模型選擇標準,懲罰回歸,結語
- 一. 模型選擇標準(Model selection criteria)
- 二. 懲罰回歸(Penalized Regression)
- 三. 結語
一. 模型選擇標準(Model selection criteria)
我們回顧下監督學習
當我們有
p
+
1
p+1
p+1個變數和n組資料(n行),如果我們要預測其中的一個變數,我們要利用剩下的部分變數(<=p個)來預測我們的這個變數,
如果我們的預測變數是分類資料,那么我們利用分類有關的模型,
如果我們的預測變數是數字型資料,那么我們利用回歸相關的模型,
在第7章和第6章,我們有提到過,剩下的p個變數我們不一定全部都會用上,因為有的變數很重要,有的變數不重要,舉個例子,我們預測房價,但是,假如我們有個變數是關于客戶的血壓,這個變數很明顯和我們的預測房價這個變數多多少少關系不大,那我們則會忽略這個變數,如果我們有個變數是關于客戶的薪資,這個變數我們自然會把它考慮在內,至于如何挑選有關變數請看第7章邏輯回歸模型(分類模型)的變數選擇,模型選擇,和第6章的模型選擇,利用模型的資訊準則和正向邏輯或者逆向邏輯來選擇相關的變數,
如果我們忽視了某個重要的變數,那么我們的模型很容非飽和,也就是我們的預測(對于訓練資料內部的預測)會有很大的偏差,
如果我們把全部的變數都考慮在內,那么我們的模型很容易過飽和,這是因為我們的模型也“學習”到了資料里的噪音和隨機變化,那么對于我們未知資料的預測(對于測驗資料的預測)會產生極其不準確的影響,
非飽和,過飽和例子
假如我們這里有n組資料(n行),我們有一個x變數和一個預測y變數,我們現在要用一個模型來詮釋我們的資料,即x變數和y變數的關系,根據第6章所述,我們用一個簡單粗暴的模型即多項式回歸模型,它很簡單,很靈活,可以表達非線性的關系,
我們先隨便寫個多項式模型:
y
=
β
0
+
β
1
x
+
β
2
x
2
+
β
3
x
3
+
.
.
.
+
β
p
x
p
y=\beta_0+\beta_1x+\beta_2x^2+\beta_3x^3+...+\beta_px^p
y=β0?+β1?x+β2?x2+β3?x3+...+βp?xp
上述多項式模型有p+1項,x最高為p次,沒錯
x
2
x^2
x2意味平方,
x
p
x^p
xp意味著p次方,小弟這里只是為了舉個非飽和和過飽和的例子,我們可以把
(
x
,
x
2
,
x
3
,
.
.
.
,
x
p
)
(x,x^2,x^3,...,x^p)
(x,x2,x3,...,xp)看成有p個x變數即
(
x
1
,
x
2
,
.
.
.
,
x
p
)
(x_1,x_2,...,x_p)
(x1?,x2?,...,xp?),
假設我們有50個資料,那么先把它的正確曲線標畫出來,其實這50個資料就是由該曲線加上誤差
ε
\varepsilon
ε產生的,如下圖:
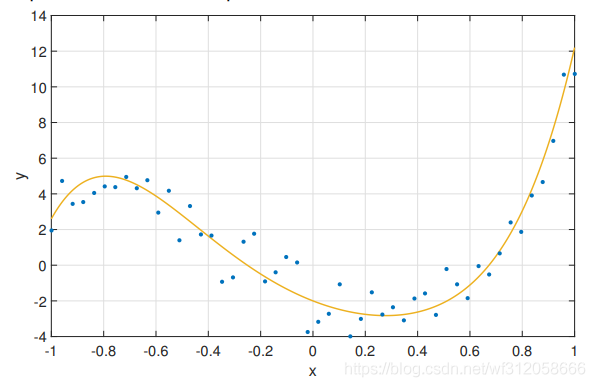
上圖的黃色曲線為我們的正確回歸曲線,
如果我們的多項式回歸模型僅僅有兩項即
(
x
,
x
2
)
(x,x^2)
(x,x2),那么我們的影像虛線為:
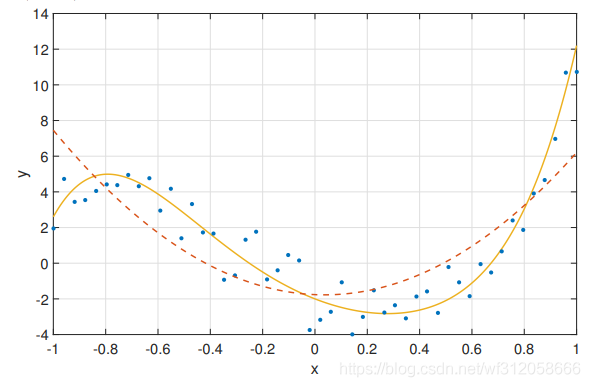
從這張影像中我們可以看到,我們的虛線過于簡單了,我們的虛線無法詮釋大部分藍色資料的點,這即為非飽和,
如果我們的多項式回歸模型有20項
(
x
,
x
2
,
.
