本系列文章將整理各個流媒體傳輸協議,包括 RTP/RTCP,RTMP,希望通過深入梳理協議的設計細節,能夠給流媒體領域的開發者帶來一定的啟發,
作者:逸殊
審核:泰一
接上篇:《 流媒體傳輸協議之 RTP(上篇)》
RTP 控制協議
Sender & Receiver 報告
RTP 使用 Sender 報告(SR)和 Receiver 報告(RR)來反饋資料的接收質量,如果是媒體資料的發送者那就會發送 SR,否則發送 RR,這兩類報文是通過頭部的報文型別識別碼來做區分的,SR 相對于 RR 來說多了 20byte 的 Sender 相關資訊,除此之外其他內容都是一樣的,
SR 報文

SR 報文包含三個部分,第一個部分是頭部,有 8 BYTE,各個欄位的含義如下:
- version (V): 2 bits,RTP 協議版本,
- padding (P): 1 bit,是否包含填充,最后一個填充位元組標識了總共需要忽略多少個填充位元組(包括自己),Padding 可能會被一些加密演算法使用,因為有些加密演算法需要定長的資料塊,在復合包中,只有最后一個 RTCP 包需要添加填充,
- reception report count (RC): 5 bits,有多少個接收報告,可以為 0,
- packet type (PT): 8 bits,200 表示 SR 報文,
- length: 16 bits,報文長度(按 32-bit 字統計),包含頭部和填充位元組,
- SSRC: 32 bits,身份定位符,
第二部分是發送者資訊,包含 20 BYTE 的資料,總結了這個發送的的傳輸統計,各個欄位的含義如下:
- NTP timestamp: 64 bits,Wallclock time,用于計算 RTT,
- RTP timestamp: 32 bits,RTP 時間戳,基于 NTP 的某一隨機偏移量,用于媒體資料內同步,
- sender's packet count: 32 bits,這個 SSRC 總共發送了多少包,
- sender's octet count: 32 bits,這個 SSRC 總共發送了多少 BYTE 的資料,
第三部分可能什么都沒有,也可能有多個接收報告,這取決的上次報告以后收到了多少個 Sender 的資料,每個報告塊統計了一個 SSRC 的包數,具體內容如下:
- SSRC_n (source identifier): 32 bits,這個資訊塊對應的 SSRC,
- fraction lost: 8 bits,上次 SR 或 RR 發送后到目前為止的丟包率,
- cumulative number of packets lost: 24 bits,整體程序的丟包總數,
- extended highest sequence number received: 32 bits,低 16-bit 是收到的最新的 RTP 報文序列號,高 16-bit 是序列號回圈的次數,
- interarrival jitter: 32 bits,RTP 資料報文抵達時間的抖動,如果 Si 代表 i 包中包含的 RTP 時間戳,Ri 代表 i 包被接收時的 RTP 時間戳,那兩個包 i 和 j 的到達時間抖動演算法如下::D(i,j) = (Rj - Ri) - (Sj - Si) = (Rj - Sj) - (Ri - Si),我們在計算這個抖動時,要結合每個包的抖動,來計算一個平均值,計算平均值的方案如下:J(i) = J(i-1) * (15 / 16) + (|D(i-1,i)|)/16,
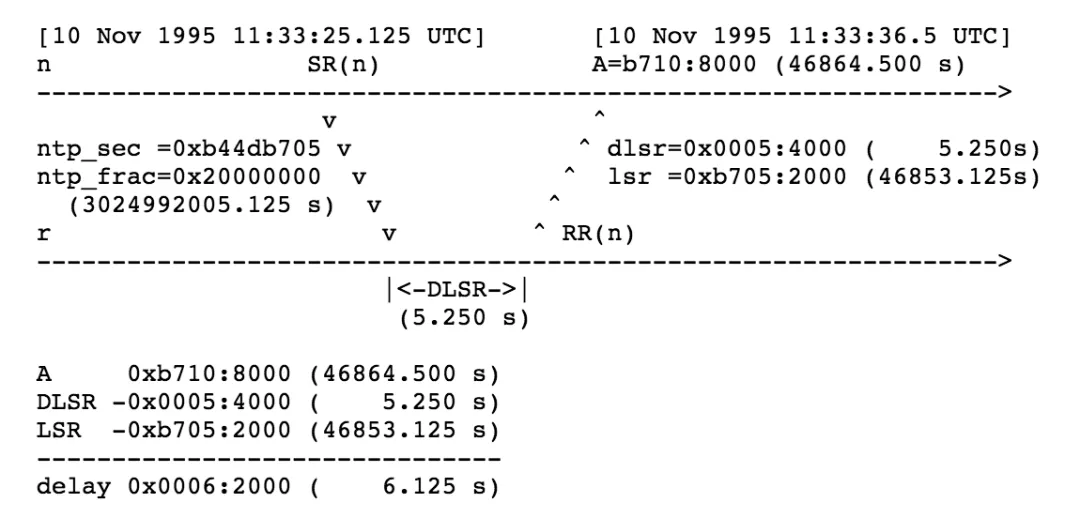
- last SR timestamp (LSR): 32 bits,該 SSRC 最后一個 RTCP 報文(SR)中帶的 NTP 時間,
