嗷嗚!
作為不是在戲精,就是在戲精的路上的二哈
本汪最近又搞到了新玩意兒
做數倉,主要用于支撐大資料分析和架構層決策
前言
通過這篇文章,我們能學到什么:
1、了解數倉的前景,
2、了解到數倉前期ETL 所面臨的問題,
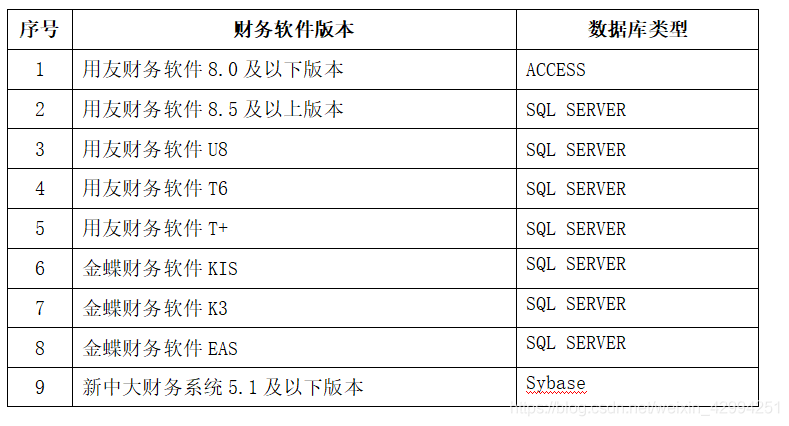
3、了解到當下市面上常見的金融管理軟體,用友、金蝶等進行移庫時,資料型別的轉換情況,及其軟體本身存在的問題所帶出的挑戰,
4、經濟實用的工具軟體推薦,
這篇博客為本汪“數倉系列”博客的開篇,后期本汪會隨著專案的推進,為大家帶來更多實際研發程序中碰到的問題及解決方案,
一、前景
城市數字化轉型,首當其沖的,便是要實作資料富足
2020.12.26 日,在江蘇南京舉辦的,第二屆全國中臺戰略大會暨第四屆互聯網構架峰會,本汪當時也是有幸參會,識訓了不少前沿資訊,嗷嗚嗷嗚!
另外有需要當時會議內部資料的,可以留言哦!
珍貴的歷史照片,如下:




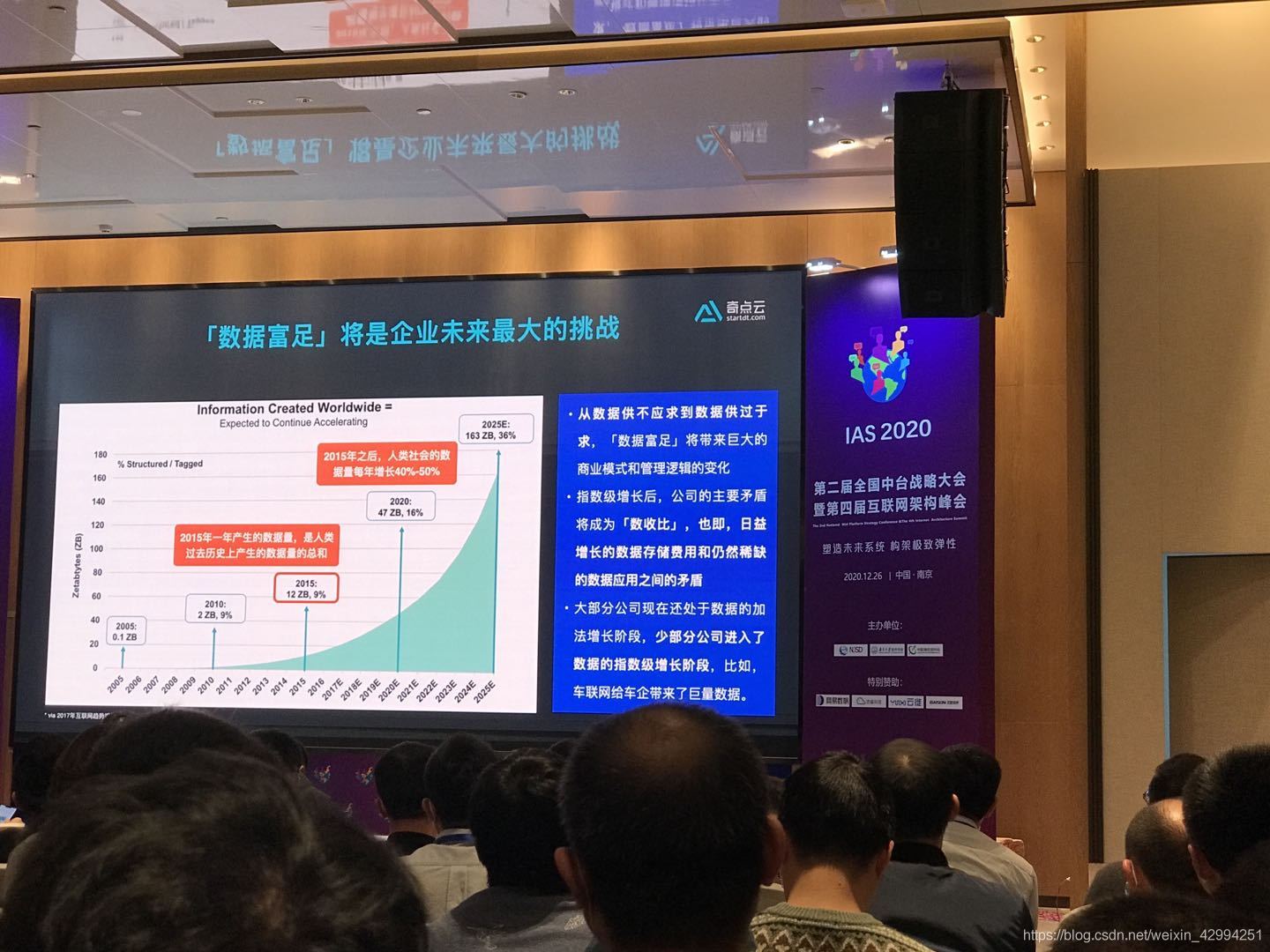
會議中,提到的數倉的使用場景:
1、邊境緝毒:利用監控設備對毒販常開車輛進行資料采集,之后根據地區、團伙大小進行資料模型的建立,結合演算法,對符合條件的車輛進行預警標識,從而提醒邊防武警進行重點檢查,大大提高了云南等邊境地區的販毒打擊效率,
2、智慧城市:按網格劃分,對城市的各個區域,各項資料進行多維度展示和監控,從而提前預警,實時反饋,為城市的宏觀調控提供資料支撐,
3、促進企業的數字化轉型:大多數企業可能已經擁有了大量的業務資料,但是有資料并不代表已經實作了資料富足,資料富足,是指按照業務邏輯,將有效資料按不同維度進行整合,從而有效為企業的數字化轉型提供資料依據,
—————————————————————————————
