文章目錄
- 多重共線性檢驗-方差膨脹系數(VIF)
- 1、原理:
- 2、多重共線性:
- 3、檢驗方法:
- 方差膨脹系數(VIF):
- 相關性檢驗:
- 4、代碼測驗
- 4.1 匯入相關庫
- 4.2準備資料
- 4.3計算膨脹因子
- 4.4計算相關系數
- 4.5分割測驗集
- 4.6模型選擇
- 4.7AUC值
- 4.8模型調整
- 4.8.1洗掉 賬戶資金
- 4.8.2洗掉 累計交易傭金
- 5、總結
多重共線性檢驗-方差膨脹系數(VIF)
1、原理:
方差膨脹系數是衡量多元線性回歸模型中多重共線性嚴重程度的一種度量,
它表示回歸系數估計量的方差與假設自變數間不線性相關時方差相比的比值,
2、多重共線性:
是指各特征之間存在線性相關關系,即一個特征可以是其他一個或幾個特征的線性組合,如果存在多重共線性,求損失函式時矩陣會不可逆,導致求出結果會與實際不同,有所偏差,
例如:
x1=[1,2,3,4,5]
x2=[2,4,6,8,10]
x3=[2,3,4,5,6]
# x2=x1*2
# x3=x1+1
上述x2,x3都和x1成線性關系,這會進行回歸時,影響系數的準確性,說白了就是多個特征存在線性關系,資料冗余,但不完全是,所以要將成線性關系的特征進行降維
3、檢驗方法:
方差膨脹系數(VIF):
通常情況下,當VIF<10,說明不存在多重共線性;當10<=VIF<100,存在較強的多重共線性,當VIF>=100,存在嚴重多重共線性
# 匯入計算膨脹因子的庫
from statsmodels.stats.outliers_influence import variance_inflation_factor
# get_loc(i) 回傳對應列名所在的索引
vif=[variance_inflation_factor(x.values,x.columns.get_loc(i)) for i in x.columns]
list(zip(list(range(1,21)),vif))
相關性檢驗:
這個就不舉例子,很容易的
import pandas as pd
data=pd.DataFrame([[3,4],[4,5],[1,2]])
data.corr()
4、代碼測驗
說明:由于只是介紹多重相關性,所以建模的引數都為默認,只是基本結構
4.1 匯入相關庫
# 畫圖
import seaborn as sns
# 制作資料集
from sklearn.datasets import make_blobs
# VIF膨脹因子
from statsmodels.stats.outliers_influence import variance_inflation_factor
# 分割資料集
from sklearn.model_selection import train_test_split
# 邏輯回歸
from sklearn.linear_model import LogisticRegression
# AUC和準確度
from sklearn.metrics import accuracy_score
from sklearn.metrics import roc_auc_score
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
4.2準備資料
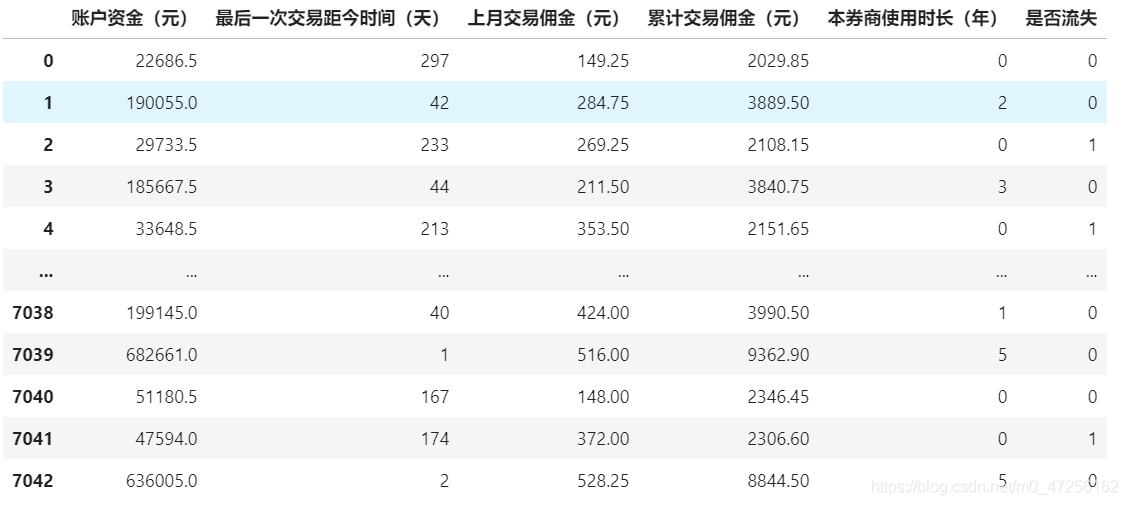
data=pd.read_excel('股票客戶流失'.xlsx)
# 提取特征矩陣和標簽
x=data.drop(columns=['是否流失'])
y=data['是否流失']
4.3計算膨脹因子

