邱錫鵬《神經網路與深度學習》學習筆記,
神經網路與深度學習(六)—— 注意力機制
- 1.1 注意力機制
- 1.1.1 認知神經學中的注意力
- 1.1.2 注意力機制
- 1.1.2.1 注意力分布
- 1.1.2.2 加權平均
- 1.1.3 注意力機制的變體
- 1.1.3. 1 鍵值對注意力
- 1.1.3.2 多頭注意力
- 1.1.3.3 結構化注意力
- 1.1.3.4 指標網路
- 1.2 自注意力機制
為了減少計算復雜度,我們引入了區域連接,權重共享以及池化操作來簡化網路結構,但目前計算機的計算能力依然是限制神經網路發展的瓶頸,因此我們依然希望在不過度增加模型復雜度(主要是模型引數)的情況下來提高模型的表達能力,
神經網路中可以存盤的資訊量稱為網路容量(Network Capacity),一般來講神經網路的存盤容量和神經元的數量以及網路的復雜度成正比,
我們可以借鑒人腦解決輸入資訊過載的機制,從兩個方面來提高神經網路處理資訊的能力:
- 注意力機制,通過自上而下的資訊選擇機制來過濾掉大量的無關資訊;
- 外部記憶,引入額外的外部記憶,優化神經網路結構來提高網路存盤資訊的容量,
本文僅探討注意力機制,
1.1 注意力機制
在計算能力有限的情況下,Attention Mechanism 作為資源分配方案,是解決資訊超載問題的主要手段,
一個非常有助于理解的鏈接:深度學習中的注意力模型,
1.1.1 認知神經學中的注意力
大腦從大量的輸入資訊中,重點關注一小部分有用的資訊同時忽略其他資訊的選擇能力,叫做注意力 (Attention),
大腦的注意力一般分為兩種:
- 聚焦式注意力(Focus Attention),有預定目標、依賴任務的、主動有意識的聚焦于某一物件的注意力,
- 基于顯著性的注意力(Saliency Based Attention),由外界刺激驅動的注意力,不需要主動干預,也和任務無關,如果一個物件的刺激資訊不同于其周圍資訊,一種無意識的“贏者通吃(Winner-Take-All)”或者門控機制(Gating)就可以把注意力轉向這個物件,
目前的神經網路模型中最大池化(Max Pooling)、門控機制(Gating)近似可以看做基于顯著性的注意力機制,
1.1.2 注意力機制
此處注意力機制指主動的聚焦式注意力,
用 X = [ x 1 , ? ? , x N ] ∈ R D × N \boldsymbol{X}=\left[\boldsymbol{x}_{1}, \cdots, \boldsymbol{x}_{N}\right] \in \mathbb{R}^{D \times N} X=[x1?,?,xN?]∈RD×N表示 N N N 組輸入資訊,其中 D D D維向量 x n ∈ R D , n ∈ [ 1 , N ] \boldsymbol{x}_{n}\in\mathbb{R}^{D},n\in[1,N] xn?∈RD,n∈[1,N]表示一組輸入資訊,為了節省計算資源,只需要從 X \boldsymbol{X} X 中選擇一些和任務相關的資訊,
注意力機制的計算可以分為兩步:
- 在所有輸入資訊上計算注意力分布,
- 根據注意力分布計算輸入資訊的加權平均,
1.1.2.1 注意力分布
為了從 N N N 個輸入向量 [ x 1 , ? ? , x N ] [\boldsymbol{x}_{1}, \cdots, \boldsymbol{x}_{N}] [x1?,?,xN?]中選擇出和某個特定任務相關的資訊,我們需要引入一個和任務相關的表示,稱為查詢向量(Query Vector),并通過一個打分函式來計算每個輸入向量和查詢向量之間的相關性,
給定一個和任務相關的查詢向量
q
\boldsymbol{q}
q(查詢向量可以是動態生成的,也可以是可學習的引數),我們用注意力變數
z
∈
[
1
,
N
]
z\in[1,N]
z∈[1,N]來表示被選擇資訊的索引位置,即
z
=
n
z=n
z=n 表示選擇了第
n
n
n個輸入向量,為了方便計算,我們采用一種“軟性”的資訊選擇機制,首先計算在給定
q
\boldsymbol{q}
q和
X
\boldsymbol{X}
X下,選擇第
i
i
i個輸入向量的概率
α
n
\alpha_n
αn?:
α
n
=
p
(
z
=
n
∣
X
,
q
)
=
softmax
?