- delay since last SR (DLSR): 32 bits,從該 SSSR 最后一個 RTCP 報文(SR)被收到以來經過的時間,
資料的發送者可以通過當前時間 A,接收到 RR 部分中的 LSR 和 DLSR 來計算 RTT,計算示意圖如下:
RR 報文

接收報告的格式和發送報文格式一樣,只不過它在頭部中用 201 表示這是一個 RR 報文,此外 RR 報文中不含有上述 SR 報文中的第二部分,如果 RR 報文是空的那么需要在頭部標明 RC=0,
發送 / 接收報文的拓展
一些預設可能根據自己的需求,要在接收報告和發送報告中附加一些資訊,那么這些附加內容應該在 SR 或者 RR 的結尾之后,如果這些內容只有發送者相關,那么 RR 中就不包含這些資訊,
分析發送報告和接收報告
這些接收質量的報告資訊可能不光只有發送者要使用,接收者或者第三方監控器也會使用,發送者可能根據接收質量調整自己的傳輸策略,接收者可以根據這個資訊來確定自己遇到的問題是本地網路的問題還是整個 Session 的問題,網路的管理者可以根據這些資訊來評估整個網路環境的情況,
SDES 報文
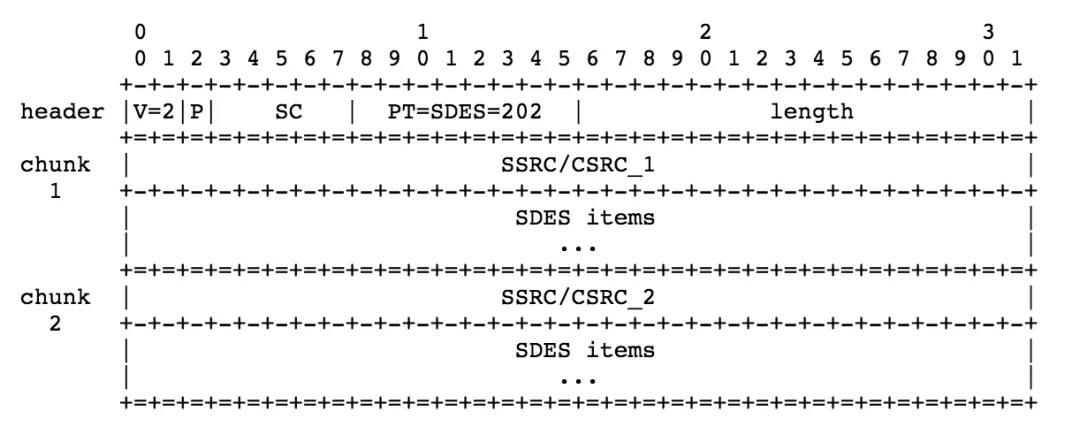
SDES 是一個三級結構,它包含一個頭和 0 個或多個資料塊,每一個資料塊對應了一個 SSRC 或 CSRC,它又由多個描述欄位組成,頭部的資訊如下:
- version (V),padding (P),length: 和上面一樣,
- packet type (PT): 8 bits,202 表示 SDES 型別,
- source count (SC): 5 bits,SSRC/CSRC 塊的數量,
每一個塊中都包含多個描述內容,這些描述內容都是 32-bit 對齊的,其中前 8-bit 描述了型別,接著 8-bit 描述了資訊長度(不包含前 16-bit),然后資訊內容,注意資訊部分不能超過 255 BYTE,這和前面的很多作業類似是為了約束 RTCP 的帶寬,
描述的文本內容是 UTF-8 編碼的,如果要使用多位元組的編碼,需要在醒目的地方表示用的什么的編碼,
各個描述部分是沒有中間分隔的,所以要用空位元組來填充以達到對齊的效果,注意這里的填充和 RTCP 頭部的 P 不是一個概念,
末端節點發送的 SDES 包含他自己的資料源標識,而 Mixer 發送的 SDES 包含多個 CSRC,如果 CSRC 的數量超過了 31 個,會拆分成多個 SDES 報文,
SDES 的所有型別會在后面一一介紹,其中只有 CNAME 是強制要有的,可能有一些型別的的描述只有部分預設才會使用,但是這些內容都是在一個共通的地方來記載,以防止不同的預設使用的描述型別發生沖突,如果要注冊新的型別,需要通過 IANA 注冊,
CNAME:權威的末端節點身份標識

CNAME 有如下特征:
- 因為 SSRC 在許多意外情況下會重新生成,所以 CNAME 被用來系結舊的 SSRC 和新的 SSRC,來保持資料源的連續,
- 和 SSRC 一樣,CNAME 也需要保證唯一性(同一個 Session 中),
- 為了讓同一個參與者的多個 SSRC 系結在一起,我們需要 CNAME 是固定的,
- 為了讓第三方監控用起來方便,CNAME 應該即方便程式使用,也要設計成可讀的,可以根據它確認來源,
因此 CNAME 應該通過演算法來生成而不是手動生成,為了滿足如上需要,一般來說是按照如下的格式來描述 CNAME:
- "user@host" eg: "[email protected]" or "doe@2201:056D::112E:144A:1E24".
- "host", 如果是單用戶系統,獲取不到 user 時只使用 host,eg: "sleepy.example.com","192.0.2.89" or "2201:056D::112E:144A:1E24".
