聊聊Mysql索引和redis跳表 ---redis的有序集合zset資料結構底層采用了跳表原理 時間復雜度O(logn)(阿里)
redis使用跳表不用B+數的原因是:redis是記憶體資料庫,而B+樹純粹是為了mysql這種IO資料庫準備的,B+樹的每個節點的數量都是一個mysql磁區頁的大小(阿里面試)
敲黑板:
每級遍歷 3 個結點即可,而跳表的高度為 h ,所以每次查找一個結點時,需要遍歷的結點數為 3*跳表高度 ,所以忽略低階項和系數后的時間復雜度就是 ○(㏒n),空間復雜度是O(n)
問題
如果對以下問題感到困惑或一知半解,請繼續看下去,相信本文一定會對你有幫助
-
mysql 索引如何實作
-
mysql 索引結構B+樹與hash有何區別,分別適用于什么場景
-
資料庫的索引還能有其他實作嗎
-
redis跳表是如何實作的
-
跳表和B+樹,LSM樹有何區別呢
決議
首先為什么要把mysql索引和redis跳表放在一起討論呢,因為他們解決的都是同一種問題,用于解決資料集合的查找問題,即根據指定的key,快速查到它所在的位置(或者對應的value)
當你站在這個角度去思考問題時,還會不知道B+樹索引和hash索引的區別嗎
資料集合的查找問題
現在我們將問題領域邊界劃分清楚了,就是為了解決資料集合的查找問題,這一塊需要考慮哪些問題呢
-
需要支持哪些查找方式,單key/多key/范圍查找,
-
插入/洗掉效率
-
查找效率(即時間復雜度)
-
存盤大小(空間復雜度)
我們看下幾種常用的查找結構
hash
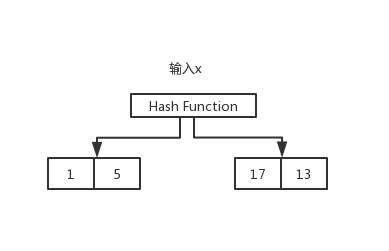
hash是key,value形式,通過一個散列函式,能夠根據key快速找到value
B+ 樹:
注意 這是關于B+樹的總結,如果你掌握到這個程度 是遠遠不夠的,
B+樹 的資料都在葉子節點,非葉子節點存放 索引
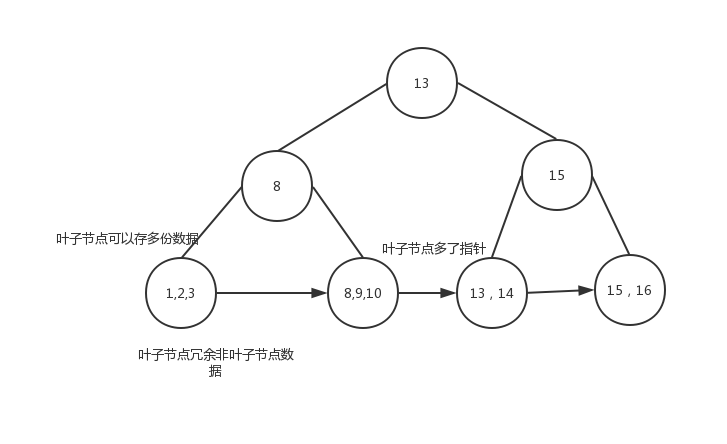
B+樹是在平衡二叉樹基礎上演變過來,為什么我們在演算法課上沒學到B+樹和跳表這種結構呢,因為他們都是從工程實踐中得到,在理論的基礎上進行了妥協,
B+樹首先是有序結構,為了不至于樹的高度太高,影響查找效率,在葉子節點上存盤的不是單個資料,而是一頁資料,提高了查找效率,而為了更好的支持范圍查詢,B+樹在葉子節點冗余了非葉子節點資料,為了支持翻頁,葉子節點之間通過指標連接,
跳表
redis跳表視頻講解點擊鏈接:redis跳表
C/C++Linux服務器開發精彩內容包括:C/C++,Linux,Nginx,ZeroMQ,MySQL,Redis,MongoDB,ZK,流媒體,P2P,Linux內核,Docker,TCP/IP,協程,DPDK多個高級知識點
學習視頻資料點擊:C/C++Linux服務器開發/Linux后臺架構師-學習視頻
C/C++Linux后臺服務器開發技術交流:技術qun
跳表:為什么 Redis 一定要用跳表來實作有序集合?
