paddle深度學習高層API第一天
- 傳說中的第四次“工業革命”
- 神經網路
- 深度學習萬能開發公示
- 聞說雙飛槳,翩然下廣津
- 手寫數字識別實戰
- 代碼決議
- 資料處理
- 資料查看
- 網路模型構造
- 模型網路結構可視化
- 模型配置及訓練
- 模型評估
- 模型預測
- 保存模型
- 繼續調優訓練
- 保存預測模型
- 整理
- 總結
大家好,這里是三歲,別的不會,擅長白話,今天就是我們的白話系列,內容是paddle2.0新出的高程API,在這里的七日打卡營0基礎學習,emmm我這個負基礎的也來湊湊熱鬧,那么就開始吧~~~~
注:以下白話內容為個人理解,如有不同看法和觀點及不對的地方歡迎大家批評指正!
傳說中的第四次“工業革命”
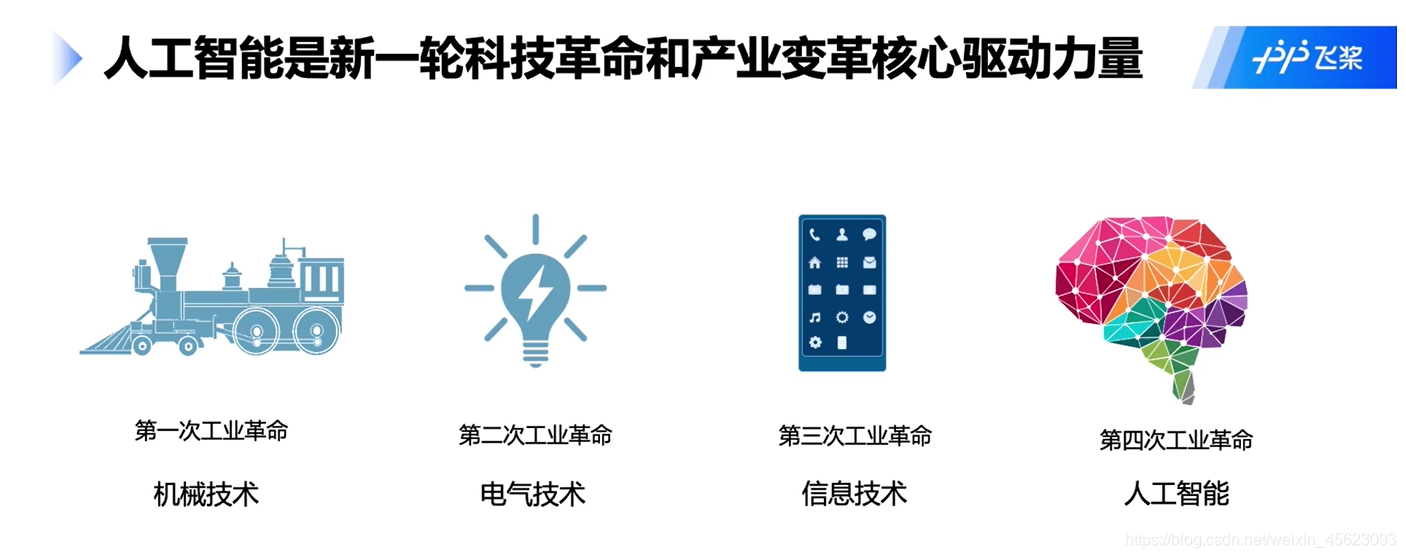
【白話時間】人工智能縮寫AI,大家已經見過很多的人工智能產品,而且越來越多的產品在不斷的涌現,質量效果也越來越好
前幾年有一個對人工智能的愛稱“人工智障”訓練的好是人工智能訓練不好是“人工智障”,但是近年來,水平的不斷提高,在非常多方面已經超過了之前的水平,甚至有非常有意義的使用價值(部分方面超過人 )
