分布式存盤引擎大廠實戰——一致性哈希在大廠的應用
- 背景
- 資料是如何存盤的
- DHT優化
背景
? 作為k-v存盤的開山鼻祖,Dynamo從亞馬遜研發出來之后就在存盤領域引起了轟動,理論上說Dynamo可以無限擴容,且性能是無限線性遞增的(后面會將為啥理論上講是無限線性增長),Dynamo的動態伸縮讓系統的scale-out能力極強,Dynamo延伸出dynamoDB作為nosql 領域的代表DB,Dynamo保證系統無限擴展且同時性能不下降的關鍵,是讓整個存盤集群沒有中心節點,擴容的所有的節點都能負載均衡,跟集群里面的其他節點對等,要實作這樣的能力,需要依賴一種資料的均勻分布的演算法,該演算法夠隨機并且在節點變動的時候,不能引起資料大面積失效(必須保證大部分資料在集群出現擴縮容時候不震蕩),這時分布式哈希表(DHT)就應運而生了,
資料是如何存盤的
? 講DHT之前,我們先講講分布式集群里面資料會怎么存盤,既然是分布式集群,那么資料是分布存盤的,不會只存在一個節點上面,那么必然是需要一種存盤的邏輯來控制資料是在集群里面的分布存的,舉個例子,假設集群里面的有4個節點 node1 node2 node3 node4,要存的資料是存盤 1 -20 這20個數字,那么你會怎么建立資料—》節點的存盤關系?比較常用的是按節點數取模演算法,按該演算法資料分布如下:
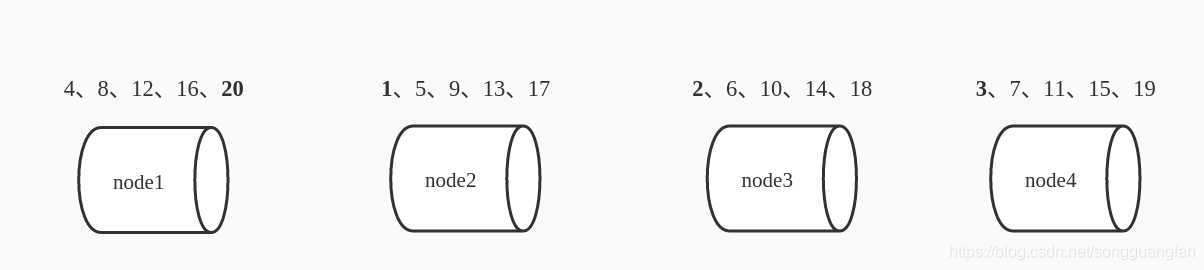
? 這個映射的關系就是資料n( 1=<n<=20) 按照 m = n%4 +1 存到下標是m的node中去, 如果這時候集群里面的節點加一個,變成了node5 ,那么資料該怎么分布式了?
