【YOLOv4探討 之三】mosaic資料增強
- mosaic資料增強原理
- darknet框架下mosaic資料增強的代碼解讀
- 引數配置
- 處理程序
- 判斷采用哪種資料增強模式
- 獲取影像路徑
- 設定初始平移量
- 影像偏移與truth值更新
- 常規資料增強
- 影像填充
- 系結目標引數
- 步驟綜合
- 總結
最近太忙,久未更新,對不住大家,進入正題,我們聊一聊YOLOv4中使用的mosaic資料增強,關于mosaic資料增強相關文章不少,三個月前這個方面的學習開了個頭,那時候各路諸侯都是以TensorFlow框架為主,我這里依然堅持分析研究darknet框架下的資料增強,
mosaic資料增強原理
YOLOv4中在載入圖片資料時同步進行mosaic資料增強,
mosaic資料增強基本原理就是在訓練集中隨機選擇若干個(一般是4個)影像,經過裁剪拼接形成新的訓練集元素,可以緩解訓練集元素少或者增強識別能力,是cutmix資料增強的升級版,基本原理如下圖,

darknet框架下mosaic資料增強的代碼解讀
引數配置
darknet框架下是否使用mosaic資料增強通過cfg檔案進行配置,核心的引數包括
由于實際的yolo4.cfg中只有
#cutmix=1
mosaic=1
其他的配置引數我們通過parser.c檔案中parse_net_options函式中的一些代碼來看:
net->flip = option_find_int_quiet(options, "flip", 1);//翻轉,默認為flip =1,
net->blur = option_find_int_quiet(options, "blur", 0);//糊化,默認不糊化
net->gaussian_noise = option_find_int_quiet(options, "gaussian_noise", 0);//高斯噪聲,默認不加噪聲
net->mixup = option_find_int_quiet(options, "mixup", 0);//使用資料增強,默認為0
int cutmix = option_find_int_quiet(options, "cutmix", 0); // cutmix增強,默認為0
int mosaic = option_find_int_quiet(options, "mosaic", 0); // mosaic增強,默認為0
//對使用不同型別的資料增強進行值定義
if (mosaic && cutmix) net->mixup = 4;
else if (cutmix) net->mixup = 2;
else if (mosaic) net->mixup = 3;
net->letter_box = option_find_int_quiet(options, "letter_box", 0);
net->mosaic_bound = option_find_int_quiet(options, "mosaic_bound", 0);
net->contrastive = option_find_int_quiet(options, "contrastive", 0);
net->contrastive_jit_flip = option_find_int_quiet(options, "contrastive_jit_flip", 0);
通過以上函式將關鍵引數傳入net,再傳給detector.c中的train_detector函式中的args ,再通過load_thread = load_data(args)進行資料載入和同時進行資料增強,
對模型進行訓練時使用load_data_detection函式1:
data load_data_detection(int n, char **paths, int m, int w, int h, int c, int boxes, int truth_size, int classes, int use_flip, int use_gaussian_noise, int use_blur, int use_mixup, float jitter, float resize, float hue, float saturation, float exposure, int mini_batch, int track, int augment_speed, int letter_box, int mosaic_bound, int contrastive, int contrastive_jit_flip, int show_imgs)
這里對每個引數進行分析:
int n表示一個完整的批次處理的圖片數量,在cfg檔案中的n = batch*ngpus,在單GPU條件下,一個批次通常取64張圖片
char **paths 表示訓練資料集的路徑的集合
int m 表示所使用的資料集的所有圖片數量
int w,int h,int c 表示載入圖片后歸一化的用于模型處理的圖片資料寬、高和通道數,是一個正方形圖片資料,一般w = h
int boxes表示一張圖片最多能夠識別出來的目標數,即一個層中使用的最大目標識別框的個數,對應args.num_boxes = l.max_boxes = option_find_int_quiet(options, "max", 200),在yolov4.cfg檔案中沒有明確,表示一次最多支持200個目標識別框
int truth_size 表示真值包含的元素個數一般為5
int classes 表示可以分類的數量,YOLOv4標準型為80個
int use_flip 表示是否使用翻轉,默認為1,表示使用翻轉
int use_gaussian_noise 表示是否加噪聲,默認不加
int use_blur 表示是使用糊化,默認不使用
int use_mixup 使用的混合資料增強的種類,包括cutmix,mixip,mosaic等
int jitter表示影像抖動范圍,默認0.2,既然是抖動就可能往左往右都有
float resize 表示影像縮放的比例,默認不縮放
float hue 表示色調(色相),默認為0,表示色調(色相)沒有偏移
float exposure 表示曝光度,通常曝光度設定為1
int mini_batch 表示最小批次,mini_batch = batch / subdivs,表示每次實際處理影像的批次
int track 在cfg檔案中未定義track,則在進行資料增強時不采取序列路徑,而是隨機抽取影像進行組合
int augment_speed 表示增強速度,默認為2,當依序列獲取增強資料路徑時,每次跳過的影像索引個數
int letter_box 表示是否使用letter_box變換,一般默認為0,表示不使用,影像進入神經網路后被拉伸成長寬比為1的正方形,會造成影像失真,letter_box變換就是將影像還原成原始比例,放在正方形中,將剩余的影像填入灰色,在YOLOv3中使用test_detector函式進行探測時直接進行了這個操作,在YOLOv4中專門設定一個if(letter_box)的陳述句,可以進行選擇使用,如果需要使用letter_box變換,后面在計算剪切后的影像時就要考慮進去,
int contrastive 表示是否使用對比,這個和序列抽取需要增強的資料影像時的起始索引有關,設定為1表示采用相鄰索引,設定為0表示采用隨機起始索引
int contrastive_jit_flip表示是否使用翻轉對比
int show_imgs 表示是否需要顯示組合的影像
處理程序
判斷采用哪種資料增強模式
