全部筆記的匯總貼:《百面機器學習》-讀書筆記匯總
強化學習近年來在機器學習領域越來越火,也受到了越來越多人的關注,強化學習是一個20世紀80年代興起的,受行為心理學啟發而來的一個機器學習領域,它關注身處某個環境中的決策器通過采取行動獲得最大化的累積收益,和傳統的監督學習不同,在強化學習中,并不直接給決策器的輸出打分,相反,決策器只能得到一個間接的反饋,而無法獲得一個正確的輸入/輸出對,因此需要在不斷的嘗試中優化自己的策略以獲得更高的收益,從廣義上說,大部分涉及動態系統的決策學習程序都可以看成是一種強化學習,強化學習的應用非常廣泛,包括博弈論、控制論、優化等多個不同領域,這兩年,AlphaGo及其升級版橫空出世,徹底改變了圍棋這一古老的競技領域,在業界引起很大震驚,其核心技術就是強化學習,與未來科技發展密切相關的機器人領域,從機器人行走、運動控制,到自動駕駛,都是強化學習的用武之地,
一、強化學習基礎
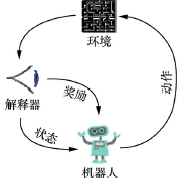
假設我們有一個3×3的棋盤,其中有一個單元格是馬里奧,另一個單元格是寶藏,如圖所示,在游戲的每個回合,可以往上、下、左、右四個方向移動馬里奧,直到馬里奧找到寶藏,游戲結束,在這個場景中,強化學習需要定義一些基本概念來完成對問題的數學建模,

