selenium+requests+bs4模塊–簡單爬蟲實體–網易云音樂篇
文章目錄
- section1: 宣告
- section2 :下載鏈接分析
- section3:代碼撰寫
- 1、導包
- 2、構建請求頭
- 3、創建檔案夾
- 4、實作頁面無可視化
- 5、構建獲取音樂ID的函式
- 6、構建獲取音樂name的函式
- 7、構建獲取歌手name的函式
- 8、構建下載音樂的函式
- 9、構建主函式
- 10、完整代碼
- section4:參考博文及學習鏈接
- 1、chromedriver與chrome版本映射表及下載地址
- 2、selenium安裝
- 3、Selenium的視頻講解
- 4、思路參考
- section5:代碼不足(說明)
section1: 宣告
1、只支持能在網易云音樂平臺在線播放的音樂!!!
對于音樂人,我們要支持他們,支持正版著作權!!!
2、因為是學習筆記,所以只下載搜到的歌曲串列的第一首音樂,需要下載更多的,可以自行修改一下代碼,
3、本文如有侵權,請聯系我洗掉文章!!!
section2 :下載鏈接分析
網易云在線播放每首歌曲時,都有一個外鏈地址,這是不會變的,跟每首歌的唯一一個id系結在一起,而每首歌audio檔案的URL如下:
url = 'http://music.163.com/song/media/outer/url?id=' + 歌曲的id值 + '.mp3'
那么id是什么呢?id應該怎么獲取呢?
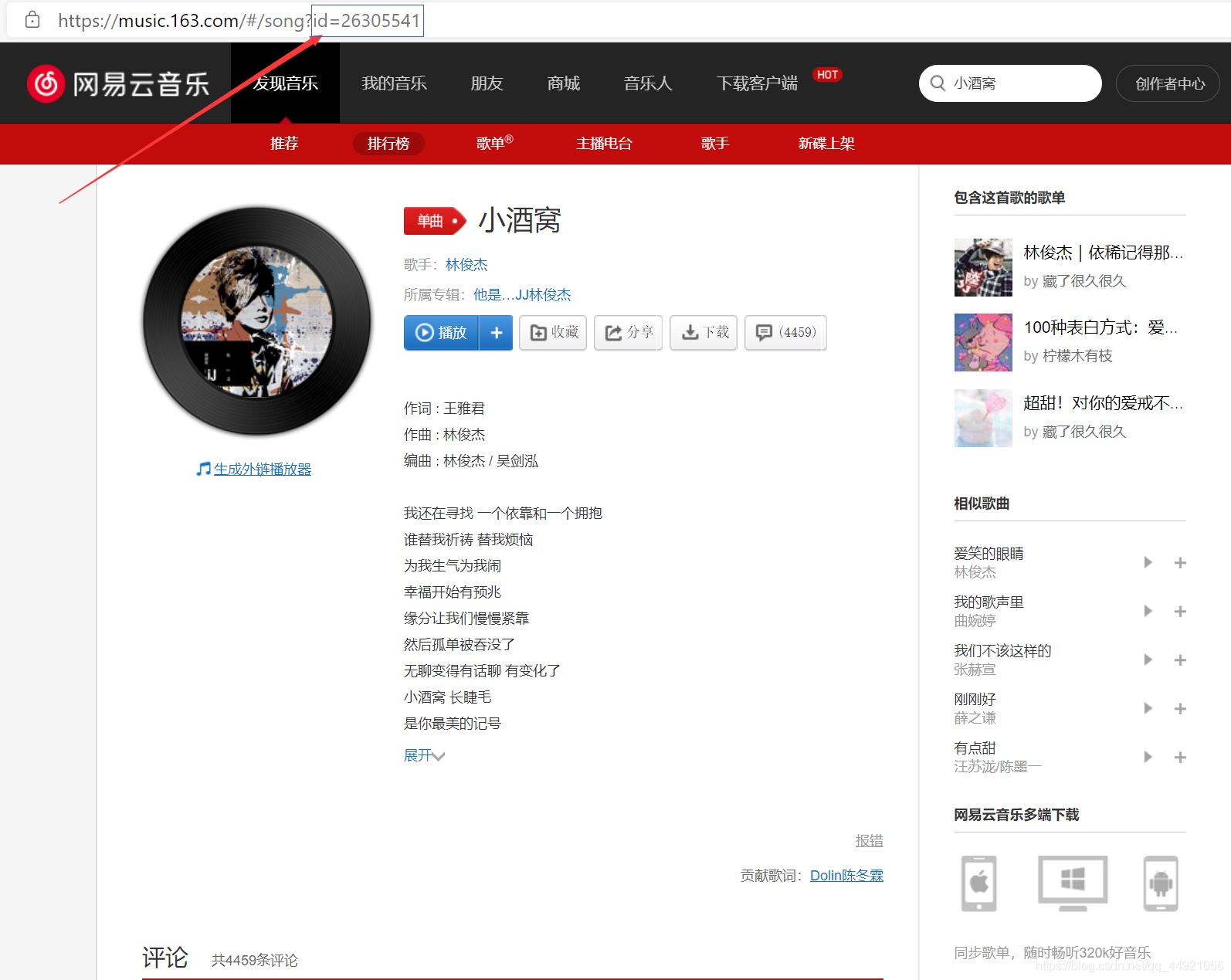
其實很簡單,當你在網易云打開一個音樂時,就能很明顯地發現:(本文以《小酒窩》為例)
Q:那怎么獲取不同音樂的id呢?