有些人可能會發現,如果上述的 host 使用的是子網地址的話,就沒辦法保證整個 Session 的唯一性了,通常這類沒有直接 IP 的使用者是通過一個 RTP 級別的 Translator 來訪問公共網路,這個 Translator 會處理從私有地址到公網地址的轉換作業,
NAME:用戶名

這個是描述資料源的真實名字,eg:"John Doe, Bit Recycler",整個 Session 程序中希望這個值不變,全 Session 不需要唯一,
EMAIL:電子郵箱地址

電子郵箱地址,eg: "[email protected]",整個 Session 程序中希望這個值不變,
PHONE:電話號碼

電話號碼需要以國際訪問碼開頭,eg: "+1 908 555 1212",
LOC:用戶地理地址

視應用不同,詳細程度會各不相同,
TOOL:應用名或工具名

帶版本號的應用名,可以用來 DEBUG,
NOTE:提醒 / 狀態

用來發送暫時性的訊息描述當前狀態,eg: "on the phone, can't talk",
PRIV:自定義拓展

上層應用自定義的格式,一般都是用過一個前綴描述訊息型別,然后后面跟著訊息正文,
BYE 報文
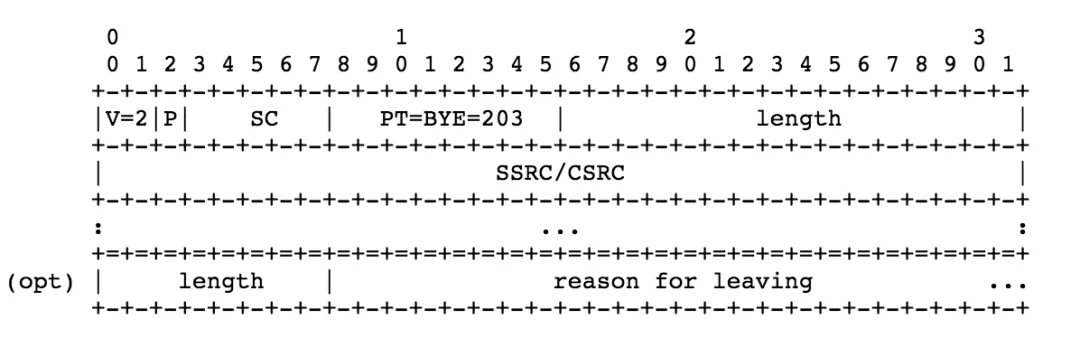
BYE 報文表示一個或多個流媒體源不再活躍,
- version (V),padding (P),length: 同上,
- packet type (PT): 8 bits,203 表示 BYE 報文,
- source count (SC): 5 bits,退出 Session 的 SSRC 的數量,
如果 BYE 報文被 Mixer 收到了,Mixer 應該啥都不改動,就發給下一節點,如果 Mixer 關閉了,它要發送一個包含它管理的所有 SSRC 的 BYE 報文,BYE 報文中可能也會跟著帶一些離開原因的描述,這些描述和 SDES 中帶的描述類似,需要 32-bit,用空位元組填補空缺,
APP:應用定義的 RTCP 報文
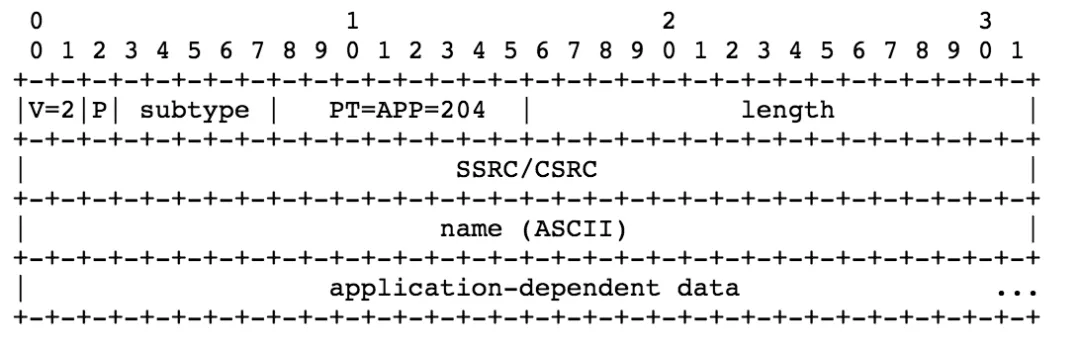
APP 報文一般用于實驗性的功能和開發,如果識別到了不認識 NAME 那么上層應用一般都會忽略它,如果開發或者測驗功能穩定了,一般是要通過 IANA 注冊一個新的 RTCP 報文型別,
- version (V),padding (P),length: 同上,
- subtype: 5 bits,APP 報文子型別,一般是上層應用定義,
- packet type (PT): 8 bits,204 表示 APP 型別的 RTCP 報文,
- name: 4 octets 一般是應用名,防止 subtype 沖突,
- application-dependent data: variable length 和上層應用相關的內容,需要 32-bit 對齊,
RTP Translator & Mixer
作為末端節點的補充,RTP 引入了 Translator 和 Mixer 的概念,它們是 RTP 層的中間件,雖然這多少增加了協議的復雜度,但是對音視頻通話應用來說它們還是很關鍵的,因為它們能解決防火墻問題和低帶寬連接的問題,
描述
一個 RTP Translator/Mixer 連接至少兩個傳輸層的用戶組,通常來說,這里提到的用戶組是公共網路的概念,傳輸層協議會為其生成一個組播地址(ip:port),網路層協議,像是 IPv4 和 IPv6 對 RTP 協議來說是隱藏的,一個系統可能會有多個 Translator 和 Mixer(多個 Session),它們中的每一個都可以看作是一個用戶組的邏輯分割,
為了避免創建在創建 Translator 和 Mixer 造成了網路包回圈,必須遵循下列規則:
- 每個通過連接 Translator 和 Mixer 而加入 Session 的用戶組,要么需要網路層隔離,要么最少互相知道這些引數(protocol,address,port)中的一個,
- 由上一個規則推廣的話,各個用戶組絕對不能同時連接多個 Translator 或者 Mixer,除非有某種機制能保證他們之間資料被阻斷,
Translator:在不改變 RTP 報文 SSRC 的條件下,向后傳播該報文,正因為如此,報文的接收者才能識別到 Translator 轉發后的報文到底是來自哪個人,有些 Translator 可能直接轉發報文,不做任何改動,也有可能改變資料編碼,payload 型別和時間戳,
如果多個資料報文被重新編碼并合并到一起的話,Translator 必須為這類報文指定一個組新的序列號,這樣,輸入報文的丟失就會導致輸出報文的斷層,資料的接收者一般是不知道 Translator 的存在的,除非通過 payload 型別的不同或者傳輸層報文的源地址來判斷,
Mixer:從一個或多個資料源那里接收資料,隨后可能會改變資料的格式,然后將這些資料合并,并傳遞給下家,因為多個資料源的時序并不一定是同步的,所以 Mixer 需要整合各個資料源的時序關系,并將其映射到自己的一套時序上,所以 Mixer 也是一個 SSRC,所有通過 Mixer 的報文必須打上該 Mixer 的 SSRC,
為了表示這些資料的原始資料源,一般會通過 CSRC 串列來記錄,有些 Mixer 可能自己也是一個原始資料源,所以他自己的 SSRC 也會出現在 CSRC 串列中,有些應用可能不希望 Mixer 的 SSRC 出現在 CSRC 中,但是這樣可能就無法發現回圈網路包,
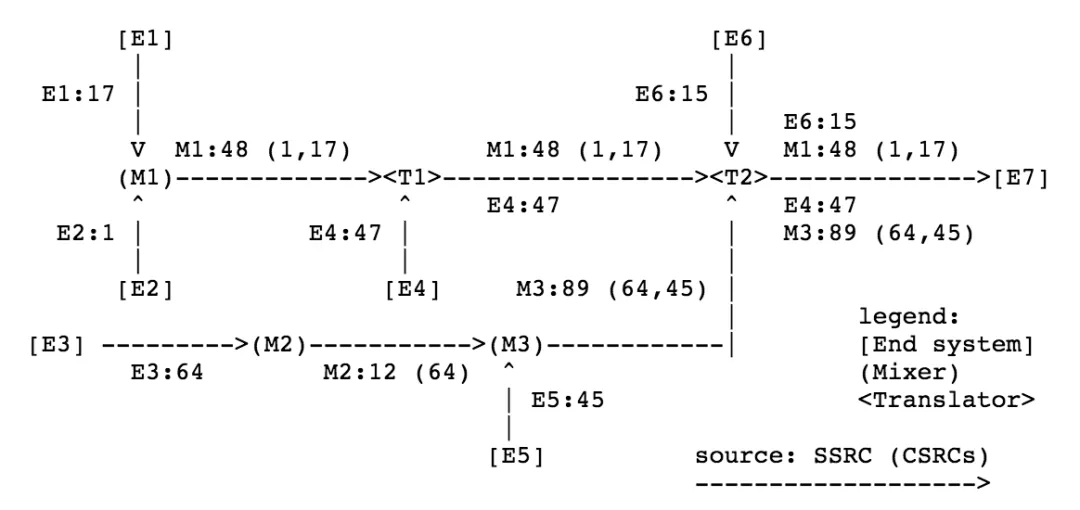
上圖是一個 Mixers 和 Translators 連接的例子,[] 代表末端節點,() 代表 Mixer,<> 代表 Translator,"M1:48 (1, 17)" 表示 Mixer1 的報文,48 是 Mixer1 的 SSRC,括號里的 1,17 是 CSRC,它合并了 E1:17 和 E2:1 這兩個節點的資料,
Translator 處理 RTCP
除了要轉發資料包,進行資料包的更改,Translator 和 Mixer 也要發送 RTCP 報文,在很多情況下,它會將收到的末端節點的 RTCP 報文合并到復合包中,當再次收到這些包時或者自己的 RTCP 周期到時,它會將復合包發送出去,
有的 Translator 可能對收到的 RTCP 報文不做任何改動,只是簡單的轉發這個包,如果這個 Translator 改變了報文資料的 payload,它必須對 SR 或者 RR 做相關的改動,通常來說,Translator 不能將多個資料源的 SR 和 RR 合并,因為這樣會導致 RTT 的計算出現問題(RTT 根據 LSR 和 DLSR 計算),
- SR 中的發送者資訊: Translator 不會創建自己的發送者資訊,它會將收到 SR 傳給下家,其中 SSRC 不會發生任何改動,但是發送者資訊有必要的話一定要做適當的改動,如果 Translator 改變了資料編碼,那 "byte count" 欄位就要更改,如果他將多個資料報文合并,那它需要修改 "sender's packet count" 欄位,如果它改變了時間頻率,那就需要修改 "RTP timestamp",
- SR/RR 中的接收者資訊:SSRC 不會發生任何改動,如果 Translator 改變了序列號,那就需要修改 "extended last sequence number",在某些極端情況下,它可能完全沒有接收反饋,或者根據接收到的 SR/RR 來構建自己的接收報告,一般情況下 Translator 是不需要自己的 SSRC 的,但是如果是為了表示自己的資料接收情況,它可能也會生成自己的 SSRC,并將這些 RTCP 報文發送過所有的連接者,