(
s
(
x
n
,
q
)
)
=
exp
?
(
s
(
x
n
,
q
)
)
∑
j
=
1
N
exp
?
(
s
(
x
j
,
q
)
)
\begin{aligned} \alpha_{n} &=p(z=n \mid \boldsymbol{X}, \boldsymbol{q}) \\ &=\operatorname{softmax}\left(s\left(\boldsymbol{x}_{n}, \boldsymbol{q}\right)\right) \\ &=\frac{\exp \left(s\left(\boldsymbol{x}_{n}, \boldsymbol{q}\right)\right)}{\sum_{j=1}^{N} \exp \left(s\left(\boldsymbol{x}_{j}, \boldsymbol{q}\right)\right)} \end{aligned}
αn??=p(z=n∣X,q)=softmax(s(xn?,q))=∑j=1N?exp(s(xj?,q))exp(s(xn?,q))??
其中
α
n
\alpha_{n}
αn?稱為注意力分布(Attention Distribution),
s
(
x
n
,
q
)
s\left(\boldsymbol{x}_{n}, \boldsymbol{q}\right)
s(xn?,q)為注意力打分函式(s即similarity,計算兩者的相似性或者相關性),可以使用以下幾種方式來計算:
- 加性模型: s ( x , q ) = v ? tanh ? ( W x + U q ) s(\boldsymbol{x}, \boldsymbol{q})=\boldsymbol{v}^{\top} \tanh (\boldsymbol{W} \boldsymbol{x}+\boldsymbol{U} \boldsymbol{q}) s(x,q)=v?tanh(Wx+Uq)
- 點積模型: s ( x , q ) = x T q s(\boldsymbol{x}, \boldsymbol{q})=\boldsymbol{x}^{\text{T}}\boldsymbol{q} s(x,q)=xTq
- 縮放點積模型: s ( x , q ) = x ? q D s(\boldsymbol{x}, \boldsymbol{q})=\frac{\boldsymbol{x}^{\top} \boldsymbol{q}}{\sqrt{D}} s(x,q)=D ?x?q?
- 雙線性模型: S ( x , q ) = x ? W q S(\boldsymbol{x}, \boldsymbol{q})=\boldsymbol{x}^{\top} \boldsymbol{W} \boldsymbol{q} S(x,q)=x?Wq
其中 W \boldsymbol{W} W, U \boldsymbol{U} U, v \boldsymbol{v} v 為可學習的引數, D D D為輸入向量的維度,
理論上加性模型和點積模型的復雜度差不多,但點積模型可以更好的利用矩陣乘積,計算效率更高,
當輸入向量的維度較高時,點積模型的值通常由較大的方差,從而導致 Softmax 函式的梯度會比較小,而縮放點積模型可以較好的解決這個問題,
雙線性模型是一種泛化的點積模型,假設模型引數 W = U T V \boldsymbol{W}=\boldsymbol{U}^T\boldsymbol{V} W=UTV,雙線性模型可寫為 s ( x , q ) = x ? U ? V q = ( U x ) ? ( V q ) s(\boldsymbol{x}, \boldsymbol{q})=\boldsymbol{x}^{\top} \boldsymbol{U}^{\top} \boldsymbol{V} \boldsymbol{q}=(\boldsymbol{U} \boldsymbol{x})^{\top}(\boldsymbol{V} \boldsymbol{q}) s(x,q)=x?U?Vq=(Ux)?(Vq),即分別對 x \boldsymbol{x} x, q \boldsymbol{q} q進行線性變換后計算點積,相比點積模型,雙線性模型在計算相似度時引入了非對稱性,
1.1.2.2 加權平均
注意力分布
α
n
\alpha_n
αn?可以解釋為在給定任務相關的查詢
q
\boldsymbol{q}
q時,第
n
n
n個輸入向量受關注的程度,我們采用一種“軟性”的資訊選擇機制對輸入資訊進行匯總,即軟性注意力機制(Soft Attention Mechanism):
att
?