使用use_mixup引數配置資料回圈及影像組合次數,當傳入mosaic && cutmix ==1或者cutmix ==1,令use_mixup = 3,即統統轉為使用mosaic資料增強,在YOLOv4默認的cfg檔案中,令mosaic = 1,這里表示YOLOv4的模型主要支撐mosaic資料增強,需要注意的一點是cutmix的資料增強方法主要用于分類而非探測,
use_mixup = 3意味著后續的處理要回圈四次,即把四張圖片拼接在一起,
當use_mixup = 3時,設定(cut_x,cut_y)得位置,這個位置是隨機的,示意圖如下:
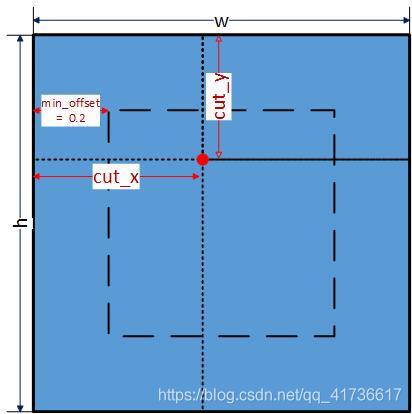
原始碼及注釋如下:
//這里是針對所有含cutmix=1的情況
//cutmix=1只適用于分類,不支持Detector,所以在load_data_detection中如果有cutmix=1,將會提醒以下陳述句:
//"cutmix=1 - isn't supported for Detector (use cutmix=1 only for Classifier)"
if (use_mixup == 2 || use_mixup == 4) {
printf("\n cutmix=1 - isn't supported for Detector (use cutmix=1 only for Classifier) \n");
if (check_mistakes) getchar();
if(use_mixup == 2) use_mixup = 0;//回圈次數use_mixup+1 = 1;
else use_mixup = 3;//同時使用mosaic和cutmix資料增強方法,回圈次數use_mixup+1 = 4
}
//這里不支持letterbox變換和mosaic變換同時成立的情況,
if (use_mixup == 3 && letter_box) {
//printf("\n Combination: letter_box=1 & mosaic=1 - isn't supported, use only 1 of these parameters \n");
//if (check_mistakes) getchar();
//exit(0);
}
if (random_gen() % 2 == 0) use_mixup = 0;//當使用mosaicDA,平均有一半的use_mixup = 0,即不進行任何變換
int i;
//資料增強策略:mosaic條件平均有一半的use_mixup = 0,其他條件下所有use_mixup = 0
//use_mixup == 3的條件下,設定mosaic DA 初始cut值
int *cut_x = NULL, *cut_y = NULL;
if (use_mixup == 3) {
cut_x = (int*)calloc(n, sizeof(int));
cut_y = (int*)calloc(n, sizeof(int));
const float min_offset = 0.2; // 20%
//一個imgs中每個圖片都設定一組cut_x,cut_y值,取值范圍在舉例邊界20%距離的內圈
for (i = 0; i < n; ++i) {
cut_x[i] = rand_int(w*min_offset, w*(1 - min_offset));
cut_y[i] = rand_int(h*min_offset, h*(1 - min_offset));
}
}
設定資料增強相關初始引數:
data d = {0};//設定data變數d,所有變換后的資料存盤在這個變數中
d.shallow = 0;
d.X.rows = n;//d.X中存盤一個batch的n個圖片
d.X.vals = (float**)xcalloc(d.X.rows, sizeof(float*));
d.X.cols = h*w*c;//每個圖片的尺寸,這里要考慮RGB通道
float r1 = 0, r2 = 0, r3 = 0, r4 = 0, r_scale = 0;//設定影像抖動最小隨機平移量
float resize_r1 = 0, resize_r2 = 0;//用于當影像出現縮放的時候的最小隨機平移量
float dhue = 0, dsat = 0, dexp = 0, flip = 0, blur = 0;//抖動、色調、曝光、翻轉、糊化引數初始值
int augmentation_calculated = 0, gaussian_noise = 0;//增強計算標志位和是否使用高斯噪聲
//d.y存盤標簽值,每一行為一幅圖的標簽,容量90*5個
d.y = make_matrix(n, truth_size*boxes);
利用回圈進行資料增強影像拼接處理,mosaic資料增強回圈分4次完成,每次獲取一個batch的影像,獲取完同時進行拼接,4次回圈完畢,完成batch個拼接影像的處理,
資料增強拼接處理分幾個步驟:
獲取影像路徑
分為兩種方式:序列獲取法和隨機獲取法,序列獲取法適合圖片集較少的情況,序列獲取圖片后,對圖片進行糊化、高斯噪聲、曝光、色調偏移、抖動位置重新設定等等操作;隨機獲取法適合圖片集較多的情況,直接組合拼接圖片也不擔心出現組合影像重復的情況,如此設定可以保證滿足資料增強需求的情況下不至于過度增加運算量,
每次獲取一個batch的圖片,使用函式的原始碼如下:
//抽取序列影像路徑
char **get_sequential_paths(char **paths, int n, int m, int mini_batch, int augment_speed, int contrastive)
{
int speed = rand_int(1, augment_speed);//speed在(1, augment_speed)或(augment_speed,1)中間取值,程式中默認augment_speed =2所以speed一般為1.x
if (speed < 1) speed = 1;//如果speed小于1,則取1
char** sequentia_paths = (char**)xcalloc(n, sizeof(char*));
int i;
pthread_mutex_lock(&mutex);
//printf("n = %d, mini_batch = %d \n", n, mini_batch);
//start_time_indexes中存了一個mini_batch的開始時間序列
unsigned int *start_time_indexes = (unsigned int *)xcalloc(mini_batch, sizeof(unsigned int));
for (i = 0; i < mini_batch; ++i) {
//如果使用contrastive模式且i為奇數,start_time_indexes和上一個start_time_indexes相同
if (contrastive && (i % 2) == 1) start_time_indexes[i] = start_time_indexes[i - 1];
else start_time_indexes[i] = random_gen() % m;//否則,start_time_indexes為一個0-m之間的亂數,即在所有圖片集中隨機抽取
//這里是說,如果非contrastive模式,圖片起始位置為隨機選取
//如果contrastive模式,圖片兩個相鄰起始位置相同,但也都是隨機選取
//printf(" start_time_indexes[i] = %u, ", start_time_indexes[i]);
