目錄
- 0引言
- 1、賽題要求
- 1.1翻譯后的要求:
- 1.2賽題小結
- 2、問題一模型思路
- 2.1資料讀入合并
- 2.2可視化
- 2.2回歸模型
- 2.3時間序列模型
- 2.3.1 重塑資料
- 2.3.2 選擇模型
- 2.4生長季模型
- 3、問題二的模型思路(影像)
- 3.1評論文本的詞頻統計及詞云圖
- 3.2 資料和圖片資料整理
- 3.3模型部分
- 3.3.1
- 3.3變數整理
- 本文涉及代碼
- 第一問代碼
- 寫在最后的建議
0引言
看了一天多的美賽C題,打算這兩天從編程手的角度更新一些美賽的思路以及代碼資料(R語言),
更新中… …
注意:本文的代碼及思路僅供參考,切勿照抄,比賽期間勿私聊 … … ,
1、賽題要求
1.1翻譯后的要求:
– 1、討論這種害蟲隨著時間的推移而傳播是否可以被預測,傳播的特點是什么,
– 2、很多報道的目擊事件都將其他黃蜂誤認為是野黃蜂,使用提供的資料集檔案和檔案提供的影像視頻檔案來創建模型,并分析和預測錯誤分類的概率,
– 3、使用建立的模型討論您的分類標準如何導致優先調查最有可能是陽性(野黃蜂)的目擊報告,
– 4、隨著時間的推移如何使用模型更新出新報告,預測發生的頻率,
– 5、使用你的模型,什么時候可以說明華盛頓州已經消滅了這種害蟲?
1.2賽題小結
前兩問是本次問題建模的核心,分別是:
1、根據時間和空間的經緯度關系分析出該黃蜂的傳播特點以及生存特性,
2、結合給出的每次目擊報告的檔案資訊:影像資料、文本評論資料作為協變數資料、識別結果:陽性陰性作為相應遍量建立可預測的回歸模型,
后面三問都是對前兩問中的一個模型應用以及模型穩健分析,
2、問題一模型思路
2.1資料讀入合并
為了更好了構建模型,分析資料先讀取資料進行預處理和可視化,
兩個Excel資料可去鏈接免費下載:2021美賽excel資料
讀入資料,分析欄位
> str(GlobalID)
Classes ‘data.table’ and 'data.frame': 3305 obs. of 3 variables:
$ FileName: chr "ATT1_DSCN9647.jpg" "ATT10_67EAF187-B59C-4F5F-BAAC-9F76E06A96D6.jpg" "ATT100_inbound241937372812029587.jpg" "ATT1000_A5A50BAB-A6EF-4576-A1F8-A07862AADE3A.jpg" ...
$ GlobalID: chr "{5AC8034E-5B46-4294-85F0-5B13117EBEFE}" "{C4F44511-EA53-4FCF-9422-E1C57703720D}" "{43506835-18B8-46B2-A2CB-586AF9C8ECE6}" "{E0AE2F2A-38A5-463C-97B5-9F84A477F9AE}" ...
$ FileType: chr "image/jpg" "image/jpg" "image/jpg" "image/jpg" ...
- attr(*, ".internal.selfref")=<externalptr>
> str(DataSet)
Classes ‘data.table’ and 'data.frame': 4440 obs. of 8 variables:
$ GlobalID : chr "{7D0E73B4-EB54-4CA5-B6B0-F36CC41EBFBC}" "{55C3DF05-0FC3-4737-98CE-2AECFA6C21DB}" "{29CAD9B0-977C-4947-BD62-5CA381CEEA33}" "{DFA7F66D-8DCB-43D7-93EC-3F2E42602600}" ...
$ Detection Date : POSIXct, format: "2020-01-21" "2020-01-22" ...
$ Notes : chr "Definitive orange color....1.5-1.75\" long...very large body....this is the same report I turned in last night,"| __truncated__ "Looked like a yellow jacket on steroids was over an inch long I stepped on it to kill my wife scooped up with s"| __truncated__ "Big and nasty" "I killed this hornet with a bug zapper it took about 30 to 40 mins to kill every time I hit it it came back wit"| __truncated__ ...
$ Lab Status : chr "Unverified" "Unverified" "Unverified" "Unverified" ...
$ Lab Comments : chr "If you see it again, please submit a picture with your next reported sighting." NA NA NA ...