(
X
,
q
)
=
∑
n
=
1
N
α
n
x
n
=
E
z
~
p
(
z
∣
X
,
q
)
[
x
z
]
\begin{aligned} \operatorname{att}(\boldsymbol{X}, \boldsymbol{q}) &=\sum_{n=1}^{N} \alpha_{n} \boldsymbol{x}_{n} \\ &=\mathbb{E}_{z \sim p(z \mid \boldsymbol{X}, \boldsymbol{q})}\left[\boldsymbol{x}_{z}\right] \end{aligned}
att(X,q)?=n=1∑N?αn?xn?=Ez~p(z∣X,q)?[xz?]?
軟性注意力機制選擇的資訊是所有輸入向量在注意力分布下的期望,
下圖為軟性注意力機制示例:
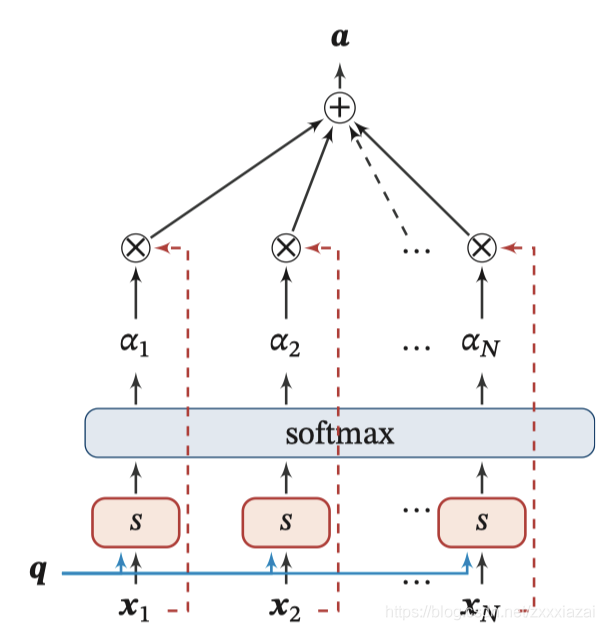
另一種注意力是只關注某一輸入向量,叫作硬性注意力(Hard Attention),硬性注意力有兩種實作方式:
1)選取注意力分布中概率最高的輸入向量,即最大采樣:
att
?
(
X
,
q
)
=
x
n
^
\operatorname{att}(\boldsymbol{X}, \boldsymbol{q})=\boldsymbol{x}_{\hat{n}}
att(X,q)=xn^?
其中 n ^ \hat{n} n^為概率最大的輸入向量的下標,即 n ^ = arg ? max ? n = 1 N α n \hat{n}={\arg \max}^{N}_{n=1} \alpha_{n} n^=argmaxn=1N?αn?,
2)在注意力分布式上隨機采樣,
硬性注意力的一個缺點是損失函式與注意力分布之間的函式關系不可導,無法使用反向傳播演算法進行訓練,因此硬性注意力通常使用強化學習來進行訓練,
注意力機制可以單獨使用,但更多的是作為神經網路中的一個組件,
1.1.3 注意力機制的變體
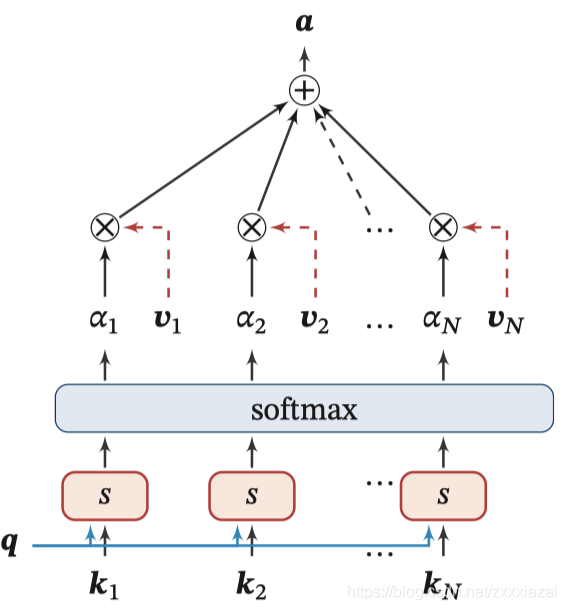
1.1.3. 1 鍵值對注意力
用鍵值對(key-velue pair)格式表示輸入資訊,其中“鍵”用來計算注意力分布 α n \alpha_n αn?,“值”用來計算聚合資訊,
用
(
K
,
V
)
=
[
(
k
1
,
v
1
)
,
?