}
//按一個完整批次的圖片進行回圈
//這里是針對一個mimi_batch的影像回圈取完,然后一起進行增強
for (i = 0; i < n; ++i) {
do {
int time_line_index = i % mini_batch;//回圈設定time_line_index索引
//實際圖片的索引為從start_time_indexes[0]開始的mimi_batch個順序影像索引,對m取模是為了防止取到所有圖片末尾后從頭回圈
unsigned int index = start_time_indexes[time_line_index] % m;
//start_time_indexes序列中的值在start_time_indexes[0]基礎上按照speed順序增加,如果mimi_batch為4,speed為1,mimi_batch為8,一般speed在1-2之間
start_time_indexes[time_line_index] += speed;
//int index = random_gen() % m;
sequentia_paths[i] = paths[index];//獲取一個batch的圖片序列
//printf(" index = %d, ", index);
//if(i == 0) printf("%s\n", paths[index]);
//printf(" index = %u - grp: %s \n", index, paths[index]);
//圖片路徑應大于4個字符
if (strlen(sequentia_paths[i]) <= 4) printf(" Very small path to the image: %s \n", sequentia_paths[i]);
} while (strlen(sequentia_paths[i]) == 0);
}
free(start_time_indexes);
pthread_mutex_unlock(&mutex);
return sequentia_paths;
}
//隨機抽取序列比較簡單,就是直接在所有的m個影像中隨機選取
char **get_random_paths_custom(char **paths, int n, int m, int contrastive)
{
char** random_paths = (char**)xcalloc(n, sizeof(char*));
int i;
pthread_mutex_lock(&mutex);
int old_index = 0;
//printf("n = %d \n", n);
for(i = 0; i < n; ++i){
do {
int index = random_gen() % m;
if (contrastive && (i % 2 == 1)) index = old_index;
else old_index = index;
random_paths[i] = paths[index];
//if(i == 0) printf("%s\n", paths[index]);
//printf("grp: %s\n", paths[index]);
if (strlen(random_paths[i]) <= 4) printf(" Very small path to the image: %s \n", random_paths[i]);
} while (strlen(random_paths[i]) == 0);
}
pthread_mutex_unlock(&mutex);
return random_paths;
}
設定初始平移量
抖動一般是針對于序列獲取路徑的情況下設定的,第一個batch的影像不需要抖動,后面的三個batch的影像需要抖動,
抖動通過int pleft = rand_precalc_random(-dw, dw, r1);等函式完成,如果抖動r1使用r1 = random_float();等函式設定亂數,如果不抖動pleft = -dw,即-0.2*原始影像的寬度,
rand_precalc_random函式定義如下:
//如果random_part為0,則回傳min
float rand_precalc_random(float min, float max, float random_part)
{
if (max < min) {
float swap = min;
min = max;
max = swap;
}
return (random_part * (max - min)) + min;
}
如果還存在縮放,則進一步進行修正:
以影像收縮為例,resize<1,則
pleft += rand_precalc_random(min_rdw, 0, resize_r1);
在非抖動的情況下,pleft = pleft + min_rdw
如果還存在letter_box變換,則pleft或者ptop的位置要切掉五十度灰的區域
影像偏移與truth值更新
對影像進行偏移處理后,將需要處理的影像在w×h的特征框中拉伸,并計算新的truth值,如果無抖動,裁剪影像裁剪位置就是影像的(0,0)坐標,如果有抖動,且抖動為正方向,就裁減掉pleft左邊、ptop上邊的部分影像,最后取得w和h尺寸的部分,如果尺寸不夠,再使用resize_image函式進行拉伸處理,拉伸到w×h的尺寸,
然后,在使用fill_truth_detection函式修正影像中目標的位置標簽等,
其中pleft和dx關系如下所示,計算新的truth值是一個線性變換,核心函式為中的correct_boxes函式,dx、dy為偏移量,sx、sy為拉伸比例
影像上下左右四個點坐標更新計算方法為:
l
e
f
t
n
e
w
=
l
e
f
t
_
o
r
i
g
i
n
?
s
x
–
d
x
left_new = left\_origin * sx – dx
leftn?ew=left_origin?sx–dx
r
i
g
h
t
n
e
w
=
r
i
g
h
t
_
o
r
i
g
i
n
?
s
x
–
d
x
right_new = right\_origin * sx – dx
rightn?ew=right_origin?sx–dx
t
o
p
n
e
w
=
t
o
p
_
o
r
i
g
i
n
?
s
y
–
d
y
top_new = top\_origin * sy – dy
topn?ew=top_origin?sy–dy
b
o
t
t
o
m
n
e
w
=
b
o
t
t
o
m
_
o
r
i
g
i
n
?
s
y
–
d
y
bottom_new = bottom\_origin * sy – dy
bottomn?ew=bottom_origin?sy–dy
具體目標的坐標及寬高引數為:
x
=
(
l
e
f
t
_
n
e
w
+
r
i
g
h
t
_
n
e
w
)
/
2
x = (left\_new + right\_new)/2
x=(left_new+right_new)/2
y
=
(
t
o
p
_
n
e
w
+
b
o
t
t
o
m
_
n
e
w
)
/
2
y = (top\_new + bottom\_new)/2
y=(top_new+bottom_new)/2
w
=
(
r
i
g
h
t
_
n
e
w
?
l
e
f
t
_
n
e
w
)
w = (right\_new - left\_new)
w=(right_new?left_new)
h
=
(
b
o
t
t
o
m
_
n
e
w
?
