1.Spark Graph簡介
GraphX 是 Spark 一個組件,專門用來表示圖以及進行圖的并行計算,GraphX 通過重新定義了圖的抽象概念來拓展了 RDD: 定向多圖,其屬性附加到每個頂點和邊,為了支持圖計算, GraphX 公開了一系列基本運算子(比如:mapVertices、mapEdges、subgraph)以及優化后的 Pregel API 變種,此外,還包含越來越多的圖演算法和構建器,以簡化圖形分析任務,GraphX在圖頂點資訊和邊資訊存盤上做了優化,使得圖計算框架性能相對于原生RDD實作得以較大提升,接近或到達 GraphLab 等專業圖計算平臺的性能,GraphX最大的貢獻是,在Spark之上提供一堆疊式資料解決方案,可以方便且高效地完成圖計算的一整套流水作業,
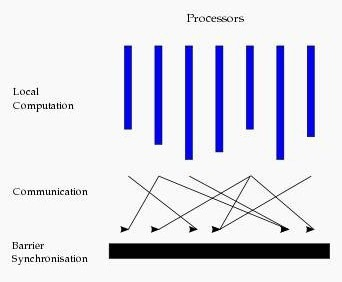
圖計算的模式:
基本圖計算是基于BSP的模式,BSP即整體同步并行,它將計算分成一系列超步的迭代,從縱向上看,它是一個串行模式,而從橫向上看,它是一個并行的模式,每兩個超步之間設定一個柵欄(barrier),即整體同步點,確定所有并行的計算都完成后再啟動下一輪超步,
每一個超步包含三部分內容:
計算compute:每一個processor利用上一個超步傳過來的訊息和本地的資料進行本地計算
訊息傳遞:每一個processor計算完畢后,將訊息傳遞個與之關聯的其它processors
整體同步點:用于整體同步,確定所有的計算和訊息傳遞都進行完畢后,進入下一個超步
2.來看一個例子
圖描述
## 頂點資料
1, "SFO"
2, "ORD"
3, "DFW"
## 邊資料
1, 2,1800
2, 3, 800
3, 1, 1400
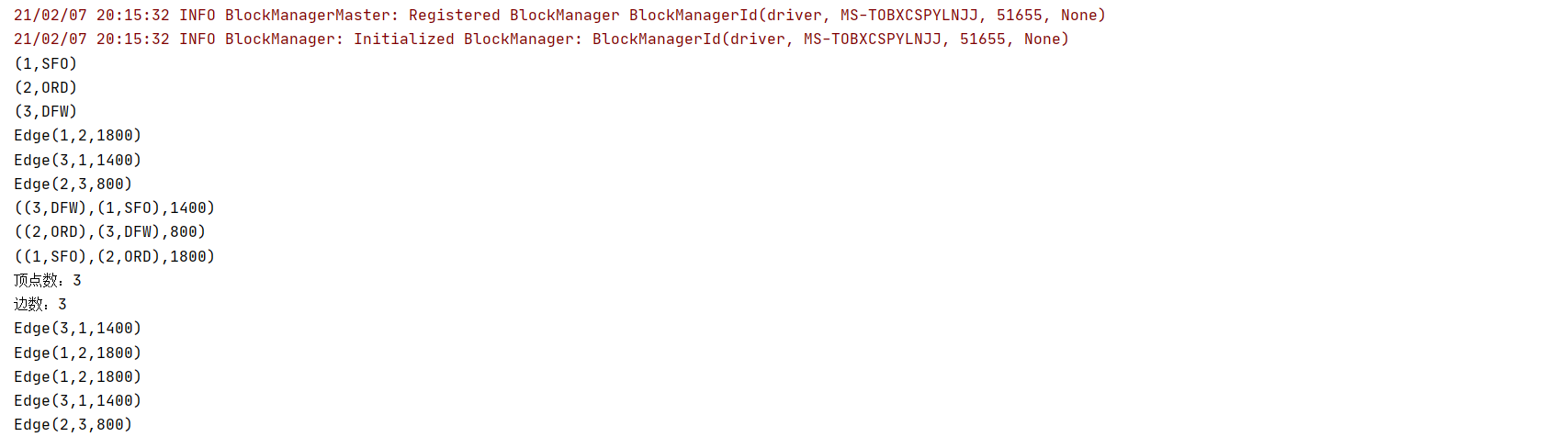
計算所有的頂點,所有的邊,所有的triplets,頂點數,邊數,頂點距離大于1000的有那幾個,按頂點的距離排序,降序輸出
代碼實作
package com.hoult.Streaming.work
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.graphx.{Edge, Graph, VertexId}
import org.apache.spark.rdd.RDD
object GraphDemo {
def main(args: Array[String]): Unit = {
// 初始化
val conf = new SparkConf().setAppName(this.getClass.getCanonicalName.init).setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("warn")
//初始化資料
val vertexArray: Array[(Long, String)] = Array((1L, "SFO"), (2L, "ORD"), (3L, "DFW"))
val edgeArray: Array[Edge[Int]] = Array(
Edge(1L, 2L, 1800),
Edge(2L, 3L, 800),
Edge(3L, 1L, 1400)
)
//構造vertexRDD和edgeRDD
val vertexRDD: RDD[(VertexId, String)] = sc.makeRDD(vertexArray)
val edgeRDD: RDD[Edge[Int]] = sc.makeRDD(edgeArray)
//構造圖
val graph: Graph[String, Int] = Graph(vertexRDD, edgeRDD)
//所有的頂點
graph.vertices.foreach(println)
//所有的邊
graph.edges.foreach(println)
//所有的triplets
graph.triplets.foreach(println)
//求頂點數
val vertexCnt = graph.vertices.count()
println(s"頂點數:$vertexCnt")
//求邊數
val edgeCnt = graph.edges.count()
println(s"邊數:$edgeCnt")
//機場距離大于1000的
graph.edges.filter(_.attr > 1000).foreach(println)
//按所有機場之間的距離排序(降序)
graph.edges.sortBy(-_.attr).collect().foreach(println)
}
}
輸出結果
3.圖的一些相關知識
例子是demo級別的,實際生產環境下,如果使用到必然比這個復雜很多,但是總的來說,一定場景才會使用到吧,要注意圖計算情況下,要注意快取資料,RDD默認不存盤于記憶體中,所以可以盡量使用顯示快取,迭代計算中,為了獲得最佳性能,也可能需要取消快取,默認情況下,快取的RDD和圖保存在記憶體中,直到記憶體壓力迫使它們按照LRU【最近最少使用頁面交換演算法】逐漸從記憶體中移除,對于迭代計算,先前的中間結果將填滿記憶體,經過它們最終被移除記憶體,但存盤在記憶體中的不必要資料將減慢垃圾回收速度,因此,一旦不再需要中間結果,取消快取中間結果將更加有效,這涉及在每次迭代中實作快取圖或RDD,取消快取其他所有資料集,并僅在以后的迭代中使用實作的資料集,但是,由于圖是有多個RDD組成的,因此很難正確地取消持久化,對于迭代計算,建議使用Pregel API,它可以正確地保留中間結果,
吳邪,小三爺,混跡于后臺,大資料,人工智能領域的小菜鳥,
更多請關注

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/257999.html
標籤:其他