上幾篇主要是學習二分查找演算法,但是二分查找底層依賴的是陣列隨機訪問的特性,所以只能用陣列來實作,如果資料存盤在鏈表中,就沒辦法使用二分查找了嗎?
此時跳表出現了,跳表(Skip list) 實際上就是在鏈表的基礎上改造生成的,
跳表是一種各方面性能都比較優秀的 動態資料結構,可以支持快速的插入、洗掉、查找操作,寫起來也不復雜,甚至可以替代 紅黑樹??,
Redis 一共有5種資料結構,包括:
1、字串(String) redis對于KV的操作效率很高,可以直接用作計數器,例如,統計在線人數等等,另外string型別是二進制存盤安全的,所以也可以使用它來存盤圖片,甚至是視頻等,
2、哈希(hash) 存放鍵值對,一般可以用來存某個物件的基本屬性資訊,例如,用戶資訊,商品資訊等,另外,由于hash的大小在小于配置的大小的時候使用的是ziplist結構,比較節約記憶體,所以針對大量的資料存盤可以考慮使用hash來分段存盤來達到壓縮資料量,節約記憶體的目的,例如,對于大批量的商品對應的圖片地址名稱,比如:商品編碼固定是10位,可以選取前7位作為hash的key,后三位作為field,圖片地址作為value,這樣每個hash表都不超過999個,只要把redis.conf中的hash-max-ziplist-entries改為1024,即可, 3、串列(List) 串列型別,可以用于實作訊息佇列,也可以使用它提供的range命令,做分頁查詢功能,
4、集合(Set) 集合,整數的有序串列可以直接使用set,可以用作某些去重功能,例如用戶名不能重復等,另外,還可以對集合進行交集,并集操作,來查找某些元素的共同點
5、有序集合(zset) 有序集合,可以使用范圍查找,排行榜功能或者topN功能,