t
o
p
_
n
e
w
)
h = (bottom\_new - top\_new)
h=(bottom_new?top_new)
影像偏移拉伸示意圖如下:

影像位置標簽truth值修正函式代碼如下:
//影像位置標簽truth值修正函式
int fill_truth_detection(const char *path, int num_boxes, int truth_size, float *truth, int classes, int flip, float dx, float dy, float sx, float sy,
int net_w, int net_h)
{
char labelpath[4096];//初始化標簽檔案的路徑
replace_image_to_label(path, labelpath);//使用一定的規則根據影像的路徑算出label檔案的路徑
int count = 0;
int i;
box_label *boxes = read_boxes(labelpath, &count);
int min_w_h = 0;
float lowest_w = 1.F / net_w;//計算寬度的下限,1.F位浮點數1
float lowest_h = 1.F / net_h;
randomize_boxes(boxes, count);
correct_boxes(boxes, count, dx, dy, sx, sy, flip);//修正目標尺寸,平移加尺度伸縮,即線性變換
if (count > num_boxes) count = num_boxes;
float x, y, w, h;
int id;
int sub = 0;
//給坐標、尺寸和id賦值
for (i = 0; i < count; ++i) {
x = boxes[i].x;
y = boxes[i].y;
w = boxes[i].w;
h = boxes[i].h;
id = boxes[i].id;
int track_id = boxes[i].track_id;
// not detect small objects
//if ((w < 0.001F || h < 0.001F)) continue;
// if truth (box for object) is smaller than 1x1 pix
char buff[256];
if (id >= classes) {
printf("\n Wrong annotation: class_id = %d. But class_id should be [from 0 to %d], file: %s \n", id, (classes-1), labelpath);
sprintf(buff, "echo %s \"Wrong annotation: class_id = %d. But class_id should be [from 0 to %d]\" >> bad_label.list", labelpath, id, (classes-1));
system(buff);
if (check_mistakes) getchar();
++sub;
continue;
}
if ((w < lowest_w || h < lowest_h)) {
//sprintf(buff, "echo %s \"Very small object: w < lowest_w OR h < lowest_h\" >> bad_label.list", labelpath);
//system(buff);
++sub;
continue;
}
if (x == 999999 || y == 999999) {
printf("\n Wrong annotation: x = 0, y = 0, < 0 or > 1, file: %s \n", labelpath);
sprintf(buff, "echo %s \"Wrong annotation: x = 0 or y = 0\" >> bad_label.list", labelpath);
system(buff);
++sub;
if (check_mistakes) getchar();
continue;
}
if (x <= 0 || x > 1 || y <= 0 || y > 1) {
printf("\n Wrong annotation: x = %f, y = %f, file: %s \n", x, y, labelpath);
sprintf(buff, "echo %s \"Wrong annotation: x = %f, y = %f\" >> bad_label.list", labelpath, x, y);
system(buff);
++sub;
if (check_mistakes) getchar();
continue;
}
if (w > 1) {
printf("\n Wrong annotation: w = %f, file: %s \n", w, labelpath);
sprintf(buff, "echo %s \"Wrong annotation: w = %f\" >> bad_label.list", labelpath, w);
system(buff);
w = 1;
if (check_mistakes) getchar();
}
if (h > 1) {
printf("\n Wrong annotation: h = %f, file: %s \n", h, labelpath);
sprintf(buff, "echo %s \"Wrong annotation: h = %f\" >> bad_label.list", labelpath, h);
system(buff);
h = 1;
if (check_mistakes) getchar();
}
if (x == 0) x += lowest_w;
if (y == 0) y += lowest_h;
truth[(i-sub)*truth_size +0] = x;
truth[(i-sub)*truth_size +1] = y;
truth[(i-sub)*truth_size +2] = w;
truth[(i-sub)*truth_size +3] = h;
truth[(i-sub)*truth_size +4] = id;
truth[(i-sub)*truth_size +5] = track_id;
//float val = track_id;
//printf(" i = %d, sub = %d, truth_size = %d, track_id = %d, %f, %f\n", i, sub, truth_size, track_id, truth[(i - sub)*truth_size + 5], val);
if (min_w_h == 0) min_w_h = w*net_w;
if (min_w_h > w*net_w) min_w_h = w*net_w;
if (min_w_h > h*net_h) min_w_h = h*net_h;
}
free(boxes);
return min_w_h;
}
correct_boxes函式代碼如下:
//偏移修正函式
void correct_boxes(box_label *boxes, int n, float dx, float dy, float sx, float sy, int flip)
{
int i;
//設定初始值
for(i = 0; i < n; ++i){
if(boxes[i].x == 0 && boxes[i].y == 0) {
boxes[i].x = 999999;
boxes[i].y = 999999;
boxes[i].w = 999999;
boxes[i].h = 999999;
continue;
}
if ((boxes[i].x + boxes[i].w / 2) < 0 || (boxes[i].y + boxes[i].h / 2) < 0 ||
(boxes[i].x - boxes[i].w / 2) > 1 || (boxes[i].y - boxes[i].h / 2) > 1)
{
boxes[i].x = 999999;
boxes[i].y = 999999;
boxes[i].w = 999999;
boxes[i].h = 999999;
continue;
}
boxes[i].left = boxes[i].left * sx - dx;//dx為偏移量,sx為拉伸比例
boxes[i].right = boxes[i].right * sx - dx;
boxes[i].top = boxes[i].top * sy - dy;//dy為偏移量,sy為拉伸比例
boxes[i].bottom = boxes[i].bottom* sy - dy;
//翻轉修正
if(flip){
float swap = boxes[i].left;
boxes[i].left = 1. - boxes[i].right;
boxes[i].right = 1. - swap;
}
//若影像邊界坐標在[0,1]之間,取區間值,否者取上下限
//這里的修正主要是針對當抖動中出現坐標超出影像邊界的情況
boxes[i].left = constrain(0, 1, boxes[i].left);
boxes[i].right = constrain(0, 1, boxes[i].right);
boxes[i].top = constrain(0, 1, boxes[i].top);
boxes[i].bottom = constrain(0, 1, boxes[i].bottom);
