廢話不多說直接上模型:
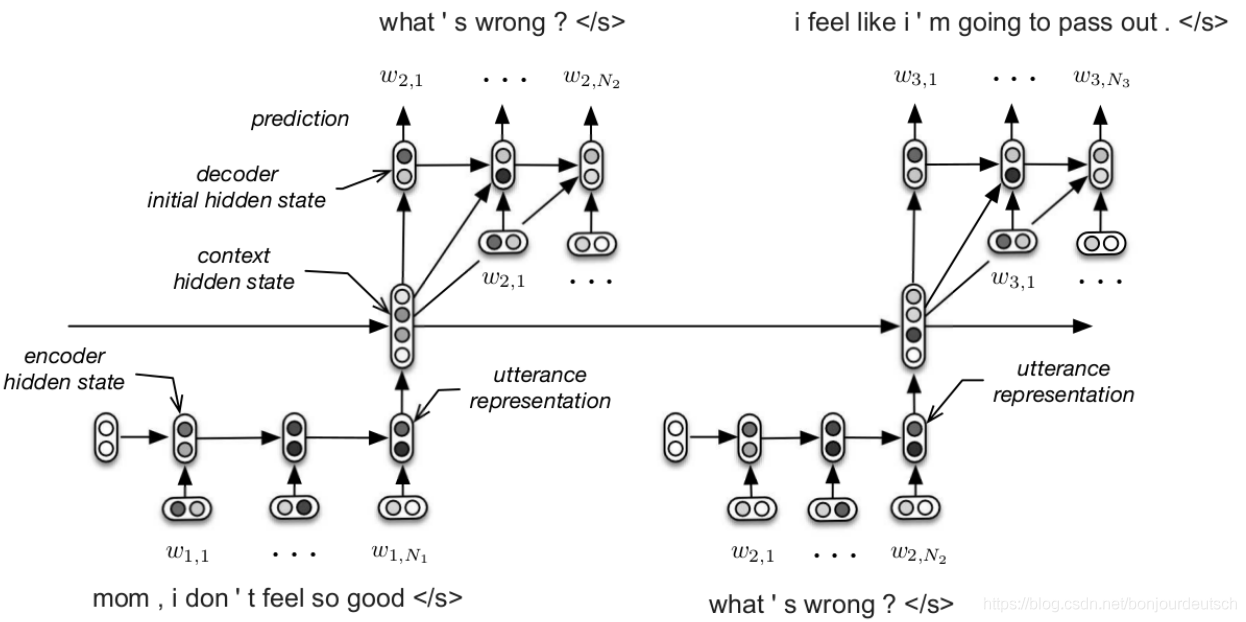
這是一個非常經典的對話生成模型,叫做HRED(Hierarchical RNN Enconder-Decoder),思路很簡單,就是用一個RNN來建模前
j
?
1
j-1
j?1句話,再用一個RNN來建模第
j
j
j句話的
k
?
1
k-1
k?1個詞,然后再用一個RNN來解碼第
j
j
j句話的第
k
k
k個詞,
HRED模型的訓練:給定一個詞的上文,最大化這個詞出現的對數似然(極大似然估計)
即: a r g m a x ( l o g p θ ( w j , k ∣ w 1 , w 2 , . . . , w j ? 1 , w j , 1 , w j , 2 , . . . , w j , k ) ) argmax(logp_\theta(w_{j,k}|w_{1}, w_{2}, ..., w_{j-1}, w_{j, 1}, w_{j, 2}, ..., w_{j,k})) argmax(logpθ?(wj,k?∣w1?,w2?,...,wj?1?,wj,1?,wj,2?,...,wj,k?))
為了方便下文的推導,let w w w = w j , k w_{j,k} wj,k?, c c c = w 1 , w 2 , . . . , w j ? 1 , w j , 1 , w j , 2 , . . . , w j , k w_{1}, w_{2}, ..., w_{j-1}, w_{j, 1}, w_{j, 2}, ..., w_{j,k} w1?,w2?,...,wj?1?,wj,1?,wj,2?,...,wj,k?
