制作思路較為通俗易懂,適合入門選手,所給出的模型及代碼均已實作,沒有空頭支票,
題目翻譯個別關鍵單詞有問題,手動修改了過來,會影響題目理解,如capture、explict等
1.題目重點重述 (熟悉題目的請跳過)
我們的目標是衡量以前制作的音樂對新音樂和藝術家的影響,
一些藝術家可以列出十幾個甚至更多的影響了他們自己的音樂作品藝術家,也有人建議,影
響可以通過歌曲特征(如結構、節奏或歌詞)之間的相似程度來衡量,音樂有時會有革命性的
變化,以提供新的聲音或節奏,例如當新的流派出現時,或者現有流派的再創造(例如古典、
流行/搖滾、爵士樂等),這可以歸因于一系列的小變化,藝術家的合作努力,一系列有影響
力的藝術家,或者社會內部的轉變,
(題目開頭給出了一些問題的提示:如衡量特征指標的相似程度(問題1、2)、考慮音樂節奏上的變化以衡量革命性的飛躍(問題5)、有影響力的藝術家及社會轉變(問題6))
許多歌曲都有相似的旋律,許多藝術家對音樂流派的重大轉變做出了貢獻,有時,這些變化
是由于一位藝術家影響了另一位藝術家,有時,它是對外部事件(如重大世界事件或技術進
步)的回應而出現的變化,通過考慮歌曲的網路和它們的音樂特征,我們可以開始捕捉到音
樂藝術家對彼此的影響,也許,我們還可以更好地理解音樂是如何隨著時間的推移在社會中
演變的,
您的團隊受綜合集體音樂協會委托來開發一種衡量音樂影響力的模型,這個問題要求你考察藝術家和流派的進化和革命趨勢,為此,ICM 向您的團隊提供了幾個資料集:
(1)“Influence_Data”代表藝人自己報道的音樂影響者和追隨者,以及行業專家的意見,這些資料包含 5854 名藝術家在過去 90 年中的影響力和追隨者,
(2)“full_music_data”提供了 16 個變數條目,包括舞蹈性、節奏、響度和音調等音樂特征,以及針對 98,340 首歌曲的 artist_name 和 artist_id,
這些資料用于創建兩個匯總資料集,包括:
(3)藝術家的平均值“data_by_artist”,
(4)根據年份的統計值“data_by_year”, (這個應該沒什么用 無視,處理問題6:“隨時間推移” 也不是用這個資料集)
2.問題回答與模型建立
Influence_Data資料集預覽:
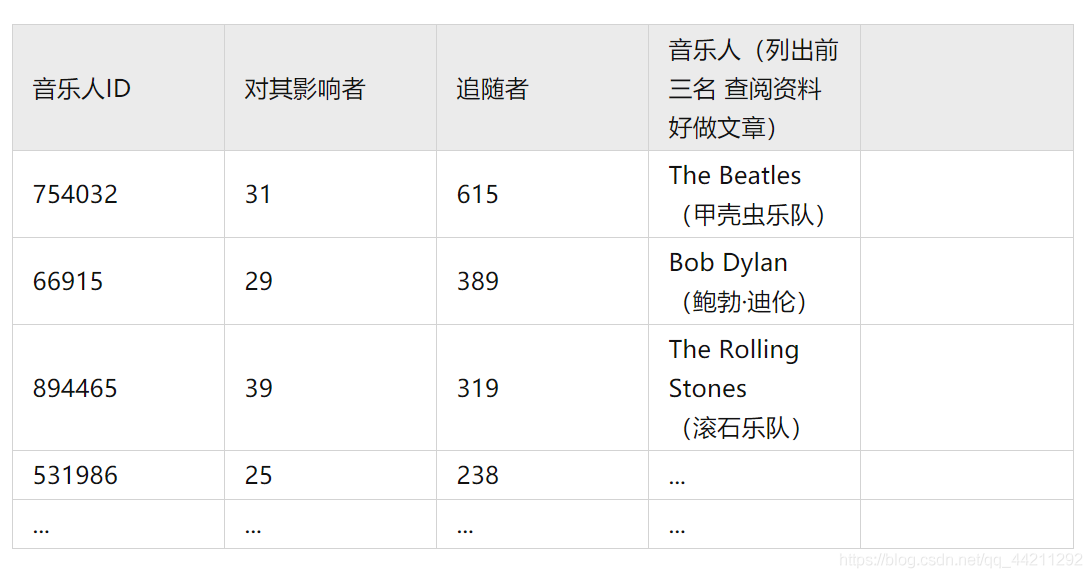
使用圖與網路模型,得到所有音樂人的影響出度(追隨者\影響的人)與入度(對其影響者)
音樂人ID 對其影響者 追隨者 音樂人(列出前三名 查閱資料 好做文章)
754032 31 615 The Beatles(甲殼蟲樂隊)
66915 29 389 Bob Dylan
(鮑勃·迪倫)
894465 39 319 The Rolling Stones
(滾石樂隊)
531986 25 238 …
… … … …
當你得到了如上表,并且在圖與網路模型中得到了網路關系圖,你就可以大做文章了,與下文得出的相關結論,結合樂隊流派與歷史,開始寫英語作文,(時間緊,網路關系圖未作處理不放上了,注意用所有資料做出的圖非常的密集,這時需要分年份\或者下文聚類、流派將有名氣的樂隊作為節點重新畫非常好看的圖)
注1:(上圖只是預覽 下文還將計算圖與網路模型中的點度中心性來衡量一個結點的影響力),中介中心性、接近中心性、特征向量中心性都可以使用)
問題1:
(1)使用 Influence_Data 資料集創建音樂影響力的有向網路
根據Influence_Data 資料集構建有向網路圖,
