為什么要改造XXL-JOB原有的日志檔案生成體系
? xxl-job原本自己的客戶端日志檔案生成策略是:一個日志記錄就生成一個檔案,也就是當資料庫存在一條日志logId,對應的客戶端就會生成一個檔案,由于定時任務跑批很多,并且有些任務間隔時間很短,比如幾秒觸發一次,這樣的結果就是客戶端會生成大量的檔案,但是每個檔案的內容其實不多,但大量的單獨檔案相比會占用更多的磁盤,造成磁盤資源緊張,同時對檔案系統性能存在影響,長久以來,就會觸發資源報警,所以,如果不想經常去清理日志檔案的話,那么將零碎的檔案通過某種方式進行整合就顯得迫切需要了,
本文篇幅較長,代碼涉及較多啦~
改造后的日志檔案生成策略
基本描述
? 減少日志檔案個數,其實就是要將分散的日志檔案進行合并,同時建立外部索引檔案維護各自當次日志Id所對應的起始日志內容,在讀取的時候先通過讀取索引檔案,進而再讀取真實的日志內容,
? 下面是日志檔案描述分析圖:
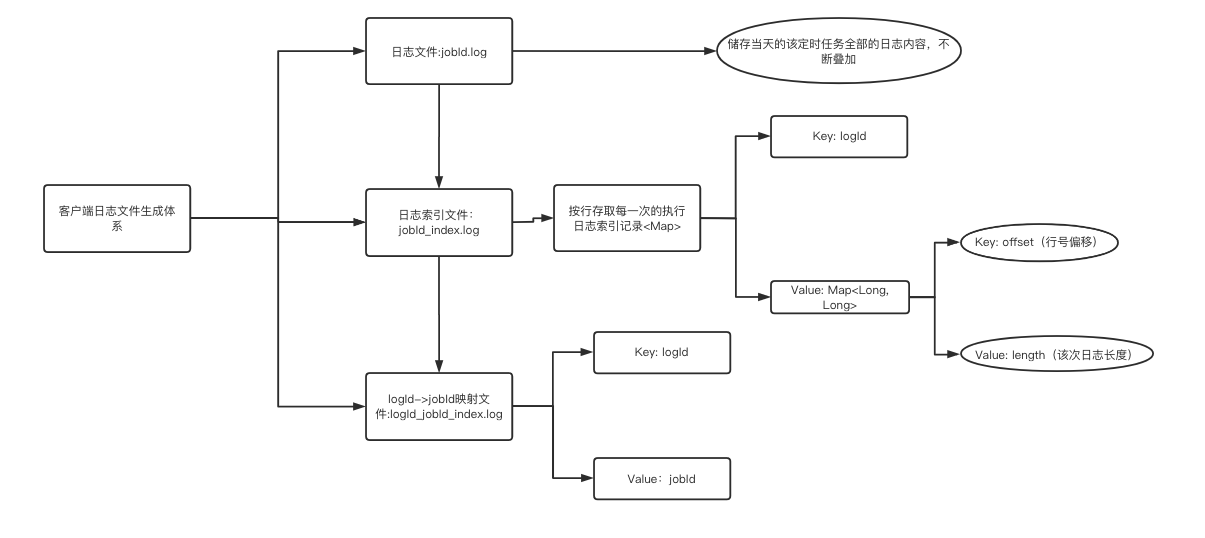
對于一個執行器,在執行器下的所有的定時任務每天只生成一個logId_jobId_index.log的索引檔案,用來維護日志Id與任務Id的對應關系;
對于一個定時任務,每天只生成一個jobId.log的日志內容檔案,里面保存當天所有的日志內容;
對于日志索引檔案jobId_index.log,用來維護日志內容中的索引,便于知道jobId.log中對應行數是屬于哪個logId的,便于查找,
? 大致思路就是如此,可以預期,日志檔案大大的減少,磁盤占用應該會得到改善.