訓練目標簡寫為: a r g m a x ( l o g p θ ( w ∣ c ) ) argmax(logp_\theta(w|c)) argmax(logpθ?(w∣c))
而 p θ p_\theta pθ?其實就是我們定義的RNN,RNN的公式網上一查就查到了,因此計算梯度,反向傳播,引數更新,都是理所當然的事情,最后我們就得到了一個對話生成模型,
但是極大似然估計有一個問題,那就是模型容易置信度過高,而在真實的對話流程中,一句輸入,其實可能有無數種回答的方式,每一種回答都是合理的(因為是閑聊嘛),將模型的所有變數都建模為可見的引數 θ \theta θ,會導致傾向于生成單調的通用性回復,比如“我不知道”,“嗯嗯”,等,這種回復本質上是沒錯的,但是很無聊,
于是我們提出了下面這個模型:
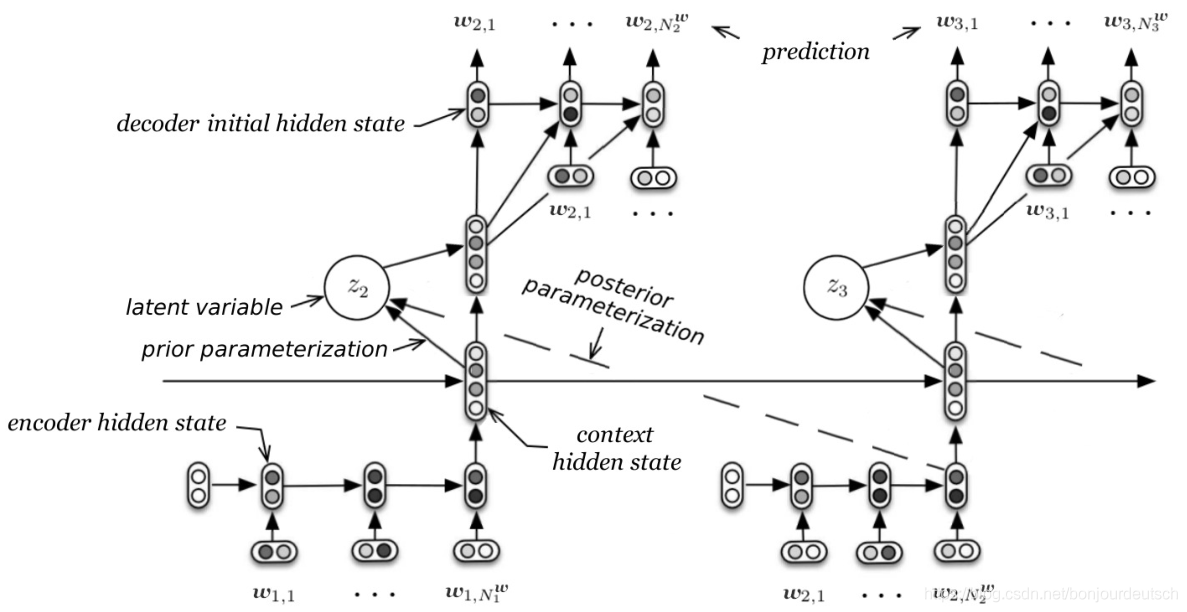
這個模型叫做VHRED(Variational Hierarchical RNN Encoder-Decoder),引入一個不可觀測的隱變數,用于生成對話回復,隱變數每次都采樣于一個分布,這樣,回復的多樣性極大的增加了,
VHRED模型的訓練:在生成每一個詞的時候,引入了一個隱變數 z z z,這個隱變數無法觀測到,所以無法用引數 θ \theta θ建模,因此,訓練目標重新寫為:
a r g m a x ( l o g p θ ( w ∣ c ) ) = a r g m a x ( l o g ∫ p θ ( w ∣ c , z ) p θ ( z ∣ c ) d z ) argmax(logp_\theta(w|c)) = argmax(log\int p_\theta(w|c,z)p_\theta(z|c) d_{z}) argmax(logpθ?(w∣c))=argmax(log∫pθ?(w∣c,z)pθ?(z∣c)dz?)
問題出現了: z z z是一個高維變數,遍歷所有 z z z是不可行的!也就是說,等式右邊的式子你是寫不出來的,自然也無法計算梯度,進行梯度反向傳播,引數更新,
萬幸,提出VAE(Variational Autoencoder,VHRED的V就是從這里來的)的論文提供了一個復雜且精妙的解決方案,那就是引入變分推斷,用一個認知網路 q ? ( z ∣ c , w ) q_\phi(z|c,w) q??(z∣c,w)擬合真實的后驗分布 p θ ( z ∣ c , w ) p_\theta(z|c,w) pθ?(z∣c,w),
(一大波推導來襲)
l
o
g
p
θ
(
w
∣
c
)
=
E
z
~
q
?
(
z
∣
c
,
w
)
l
o
g
p
θ
(
w
∣
z
)
#
樣
本
分
布
與
認
知
網
絡
無
關
=
E
z
l
o
g
(
p
θ
(
w
∣
c
,
z
)
×
p
θ
(
z
∣
c
)
p
θ
(
z
∣
c
,
w
)
)
=
E
z
l
o
g
(
p
θ
(
w
∣
c
,
z
)
×
p
θ
(
z
∣
c
)
p
θ
(
z
∣
c
,
w
)
×
q
?
