資料分析中將兩個資料集進行 Join 操作是很常見的場景,在 Spark 的物理計劃階段,Spark 的 Join Selection 類會根
據 Join hints 策略、Join 表的大小、 Join 是等值 Join 還是不等值以及參與 Join 的 key 是否可以排序等條件來選擇最
終的 Join 策略,最后 Spark 會利用選擇好的 Join 策略執行最終的計算,當前 Spark 一共支持五種 Join 策略:
-
Broadcast hash join (BHJ) -
Shuffle hash join(SHJ) -
Shuffle sort merge join (SMJ) -
Shuffle-and-replicate nested loop join,又稱笛卡爾積(Cartesian product join) -
Broadcast nested loop join (BNLJ)
其中 BHJ 和 SMJ 這兩種 Join 策略是我們運行 Spark 作業最常見的,JoinSelection 會先根據 Join 的 Key 為等值 Join
來選擇 Broadcast hash join、Shuffle hash join 以及 Shuffle sort merge join 中的一個;如果 Join 的 Key 為不等值
Join 或者沒有指定 Join 條件,則會選擇 Broadcast nested loop join 或 Shuffle-and-replicate nested loop join,
不同的 Join 策略在執行上效率差別很大,了解每種 Join 策略的執行程序和適用條件是很有必要的,
1、Broadcast Hash Join
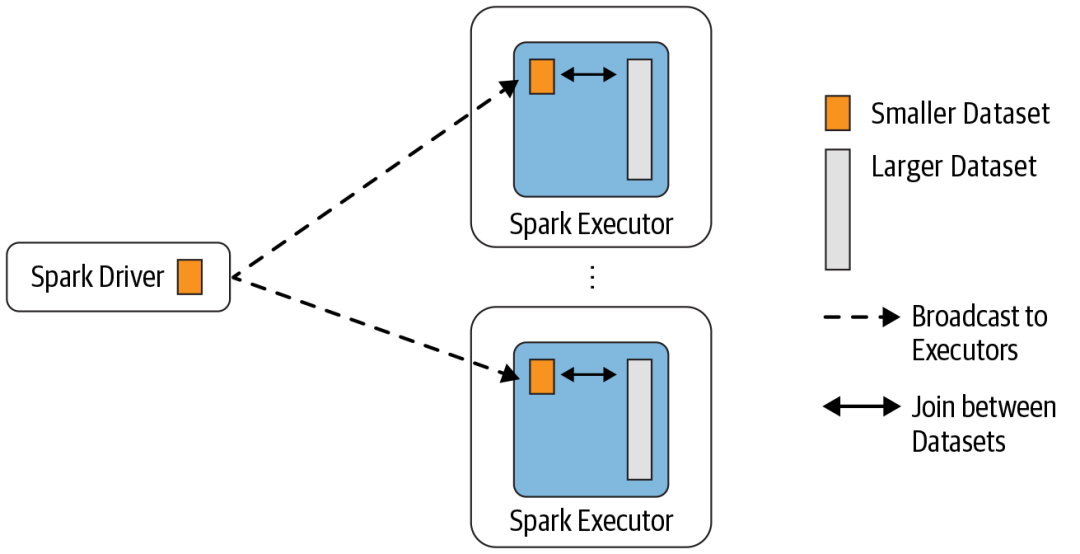
Broadcast Hash Join 的實作是將小表的資料廣播到 Spark 所有的 Executor 端,這個廣播程序和我們自己去廣播數
據沒什么區別:
利用 collect 算子將小表的資料從 Executor 端拉到 Driver 端
在 Driver 端呼叫 sparkContext.broadcast 廣播到所有 Executor 端
在 Executor 端使用廣播的資料與大表進行 Join 操作(實際上是執行map操作)
這種 Join 策略避免了 Shuffle 操作,一般而言,Broadcast Hash Join 會比其他 Join 策略執行的要快,
使用這種 Join 策略必須滿足以下條件:
小表的資料必須很小,可以通過 spark.sql.autoBroadcastJoinThreshold 引數來配置,默認是 10MB
如果記憶體比較大,可以將閾值適當加大
將 spark.sql.autoBroadcastJoinThreshold 引數設定為 -1,可以關閉這種連接方式
只能用于等值 Join,不要求參與 Join 的 keys 可排序
2、Shuffle Hash Join
當表中的資料比較大,又不適合使用廣播,這個時候就可以考慮使用 Shuffle Hash Join,
Shuffle Hash Join 同樣是在大表和小表進行 Join 的時候選擇的一種策略,它的計算思想是:把大表和小表按照相同
的磁區演算法和磁區數進行磁區(根據參與 Join 的 keys 進行磁區),這樣就保證了 hash 值一樣的資料都分發到同一
