
int []num ={7,14,9,333,201,1,88,6,57,10,56,74,36,234,456};
long startTime=System.currentTimeMillis();
int max=Integer.MIN_VALUE;
//第一次遍歷獲得序列中的最大值
for(int i=0;i<num.length;i++) {
if(num[i]>max)
max=num[i];
}
int k=1;
for(int i=0;i<String.valueOf(max).length();i++) {
split(list, num, k);
System.out.println("第"+(i+1)+"次排序");
merge(list, num);
k=k*10;
}
long endTime=System.currentTimeMillis();
System.out.println("程式運行時間: "+(endTime-startTime)+"ms");
}

復雜度分析:
理解完基數排序的基本思想之后,我們就需要來分析一下他的時間復雜度,空間復雜度.
-
時間復雜度
看完我們上面的動圖演示之后我們可以看到基數排序只需要根據最大元素的位數,遍歷相應次數的序列即可,所以我們可以確定基數排序的時間復雜度一定是線性級別的,但是雖然是線性級別的,但是有一個系數的,這個系數就是最大元素的位數K,所以時間復雜度應該是
O(n*k) -
空間復雜度
空間復雜度我們也可以看出來,主要就是取決于
鏈表的數量以及序列元素的數量,所以空間復雜度為O(n+k)
到這里十大經典排序演算法詳解的內容就已經全部講解完畢了.這一次文章不管是在內容的質量上或者是在文章的排版上,都是目前作業量比較大的一期.所以如果大家覺得文章還行或者覺得文章對你有幫助的話,UP希望能關注一下我的公眾號:萌萌噠的瓤瓤,或者覺得關注公眾號麻煩的話,也可以給我的文章一鍵三連.新人UP真的很需要你的支持!!!

不點在看,你也好看!
點點在看,你更好看!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/256319.html
標籤:AI
上一篇:作業經驗|lambada處理集合的常用10種實戰騷操作,我都記錄下來了
下一篇:[數學建模]差值演算法及代碼