(
z
∣
c
,
w
)
q
?
(
z
∣
c
,
w
)
)
=
E
z
l
o
g
(
p
θ
(
w
∣
c
,
z
)
×
p
θ
(
z
∣
c
)
q
?
(
z
∣
c
,
w
)
×
q
?
(
z
∣
c
,
w
)
p
θ
(
z
∣
c
,
w
)
)
=
E
z
l
o
g
(
p
θ
(
w
∣
c
,
z
)
?
E
z
l
o
g
(
q
?
(
z
∣
c
,
w
)
p
θ
(
z
∣
c
)
)
+
E
z
l
o
g
(
q
?
(
z
∣
c
,
w
)
p
θ
(
z
∣
c
,
w
)
)
=
E
z
l
o
g
(
p
θ
(
w
∣
c
,
z
)
?
∫
q
?
(
z
∣
c
,
w
)
l
o
g
q
?
(
z
∣
c
,
w
)
p
θ
(
z
∣
c
)
d
z
+
∫
q
?
(
z
∣
c
,
w
)
q
?
(
z
∣
c
,
w
)
p
θ
(
z
∣
c
,
w
)
d
z
=
E
z
~
q
?
(
z
∣
c
,
w
)
l
o
g
p
θ
(
w
∣
c
,
z
)
?
K
L
(
q
?
(
z
∣
c
,
w
)
∣
∣
p
θ
(
z
∣
c
)
)
+
K
L
(
q
?
(
z
∣
c
,
w
)
∣
∣
p
θ
(
z
∣
c
,
w
)
)
\begin{aligned} logp_\theta(w|c) &= \mathbb{E}_{z \sim q_\phi(z|c,w)}logp_\theta(w|z) \#樣本分布與認知網路無關\\ & = \mathbb{E}_zlog( \frac{p_\theta(w|c, z) \times p_\theta(z|c)}{p_\theta(z|c, w)})\\ & = \mathbb{E}_zlog(\frac{p_\theta(w|c, z) \times p_\theta(z|c)}{p_\theta(z|c, w)} \times \frac{q_\phi(z|c, w)}{q_\phi(z|c, w)}) \\ & = \mathbb{E}_zlog(p_\theta(w|c, z) \times \frac{p_\theta(z|c)}{q_\phi(z|c,w)} \times \frac{q_\phi(z|c, w)}{p_\theta(z|c, w)}) \\ & = \mathbb{E}_zlog(p_\theta(w|c, z) - \mathbb{E}_z log(\frac{q_\phi(z|c,w)}{p_\theta(z|c)}) + \mathbb{E}_z log(\frac{q_\phi(z|c, w)}{p_\theta(z|c, w)}) \\ & = \mathbb{E}_zlog(p_\theta(w|c, z) - \int q_\phi(z|c,w)log\frac{q_\phi(z|c,w)}{p_\theta(z|c)} d_z + \int q_\phi(z|c,w) \frac{q_\phi(z|c, w)}{p_\theta(z|c, w)}d_z \\ & = \mathbb{E}_{z \sim q_\phi(z|c,w)}logp_\theta(w|c,z) - KL(q_\phi(z|c,w)||p_\theta(z|c)) + KL(q_\phi(z|c,w)||p_\theta(z|c, w)) \end{aligned}
logpθ?(w∣c)?=Ez~q??(z∣c,w)?logpθ?(w∣z)#樣本分布與認知網絡無關=Ez?log(pθ?(z∣c,w)pθ?(w∣c,z)×pθ?(z∣c)?)=Ez?log(pθ?(z∣c,w)pθ?(w∣c,z)×pθ?(z∣c)?×q??(z∣c,w)q??(z∣c,w)?)=Ez?log(pθ?(w∣c,z)×q??(z∣c,w)pθ?(z∣c)?×pθ?(z∣c,w)q??(z∣c,w)?)=Ez?log(pθ?(w∣c,z)?Ez?log(pθ?(z∣c)q??(z∣c,w)?)+Ez?log(pθ?(z∣c,w)q??(z∣c,w)?)=Ez?log(pθ?(w∣c,z)?∫q??(z∣c,w)logpθ?(z∣c)q??(z∣c,w)?dz?+∫q??(z∣c,w)pθ?(z∣c,w)q??(z∣c,w)?dz?=Ez~q??(z∣c,w)?logpθ?(w∣c,z)?KL(q??(z∣c,w)∣∣pθ?(z∣c))+KL(q??(z∣c,w)∣∣pθ?(z∣c,w))?