? 同樣按照 m=n%5+1的原則 資料分布變成如下, 通過對比 4 節點到 5 節點資料的分布,發現其實只有4個資料還在原來的節點上,其他的資料分布完全變了,1-4/20=80% , 可以看到新加了一個桶后80%都變了,這就意味這哈希表的每次擴展和收縮都會導致條目分布的重新計算,這個特性在某些場景下是不能接受的,如下圖所示

? 分布式存盤系統中,圖中的每個桶就相當于一個機器,檔案分布在哪臺機器由哈希演算法來決定,這個系統想要加一臺機器由哈希演算法來決定,這個系統想要加一臺機器時就需要停下來等所有檔案重新分布一次才能對外提供服務,而當一臺機器掉線的時候盡管只掉了一部分資料,但所有資料訪問路由都會出問題,這樣整個服務無法平滑地擴縮容,成了有狀態的服務,那么怎么實作無狀態化呢?今天的主角DHT演算法就出現了,DHT 全稱(Distributed Hash Table,分布式哈希表),前面的取模演算法之所以會導致資料分布震蕩的原因是,資料分布邏輯隨著節點的變化規則完全變了,不能讓已分布的資料有較好的繼承性(即資料依然大部分分布在原來的節點),
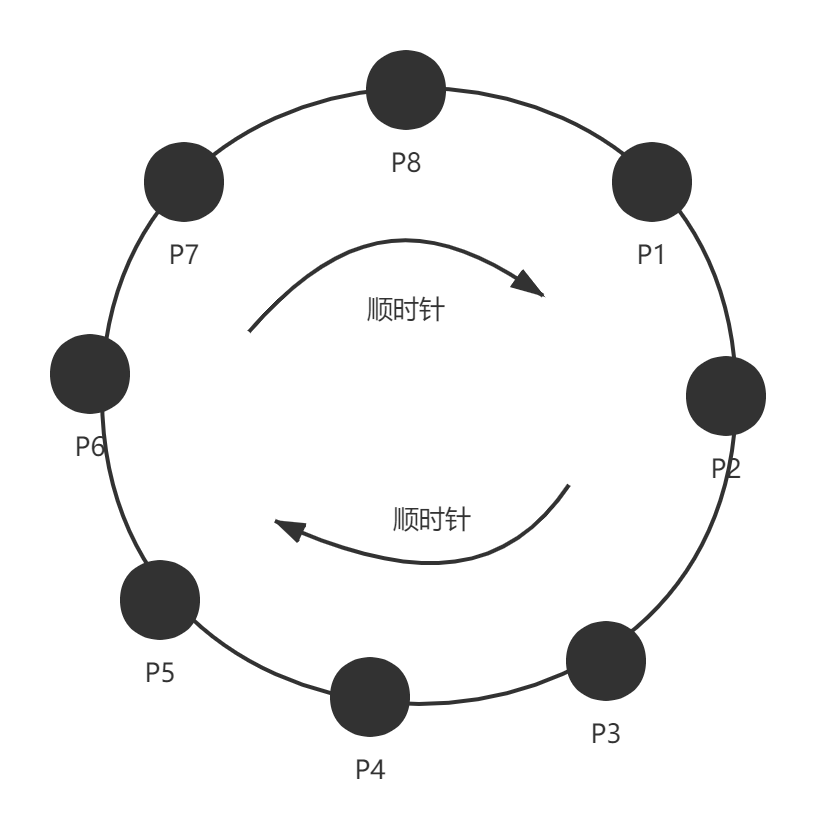
? 典型的DHT模型有環形結構,會把所有輸入key的hash值映射到一個環形的空間上面,我們還是來看上面的例子,資料 1-20 需要存盤在四個節點上,環形空間用0-63(2的n次方-1,這里n=6)表示, 這里 hash(key)范圍屬于(0-15] 則映射到node1,hash(key)范圍屬于(15,31] 則映射到 node2 , hash(key)范圍屬于(31,47] 則映射到node3,hash(key) 范圍屬于 (47,63] 則映射到node4 ,按照順時針方向,資料的hash值放到下一個距離自己最近的node節點上,
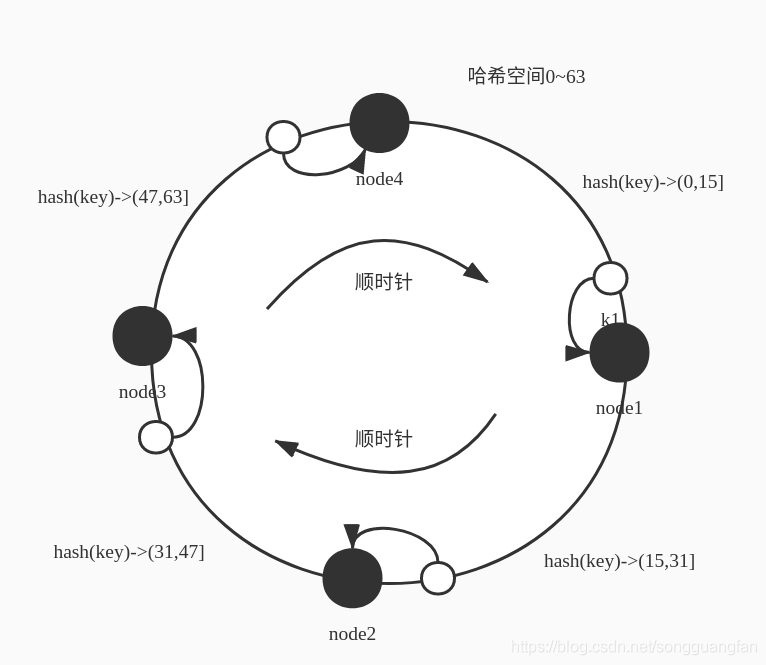
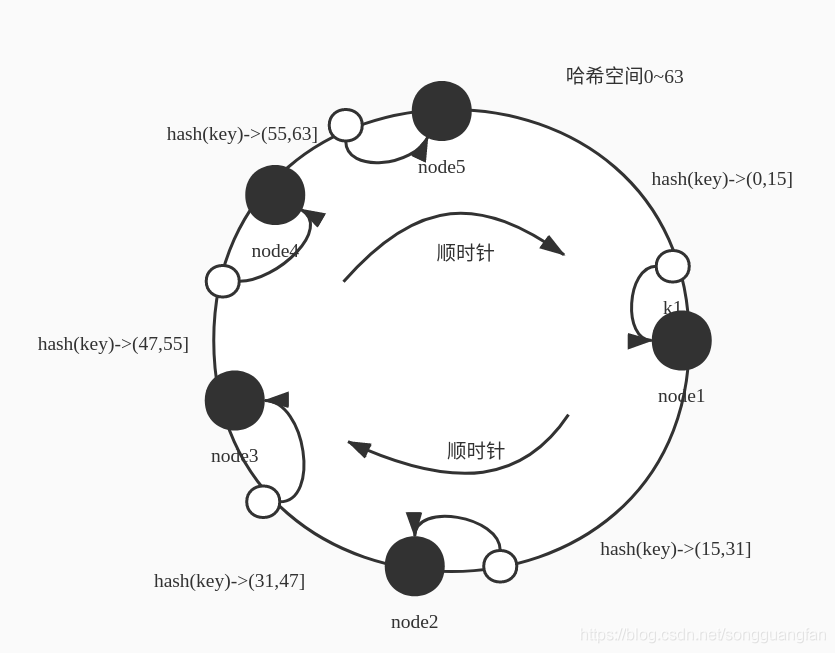