?
,
(
k
N
,
v
N
)
]
(\boldsymbol{K}, \boldsymbol{V})=\left[\left(\boldsymbol{k}_{1}, \boldsymbol{v}_{1}\right), \cdots,\left(\boldsymbol{k}_{N}, \boldsymbol{v}_{N}\right)\right]
(K,V)=[(k1?,v1?),?,(kN?,vN?)]表示
N
N
N組輸入資訊,給定任務相關的查詢向量
q
\boldsymbol{q}
q時,注意力函式為:
att
?
(
(
K
,
V
)
,
q
)
=
∑
n
=
1
N
α
n
v
n
=
∑
n
=
1
N
exp
?
(
s
(
k
n
,
q
)
)
∑
j
exp
?
(
s
(
k
j
,
q
)
)
v
n
\begin{aligned} \operatorname{att}((\boldsymbol{K}, \boldsymbol{V}), \boldsymbol{q}) &=\sum_{n=1}^{N} \alpha_{n} \boldsymbol{v}_{n} \\ &=\sum_{n=1}^{N} \frac{\exp \left(s\left(\boldsymbol{k}_{n}, \boldsymbol{q}\right)\right)}{\sum_{j} \exp \left(s\left(\boldsymbol{k}_{j}, \boldsymbol{q}\right)\right)} \boldsymbol{v}_{n} \end{aligned}
att((K,V),q)?=n=1∑N?αn?vn?=n=1∑N?∑j?exp(s(kj?,q))exp(s(kn?,q))?vn??
當
K
=
V
\boldsymbol{K}=\boldsymbol{V}
K=V時,鍵值對模式就等價于普通的注意力機制,
鍵值對模式圖示:
1.1.3.2 多頭注意力
Multi-Head Attention 是利用多個查詢
Q
=
[
q
1
,
?
?
,
q
M
]
\boldsymbol{Q}=\left[\boldsymbol{q}_{1}, \cdots, \boldsymbol{q}_{M}\right]
Q=[q1?,?,qM?]來并行地從輸入資訊中選取多組資訊,每個注意力關注輸入資訊的不同部分,
att
?
(
(
K
,
V
)
,
Q
)
=
att
?
(
(
K
,
V
)
,
q
1
)
⊕
?
⊕
att
?
(
(
K
,
V
)
,
q
M
)
\operatorname{att}((\boldsymbol{K}, \boldsymbol{V}), \boldsymbol{Q})=\operatorname{att}\left((\boldsymbol{K}, \boldsymbol{V}), \boldsymbol{q}_{1}\right) \oplus \cdots \oplus \operatorname{att}\left((\boldsymbol{K}, \boldsymbol{V}), \boldsymbol{q}_{M}\right)
att((K,V),Q)=att((K,V),q1?)⊕?⊕att((K,V),qM?)
