明天大年三十,去趟迪士尼,今天下班早,睡前寫下這篇,結束這一農歷年,
其實寫這篇的初衷起因于我對那些看見4個視窗就想加到8個視窗的人鄙視,并且這些人幾乎都是狂暴之人,我發現那些做業務邏輯的只要懂點TCP都不會好好說話,事實上他們大多數人什么都不懂,只有什么都不懂的人才會自以為是,天天鄙視別人,
對于TCP的優化,我聽過無數遍 “丟包就慢點降窗,不丟包就快點增窗唄,這還不簡單!” 我只是覺得他們只想炫耀,
就像我很討厭網吧的網管以及阿里巴巴的運維一樣,我也很討厭那些對TCP夸夸其談卻給不出任何建設性建議的人,懂點網路有啥了不起嗎?在我看來,端到端的東西,比如TCP,和網路只是沾邊兒!
本文再來聊聊BBR的公平性,
我一直都想知道BBR演算法的收斂點,因為我想借此看看它如何保證可以收斂到公平,遺憾的是并沒有找到,就連BBR的原始論文以及原始碼實作,除了一些定性的分析之外,再沒有任何更加細致深入的解釋,這讓我覺得不舒服,
在我看來,擁塞控制演算法的公平性比效率更加重要,如果你想提高傳輸效率,那就別在擁塞控制上做文章了,擁塞控制注定是降低效率的,它提高的是公平性,擁塞控制的目標是保證所有人有路可走,不怕慢就怕停,不患寡而患不均,
而我們知道,包括CUBIC在內的Reno家族CC在這方面做的很好,其背后起作用的就是AIMD,那么BBR的公平性,何去何從?
其實Reno家族的CC和BBR在公平性方面可以是一回事,
再回到BBR論文里的BtlBw/RTprop示意圖:
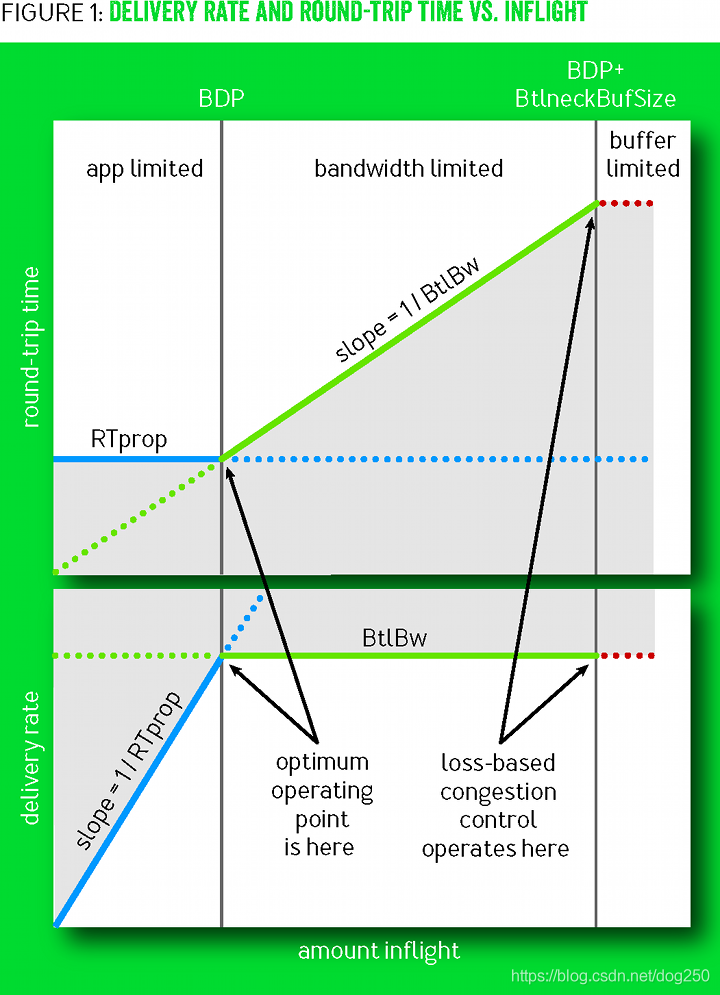
我們來比較一下Reno和BBR的Operating point,先來說什么是Operating point,
所謂的Operating point實際上就是一個 收斂點 ,我們知道TCP的CC是一個典型的反饋系統,任何負反饋系統都有一個所謂的 “目標” ,也就是這個系統趨向的位置,然后在這個目標位置附近左右搖擺,最終這實際上是一個平衡點,
對于Reno家族的CC,其收斂點就是 buffer被填滿的位置 ,在該位置:
- Reno流的BtlBw最大,RTT最大,
對于BBR而言,其收斂點在 buffer即將被填充但尚未被填充的位置 ,在該位置:
- BBR流的BtlBw最大,RTT最小,等于RTprop,
由控制論可知在上述的收斂點執行AIMD可以保證公平性,現在的問題是Reno家族和BBR分別怎么知道自己到了收斂點,
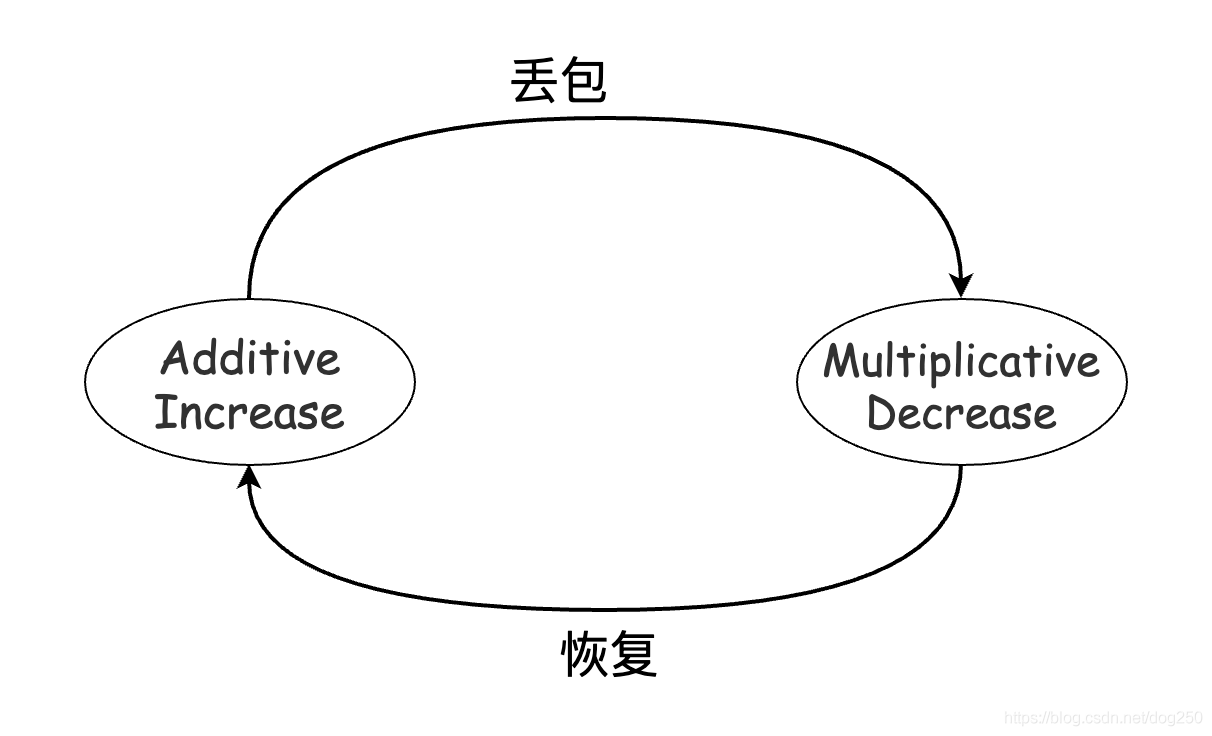