? 筆者改造的這個功能已經在線上跑了快接近一年了,目前暫未出現問題,如有需要可結合自身業務進行相應的調整與改造,以及認真測驗,以防未知錯誤,
代碼實操
本文改造是基于XXL-JOB 1.8.2 版本改造,其他版本暫未實驗
? 打開代碼目錄xxl-job-core模塊,主要涉及以下幾個檔案的改動:
- XxlJobFileAppender.java
- XxlJobLogger.java
- JobThread.java
- ExecutorBizImpl.java
- LRUCacheUtil.java
XxlJobFileAppender.java
? 代碼中部分原有未涉及改動的方法此處不再粘貼,
package com.xxl.job.core.log;
import com.xxl.job.core.biz.model.LogResult;
import com.xxl.job.core.util.LRUCacheUtil;
import org.apache.commons.io.FilenameUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.util.StringUtils;
import java.io.*;
import java.text.DecimalFormat;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Pattern;
/**
* store trigger log in each log-file
* @author xuxueli 2016-3-12 19:25:12
*/
public class XxlJobFileAppender {
private static Logger logger = LoggerFactory.getLogger(XxlJobFileAppender.class);
// for JobThread (support log for child thread of job handler)
//public static ThreadLocal<String> contextHolder = new ThreadLocal<String>();
public static final InheritableThreadLocal<String> contextHolder = new InheritableThreadLocal<String>();
// for logId,記錄日志Id
public static final InheritableThreadLocal<Integer> contextHolderLogId = new InheritableThreadLocal<>();
// for JobId,定時任務的Id
public static final InheritableThreadLocal<Integer> contextHolderJobId = new InheritableThreadLocal<>();
// 使用一個快取map集合來存取索引偏移量資訊
public static final LRUCacheUtil<Integer, Map<String ,Long>> indexOffsetCacheMap = new LRUCacheUtil<>(80);
private static final String DATE_FOMATE = "yyyy-MM-dd";
private static final String UTF_8 = "utf-8";
// 檔案名后綴
private static final String FILE_SUFFIX = ".log";
private static final String INDEX_SUFFIX = "_index";
private static final String LOGID_JOBID_INDEX_SUFFIX = "logId_jobId_index";
private static final String jobLogIndexKey = "jobLogIndexOffset";
private static final String indexOffsetKey = "indexOffset";
/**
* log base path
*
* strut like:
* ---/
* ---/gluesource/
* ---/gluesource/10_1514171108000.js
* ---/gluesource/10_1514171108000.js
* ---/2017-12-25/
* ---/2017-12-25/639.log
* ---/2017-12-25/821.log
*
*/
private static String logBasePath = "/data/applogs/xxl-job/jobhandler";
private static String glueSrcPath = logBasePath.concat("/gluesource");
public static void initLogPath(String logPath){
// init
if (logPath!=null && logPath.trim().length()>0) {
logBasePath = logPath;
}
// mk base dir
File logPathDir = new File(logBasePath);
if (!logPathDir.exists()) {
logPathDir.mkdirs();
}
logBasePath = logPathDir.getPath();
// mk glue dir
File glueBaseDir = new File(logPathDir, "gluesource");
if (!glueBaseDir.exists()) {
glueBaseDir.mkdirs();
}
glueSrcPath = glueBaseDir.getPath();
}
public static String getLogPath() {
return logBasePath;
}
public static String getGlueSrcPath() {
return glueSrcPath;
}
/**
* 重寫生成日志目錄和日志檔案名的方法:
* log filename,like "logPath/yyyy-MM-dd/jobId.log"
* @param triggerDate
* @param jobId
* @return
*/
public static String makeLogFileNameByJobId(Date triggerDate, int jobId) {
// filePath/yyyy-MM-dd
// avoid concurrent problem, can not be static
SimpleDateFormat sdf = new SimpleDateFormat(DATE_FOMATE);
File logFilePath = new File(getLogPath(), sdf.format(triggerDate));
if (!logFilePath.exists()) {
logFilePath.mkdir();
}
// 生成日志索引檔案
String logIndexFileName = logFilePath.getPath()
.concat("/")
.concat(String.valueOf(jobId))
.concat(INDEX_SUFFIX)
.concat(FILE_SUFFIX);
File logIndexFilePath = new File(logIndexFileName);
if (!logIndexFilePath.exists()) {
try {
logIndexFilePath.createNewFile();
logger.debug("生成日志索引檔案,檔案路徑:{}", logIndexFilePath);
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
}
// 在yyyy-MM-dd檔案夾下生成當天的logId對應的jobId的全域索引,減少對后管的修改
String logIdJobIdIndexFileName = logFilePath.getPath()
.concat("/")
.concat(LOGID_JOBID_INDEX_SUFFIX)
.concat(FILE_SUFFIX);
File logIdJobIdIndexFileNamePath = new File(logIdJobIdIndexFileName);
if (!logIdJobIdIndexFileNamePath.exists()) {
try {
logIdJobIdIndexFileNamePath.createNewFile();
logger.debug("生成logId與jobId的索引檔案,檔案路徑:{}", logIdJobIdIndexFileNamePath);
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
}
// filePath/yyyy-MM-dd/jobId.log log日志檔案
String logFileName = logFilePath.getPath()
.concat("/")
.concat(String.valueOf(jobId))