boxes[i].x = (boxes[i].left+boxes[i].right)/2;//重新計算坐標位置
boxes[i].y = (boxes[i].top+boxes[i].bottom)/2;
boxes[i].w = (boxes[i].right - boxes[i].left);
boxes[i].h = (boxes[i].bottom - boxes[i].top);
boxes[i].w = constrain(0, 1, boxes[i].w);
boxes[i].h = constrain(0, 1, boxes[i].h);
}
}
常規資料增強
直接參考image_opencv.cpp中的資料增強函式image_data_augmentation,調整顏色、亮度、飽和度,還有翻轉、拉伸、平移、噪聲、模糊化等處理
具體處理方法這里不細討論,詳見image_opencv.cpp檔案,
影像填充
利用如下代碼計算平移量,注意,計算基本上是建立在默認翻轉的基礎之上的,這里代碼的作用是保證平移之后,待切割的影像中有充足的像素點對平移量進一步進行修正,
const int left_shift = min_val_cmp(cut_x[i], max_val_cmp(0, (-pleft*w / ow)));
const int top_shift = min_val_cmp(cut_y[i], max_val_cmp(0, (-ptop*h / oh)));
const int right_shift = min_val_cmp((w - cut_x[i]), max_val_cmp(0, (-pright*w / ow)));
const int bot_shift = min_val_cmp(h - cut_y[i], max_val_cmp(0, (-pbot*h / oh)));
填充原理如下:

系結目標引數
利用blend_truth_mosaic函式系結目標引數,主要是針對前一步計算的目標引數進行平移,源代碼如下:
//系結目標引數x,y,w,h
void blend_truth_mosaic(float *new_truth, int boxes, int truth_size, float *old_truth, int w, int h, float cut_x, float cut_y, int i_mixup,
int left_shift, int right_shift, int top_shift, int bot_shift,
int net_w, int net_h, int mosaic_bound)
{
const float lowest_w = 1.F / net_w;
const float lowest_h = 1.F / net_h;
int count_new_truth = 0;
int t;
for (t = 0; t < boxes; ++t) {
float x = new_truth[t*truth_size];
if (!x) break;
count_new_truth++;
}
int new_t = count_new_truth;
for (t = count_new_truth; t < boxes; ++t) {
float *new_truth_ptr = new_truth + new_t*truth_size;
new_truth_ptr[0] = 0;
float *old_truth_ptr = old_truth + (t - count_new_truth)*truth_size;
float x = old_truth_ptr[0];
if (!x) break;
float xb = old_truth_ptr[0];
float yb = old_truth_ptr[1];
float wb = old_truth_ptr[2];
float hb = old_truth_ptr[3];
// shift 4 images
//主要是針對前一步計算的目標引數進行平移
if (i_mixup == 0) {
xb = xb - (float)(w - cut_x - right_shift) / w;
yb = yb - (float)(h - cut_y - bot_shift) / h;
}
if (i_mixup == 1) {
xb = xb + (float)(cut_x - left_shift) / w;
yb = yb - (float)(h - cut_y - bot_shift) / h;
}
if (i_mixup == 2) {
xb = xb - (float)(w - cut_x - right_shift) / w;
yb = yb + (float)(cut_y - top_shift) / h;
}
if (i_mixup == 3) {
xb = xb + (float)(cut_x - left_shift) / w;
yb = yb + (float)(cut_y - top_shift) / h;
}
int left = (xb - wb / 2)*w;
int right = (xb + wb / 2)*w;
int top = (yb - hb / 2)*h;
int bot = (yb + hb / 2)*h;
if(mosaic_bound)
{
// fix out of Mosaic-bound
float left_bound = 0, right_bound = 0, top_bound = 0, bot_bound = 0;
if (i_mixup == 0) {
left_bound = 0;
right_bound = cut_x;
top_bound = 0;
bot_bound = cut_y;
}
if (i_mixup == 1) {
left_bound = cut_x;
right_bound = w;
top_bound = 0;
bot_bound = cut_y;
}
if (i_mixup == 2) {
left_bound = 0;
right_bound = cut_x;
top_bound = cut_y;
bot_bound = h;
}
if (i_mixup == 3) {
left_bound = cut_x;
right_bound = w;
top_bound = cut_y;
bot_bound = h;
}
if (left < left_bound) {
//printf(" i_mixup = %d, left = %d, left_bound = %f \n", i_mixup, left, left_bound);
left = left_bound;
}
if (right > right_bound) {
//printf(" i_mixup = %d, right = %d, right_bound = %f \n", i_mixup, right, right_bound);
right = right_bound;
}
if (top < top_bound) top = top_bound;
if (bot > bot_bound) bot = bot_bound;
xb = ((float)(right + left) / 2) / w;
wb = ((float)(right - left)) / w;
yb = ((float)(bot + top) / 2) / h;
hb = ((float)(bot - top)) / h;
}
else
{
// fix out of bound
if (left < 0) {
float diff = (float)left / w;
xb = xb - diff / 2;
wb = wb + diff;
}
if (right > w) {
float diff = (float)(right - w) / w;
xb = xb - diff / 2;
wb = wb - diff;
}
if (top < 0) {
float diff = (float)top / h;
yb = yb - diff / 2;
hb = hb + diff;
}
if (bot > h) {
float diff = (float)(bot - h) / h;
yb = yb - diff / 2;
hb = hb - diff;
}
left = (xb - wb / 2)*w;
right = (xb + wb / 2)*w;
top = (yb - hb / 2)*h;
bot = (yb + hb / 2)*h;
}
// leave only within the image
if(left >= 0 && right <= w && top >= 0 && bot <= h &&
wb > 0 && wb < 1 && hb > 0 && hb < 1 &&
xb > 0 && xb < 1 && yb > 0 && yb < 1 &&
wb > lowest_w && hb > lowest_h)
{
new_truth_ptr[0] = xb;
new_truth_ptr[1] = yb;
new_truth_ptr[2] = wb;
new_truth_ptr[3] = hb;
new_truth_ptr[4] = old_truth_ptr[4];
new_t++;
}
}
//printf("\n was %d bboxes, now %d bboxes \n", count_new_truth, t);
}
步驟綜合
對以上幾個步驟進行綜合,部分使用OpenCV代碼模塊的的load_data_detection函式源代碼如下,不使用OpenCV代碼模塊的源代碼大體思路一樣,這里不再詳解了,
