python網路爬蟲抓取數個最優鏈接展示(百度抓取)
文章目錄
- python網路爬蟲抓取數個最優鏈接展示(百度抓取)
- 前言
- 一、庫宣告
- 二、步驟
- 1.引入庫
- 2.獲取命令列引數
- 3.找到查詢的結果
- 4.打開瀏覽器
- 三、完整代碼
前言
今天試一下python網路爬蟲的鏈接抓取實戰,一起來試一下
一、庫宣告
我們這次需要用到requests,sys, webbrowser,bs4,os庫,如果沒有庫的小伙伴可以看我這個博文,pip快速安裝各種庫
二、步驟
1.引入庫
代碼如下(示例):
import requests,sys, webbrowser,bs4,os
2.獲取命令列引數
如果有小伙伴問,什么是命令列引數?請看我的一些理解與解釋,希望可以幫你梳理一下思路
1、 什么是命令列的引數?
如:我在cmd里面,輸入了1.路徑檔案后,2.加上空格,3.再加上后面輸入的引數,這個3,就是命令列引數的主要組成部分(前面還附帶了檔案名,看不懂沒關系,我們上圖!!!不啰嗦)

這是代碼
代碼如下
res=requests.get('http://www.baidu.com/s?wd='+''.join(sys.argv[1:]))
print(sys.argv[0])
print(sys.argv[1])
print(sys.argv[2])
print(sys.argv[3])
print(sys.argv[0:])
print(sys.argv[1:])
對應起來看,大家會發現命令列引數就是在你輸入的引數前,再加上檔案名字作為sys.argv[0],依次按照順序構成串列,看到這里,相信大家應該可以明白命令列引數的基本構成了,那么我們繼續!(因為考慮到可能并不是每個人都喜歡用cmd,來輸入命令列進行運行程式,所以,我特地安排了在python IDLE中也同樣可以輸入命令運行,希望可以方便到大家,)
3.找到查詢的結果
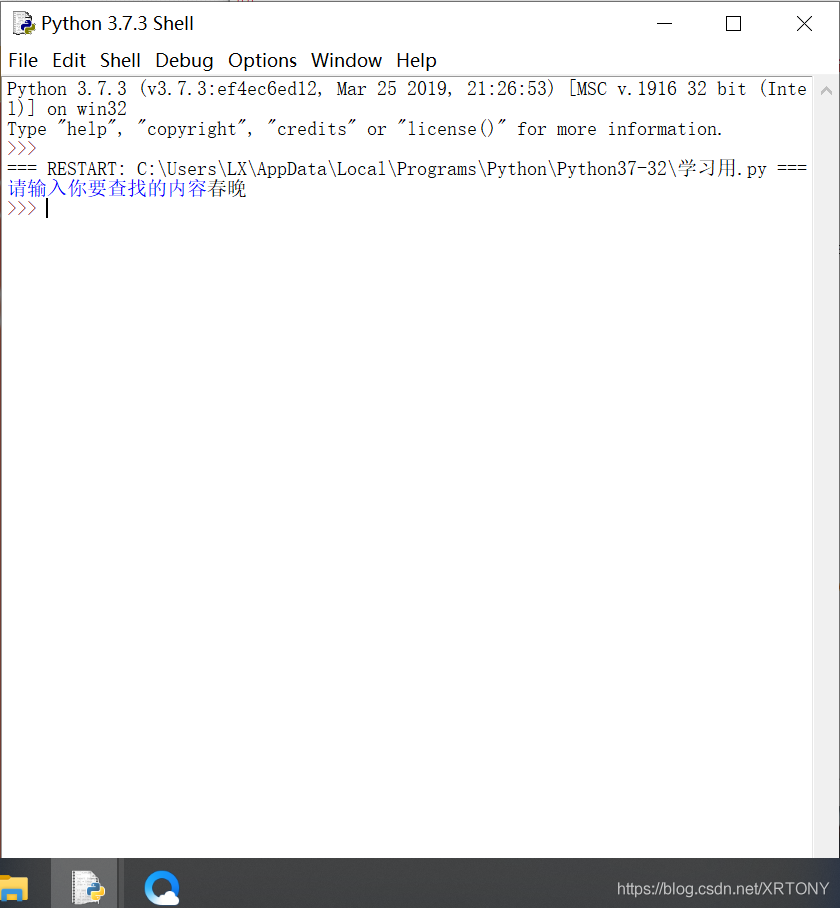
search=input('請輸入你要查找的內容')
res=requests.get('http://www.baidu.com/s?wd='+search)#用requests.get獲得