$ Submission Date: POSIXct, format: "2020-07-07" "2020-05-05" ...
$ Latitude : num 47.4 47.4 47.5 48.1 45.6 ...
$ Longitude : num -119 -122 -122 -122 -123 ...
- attr(*, ".internal.selfref")=<externalptr>
為了后面的容易處理,用DataSet做主表,對GlobalID做左連接合成一個表,
并提取年份和月份,記為變數y和m
維度:5618行13列
> str(r)
Classes ‘data.table’ and 'data.frame': 5618 obs. of 13 variables:
$ FileName : chr NA NA NA NA ...
$ GlobalID : chr "{7D0E73B4-EB54-4CA5-B6B0-F36CC41EBFBC}" "{55C3DF05-0FC3-4737-98CE-2AECFA6C21DB}" "{29CAD9B0-977C-4947-BD62-5CA381CEEA33}" "{DFA7F66D-8DCB-43D7-93EC-3F2E42602600}" ...
$ FileType : chr NA NA NA NA ...
$ DetectionDate : POSIXct, format: "2020-01-21" "2020-01-22" ...
$ Notes : chr "Definitive orange color....1.5-1.75\" long...very large body....this is the same report I turned in last night,"| __truncated__ "Looked like a yellow jacket on steroids was over an inch long I stepped on it to kill my wife scooped up with s"| __truncated__ "Big and nasty" "I killed this hornet with a bug zapper it took about 30 to 40 mins to kill every time I hit it it came back wit"| __truncated__ ...
$ LabStatus : chr "Unverified" "Unverified" "Unverified" "Unverified" ...
$ LabComments : chr "If you see it again, please submit a picture with your next reported sighting." NA NA NA ...
$ SubmissionDate: POSIXct, format: "2020-07-07" "2020-05-05" ...
$ Latitude : num 47.4 47.4 47.5 48.1 45.6 ...