A:換首歌即可呀,
Q:那獲取每首歌的這個頁面有什么規律可循嘛?
A:當然!
請看:
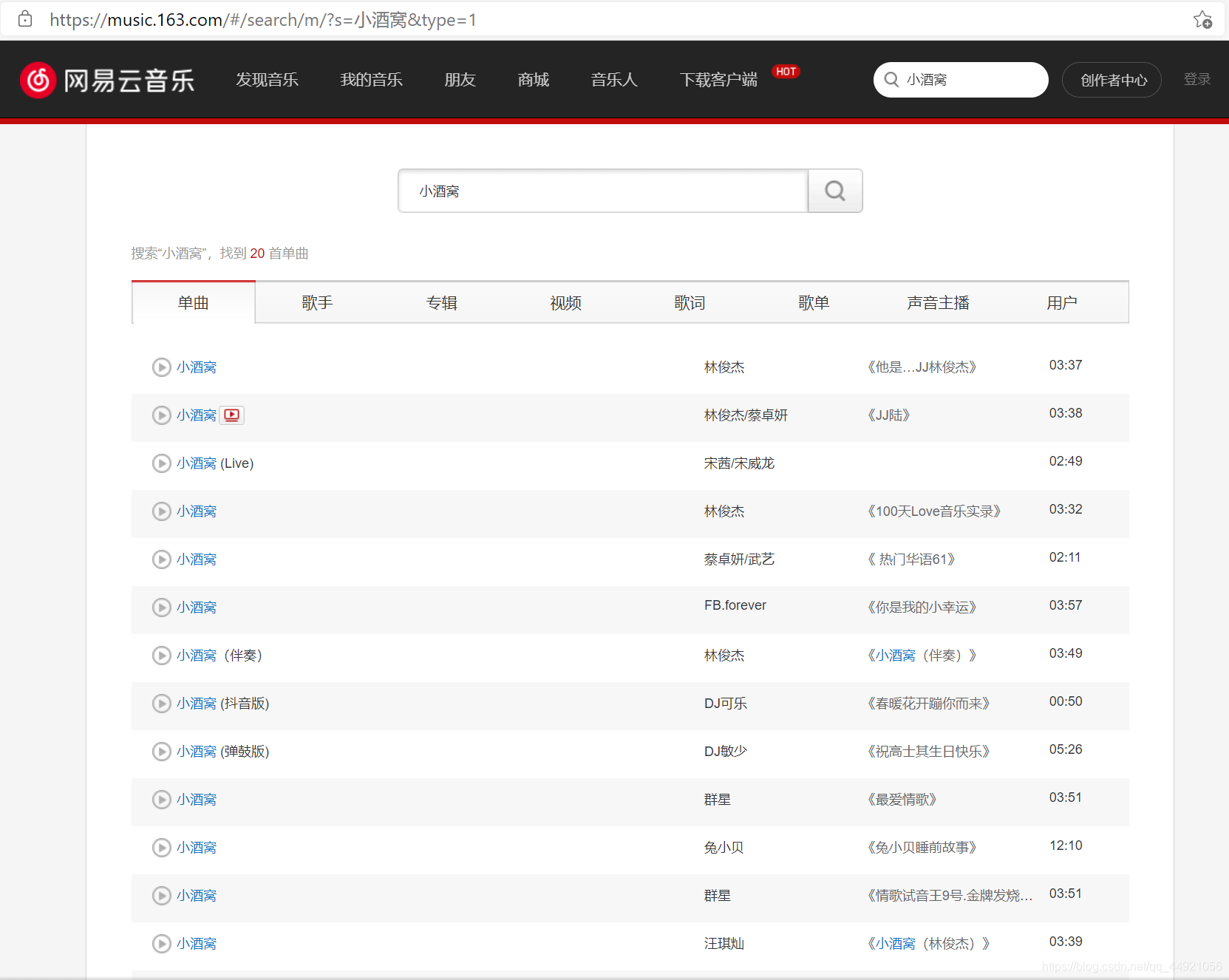
這是根據歌曲名搜索得到的頁面,我們搜幾首不同的歌,看看變化,
《小酒窩》

《用心良苦》

《Scarborough Fair》

通過這三個例子,我們就能提取出一個通用的URL模板:
url='https://music.163.com/#/search/m/?s= ' + 歌曲的名字 + ' &type=1'
這樣,我們就可以通過一個歌曲的名字獲取到一個頁面,在這個頁面能獲取歌曲的ID,然后通過ID和之前的一個URL模板組合起來,就能得到一個全新的URL,
以《小酒窩》為例,得到一個URL:
http://music.163.com/song/media/outer/url?id=26305541.mp3
訪問這個URL,出現這個頁面,就是我們想要得到的外鏈

接著對這個頁面進行分析
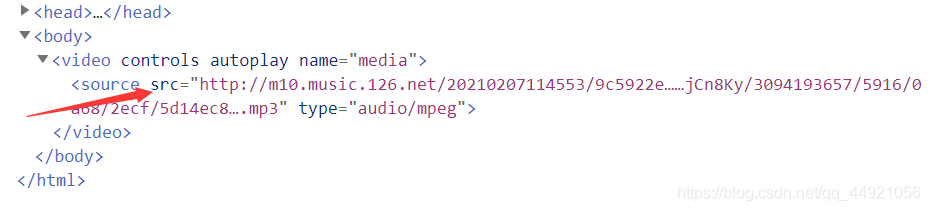
這里面的內容就是我們想要得到的,最終的下載鏈接!
section3:代碼撰寫
1、導包
import requests
import os
import bs4
from selenium import webdriver
from time import sleep
from selenium.webdriver.chrome.options import Options
2、構建請求頭
headers = {
'user - agent': 'Mozilla / 5.0(WindowsNT10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 80.0.3987.116Safari / 537.36'
}
3、創建檔案夾
#創建檔案夾
if not os.path.exists('D:/網易云音樂'):
os.mkdir('D:/網易云音樂')
4、實作頁面無可視化
# 實作無可視化界面(固定寫法)
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
5、構建獲取音樂ID的函式
#獲取音樂id
def get_music_ids(url):
# 初始化browser物件
browser = webdriver.Chrome(executable_path='chromedriver.exe', chrome_options=chrome_options)
# 訪問該url
browser.get(url=url)
# 由于網頁中有iframe框架,進行切換
browser.switch_to.frame('g_iframe')
# 等待0.5秒
sleep(0.5)
# 抓取到頁面資訊
page_text = browser.execute_script("return document.documentElement.outerHTML")
# 退出瀏覽器
browser.quit()
# 提取音樂的id,名字,歌手名
soup = bs4.BeautifulSoup(page_text, 'html.parser')
music_ids = soup.select("div[class='td w0'] a") # 音樂id
music_id = music_ids[0].get("href")
music_id = music_id.split('=')[-1]
return music_id
6、構建獲取音樂name的函式
#獲取音樂名稱
def get_music_names(url):
browser = webdriver.Chrome(executable_path='chromedriver.exe', chrome_options=chrome_options)
browser.get(url=url)
browser.switch_to.frame('g_iframe')
sleep(0.5)
page_text = browser.execute_script("return document.documentElement.outerHTML")
browser.quit()
soup = bs4.BeautifulSoup(page_text, 'html.parser')
music_names = soup.select("div[class='td w0'] a b") # 音樂名字
music_name=music_names[0].get("title")
return music_name
7、構建獲取歌手name的函式
#獲取歌手名稱
def get_music_singers(url):
browser = webdriver.Chrome(executable_path='chromedriver.exe', chrome_options=chrome_options)
browser.get(url=url)
browser.switch_to.frame('g_iframe')
sleep(0.5)
page_text = browser.execute_script("return document.documentElement.outerHTML")
