MVS重建:根據輸出表示,MVS方法可以分為
1)直接點云重建:基于點云的方法直接對三維點進行操作,通常依靠傳播策略逐步強化重構,由于點云的傳播是順序進行的,這些方法很難完全并行化,通常需要較長的處理時間,
2)體積重建:基于體積的方法將三維空間劃分為規則網格,然后估計每個體素是否附著在表面上,這種表示的缺點是空間離散化誤差和高記憶體消耗,
3)深度圖重建:深度映射是其中最靈活的表示方式,它將復雜的MVS問題解耦為每個視圖深度地圖估計的小問題,每次只關注一個參考影像和幾個源影像,此外,深度地圖可以很容易地融合到點云或體積重建,目前最好的MVS演算法都是基于深度映射的方法,
論文簡介:
一個端到端的深度學習架構,用于從多視圖影像進行深度映射推斷,在該網路中,首先提取深度視覺影像特征,然后通過可微分單應性翹曲在參考攝像機截錐上建立三維代價體,
MVSNet:MVSNet是一種監督學習的方法,以一個參考影像和多張原始影像為輸入,而得到參考影像深度圖的一種端到端的深度學習框架,網路首先提取影像的深度特征,然后通過可微分投影變換構造3D的代價體,再通過正則化輸出一個3D的概率體,再通過soft argMin層,沿深度方向求取深度期望,獲得參考影像的深度圖,
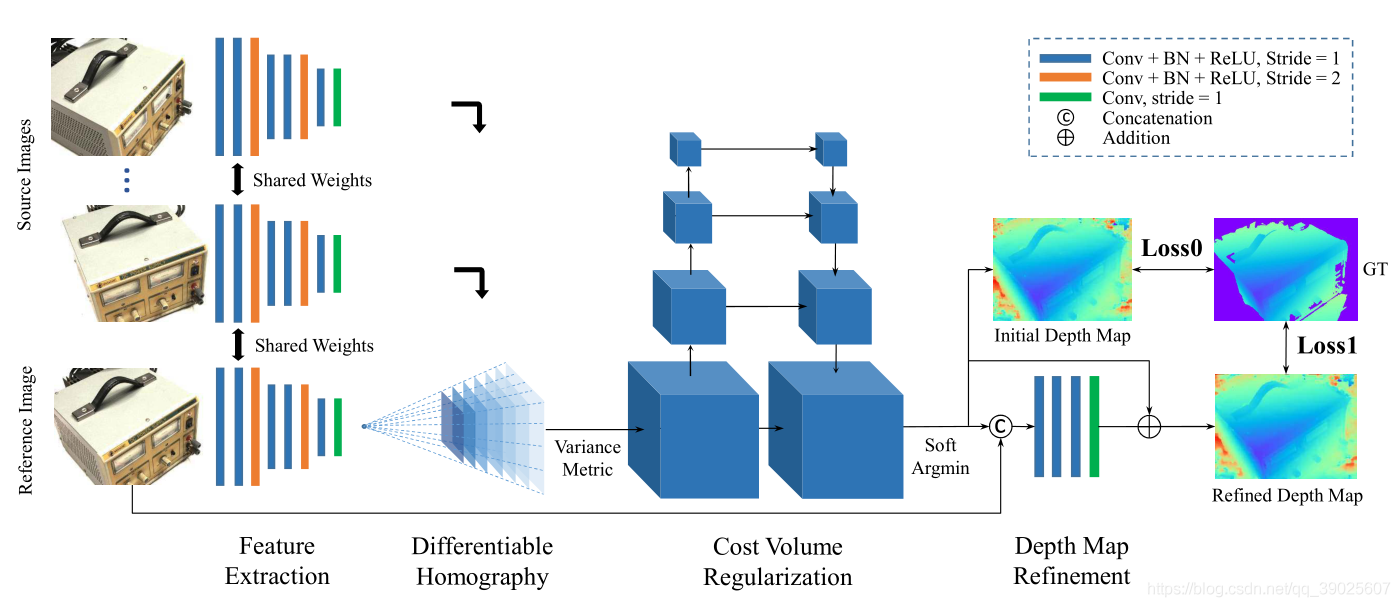
步驟:深度特征提取,構造匹配代價,代價累計,深度估計,深度圖優化,
1、深度特征提取:深度特征指通過神經網路提取的影像特征,相比傳統SIFT、SURF的特征有更好的匹配精度和效率,經過視角選擇之后,輸入已經配對的N張影像,即參考影像和候選集,首先利用一個八層的二維卷積神經網路提取立體像對的深度特征 Fi,輸出32通道的特征圖.