.
,
x
2
0
)
(x,x^2,..,x^20)
(x,x2,..,x20),那么我們的影像虛線為:
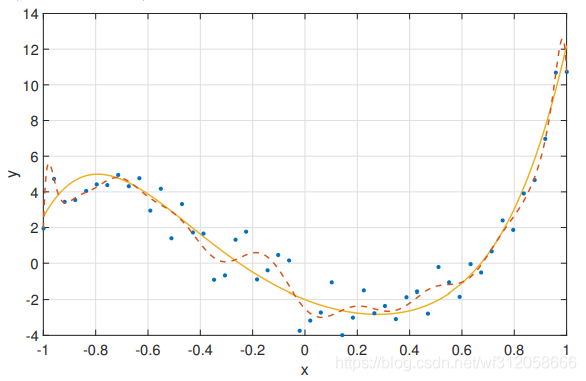
從上圖可以看到,我們的多項式回歸模型過于復雜了,導致我們的虛線甚至都學習到了藍色資料點中的噪音,變得更加彎彎曲曲,雖然對于訓練資料來說,會有很好的表現即偏差較小,但會有很大的方差即對于預測測驗資料的表現很差,這即為過飽和,
如果我們的多項式回歸模型有5項
(
x
,
x
2
,
.
,
x
5
)
(x,x^2,.,x^5)
(x,x2,.,x5),那么我們的影像虛線為:
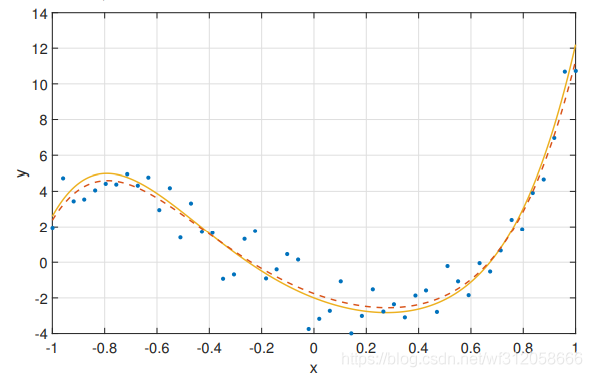
上述這張圖,很明顯就自然很多了,這樣的多項回歸模型所展示的虛線和我們的真實曲線就接近很多,由于測量的隨機性和噪音導致這兩條曲線無法完全一樣,但足夠接近,
均方預測誤差(Mean squared prediction error)
我們回顧下之前的知識點:
如果是回歸模型,那么:
E
[
Y
∣
x
1
,
.
.
.
,
x
p
]
=
f
(
x
1
,
.
.
.
,
x
p
)
E[Y|x_1,...,x_p]=f(x_1,...,x_p)
E[Y∣x1?,...,xp?]=f(x1?,...,xp?)
如果是二元分類模型,那么:
l
o
g
(
P
(
Y
=
1
∣
x
1
,
.
.
.
,
x
p
)
1
?
P
(
Y
=
1
∣
x
1
,
.
.
,
x
p
)
)
=
f
(
x
1
,
.
.
.
,
x
p
)
log(\frac{P(Y=1|x_1,...,x_p)}{1-P(Y=1|x_1,..,x_p)})=f(x_1,...,x_p)
log(1?P(Y=1∣x1?,..,xp?)P(Y=1∣x1?,...,xp?)?)=f(x1?,...,xp?)
f
(
?
)
f(·)
f(?)定義某個方程,即為真實的關于
y
,
(
x
1
,
x
2
,
.
.
.
,
x
p
)
y,(x_1,x_2,...,x_p)
y,(x1?,x2?,...,xp?)關系方程,我們很明顯是不知道這個
f
(
?
)
f(·)
f(?),我們會從總體資料中抽取樣本這里我們寫作
y
=
(
y
1
,
y
2
,
.
.
.
,
y
n
)
y=(y_1,y_2,...,y_n)
y=(y1?,y2?,...,yn?)作為我們的訓練資料,我們利用我們的訓練資料去估計
f
(
?
)
f(·)
f(?)得到我們的模型寫作
M
ˉ
(
y
)
≡
M
\bar M(y)≡M
Mˉ(y)≡M,之后,我們再從總體資料中取一組新的資料
y
′
=
(
y
1
′
,
y
2
′
,
.
.
.