- ★☆☆☆☆ 強化學習中有哪些基本概念?在馬里奧找寶藏問題中如何定義這些概念?
強化學習的基本場景可以用下圖來描述,主要由環境(Environment)、機器人(Agent)、狀態(State)、動作(Action)、獎勵(Reward)等基本概念構成,一個機器人在環境中會做各種動作,環境會接收動作,并引起自身狀態的變遷,同時給機器人以獎勵,機器人的目標就是使用一些策略,做合適的動作,最大化自身的收益,
整個場景一般可以描述為一個馬爾可夫決策程序(Markov Decision Process,MDP),馬爾可夫決策程序是馬爾可夫程序與確定性的動態規劃相結合的產物,指決策者周期地或連續地觀察具有馬爾可夫性的隨機動態系統,序貫地做出決策的程序,以俄羅斯數學家安德雷·馬爾可夫的名字命名,這個程序包括以下幾個要素:
- 動作:所有可能做出的動作的集合,記作A(可能是無限的),對于本題,A=馬里奧在每個單元格可以行走的方向,即{上、下、左、右},
- 狀態:所有狀態的集合,記作S,對于本題,S為棋盤中每個單元格的位置坐標{(x,y); x=1,2,3; y=1,2,3},馬里奧當前位于(1,1),寶藏位于(3,2),
- 獎勵:機器人可能收到的獎勵,一般是一個實數,記作r,對于本題,如果馬里奧每移動一步,定義r=?1;如果得到寶藏,定義r=0,游戲結束,
- 時間(t=1,2,3…):在每個時間點t,機器人會發出一個動作 a t a_t at?,收到環境給出的收益 r t r_t rt?,同時環境進入到一個新的狀態 s t s_t st?,
- 狀態轉移: S × A → S S×A→S S×A→S滿足 P a ( s t ∣ s t ? 1 , a t ) = P a ( s t ∣ s t ? 1 , a t , s t ? 2 , a t ? 1 ? ? ) P_a(s_t|s_{t-1},a_t)=P_a(s_t|s_{t-1},a_t,s_{t-2},a_{t-1}\cdots) Pa?(st?∣st?1?,at?)=Pa?(st?∣st?1?,at?,st?2?,at?1??),也就是說,從當前狀態到下一狀態的轉移,只與當前狀態以及當前所采取的動作有關,這就是所謂的馬爾可夫性,
- 累積收益:從當前時刻0開始累積收益的計算方法是 R = E ( ∑ t = 0 T γ t r t ∣ s 0 = s ) R=E(\sum_{t=0}^T\gamma^tr_t|s_0=s) R=E(∑t=0T?γtrt?∣s0?=s),在很多時候,我們可以取 γ = ∞ \gamma=\infty γ=∞,
強化學習的核心任務是,學習一個從狀態空間S到動作空間A的映射,最大化累積受益,常用的強化學習演算法有Q-Learning、策略梯度,以及演員評判家演算法(Actor-Critic)等,
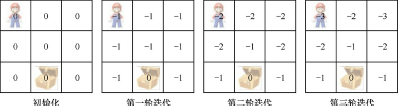
- ★★☆☆☆ 根據上圖給定的馬里奧的位置以及寶藏的位置,從價值迭代來考慮,如何找到一條最優路線?
首先,初始化所有狀態的價值V(s)=0,然后,在每一輪迭代中,對每個狀態s依次執行以下步驟,
- 逐一嘗試{上、下、左、右}四個動作a,記錄到達狀態s′和獎勵r,
- 計算每個動作的價值q(s,a)=r+V(s′),
- 從四個動作中選擇最優的動作 max ? a { q ( s , a ) } \max_a\{q(s,a)\} maxa?{q(s,a)},
- 更新s狀態價值,
在第一輪迭代中,由于初始狀態V(s)均為0,因此對除寶藏所在位置外的狀態s均有V(s)=r+V(s′)=?1+0=?1,即從當前位置出發走一步獲得獎勵r=?1,
在第二輪迭代中,對于和寶藏位置相鄰的狀態,最優動作為一步到達V(s′)=0的狀態,即寶藏所在的格子,因此,V(s)更新為r+V(s′)=?1+0=?1;其余只能一步到達V(s′)=?1的狀態,V(s)更新為r+V(s′)=?1+(?1)=?2,
第三輪和第四輪迭代如法炮制,可以發現,在第四輪迭代中,所有V(s)更新前后都沒有任何變化,價值迭代已經找到了最優策略,最終,只需要從馬里奧所在位置開始,每一步選擇最優動作,即可最快地找到寶藏,
?? \;
上面的迭代程序實際上運用了貝爾曼方程(Bellman Equation),來對每個位置的價值進行更新 V ? ( s ) = max ? a ∑ s ′ , r p ( s ′ , r ∣ s , a ) [ r + γ V ? ( s ′ ) ] V_*(s)=\max_a\sum_{s',r}p(s',r|s,a)[r+\gamma V_*(s')] V??(s)=amax?s′,r∑?p(s′,r∣s,a)[r+γV??(s′)]貝爾曼方程中狀態s的價值V(s)由兩部分組成:
- 采取動作a后帶來的獎勵r,
- 采取動作a后到達的新狀態的價值V(s′),
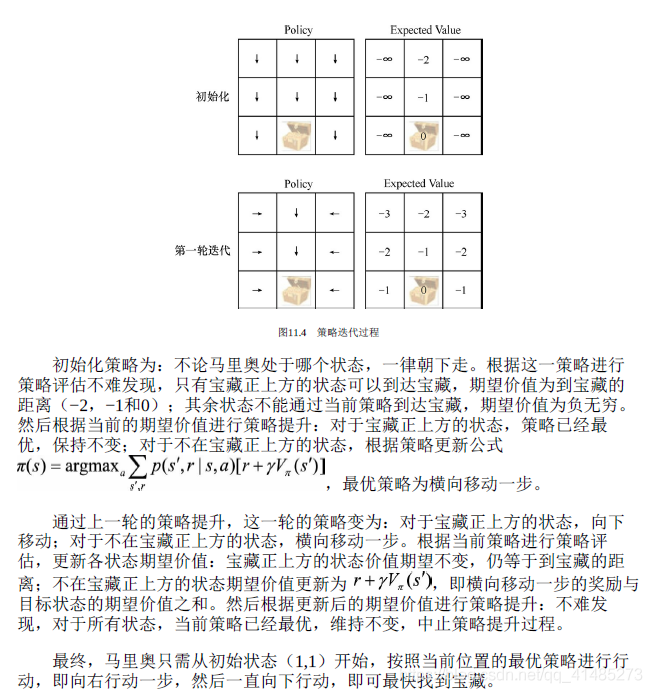
- ★★☆☆☆ 根據上圖給定的馬里奧的位置以及寶藏的位置,從策略迭代來考慮,如何找到一條最優路線?