⊕
\oplus
⊕表示向量拼接,
1.1.3.3 結構化注意力
1.1.3.4 指標網路
注意力機制主要用來做資訊篩選,從輸入資訊中選取相關的資訊,
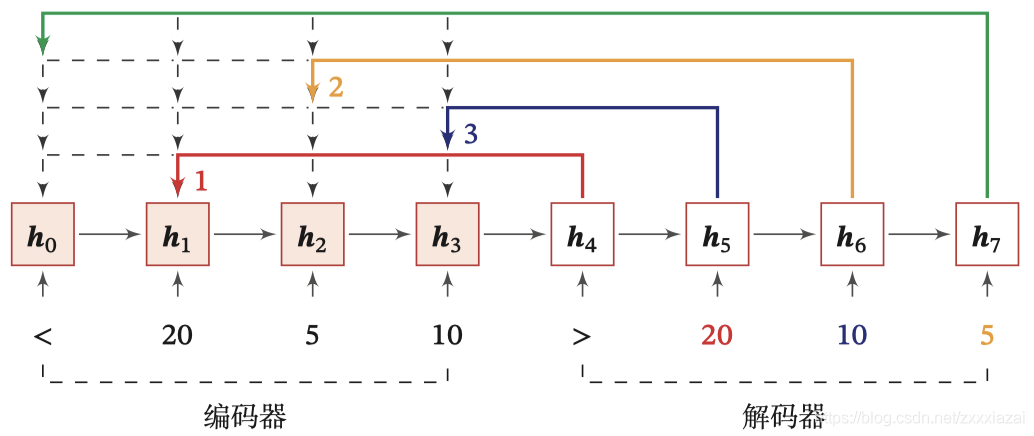
指標網路(Pointer Network)是一種序列到序列模型,輸入是長度為 N N N的向量序列 X = [ x 1 , ? ? , x N ] \boldsymbol{X}=\left[\boldsymbol{x}_{1}, \cdots, \boldsymbol{x}_{N}\right] X=[x1?,?,xN?],輸出是長度為 M M M的下標序列 c 1 : M = c 1 , c 2 , ? ? , c M , c m ∈ [ 1 , N ] , ? m \boldsymbol{c}_{1: M}=c_{1}, c_{2}, \cdots, c_{M}, c_{m} \in[1, N], \forall m c1:M?=c1?,c2?,?,cM?,cm?∈[1,N],?m
和一般的序列到序列的任務不同,這里的輸出序列是輸入序列的下標(索引),比如輸入一組亂序的數字,輸出為按大小排序的輸入數字序列的下標,如輸入 20,5,10,輸出 1,3,2,
條件概率
p
(
c
1
:
M
∣
x
1
:
N
)
p\left(c_{1: M} \mid \boldsymbol{x}_{1: N}\right)
p(c1:M?∣x1:N?)可以寫為
p
(
c
1
:
M
∣
x
1
:
N
)
=
∏
m
=
1
M
p
(
c
m
∣
c
1
:
(
m
?
1
)
,
x
1
:
N
)
≈
∏
m
=
1
M
p
(
c
m
∣
x
c
1
,
?
?
,
x
c
m
?
1
,
x
1
:
N
)
\begin{aligned} p\left(c_{1: M} \mid \boldsymbol{x}_{1: N}\right) &=\prod_{m=1}^{M} p\left(c_{m} \mid c_{1:(m-1)}, \boldsymbol{x}_{1: N}\right) \\ & \approx \prod_{m=1}^{M} p\left(c_{m} \mid \boldsymbol{x}_{c_{1}}, \cdots, \boldsymbol{x}_{c_{m-1}}, \boldsymbol{x}_{1: N}\right) \end{aligned}
p(c1:M?∣x1:N?)?=m=1∏M?p(cm?∣c1:(m?1)?,x1:N?)≈m=1∏M?p(cm?∣xc1??,?,xcm?1??,x1:N?)?其中條件概率
p
(
c
m
∣
x
c
1
,
?
?
,
x
c
m
?
1
,
x
1
:
N
)
p\left(c_{m} \mid \boldsymbol{x}_{c_{1}}, \cdots, \boldsymbol{x}_{c_{m-1}}, \boldsymbol{x}_{1: N}\right)
p(cm?∣xc1??,?,xcm?1??,x1:N?)可以通過注意力分布來計算,假設用一個回圈神經網路對
x
c
1
,
?
?
,
x
c
m
?
1
,
x
1
:
N
\boldsymbol{x}_{c_{1}}, \cdots, \boldsymbol{x}_{c_{m-1}}, \boldsymbol{x}_{1: N}
xc1??,?,xcm?1??,x1:N?進行編碼得到向量
h
m
\boldsymbol{h}_m
hm?,則
p
(
c
m
∣
c
1
:
(
m
?
1
)
,
x
1
:
N
)
=
softmax
?