$ Longitude : num -119 -122 -122 -122 -123 ...
$ y : num 2020 2020 2020 2020 2020 2020 2020 2020 2020 2020 ...
$ m : num 1 1 1 1 1 1 1 1 1 1 ...
$ m : num 1 1 1 1 1 1 1 1 1 1 ...
- attr(*, ".internal.selfref")=<externalptr>
2.2可視化
賽題給了我們經緯度,先看一下具體的位置在哪里:
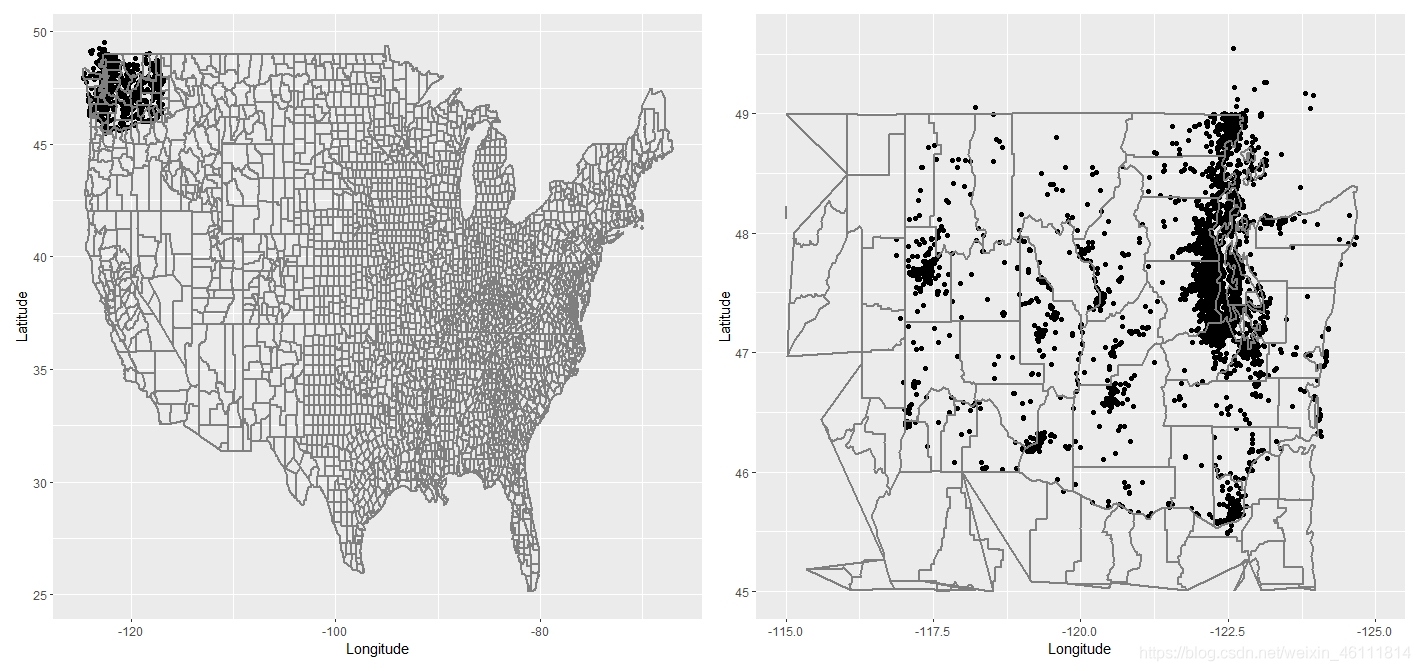
我找到了地圖當底盤,畫了散點圖,左邊是美國所有州的地圖,我們看到只有左上角的華盛頓州有記錄,所以我們調整圖片的范圍得到右圖,但是這樣畫到一起看不出任何的資訊,通過R語言glpot2分面的技術得到下面的圖,

假設點不重疊,從點的數目上可以看出黃蜂從2017年開始有苗頭2018-2019增長期,2020年份數目驟增,接下來我們還想知道該物種是否具有季性,故加下來以2020年為例分月份我們畫出了下面兩幅圖形,

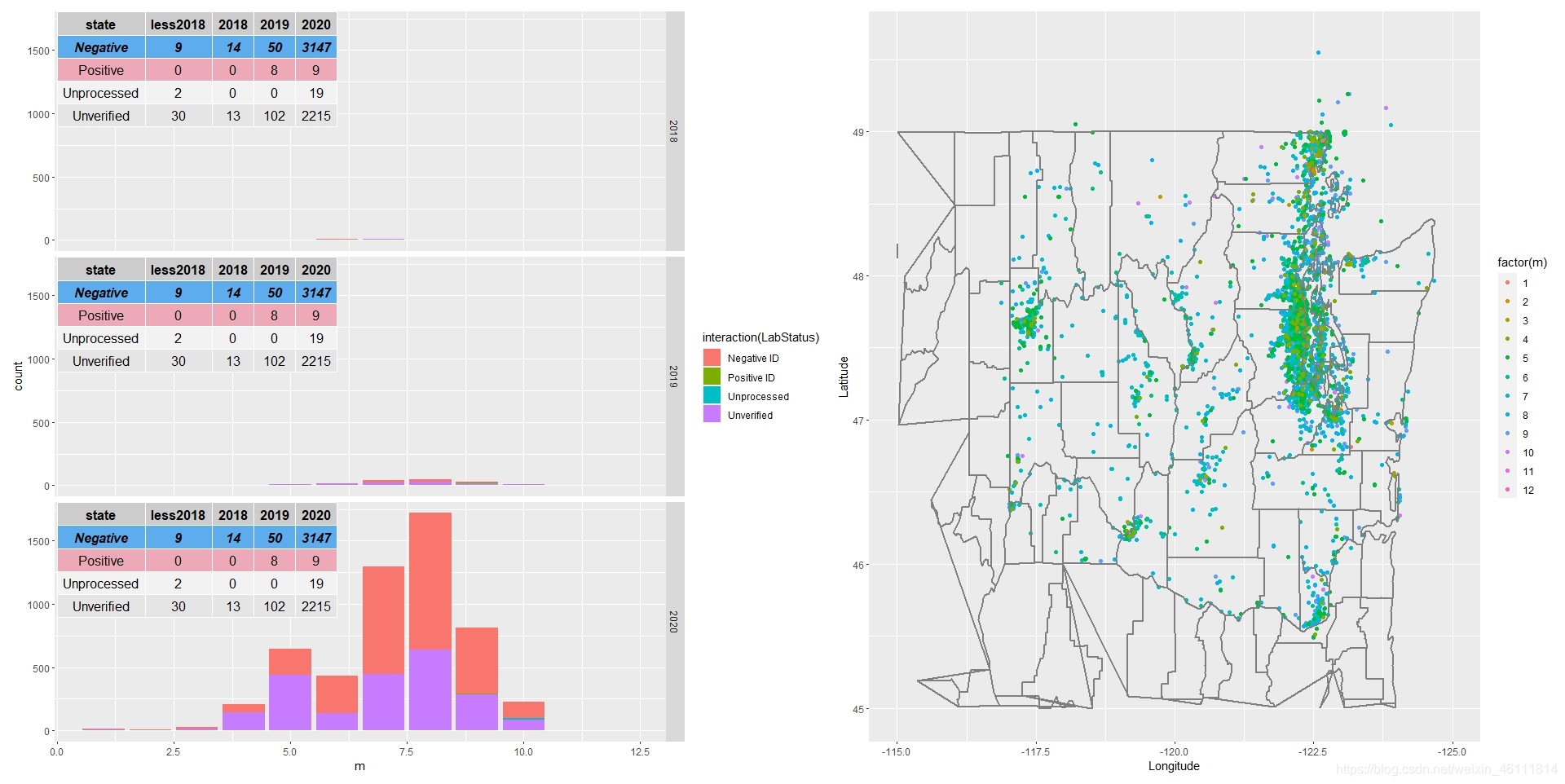
上面那一幅圖的是2020年不同月份發現的黃蜂報告數目,可以看出報告多集中在夏季前后,下面的幅圖是每個月份做出的具體統計與可視化,有了這些關于黃蜂的資料特點我們下面選回歸模型、時間序列的分解模型和生長季模型來量化黃蜂生長的時間特點,
2.2回歸模型
統計每年的報告資料做回歸模型:
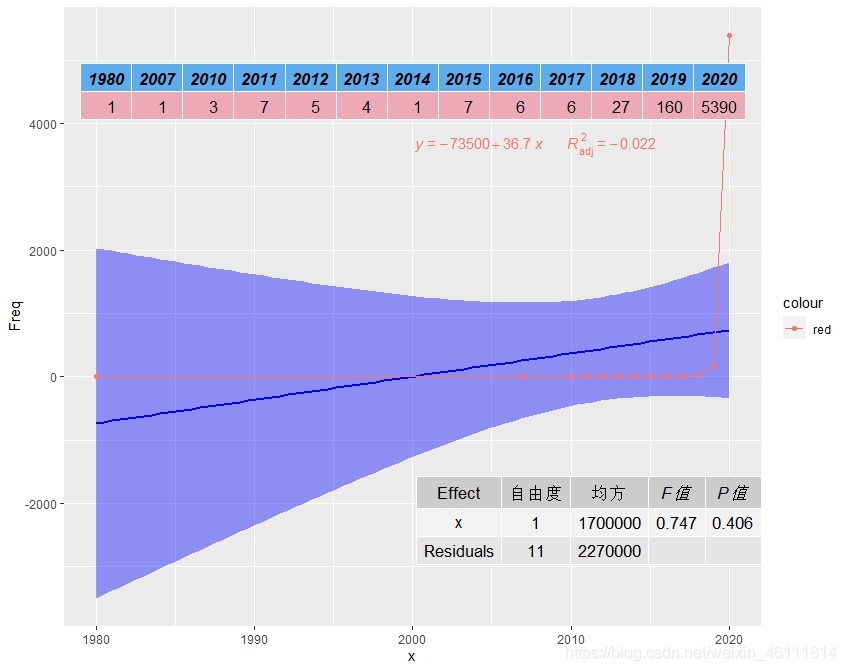
我們看到這個模型的效果不是很好無論是R2還是擬合曲線,還是曲線的方差,原因就在于這個資料在2020年有一個突增,
2.3時間序列模型
在時間序列模型中我們選擇從2010年到2020年11年的時間,并細化到月份,
2.3.1 重塑資料
> Ts
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
2010 0 1 0 1 0 0 0 0 1 0 0 0
2011 1 0 0 1 1 0 1 2 1 0 0 0
2012 0 0 0 0 0 2 2 1 0 0 0 0
2013 0 0 0 0 0 0 2 2 0 0 0 0
2014 0 0 0 1 0 0 0 0 0 0 0 0
2015 0 0 0 2 1 1 1 2 0 0 0 0
2016 0 0 0 0 0 1 3 2 0 0 0 0
2017 3 0 0 0 0 2 0 0 1 0 0 0
2018 0 1 0 1 5 7 9 3 1 0 0 0
2019 2 0 1 1 11 18 39 50 26 7 3 2
2020 12 7 25 205 649 435 1296 1719 811 227 3 1
從統計資料中我們可以看到一定的季節性,和周期性,下面我們通過建模進行提取關鍵資訊,
2.3.2 選擇模型
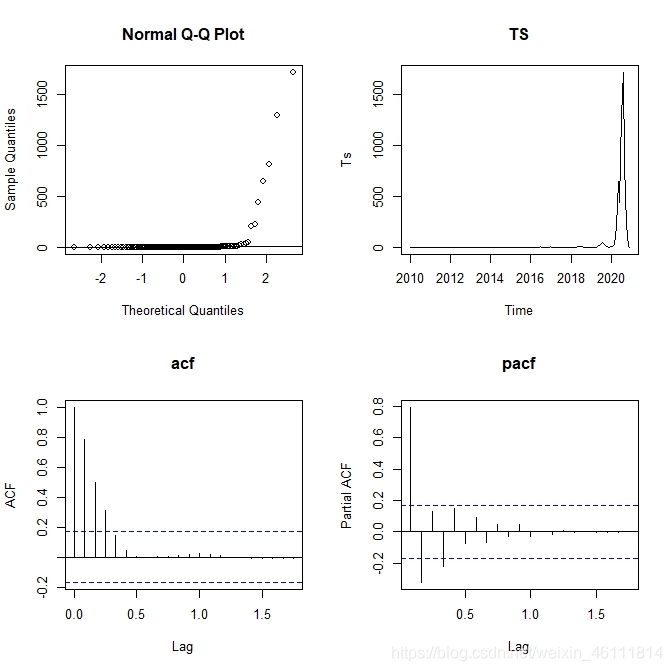