.concat(FILE_SUFFIX);
return logFileName;
}
/**
* 后管平臺讀取詳細日志查看,生成檔案名
* admin read log, generate logFileName bu logId
* @param triggerDate
* @param logId
* @return
*/
public static String makeFileNameForReadLog(Date triggerDate, int logId) {
// filePath/yyyy-MM-dd
SimpleDateFormat sdf = new SimpleDateFormat(DATE_FOMATE);
File logFilePath = new File(getLogPath(), sdf.format(triggerDate));
if (!logFilePath.exists()) {
logFilePath.mkdir();
}
String logIdJobIdFileName = logFilePath.getPath().concat("/")
.concat(LOGID_JOBID_INDEX_SUFFIX)
.concat(FILE_SUFFIX);
// find logId->jobId mapping
// 獲取索引映射
String infoLine = readIndex(logIdJobIdFileName, logId);
String[] arr = infoLine.split("->");
int jobId = 0;
try {
jobId = Integer.parseInt(arr[1]);
} catch (Exception e) {
logger.error("makeFileNameForReadLog StringArrayException,{},{}", e.getMessage(), e);
throw new RuntimeException("StringArrayException");
}
String logFileName = logFilePath.getPath().concat("/")
.concat(String.valueOf(jobId)).concat(FILE_SUFFIX);
return logFileName;
}
/**
* 向日志檔案中追加內容,向索引檔案中追加索引
* append log
* @param logFileName
* @param appendLog
*/
public static void appendLogAndIndex(String logFileName, String appendLog) {
// log file
if (logFileName == null || logFileName.trim().length() == 0) {
return;
}
File logFile = new File(logFileName);
if (!logFile.exists()) {
try {
logFile.createNewFile();
} catch (Exception e) {
logger.error(e.getMessage(), e);
return;
}
}
// start append, count line num
long startLineNum = countFileLineNum(logFileName);
logger.debug("開始追加日志檔案,開始行數:{}", startLineNum);
// log
if (appendLog == null) {
appendLog = "";
}
appendLog += "\r\n";
// append file content
try {
FileOutputStream fos = null;
try {
fos = new FileOutputStream(logFile, true);
fos.write(appendLog.getBytes("utf-8"));
fos.flush();
} finally {
if (fos != null) {
try {
fos.close();
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
}
}
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
// end append, count line num,再次計數
long endLineNum = countFileLineNum(logFileName);
Long lengthTmp = endLineNum - startLineNum;
int length = 0;
try {
length = lengthTmp.intValue();
} catch (Exception e) {
logger.error("Long to int Exception", e);
}
logger.debug("結束追加日志檔案,結束行數:{}, 長度:{}", endLineNum, length);
Map<String, Long> indexOffsetMap = new HashMap<>();
appendIndexLog(logFileName, startLineNum, length, indexOffsetMap);
appendLogIdJobIdFile(logFileName, indexOffsetMap);
}
/**
* 創建日志Id與JobId的映射關系
* @param logFileName
* @param indexOffsetMap
*/
public static void appendLogIdJobIdFile(String logFileName, Map indexOffsetMap) {
// 獲取ThreadLocal中變數保存的值
int logId = XxlJobFileAppender.contextHolderLogId.get();
int jobId = XxlJobFileAppender.contextHolderJobId.get();
File file = new File(logFileName);
// 獲取父級目錄,尋找同檔案夾下的索引檔案
String parentDirName = file.getParent();
// logId_jobId_index fileName
String logIdJobIdIndexFileName = parentDirName.concat("/")
.concat(LOGID_JOBID_INDEX_SUFFIX)
.concat(FILE_SUFFIX);
// 從快取中獲取logId
boolean jobLogIndexOffsetExist = indexOffsetCacheMap.exists(logId);
Long jobLogIndexOffset = null;
if (jobLogIndexOffsetExist) {
jobLogIndexOffset = indexOffsetCacheMap.get(logId).get(jobLogIndexKey);
}
if (jobLogIndexOffset == null) {
// 為空則添加
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append(logId).append("->").append(jobId).append("\r\n");
Long currentPoint = getAfterAppendIndexLog(logIdJobIdIndexFileName, stringBuffer.toString());
indexOffsetMap.put(jobLogIndexKey, currentPoint);
indexOffsetCacheMap.save(logId, indexOffsetMap);
}
// 不為空說明快取已經存在,不做其他處理
}
/**
* 追加索引檔案內容,回傳偏移量
* @param fileName
* @param content
* @return
*/
private static Long getAfterAppendIndexLog(String fileName, String content) {
RandomAccessFile raf = null;
Long point = null;
try {
raf = new RandomAccessFile(fileName, "rw");
long end = raf.length();
// 因為是追加內容,所以將指標放入到檔案的末尾
raf.seek(end);
raf.writeBytes(content);
// 獲取當前的指標偏移量
/**
* 偏移量放入到快取變數中:注意,此處獲取偏移量,是獲取開始的地方的偏移量,不能再追加內容后再獲取,否則會獲取到結束
* 時的偏移量
*/
point = end;
} catch (IOException e) {
logger.error(e.getMessage(), e);
} finally {
try {
raf.close();
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
}
return point;
}
/**
* 追加索引日志,like "345->(577,10)"