其中第五個zset 有序集合 就是用跳表來實作的,那 Redis 為什么會選擇用跳表來實作有序集合呢?
一、如何理解跳表?
對于單鏈表來說,我們查找某個資料,只能從頭到尾遍歷鏈表,此時時間復雜度是 ○(n),
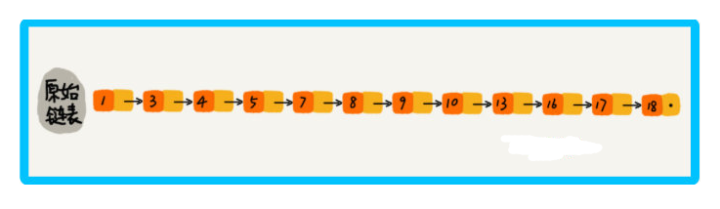
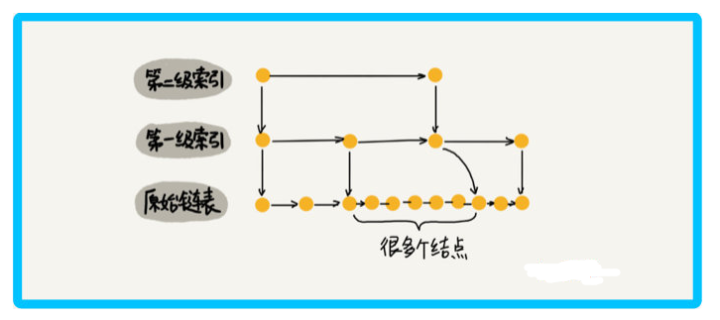
那么怎么提高單鏈表的查找效率呢?看下圖,對鏈表建立一級 索引,每兩個節點提取一個結點到上一級,被抽出來的這級叫做 索引 或 索引層,
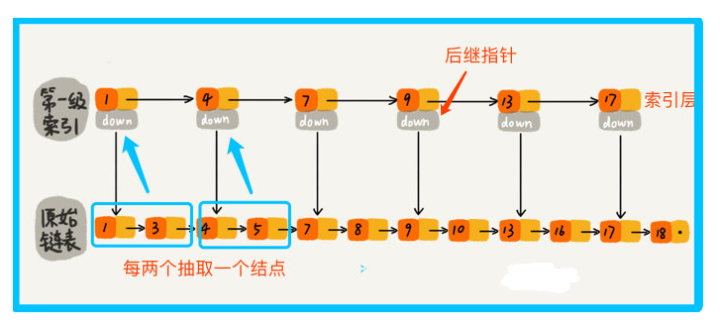
開發中經常會用到一種處理方式,hashmap 中存盤的值型別是一個 list,這里就可以把索引當做 hashmap 中的鍵,將每 2 個結點看成每個鍵對應的值 list,
所以要找到13,就不需要將16前的結點全遍歷一遍,只需要遍歷索引,找到13,然后發現下一個結點是17,那么16一定是在 [13,17] 之間的,此時在13位置下降到原始鏈表層,找到16,加上一層索引后,查找一個結點需要遍歷的結點個數減少了,也就是說查找效率提高了
那么我們再加一級索引呢? 跟前面建立一級索引的方式相似,我們在第一級索引的基礎上,每兩個結點就抽出一個結點到第二級索引,此時再查找16,只需要遍歷 6 個結點了,需要遍歷的結點數量又減少了,
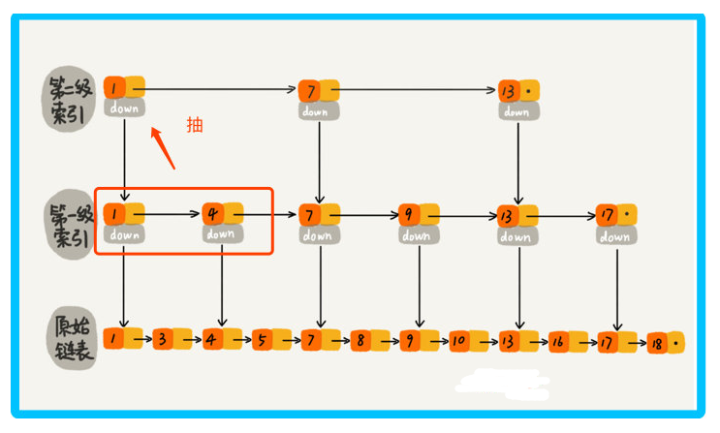
當結點數量多的時候,這種添加索引的方式,會使查詢效率提高的非常明顯
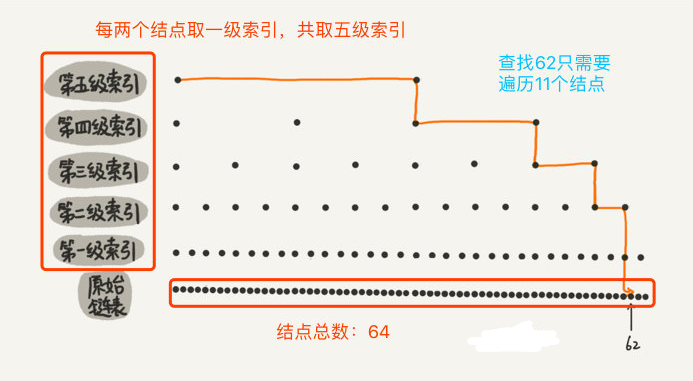
二、用跳表查詢到底有多快
在一個單鏈表中,查詢某個資料的時間復雜度是 ○(n),那在一個具有多級索引的跳表中,查詢某個資料的時間復雜度是多少呢?