//int n = imgs
//按照parser中的解釋,同時使用mosaic和cutmix資料增強方法,use_mixup = 4;只使用cutmix,use_mixup = 2;只使用mosaic,use_mixup = 3;都不使用,use_mixup = 0
//但是在實際函式中,darknet依然保持他喜歡在代碼中迷惑人的風范,use_mixup = 0是使用OpenCV中的調節亮度色彩飽和度、噪點等,use_mixup = 1為mixup
//use_mixup = 2的cutmix被mosaic DA所取代
//use_mixup 用于表征采用哪種增強方法,use_mixup == 4時,拼接4張圖片,回圈4次,采用mosaic,賦值use_mixup = 3
//use_mixup == 2,賦值use_mixup = 0,則影像拼接的回圈執行1次,處理一張圖片
//采用use_mixup = 0還是use_mixup = 3按50%的概率發生
data load_data_detection(int n, char **paths, int m, int w, int h, int c, int boxes, int truth_size, int classes, int use_flip, int use_gaussian_noise, int use_blur, int use_mixup,
float jitter, float resize, float hue, float saturation, float exposure, int mini_batch, int track, int augment_speed, int letter_box, int mosaic_bound, int contrastive, int contrastive_jit_flip, int show_imgs)
{
//!!!!!!!!!!!!!!!用于給混合的后的影像命名,這個要回頭再確認
const int random_index = random_gen();
c = c ? c : 3;//保證影像為RGB三通道
//這里是針對所有含cutmix=1的情況
//cutmix=1只適用于分類,不支持Detector,所以在load_data_detection中如果有cutmix=1,將會提醒以下陳述句:
//"cutmix=1 - isn't supported for Detector (use cutmix=1 only for Classifier)"
if (use_mixup == 2 || use_mixup == 4) {
printf("\n cutmix=1 - isn't supported for Detector (use cutmix=1 only for Classifier) \n");
if (check_mistakes) getchar();
if(use_mixup == 2) use_mixup = 0;//回圈次數use_mixup+1 = 1;
else use_mixup = 3;//同時使用mosaic和cutmix資料增強方法,回圈次數use_mixup+1 = 4
}
//這里不支持letterbox變換和mosaic變換同時成立的情況,
if (use_mixup == 3 && letter_box) {
//printf("\n Combination: letter_box=1 & mosaic=1 - isn't supported, use only 1 of these parameters \n");
//if (check_mistakes) getchar();
//exit(0);
}
if (random_gen() % 2 == 0) use_mixup = 0;//當使用mosaicDA,平均有一半的use_mixup = 0,即不進行任何變換
int i;
//資料增強策略:mosaic條件平均有一半的use_mixup = 0,其他條件下所有use_mixup = 0
//use_mixup == 3的條件下,設定mosaic DA 初始cut值
int *cut_x = NULL, *cut_y = NULL;
if (use_mixup == 3) {
cut_x = (int*)calloc(n, sizeof(int));
cut_y = (int*)calloc(n, sizeof(int));
const float min_offset = 0.2; // 20%
//一個imgs中每個圖片都設定一組cut_x,cut_y值,取值范圍在舉例邊界20%距離的內圈
for (i = 0; i < n; ++i) {
cut_x[i] = rand_int(w*min_offset, w*(1 - min_offset));
cut_y[i] = rand_int(h*min_offset, h*(1 - min_offset));
}
}
data d = {0};//設定data變數d,所有變換后的資料存盤在這個變數中
d.shallow = 0;
d.X.rows = n;//d.X中存盤一個batch的n個圖片
d.X.vals = (float**)xcalloc(d.X.rows, sizeof(float*));
d.X.cols = h*w*c;//每個圖片的尺寸,這里要考慮RGB通道
float r1 = 0, r2 = 0, r3 = 0, r4 = 0, r_scale = 0;//設定影像抖動最小隨機平移量
float resize_r1 = 0, resize_r2 = 0;//用于當影像出現縮放的時候的最小隨機平移量
float dhue = 0, dsat = 0, dexp = 0, flip = 0, blur = 0;//抖動、色調、曝光、翻轉、糊化引數初始值
int augmentation_calculated = 0, gaussian_noise = 0;//增強計算標志位和是否使用高斯噪聲
//d.y存盤標簽值,每一行為一幅圖的標簽,容量90*5個
d.y = make_matrix(n, truth_size*boxes);
int i_mixup = 0;
//mosaic DA條件下一半情況下use_mixup = 3,要執行4次回圈,處理4張圖片,其他情況use_mixup = 0,回圈只執行1次
for (i_mixup = 0; i_mixup <= use_mixup; i_mixup++) {
//如果是非首次回圈,augmentation_calculated = 0
if (i_mixup) augmentation_calculated = 0; // recalculate augmentation for the 2nd sequence if(track==1)
//獲取用于拼接的檔案路徑集合
//如果track == 1則執行get_sequential_paths,從所有m個訓練圖片集中獲n個取序列路徑,否則獲取n個隨機路徑
//track實際上默認為0,表示純隨機選取圖片進行資料增強
char **random_paths;
if (track) random_paths = get_sequential_paths(paths, n, m, mini_batch, augment_speed, contrastive);
else random_paths = get_random_paths_custom(paths, n, m, contrastive);
//這個回圈是為了再隨機圖片序列中挨個取一個圖,在圖上進行截取(cut)
for (i = 0; i < n; ++i) {
float *truth = (float*)xcalloc(truth_size * boxes, sizeof(float));//真值初始化
const char *filename = random_paths[i];//獲取檔案名
int flag = (c >= 3);//通道數大于等于3,則flag=1
mat_cv *src;
src = load_image_mat_cv(filename, flag);//使用OpenCV讀取影像資訊
if (src == NULL) {//如果讀取為空,清空快取,繼續讀取
printf("\n Error in load_data_detection() - OpenCV \n");
fflush(stdout);
if (check_mistakes) {
getchar();
}
continue;
}
//獲取圖片的原始高oh(origin height)和寬ow(origin width)
int oh = get_height_mat(src);
int ow = get_width_mat(src);
//確定素材影像抖動的初始位置
int dw = (ow*jitter);//jitter=0.2
int dh = (oh*jitter);
//此處為影像縮放處理
//resize比例初始值為1,組態檔沒有寫就默認為1
//min_rdw,min_rdh 一定 < 0,max_rdw,max_rdh 一定 > 0,相當于計算ow和oh的“緩沖帶”的上下沿
float resize_down = resize, resize_up = resize;
if (resize_down > 1.0) resize_down = 1 / resize_down;
int min_rdw = ow*(1 - (1 / resize_down)) / 2; // < 0
int min_rdh = oh*(1 - (1 / resize_down)) / 2; // < 0
if (resize_up < 1.0) resize_up = 1 / resize_up;//切邊?