那么人工智能下面有哪些分支和我們要學的深度學習又有說沒關系嗯?

人工智能>機器學習>深度學習
人工智能大家都知道那么什么是機器學習???
回顧人類的歷史長河,我們是怎么樣一步一步的創新,發展的?
在生物中這個叫做變異,當然有正確的有錯誤的,所以就有了現在大家說知曉的適者生存,不適者淘汰的理論
那么機器可不可以通過不斷的嘗試試錯得到一個比較好的理論呢???
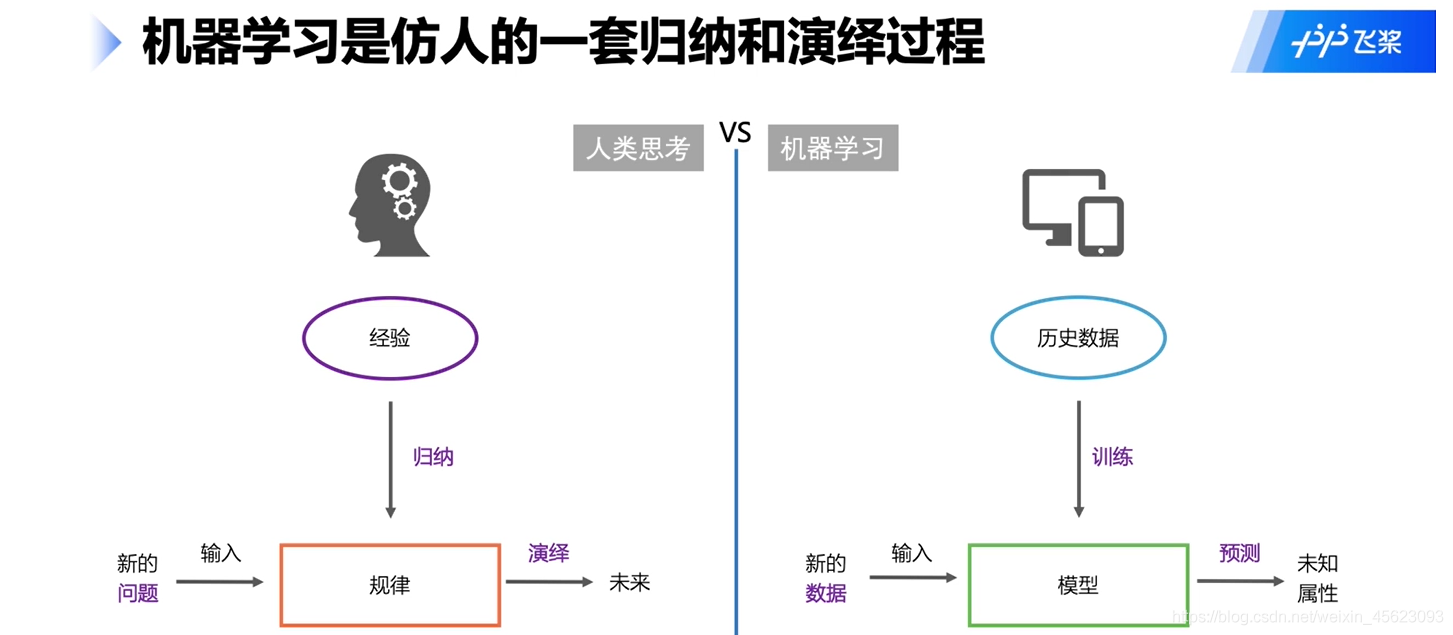
看到這個圖就知道了,其實 是一樣的,規律就是大家不斷探索以后得到的一個結果,也就是一個試錯的程序,通過我們構建的一個規則然后機器通過算力不斷的探索,最后得到一個比較好的結果,這個結果就是傳說中的“規律”,
機器學習就是通過一個“函式”(模型)來判斷輸出你想要的比較合適的一個結果
深度學習就是通過一些神經網路等方法,提取我們的一些特征進行處理,
計算機識別的都是二進制內容不好理解
我們舉一個栗子大家就明白了,如果說水果是臭的帶刺的你們會想到什么水果,那基本上就是榴蓮,通過幾個特殊的特征進行提取,
神經網路
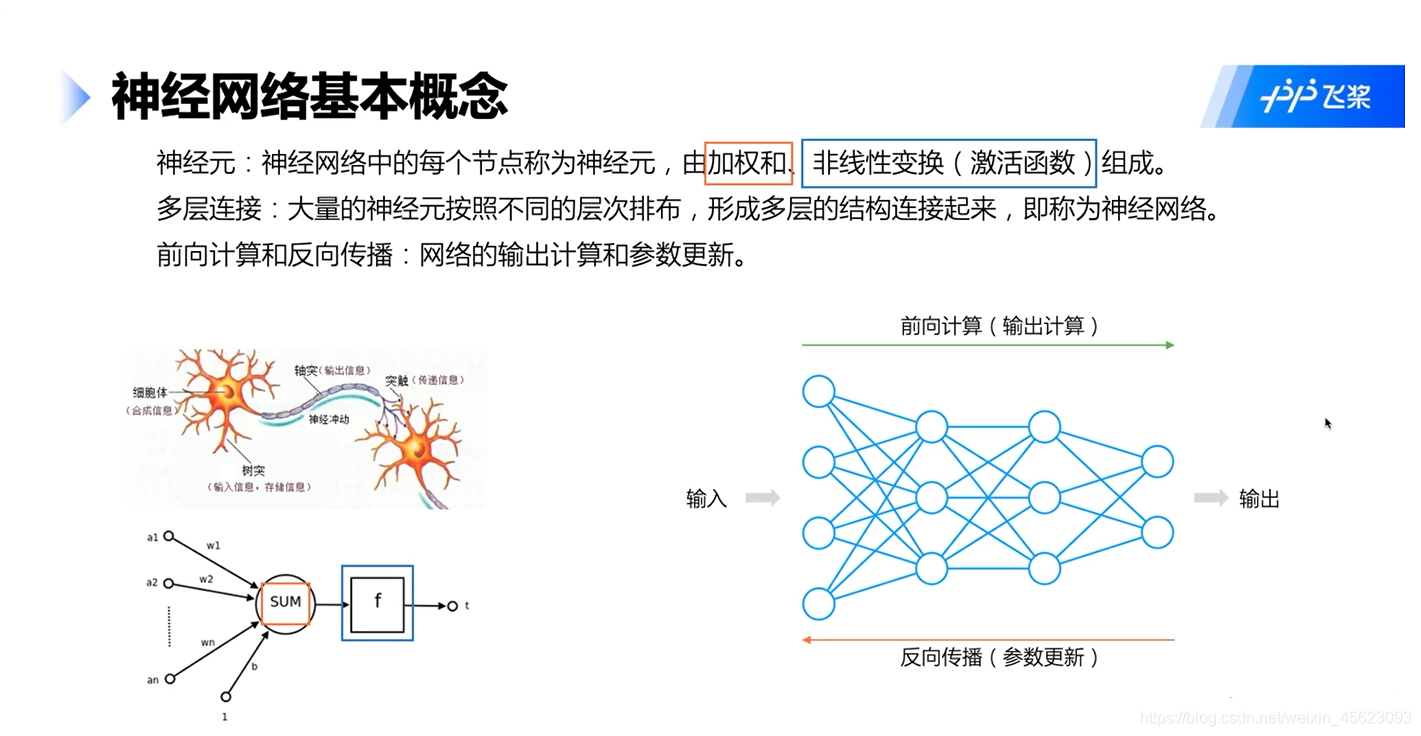