按照上面的示例,每兩個節點就抽出一個一級索引,每兩個一級索引又抽出一個二級索引,所以第一級索引的結點個數大約就是 n/2,第二級索引的結點個數就是 n/4,第 k 級索引的結點個數就是 n/2^k,
假設一共建立了 h 級索引,最高級的索引有兩個節點(如果最高級索引只有一個結點,那么這一級索引起不到判斷區間的作用,那么是沒什么意義的),所以有:

時間復雜度的分析
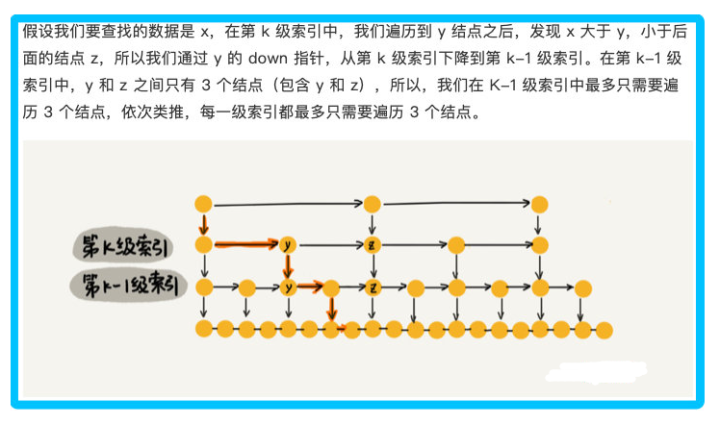
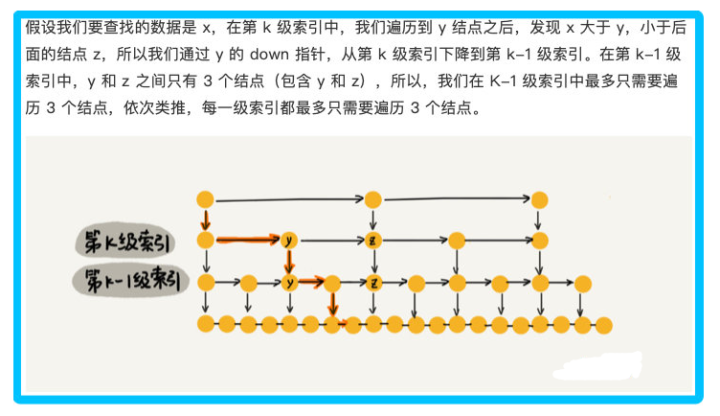
根據上圖得知,每級遍歷 3 個結點即可,而跳表的高度為 h ,所以每次查找一個結點時,需要遍歷的結點數為 3*跳表高度 ,所以忽略低階項和系數后的時間復雜度就是 ○(㏒n)
其實此時就相當于基于單鏈表實作了二分查找,但是這種查詢效率的提升,由于建立了很多級索引,會不會很浪費記憶體呢?
三、跳表是不是很浪費記憶體?
來分析一下跳表的空間復雜度, 為O(n)
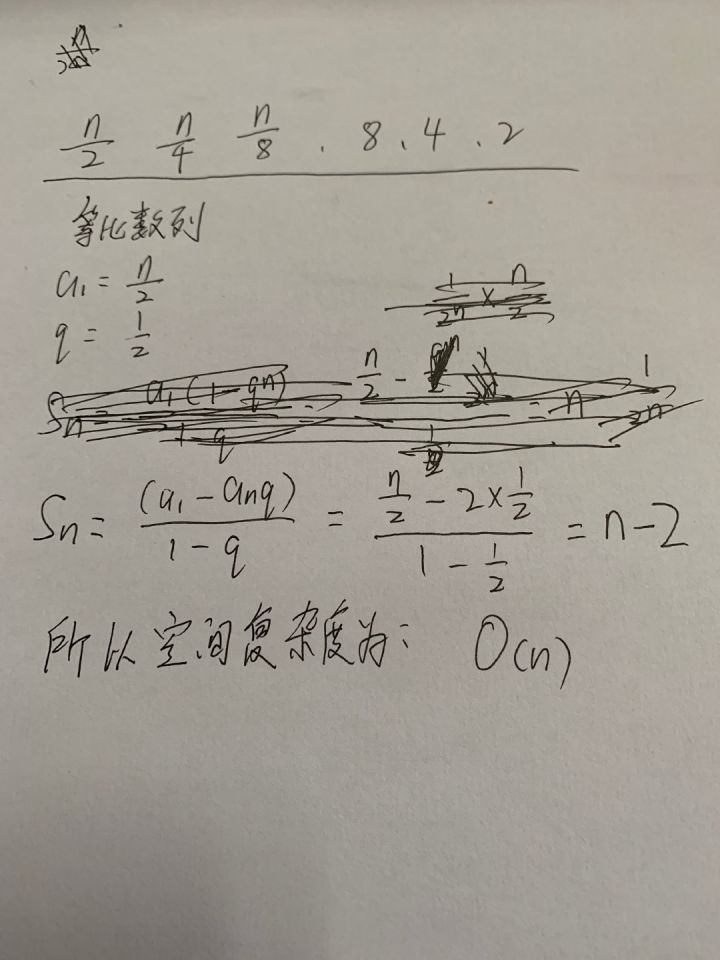
空間復雜度
所以如果將包含 n 個結點的單鏈表構造成跳表,我們需要額外再用接近 n 個結點的存盤空間,那怎么才能降低索引占用的記憶體空間呢?
