1. ArrayList如何保證執行緒安全?
// 答案:
// 方式一:
// synchronizedList底層相當于把集合的set add remove方法加上synchronized鎖
List<Object> list = Collections.synchronizedList(new ArrayList<>());
// 方式二:
// 使用執行緒安全的CopyOnWriteArrayList,其底層也是對增刪改方法進行加鎖:final ReentrantLock lock = this.lock;
// 方式三:
// 自己寫一個包裝類,繼承ArrayList 根據業務,對add set remove方法進行加鎖控制
2. Vector 和 ArrayList 的初始容量和擴容?
- 二者初始容量均為0,即在呼叫空參建構式實體化時,二者容量為0,并在第一次加入元素資料時候附上初始容量值10
- Vector擴容時,如果未指定擴容遞增值capacityIncrement,或該值不大于0時,每次擴容為原來的1倍,否則擴容量為capacityIncrement的值
- ArrayList擴容時,每次擴容為原來的1.5倍
3. CopyOnWriteArrayList添加新元素是否需要擴容?具體是如何做的?
- CopyOnWriteArrayList 底層并非動態擴容陣列,不能動態擴容,其執行緒安全是通過加可重入鎖ReentrantLock來保證的
- 當向CopyOnWriteArrayList添加元素時,執行緒獲取鎖的執行權后,add 方法中會新建一個容量為(舊陣列容量+1)的陣列,將舊陣列資料拷貝到該陣列中,并將新加入的資料放入新陣列尾部
代碼如下:
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
CopyOnWriteArrayList適用于,讀多寫少的情況下(讀寫分離)!因為每次呼叫修改陣列結構的方法都需要重新新建陣列,性能低!
4. HashMap 與 HashTable 的區別?
HashMap
- HashMap:底層是基于陣列+鏈表 + 紅黑樹,非執行緒安全的,默認容量是16、允許有空的健和值
- 初始
size為16,擴容:newsize = oldsize << 1,size一定為2的n次冪 - 當Map中元素總數超過Entry陣列的75%,觸發擴容操作,為了減少鏈表長度,元素分配更均勻計算
index方法:index = hash & (tab.length – 1) - 擴容針對整個Map,每次擴容時,原來陣列中的元素依次重新計算存放位置,并重新插入
HashTable
- HashTable:底層陣列+鏈表實作,無論key還是value都不能為
null,執行緒安全,實作執行緒安全的方式是在修改資料時鎖(synchroized)住整個HashTable,效率低,ConcurrentHashMap做了相關優化 - 初始
size為11,擴容:(tab.length << 1) + 1 - 計算
index的方法:index = (hash & 0x7FFFFFFF) % tab.length
二者區別
- HashMap不是執行緒安全的,HashTable是執行緒安全的
- HashMap允許將null作為一個entry的key或者value,而Hashtable不允許
- HashMap把Hashtable的contains方法去掉了,改成containsvalue和containsKey,因為contains方法容易讓人引起誤解
- Hashtable繼承自Dictionary類,而HashMap是Map 介面的一個實作類
HashMap與HashTable 求index桶位
- HashMap:
index = hash & (tab.length – 1) - HashTable:
index = (hash & 0x7FFFFFFF) % tab.length
二者求桶位index的公式都是為了使每次計算得到的桶位index更分散,這樣可以降低哈希沖突,
HashTable中:
0x7FFFFFFF是0111 1111 1111 1111 1111 1111 1111 1111:除符號位外的所有 1(hash & 0x7FFFFFFF)得到的結果將產生正整數(hash & 0x7FFFFFFF) % tab.length計算得到的index結果始終為正整數,且確保index的值在tab.length范圍內!- HashTable 的陣列長度采用奇數導致的hash沖突會比較少,采用偶數會導致的沖突會增多!所以初始容量為11,擴容為
newsize = olesize << 1+1,保證每次擴容結果均為奇數
HashMap中:
- 初始容量為 16,當有效資料數量達到陣列容量的0.75倍時,觸發擴容
- 桶位計算公式:
index = hash & (tab.length – 1),計算桶位index時,容量一定要為2的n次冪,即偶數,這樣是為了減少hash沖突,擴容:newsize = oldsize << 1,得到的結果也是偶數 - 此外桶中的鏈表長度大于8時且陣列長度達到64,鏈表進行樹化,小于6時進行反樹化
- JDK1.8前HashMap中的鏈表采用的是頭插法,優點是:效率高于尾插法,因為不需要遍歷一次鏈表再進行資料插入
- JDK1.8后使用尾插法,之所以采用尾插法是因為要去判段鏈表的長度是否大于了8
- HashMap解決哈希沖突的方法采用的是:鏈表法
- HashMap是先插入資料再判斷是否需要庫容!
5. HashMap和TreeMap的區別?
- HashMap 上面介紹過了,直接看TreeMap
- TreeMap 底層是基于平衡二叉樹(紅黑樹),可以自定義排序規則,要實作Comparator介面,能便捷的實作內部元素的各種排序,但是性能比HashMap差
6. Set和Map的關系
- 二者核心都是不保存重復的元素,存盤一組唯一的物件
- Set的每一種實作都是對應Map里面的一種封裝
- 例如HashSet 底層對應的就是封裝了HashMap,TreeSet底層就是封裝了TreeMap
7. 插件Map的排序規則是怎樣的?
- LinkedHashMap,按照元素添加順序排序(也可以設定成按照訪問順序排序)
- TreeMap,可以按照自然排序,也可以自定義排序
TreeMap(Comparetor c)
8. HashMap底層為什么選擇紅黑樹而不用其他樹,比如二叉查找樹,為什么不一開始就使用紅黑樹,而是鏈表長度到達8且陣列容量大于64的時候才樹化?
- 二叉查找樹在特殊情況下也會變成一條線性結構,和原先的長鏈表存在一樣的深度遍歷問題,查找性能慢,例如:
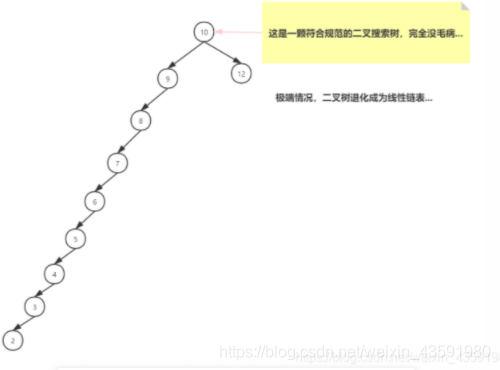
- 使用紅黑樹主要是為了提升查找資料的速度,紅黑樹是平衡二叉樹的一種,插入新資料后會通過左旋,右旋,變色等操作來保持平衡,解決單鏈表查詢深度的問題
- 之所以一開始不用紅黑樹是因為,當鏈表資料量少的時候,遍歷線性鏈表比遍歷紅黑樹消耗的資源少 (因為少量資料,紅黑樹本身自選、變色保持平衡也是需要消耗資源的),所以前期使用線性表
- 而之所以以8為樹化門檻,是因為經過大量測驗,8這個值是最合適的
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/259416.html
標籤:其他
上一篇:執行緒安全與同步總結