神經元:和我們的神經元類似,但是他更類似于數學函式里面的斜率之類的一些重要引數,(有加權和、激活函式等構成)
多層神經網路:相對應人類的神經傳導,輸入相對應接受電信號并傳輸到大腦皮層的一個程序,前向計算:相對應大腦給出一個指令然后進行運行;回傳傳播:相對應輸入資訊不斷更新后大腦發出指令完成系列任務,輸出相對應完成一件事情,
栗子:手碰到針,大腦皮層會產生痛覺然后大腦(應該是腦干)會發出收手的信號然后會一直檢測直到痛感消失,

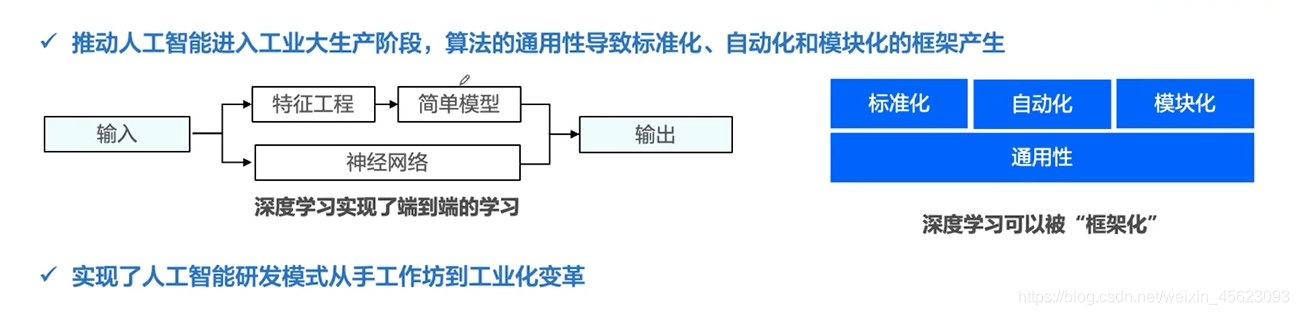
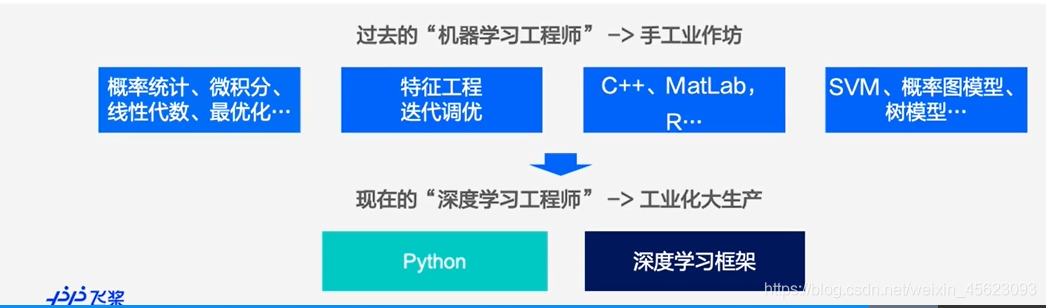
在不斷的發展程序,越來越多的內容標準化,逐步的形成了一些框架和架構,
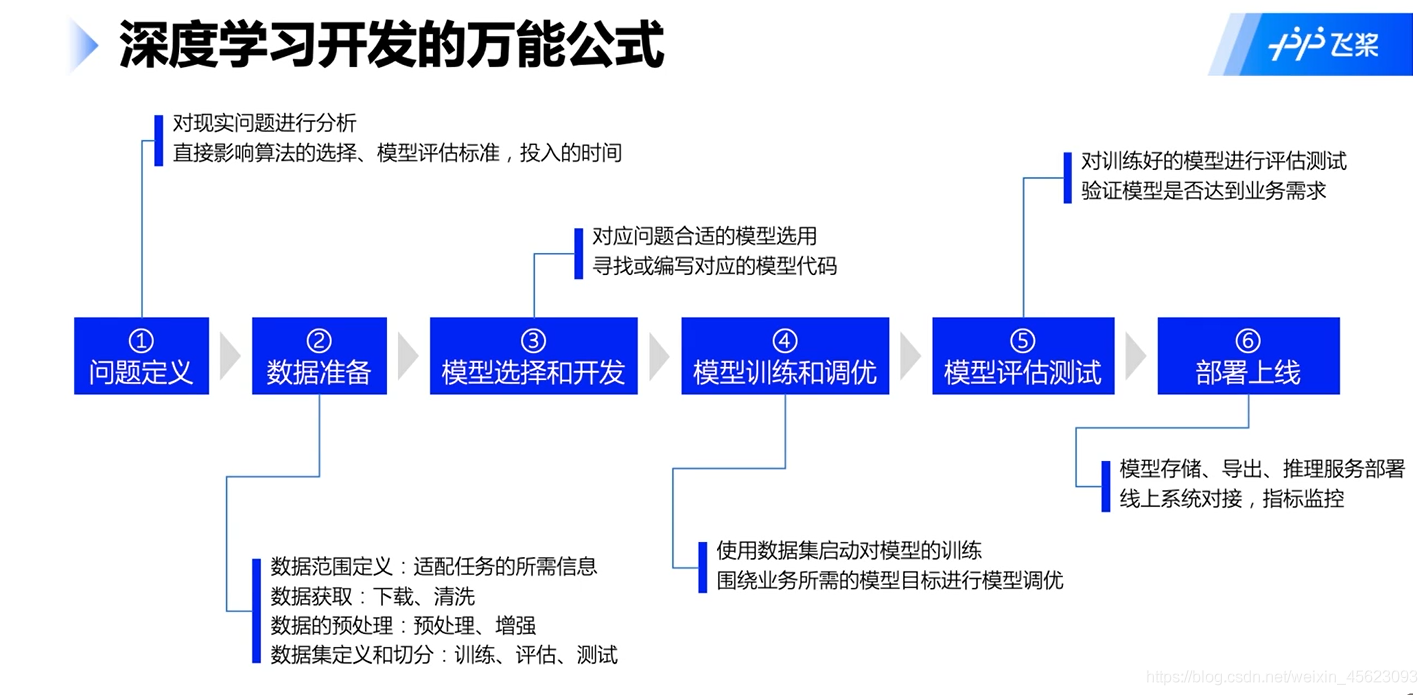
深度學習萬能開發公示
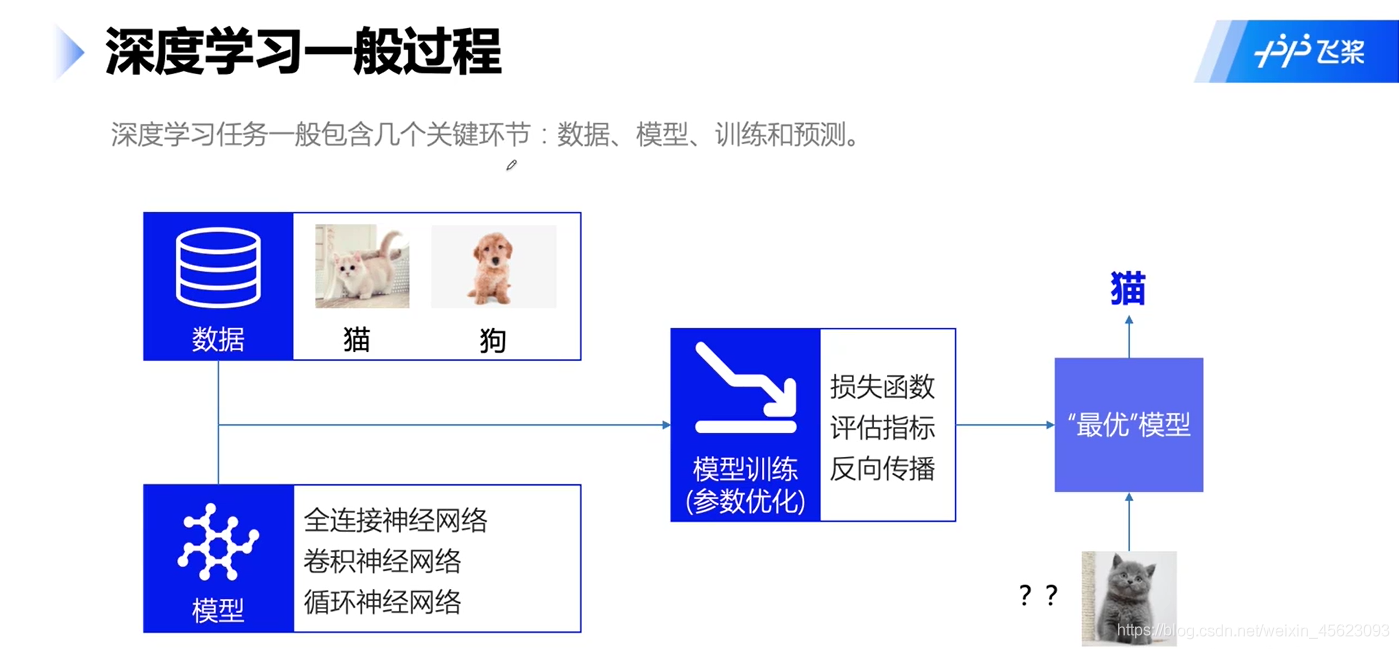
深度學習訓練就像是我們平時的考試,資料是知識,模型是我們的大腦,調優就是我們學習的方法,最后的預測相對應我們的考試,評價我們對知識的掌握情況