前面是每兩個結點抽一個結點到上級索引,如果我們每三個,或每五個結點,抽一個結點到上級索引,是不是就不用那么多索引結點了呢?
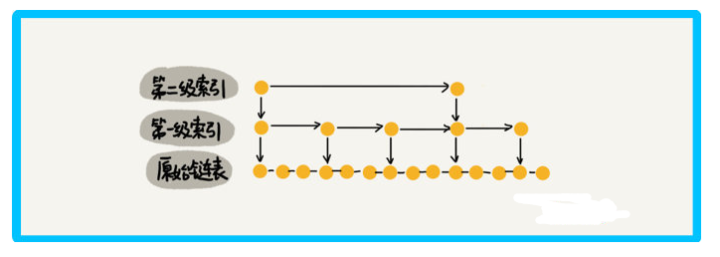
計算空間復雜度的程序與前面的一致,盡管最后空間復雜度依然是 ○(n),但我們知道,使用大○表示法忽略的低階項或系數,實際上同樣會產生影響,只不過我們為了關注高階項而將它們忽略,

空間復雜度
實際上,在實際開發中,我們不需要太在意索引占據的額外空間,在學習資料結構與演算法時,我們習慣的將待處理資料看成整數,但是實際開發中,原始鏈表中存盤的很可能是很大的物件,而索引結點只需要存盤關鍵值(用來比較的值)和幾個指標(找到下級索引的指標),并不需要存盤原始鏈表中完整的物件,所以當物件比索引結點大很多時,那索引占用的額外空間就可以忽略了,
四、高效的動態插入和洗掉
跳表這個動態資料結構,不僅支持查找操作,還支持動態的插入、洗掉操作,而且插入、洗掉操作的時間復雜度也是 ○(㏒n),
對于單純的單鏈表,需要遍歷每個結點來找到插入的位置,但是對于跳表來說,因為其查找某個結點的時間復雜度是 ○(㏒n),所以這里查找某個資料應該插入的位置,時間復雜度也是 ○(㏒n),
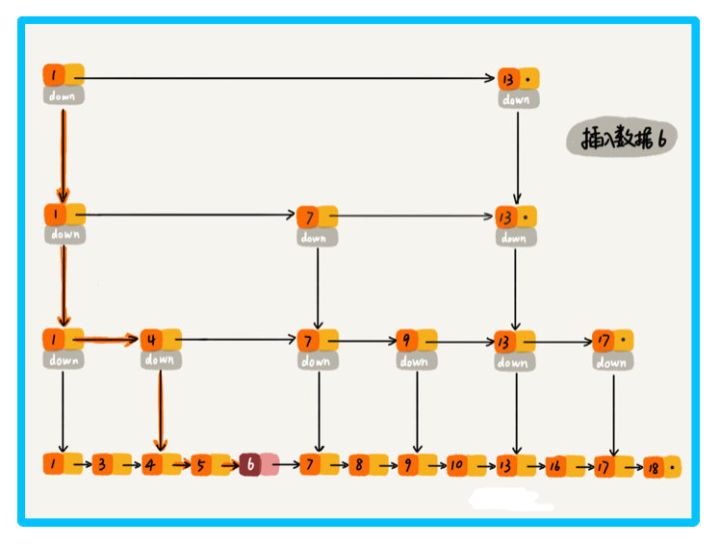
那么洗掉操作呢?