- SDES:一般 Translator 收到 SDES 后會什么都不改就發給下家,但是也有可能為了節約帶寬篩掉 CNAME 之外的資訊的,如果 Translator 要發送自己的 RR 資訊,那它一定要發送一個自己的 SDES 給所有連接者,
- BYE:無改動轉發,如果 Translator 有自己的 SSRC 也要發送自己的 BYE,
- APP:無改動轉發,
Mixer 處理 RTCP
因為 Mixer 會生成自己的資料流,所以他不會轉發經過他的 SR 和 RR 而是為連接雙方發送自己的 SR 和 RR 報文,
- SR 的發送者資訊:Mixer 不轉發資料來源的發送資訊,它會生成自己的發送者資訊并把它發送給下家,
- SR/RR 中的接收者資訊:Mixer 會生成自己的接收資訊,然后發送給所有資料來源,它絕對不能做接收報告的轉發作業,或者把自己的接收資訊發給錯誤的物件,
- SDES:Mixers 通常會不做任何改動就轉發 SDES 資訊,但是也有可能為了節約帶寬過濾除了 CNAME 之外的其他資訊,Mixer 必須發送自己的 SDES 報文,通常,Mixer 會將多個收到的 SDES 打包一起發送,
- BYE:Mixer 必須轉發 BYE 報文,如果 Mixer 要退出時,它會將所有資料來源的 SSRC 放進 BYE 報文,也包括自己的 SSRC,
- APP:視上層應用,
瀑布型 Mixer
一個 RTP Session 可能包含多個 Mixer 和 Translator,就像上圖一樣,如果 Mixer 是瀑布型的,就像 M2 和 M3,一個 Mixer 收到的資料可能是已經合并過的,它有自己的 CSRC 串列,那么第二個 Mixer 需要將之前的 CSRC 和自己接收的所有 SSRC 合并,就像圖中 M3 的輸出是 M3:89 (64,45),
SSRC 的分配和使用
前面已經說過 SSRC 是一個隨機的 32-bit 數,它需要在整個 Session 內保證唯一性,所以同一個網路下的參與者在剛加入 Session 時使用不同的 SSRC 至關重要,
我們不能簡單的用本地的網路地址,因為可能不唯一,也不能不考慮初始狀態而簡單地調一個亂數函式,
碰撞的可能性
因為 SSRC 是隨機選擇的,這就可能多個資料源選用了相同的 SSRC,如果大家是同時加入 Session 的話,這個碰撞的幾率就更高,如果 SSRC 的數量是 N,L 是 SSRC 的資料長度(這里是 32),那么碰撞的可能性是 1 - exp(-N2 / 2(L+1)),當 N=1000 時,碰撞率大概是 10**-4,
通常來說,實際的碰撞率會比上述的最壞情況要低,通常一個新節點加入時,其他節點已經有了自己的唯一 SSRC,這時候碰撞的概率只是生成的新 SSRC 在這些現有 SSRC 之中的可能性,這時候碰撞率是 N/2**L,當 N=1000 時,碰撞率大約是 2*10**-7,
因為新加入的節點會先接收一段時間的報文然后才發送自己的第一個報文,所以在它生成 SSRC 時可以避開已知的 SSRC,這也有效的降低了碰撞的幾率,
碰撞的解決方案和回圈的發現
通常來說 SSRC 碰撞的可能性很小,所有的 RTP 實作必須有發現沖突的機制,并在發現沖突時作出適當的處理,如果資料源發現了任何一個別的資料源和自己使用同一個 SSRC,它必須用原來的 SSRC 發送一個 BYE 報文,然后選用一個新的 SSRC,如果一個資料的接收者發現了多個資料源的 SSRC 碰撞了(通過傳輸地址或者 CNAME),那么它會只接收其中一個人的報文,丟棄另一個人的所有報文,