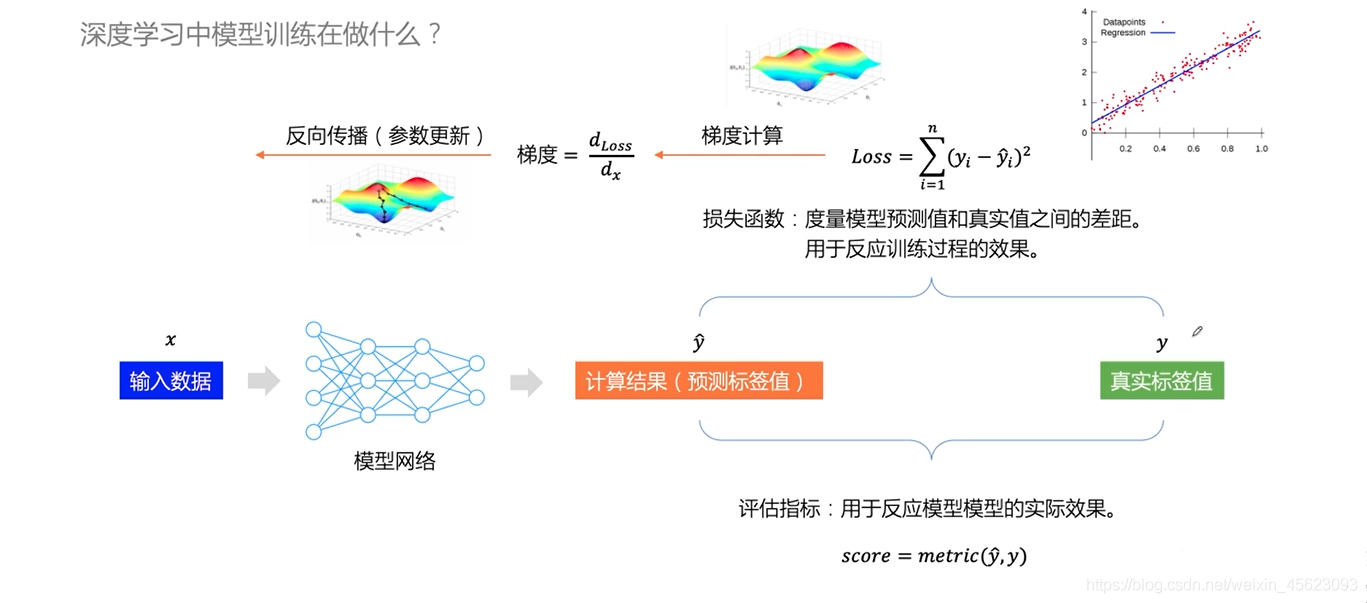
里面的
loss是用于評判模型訓練程序好壞的一個值,相對應我們平時對學習方法的一種認可與否,
score這是判斷學習成果的,相對應單元測驗卷(以上是個人認知,不對可以批評指正,相互學習)
聞說雙飛槳,翩然下廣津
-
飛槳
官網傳送門


-
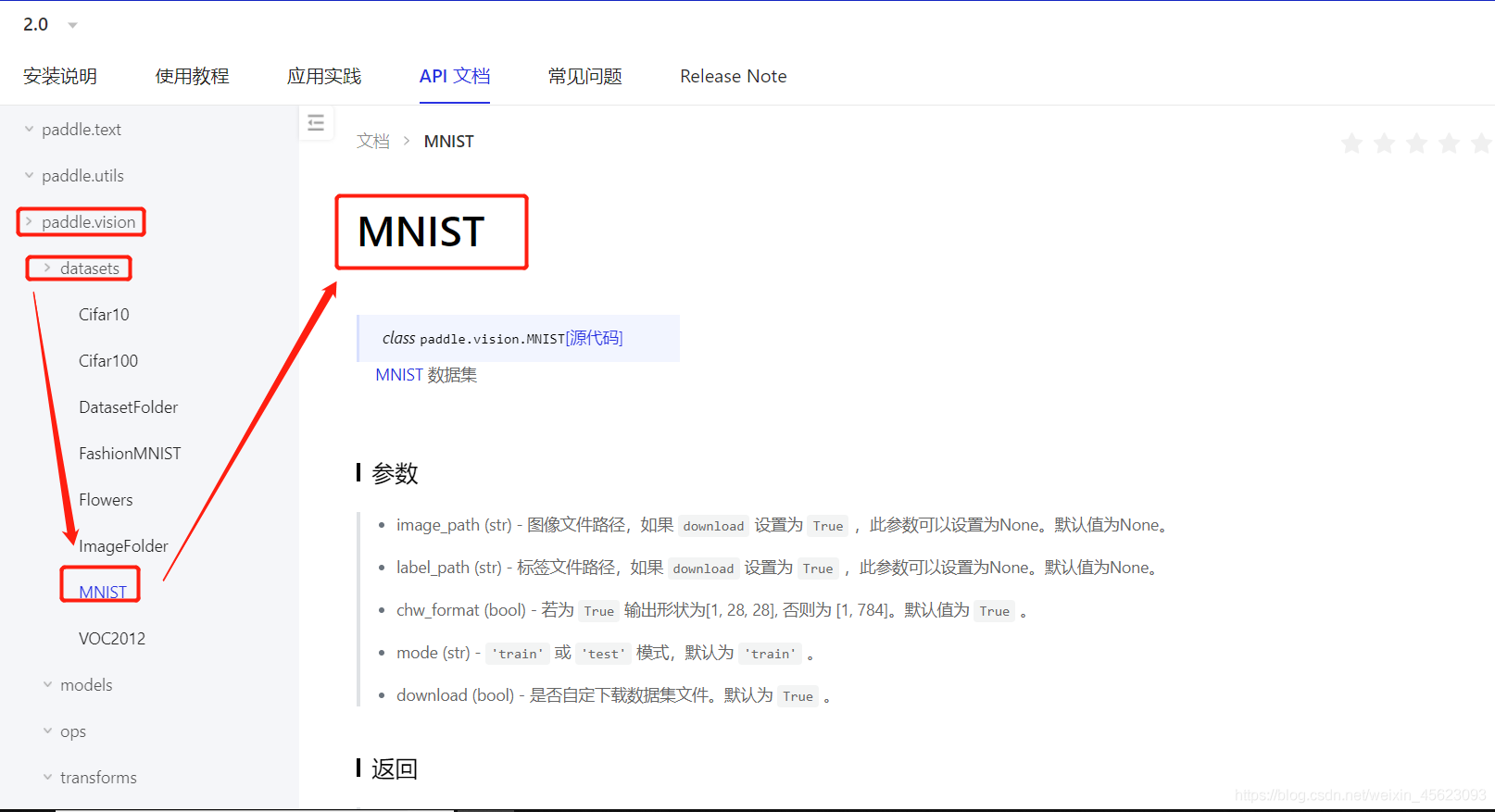
paddle的高層API
里面涵蓋了大量的基礎API和實作方法,使用方便快捷
API檔案傳送門

手寫數字識別實戰

這個內容三歲之前也做過,看了一下發現沒有那么的詳細但是還是恬不知恥把專案鏈接什么的貼出來,有興趣的小伙伴可以去看看
『深度學習7日打卡營』第1課案例:手寫數字識別(課程代碼地址)
PaddlePaddle2.0 ——手寫數字識別(三歲白話paddle專案)
[三歲白話系列]PaddlePaddle2.0——手寫數字識別(三歲白話paddle系列博客)

官網傳送門


上面的4步就是我們完成一個書寫數字識別的流程,接下來就是雨哥詳細代碼決議,有一說一,真的細節!
『深度學習7日打卡營』第1課案例:手寫數字識別(課程代碼地址)