注意上面的第三項是寫不出來的,原因:
p
θ
(
z
∣
c
,
w
)
=
p
θ
(
w
∣
c
,
z
)
×
p
θ
(
z
∣
c
)
p
θ
(
w
∣
c
)
p_\theta(z|c, w) = \frac{p_\theta(w|c, z) \times p_\theta(z|c)}{p_\theta(w|c)}
pθ?(z∣c,w)=pθ?(w∣c)pθ?(w∣c,z)×pθ?(z∣c)?
p θ ( w ∣ c ) p_\theta(w|c) pθ?(w∣c)寫不出來, p θ ( z ∣ c , w ) p_\theta(z|c,w) pθ?(z∣c,w)就寫不出來,但是KL散度有個性質,那就是KL散度始終是大于等于零的,
于是我們得到:
l o g p θ ( w ∣ c ) ≥ E z ~ q ? ( z ∣ c ) l o g p θ ( w ∣ c , z ) ? K L ( q ? ( z ∣ c , w ) ∣ ∣ p θ ( z ∣ c ) ) logp_\theta(w|c) \geq \mathbb{E}_{z \sim q_\phi(z|c)}logp_\theta(w|c,z) - KL(q_\phi(z|c,w)||p_\theta(z|c)) logpθ?(w∣c)≥Ez~q??(z∣c)?logpθ?(w∣c,z)?KL(q??(z∣c,w)∣∣pθ?(z∣c))
因此,只要最大化不等式右邊的內容,就變相的最大化了訓練樣本的對數似然,而不等式右邊的內容就稱為證據下界(ELBO, Evidence Lower-Bound),
綜上, a r g m a x ( l o g p θ ( w ∣ c ) ) = a r g m a x ( E L B O ) argmax(logp_\theta(w|c)) = argmax(ELBO) argmax(logpθ?(w∣c))=argmax(ELBO),而 E L B O = E z ~ q ? ( z ∣ c ) l o g p θ ( w ∣ c , z ) ? K L ( q ? ( z ∣ c , w ) ∣ ∣ p θ ( z ∣ c ) ) ELBO = \mathbb{E}_{z \sim q_\phi(z|c)}logp_\theta(w|c,z) - KL(q_\phi(z|c,w)||p_\theta(z|c)) ELBO=Ez~q??(z∣c)?logpθ?(w∣c,z)?KL(q??(z∣c,w)∣∣pθ?(z∣c))
觀察上式中的每一項, q ? ( z ∣ c , w ) q_\phi(z|c,w) q??(z∣c,w)就是我們的認知網路(其實也就是變分自編碼器中的編碼器), p θ ( w ∣ c , z ) p_\theta(w|c, z) pθ?(w∣c,z)就是我們的RNN解碼器,而 p θ ( z ∣ c ) p_\theta(z|c) pθ?(z∣c)是我們假設的先驗分布(一般假設為一個協方差為對角矩陣的高斯分布),因此ELBO里的每一項都是可以寫出來的,進而就可以計算梯度,進行梯度反向傳播了,
最后要提的一件事,那就是 z ~ q ? ( z ∣ c , w ) z \sim q_\phi(z|c,w) z~q??(z∣c,w)這里涉及到一個采樣操作,而采樣是不可微的,所以論文中引入了重引數化技巧,使得梯度可以更新,但是這不是本文的重點,所以也不在這上面花費筆墨了,
行文至此,其實有幾個關鍵的問題還是沒有解決:
問題一:條件變分自編碼器,條件在哪里?變分在哪里?自編碼在哪里?
1.條件的意思,是我們假設隱變數 z z z的先驗分布 p θ ( z ∣ c ) p_\theta(z|c) pθ?(z∣c)依賴于 c c c,如果 z z z不依賴與 c c c,即退化為原始的變分自編碼器,僅僅需要假設 p θ ( z ) p_\theta(z) pθ?(z)是一個標準高斯分布即可,但是推導程序是一樣的,
在對話生成中,假設隱變數 z z z依賴于上文 c c c是一個非常自然的想法,這樣 z z z可以用于建模背景關系一致性,實際上,我們還可以讓 z z z依賴于更多的內容,比如一個額外的知識圖譜等,進而建模更多的高維特征,
2.而變分是因為,用 q ? ( z ∣ c , w ) q_\phi(z|c,w) q??(z∣c,w)去擬合 p θ ( z ∣ c ) p_\theta(z|c) pθ?(z∣c),然后最大化證據下界的程序,其實借用了泛函分析中的近似推斷思想,因為無法求出先驗分布 p θ ( z ∣ c ) p_\theta(z|c) pθ?(z∣c)的決議解,所以用 q ? ( z ∣ c , w ) q_\phi(z|c, w) q??(z∣c,w)去擬合 p θ ( z ∣ c ) p_\theta(z|c) pθ?(z∣c),曲徑通幽,最終求出先驗分布 p θ ( z ∣ c ) p_\theta(z|c) pθ?(z∣c)的數值解,更加嚴格的證明涉及到統計物理學中的平均場理論,筆者在此略過(qishimeikandong),
3.最讓人難以理解的,其實是自編碼,特別是現有的講解CVAE的博文總是從自編碼器的角度出發,先假設一個編碼器-解碼器結構,再討論變分推斷的問題,
但是實際上,真實的網路結構,僅僅包含一個解碼器!