,
y
m
′
)
y'=(y'_1,y'_2,...,y'_m)
y′=(y1′?,y2′?,...,ym′?)作為我們的測驗資料,那么,我們可以利用我們之前得到的模型
M
ˉ
(
y
)
≡
M
\bar M(y)≡M
Mˉ(y)≡M來做預測,得:
y
ˉ
i
(
M
ˉ
(
y
)
)
=
y
ˉ
(
x
i
,
1
′
,
x
i
,
2
′
,
.
.
.
,
x
i
,
p
′
,
M
ˉ
(
y
)
)
\bar y_i(\bar M(y))=\bar y( x'_{i,1}, x'_{i,2},..., x'_{i,p},\bar M(y))
yˉ?i?(Mˉ(y))=yˉ?(xi,1′?,xi,2′?,...,xi,p′?,Mˉ(y))
別被這公式的寫法嚇住了,這其實就是在說利用測驗資料的
(
x
i
,
1
′
,
x
i
,
2
′
,
.
.
.
,
x
i
,
p
′
)
( x'_{i,1}, x'_{i,2},..., x'_{i,p})
(xi,1′?,xi,2′?,...,xi,p′?)和我們通過訓練資料估計出的模型來預測我們的測驗資料的y值(
y
i
′
y_i'
yi′?).
還記得我們第三章內容估計的均方誤差(mean squared error,簡寫MSE)么,沒錯,一樣的操作,那么我們可以寫成:
M
S
P
E
(
M
ˉ
(
y
)
)
=
1
m
∑
i
=
1
m
(
y
i
′
?
y
ˉ
i
(
M
ˉ
(
y
)
)
)
2
MSPE(\bar M(y))=\frac{1}{m}\sum_{i=1}^{m}(y'_i-\bar y_i(\bar M(y)))^2
MSPE(Mˉ(y))=m1?i=1∑m?(yi′??yˉ?i?(Mˉ(y)))2
這就是基于我們測驗資料的均方預測誤差. 那么MSPE越小,說明我們的預測越準確,因此我們需要找一個模型具有較小的MSPE
偏差和方差
根據我們的MSPE公式,我們會發現,MSPE這個公式很依賴于我們的估計的模型,而我們的估計的模型很依賴于我們的訓練樣本,還記得我們第二章和第三章講置信區間時所說,我們一般會多次取樣,每次取樣本數為n,也就是說,MSPE很依賴于我們抽取一次樣本該樣本的具體數值,那么,為了解決這個我們MSPE公式對于抽一次樣后樣本具體數值的依賴,我們利用期望即均值對MSPE公式進行優化,那么得EMSPE(expected MSPE):
E
M
S
P
E
=
E
[
M
S
P
E
(
M
ˉ
(
y
)
)
]
=
偏
差
2
+
方
差
EMSPE=E[MSPE(\bar M(y))]=偏差^2+方差
EMSPE=E[MSPE(Mˉ(y))]=偏差2+方差
這里的期望意味著,多次取樣后的均值,也就是,多次取樣估計模型,然后分別計算MSPE,最后取均值得MSPE,這里的偏差意味著,我的預測與測驗資料的偏差,方差為關于測驗資料預測的變化程度大小,
那么我們會發現,如果要得到較小的MSPE,我們需要使偏差和方差都要比較小一些,
再次回到我們的非飽和,過飽和,利用多項式回歸模型的例子中去,如果我們多次取樣,根據我們第二章和第三章的知識,我們可以得到95%的置信區間關于我們對于訓練資料的預測,
當我們的多項式回歸模型僅僅有兩項即
(
x
,
x
2
)
(x,x^2)
(x,x2)時:
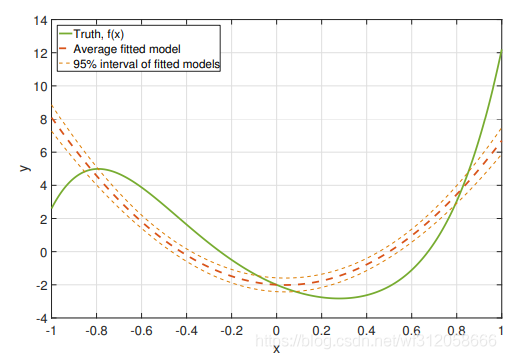
虛線為95%的置信區間預測,紅色虛線為我們根據多次取樣后分別估計得到的模型,然后進行訓練資料的預測再取均值,綠色的實線為真實的曲線,那么上圖的 EMSPE=3.33, 偏差的平方為3.27,方差為0.058. 根據我們之前的結論我們知道這是非飽和的,
當我們的多項式回歸模型有20項
(
x
,
x
2
,
.
.