* @param logFileName
* @param from
* @param length
* @param indexOffsetMap
*/
public static void appendIndexLog(String logFileName, Long from, int length, Map indexOffsetMap) {
int strLength = logFileName.length();
// 通過截取獲取索引檔案名
String prefixFilePath = logFileName.substring(0, strLength - 4);
String logIndexFilePath = prefixFilePath.concat(INDEX_SUFFIX).concat(FILE_SUFFIX);
File logIndexFile = new File(logIndexFilePath);
if (!logIndexFile.exists()) {
try {
logIndexFile.createNewFile();
} catch (IOException e) {
logger.error(e.getMessage(), e);
return;
}
}
int logId = XxlJobFileAppender.contextHolderLogId.get();
StringBuffer stringBuffer = new StringBuffer();
// 判斷是添加還是修改
boolean indexOffsetExist = indexOffsetCacheMap.exists(logId);
Long indexOffset = null;
if (indexOffsetExist) {
indexOffset = indexOffsetCacheMap.get(logId).get(indexOffsetKey);
}
if (indexOffset == null) {
// append
String lengthStr = getFormatNum(length);
stringBuffer.append(logId).append("->(")
.append(from).append(",").append(lengthStr).append(")\r\n");
// 添加新的索引,記錄偏移量
Long currentIndexPoint = getAfterAppendIndexLog(logIndexFilePath, stringBuffer.toString());
indexOffsetMap.put(indexOffsetKey, currentIndexPoint);
} else {
String infoLine = getIndexLineIsExist(logIndexFilePath, logId);
// 修改索引檔案內容
int startTmp = infoLine.indexOf("(");
int endTmp = infoLine.indexOf(")");
String[] lengthTmp = infoLine.substring(startTmp + 1, endTmp).split(",");
int lengthTmpInt = 0;
try {
lengthTmpInt = Integer.parseInt(lengthTmp[1]);
from = Long.valueOf(lengthTmp[0]);
} catch (Exception e) {
logger.error("appendIndexLog StringArrayException,{},{}", e.getMessage(), e);
throw new RuntimeException("StringArrayException");
}
int modifyLength = length + lengthTmpInt;
String lengthStr2 = getFormatNum(modifyLength);
stringBuffer.append(logId).append("->(")
.append(from).append(",").append(lengthStr2).append(")\r\n");
modifyIndexFileContent(logIndexFilePath, infoLine, stringBuffer.toString());
}
}
/**
* handle getFormatNum
* like 5 to 005
* @return
*/
private static String getFormatNum(int num) {
DecimalFormat df = new DecimalFormat("000");
String str1 = df.format(num);
return str1;
}
/**
* 查詢索引是否存在
* @param filePath
* @param logId
* @return
*/
private static String getIndexLineIsExist(String filePath, int logId) {
// 讀取索引問價判斷是否存在,日志每生成一行就會呼叫一次,所以索引檔案需要將同一個logId對應的進行合并
String prefix = logId + "->";
Pattern pattern = Pattern.compile(prefix + ".*?");
String indexInfoLine = "";
RandomAccessFile raf = null;
try {
raf = new RandomAccessFile(filePath, "rw");
String tmpLine = null;
// 偏移量
boolean indexOffsetExist = indexOffsetCacheMap.exists(logId);
Long cachePoint = null;
if (indexOffsetExist) {
cachePoint = indexOffsetCacheMap.get(logId).get(indexOffsetKey);
}
if (null == cachePoint) {
cachePoint = Long.valueOf(0);
}
raf.seek(cachePoint);
while ((tmpLine = raf.readLine()) != null) {
final long point = raf.getFilePointer();
boolean matchFlag = pattern.matcher(tmpLine).find();
if (matchFlag) {
indexInfoLine = tmpLine;
break;
}
cachePoint = point;
}
} catch (IOException e) {
logger.error(e.getMessage(), e);
} finally {
try {
raf.close();
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
}
return indexInfoLine;
}
/**
* 在后管頁面上需要查詢執行日志的時候,獲取索引資訊,
* 此處不能與上個通用,因為讀取時沒有map存取偏移量資訊,相對隔離
* @param filePath
* @param logId
* @return
*/
private static String readIndex(String filePath, int logId) {
filePath = FilenameUtils.normalize(filePath);
String prefix = logId + "->";
Pattern pattern = Pattern.compile(prefix + ".*?");
String indexInfoLine = "";
BufferedReader bufferedReader = null;
try {
bufferedReader = new BufferedReader(new FileReader(filePath));
String tmpLine = null;
while ((tmpLine = bufferedReader.readLine()) != null) {
boolean matchFlag = pattern.matcher(tmpLine).find();
if (matchFlag) {
indexInfoLine = tmpLine;
break;
}
}
bufferedReader.close();
} catch (IOException e) {
logger.error(e.getMessage(), e);
} finally {
if (bufferedReader != null) {
try {
bufferedReader.close();
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
}
}
return indexInfoLine;
}
/**
* 修改 logIndexFile 內容
* @param indexFileName
* @param oldContent
* @param newContent
* @return
*/