因為整個 Session 中的 SSRC 是唯一的,所以它也可以被用來發現環型報文,環形報文會導致資料的重復以及控制資訊的重復,
- Translator 可能會錯誤地將報文發送回該報文來的地方,
- 兩個 Translator 錯誤地同時啟動,它們兩個都會轉發同樣的資料,
- Mixer 可能會錯誤地將合并報文發送回這些報文來的地方,
一個資料源可能發現自己的或者別人的報文被回圈發送了,無論是報文回圈還是 SSRC 的碰撞都會導致同一個現象,即 SSRC 相同但是傳輸地址不同的報文,因此,如果資料源改變了自己的傳輸地址,那它就需要同時改變自己的 SSRC 來避免被檢測成環形報文,有一個需要注意的內容是,如果一個 Translator 再重啟的程序中改變了自己的傳輸地址,那么這個 Translator 轉發的所有資料都會被檢測成環,這類情況的解決方案一般有如下兩個:
- 重啟的時候不改變傳輸地址,
- 接收者的超時機制,
如果回圈或者碰撞發生在離 Translator 和 Mixer 很遠的地方,我們就不能通過傳輸地址來發現,但是我們仍然可以通過 CNAME 的不同來發現 SSRC 碰撞,
為了解決上述問題,RTP 的實作必須包含一個類似如下的演算法,這個演算法不包括多個資料源 SSRC 碰撞的情況,這類情況通常下都是先用原來的 SSRC 發送一個 BYE 然后重新選擇一個新的 SSRC,
這個演算法需要維護一個 SSRC 和傳輸地址的映射關系,因為 RTP 的資料和 RTCP 傳輸使用的是兩個不同的埠,所以一個 SSRC 對應的是兩個傳輸地址,
每次收到 RTP 報文和 RTCP 報文都會將其 SSRC 和 CSRC 在上述的表中進行比對,如果發現了傳輸地址對不上的情況,我們就可以說發現了一個回圈或者碰撞,對于 RTCP 資料來說,可能每個資料塊都有自己獨立的 SSRC,比如 SDES 資料,對于這種情況就需要分別比對,如果沒有在表中找到這個 SSRC 或者 CSRC,就需要新添加一項,當收到 BYE 報文時,需要先比對這個 BYE 的傳輸地址,如果傳輸地址匹配上了,就將這一項從表中洗掉,或者基于超時機制,將超時的資料從表中移除,
為了追蹤自己的資料報文回圈情況,必須維護另一個串列,這個表存盤沖突報文的傳輸地址和收到該報文的時間,如果超過 10 個 RTCP 周期都沒有收到這個傳輸地址的沖突報文,就將該項從表中洗掉,
下面的演算法還假設參與者自己的 SSRC 和狀態都包含在 SSRC 表中,它會先比對自己的 SSRC,
if (SSRC or CSRC identifier is not found in the source
identifier table) {
create a new entry storing the data or control source
transport address, the SSRC or CSRC and other state;
}
/* Identifier is found in the table */
else if (table entry was created on receipt of a control packet
and this is the first data packet or vice versa) {
store the source transport address from this packet;
}
else if (source transport address from the packet does not match
the one saved in the table entry for this identifier) {
/* An identifier collision or a loop is indicated */
if (source identifier is not the participant's own) {