browser.quit()
soup = bs4.BeautifulSoup(page_text, 'html.parser')
music_singers = soup.select("div[class='td w1'] a")
music_singer=music_singers[0].string
return music_singer
8、構建下載音樂的函式
#下載音樂
def download_music(url,name,singer):
response=requests.get(url=url,headers=headers)
music_data=response.content
music_path_name='{}_{}.mp3'.format(name,singer)
music_path='D:/網易云音樂/'+music_path_name
with open(music_path,'wb') as f:
f.write(music_data)
print(music_path_name,'下載成功')
9、構建主函式
#主函式
def main():
name = input('請輸入歌名:')
url = 'https://music.163.com/#/search/m/?s=' + name + '&type=1'
music_name=get_music_names(url)
musice_singer=get_music_singers(url)
music_id=get_music_ids(url)
music_url= 'http://music.163.com/song/media/outer/url?id=' + music_id + '.mp3'
browser = webdriver.Chrome(executable_path='chromedriver.exe', chrome_options=chrome_options)
browser.get(url=music_url)
sleep(0.5)
page_text = browser.execute_script("return document.documentElement.outerHTML")
browser.quit()
soup = bs4.BeautifulSoup(page_text, 'html.parser')
music_source=soup.select("video source")
source_url=music_source[0].get('src')
download_music(source_url,music_name,musice_singer)
10、完整代碼
import requests
import os
import bs4
from selenium import webdriver
from time import sleep
from selenium.webdriver.chrome.options import Options
headers = {
'user - agent': 'Mozilla / 5.0(WindowsNT10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 80.0.3987.116Safari / 537.36'
}
#創建檔案夾
if not os.path.exists('D:/網易云音樂'):
os.mkdir('D:/網易云音樂')
# 實作無可視化界面(固定寫法)
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
#獲取音樂id
def get_music_ids(url):
# 初始化browser物件
browser = webdriver.Chrome(executable_path='chromedriver.exe', chrome_options=chrome_options)
# 訪問該url
browser.get(url=url)
# 由于網頁中有iframe框架,進行切換
browser.switch_to.frame('g_iframe')
# 等待0.5秒
sleep(0.5)
# 抓取到頁面資訊
page_text = browser.execute_script("return document.documentElement.outerHTML")
# 退出瀏覽器
browser.quit()
# 提取音樂的id,名字,歌手名
soup = bs4.BeautifulSoup(page_text, 'html.parser')
music_ids = soup.select("div[class='td w0'] a") # 音樂id
music_id = music_ids[0].get("href")
music_id = music_id.split('=')[-1]
return music_id
#獲取音樂名稱
def get_music_names(url):
browser = webdriver.Chrome(executable_path='chromedriver.exe', chrome_options=chrome_options)