private static boolean modifyIndexFileContent(String indexFileName, String oldContent, String newContent) {
RandomAccessFile raf = null;
int logId = contextHolderLogId.get();
try {
raf = new RandomAccessFile(indexFileName, "rw");
String tmpLine = null;
// 偏移量
boolean indexOffsetExist = indexOffsetCacheMap.exists(logId);
Long cachePoint = null;
if (indexOffsetExist) {
cachePoint = indexOffsetCacheMap.get(logId).get(indexOffsetKey);
}
if (null == cachePoint) {
cachePoint = Long.valueOf(0);
}
raf.seek(cachePoint);
while ((tmpLine = raf.readLine()) != null) {
final long point = raf.getFilePointer();
if (tmpLine.contains(oldContent)) {
String str = tmpLine.replace(oldContent, newContent);
raf.seek(cachePoint);
raf.writeBytes(str);
}
cachePoint = point;
}
} catch (IOException e) {
logger.error(e.getMessage(), e);
} finally {
try {
raf.close();
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
}
return true;
}
/**
* 統計檔案內容行數
* @param logFileName
* @return
*/
private static long countFileLineNum(String logFileName) {
File file = new File(logFileName);
if (file.exists()) {
try {
FileReader fileReader = new FileReader(file);
LineNumberReader lineNumberReader = new LineNumberReader(fileReader);
lineNumberReader.skip(Long.MAX_VALUE);
// getLineNumber() 從0開始計數,所以加1
long totalLines = lineNumberReader.getLineNumber() + 1;
fileReader.close();
lineNumberReader.close();
return totalLines;
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
}
return 0;
}
/**
* 重寫讀取日志:1. 讀取logIndexFile;2.logFile
* @param logFileName
* @param logId
* @param fromLineNum
* @return
*/
public static LogResult readLogByIndex(String logFileName, int logId, int fromLineNum) {
int strLength = logFileName.length();
// 獲取檔案名前綴出去.log
String prefixFilePath = logFileName.substring(0, strLength-4);
String logIndexFilePath = prefixFilePath.concat(INDEX_SUFFIX).concat(FILE_SUFFIX);
// valid logIndex file
if (StringUtils.isEmpty(logIndexFilePath)) {
return new LogResult(fromLineNum, 0, "readLogByIndex fail, logIndexFile not found", true);
}
logIndexFilePath = FilenameUtils.normalize(logIndexFilePath);
File logIndexFile = new File(logIndexFilePath);
if (!logIndexFile.exists()) {
return new LogResult(fromLineNum, 0, "readLogByIndex fail, logIndexFile not exists", true);
}
// valid log file
if (StringUtils.isEmpty(logFileName)) {
return new LogResult(fromLineNum, 0, "readLogByIndex fail, logFile not found", true);
}
logFileName = FilenameUtils.normalize(logFileName);
File logFile = new File(logFileName);
if (!logFile.exists()) {
return new LogResult(fromLineNum, 0, "readLogByIndex fail, logFile not exists", true);
}
// read logIndexFile
String indexInfo = readIndex(logIndexFilePath, logId);
int startNum = 0;
int endNum = 0;
if (!StringUtils.isEmpty(indexInfo)) {
int startTmp = indexInfo.indexOf("(");
int endTmp = indexInfo.indexOf(")");
String[] fromAndTo = indexInfo.substring(startTmp + 1, endTmp).split(",");
try {
startNum = Integer.parseInt(fromAndTo[0]);
endNum = Integer.parseInt(fromAndTo[1]) + startNum;
} catch (Exception e) {
logger.error("readLogByIndex StringArrayException,{},{}", e.getMessage(), e);
throw new RuntimeException("StringArrayException");
}
}
// read File
StringBuffer logContentBuffer = new StringBuffer();
int toLineNum = 0;
LineNumberReader reader = null;
try {
reader = new LineNumberReader(new InputStreamReader(new FileInputStream(logFile), UTF_8));
String line = null;
while ((line = reader.readLine()) != null) {
// [from, to], start as fromNum(logIndexFile)
toLineNum = reader.getLineNumber();
if (toLineNum >= startNum && toLineNum < endNum) {
logContentBuffer.append(line).append("\n");
}
// break when read over
if (toLineNum >= endNum) {
break;
}
}
} catch (IOException e) {
logger.error(e.getMessage(), e);
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
}
}
LogResult logResult = new LogResult(fromLineNum, toLineNum, logContentBuffer.toString(), false);
return logResult;
}
}
XxlJobLogger.java
package com.xxl.job.core.log;
import com.xxl.job.core.util.DateUtil;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.slf4j.helpers.FormattingTuple;
import org.slf4j.helpers.MessageFormatter;
import java.io.PrintWriter;
import java.io.StringWriter;
import java.util.Date;
/**
* Created by xuxueli on 17/4/28.