五、跳表索引動態更新
當我們不停的往跳表中插入資料時,如果我們不更新索引,就可能出現某 2 個索引結點之間資料非常多的情況,極端情況下,跳表會退化成單鏈表,
作為一種動態資料結構,我們需要某種手段來維護索引與原始鏈表大小之間的平滑,也就是說如果鏈表中結點多了,索引結點就相應地增加一些,避免復雜度退化,以及查找、插入、洗掉操作性能下降,
跳表是通過隨機函式來維護前面提到的 平衡性,
我們往跳表中插入資料的時候,可以選擇同時將這個資料插入到第幾級索引中,比如隨機函式生成了值 K,那我們就將這個結點添加到第一級到第 K 級這 K 級索引中,
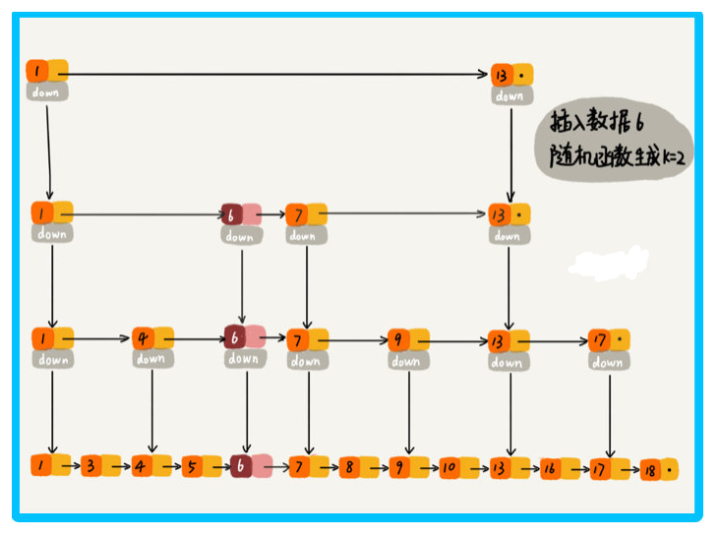
隨機函式可以保證跳表的索引大小和資料大小的平衡性,不至于性能過度退化,
跳表的實作有點復雜,并且跳表的實作并不是這篇的重點,主要是學習思路,
六、解答開篇
Redis 中的有序集合是通過跳表來實作的,嚴格點講,還用到了散串列,如果查看 Redis 開發手冊,會發現 Redis 中的有序集合支持的核心操作主要有下面這幾個:
-
插入一個資料
-
洗掉一個資料
-
查找一個資料
-
按照區間查找資料(比如查找在[100,356]之間的資料)
-
迭代輸出有序序列
其中,插入、查找、洗掉以及迭代輸出有序序列這幾個操作,紅黑樹也能完成,時間復雜度和跳表是一樣的,但是,按照區間來查找資料這個操作,紅黑樹的效率沒有跳表高,
對于按照區間查找資料這個操作,跳表可以做到 ○(㏒n) 的時間復雜度定位區間的起點,然后在原始鏈表中順序往后遍歷就可以了,這樣做非常高效,
當然,還有其他原因,比如,跳表代碼更容易實作,可讀性好不易出錯,跳表更加靈活,可以通過改變索引構建策略,有效平衡執行效率和記憶體消耗,
不過跳表也不能完全替代紅黑樹,因為紅黑樹出現的更早一些,很多編程語言中的 Map 型別都是用紅黑樹來實作的,寫業務的時候直接用就行,但是跳表沒有現成的實作,開發中想用跳表,得自己實作,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/256762.html
標籤:其他
上一篇:FPGA 折疊 近似計算實作卷積