95%置信區間
科技論文里經常會出現【95%CI】的評價,這個評價到底有什么意義,他和68-95-99.7法則的關系是什么,可能很多人沒有清楚的理解,包括之前寫論文評價95%CI的自己,
目的
理解【95%CI置信區間】的含義,以及他和 【68-95-99.7%法則 】的關系,
什么是置信區間
首先明白置信區間的定義是什么:
在統計學中,一個概率樣本的置信區間(英語:Confidence interval,CI),是對產生這個樣本的總體的引數分布(Parametric Distribution)中的某一個未知引數值,以區間形式給出的估計,相對于點估計(Point Estimation)用一個樣本統計量來估計引數值,置信區間還蘊含了估計的精確度的資訊, 1
Keyword
- 置信區間并非評價該組樣本的發生概率
- 置信區間是通過概率樣本來推測 未知的總體引數
- 置信區間給出的是對于總體引數的 區間 估計,而非 點 估計
置信區間計算例
這里假設有10個人的體重作為總體引數,選5個人作為一組抽樣標本,來評價他們的平均值,10個人的體重分別如下表
| 路人1 | 路人2 | 路人3 | 路人4 | 路人5 | 路人6 | 路人7 | 路人8 | 路人9 | 路人10 |
|---|---|---|---|---|---|---|---|---|---|
| 50.4 | 54.6 | 55.2 | 58.4 | 64.3 | 65.5 | 69.1 | 71.4 | 74.5 | 88.3 |
我們可以知道總體引數的平均值為65.17
從這10個人的總體引數里,取出5個人作為抽樣標本并計算其平均值,
- 路人1~5作為標本1,其平均值為56.58.
- 路人3~7作為標本2,其平均值為62.5.
- 路人3,4,7,8,10作為標本3,其平均值為68.48.
| 總平均 | 標本1平均 | 標本2平均 | 標本3平均 |
|---|---|---|---|
| 65.17 | 56.58 | 62.5 | 68.48 |
結果可以知道,任意一組標本跟總體平均都不一致,
我們不能用標本的 點推測 來推測總體資料的平均值,
當然,很多人會說這理所應當的,這也是總所周知的事實,
一組抽樣標本,他的平均值并不能代表總體資料的平均值
換個思想,更簡單的話就是:
當我們在實驗室對10臺復合鋼做材料實驗,能獲得這一組強度資料,并進行資料整理的時候,得到的是這一組標本的資料,不能代表這個復合鋼全體的資料,如何通過這組標本獲得的資料,來推測復合鋼的性質,這時我們可能就需要用 區間推測 來評價復合鋼的強度,
這個時候我們就可以說,復合鋼強度平均值是在這個 區間范圍 以內,這個平均值不用點表示,而用 區間 來表示,
95%置信區間表示了什么
進入正題,論文里經常能看到的95%置信區間(95% Confidence Interval; 95%CI)到底代表了什么意思,
95%置信區間是通過標本資料平均值對總體平均值的區間推測指標
- 換句話說,95%置信區間是評價總體平均值的一個范圍,我們進行100組實驗,只有5組實驗資料的平均值是落在這個范圍之外的,
置信區間怎么求得的
知道了95%置信區間表示了什么意思之后,來看看置信區間是怎么通過計算獲得的,要理解95%CI,首先我們得先理解標準誤差(Standard Error; SE),
標準誤差SE和標準偏差SD很相似,