代碼決議
資料處理
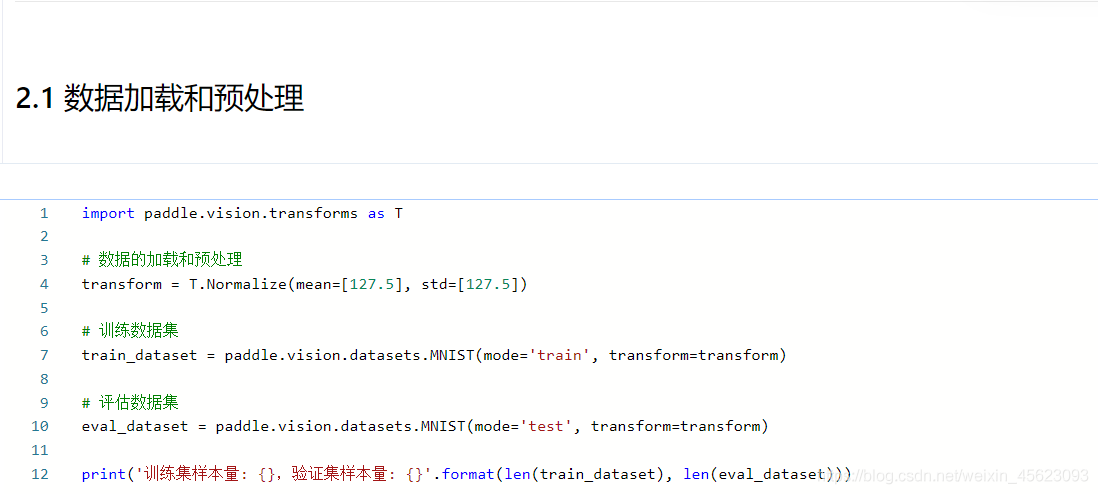
import paddle.vision.transforms as T
# 資料的加載和預處理
transform = T.Normalize(mean=[127.5], std=[127.5])
# 訓練資料集
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
# 評估資料集
eval_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
print('訓練集樣本量: {},驗證集樣本量: {}'.format(len(train_dataset), len(eval_dataset)))
這個里面涉及了兩個高層的API
讓我們一起看一下
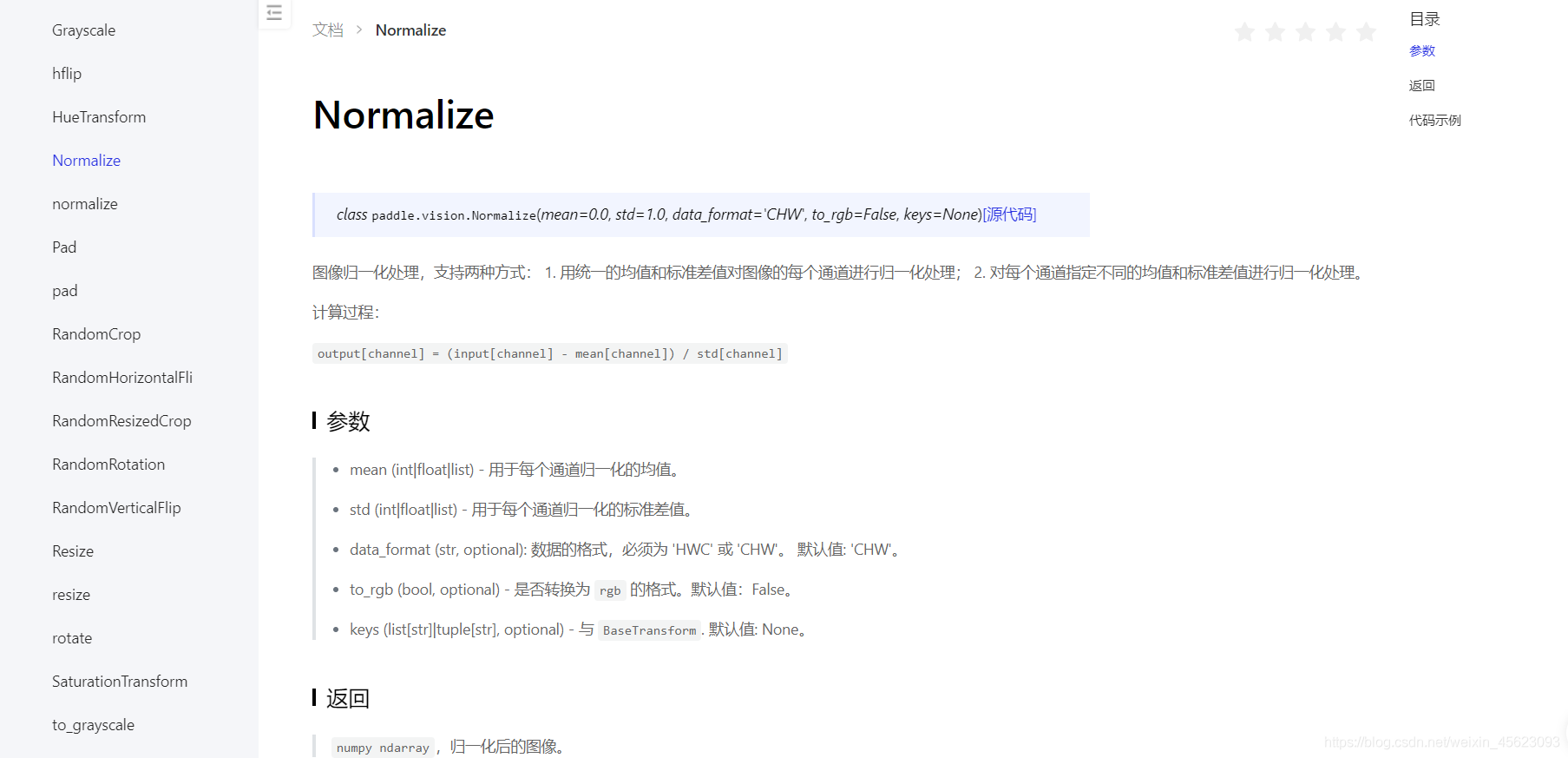
這個是paddle.vision.Normalize(mean=0.0, std=1.0, data_format='CHW', to_rgb=False, keys=None)