Reno家族簡單,路由器交換機的buffer填滿后會丟包,基于尾部丟包的假設,丟包將會被所有的Reno TCP流感知,于是它們均會執行MD減窗,然后進行相對緩慢的AI增窗,以此反復我們可以通過數學推匯出所有Reno流將收斂到公平,
然而BBR呢?BBR如何感知到自己到達了收斂點呢?似乎很難,沒有任何全域信號可以指示收斂點的到來,
根據上圖,BBR的BtlBw和RTprop無法同時測量的,測量BtlBw需要塞滿buffer,測量RTprop不能使用buffer,
BBR取了個巧:
- ProbeBW狀態:BBR通過延續10s的up/down穩態來試圖塞滿帶寬,由此可以測得BtlBw,
不管這10s中是自己還是其它流塞滿了帶寬,但幾乎10s肯定能測量出最大的帶寬, - ProbeRTT狀態:BBR在延續10s的up/down之后突然排空所有的buffer,由此可以測得RTprop,
通過將自己cwnd限制為4看起來不能保證整個buffer被排空,但這里有一個自動全域同步,下面說,
注意上面的ProbeRTT狀態,很多人會誤認為在這個階段pacing rate會跌零然后重新開始,事實上這是錯誤的,ProbeRTT狀態相比ProbeBW狀態而言持續非常短,而BBR計算pacing rate所使用的BtlBw是windowed_max的,因此離開ProbeRTT再次進入ProbeBW狀態時,絕大多數情況下,其BtlBw是沒有變化的,我們還是看代碼的注釋吧:
/* Bottleneck Bandwidth and RTT (BBR) congestion control
*
* BBR congestion control computes the sending rate based on the delivery
* rate (throughput) estimated from ACKs. In a nutshell:
*
* On each ACK, update our model of the network path:
* bottleneck_bandwidth = windowed_max(delivered / elapsed, 10 round trips)
* min_rtt = windowed_min(rtt, 10 seconds)
* pacing_rate = pacing_gain * bottleneck_bandwidth
* cwnd = max(cwnd_gain * bottleneck_bandwidth * min_rtt, 4)
...