int max_rdw = ow*(1 - (1 / resize_up)) / 2; // > 0
int max_rdh = oh*(1 - (1 / resize_up)) / 2; // > 0
//printf(" down = %f, up = %f \n", (1 - (1 / resize_down)) / 2, (1 - (1 / resize_up)) / 2);
//首次回圈,處理第一張圖片,如果track=0,則此處不運行;二次回圈一定運行
//augmentation_calculated:資料增強引數設定,選取一個batch的圖片,都按照相同的引數
//如果采取序列獲取圖片路徑的方式,則重新計算影像拼接平移的量,同時使用糊化、高斯噪聲、曝光、色調偏移等等資料增強方式
//因為如果圖片較少的情況下,很可能總是相同的幾個影像進行組合,因此要對組合的幾個影像進行處理
//這也告訴我們,大訓練集使用隨機獲取路徑的方式,小訓練集使用序列獲取路徑并進行區域處理方式,從而保證資料增強可控、有效
if (!augmentation_calculated || !track)
{
augmentation_calculated = 1;//每4次影像抽取更新一次隨機處理的引數
resize_r1 = random_float();//0-1之間的隨機浮點數
resize_r2 = random_float();
//存在對比、翻轉或者第二次
if (!contrastive || contrastive_jit_flip || i % 2 == 0)
{
r1 = random_float();
r2 = random_float();
r3 = random_float();
r4 = random_float();
flip = use_flip ? random_gen() % 2 : 0;//use_flip初始值為1,flip為隨機0或1
}
r_scale = random_float();
//cfg中,saturation = 1.5,exposure = 1.5中
dhue = rand_uniform_strong(-hue, hue);
dsat = rand_scale(saturation);//隨機為1-1.5之間或者0.66-1之間
dexp = rand_scale(exposure);
if (use_blur) {
int tmp_blur = rand_int(0, 2); // 0 - disable, 1 - blur background, 2 - blur the whole image
if (tmp_blur == 0) blur = 0;
else if (tmp_blur == 1) blur = 1;
else blur = use_blur;
}
if (use_gaussian_noise && rand_int(0, 1) == 1) gaussian_noise = use_gaussian_noise;
else gaussian_noise = 0;
}
//設定初始平移量
int pleft = rand_precalc_random(-dw, dw, r1);
int pright = rand_precalc_random(-dw, dw, r2);
int ptop = rand_precalc_random(-dh, dh, r3);
int pbot = rand_precalc_random(-dh, dh, r4);
//如果存在縮放,則對平移量進行微調,注意,此時的資料針對計算都還是對原始圖片,沒有按正方形的待卷積的形狀進行處理
//由于cfg檔案中沒有resize引數,所以在parser.c中,是將resize賦值為1,置入引數設定
if (resize < 1) {
// downsize only
pleft += rand_precalc_random(min_rdw, 0, resize_r1);
pright += rand_precalc_random(min_rdw, 0, resize_r2);
ptop += rand_precalc_random(min_rdh, 0, resize_r1);
pbot += rand_precalc_random(min_rdh, 0, resize_r2);
}
else {
pleft += rand_precalc_random(min_rdw, max_rdw, resize_r1);
pright += rand_precalc_random(min_rdw, max_rdw, resize_r2);
ptop += rand_precalc_random(min_rdh, max_rdh, resize_r1);
pbot += rand_precalc_random(min_rdh, max_rdh, resize_r2);
}
//printf("\n pleft = %d, pright = %d, ptop = %d, pbot = %d, ow = %d, oh = %d \n", pleft, pright, ptop, pbot, ow, oh);
//float scale = rand_precalc_random(.25, 2, r_scale); // unused currently
//printf(" letter_box = %d \n", letter_box);
//如果使用letter_box變換,在計算ptop及pbot時需要將填充的五十度灰色去掉,YOLOv4中默認不使用
if (letter_box)
{
float img_ar = (float)ow / (float)oh;
float net_ar = (float)w / (float)h;
float result_ar = img_ar / net_ar;
//printf(" ow = %d, oh = %d, w = %d, h = %d, img_ar = %f, net_ar = %f, result_ar = %f \n", ow, oh, w, h, img_ar, net_ar, result_ar);
if (result_ar > 1) // sheight - should be increased
{
float oh_tmp = ow / net_ar;
float delta_h = (oh_tmp - oh)/2;
ptop = ptop - delta_h;
pbot = pbot - delta_h;
//printf(" result_ar = %f, oh_tmp = %f, delta_h = %d, ptop = %f, pbot = %f \n", result_ar, oh_tmp, delta_h, ptop, pbot);
}
else // swidth - should be increased
{
float ow_tmp = oh * net_ar;
float delta_w = (ow_tmp - ow)/2;
pleft = pleft - delta_w;
pright = pright - delta_w;
//printf(" result_ar = %f, ow_tmp = %f, delta_w = %d, pleft = %f, pright = %f \n", result_ar, ow_tmp, delta_w, pleft, pright);
}
//printf("\n pleft = %d, pright = %d, ptop = %d, pbot = %d, ow = %d, oh = %d \n", pleft, pright, ptop, pbot, ow, oh);
}
// move each 2nd image to the corner - so that most of it was visible
// 將第二張圖片移到角上,這樣圖片的大部分像素都可以看見,也可能這是最初的設計
// 但是在實際影像處理中,因為要對圖片進行平移,flip條件下還要進行資料對換,這個一會給left賦0.一會給right賦0的伎倆并沒有什么實際意義
// pleft += pright可以看成增強資料的隨機性的一種方式,可以保證平移量出現較大的資料范圍
if (use_mixup == 3 && random_gen() % 2 == 0) {
if (flip) {
if (i_mixup == 0) pleft += pright, pright = 0, pbot += ptop, ptop = 0;
if (i_mixup == 1) pright += pleft, pleft = 0, pbot += ptop, ptop = 0;
if (i_mixup == 2) pleft += pright, pright = 0, ptop += pbot, pbot = 0;
if (i_mixup == 3) pright += pleft, pleft = 0, ptop += pbot, pbot = 0;
}
else {
if (i_mixup == 0) pright += pleft, pleft = 0, pbot += ptop, ptop = 0;
if (i_mixup == 1) pleft += pright, pright = 0, pbot += ptop, ptop = 0;
if (i_mixup == 2) pright += pleft, pleft = 0, ptop += pbot, pbot = 0;
if (i_mixup == 3) pleft += pright, pright = 0, ptop += pbot, pbot = 0;
}
}
//無抖動條件下swidth = ow,sheight = oh
//有抖動條件下swidth與ow,sheight與oh存在偏差
int swidth = ow - pleft - pright;
int sheight = oh - ptop - pbot;
//計算偏移后影像與原始影像比例
float sx = (float)swidth / ow;
float sy = (float)sheight / oh;
//影像在拉伸情況下的偏移量
float dx = ((float)pleft / ow) / sx;