二、視頻游戲里的強化學習
游戲是強化學習中最有代表性也是最合適的應用領域之一,幾乎涵蓋了強化學習所有的要素:環境—游戲本身的狀態;動作——用戶操作;機器人——程式;回饋——得分、輸贏等,通過輸入原始像素來玩視頻游戲,是人工智能成熟的標志之一,雅達利(Atari)是二十世紀七八十年代紅極一時的電腦游戲,類似于國內的紅白機游戲,但是畫面元素要更簡單一些,它的模擬器相對成熟,使用雅達利游戲來測驗強化學習,可謂量身定做,其應用場景可以描述為:在離散的時間軸上,每個時刻你可以得到當前的游戲畫面(環境),選擇向游戲機發出一個行動指令(如上、下、左、右、開火等),然后得到一個反饋(獎勵),基于原始像素的強化學習由于對應的狀態空間巨大,沒有辦法直接使用傳統的方法,于是,2013年DeepMind提出了深度強化學習模型,開始了深度學習和強化學習的結合,
傳統的強化學習主要使用Q-learning,而深度強化學習也使用Q-learning為基本框架,把Q-learning的對應步驟改為深度形式,并引入了一些技巧,例如經驗重放(experience replay)來加快收斂以及提高泛化能力,
- ★★★☆☆ 什么是深度強化學習,它和傳統的強化學習有什么不同?



三、策略梯度
Q-learning因為涉及在狀態空間上求Q函式的最大值,所以只適用于處理離散的狀態空間,對于連續的狀態空間,最大化Q函式將變得非常困難,所以對于機器人控制等需要復雜連續輸出的領域,Q-learning就顯得不太合適了,其次,包括深度Q-learning在內的大多數強化學習演算法,都沒有收斂性的保證,而策略梯度(Policy Gradient)則沒有這些問題,它可以無差別地處理連續和離散狀態空間,同時保證至少收斂到一個區域最優解,
- ★★★★☆ 什么是策略梯度,它和傳統Q-learning有什么不同,相對于Q-learning來說有什么優勢?



四、探索與利用
在和環境不斷互動的程序中,智能體在不同的狀態下不停地探索,獲取不同的動作的反饋,探索(Exploration)能夠幫助智能體通過不斷試驗獲得反饋,利用(Exploitation)是指利用已有的反饋資訊選擇最好的動作,因此如何平衡探索和利用是智能體在互動中不斷學習的重要問題,
- ★★★☆☆ 在智能體與環境的互動中,什么是探索和利用?如何平衡探索與利用?
假設我們開了一家叫Surprise Me的飯館,客人來了不用點餐,而是用演算法來決定該做哪道菜,具體程序為:
(1)客人 user = 1,…,T 依次到達飯館,
(2)給客人推薦一道菜,客人接受則留下吃飯(Reward=1),拒絕則離開(Reward=0),
(3)記錄選擇接受的客人總數 total_reward,
?? \;
為了由淺入深地解決這個問題,我們先做以下三個假設,
(1)同一道菜,有時候會做得好吃一些(概率=p),有時候會難吃一些(概率 = 1?p),但是并不知道概率p是多少,只能通過多次觀測進行統計,
(2)不考慮個人口味的差異,即當菜做得好吃時,客人一定會留下(Reward=1);當菜不好吃時,客人一定會離開(Reward=0),
(3)菜好吃或不好吃只有客人說的算,飯館是事先不知道的,


下一章傳送門:《百面機器學習》讀書筆記(十二)-集成學習
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/259023.html
標籤:其他