/* OPTIONAL error counter step */
if (source identifier is from an RTCP SDES chunk
containing a CNAME item that differs from the CNAME
in the table entry) {
count a third-party collision;
} else {
count a third-party loop;
}
abort processing of data packet or control element;
/* MAY choose a different policy to keep new source */
}
/* A collision or loop of the participant's own packets */
else if (source transport address is found in the list of
conflicting data or control source transport
addresses) {
/* OPTIONAL error counter step */
if (source identifier is not from an RTCP SDES chunk
containing a CNAME item or CNAME is the
participant's own) {
count occurrence of own traffic looped;
}
mark current time in conflicting address list entry;
abort processing of data packet or control element;
}
/* New collision, change SSRC identifier */
else {
log occurrence of a collision;
create a new entry in the conflicting data or control
source transport address list and mark current time;
send an RTCP BYE packet with the old SSRC identifier;
choose a new SSRC identifier;
create a new entry in the source identifier table with
the old SSRC plus the source transport address from
the data or control packet being processed;
}
}
層級編碼
對于不同 Session 的層級編碼傳輸,一般都是所有層都使用同一個 SSRC,如果其中某一層發現了 SSRC 沖突,那么只改變這一層的 SSRC,而且他層的 SSRC 不做改變,
安全
下層協議可能會提供 RTP 應用所需要的所有安全服務,包括認證,資料完整性,資料保密性,這些服務在 IP 協議中都有解決方案,因為 Audio 和 Video 初始化程序中需要資料加密,而這時候 IP 協議這一層的安全服務還沒有提供,所以,RTP 需要實作一個 RTP 專用的保密服務,這個保密服務是非常輕量級的,而且保密部分的服務向后兼容,以后可以隨時進行更換,或者,某些預設會提供這部分加密服務,比如 SRTP(Secure Real-time Transport Protocol),SRTP 是基于 Advanced Encryption Standard (AES) 提供了一個比 RTP 默認加密服務更強大的實作,