*/
...
/* The goal of PROBE_RTT mode is to have BBR flows cooperatively and
* periodically drain the bottleneck queue, to converge to measure the true
* min_rtt (unloaded propagation delay). This allows the flows to keep queues
* small (reducing queuing delay and packet loss) and achieve fairness among
* BBR flows.
*
* The min_rtt filter window is 10 seconds. When the min_rtt estimate expires,
* we enter PROBE_RTT mode and cap the cwnd at bbr_cwnd_min_target=4 packets.
* After at least bbr_probe_rtt_mode_ms=200ms and at least one packet-timed
* round trip elapsed with that flight size <= 4, we leave PROBE_RTT mode and
* re-enter the previous mode. BBR uses 200ms to approximately bound the
* performance penalty of PROBE_RTT's cwnd capping to roughly 2% (200ms/10s).
*
* Note that flows need only pay 2% if they are busy sending over the last 10
* seconds. Interactive applications (e.g., Web, RPCs, video chunks) often have
* natural silences or low-rate periods within 10 seconds where the rate is low
* enough for long enough to drain its queue in the bottleneck. We pick up
* these min RTT measurements opportunistically with our min_rtt filter. :-)
*/
當我們把BBR簡化,去除了非核心的雜項之后,BBR其實就是一個在兩個狀態之間周期轉換的狀態機:
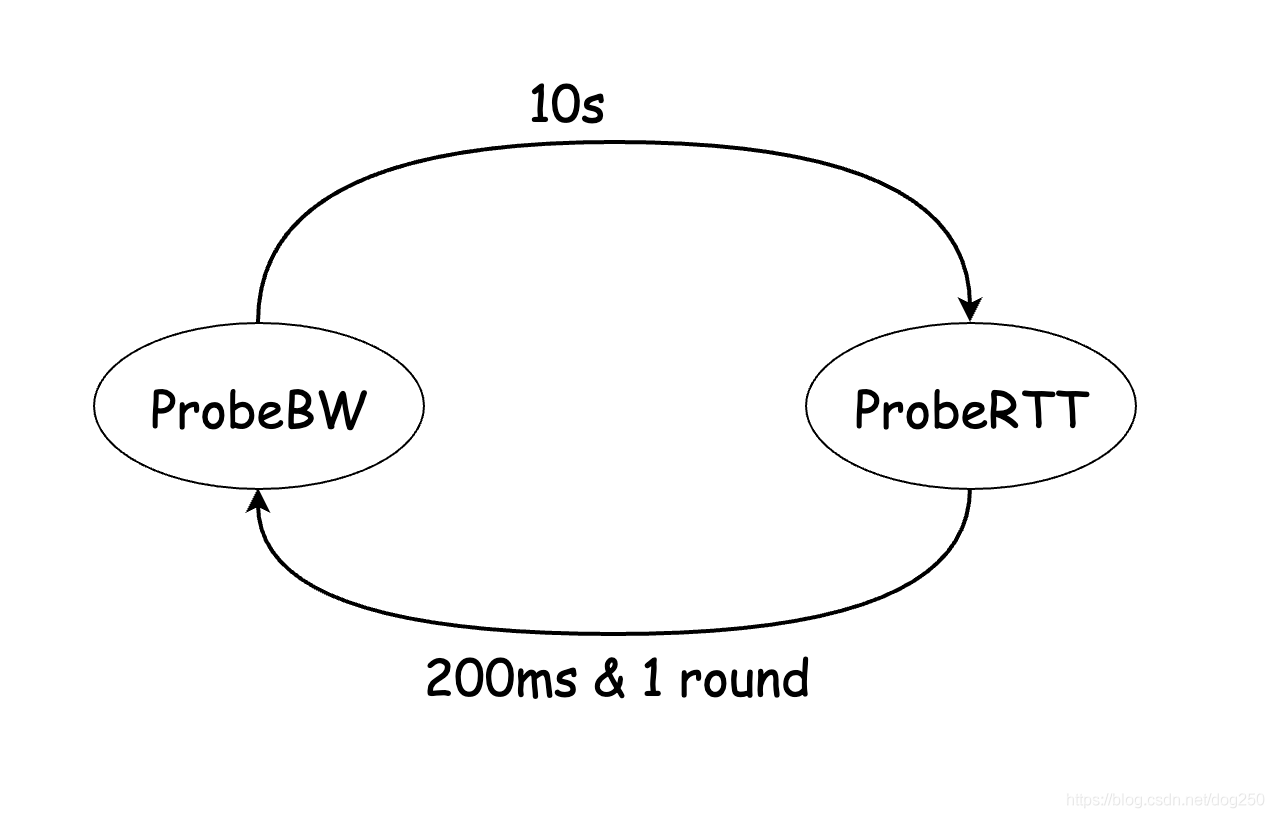
是不是和Reno家族的AI狀態和MD狀態周期轉換的狀態機很類似:
我們可以在BtlBw/RTprop圖示上將兩者統一起來:
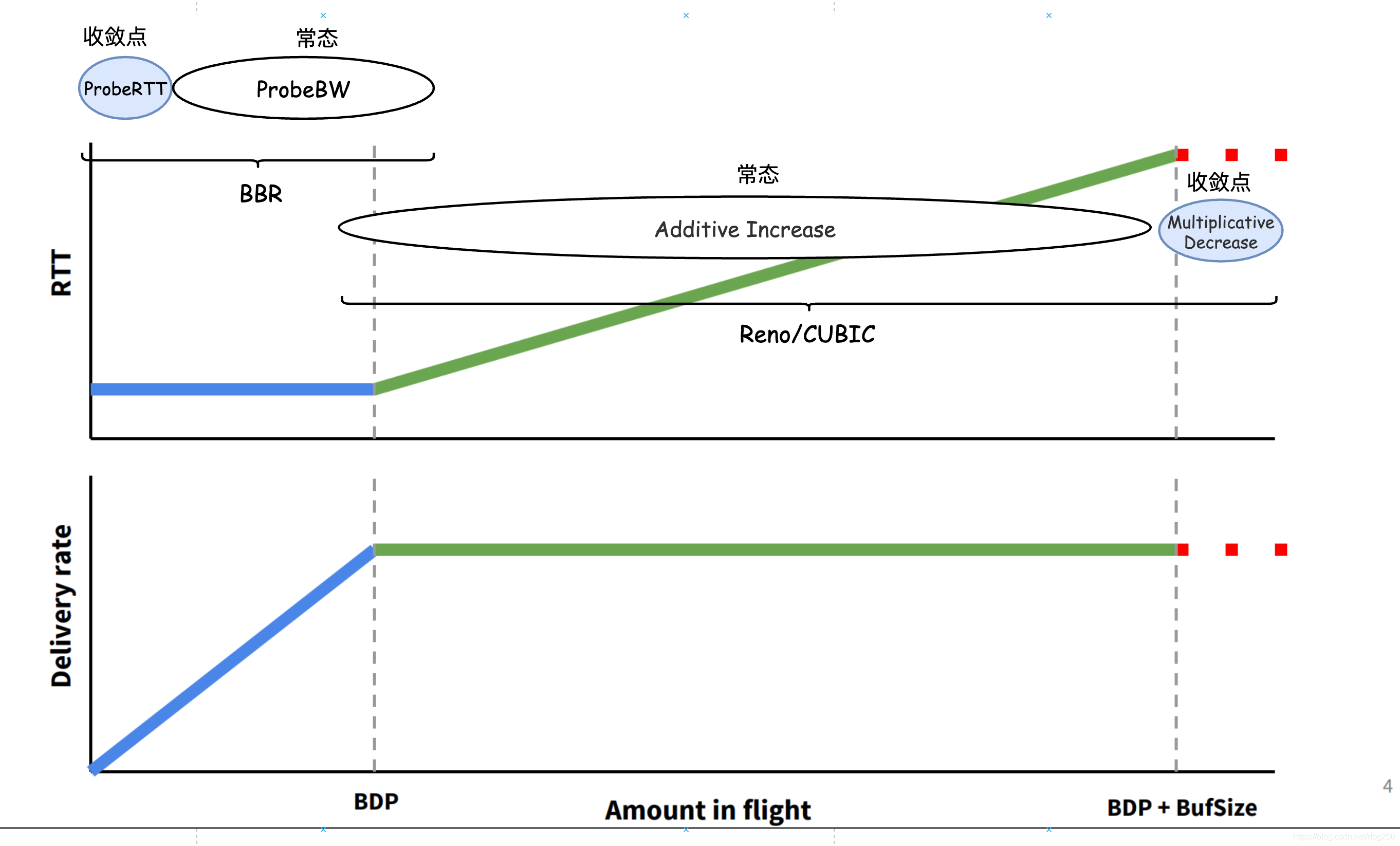
哈哈,Reno確實是 面向buffer的 ,它是bufferbloat的初始,沒有buffer的overflow便無法指示Reno的收斂點,
westwood像是一個經過BBR調制的Reno…
附帶一個引自BBR論文的描述:
BBR synchronizes flows around the desirable event of an empty bottleneck queue. By contrast, loss-based congestion control synchronizes around the undesirable events of periodic queue growth and overflow, amplifying delay and packet loss.
現在讓我們看為什么BBR會收斂到全域同步進入ProbeRTT狀態,我覺得還是參考原文的好:
To learn the true RTProp, a flow moves to the left of BDP using ProbeRTT state: when the RTProp estimate has not been updated (i.e., by measuring a lower RTT) for many seconds, BBR enters ProbeRTT, which reduces the inflight to four packets for at least one round trip, then returns to the previous state. Large flows entering ProbeRTT drain many packets from the queue, so several flows see a new RTprop (new minimum RTT). This makes their RTprop estimates expire at the same time, so they enter ProbeRTT together, which makes the total queue dip larger and causes more flows to see a new RTprop, and so on. This distributed coordination is the key to both fairness and stability.