個磁區中,然后在同一個 Executor 中兩張表 hash 值一樣的磁區就可以在本地進行 hash Join 了,在進行 Join 之
前,還會對小表的磁區構建 Hash Map,Shuffle hash join 利用了分治思想,把大問題拆解成小問題去解決,
要啟用 Shuffle Hash Join 必須滿足以下條件:
僅支持等值 Join,不要求參與 Join 的 Keys 可排序
spark.sql.join.preferSortMergeJoin 引數必須設定為 false,引數是從 Spark 2.0.0 版本引入的,默認值為
true,也就是默認情況下選擇 Sort Merge Join
小表的大小(plan.stats.sizeInBytes)必須小于 spark.sql.autoBroadcastJoinThreshold *
spark.sql.shuffle.partitions(默認值200)
而且小表大小(stats.sizeInBytes)的三倍必須小于等于大表的大小(stats.sizeInBytes),也就是
a.stats.sizeInBytes * 3 < = b.stats.sizeInBytes
3、Shuffle Sort Merge Join
前面兩種 Join 策略對表的大小都有條件的,如果參與 Join 的表都很大,這時候就得考慮用 Shuffle Sort Merge Join
了,
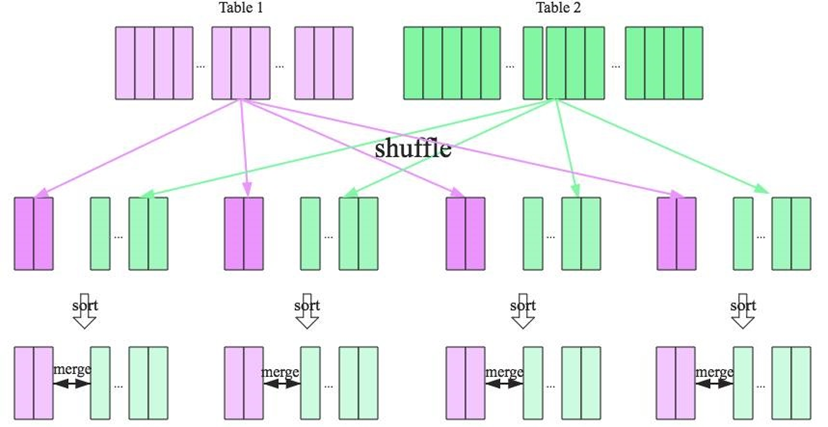
Shuffle Sort Merge Join 的實作思想:
將兩張表按照 join key 進行shuffle,保證join key值相同的記錄會被分在相應的磁區
對每個磁區內的資料進行排序
排序后再對相應的磁區內的記錄進行連接
無論磁區有多大,Sort Merge Join都不用把一側的資料全部加載到記憶體中,而是即用即丟;因為兩個序列都有序,從
頭遍歷,碰到key相同的就輸出,如果不同,左邊小就繼續取左邊,反之取右邊,從而大大提高了大資料量下sql join
的穩定性,
要啟用 Shuffle Sort Merge Join 必須滿足以下條件:
僅支持等值 Join,并且要求參與 Join 的 Keys 可排序
4、Cartesian product join
如果 Spark 中兩張參與 Join 的表沒指定連接條件,那么會產生 Cartesian product join,這個 Join 得到的結果其實
就是兩張表行數的乘積,
5、Broadcast nested loop join
可以把 Broadcast nested loop join 的執行看做下面的計算:
for record_1 in relation_1:
for record_2 in relation_2:
join condition is executed
可以看出 Broadcast nested loop join 在某些情況會對某張表重復掃描多次,效率非常低下,從名字可以看出,這種
join 會根據相關條件對小表進行廣播,以減少表的掃描次數,
Broadcast nested loop join 支持等值和不等值 Join,支持所有的 Join 型別,
吳邪,小三爺,混跡于后臺,大資料,人工智能領域的小菜鳥,
更多請關注

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/258328.html
標籤:其他
下一篇:計算機網路與通信網路