文章目錄
- 背景
- 常見方案
- 一、Hash取模
- 二、一致性Hash演算法
- 三、虛擬節點
- 思考題
- 參考
背景
隨著資料量的不斷增長,單個資料庫已經無法支撐現有的業務時,就需要引入分布式存盤,比如MySQL分庫分表、Redis Cluster 集群,
引入分布式存盤時,不得不面臨一個問題:如何保證資料盡可能均勻分布到各個節點上,并且盡量在增減節點時較小范圍對現有資料的影響,
以下以集群快取服務器為案例分析,分析如何實作資料均勻分布的,
常見方案
一、Hash取模
1.1 描述
根據 key 進行 Hash,然后取模分配到N個節點,則可以通過 Hash(key) % N 計算出存放的節點,
1.2 優點
可以實作資料均衡分布,簡單易懂,
1.3 缺點
當有節點增加或者洗掉時,會造成大量資料失效,因此容錯性和擴展性都比較差,
下面以3個節點減到2個節點為例子,計算一下失效率:

圖中6個key,標記紅色為失效的有4個,失效率=66.7%
二、一致性Hash演算法
2.1 描述
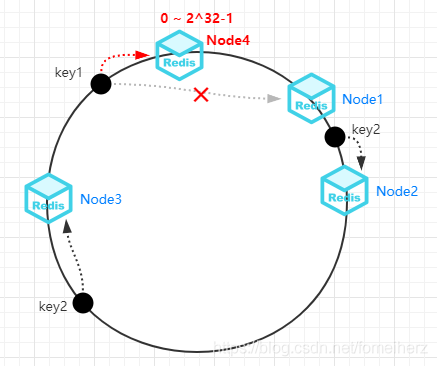
首先,構建一個一致性 Hash 環的結構,一致性 Hash 環的大小是 0 到 2^32-1 ,
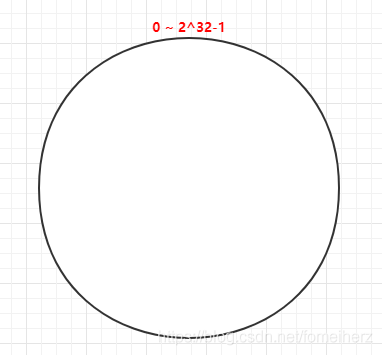
然后,將快取服務器的節點(如 IP 地址或 hostname)經過 Hash 演算法后散列到這個環上,
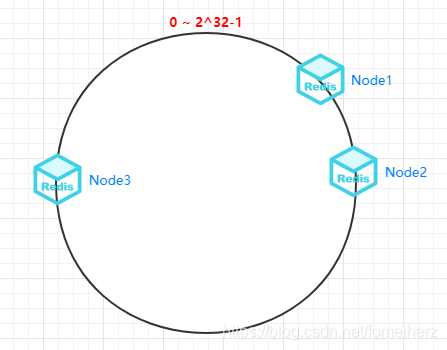
如有3個節點時,分布情況如下圖所示:
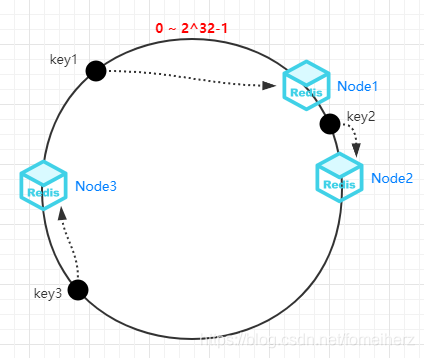
有3個key需要存盤到快取集群時,分別計算 Hash 后映射到這個環上,
然后,按照順時針方向把 key1 定位到 Node1,key2 定位到 Node2,key3 定位到 Node3,
2.2 優點
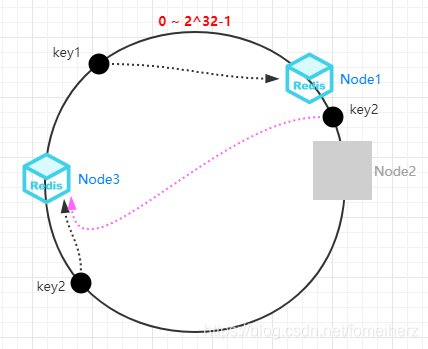
2.2.1 容錯性
當 Node2 宕機之后,key2 被重新定位到 Node3 節點上,此時只會影響 Node1 和 Node2 之間的資料,很好實作了容錯,
2.2.2 擴展性
當快取集群需要擴展一個 Node4 節點時,key1 被重新定位到 Node4 節點上,此時只會影響 Node3 和 Node4 之間的資料,很好實作了可擴展性,
2.3 缺點
仔細看剛剛圖可以發現,節點之間的分布并不均勻,Node1 和 Node2 距離較近,分布較少的資料;而 Node2 和 Node3 距離較遠,分布了較多的資料,
三、虛擬節點
為了解決一致性 Hash 出現的分布不均勻的問題,引入 虛擬節點 來解決該問題,
將每臺集群節點虛擬為一組節點,如圖中每個節點虛擬出2個節點(實際應用中可能有很多),將虛擬服務器的 Hash 值放置在 Hash 環上,
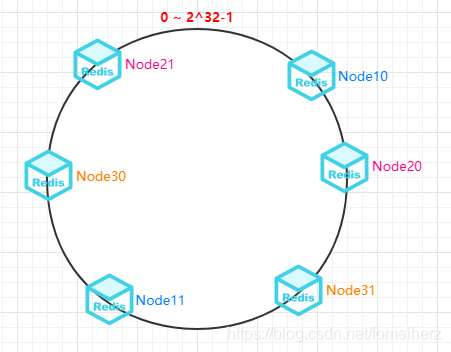
當有一個 key 需要存盤到快取集群時,先找到虛擬節點,再得到物理服務器資訊,
假如有新節點加入時,也按相同規則分配時,即可保證資料的均勻分布,
思考題
資料庫在做分庫分表,如何能做到在增加分表數時,盡可能少遷移資料呢?
參考
深入解讀快取(二)——一致性Hash演算法
一致性 Hash 演算法分析
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/257768.html
標籤:其他
上一篇:proto3檔案定義Demo-用戶表單條、多條、所有、編輯
下一篇:五個吊炸天的網站