BBR的ProbeRTT狀態的同步是一種自然的同步,
OK,現在我們確定了BBR的收斂點,即離開ProbeRTT階段進入ProbeBW的那一刻,在那一刻,BtlBw保持,而RTprop最新測得,為了保證公平性,需要在這個收斂點做點什么,就像Reno家族在buffer overflow做的MD減窗操作那樣,
遺憾的是,BBR在這里除了隨機選擇一個phase進入ProbeBW階段之外,什么也沒有做,我想象不出BBR論文中下圖的理由:
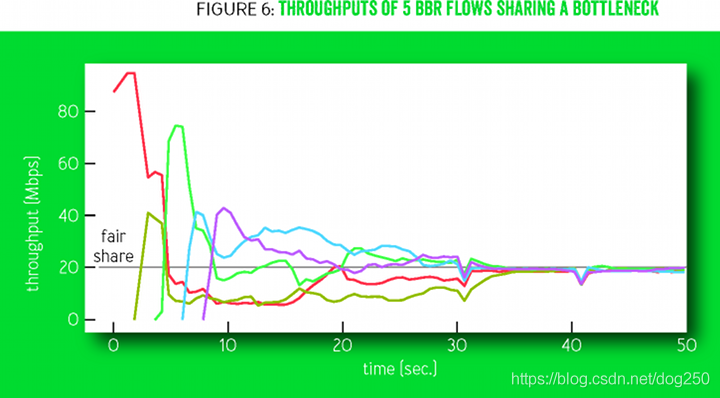
下面這個圖倒是像真的:
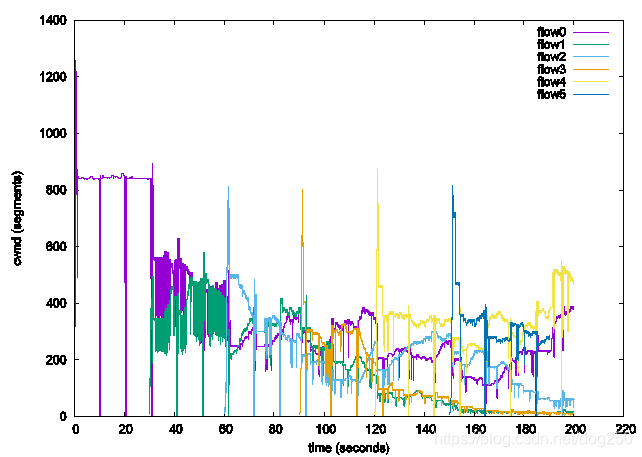
我的測驗結果如下:
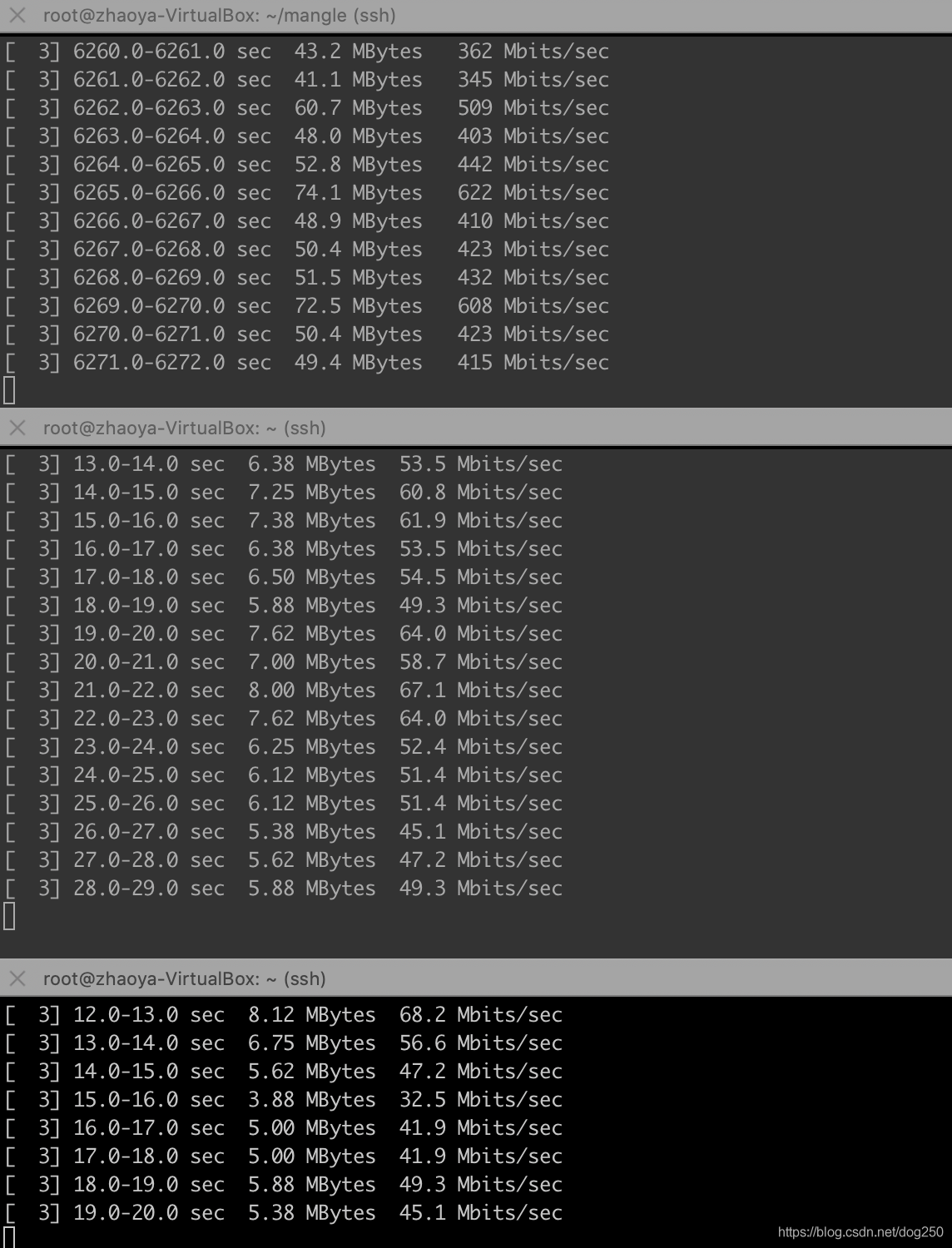
