文章目錄
- 一.演算法效率
- 二.時間復雜度
- 1.時間復雜度的概念
- 2.大 o的漸進表示法
- 3.常見時間復雜度的計算
一.演算法效率
演算法效率分析分為兩種:第一種是時間效率,第二種是空間效率,時間效率被稱為時間復雜度,而空間效率被稱作空間復雜度, 時間復雜度主要衡量的是一個演算法的運行速度,而空間復雜度主要衡量一個演算法所需要的額外空間,在計算機發展的早期,計算機的存盤容量很小,所以對空間復雜度很是在乎,但是經過計算機行業的迅速發展,計算機的存盤容量已經達到了很高的程度,所以我們如今已經不需要再特別關注一個演算法的空間復雜度,
二.時間復雜度
1.時間復雜度的概念
時間復雜度的定義:在計算機科學中,演算法的時間復雜度是一個函式,它定量描述了該演算法的運行時間,一個演算法執行所耗費的時間,從理論上說,是不能算出來的,只有你把你的程式放在機器上跑起來,才能知道,但是我們需要每個演算法都上機測驗嗎?是可以都上機測驗,但是這很麻煩,所以才有了時間復雜度這個分析方式,一個演算法所花費的時間與其中陳述句的執行次數成正比例,演算法中的基本操作的執行次數,為演算法的時間復雜度,
2.大 o的漸進表示法
實際中我們計算時間復雜度時,我們其實并不一定要計算精確的執行次數,而只需要大概執行次數,那么這里我們使用大O的漸進表示法,
大O符號(Big O notation):是用于描述函式漸進行為的數學符號.
推導大O階方法:
1、用常數1取代運行時間中的所有加法常數,
2、在修改后的運行次數函式中,只保留最高階項,
3、如果最高階項存在且不是1,則去除與這個專案相乘的常數,得到的結果就是大O階,
// 請計算一下Func1基本操作執行了多少次?
void Func1(int N)
{
int count = 0; // 1次
for (int i = 0; i < N; ++i)
{
for (int j = 0; j < N; ++j)
{
++count; // N*N次
}
}
for (int k = 0; k < 2 * N; ++k)
{
++count; // 2*N次
}
int M = 10;
while (M--)
{
++count; // 10次
}
printf("%d\n", count); // 1次
}
Func1 執行的基本操作次數 :
F(N) = N*N + 2 * N + 12
使用大O的漸進表示法以后,Fun1的時間復雜度為 O(N^2)
通過上面我們會發現大O的漸進表示法去掉了那些對結果影響不大的項,簡潔明了的表示出了執行次數,
另外有些演算法的時間復雜度存在最好、平均和最壞情況:
最壞情況:任意輸入規模的最大運行次數(上界)
平均情況:任意輸入規模的期望運行次數
最好情況:任意輸入規模的最小運行次數(下界)
例如:在一個長度為N陣列中搜索一個資料x
最好情況:1次找到
最壞情況:N次找到
平均情況:N/2次找到
在實際中一般情況關注的是演算法的最壞運行情況,所以陣列中搜索資料時間復雜度為O(N)
3.常見時間復雜度的計算
(1).
// 計算Func2的時間復雜度?
void Func2(int N)
{
int count = 0; // 1次
for (int k = 0; k < 2 * N; ++k)
{
++count; // 2 * N次
}
int M = 10; // 1次
while (M--)
{
++count; // 10次
}
printf("%d\n", count); // 1次
}
Func2 執行的基本操作次數 :
F(N) = 2 * N + 13
使用大O的漸進表示法以后,Fun1的時間復雜度為 O(N)
(2).
// 計算Func3的時間復雜度?
void Func3(int N, int M)
{
int count = 0; // 1次
for (int k = 0; k < M; ++k)
{
++count; // M次
}
for (int k = 0; k < N; ++k)
{
++count; // N次
}
printf("%d\n", count); // 1次
}
Func2 執行的基本操作次數 :
F(N) = M + N + 2
使用大O的漸進表示法以后,Fun1的時間復雜度為 O(M + N)
(3).
// 計算Func4的時間復雜度?
void Func4(int N)
{
int count = 0;
for (int k = 0; k < 100; ++k)
{
++count;
}
printf("%d\n", count);
}
因為執行次數為常數,由第一條規則:
用常數1取代運行時間中的所有加法常數
可知時間復雜度為: O(1)
(4).
// 計算BubbleSort的時間復雜度?
void BubbleSort(int* arr, int n)
{
assert(arr); // 1次
int i = 0; // 1次
for (i = 0; i < n - 1; i++)
{
int flag = 0; // n - 1次
int j = 0; // n - 1次
for (j = 0; j < n - 1 - i; j++)
{
if (arr[j] > arr[j + 1]) // 1 + 2 +3 + ....+ n - 1次
{
int tmp = arr[j]; // 1 + 2 +3 + ....+ n - 1次
arr[j] = arr[j + 1]; // 1 + 2 +3 + ....+ n - 1次
arr[j + 1] = tmp; // 1 + 2 +3 + ....+ n - 1次
flag = 1; // 1 + 2 +3 + ....+ n - 1次
}
}
if (flag == 0)
break;
}
}
考慮最壞的情況,資料為降序,將其排為升序
BubbleSort 執行的基本操作次數 :
F(N) = 2 * n^2 + n
使用大O的漸進表示法以后,BubbleSort 的時間復雜度為 O(n^2)
考慮最好的情況,資料本來就是升序,只需要進行最內層回圈 j 從 0 到 n - 1,進行 n - 1 比較,之后檢查出有序,即可退出整個回圈
復雜度為 O(n)
(5).