,
x
2
0
)
(x,x^2,..,x^20)
(x,x2,..,x20)時:
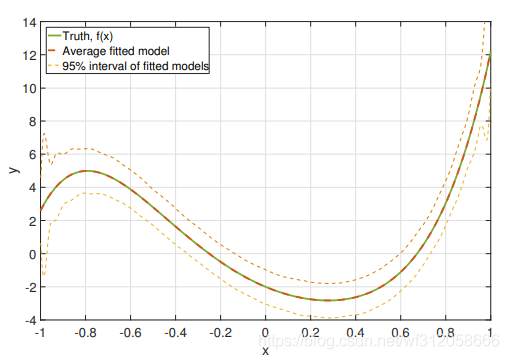
EMSPE=0.4860,偏差的平方為0,方差為0.4860.我們可以看到在曲線兩端的95%區間很明顯范圍變大了,這說明,我們的預測數值會有較大的變化,即為過飽和,
當我們的多項式回歸模型有5項
(
x
,
x
2
,
.
,
x
5
)
(x,x^2,.,x^5)
(x,x2,.,x5)時:
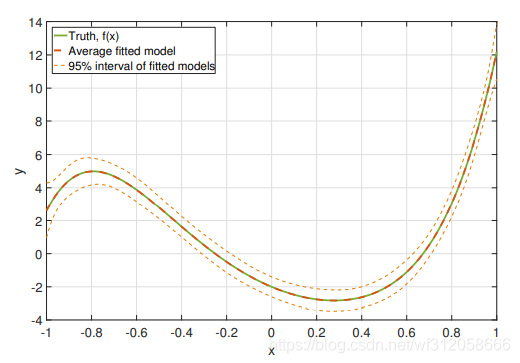
EMSPE=0.147,方差為0.147,偏差的平方為0
我們可以看到在曲線兩端的95%區間很明顯范圍還是比較窄的,這說明,我們的預測數值不會有較大的變化,
所以,總的來說:
1.模型越簡單(變數越小)會有較大的偏差,較低的方差,
2.模型越復雜(變數越多)會有較低的偏差,較高的方差,
3.方差會隨著樣本數目n的增加而減少,但偏差不會,
4.方差會隨著變數數目的增加而增加,
5.忽視一個變數會減少方差,但如果那個變數很重要則會增加偏差,
所以對于模型的變數選擇就需要我們對于偏差和方差之間做出衡量,從而選擇一個適當的模型復雜度,
假設檢驗和多次檢驗問題(hypothesis testing and multiple testing problems)
我們再次回到了小弟經常說的一個問題,如何判斷該變數是否重要,我們會用到一種方法:利用假設檢驗
H
0
:
β
j
=
0
H_0:\beta_j=0
H0?:βj?=0
H
1
:
β
j
≠
0
H_1:\beta_j≠0
H1?:βj??=0
如果p值較小,那么我們拒絕原假設,
但是,在運用中,這個方法有個潛在問題,當我們僅僅測驗一個變數,如果它的p值小于0.05我們拒絕原假設 β = 0 \beta=0 β=0,也就是說該變數與我們的預測y值無關,因為我們僅僅測驗了這一個變數,那么我們也可以認為5%的概率該變數與我們的y值預測有關,那么問題來了,如果我們有p個變數,那么我們就會做p次檢驗,從概率的角度上來看那么會有px5%個變數會和y值的預測有關,即有px5%個變數是重要的,如果我們的p很大,假如我們的p=10000,那么會有10000*5%=500個變數很重要,即使我們這10000個變數其實跟y值無關,但我們從概率的角度來看依然有500個很多的變數跟y值有關,也就是說,其實并沒有那么多的變數跟y值有關,這個問題被稱為資料疏浚(data dredging)意味著當我們在資料中尋找更多有意義的資訊的時候,會導致本來無關系的變數之間變的有關系甚至變的關系重要,但單純由于p值導致的資料疏浚我們也可以把該問題稱為"p-hacking".但歸根結底我們也知道它本身是因為大量多次檢驗導致的,
關于這個問題,有很多方法可以解決它,最常用的方法是邦費羅尼矯正(Bonferroni Procedure).關于它的由來和更深的原理,小弟也不知道,我們這里只學習他如何解決由于p值導致的資料疏浚問題,
也很簡單,舉個例子就明白了,如果我們要做p次檢驗,那么邦費羅尼這個大哥告訴我們,只有當:
P
值
<
α
p
P值<\frac{\alpha}{p}
P值<pα?
時,我們才要拒絕原假設,這里的
α
=
0.05
\alpha=0.05
α=0.05,
似然和資訊準則
如何判斷該變數是否重要,我們會用到另外一種方法:似然和資訊準則
小弟在第6章已經簡單分享了該方面知識,現在帶大家重新回顧一下,
我們經常用負log似然來估計模型的引數,從而使得我們的負log似然的值為最小值:
L
(
y
∣
θ
ˉ
)
=
?