qq圖告訴我們這幅圖不是純隨機的圖也不是正態圖,從時序圖中我們看到該序列具有明顯趨勢,故不平穩,從acf、pacf中可以看出,雖然有截尾特征,但是他的不滿足平穩時間序列的前提,所以不能夠建立ARMA模型,可以考慮ARIMA以及SARIMA,就這個題目而言SARIMA比較貼切,
這里我們用加法模型來擬合資料,因為乘法模型對資料突變的資料處理總是不好,

季節指數圖:
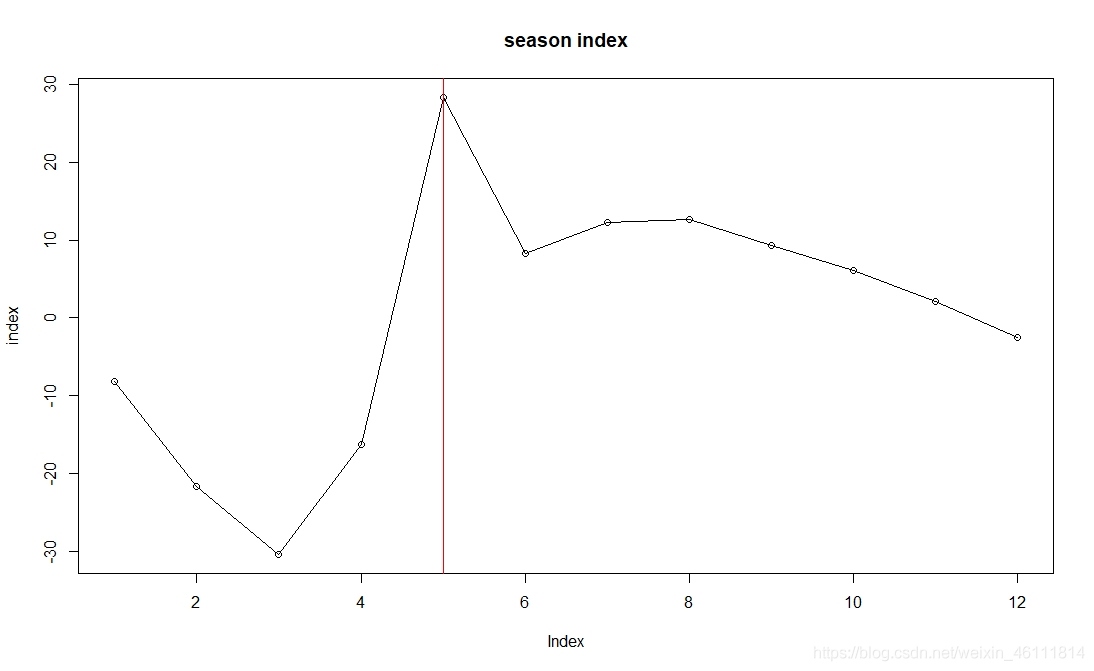
上圖是1-12月份的季節指數,可以看出5月份季節指數最高,3月份達到低谷,
最后我們給出分解模型的三個組成部分:
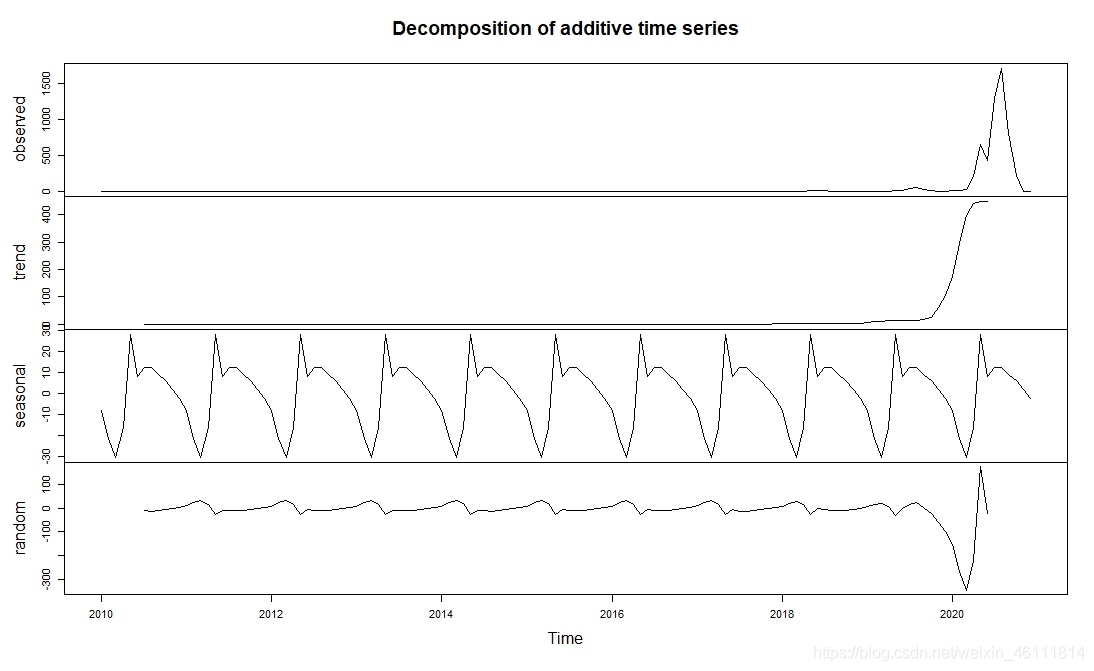
第一行是原始的時間序列圖,第二行是長期的趨勢,第三行是模型的周期性,第四行是模型的隨機因素,如果想具體到幾月份達到峰值,周期長度是多少,驟變結點是哪一個,可以直接處理資料的資料,篇幅原因就不把每個模型的資料輸出了,
當然我個人不是和喜歡這個圖的風格,想改的下面的代碼可以實作,
function (x, ...)
{
xx <- x$x
if (is.null(xx))
xx <- with(x, if (type == "additive")
random + trend + seasonal
else random * trend * seasonal)
plot(cbind(observed = xx, trend = x$trend, seasonal = x$seasonal,
random = x$random), main = paste("Decomposition of",
x$type, "time series"), ...)