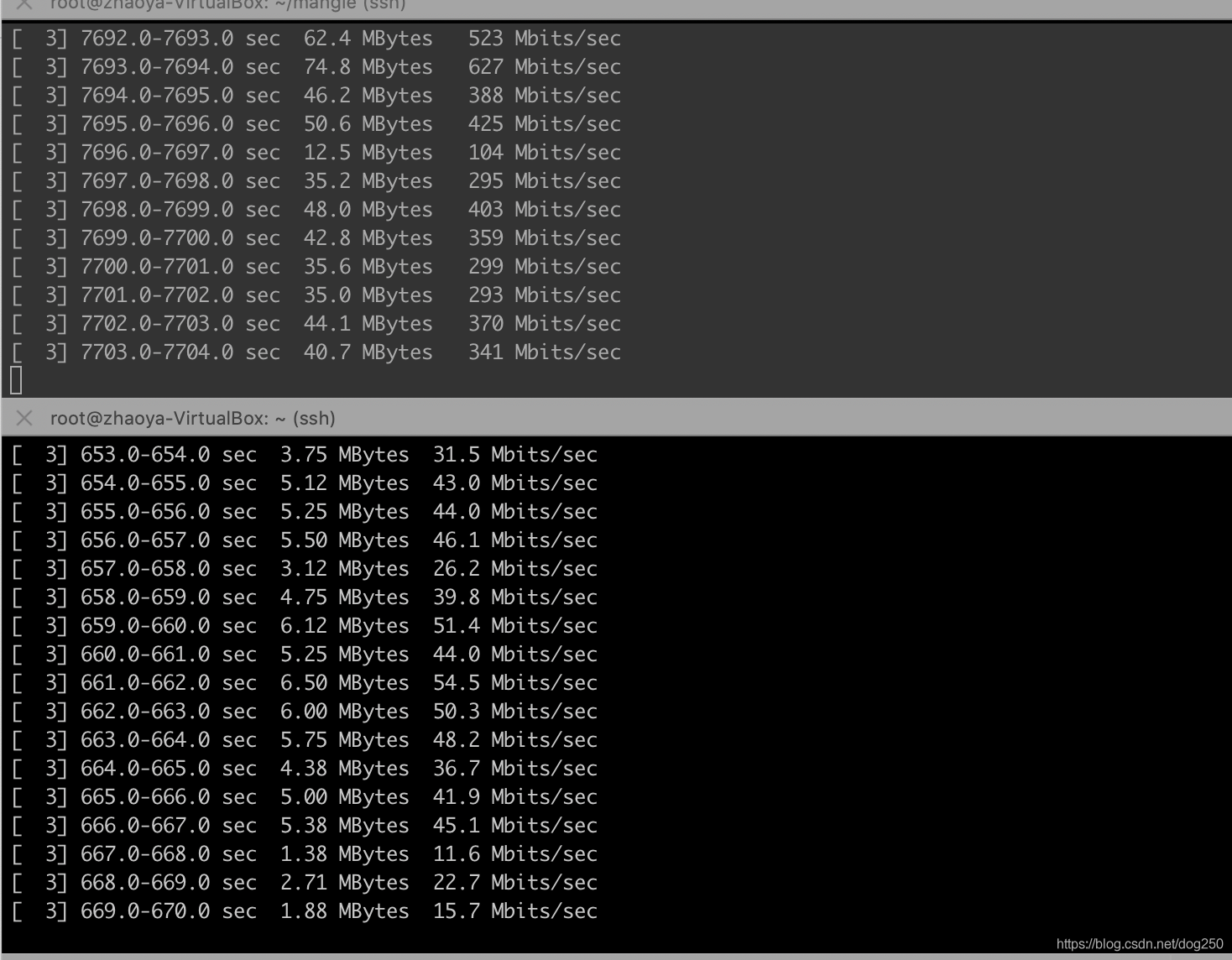
我想象不出除了靠運氣,還有什么潛在的動力學可以保證這些流最終收斂到公平,
假設塞滿整個pipe時兩條流的BtlBw之比是 m n \dfrac{m}{n} nm?,離開ProbeRTT狀態進入ProbeBW狀態時,除非二者分別一個up phase一個down phase,否則它們的BtlBw還將保持這個比例,
5 4 \dfrac{5}{4} 45?和 3 4 \dfrac{3}{4} 43?的均值是1,相當于什么也沒有做,除非真的有空余帶寬被加進來(有流退出或者路由重新收斂到更大帶寬的路徑)才會避免 3 4 \dfrac{3}{4} 43? down,
那么如何解決BBR的這個公平性問題?