這個容易,推薦使用python或者gephi軟體制圖,還可以進一步網路處理,關鍵是簡單好學,
我們需要匯入的資料有三列:source、target、weight(源、目標、權重)
所以第一步需要進行資料歸約,構建source、target、weight資料集,影響者和追隨者的資料已經有了,定義權重來解釋“音樂影響力”是關鍵的,
如何定義“音樂影響力”權重?眾所周知,音樂人之間的影響與其流派、流行時間有著不可分割的聯系 ,我們需要建立一個音樂人影響力評價指標體系,由于本文是思路,就不詳細展開,這個相互影響力權重以及影響力評價指標體系有多種定義方法,(此方案待定,可以簡化)
(2)使用子網路描述音樂影響力,分析你建立的音樂影響力揭示了什么?
根據上表,可以選擇有代表性的年份、有代表性的若干音樂人(影響力大的)重新進行制圖,得出結論任意發揮,與政治歷史時期或音樂發展史結果寫作,(此方案待定)
問題2:
(1)用音樂特征資料集( FULL_MUSIC_DATA)以及音樂家影響資料集(influence_data)建立音樂相似度模型,
非常容易
兩個方向:相似度度量與距離度量
可以采用余弦相似度\jaccord相似系數(相似度度量)或歐式距離\切比雪夫距離(距離度量)構建相似度模型,
如用余弦相似度得到兩兩音樂人之間的相似度矩陣,
由于資料量大,可以先使用R型聚類分析、主成分分析的方式降維,
(2)利用該模型回答問題:流派內與流派外音樂家相似度更大嗎?
該問題比較關鍵:
方法1:統計假設方法—方差分析\顯著性檢驗,比如X流派中a與自身流派的相似度為{0.7,0.5,0.8,0.9,0.65},a與Y流派中音樂人的相似度為{0.2,0.3,0.5,0.1,0.4},我們是否可以使用求均值的方法判斷不同的流派是否對相似度有影響?忽略偶然因素是可以這樣的,但是我們也可以從概率統計的角度考慮進行顯著性檢驗,
即 對于兩組資料,流派的不同是否對相似度具有顯著性影響?我們可以作出假設,驗證,得到結論,(由于各流派的音樂人數不一樣,我們需要考慮將流派人數多的一方中影響力小的的音樂人去除處理)
方法2:編程實作:選出3-5個count數最多的流派,將其里面所有的音樂人與自己流派的相似度求均值,再與其他流派的均值做對比串列解釋,
問題3:
(1)比較流派之間的相似之處?流派的區別是什么?
編程問題,將音樂人與其流派鏈接在同一資料集中,
做法1:這里的相似之處比較定性,可以使用距離度量和余弦相似度結合計算,得出最相近\相似的流派,手動分析,
流派的區別可以根據相似度最低的流派特征手動分析,
做法2:
(2)流派是如何隨著時間推移變化的?
根據資料特征畫出流派關于時間變化的折線圖,分別為流行指標、發行數量…(未完)
-時間緊迫思路沒有來得及制作,會持續更新,上述提到的方法和代碼加群即可免費咨詢,
思路總結:現在需要做的事☆
1.根據influence資料編程求出各音樂人的出度入度
2.根據full_music資料建立相似度模型,計算出音樂相似度,需要使用資料降維方法以及篩出部分再influnce資料里沒有的音樂人,
3.進行顯著性檢驗,得出不同流派對音樂的相似度有顯著性影響的結論,
4.對時間軸進行處理
2021美賽D題美國大學生數學建模競賽D題
公眾號:積木數學建模
qun:719893042
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/257074.html
標籤:其他
上一篇:2021數學建模美賽F題資料分享
下一篇:2021美賽C題資料讀取