? 這時候如果加一個節點 node5,變成5個,hash范圍還是0-63,則映射規則會變化,新加入的節點也要分攤一部分空間的映射,則可能的一種空間分配的方式,節點node5 添加到 node4 和node 1 之間,這時候的空間分配可能變成如下,范圍屬于(0-15] 則映射到node1,hash(key)范圍屬于(15,31] 則映射到 node2 , hash(key)范圍屬于(31,47] 則映射到node3,hash(key) 范圍屬于 (47,55] 則映射到node4 ,hash(key)范圍屬于(55,63] 映射到node5 如下圖表示 :
? 如果反之,這時候一個節點退出集群,少了一個節點,比如node3退出了,那么資料會如何分布?按照資料會按hash值按順時針方向找距離自己最近的那個node節點存放,則范圍屬于(0-15] 則映射到node1,hash(key)范圍屬于(15,31] 則映射到 node2 , hash(key)范圍屬于(31,63] 則映射到node4 , node4的負載是其他節點2倍:如下圖
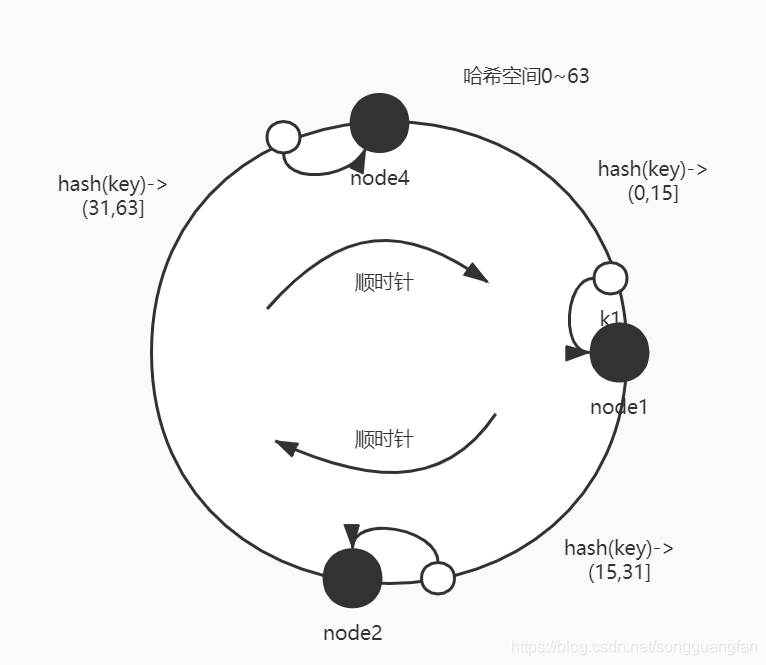
? 很明顯的看到,新增了一個節點如果映射空間分配滿,則1-8/64=87.5%的資料依然會分布在原來的節點上,減少了一個節點,則有1-16/64=75%分布在原來的節點上,資料的動蕩范圍大幅度降低,對比前后兩種模式,大家就能感受到DHT演算法做分布式資料分布的好處,第二種方式有沒有啥問題?工程里面是這樣直接使用的嗎?下面會就工程里面的使用方式做優化,
DHT優化
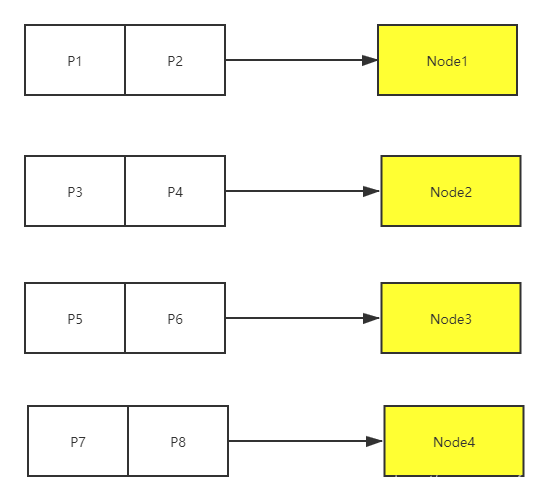