*/
public class XxlJobLogger {
private static Logger logger = LoggerFactory.getLogger("xxl-job logger");
/**
* append log
*
* @param callInfo
* @param appendLog
*/
private static void logDetail(StackTraceElement callInfo, String appendLog) {
/*// "yyyy-MM-dd HH:mm:ss [ClassName]-[MethodName]-[LineNumber]-[ThreadName] log";
StackTraceElement[] stackTraceElements = new Throwable().getStackTrace();
StackTraceElement callInfo = stackTraceElements[1];*/
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append(DateUtil.formatDateTime(new Date())).append(" ")
.append("["+ callInfo.getClassName() + "#" + callInfo.getMethodName() +"]").append("-")
.append("["+ callInfo.getLineNumber() +"]").append("-")
.append("["+ Thread.currentThread().getName() +"]").append(" ")
.append(appendLog!=null?appendLog:"");
String formatAppendLog = stringBuffer.toString();
// appendlog
String logFileName = XxlJobFileAppender.contextHolder.get();
if (logFileName!=null && logFileName.trim().length()>0) {
// XxlJobFileAppender.appendLog(logFileName, formatAppendLog);
// 此處修改方法呼叫
// modify appendLogAndIndex for addIndexLogInfo
XxlJobFileAppender.appendLogAndIndex(logFileName, formatAppendLog);
} else {
logger.info(">>>>>>>>>>> {}", formatAppendLog);
}
}
}
JobThread.java
@Override
public void run() {
......
// execute
while(!toStop){
running = false;
idleTimes++;
TriggerParam triggerParam = null;
ReturnT<String> executeResult = null;
try {
// to check toStop signal, we need cycle, so wo cannot use queue.take(), instand of poll(timeout)
triggerParam = triggerQueue.poll(3L, TimeUnit.SECONDS);
if (triggerParam!=null) {
running = true;
idleTimes = 0;
triggerLogIdSet.remove(triggerParam.getLogId());
// log filename, like "logPath/yyyy-MM-dd/9999.log"
// String logFileName = XxlJobFileAppender.makeLogFileName(new Date(triggerParam.getLogDateTim()), triggerParam.getLogId());
// modify 將生成的日志檔案重新命名,以jobId命名
String logFileName = XxlJobFileAppender.makeLogFileNameByJobId(new Date(triggerParam.getLogDateTim()), triggerParam.getJobId());
XxlJobFileAppender.contextHolderJobId.set(triggerParam.getJobId());
// 此處根據xxl-job版本號做修改
XxlJobFileAppender.contextHolderLogId.set(Integer.parseInt(String.valueOf(triggerParam.getLogId())));
XxlJobFileAppender.contextHolder.set(logFileName);
ShardingUtil.setShardingVo(new ShardingUtil.ShardingVO(triggerParam.getBroadcastIndex(), triggerParam.getBroadcastTotal()));
......
}
ExecutorBizImpl.java
package com.xxl.job.core.biz.impl;
import com.xxl.job.core.biz.ExecutorBiz;
import com.xxl.job.core.biz.model.LogResult;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.biz.model.TriggerParam;
import com.xxl.job.core.enums.ExecutorBlockStrategyEnum;
import com.xxl.job.core.executor.XxlJobExecutor;
import com.xxl.job.core.glue.GlueFactory;
import com.xxl.job.core.glue.GlueTypeEnum;
import com.xxl.job.core.handler.IJobHandler;
import com.xxl.job.core.handler.impl.GlueJobHandler;
import com.xxl.job.core.handler.impl.ScriptJobHandler;
import com.xxl.job.core.log.XxlJobFileAppender;
import com.xxl.job.core.thread.JobThread;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Date;
/**
* Created by xuxueli on 17/3/1.