browser.get(url=url)
browser.switch_to.frame('g_iframe')
sleep(0.5)
page_text = browser.execute_script("return document.documentElement.outerHTML")
browser.quit()
soup = bs4.BeautifulSoup(page_text, 'html.parser')
music_names = soup.select("div[class='td w0'] a b") # 音樂名字
music_name=music_names[0].get("title")
return music_name
#獲取歌手名稱
def get_music_singers(url):
browser = webdriver.Chrome(executable_path='chromedriver.exe', chrome_options=chrome_options)
browser.get(url=url)
browser.switch_to.frame('g_iframe')
sleep(0.5)
page_text = browser.execute_script("return document.documentElement.outerHTML")
browser.quit()
soup = bs4.BeautifulSoup(page_text, 'html.parser')
music_singers = soup.select("div[class='td w1'] a")
music_singer=music_singers[0].string
return music_singer
#下載音樂
def download_music(url,name,singer):
response=requests.get(url=url,headers=headers)
music_data=response.content
music_path_name='{}_{}.mp3'.format(name,singer)
music_path='D:/網易云音樂/'+music_path_name
with open(music_path,'wb') as f:
f.write(music_data)
print(music_path_name,'下載成功')
#主函式
def main():
name = input('請輸入歌名:')
url = 'https://music.163.com/#/search/m/?s=' + name + '&type=1'
music_name=get_music_names(url)
musice_singer=get_music_singers(url)
music_id=get_music_ids(url)
music_url= 'http://music.163.com/song/media/outer/url?id=' + music_id + '.mp3'
browser = webdriver.Chrome(executable_path='chromedriver.exe', chrome_options=chrome_options)
browser.get(url=music_url)
sleep(0.5)
page_text = browser.execute_script("return document.documentElement.outerHTML")
browser.quit()
soup = bs4.BeautifulSoup(page_text, 'html.parser')
music_source=soup.select("video source")
source_url=music_source[0].get('src')
download_music(source_url,music_name,musice_singer)
if __name__ =='__main__' :
main()
section4:參考博文及學習鏈接
1、chromedriver與chrome版本映射表及下載地址
參考博文1:點擊此處獲取
2、selenium安裝
參考博文2:點擊此處獲取
3、Selenium的視頻講解
參考B站視頻:點擊此處獲取
4、思路參考
參考博文3:點擊此處獲取
(我是看了這個博主的文章,才有的明確思路)
section5:代碼不足(說明)
因為是學習筆記的原因,我并沒有準備爬取太多,但仍然存在一點小問題,因為打開音樂外鏈時,音樂會自動播放,所以使用selenium打開音樂外鏈,也會有這個問題,因此,在下載音樂的程序中,會聽到音樂聲,
而以我現在的能力,我能想到的是,使用
browser.find_element_by_xpath('這里填暫停播放按鈕的xpath').click()
但是這種方法我沒試過,想嘗試的小伙伴可以試一下,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/257770.html
標籤:其他
上一篇:五個吊炸天的網站
下一篇:前端開發當中常用的正則運算式