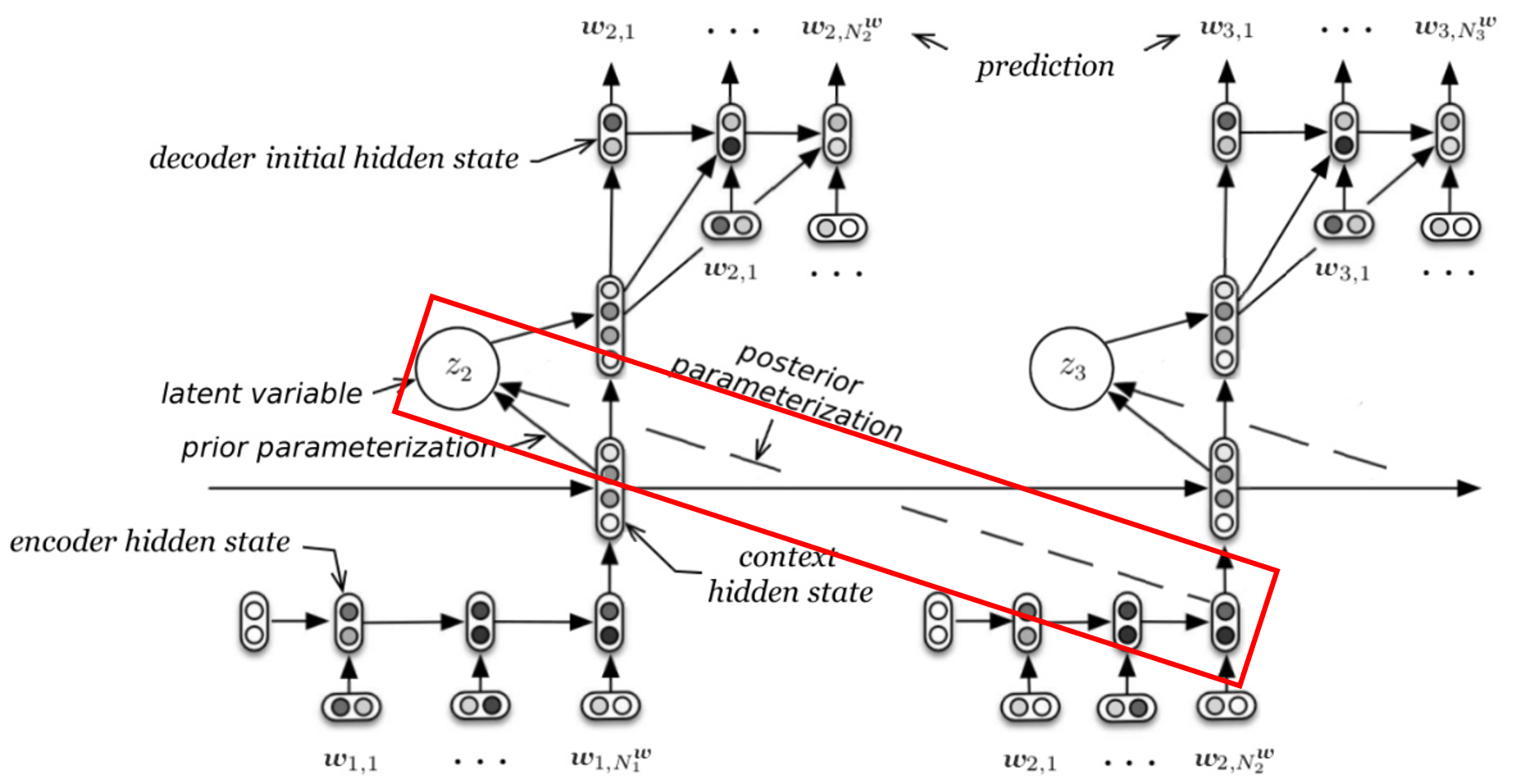
再看一下VHRED的模型圖,實線表示的是訓練完成之后的推斷程序,而虛線的部分(也就是用紅框框起來的部分),實際上在推斷程序中是不存在的,也就是說,在推斷階段,我們的隱變數僅僅參與了解碼程序,而不存在一個自編碼的程序,
而之所以訓練程序中要引入紅框框起來的認知網路,是因為 p θ ( z ∣ c ) p_\theta(z|c) pθ?(z∣c)不可決議,所以引入認知網路 q ? ( z ∣ c , w ) q_\phi(z|c, w) q??(z∣c,w)來擬合 p θ ( z ∣ c ) p_\theta(z|c) pθ?(z∣c),而認知網路 q ? ( z ∣ c , w ) q_\phi(z|c, w) q??(z∣c,w)+解碼器 p θ ( w ∣ c , z ) p_\theta(w|c, z) pθ?(w∣c,z)其實才構成了一個自編碼器架構(自編碼+自解碼),且這個自編碼器僅僅存在于訓練程序中,
所謂的條件自編碼器,僅僅是用于擬合先驗分布的,一旦訓練完成,在推斷階段,只需要使用我們事先假設的先驗分布即可,條件自編碼器就被丟到虛空中了,(這里其實也隱含了一個小陷阱,那就是CVAE在訓練時的引數其實是比測驗時多一點點的,)從這個角度來說,VHRED(Variational Hierarchical Encoder-Decoder)應該叫成LHRED(Latent Hierarchical Encoder-Decoder)更合適一些,
問題二:為什么要引入條件變分自編碼器?