(
s
m
,
n
)
p\left(c_{m} \mid c_{1:(m-1)}, x_{1: N}\right)=\operatorname{softmax}\left(s_{m, n}\right)
p(cm?∣c1:(m?1)?,x1:N?)=softmax(sm,n?)
其中
s
m
,
n
s_{m,n}
sm,n?為在解碼程序的第
m
m
m步時,
h
m
\boldsymbol{h}_m
hm?對
h
n
\boldsymbol{h}_n
hn?的未歸一化的注意力分布,即
s
m
,
n
=
v
?
tanh
?
(
W
x
n
+
U
h
m
)
,
?
n
∈
[
1
,
N
]
s_{m, n}=\boldsymbol{v}^{\top} \tanh \left(\boldsymbol{W} \boldsymbol{x}_{n}+\boldsymbol{U} \boldsymbol{h}_{m}\right), \forall n \in[1, N]
sm,n?=v?tanh(Wxn?+Uhm?),?n∈[1,N]
其中
v
\boldsymbol{v}
v,
W
\boldsymbol{W}
W,
U
\boldsymbol{U}
U為可學習的引數,
下圖給出了指標網路的實體,其中
h
1
\boldsymbol{h}_1
h1?,
h
2
\boldsymbol{h}_2
h2?,
h
3
\boldsymbol{h}_3
h3?為輸入數字 20,5,10 經過回圈神經網路的隱狀態,
h
0
\boldsymbol{h}_0
h0?對應特殊字符‘<’.當輸入‘>’時,網路一步一步輸出桑輸入數字從大到小排列的下標,
1.2 自注意力機制
雖然回圈網路理論上可以建立長距離依賴關系,但由于資訊傳遞的容量以及梯度消失問題,實際上也只能建立短距離依賴關系,
如果要建立序列之間的長距離依賴關系,可以使用以下兩種方法:
1)增加物理的層數,通過一個深層網路來獲取遠距離的資訊互動;
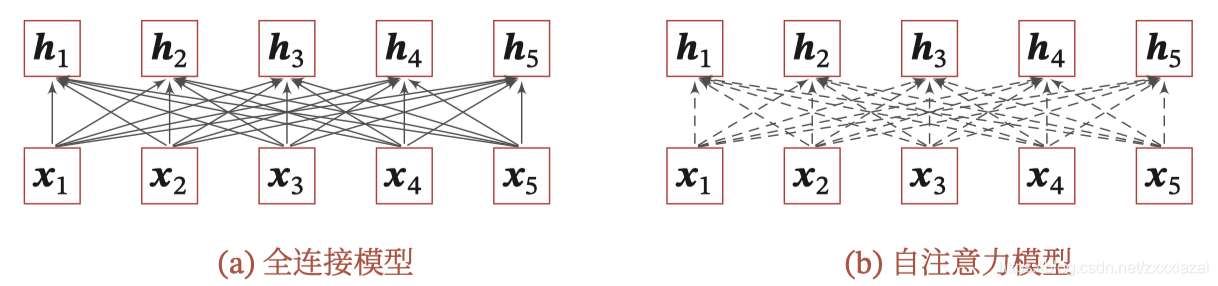
2)使用全連接網路,
全連接網路是一種非常直接的建模遠距離依賴的模型,但是無法處理變長的輸入序列,不同的輸入長度,其連接權重的大小也不同,這時我們可以利用注意力機制來“動態”的生成不同連接的權重,這就是自注意力模型(self-attention model),自注意力模型更容易捕獲中長距離的相互依賴關系,
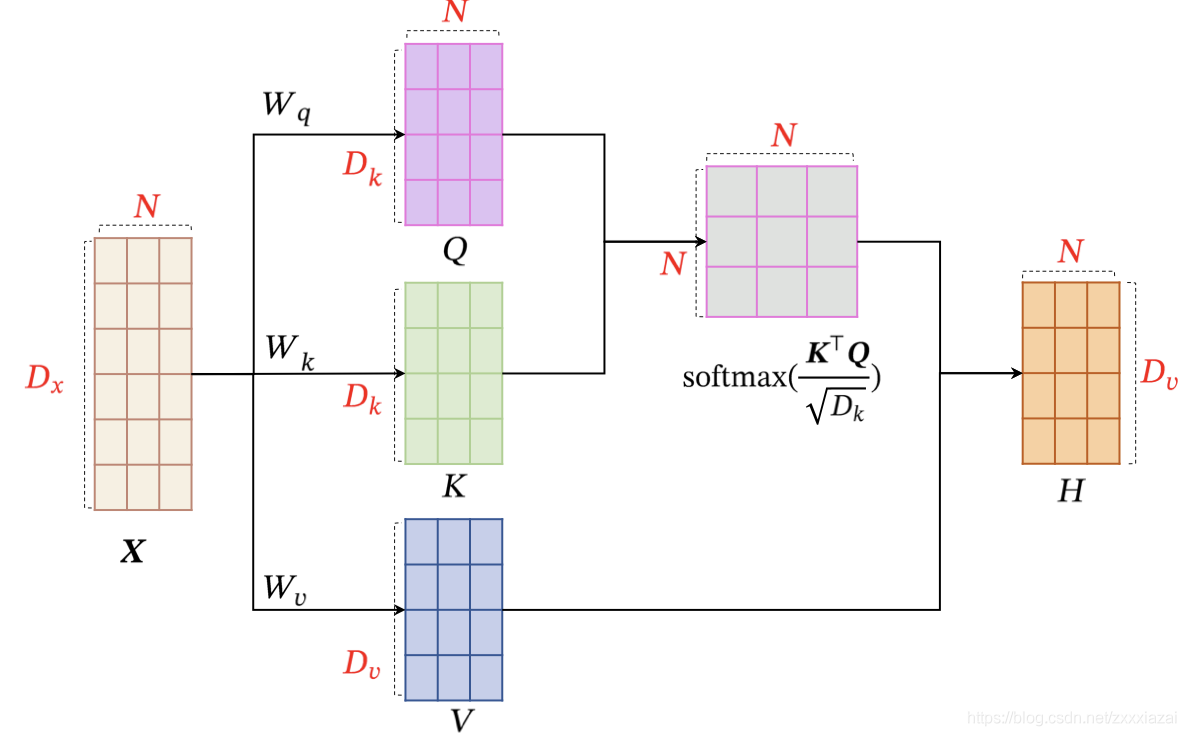