保密性
保密性是指我們的報文只希望一些特定的接收者可以解碼成明文,而其他人只能得到無用的資訊,保密性是通過加密編碼來提供的,
當需要為 RTP 和 RTCP 報文提供加密服務時,所有傳輸的內容都會在下層報文那里進行加密,對于 RTCP 來說,需要一個 32-bit 的亂數作為前綴,而 RTP 報文不需要前綴,取而代之的是隨機序列號和時間戳偏移,因為隨機部分很少,所以可以說這是一個非常弱的初始向量,此外,SSRC 也可被破解者修改,這是這個加密方案的另一個薄弱的環節,
對于 RTCP 來說,可能會將一個復合包分成兩批,第一批加密,后一批明文發送,例如,SDES 部分的資訊可能加密,而接收報告部分不加密就發送出去,因為只有這樣那些第三方監控器才能在不知道密鑰的情況下統計網路狀況,如下圖所示,SDES 資訊必須跟在一個空的 RR 后,并且要有一個隨機前綴,
RTP 協議使用的 Data Encryption Standard (DES) 演算法,使用 cipher block chaining (CBC) 模式,這需要資料填充到 64-bit 對齊,密碼演算法使用零作為初始向量,因為 RTCP 報文中已經有一個隨機前綴了,

RTP 之所以選擇這個默認協議是因為它用起來很容易,但是因為 DES 太容易破解了,所以推薦預設中使用更健壯的加密演算法來替換這個默認方案,例如 Triple-DES,這些演算法普遍需要一個隨機初始化塊,RTCP 使用了 32-bit 的亂數作為前綴,RTP 使用了時間戳和序列號的隨機偏移,可是相鄰的 RTP 報文之間的隨機性就很差,需要注意的是,無論是 RTCP 還是 RTP,它們的隨機性都有限,加密型更好的應用,需要考慮更多的保密措施,例如 SRTP 組態檔,就基于 AES 來加密,它的加密方案就更完備,選擇這個預設來使用 RTP 就挺不錯的,
前面提到過也可以用 IP 級的加密方案或者 RTP 級的加密,一些預設可能會定義別的 payload 型別來加密,這種方案,可能只加密 payload 部分而頭部分使用明文,因為只有 payload 部分才是應用真正需要的內容,這可能對硬體設備來說非常有用,它既處理解密程序,又處理解碼程序,
身份認證和訊息完整性
RTP 協議這一層沒有身份認證和訊息完整性服務,因為有些上層服務可能沒有認證就能使用,而訊息完整性服務依賴下層協議來實作,
RTP 下的網路層和傳輸層協議
RTP 需要下層協議提供多路復用機制,對于 UDP 這類應用,推薦 RTP 應該使用一個偶數埠傳輸資料,和它相關的 RTCP 流應該是用高一位的奇數埠,在單播模式下,每個參與者都需要一對埠來傳輸 RTP 和 RTCP 報文,兩個參與者可能使用相同的埠,絕對不能以接收到的報文網路地址直接作為目標地址發送報文,
建議層編碼模式是,使用相鄰的埠,因此對于層 N 來說,資料埠是 P+2N,控制埠是 P+2N+1,對于 IP 組播來說,可能不會得到相鄰的組播地址,
RTP 資料報文沒有描述報文長度的資訊,所以 RTP 報文依賴下層協議提供長度標識,所以一個 RTP 報文的最大長度由下層協議限制,
如果 RTP 報文使用的下層協議是流傳輸協議的話,必須定義一套資料幀分割機制,
參考
[1] rfc3550
閱讀作者的更多文章,關注作者個人公眾號:貝貝貓技術分享
作者的個人博客:https://www.beikejiedeliulangmao.top/
「視頻云技術」你最值得關注的音視頻技術公眾號,每周推送來自阿里云一線的實踐技術文章,在這里與音視頻領域一流工程師交流切磋,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/258618.html
標籤:其他
上一篇:C#高級篇——初識LINQ
下一篇:人生,就是一場孤獨的旅行