如果你讀懂了上一個問題,那么你一定可以理解,引入條件變分自編碼器,本質上是為了訓練條件隱變數,所以我們應該問的問題,其實是為什么要在解碼器處引入一個條件隱變數?
而這個問題,其實在介紹VHRED模型之前就已經回答了,引入一個不可觀測的隱變數,每次都采樣于高斯分布,高斯分布的樣本空間被認為在一個高維空間建模了所有可能的回復,采樣任意一個點,都對應了一句合理并且流暢的回復,這樣就在保證了回復多樣性的同時,又不會生成亂七八糟的結果,
特別的,我們引入的是一個條件隱變數 z ∣ c z|c z∣c,高斯分布的均值和方差由上文 c c c生成,實際上建模了上文 c c c和回復 w w w之間的高維的、抽象的聯系,但是因為此時的隱變數依然是采樣生成的,又不會損壞回復的多樣性,這樣一舉兩得,豈不美哉,
綜上,條件隱變數起到了兩方面的作用:
- 建模上文c與回復w之間的高維聯系;
- 增加回復多樣性,減少通用性回復,
實際上,這兩項也正好對應了我們損失函式中的兩項:
L o s s = K L ( q ? ( z ∣ c , w ) ∣ ∣ p θ ( z ∣ c ) ) ? E z ~ q ? ( z ∣ c ) l o g p θ ( w ∣ c , z ) Loss = KL(q_\phi(z|c,w)||p_\theta(z|c)) - \mathbb{E}_{z \sim q_\phi(z|c)}logp_\theta(w|c,z) Loss=KL(q??(z∣c,w)∣∣pθ?(z∣c))?Ez~q??(z∣c)?logpθ?(w∣c,z)
第一項KL散度,強制隱變數z的分布向高斯分布靠攏,本質上是在為解碼程序添加噪音,增加回復的多樣性;而第二項KL散度,也可以稱為重建誤差,強制解碼的結果與真實回復一致,本質上是建模上文與回復之間的聯系,
問題三:為什么可以把先驗分布 p θ ( z ∣ c ) p_\theta(z|c) pθ?(z∣c)建模為一個高斯分布,而不能把后驗分布 p θ ( z ∣ c , w ) p_\theta(z|c,w) pθ?(z∣c,w)建模為一個高斯分布?