作用是影像歸一化處理
這個是paddle.vision.MNIST作用就是對書寫數字識別進行下載并做基本處理,
就相當于把養殖場的活物給你處理好,直接可以下鍋,
經過歸一化處理和資料集的整理得到了以下結果:
訓練集樣本量: 60000,驗證集樣本量: 10000
資料查看
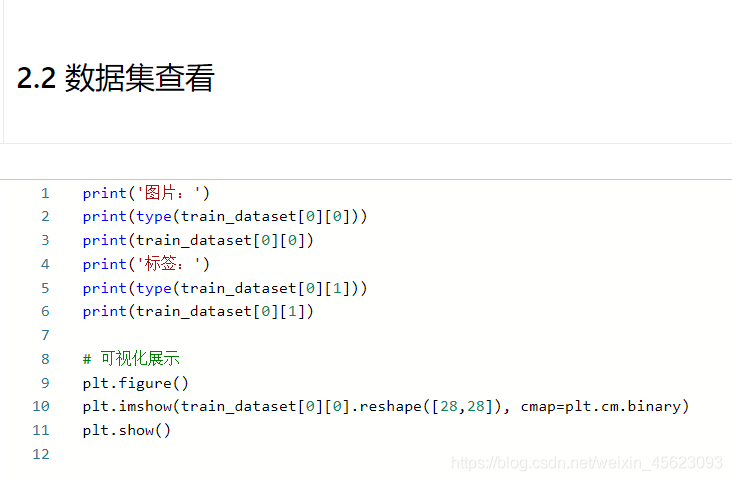
print('圖片:')
print(type(train_dataset[0][0])) # 圖片的型別
print(train_dataset[0][0]) # 輸出圖片(陣列形式)
print('標簽:')
print(type(train_dataset[0][1])) # 標簽的型別
print(train_dataset[0][1]) # 標簽的值
# 可視化展示
plt.figure()
plt.imshow(train_dataset[0][0].reshape([28,28]), cmap=plt.cm.binary)
plt.show()
仔細觀察就會發現這里面都非常容易理解,但是這個train_dataset[0][0]我們怎么自己得到?