按照控制論的觀點, 效率和公平是不可兼得的, 為了增強公平性,就不得不損失點效率,
我們知道,離開ProbeRTT狀態進入ProbeBW狀態時,所有BBR流的BtlBw之和等于網路pipe的瓶頸帶寬,沒有任何空余的帶寬空間可以用來執行公平性的作業,這個時候如果有流主動出讓帶寬,會被認為是 降低了帶寬利用率 ,而BBR的廣告詞就是提高帶寬利用率,主動降低帶寬實則打臉,我們可以從BBR論文里的一段話里看出,它涉及到一個小優化(但我并沒有在代碼里看到它的實作):
Furthermore, to improve mixing and fairness, and to reduce queues when multiple BBR flows share a bottleneck, BBR randomizes the phases of ProbeBW gain cycling by randomly picking an initial phase—from among all but the 3/4 phase—when entering ProbeBW. Why not start cycling with 3/4? The main advantage of the 3/4 pacing_gain is to drain any queue that can be created by running a 5/4 pacing_gain when the pipe is already full. When exiting Drain or ProbeRTT and entering ProbeBW, there is no queue to drain, so the 3/4 gain does not provide that advantage. Using 3/4 in those contexts only has a cost: a link utilization for that round of 3/4 instead of 1. Since starting with 3/4 would have a cost but no benefit, and since entering ProbeBW happens at the start of any connection long enough to have a Drain, BBR uses this small optimization.
但是,若想保證公平,必須有流出讓帶寬,這樣才能實作重分配,
問題是如何出讓,出讓多少呢?在我看來,在ProbeRTT狀態和ProbeBW狀態中間加一個Converge狀態即可:
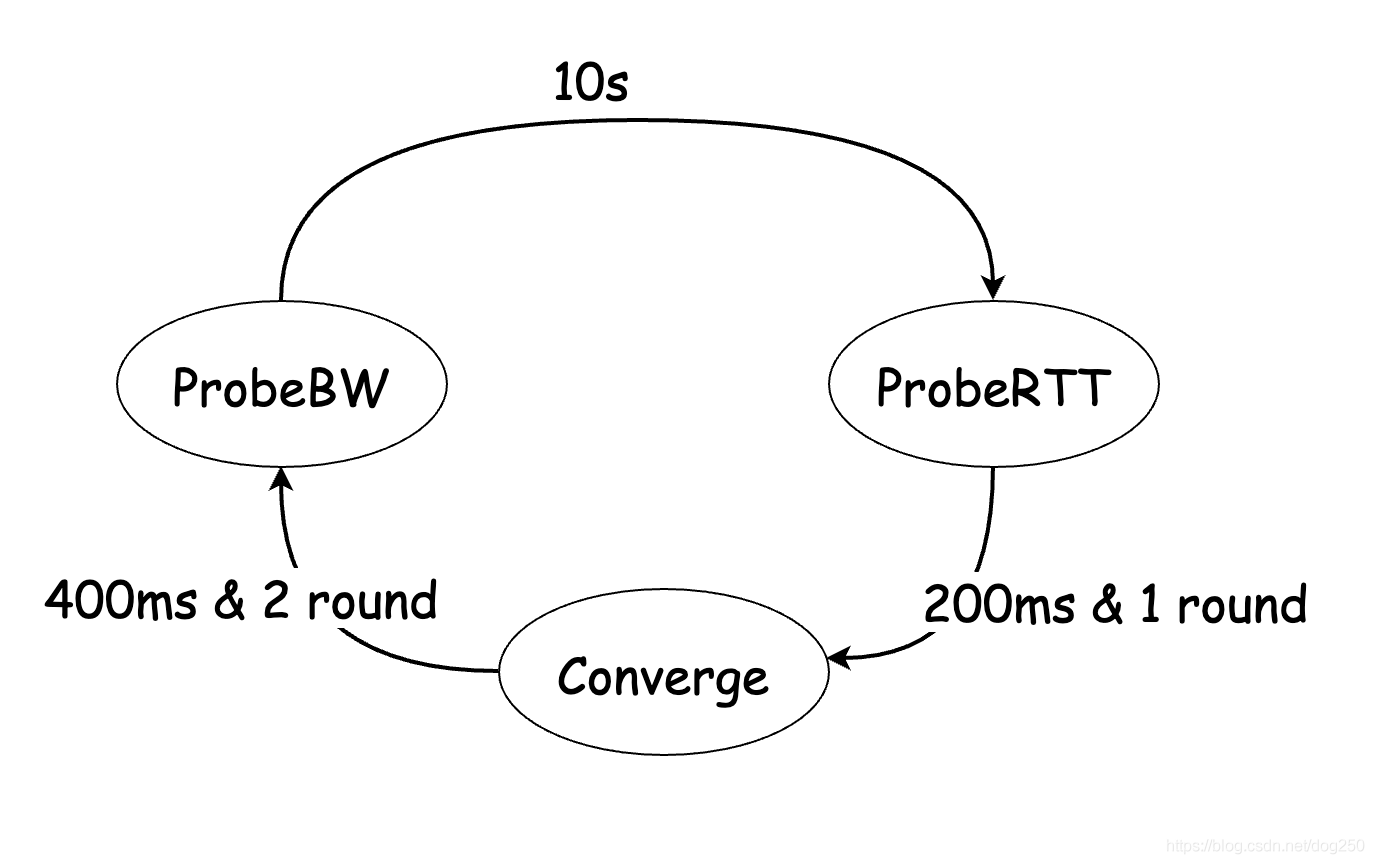