這其實是貝葉斯學派的作風,貝葉斯學派認為,觀測是恒定的,不確定的是概率,所以你可以隨便假設一個先驗分布(只要不離譜就行),然后根據觀測,不斷地調整后驗分布就行,所以我們把先驗分布假設為了一個高斯分布,因為高斯分布算各種東西都很好算,但是對于后驗分布就不能這么搞了,因為后驗分布是要講證據的,
然而,理想是美好的,現實卻是骨感的,在實際的訓練中,由于 c c c已經編碼了足夠多的資訊,所以RNN解碼器容易忽略 z z z,在這種情況之下,雖然認知網路還是在向先驗網路靠攏,但是認知網路產生的 z z z卻被丟到了虛空中(但是重建誤差還是在不斷減少的,因為RNN的學習能力就是這么強),這樣,我們的隱變數模型逐漸退化成了一個普通的RNN,所謂的建模高維特征、增加回復多樣性也就無從談起了……這就是VAE在做文本生成時,臭名昭著的Degeneration Problem,
典型的解決方案如下:
1.KL annealing
L o s s = λ K L ( q ? ( z ∣ c , w ) ∣ ∣ p θ ( z ∣ c ) ) ? E z ~ q ? ( z ∣ c , w ) l o g p θ ( w ∣ c , z ) Loss = \lambda KL(q_\phi(z|c,w)||p_\theta(z|c)) - \mathbb{E}_{z \sim q_\phi(z|c,w)}logp_\theta(w|c,z) Loss=λKL(q??(z∣c,w)∣∣pθ?(z∣c))?Ez~q??(z∣c,w)?logpθ?(w∣c,z)
思路很簡單,在KL散度前面加了一個常數項,這個常數項在訓練程序中從0到1遞增,也就是說,先不管KL散度,優先優化重建誤差,這種情況之下,模型當然優先把 q ? ( z ∣ c , w ) q_\phi(z|c,w) q??(z∣c,w)采樣為一個方差非常小的分布,這樣 z z z蘊含的 w w w的資訊自然會非常之多,因此重建程序也會更多的依賴于 z z z,然后再將 q ? q_\phi q??的分布和 p θ p_\theta pθ?拉近,保證 z z z的多樣性,
然而實際上,即便最開始重建是依賴于 z z z的,一旦 λ \lambda λ開始增大了,也就是 z z z的采樣范圍增大了,RNN還是會逐漸忽略掉 z z z,沒辦法,神經網路就是這么喜歡走捷徑……
2.word dropout
這個思路就比較巧妙了,既然RNN解碼器是如此之強,我就遮擋掉RNN解碼器的一部分輸入,也就是說,重建誤差
E z ~ q ? ( z ∣ c , w ) l o g p θ ( w ∣ c , z ) \mathbb{E}_{z \sim q_\phi(z|c,w)}logp_\theta(w|c,z) Ez~q??(z∣c,w)?logpθ?(w∣c,z)變成了 E z ~ q ? ( z ∣ c , w ) l o g p θ ( w ∣ z ) \mathbb{E}_{z \sim q_\phi(z|c,w)}logp_\theta(w|z) Ez~q??(z∣c,w)?logpθ?(w∣z),重建的線索僅剩下了隱變數 z z z,因此RNN必須要學習到根據 z z z來重建 w w w的本領,這里的word dropout率不宜過低也不宜過高,過低的話,還是會degenration;過高的話,重建的線索太少,影響到了模型性能,
3.引入全域隱變數
這個方法來自NAACL18的一篇論文A Hierarchical Latent Structure for Variational Conversation Modeling,這篇論文先是對Degeneration Problem進行了分析,然后指出,在基于CVAE的對話生成模型中,Degenartion Problem問題有兩方面原因:
-
RNN解碼器的強大表達能力;
-
條件VAE的條件架構造成的資料稀疏;
有關第二點,需要進一步說明,在優化KL散度項 K L ( q ? ( z ∣ c , w ) ∣ ∣ p θ ( z ∣ c ) ) KL(q_\phi(z|c,w)||p_\theta(z|c)) KL(q??(z∣c,w)∣∣pθ?(z∣c))的程序中, q ? ( z ∣ c , w ) q_\phi(z|c,w) q??(z∣c,w)和 p θ ( z ∣ c ) p_\theta(z|c) pθ?(z∣c)會互相靠近,因為神經網路總是喜歡走捷徑,所以 p θ ( z ∣ c ) p_\theta(z|c) pθ?(z∣c)會學成一個方差非常小的高斯分布,這樣留給 q ? q_\phi q??的就沒什么學習空間了,相比之下,非條件的VAE就不存在這個問題,因為先驗分布永遠是一個0,1的高斯分布,