print(train_dataset)
# 結果是生成器
# <paddle.vision.datasets.mnist.MNIST object at 0x7f95f4666ad0>
print(train_dataset[0])
# 得到的是陣列
train_dataset就是由60000個陣列組成的生成器
網路模型構造
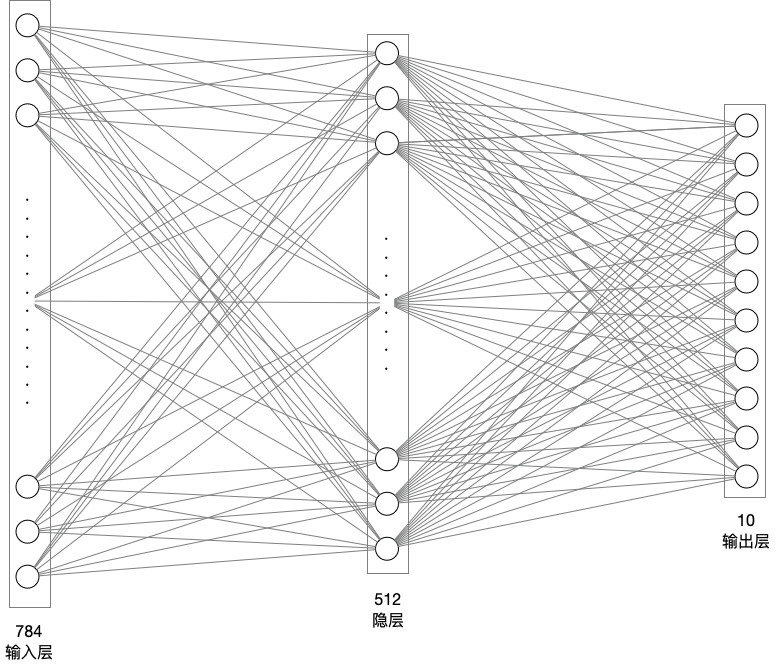
接下去就到神經網路了
輸入層是784那么這個值是怎么來的???

原始資料是28*28的大小,拉平成一維以后就是784
# 模型網路結構搭建
network = paddle.nn.Sequential(
paddle.nn.Flatten(), # 拉平,將 (28, 28) => (784)
paddle.nn.Linear(784, 512), # 隱層:線性變換層
paddle.nn.ReLU(), # 激活函式
paddle.nn.Linear(512, 10) # 輸出層
)
paddle.nn.Sequential(*layers):順序容器,子Layer將按建構式引數的順序添加到此容器中,傳遞給建構式的引數可以Layers或可迭代的name Layer元組,
paddle.nn.Flatten(start_axis=1, stop_axis=- 1):它實作將一個連續維度的Tensor展平成一維Tensor
paddle.nn.Linear(in_features, out_features, weight_attr=None, bias_attr=None, name=None):線性變換層(建議自己去API檔案理解)
paddle.nn.ReLU(name=None):ReLU激活層
paddle.nn.Linear(in_features, out_features, weight_attr=None, bias_attr=None, name=None):線性變換層-輸出 (建議自己去API檔案理解)
在這里面:輸入是784已經固定,以為輸入的一維陣列是784,輸出層的10已經固定,0-9為10個數值,需要進行判定
中間的只要輸入的線性變換層的第二個值和輸出的線性變換層第一個值一樣就行
模型網路結構可視化
# 模型封裝
model = paddle.Model(network)
# 模型可視化
model.summary((1, 28, 28))
通過對模型的封裝然后展示可以獲得每一次網路的啥情況進行一個查看和檢測
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Flatten-1 [[1, 28, 28]] [1, 784] 0
Linear-1 [[1, 784]] [1, 512] 401,920
ReLU-1 [[1, 512]] [1, 512] 0
Linear-2 [[1, 512]] [1, 10] 5,130
===========================================================================
Total params: 407,050
Trainable params: 407,050
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.01
Params size (MB): 1.55
Estimated Total Size (MB): 1.57
---------------------------------------------------------------------------
{'total_params': 407050, 'trainable_params': 407050}
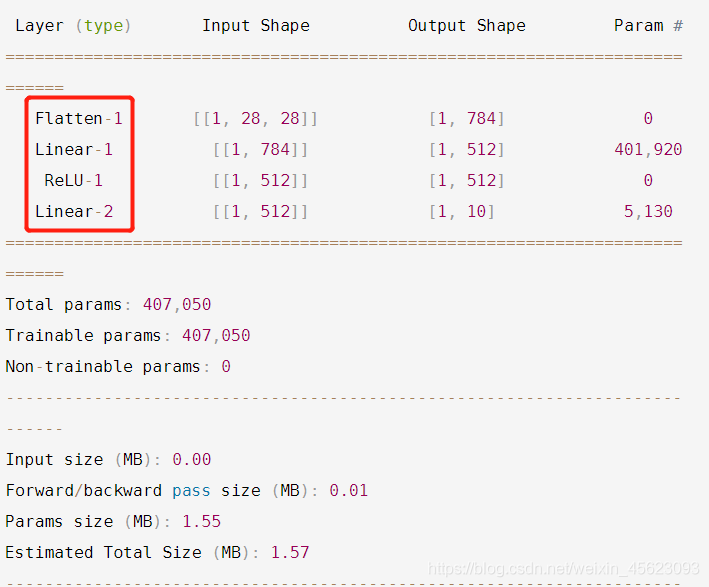
這樣子可以查看每一層的情況,包括學習的程度什么的
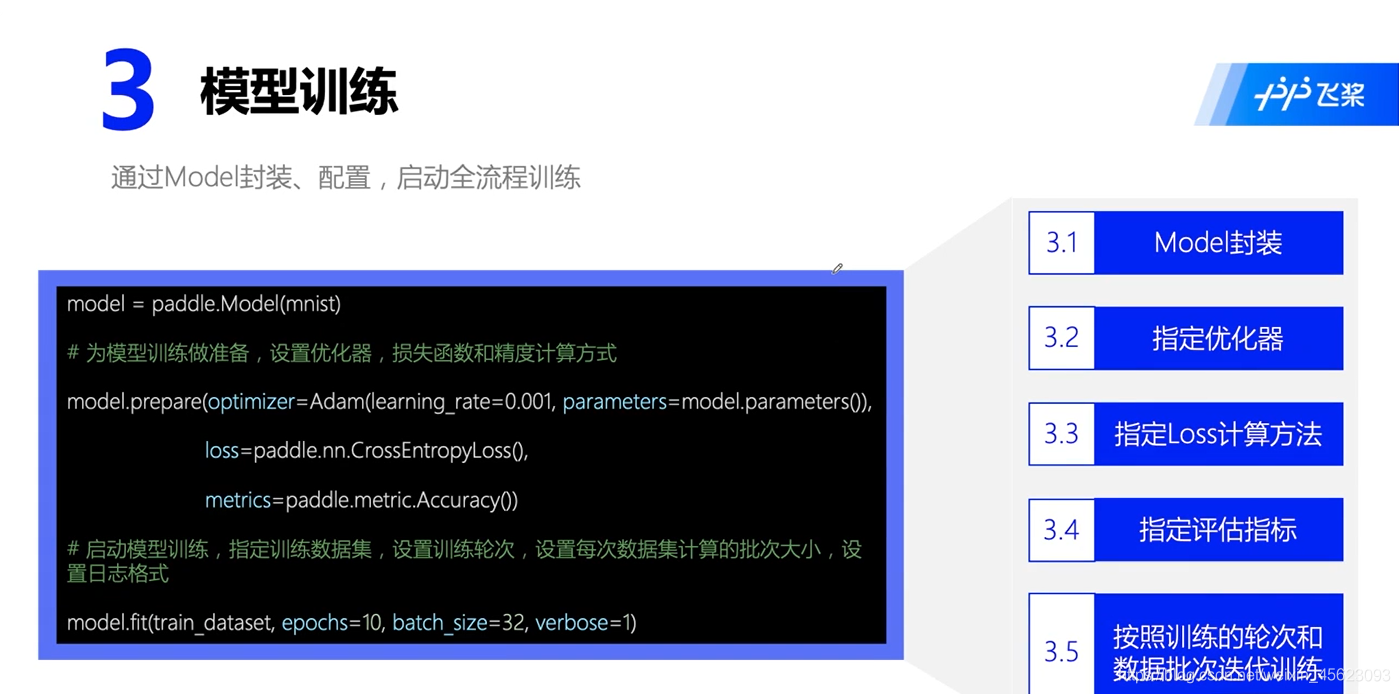
模型配置及訓練
# 配置優化器、損失函式、評估指標
model.prepare(
paddle.optimizer.Adam(learning_rate=0.001,
parameters=network.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# 啟動模型全流程訓練
model.fit(train_dataset, # 訓練資料集
eval_dataset, # 評估資料集
epochs=5, # 訓練的總輪次
batch_size=64, # 訓練使用的批大小
verbose=1) # 日志展示形式
paddle.Modle.prepare(optimizer=None, loss_function=None, metrics=None):用于配置模型所需的部件,比如優化器、損失函式和評價指標,