為提高模型能力,自注意力模型經常采用查詢-鍵-值(query-key-velue,QKV)模式,其計算程序如下圖所示,其中紅色字母表示矩陣的維度,
假設輸入序列為
X
=
[
x
1
,
?
?
,
x
N
]
∈
R
D
x
×
N
\boldsymbol{X}=\left[\boldsymbol{x}_{1}, \cdots, \boldsymbol{x}_{N}\right] \in \mathbb{R}^{D_{x} \times N}
X=[x1?,?,xN?]∈RDx?×N,輸出序列為
H
=
[
h
1
,
?
?
,
h
N
]
∈
R
D
v
×
N
\boldsymbol{H}=\left[\boldsymbol{h}_{1}, \cdots, \boldsymbol{h}_{N}\right] \in \mathbb{R}^{D_{v} \times N}
H=[h1?,?,hN?]∈RDv?×N,自注意力模型的具體計算程序如下:
1)對于每個輸入
x
i
\boldsymbol{x}_{i}
xi?,我們首先將其線性映射到三個不同的空間,得到查詢向量KaTeX parse error: Expected '}', got 'EOF' at end of input: …athbb{R}^{D_{k}、鍵向量
k
i
∈
R
D
k
\boldsymbol{k}_{i} \in \mathbb{R}^{D_{k}}
ki?∈RDk?和值向量
v
i
∈
R
D
v
\boldsymbol{v}_{i} \in \mathbb{R}^{D_{v}}
vi?∈RDv?,
對于整個輸入序列
X
\boldsymbol{X}
X,線性映射程序可以簡寫為
Q
=
W
q
X
∈
R
D
k
×
N
K
=
W
k
X
∈
R
D
k
×
N
V
=
W
v
X
∈
R
D
v
×
N
\begin{array}{l}\boldsymbol{Q}=\boldsymbol{W}_{q} \boldsymbol{X} \in \mathbb{R}^{D_{k} \times N} \\ \boldsymbol{K}=\boldsymbol{W}_{k} \boldsymbol{X} \in \mathbb{R}^{D_{k} \times N} \\ \boldsymbol{V}=\boldsymbol{W}_{v} \boldsymbol{X} \in \mathbb{R}^{D_{v} \times N}\end{array}
Q=Wq?X∈RDk?×NK=Wk?X∈RDk?×NV=Wv?X∈RDv?×N?