}
2.4生長季模型
生長季模型是一類模型常用來處理植被的時空變化的NDVI(生長指數)值,這節通過不同時間節點的報告數,并計算黃蜂的頻率指數,建立生長季模型,最終計算出不同年份中黃蜂的快速增長點,快速下降點,以及出現的時間長度,
本文建模的代碼方法參考的包phenofit,給出他的代碼示例網站鏈接,
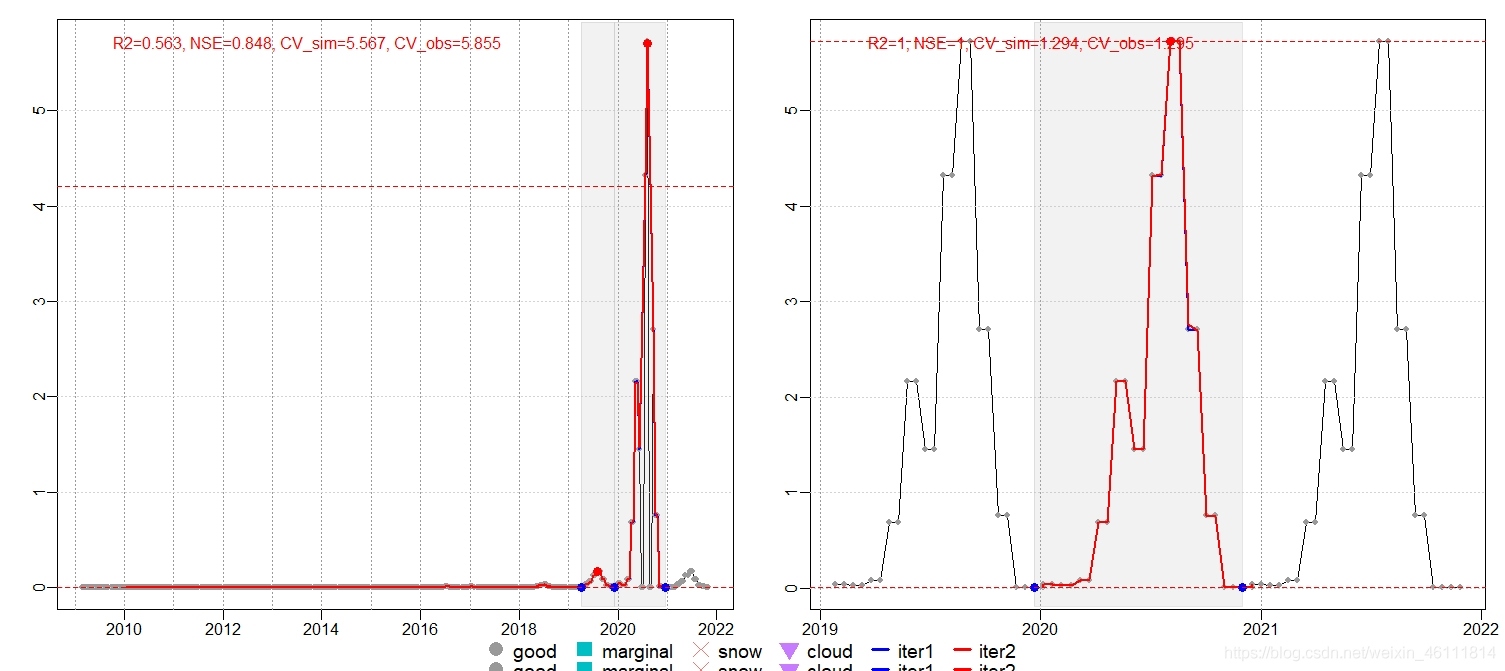
左圖是20210-2020的昆蟲的報告情況,右圖是2020年的的一個情況,(AG方法的例子)
> myfit(df[241:264,]) # 2020
flag origin TRS2.sos TRS2.eos TRS5.sos TRS5.eos TRS6.sos TRS6.eos DER.sos DER.pop
1: 2020_1 2020-01-01 124 276 160 260 170 256 171 229
DER.eos UD SD DD RD Greenup Maturity Senescence Dormancy
1: 255 113 209 238 282 94 214 290 NA
可以看到TRS2方法的生長季(sos: start of season)節的開始是這年的第124天,結束(eos)是這年的276天,持續存在了153天,
模型的引數和形式,這是對稱的模型曲線,
$fFIT
$fFIT$AG
formula: mn + (mx - mn) * exp(-((t0 - t) * rsp)^a3)
formula: mn + (mx - mn) * exp(-((t - t0) * rau)^a5)
pars:
t0 mn mx rsp a3 rau a5
nlminb 7533.309 0.03075173 5.477063 0.01217213 2 0.02732946 2
3、問題二的模型思路(影像)
整題想法:第二問是想把整個題目做成一個回歸的任務,因為回應變數是離散的,所以考慮的是分類變數,把資料按著評論、時間、空間、圖片資訊的思路進行整理,如下圖:是我代碼中整理變數生成代碼的含義:

這里圖片處理運用的是SVD的壓縮影像的技術,不過后來因為資料規模大,運行不動就改用了pac(主成分)提取最大特征值的方法進行壓縮,得到相應的協變數,
最后回歸的方法用了:
– 高斯的回歸分析
– 基于邏輯回歸和MCP結合的變數選擇方法
– lda判別分析方法
– 當然還有其他諸如:支持向量機、決策樹、隨機森林、神經網路等回歸方法,
下面具體介紹資料的整理思路,
3.1評論文本的詞頻統計及詞云圖
下面是每次報告評論的詞頻及詞云圖
> word(ls)
Encoding of stop words file: ascii
ls3
wasp hornet sawfly digger golden horntail wood asian
967 676 537 472 469 375 273 260
cicada bee killer giant dead yellow female don
243 240 239 207 166 162 158 150
bald kill faced native urocerus inches insect beetle
146 144 142 138 133 132 129 128
picture bees orange wa bug ground yard hornets
120 119 115 113 111 111 104 103
inch flying black stinger elm photo murder fly
102 99 98 98 95 95 94 89
garden june bumble killed house hard nest head
89 88 85 81 80 78 78 76
harmless alive flew genus huge looked jacket ten
73 72 72 72 72 72 71 70