? 首先的問題,一開始四個節點是把空間均勻分配的,加入個新節點后,node4 和 node5 分攤的空間明顯比其他節點少了一半,減少一個節點node3之后,node4的分攤的空間又是其他節點的2倍,這就使得各個節點的負載能力不同了,各個節點的能力無法均衡,所以首先這里有一個問題,分攤空間的節點最好是不變的,不變那怎么增加節點或者洗掉節點呢?所以真正的工程應用上引申出logic節點的概念,又叫partition, 空間一開始就按partition分配好,如把空間
2
31
^{{2^{31}}}
231 -1 映射到partition(每個partition用p表示),
? 見上圖把空間分成了8份,這8個邏輯空間是不會再變化的,然后就有一層邏輯節點到物理節點的映射關系,再以前4個物理節點為例,那么partition到node的映射關系如下圖:
? 這時候如果新增一個節點node5,則映射關心將會變化,會從node2、node3上把partition遷移到node5上,這種叫做資料均衡演算法,它是節點在出現變化時系統保持各節點負載均衡的一種機制,這個演算法會對系統可靠性以及性能影響很大,
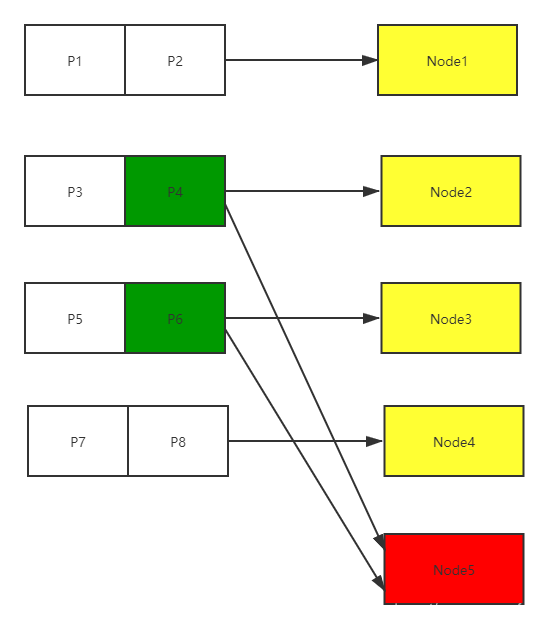
? 從上圖的增加節點資料重新遷移分配可以看出,partition必須足夠多,不然各個物理節點負載能力還是會有比較大的差異(比如上圖,遷移后,node2和node3的負載不其它節點少了一半),
一般在工程應用里面增加或者退出節點的時候,系統是會對業務IO做降級處理的,優先保障資料的均衡完成,因為存盤產品的工程應用里面選擇了CAP的AP兩個點,從而實作最終一致性,
? 本章對一致性哈希進行了講解,后續將介紹在分布式存盤系統中,資料是如何保證可靠性以及一致性的,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/257747.html
標籤:AI
上一篇:30行代碼實作螞蟻森林自動偷能量
下一篇:阿里面試題多執行緒列印問題