其中
W
q
∈
R
D
k
×
D
x
,
W
k
∈
R
D
k
×
D
x
,
W
v
∈
R
D
v
×
D
x
\boldsymbol{W}_{q} \in \mathbb{R}^{D_{k} \times D_{x}}, \boldsymbol{W}_{k} \in \mathbb{R}^{D_{k} \times D_{x}}, \boldsymbol{W}_{v} \in \mathbb{R}^{D_{v} \times D_{x}}
Wq?∈RDk?×Dx?,Wk?∈RDk?×Dx?,Wv?∈RDv?×Dx?分別為線性映射的引數矩陣,
Q
=
[
q
1
,
?
?
,
q
N
]
,
K
=
[
k
1
,
?
?
,
k
N
]
,
V
=
[
v
1
,
?
?
,
v
N
]
\boldsymbol{Q}=\left[\boldsymbol{q}_{1}, \cdots, \boldsymbol{q}_{N}\right], \boldsymbol{K}=\left[\boldsymbol{k}_{1}, \cdots, \boldsymbol{k}_{N}\right], \boldsymbol{V}=\left[\boldsymbol{v}_{1}, \cdots, \boldsymbol{v}_{N}\right]
Q=[q1?,?,qN?],K=[k1?,?,kN?],V=[v1?,?,vN?]分別由查詢向量、鍵向量和值向量構成的矩陣,
2)對于每一個查詢向量
q
n
\boldsymbol{q}_{n}
qn?利用鍵值對注意力機制,可以得到輸出
h
n
\boldsymbol{h}_{n}
hn?
h
n
=
att
?
(
(
K
,
V
)
,
q
n
)
=
∑
j
=
1
N
α
n
j
v
j
=
∑
j
=
1
N
softmax
?
(
s
(
k
j
,
q
n
)
)
v
j
\begin{aligned} \boldsymbol{h}_{n} &=\operatorname{att}\left((\boldsymbol{K}, \boldsymbol{V}), \boldsymbol{q}_{n}\right) \\ &=\sum_{j=1}^{N} \alpha_{n j} \boldsymbol{v}_{j} \\ &=\sum_{j=1}^{N} \operatorname{softmax}\left(s\left(\boldsymbol{k}_{j}, \boldsymbol{q}_{n}\right)\right) \boldsymbol{v}_{j} \end{aligned}
hn??=att((K,V),qn?)=j=1∑N?αnj?vj?=j=1∑N?softmax(s(kj?,qn?))vj??
其中
n
,
j
∈
[
1
,
N
]
n,j\in[1,N]
n,j∈[1,N]為輸出和輸入向量序列的位置,
α
n
j
\alpha_{nj}
αnj?表示第
n
n
n個輸出關注到第
j
j
j個輸入的權重,
如果使用縮放點積來作為注意力打分函式,輸出向量序列可以簡寫為
H
=
V
softmax
?
(
K
?
V
D
k
)
\boldsymbol{H}=\boldsymbol{V} \operatorname{softmax}\left(\frac{\boldsymbol{K}^{\top} \boldsymbol{V}}{\sqrt{D_{k}}}\right)
H=Vsoftmax(Dk?
?K?V?)
其中 softmax(·)為按列進行歸一化的函式,
下圖為全連接模型和自注意力模型的對比,實線表示可學習的權重,虛線表示動態生成的權重,由于自注意力模型的權重是動態生成的,因此可以處理變成的資訊序列,
一個有助于理解的延伸閱讀:詳解Transformer (Attention Is All You Need),
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/258422.html
標籤:其他