*/
public class ExecutorBizImpl implements ExecutorBiz {
private static Logger logger = LoggerFactory.getLogger(ExecutorBizImpl.class);
/**
* 重寫讀取日志方法
* @param logDateTim
* @param logId
* @param fromLineNum
* @return
*/
@Override
public ReturnT<LogResult> log(long logDateTim, long logId, int fromLineNum) {
// log filename: logPath/yyyy-MM-dd/9999.log
String logFileName = XxlJobFileAppender.makeFileNameForReadLog(new Date(logDateTim), (int)logId);
LogResult logResult = XxlJobFileAppender.readLogByIndex(logFileName, Integer.parseInt(String.valueOf(logId)), fromLineNum);
return new ReturnT<LogResult>(logResult);
}
}
LRUCacheUtil.java
? 通過LinkedHashMap實作一個快取容器
package com.xxl.job.core.util;
import java.util.LinkedHashMap;
import java.util.Map;
/**
* @Author: liangxuanhao
* @Description: 使用LinkedHashMap實作一個固定大小的快取器
* @Date:
*/
public class LRUCacheUtil<K, V> extends LinkedHashMap<K, V> {
// 最大快取容量
private static final int CACHE_MAX_SIZE = 100;
private int limit;
public LRUCacheUtil() {
this(CACHE_MAX_SIZE);
}
public LRUCacheUtil(int cacheSize) {
// true表示更新到末尾
super(cacheSize, 0.75f, true);
this.limit = cacheSize;
}
/**
* 加鎖同步,防止多執行緒時出現多執行緒安全問題
*/
public synchronized V save(K key, V val) {
return put(key, val);
}
public V getOne(K key) {
return get(key);
}
public boolean exists(K key) {
return containsKey(key);
}
/**
* 判斷是否超限
* @param elsest
* @return 超限回傳true,否則回傳false
*/
@Override
protected boolean removeEldestEntry(Map.Entry elsest) {
// 在put或者putAll方法后呼叫,超出容量限制,按照LRU最近最少未使用進行洗掉
return size() > limit;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
for (Map.Entry<K, V> entry : entrySet()) {
sb.append(String.format("%s:%s ", entry.getKey(), entry.getValue()));
}
return sb.toString();
}
}
結果
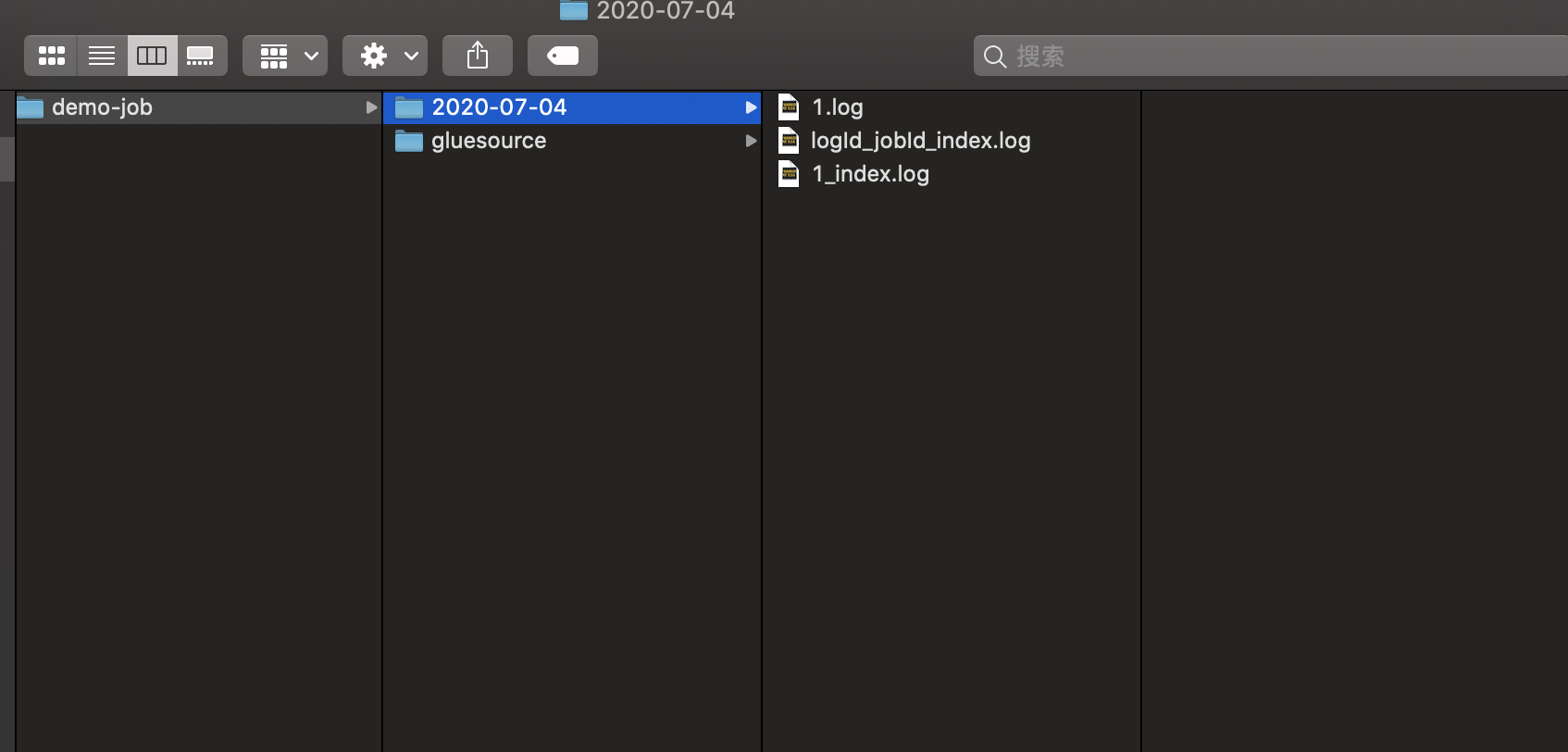
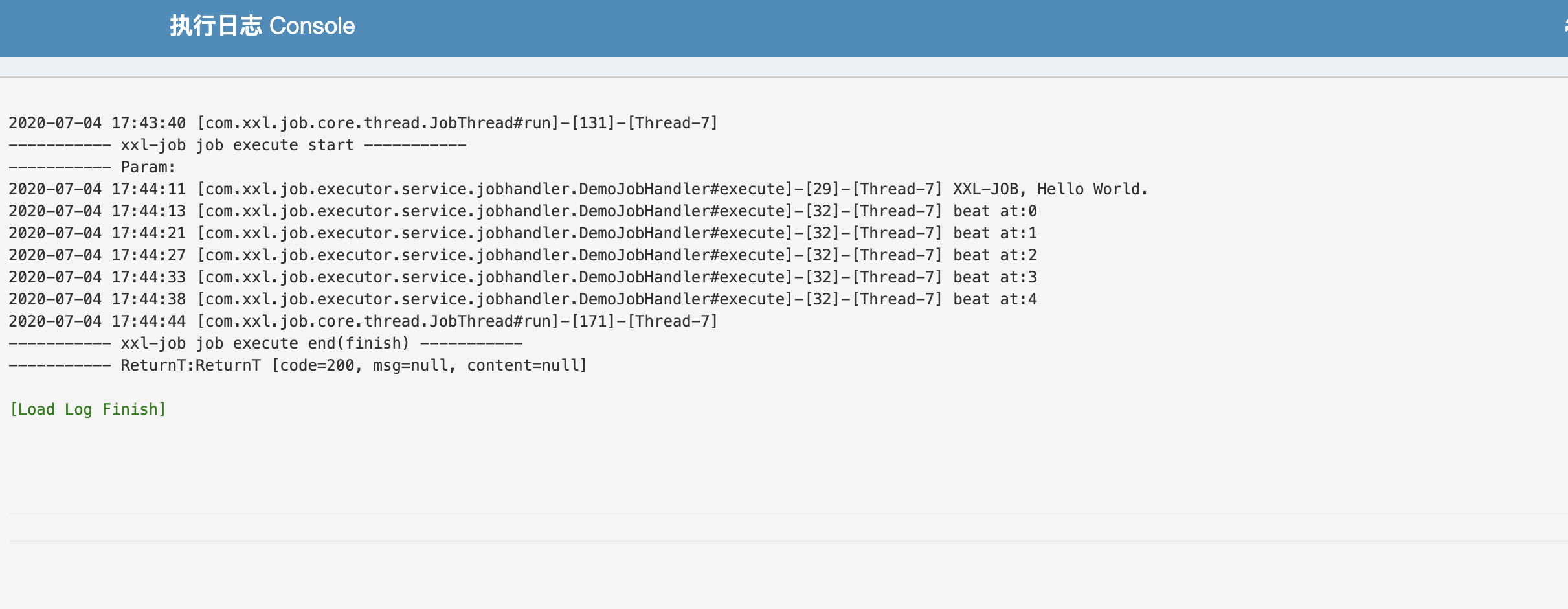
? 執行效果如圖所示:達到預期期望,且效果良好,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/256625.html
標籤:其他