∑
i
=
1
n
l
o
g
(
p
(
y
i
∣
θ
ˉ
)
)
L(y|\bar \theta)=-\sum_{i=1}^{n}log(p(y_i|\bar \theta))
L(y∣θˉ)=?i=1∑n?log(p(yi?∣θˉ))
然后在給負log似然加上不同的懲罰方程形成我們的資訊準則,我們可以通過選取不同的變數搭配使我們的資訊準則為最小值,這樣該不同的變數搭配即為我們認為的重要變數,
我們先了解下寫法:
M
M
M意味著模型,
M
ˉ
\bar M
Mˉ意味著通過資料估計出模型引數后的模型,即該模型可以詮釋我們的資料,
L
(
y
∣
M
ˉ
)
L(y|\bar M)
L(y∣Mˉ) 為最小負log似然值,也就是我們把我們估計后引數帶入負log似然公式中而已,
k
M
k_M
kM?意味著變數的個數
那么有這么幾種常用的資訊準則
1.赤池資訊準則(AIC)
A
I
C
(
M
ˉ
)
=
L
(
y
∣
M
ˉ
)
+
k
M
AIC(\bar M)=L(y|\bar M)+k_M
AIC(Mˉ)=L(y∣Mˉ)+kM?
2.庫爾貝克資訊準則(Kullback-Leibler information criterion. KIC)
庫爾貝克這個大哥跟費雪大哥的名氣是一個級別的,我們后續會學更多關于他的理論知識,
K
I
C
(
M
ˉ
)
=
L
(
y
∣
M
ˉ
)
+
3
2
k
M
KIC(\bar M)=L(y|\bar M)+\frac{3}{2}k_M
KIC(Mˉ)=L(y∣Mˉ)+23?kM?
當n很大時,AIC和KIC都很容易使我們最后的模型過飽和,但很不幸,到目前為止,沒有一個特別嚴謹的方法可以中和過飽和,當我們訓練的資料n過多使我們的引數更加精準,很容易過飽和,減少偏差,但是在運用時,KIC比AIC 表現更好點,因為KIC 可以減少一些過飽和的程度,
3.貝葉斯資訊準則(BIC)
B
I
C
(
M
ˉ
)
=
L
(
y
∣
M
ˉ
)
+
k
M
2
l
o
g
n
BIC(\bar M)=L(y|\bar M)+\frac{k_M}{2}log n
BIC(Mˉ)=L(y∣Mˉ)+2kM??logn
當我們的訓練資料n增加,BIC 過飽和的概率會趨近于0.相反,當n很小,BIC會使得我們的模型非過飽和,所以我們一般會利用AIC 和BIC 來中和我們的模型,一會算算看AIC 一會算算看BIC,這樣時我們的模型既不過飽和,也不非過飽和,當我們算的AIC和BIC之間差>=3,那么我們認為這個模型正好,
4.風險膨脹資訊準則(Risk inflation information criterion. RIC)
R
I
C
(
M
ˉ
)
=
L
(
y
∣
M
ˉ
)
+
k
M
l
o
g
p
RIC(\bar M)=L(y|\bar M)+k_M log p
RIC(Mˉ)=L(y∣Mˉ)+kM?logp
p
p
p意味著我們認為可能的變數個數,RIC這個方法本質和多次檢驗方法類似,當我們常識過多的變數個數時,我們要盡量避免過飽和,當p值很大,通常我們會用RIC.
我們在利用我們之前多項式模型的例子,來畫張圖,如下:
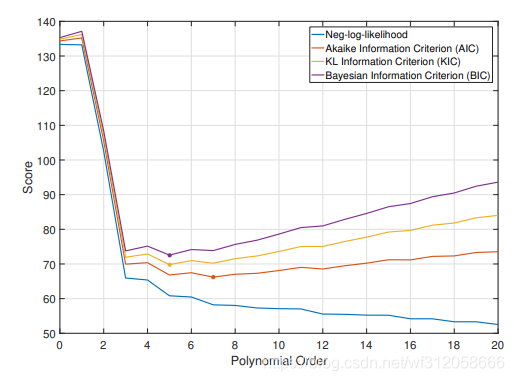
該圖的y軸為我們的資訊準則數值,x軸代表多項式的項數,從該圖中我們會發現,如果用AIC的話,我們的多項式模型的項達到7項,相比其他資訊準則,更加過飽和些,
交叉驗證(Cross validation. CV)
交叉驗證是一個很普遍的方法,它可以控制我們模型的復雜度,
根據小弟在本章最早提到,我們選擇我們的模型通過減小預測值和測驗資料里測驗資料里的真值(
y
1
′
,
y
2
′
,
.
.