vif=[variance_inflation_factor(x.values,x.columns.get_loc(i)) for i in x.columns]
list(zip(list(range(1,21)),vif))
4.4計算相關系數
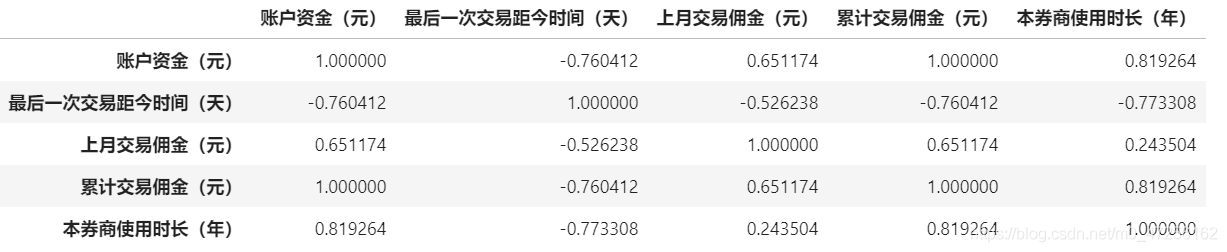
x.corr()
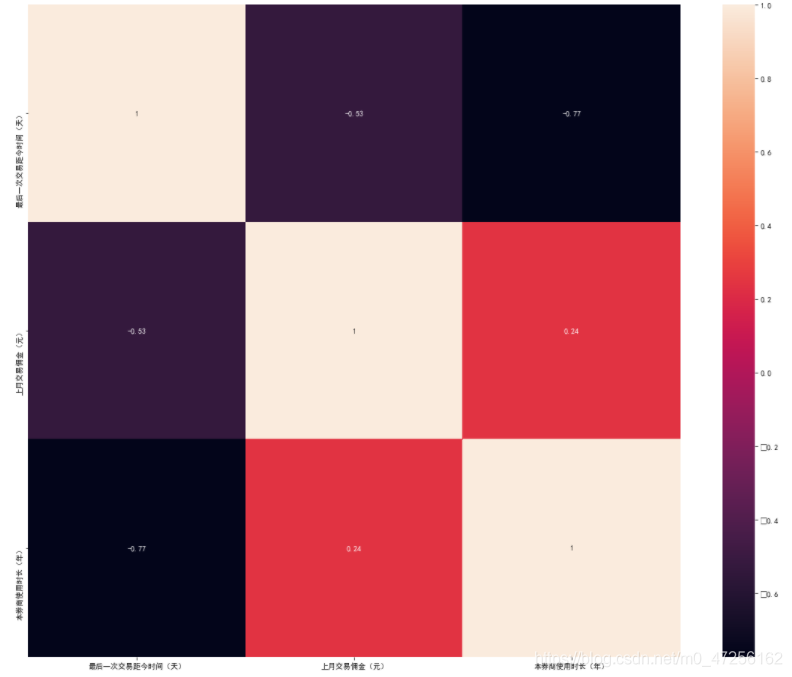
# 可以畫出熱力圖進行展示
plt.subplots(figsize=(20,16))
ax=sns.heatmap(x.corr(),vmax=1,square=True,annot=True)
4.5分割測驗集
x_train,x_test,y_train,y_test=train_test_split(x,
y,test_size=0.2,
random_state=2021
)
4.6模型選擇
clf=LogisticRegression(max_iter=300)
clf.fit(x_train,y_train)
y_pred=clf.predict(x_test)
accuracy_score(y_test,y_pred)

4.7AUC值
roc_auc_score(y_test,clf.predict_proba(x_test)[:,1])

4.8模型調整
由上述VIF值可以看出 累計交易傭金和賬戶資金有較強的多重相關性,所以考慮洗掉二者中的某個特征進行建模,我們分別洗掉兩個特征進行對比
4.8.1洗掉 賬戶資金
x=x.drop(columns=['賬戶資金(元)'])
x=pd.DataFrame(x)
y=y
vif=[variance_inflation_factor(x.values,x.columns.get_loc(i)) for i in x.columns]
vif
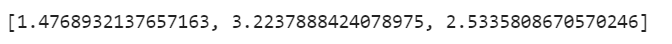
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=2021)
clf=LogisticRegression(max_iter=300)
clf.fit(x_train,y_train)
y_pred=clf.predict(x_test)
accuracy_score(y_test,y_pred)

roc_auc_score(y_test,clf.predict_proba(x_test)[:,1])
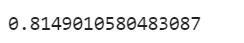
4.8.2洗掉 累計交易傭金
x=x.drop(columns=['累計交易傭金(元)'])
x=pd.DataFrame(x)
y=y
vif=[variance_inflation_factor(x.values,x.columns.get_loc(i)) for i in x.columns]
vif
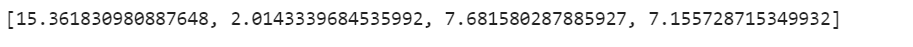
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=2021)
clf=LogisticRegression(max_iter=300)
clf.fit(x_train,y_train)
y_pred=clf.predict(x_test)
accuracy_score(y_test,y_pred)

roc_auc_score(y_test,clf.predict_proba(x_test)[:,1])

5、總結
| Score | AUC面積 | |
|---|---|---|
| 原始特征 | 0.7806 | 0.8194 |
| 洗掉賬戶資金 | 0.7821 | 0.8149 |
| 洗掉累計交易傭金 | 0.7586 | 0.7272 |
- 我們可以看出當我們洗掉賬戶資金這列特征時,分數有所上升,而AUC值下降了一點,不過影響不大,那么洗掉了共線性的特征是對我們模型的準確性是有作用的
- 但是我們發現洗掉累計交易傭金這列特征時,準確性反倒有所下降,這是為什么?不是洗掉共線性的特征對模型有幫助嗎,這時我們就會想可能是累計交易傭金這列特征所包含的資訊較多,貿然洗掉的化,可能會導致模型擬合不足(欠擬合)
- 而賬戶資金和累計交易時相關的,可以理解為賬戶資金的資訊依靠累計交易,類似于數學里面的子集這種(不過這種理解是錯誤的),就是兩列資料存在強烈的相關性,但累計交易傭金這列資料包含的資料相對于賬戶資金這列資料對模型的貢獻比較高
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/259045.html
標籤:AI
上一篇:云服務器一年費用