因此,這篇論文引入了一個全域的隱變數:
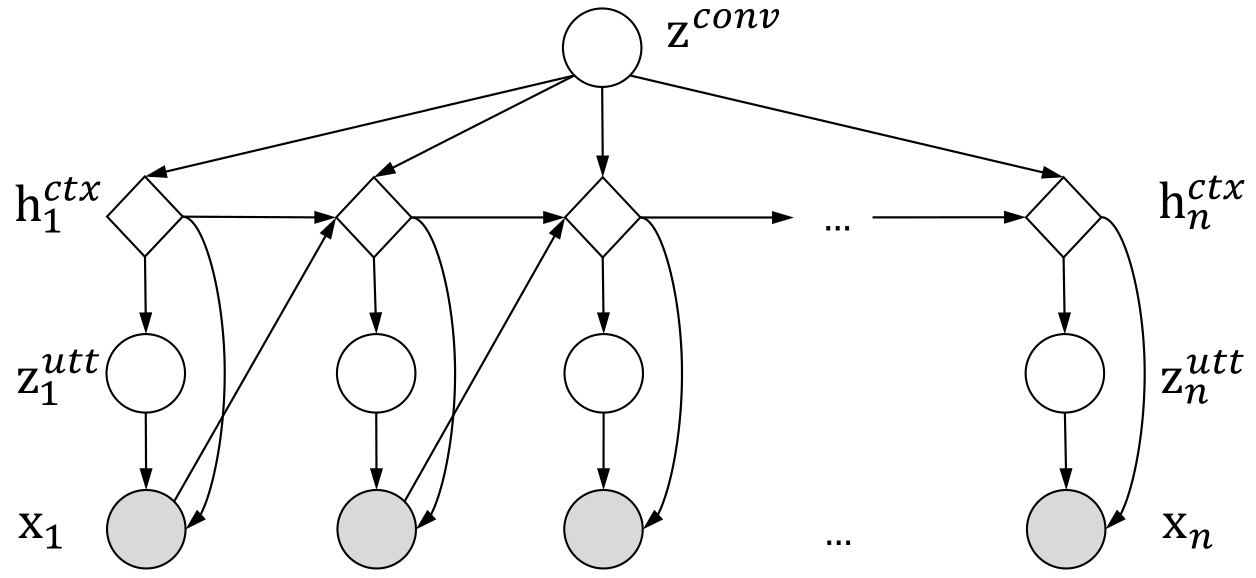
z c o n v z^{conv} zconv會參與到 h c t x h^{ctx} hctx, z i u t t z^{utt}_i ziutt?和 x i x_i xi?的生成中,但是 z c o n v z^{conv} zconv本身卻是從一個0,1高斯分布中采樣出來的隱變數,不condition到任何變數上,因此, z c o n v z^{conv} zconv在建模輸出的高維特征的同時,保證了輸出始終帶有不確定性,
這篇論文的直覺也很直接,因為條件VAE存在資料稀疏問題,所以再引入一個額外的非條件VAE,共同控制輸出的多樣性,最后的損失函式變為了三項:
L
o
s
s
=
K
L
(
q
?
(
z
c
o
n
v
∣
c
,
w
)
∣
∣
p
θ
(
z
c
o
n
v
∣
c
)
)
+
K
L
(
q
?
(
z
u
t
t
∣
c
,
w
)
∣
∣
p
θ
(
z
u
t
t
∣
c
)
)
?
E
z
c
o
n
v
~
q
?
(
z
c
o
n
v
∣
c
,
w
)
,
z
u
t
t
~
q
?
(
z
u
t
t
∣
c
,
w
)
l
o
g
p
θ
(
w
∣
c
,
z
c
o
n
v
,
z
u
t
t
)
\begin{aligned} Loss = &KL(q_\phi(z^{conv}|c,w)||p_\theta(z^{conv}|c)) \\ &+ KL(q_\phi(z^{utt}|c,w)||p_\theta(z^{utt}|c)) \\ &- \mathbb{E}_{z^{conv}\sim q_\phi(z^{conv}|c,w),z^{utt}\sim q_\phi(z^{utt}|c,w)}logp_\theta(w|c,z^{conv},z^{utt}) \end{aligned}
Loss=?KL(q??(zconv∣c,w)∣∣pθ?(zconv∣c))+KL(q??(zutt∣c,w)∣∣pθ?(zutt∣c))?Ezconv~q??(zconv∣c,w),zutt~q??(zutt∣c,w)?logpθ?(w∣c,zconv,zutt)?
(其實我不知道兩個隨機變數同時采樣的期望是不是這么寫)
寫到這里,也是本篇博客的結束了,理解對話生成模型中CVAE的關鍵,在于不要老想著自編碼的事情,CVAE的本質是從一個條件隱變數解碼輸出,引入認知網路(或者說自編碼網路)只是為了方便訓練,
鑒于條件隱變數具備建模高維特征,同時保證多樣性的用途,在實際的使用中,我們可以讓隱變數condition到各種內容上,再進行輸出,從而建立各種內容和輸出之間的聯系,當然,這種聯系必須是高維的,隱式的,比如情感的一致性、主題的一致性等等,或者換句話說,隱變數只能用來建模句子級別的因果關系,諸如詞對齊這樣顯式的、精確的因果關系,還是用顯變數建模更好一些,
[1] Auto-Encoding Variational Bayes, ICLR 2014.
[2] Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models, AAAI 2015.
[3] A Hierarchical Latent Variable Encoder-Decoder Model for Generating Dialogues, AAAI 2017.
[4] A Hierarchical Latent Structure for Variational Conversation Modeling, NAACL 2018.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/258128.html
標籤:AI
下一篇:使用Scipy進行函式優化