,
y
m
′
y'_1,y'_2,..,y'_m
y1′?,y2′?,..,ym′?)進行比較,從而選擇適合的模型,
M
S
P
E
(
M
ˉ
(
y
)
)
=
1
m
∑
i
=
1
m
(
y
i
′
?
y
ˉ
i
(
M
ˉ
(
y
)
)
)
2
MSPE(\bar M(y))=\frac{1}{m}\sum_{i=1}^{m}(y'_i-\bar y_i(\bar M(y)))^2
MSPE(Mˉ(y))=m1?i=1∑m?(yi′??yˉ?i?(Mˉ(y)))2
但計算MSPE會有一個小小的問題,那就抽取測驗資料,小弟在本章講MSPE的時候說的很輕松抽取一組樣本資料作為測驗資料,但這組測驗資料不僅要提前準備好,而且和訓練資料不能有相同,不僅如此,訓練資料和測驗資料的資料分布也要相同,這樣的話如果我們從總體中要抽取訓練資料,那么無疑困難是很大的,
在交叉驗證這個方法中,我們可以抽取樣本,并將樣本分為兩部分,第一部分為訓練資料,用來估計出引數,得到我們的模型,第二部分為測驗資料用來看我們的模型對于未來資料預測的表現,從而選取適當的模型,
交叉驗證法邏輯:
1.取樣資料y,并分為兩個部分:
-訓練集
y
t
r
a
i
n
y_{train}
ytrain?
-測驗集
y
t
e
s
t
y_{test}
ytest?
2.利用
y
t
r
a
i
n
y_{train}
ytrain?估計出引數,得到我們的模型
M
M
M
3.計算
M
S
P
E
MSPE
MSPE,根據
y
t
e
s
t
y_{test}
ytest?
4.反復這個流程多次(盡可能的多),計算
M
S
P
E
MSPE
MSPE均值,即
E
M
S
P
E
EMSPE
EMSPE,只不過這里我們不愛叫它
E
M
S
P
E
EMSPE
EMSPE而叫它“CV error”,那么我們變可以知道我們的模型對于未來預測資料的表現情況,CV error越小,模型對于預測未來資料的表現越好,另外注意點是,在第4步中,我們盡可能多來幾次,計算MSPE均值,為了避免隨機抽樣后導致MSPE的變化,從而使我們的CV error變的更低,
另外這里有兩種交叉驗證法CV的變種:
第一種: K-fold CV (KF CV)
將樣本均分為K份,訓練集為K-1份,剩下的一份作為測驗集,然后一樣反復流程,最后求均值MSPE,
第二種: Leave-one-out CV(LOO CV)
如果我們的樣本資料有n個,n-1個資料作為訓練集,剩下的那一個資料作為測驗集,然后一樣反復流程,最后求均值MSPE,
看到這里,可能大家會發現一個問題,那就是小弟在第6章選擇模型內容中所提到的,如果我們有p個變數,那么一共有 2 p 2^p 2p種組合,對沒錯,都嘗試一次,根據多次假設檢驗也好,根據資訊準則也罷,根據CV也行,這些計算量無論哪一種方法大家可想而知是很大的,令一個問題那就是,如果我們的訓練樣本的資料有少許變化,那么我們最終的結果會有很大不同,這也是這些傳統選擇模型方法的不足,即為統計的不穩定性(Statistical Instability),
二. 懲罰回歸(Penalized Regression)
到目前為止,我們學到了回歸模型中的簡單線性模型,和多元線性模型,以及多項式回歸模型,和關于分類模型里的二元邏輯分類模型,現在小弟再簡單的介紹下懲罰回歸模型里的一些著名的模型,
懲罰回歸其實是,針對于我們估計引數的懲罰,再將我們懲罰后的估計出的引數放入我們原有的回歸模型中去罷了,對于估計引數的懲罰一般會寫成:
(
β
ˉ
0
,
β
ˉ
)
=
a
r
g
m
i
n
β
0
,
β
{
R
S
S
(
β
0
,
β
)
+
λ
∑
j
=
1
p
g
(
β
j
)
}
(\bar \beta_0,\bar \beta)=arg min_{\beta_0,\beta}\{RSS(\beta_0,\beta)+\lambda \sum_{j=1}^{p}g(\beta_j)\}
(βˉ?0?,βˉ?)=argminβ0?,β?{RSS(β0?,β)+λj=1∑p?g(βj?)}
上述公式里的 R S S ( ? ) RSS(·) RSS(?)為擬合優度,例如我們在線性模型里用的最小二乘法,在二元邏輯回歸里用的似然,其實就是我們正常情況下估計引數的方法,然后加上懲罰方程 g ( ? ) g(·) g(?)