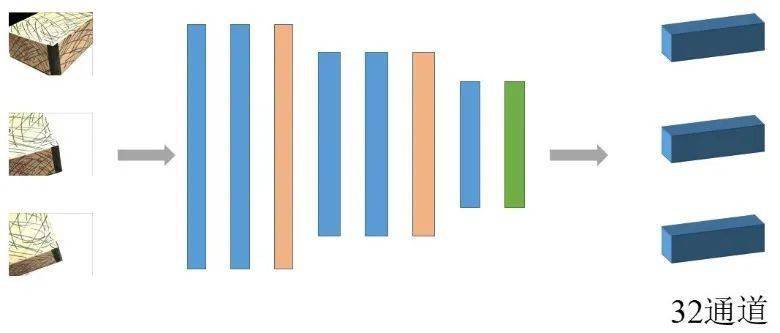
2、構造匹配代價:為防止輸入的像片被降采樣后語意資訊的丟失,像素的臨近像素之間的語意資訊已經被編碼到這個32通道的特征中,并且各個影像提取程序的網路是權值共享的,
3、代價累計:MVSNet的代價累積通過構造代價體實作的,代價體是一個由長、寬與參考影像長寬一樣的代價圖在深度方向連接而成的三維結構,在深度維度,每一個單位表示一個深度值,其中,某一深度的代價圖上面的像素表示參考影像同樣的像素在相同深度處,與候選集影像的匹配代價,
計算概率圖來測量深度估計質量,在我實驗中,將概率小于0.8的像素作為例外值,幾何約束度量多個視圖之間的深度一致性,與立體影像的左右視差檢查類似,通過深度d1將參考像素p1投影到另一個視圖中的像素pi1,然后通過pi的深度估計di將pi重新投影回參考影像,
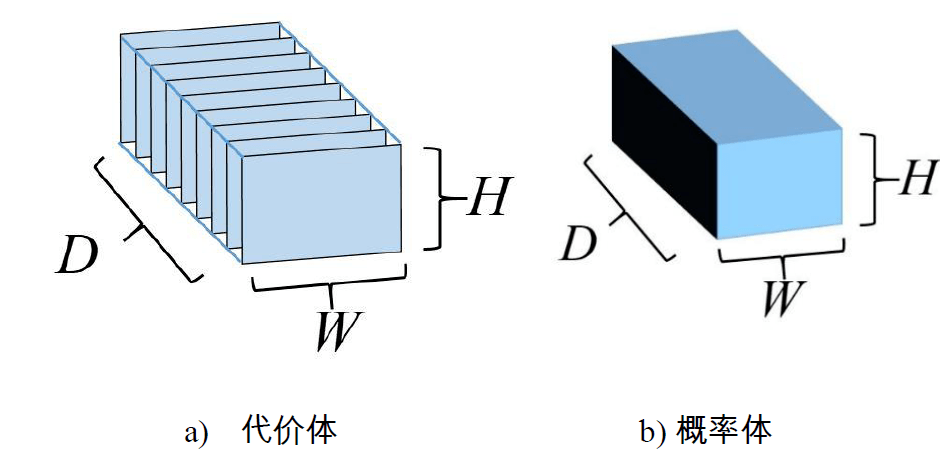
4、深度估計:MVSNet的深度估計是通過神經網路直接學習的,網路訓練方法是,輸入代價體V和對應深度圖真值,利用SoftMax回歸每一個像素在深度θ處的概率,得到一個表示參考影像每個影像沿深度方向置信度的概率體P,以此完成從代價到深度值的學習程序,
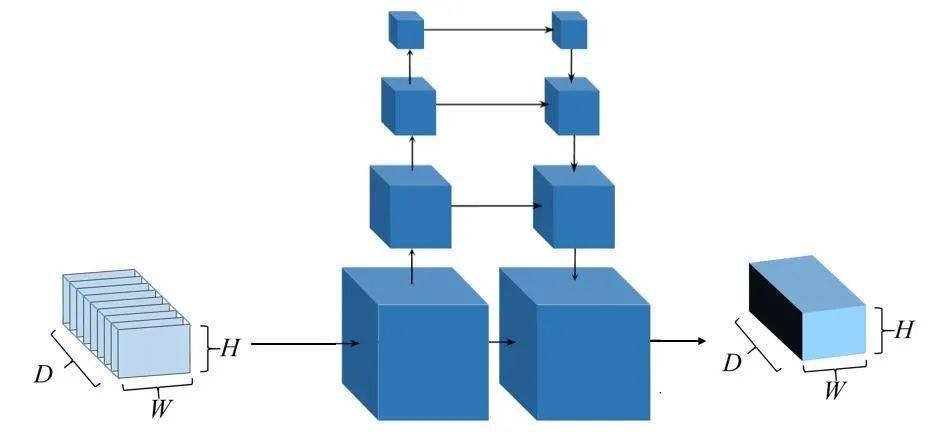
5、深度圖優化:原始代價體往往是含有噪聲污染的,因此,為防止噪聲使得網路過度擬合,MVSNet中使用基于多尺度的三維卷積神經網路進行代價體正則化,利用U-Net網路,對代價體進行降采樣,并提取不同尺度中的背景關系資訊和臨近像素資訊,對代價體進行過濾,
其他
DTU資料集:DTU資料集是一個包含100多個不同光照條件的場景的大型MVS資料集,

深度圖:

cost volume:cost-volume在計算機視覺中特指計算機視覺中的立體匹配stereo matching問題中的一種左右視差搜索空間(詳見:https://www.zhihu.com/question/297481800)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/257791.html
標籤:其他
上一篇:C語言編程>第二十四周 ④ 下列給定程式中,函式fun的功能是:給定n個實數,輸出平均值,并統計在平均值以上(含平均值)的實數個數。
下一篇:計算機網路粗略回顧