float dy = ((float)ptop / oh) / sy;
int min_w_h = fill_truth_detection(filename, boxes, truth_size, truth, classes, flip, dx, dy, 1. / sx, 1. / sy, w, h);
//for (int z = 0; z < boxes; ++z) if(truth[z*truth_size] > 0) printf(" track_id = %f \n", truth[z*truth_size + 5]);
//printf(" truth_size = %d \n", truth_size);
//計算糊化的引數
if ((min_w_h / 8) < blur && blur > 1) blur = min_w_h / 8; // disable blur if one of the objects is too small
//資料增強普通函式,在image_opencv.cpp中,在進行mosaic DA之前,前進行一輪普通增強
//直接參考image_opencv.cpp中的資料增強函式,調整顏色、亮度、飽和度,還有翻轉、拉伸、平移、噪聲、模糊化等處理
//這里輸出的影像ai就已經是正方形的了,寬為w,長為h
image ai = image_data_augmentation(src, w, h, pleft, ptop, swidth, sheight, flip, dhue, dsat, dexp,
gaussian_noise, blur, boxes, truth_size, truth);
if (use_mixup == 0) {
d.X.vals[i] = ai.data;
memcpy(d.y.vals[i], truth, truth_size * boxes * sizeof(float));
}//use_mixup == 0,表示只進行opencv中的資料增強
// use_mixup == 1,使用mixup
else if (use_mixup == 1) {
if (i_mixup == 0) {
d.X.vals[i] = ai.data;
memcpy(d.y.vals[i], truth, truth_size * boxes * sizeof(float));
}
else if (i_mixup == 1) {
image old_img = make_empty_image(w, h, c);
old_img.data = d.X.vals[i];
//show_image(ai, "new");
//show_image(old_img, "old");
//wait_until_press_key_cv();
blend_images_cv(ai, 0.5, old_img, 0.5);
blend_truth(d.y.vals[i], boxes, truth_size, truth);
free_image(old_img);
d.X.vals[i] = ai.data;
}
}
else if (use_mixup == 3) {
if (i_mixup == 0) {
image tmp_img = make_image(w, h, c);//生成臨時切割好的影像塊
d.X.vals[i] = tmp_img.data;
}
if (flip) {
int tmp = pleft;
pleft = pright;
pright = tmp;
}
// 平移之后,待切割的影像中有充足的像素點
const int left_shift = min_val_cmp(cut_x[i], max_val_cmp(0, (-pleft*w / ow)));
const int top_shift = min_val_cmp(cut_y[i], max_val_cmp(0, (-ptop*h / oh)));
const int right_shift = min_val_cmp((w - cut_x[i]), max_val_cmp(0, (-pright*w / ow)));
const int bot_shift = min_val_cmp(h - cut_y[i], max_val_cmp(0, (-pbot*h / oh)));
// 每個i_mixup回圈切割一塊像素點,放入d.X中,構成一個個用于卷積的正方形影像資料
// 排列順序是左上,右上,左下,右下
int k, x, y;
for (k = 0; k < c; ++k) {
for (y = 0; y < h; ++y) {
int j = y*w + k*w*h;
if (i_mixup == 0 && y < cut_y[i]) {
int j_src = (w - cut_x[i] - right_shift) + (y + h - cut_y[i] - bot_shift)*w + k*w*h;
memcpy(&d.X.vals[i][j + 0], &ai.data[j_src], cut_x[i] * sizeof(float));
}
if (i_mixup == 1 && y < cut_y[i]) {
int j_src = left_shift + (y + h - cut_y[i] - bot_shift)*w + k*w*h;
memcpy(&d.X.vals[i][j + cut_x[i]], &ai.data[j_src], (w-cut_x[i]) * sizeof(float));
}
if (i_mixup == 2 && y >= cut_y[i]) {
int j_src = (w - cut_x[i] - right_shift) + (top_shift + y - cut_y[i])*w + k*w*h;
memcpy(&d.X.vals[i][j + 0], &ai.data[j_src], cut_x[i] * sizeof(float));
}
if (i_mixup == 3 && y >= cut_y[i]) {
int j_src = left_shift + (top_shift + y - cut_y[i])*w + k*w*h;
memcpy(&d.X.vals[i][j + cut_x[i]], &ai.data[j_src], (w - cut_x[i]) * sizeof(float));
}
}
}
//mosaic DA的核心函式,系結資料資訊d.y
blend_truth_mosaic(d.y.vals[i], boxes, truth_size, truth, w, h, cut_x[i], cut_y[i], i_mixup, left_shift, right_shift, top_shift, bot_shift, w, h, mosaic_bound);
free_image(ai);
ai.data = d.X.vals[i];
}
if (show_imgs && i_mixup == use_mixup) // delete i_mixup
{
image tmp_ai = copy_image(ai);
char buff[1000];
//sprintf(buff, "aug_%d_%d_%s_%d", random_index, i, basecfg((char*)filename), random_gen());
sprintf(buff, "aug_%d_%d_%d", random_index, i, random_gen());
int t;
for (t = 0; t < boxes; ++t) {
box b = float_to_box_stride(d.y.vals[i] + t*truth_size, 1);
if (!b.x) break;
int left = (b.x - b.w / 2.)*ai.w;
int right = (b.x + b.w / 2.)*ai.w;
int top = (b.y - b.h / 2.)*ai.h;
int bot = (b.y + b.h / 2.)*ai.h;
draw_box_width(tmp_ai, left, top, right, bot, 1, 150, 100, 50); // 3 channels RGB
}
save_image(tmp_ai, buff);
if (show_imgs == 1) {
//char buff_src[1000];
//sprintf(buff_src, "src_%d_%d_%s_%d", random_index, i, basecfg((char*)filename), random_gen());
//show_image_mat(src, buff_src);
show_image(tmp_ai, buff);
wait_until_press_key_cv();
}
printf("\nYou use flag -show_imgs, so will be saved aug_...jpg images. Click on window and press ESC button \n");
free_image(tmp_ai);
}
release_mat(&src);
free(truth);
}
if (random_paths) free(random_paths);
}
return d;
}
總結
在darknet中之所以感覺mosaic資料增強這么“難”,應該還是影像平移翻轉、影像表示計算等等功力不夠,記得本人在學習微波工程的時候,教授講過,學習這門課需要你首先有空間想象能力,要多琢磨,琢磨什么呢?琢磨電磁場在空間傳播的形態,不同空間位置功率密度的狀態(也就是方向圖),琢磨各種極化方式、相位變化、電磁波干涉的結果、電磁波在介質中傳播中損耗情況、電磁波碰到反射面后的反射情況等等,其實看起來比影像處理還要復雜是不是?
Mosaic資料增強的代碼大體原理已經解釋完畢,細節部分有需要進一步研究的同學可以花費更多時間進行研讀,馬上要過年了,就趕緊脫手了,
完結,撒花!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/259050.html
標籤:AI
下一篇:程式員的浪漫,你值得擁有!