現在我們來理解下這個懲罰方程,一般情況下 ∣ β j ∣ |\beta_j| ∣βj?∣越大,我們對它的懲罰越大,為什么?因為如果一個引數的值越大那么它對我們的模型和預測會有很大的影響,如果引數值很小那么對于預測變數會有較小的影響,但懲罰方程它想做的就是鼓勵較小的引數值,懲罰較大的引數值,這樣做的話會使減少模型的過飽和幾率,對沒錯,可能有的同學發現了,那么其實它無疑是增加了偏差,從而減小了方差,所以懲罰回歸犧牲了偏差,從而增加了對于未來預測資料的穩定性,這里我們會注意到,懲罰一般是不會懲罰 β 0 \beta_0 β0?的,因為 β 0 \beta_0 β0?的數值其實由我們的預測變數y的單位所決定的,例如如果我們的y是米,那么 β 0 \beta_0 β0?可能以1來計算,如果y是厘米,那么 β 0 \beta_0 β0?可能以100來計算,
說到單位,現在我們出現了個很頭疼的問題那就是變數的范圍,例如有的變數資料在(0-100)的范圍內,但有的資料在(0-1)范圍內,那么我們需要先對資料進行標準化即資料標準化(data standardise),使變數滿足:
∑
i
=
1
n
x
i
,
j
=
0
\sum_{i=1}^{n}x_{i,j}=0
i=1∑n?xi,j?=0
∑
i
=
1
n
x
i
,
j
2
=
n
\sum_{i=1}^{n}x^2_{i,j}=n
i=1∑n?xi,j2?=n
使我們的變數資料均滿足上述兩個公式,其實也很容易做到,只要減去均值除以標準差即可,但為什么非要以該形式進行標準化呢?因為這樣有利于我們之后對于資料的運算,例如估計引數,例如尋找重要的變數等等,
回歸正題
(
β
ˉ
0
,
β
ˉ
)
=
a
r
g
m
i
n
β
0
,
β
{
R
S
S
(
β
0
,
β
)
+
λ
∑
j
=
1
p
g
(
β
j
)
}
(\bar \beta_0,\bar \beta)=arg min_{\beta_0,\beta}\{RSS(\beta_0,\beta)+\lambda \sum_{j=1}^{p}g(\beta_j)\}
(βˉ?0?,βˉ?)=argminβ0?,β?{RSS(β0?,β)+λj=1∑p?g(βj?)}
上述公式的
λ
\lambda
λ即為懲罰的力度,它最為人所知的名稱叫為超引數(hyperparameter).
例如我們的線性回歸,如果
λ
=
0
\lambda=0
λ=0,那我們的懲罰回歸就是最小二乘法,懲罰回歸有個好處就是在選擇模型當中,它解決了統計的不穩定性,訓練資料的小變化,使我們的最后結果也是很小的變化,
看到這里,想必大家對懲罰回歸有了初步的了解,小弟在此簡單的介紹兩個用的最多的懲罰回歸模型,
1.嶺回歸(Ridge regression)
(
β
ˉ
0
,
β
ˉ
)
=
a
r
g
m
i
n
β
0
,
β
{
R
S
S
(
β
0
,
β
)
+
λ
∑
j
=
1
p
β
j
2
}
(\bar \beta_0,\bar \beta)=arg min_{\beta_0,\beta}\{RSS(\beta_0,\beta)+\lambda \sum_{j=1}^{p}\beta_j^2\}
(βˉ?0?,βˉ?)=argminβ0?,β?{RSS(β0?,β)+λj=1∑p?βj2?}
嶺回歸的優點: 第一對于大量的樣本數目n,和大量的變數,它都算的很快,第二當很多變數之間有很大關聯時,它的方差會很低,但無論
λ
\lambda
λ為多少時,即
λ
<
∞
\lambda <∞
λ<∞,對于引數的估計不會等于0,但會收斂于0
2.拉索回歸(lasso regression)
(
β
ˉ
0
,
β
ˉ
)
=
a
r
g
m
i
n
β
0
,
β
{
R
S
S
(
β
0
,
β
)
+
λ
∑
j
=
1
p
∣
β
j
∣
}
(\bar \beta_0,\bar \beta)=arg min_{\beta_0,\beta}\{RSS(\beta_0,\beta)+\lambda \sum_{j=1}^{p}|\beta_j |\}
(βˉ?0?,βˉ?)=argminβ0?,β?{RSS(β0?,β)+λj=1∑p?∣βj?∣}
相比嶺回歸,對于引數的估計是會等于0的,
那么如何選擇適合的懲罰力度
λ
\lambda
λ呢?