// 計算BinarySearch的時間復雜度?
int BinarySearch(int* a, int n, int x)
{
assert(a);
int begin = 0;
int end = n - 1;
while (begin <= end)
{
int mid = begin + ((end - begin) >> 1);
if (a[mid] < x)
begin = mid + 1;
else if (a[mid] > x)
end = mid - 1;
else
return mid;
}
return -1;
}
因為二分查找每次排除掉一半的不適合值,所以對于n個元素的情況:
一次二分剩下:n/2
兩次二分剩下:n/2/2 = n/4
…
m次二分剩下:n/(2^m)
在最壞情況下是在排除到只剩下最后一個值之后得到結果,所以為
n/(2^m)=1;
2^m=n;
m = log2^n
而在資料結構中常常這樣寫lgn,所以時間復雜度為O(lgn);
(6).
// 計算階乘遞回Factorial的時間復雜度?
long long Factorial(size_t N)
{
return N < 2 ? N : Factorial(N - 1) * N;
}

遞回演算法的時間復雜度計算方法:
遞回的次數 * 每次遞回函式內操作的次數
求N的階乘需要遞回 N 次,每次遞回函式內操作 1 次,因此時間復雜度為 O(N)
(7).
// 計算斐波那契遞回Fibonacci的時間復雜度?
long long Fibonacci(size_t N)
{
return N < 2 ? N : Fibonacci(N-1)+Fibonacci(N-2);
}
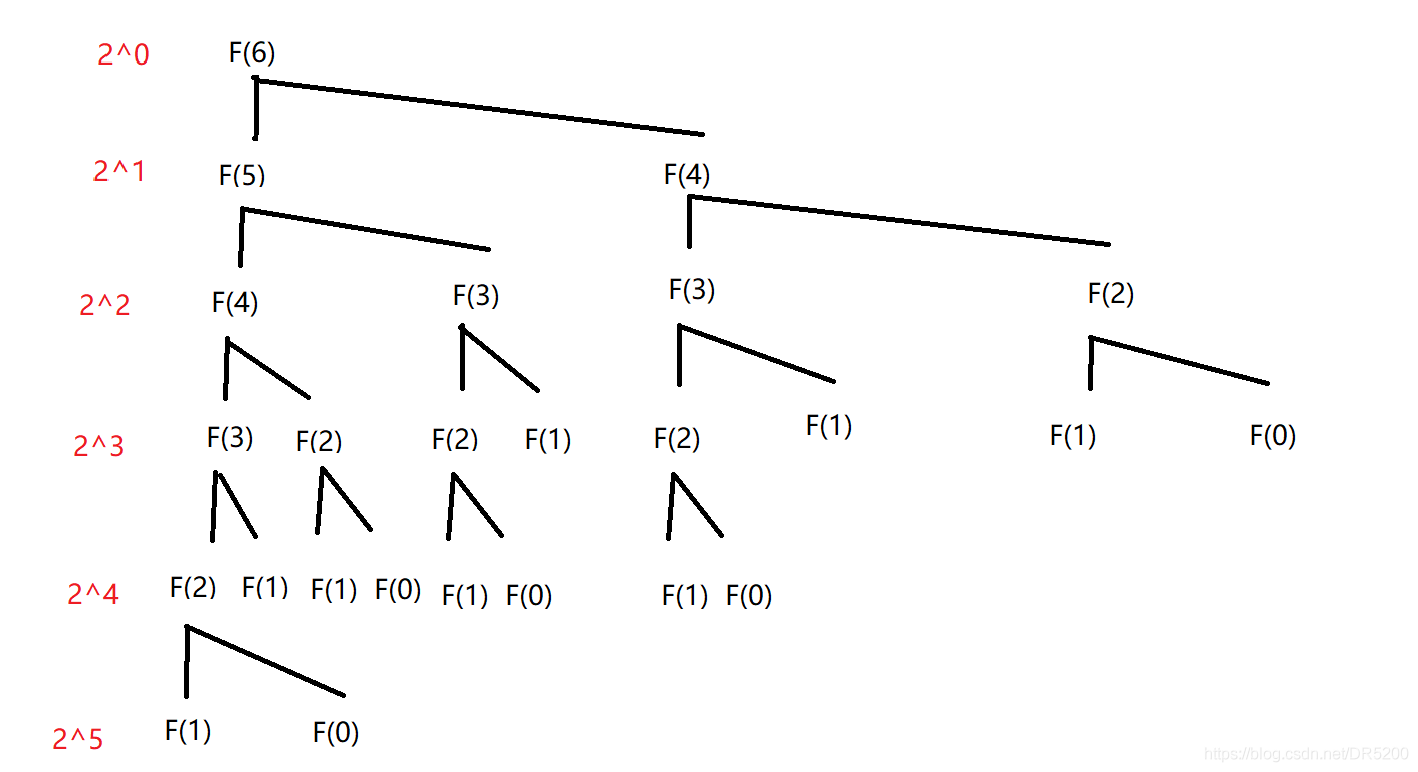 總結點數 = 斐波那契數列數列執行次數
總結點數 = 斐波那契數列數列執行次數
若為滿二叉樹,則執行次數為:
2^0 + 2^1 + 2^ 2 + …+ 2^(n - 1) = 2^n - 1
我們可以發現在圖中越靠右的部分越先停止呼叫,因此執行次數會比滿二叉樹的情況少,但當N足夠大時,這些少執行的部分影響微乎其微,
而且我們其實并不一定要計算精確的執行次數,而只需要大概執行次數,由大O的漸進表示法可知時間復雜度為O(2^n)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/259411.html
標籤:AI