res.encoding='utf-8'
res.raise_for_status()#檢驗是否已經連接
soup=bs4.BeautifulSoup(res.text,'lxml')#后面記得寫這個lxml顯式指定語法分析器
linkElems=soup.select('div.result h3.t > a')#百度和谷歌的select輸入并不相同
4.打開瀏覽器
numOpen=min(5,len(linkElems))#這里我們只獲得5條網頁回傳
for i in range(numOpen):
webbrowser.open(linkElems[i].get('href'))
三、完整代碼
#! python3
import requests,sys, webbrowser,bs4,os
if len(sys.argv)>1:
res=requests.get('http://www.baidu.com/s?wd='+''.join(sys.argv[1:]))
else:
search=input('請輸入你要查找的內容')
res=requests.get('http://www.baidu.com/s?wd='+search)
res.encoding='utf-8'
res.raise_for_status()
os.chdir(r'C:\Users\LX\Desktop')
soup=bs4.BeautifulSoup(res.text,'lxml')
linkElems=soup.select('div.result h3.t > a')
numOpen=min(5,len(linkElems))
for i in range(numOpen):
webbrowser.open(linkElems[i].get('href'))
最后展示一下顯示結果,先方法一,不用命令列引數
方法二,用命令列引數
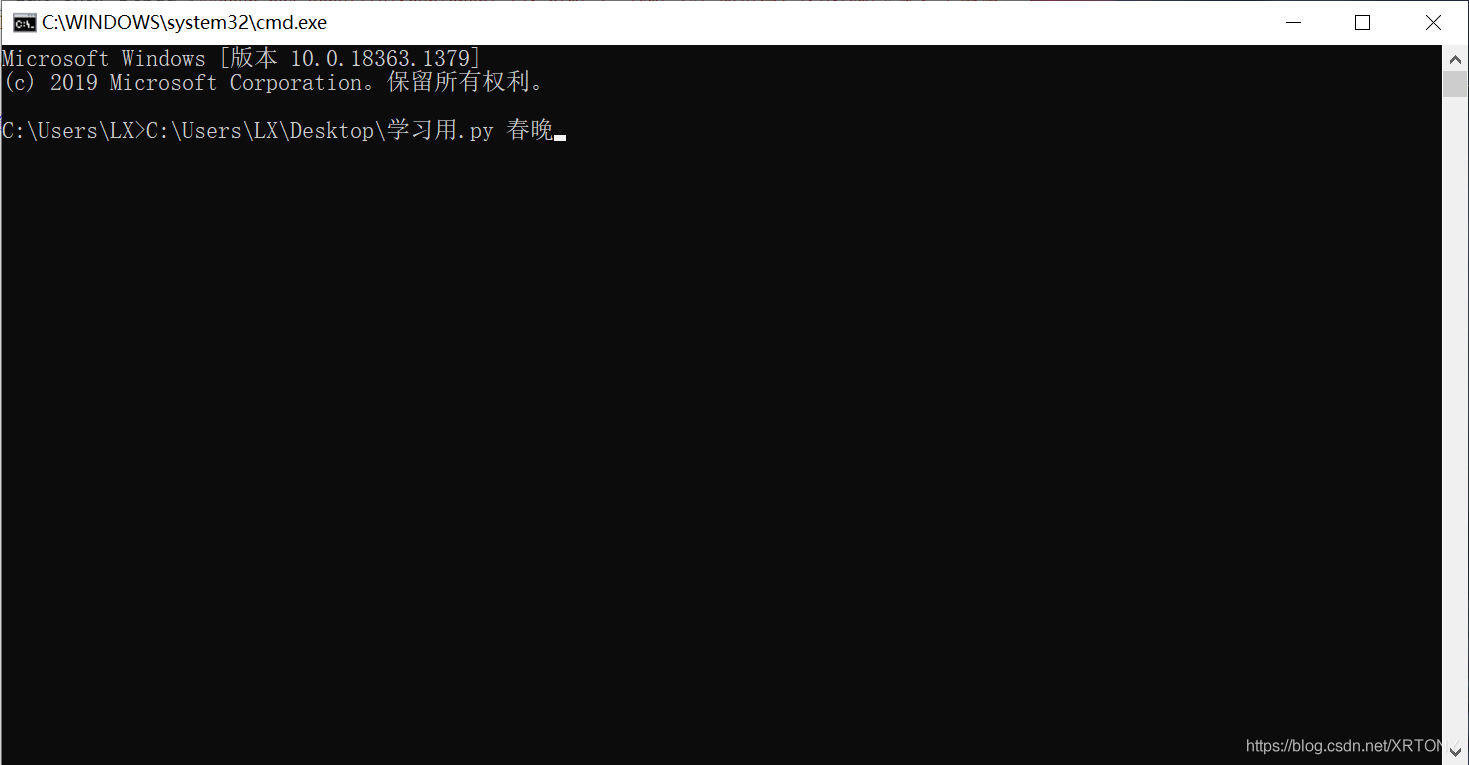
可以看到,再次打開5個頁面
這次就到這里,謝謝大家
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/259404.html
標籤:AI