最常用的方法是利用CV來選擇
λ
\lambda
λ,根據預測的值和測驗資料的真值差的多不多即CV error,
1.我們定我們的
λ
\lambda
λ屬于0(無懲罰)到一個很大的值(較大懲罰)
2.對于每個
λ
\lambda
λ我們都嘗試一次,利用CV來計算估計預測誤差,
3.選擇一個較小CV error的
λ
\lambda
λ
4.利用該
λ
\lambda
λ來估計我們的模型引數
如果用MATLAB的同學,我們會用到lasso()和lassoglm()這兩個公式,如果是用R的同學,我們需要用glmnet
懲罰回歸的偏差和方差
根據:
E
M
S
P
E
=
E
[
M
S
P
E
(
M
ˉ
(
y
)
)
]
=
偏
差
2
+
方
差
EMSPE=E[MSPE(\bar M(y))]=偏差^2+方差
EMSPE=E[MSPE(Mˉ(y))]=偏差2+方差
我們的懲罰回歸會降低方差,即提升對于未來資料預測的穩定性,但降低了偏差準確度,因為懲罰回歸會將估計的引數逐漸向0收斂,懲罰力度越大,引數估計會趨向于0.對于本身引數值較小的,懲罰力度會小,對于引數值較大的,懲罰力度會大,根據這個特點估計出來的引數也被稱為收縮估計(shrinkage estimate), 但拉索的懲罰可以將引數估計為0,所以根據拉索的懲罰回歸估計出的引數也被稱為稀疏估計(Sparse estimate).
最后來兩張圖大家就明白了
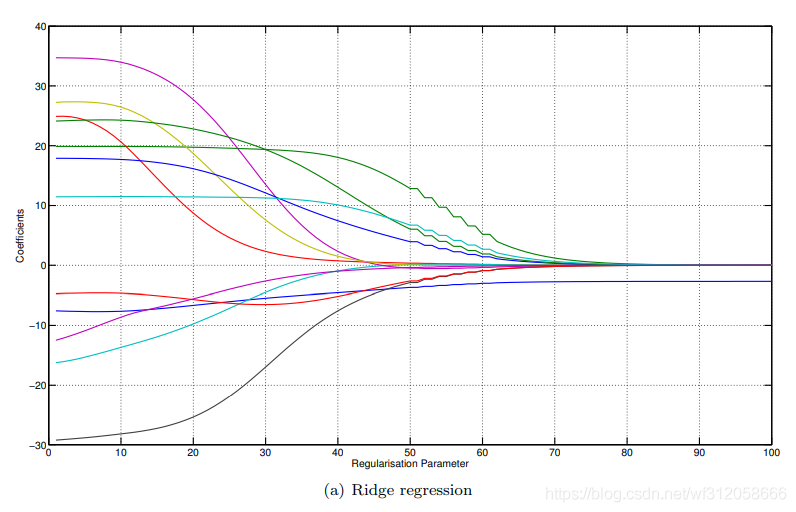
嶺回歸:
拉索回歸:
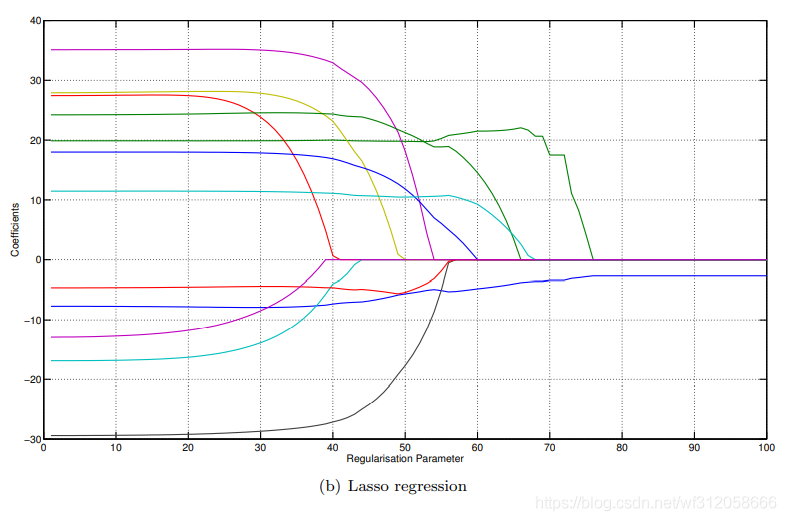
x軸即為我們的
λ
\lambda
λ懲罰力度,y軸為引數估計的具體數值,
無論是嶺回歸還是拉索回歸,我們可以看到藍線(y軸0下面的藍線)幾乎沒有受到什么懲罰,因為它是
β
0
\beta_0
β0?,其次我們可以看到,隨著懲罰力度的增加,拉索估計出的引數可以為0,但嶺回歸是逐漸向0收斂,另外我們也可以看到無論是哪種懲罰回歸,引數的絕對值越大,懲罰力度越大,弧線更狠,但對于初始絕對值很小的引數隨著懲罰力度增加,它受到的懲罰不是很大,弧線很平緩,
三. 結語
有公式推導錯誤的或理論有謬誤的,請大家指出,我好及時更正,感謝,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/257766.html
標籤:其他