body size lined county jar western siricid pictures
69 69 68 66 65 62 61 59
caught negative larger 1.5 pool sp landed didn
57 57 56 54 54 53 52 49
coloring front photos captured paper cimbex trapped species
48 47 47 46 46 45 45 44

3.2 資料和圖片資料整理
這部分介紹圖片的初步處理思路,每層.jpg的檔案是長*寬*3的一個rgb儲存彩色的形式,根據R語言——基于SVD的人臉識別所采用的方法,使用0.299、0.587、0.114三個比例對R、G、B進行加權,得到灰色模型,
效果圖如下:
轉換為灰色的好處可以圖片降維,方便后面的特征提取,或者svd降維,接下就是根據整體思路那里介紹的整理變數,
我是用的特征值的方法提取的變數,選擇了前10個特征值,他從3000+個特征值中的占比是90+%效果還OK,
下面是處理exel和影像(jpg and png)得到的可用回歸資料,3208次觀測,15個變數,
> str(Data)
Classes ‘data.table’ and 'data.frame': 3208 obs. of 15 variables:
$ y : num 1 0 0 0 0 0 0 0 0 0 ...
$ m : num 12 2 5 7 7 7 7 7 7 7 ...
$ LoN : int 55 203 199 161 54 20 95 160 160 47 ...
$ LoC : int NA 63 23 111 14 19 14 44 44 14 ...
$ EorW: logi FALSE FALSE TRUE FALSE TRUE TRUE ...
$ V1 : num -0.00781 -0.01773 -0.01358 -0.01322 -0.01536 ...
$ V2 : num 0.0412 -0.01795 -0.02085 -0.00677 0.01333 ...
$ V3 : num -0.01361 -0.01934 -0.01963 -0.00894 -0.00205 ...
$ V4 : num -0.025232 0.007893 -0.019865 0.000805 0.000668 ...
$ V5 : num -0.01894 -0.02135 0.00768 -0.00718 0.00487 ...
$ V6 : num -0.04329 -0.02533 -0.00857 -0.01218 0.02815 ...
$ V7 : num -0.05079 0.00663 -0.03299 0.0076 -0.00403 ...
$ V8 : num -0.03732 0.000421 -0.002197 -0.010853 0.020643 ...
$ V9 : num 0.00528 0.01741 -0.00041 0.00631 -0.00956 ...
$ V10 : num 0.00461 -0.0378 -0.01417 -0.00889 0.0164 ...
- attr(*, ".internal.selfref")=<externalptr>
3.3模型部分
3.3.1
寫作中… …
3.3變數整理
本文涉及代碼
每一題目(只更新前兩問)在發布完思路后,統一發布合集鏈接,更新中 … …
會陸續發布思路代碼,感興趣的下面鏈接自取,
第一問代碼
注意:代碼在安裝包之后可正常運行,不需要改動引數,但是這是R語言的代碼,沒有R語言基礎的同學不推薦購買下載,
第一問代碼鏈接,
寫在最后的建議
比賽期間合理安排作息,注意休息,O獎沖呀!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/257388.html
標籤:AI