注意不要搞混淆,這里有說明他們的區別,
簡單的說
標 準 誤 差 S E = 標 準 偏 差 S D / ( n ) 標準誤差SE=標準偏差SD/\sqrt (n) 標準誤差SE=標準偏差SD/( ?n)
這里的n代表實驗體個數,
這里可以看出,實驗體個數越多,SE就越小
舉個簡單的例子
假如想知道20歲的平均身高,
這個時候研究組A隨機抽取了50個人獲得了資料,研究組B隨機抽取了1000個人獲得了資料,
但是這兩組資料測得了完全一樣的資料:平均值為165cm,標準偏差為20,
我們如何評價研究組A和B的資料,能認為他們兩組資料一模一樣嗎,
這個時候大家憑感覺也知道抽取1000個人的研究組B的可靠性比較高,
| 研究組名 | 樣本數 | 平均值 | 標準偏差SD | 標準誤差SE |
|---|---|---|---|---|
| 研究組A | 50 | 165 | 20 | 20 / ( 50 ) 20/\sqrt(50) 20/( ?50)=2.83 |
| 研究組B | 1000 | 165 | 20 | 20 / ( 1000 ) 20/\sqrt(1000) 20/( ?1000)=0.63 |
從上面的資料我們可以看出 離散程度完全一樣的兩組資料中,樣本數的多少所表達出的對資料的可靠程度也不一樣,
這里我們可以得出重要的結論:
標準偏差代表了一組資料的離散程度,而標準誤差代表了這個平均值的可靠程度,
通過標準誤差來求得置信區間
通過上面的結論,我們知道了標準誤差SE可以代表了平均值的可靠程度,意味著我們可以通過標準誤差來推測總體資料的平均值,
理解了標準誤差SE,95%CI也能很好的理解,
資料服從正太分布的時候,95%CI可以通過如下式子計算獲得:
95%CI=1.96*SE
所以95%置信區間為:平均值±1.96SE
為什么是1.96的系數怎么計算,核心思想是跟【68-95-99.7法則】是一樣的, 是通過對概率密度函式積分所獲得,
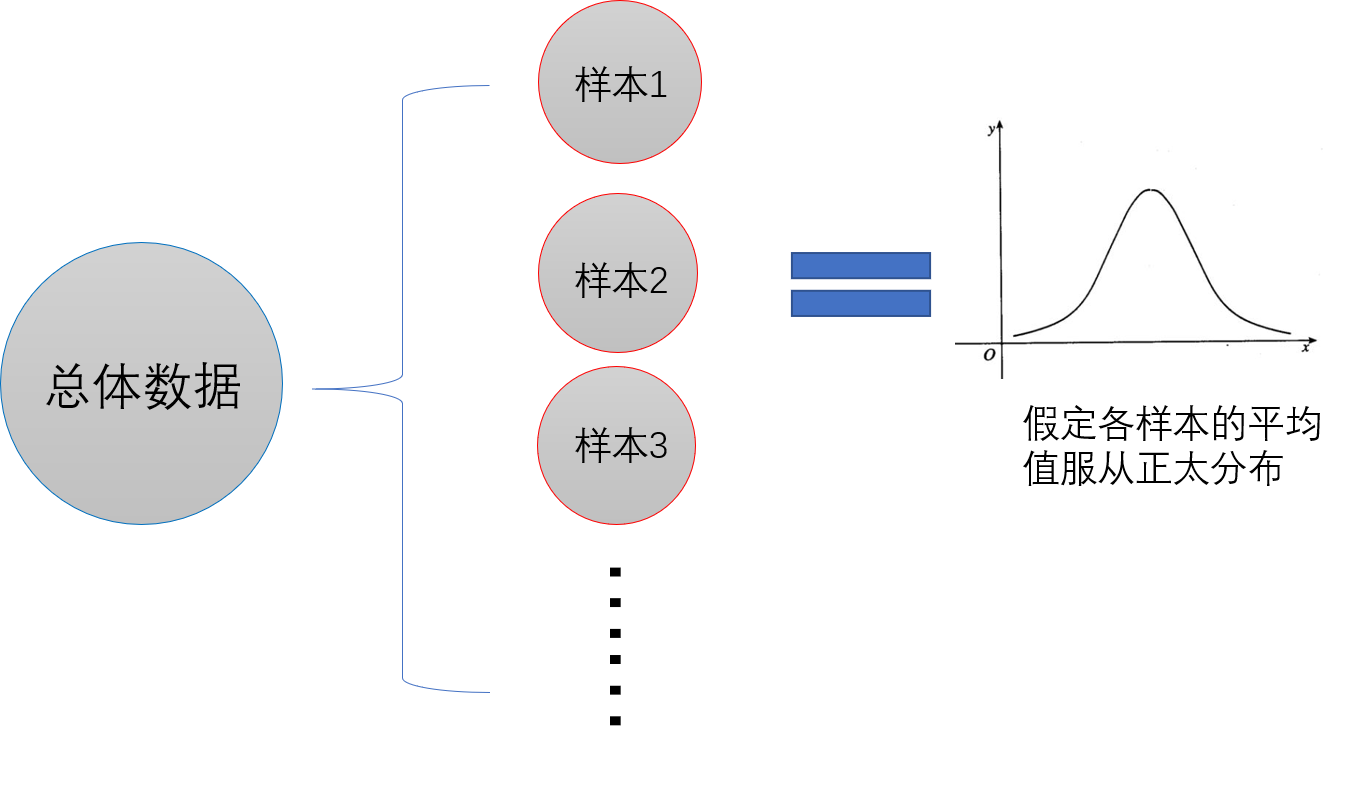
首先,我們獲得了總體資料里的一組樣本,我們可以從中計算出其平均值,
假定有多個樣本有分別不同的平均值,此時我們就可以得到總體資料對于平均值的分布,
當我們把樣本的平均值,當作一組樣本里的一個資料時,我們就可以用正太分布的性質來評價樣本的平均值,也就是n組樣本里大約有68%的平均值落在總體樣本里的 平均值±SE 的范圍里,95.5%的平均值落在 平均值±2SE 的范圍里,
所以95%的置信區間為 平均值 μ \mu μ ± 1.96SE
總結
- 標準偏差用來評價一組資料內的離散程度,可以通過【68-95-99.7法則】推測資料的分布范圍
- 標準誤差是評價一組樣本平均值的可靠性,并通過它可以推測總體資料的平均值的可靠范圍,
- 95%的置信區間意思為,假設做了100次實驗,100次實驗中有5次實驗的平均值是不在置信區間的范圍內,
- 95%置信區間的計算式為: 95%CI=1.96*SE

本作品采用知識共享署名-非商業性使用-相同方式共享 4.0 國際許可協議進行許可,
en.wikipedia.org/wiki/Confidence_interval ??
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/259167.html
標籤:AI
上一篇:2021年第一天的祝福送給大家