paddle.optimizer.Adam:Adam優化器,能夠利用梯度的一階矩估計和二階矩估計動態調整每個引數的學習率,
paddle.nn.CrossEntropyLoss:該OP計算輸入input和標簽label間的交叉熵損失 ,它結合了 LogSoftmax 和 NLLLoss 的OP計算,可用于訓練一個 n 類分類器,分類器
paddle.metric.Accuracy:計算準確率(accuracy)
paddle.Modle.fit:訓練模型
模型評估
# 模型評估,根據prepare介面配置的loss和metric進行回傳
result = model.evaluate(eval_dataset, verbose=1)
print(result)
paddle.Model.evaluate:在輸入資料上,評估模型的損失函式值和評估指標,
模型預測
- 批量預測
使用model.predict介面來完成對大量資料集的批量預測,
# 進行預測操作
result = model.predict(eval_dataset)
# 定義畫圖方法
def show_img(img, predict):
plt.figure()
plt.title('predict: {}'.format(predict))
plt.imshow(img.reshape([28, 28]), cmap=plt.cm.binary)
plt.show()
# 抽樣展示
indexs = [2, 15, 38, 211]
for idx in indexs:
show_img(eval_dataset[idx][0], np.argmax(result[0][idx]))
paddle.Modle.predict:在輸入資料上,預測模型的輸出,
通過函式把模型預測結束后,抽取個別資料集進行處理并預測
- 單張預測
# 讀取單張圖片
image = eval_dataset[501][0]
# 單張圖片預測
result = model.predict_batch([image])
# 可視化結果
show_img(image, np.argmax(result))
paddle.Model.predict_batch:在一個批次的資料上進行測驗
保存模型
# 保存用于后續繼續調優訓練的模型
model.save('finetuning/mnist')
paddle.Model.save:將模型的引數和訓練程序中優化器的資訊保存到指定的路徑,以及推理所需的引數與檔案
繼續調優訓練
from paddle.static import InputSpec
# 模型封裝,為了后面保存預測模型,這里傳入了inputs引數
model_2 = paddle.Model(network, inputs=[InputSpec(shape=[-1, 28, 28], dtype='float32', name='image')])
# 加載之前保存的階段訓練模型
model_2.load('finetuning/mnist')
# 模型配置
model_2.prepare(paddle.optimizer.Adam(learning_rate=0.001, parameters=network.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# 模型全流程訓練
model_2.fit(train_dataset,
eval_dataset,
epochs=2,
batch_size=64,
verbose=1)
這里就相當于把之前的幾個大的流程再走一遍:封裝模型,然后讀取之前的模型,模型配置,訓練配置然后就可以運行了
保存預測模型
# 保存用于后續推理部署的模型
model_2.save('infer/mnist', training=False)
再次保存,
training=False不再保存其他的訓練引數,只保留模型
整理
第一天的課程終于整理結束了,我們也來回顧一下,首先就是對人工智能、機器學習、深度學習進行的一定的解釋和梳理,使得有一定的理解,知道什么是AI,
然后對深度學習的流程進行了梳理得到了—深度學習萬能開發公式
引出了我們的boos——paddlepaddle
對書寫數字識別進行了詳細的決議,真·詳細
把整個專案掰開,一點一點的進行了分析和梳理
總結
雖然今天是課程的第一天,難度絕對不低,但是識訓真的多,花了整整5小時的時間進行了梳理,對整個深度學習的流程有了更加豐富的理解,有一種馬上就要恍然大悟但是又有點迷茫的那種狀態,
接下的課程更精彩,期待
這里是三歲,飛槳社區最菜的小白
我在AI Studio上獲得黃金等級,點亮7個徽章,來互關呀~
CSDN首頁
如果喜歡記得關注呦!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/256738.html
標籤:AI
上一篇:中國五城市六年PM2.5資料挖掘
下一篇:科目三步驟