和ProbeRTT一樣的思路,用一個比較短但又足夠長的時間來range這個Converge狀態的持續時間,比方說400ms(雖不優雅,但再來個800ms又何妨),在這個Converge狀態,對pacing執行AIMD替代ProbeBW狀態的 5 4 \dfrac{5}{4} 45?, 3 4 \dfrac{3}{4} 43?固定增益的up,down操作:
ai_up()
{
if (sub_state != up)
return;
pacing_rate += 10/RTprop;
if (is_full_length &&
(rs->losses || /* perhaps pacing_gain*BDP won't fit */
inflight >= bbr_inflight(sk, bw, bbr->pacing_gain))) {
sub_state = down;
bbr->pacing_gain = BBR_UNIT * 3/4;
}
}
md_down()
{
if (sub_state != down)
return;
bbr->pacing_gain = BBR_UNIT;
if (is_full_length ||
inflight <= bbr_inflight(sk, bw, BBR_UNIT)
sub_state = up;
}
到頭來,其實Reno家族和BBR是一樣的:
- Reno家族通過丟包被動發現收斂點,
- BBR通過ProbeRTT主動發現收斂點,
都一樣,到達收斂點之后執行AIMD即可,
很多人所謂的魔改BBR都是扯淡,根本就不理解內在的機制,亂改一通而已,
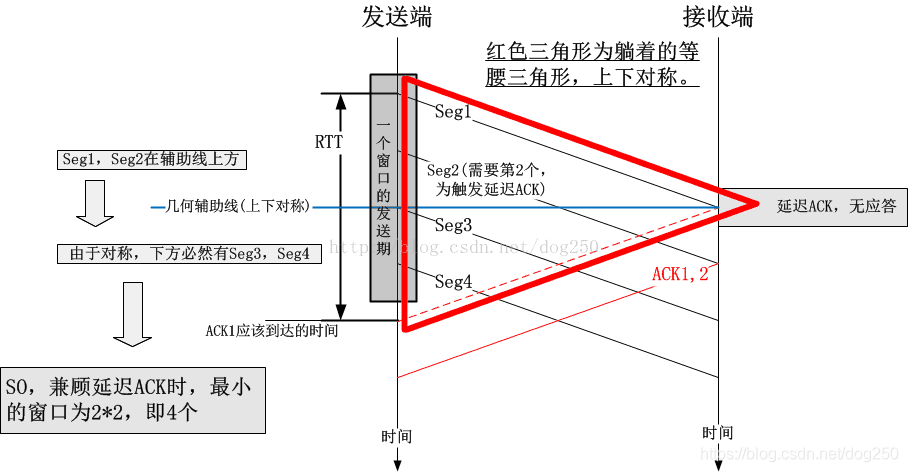
當有人看到ProbeRTT狀態只有4個視窗的時候,他們總覺得太少,總是手癢癢想加點兒,加到10?60?干脆75%吧…當他們看到200ms,10s,10輪的時候,忽而覺得時間太短,要么覺得時間太長,總之就是手癢,
為什么是4?為什么不是2?為什么不是INIT_CWND?什么叫 Try to keep at least 4 packets in flight, if things go smoothly.
請參見:https://blog.csdn.net/dog250/article/details/72042516
經理正好走到辦公室門口,滑了一下,滑跌了,可能是皮鞋底子不是牛筋底吧,但由于領帶沒有和西裝固定在一起,所以領帶保持在原來的高度,給人的感覺就是領帶好像飛起來了一樣,可是皮鞋的方向也變化了,
浙江溫州皮鞋濕,下雨進水不會胖,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/259052.html
標籤:AI
上一篇:程式員的浪漫,你值得擁有!