二、開篇有益:
1、OLTP 和 OLAP 的區別
這兩種其實我們平時作業中,都是有處理過的,業務通常由 OLTP 支撐,而現下最火的大屏展示,則大多由 OLAP 支撐,
OLTP:On-Line Transaction Processing,聯機事務處理,主要是業務資料,需要考慮高并發和事務
OLAP:On-Line Analytical Processing,聯機分析處理,重點主要是面向分析,通常都是大量的多維度查詢,很少涉及增刪改,
OLAP 通常是以多維資料模型為實作基礎,為了滿足用戶從多角度多層次進行資料查詢和分析,而建立起的基于事實和維度的,資料庫模型事務處理機制,而數倉通常以 OLAP 為主,
本汪手上這個活兒,就是根據業務情況,構建合適的資料模型,自然也包括實作底層資料的 ETL 和迭代整合,
2、常見的傳統資料庫
關系型以 Mysql 、 Oracle 、Sql Server、ACCESS、Sybase為主,非關系型以 MongoDB 為主,
有什么說什么,到目前為止,這幾個是本汪用的最多的,其他的沒怎么用過,
二、 理想是美好的,現實是殘酷的,僅前期 ETL 就已經難點重重
1、前期基礎資料 ETL
1.1 、目標:
資料拉取與整合,以 Mysql 、 Oracle 、Sql Server、ACCESS、Sybase等 為資料源,目標資料庫為 Mysql, 實作 5k 張表以上的金融資料,倒庫入 Mysql,
1.2 、主要難點:
(1)財務軟體種類多:需要對95家企業的財務系統資料進行分析,對接的財務軟體不統一、資料結構不明確且涉及表量大,需要結合實際專案需求不斷整理,
(2)資料量大:各家財務系統資料存盤量大,為達到資料快速存取,資料表需磁區分表,合理設計表結構及表關系,
(3)資料表結構不同:各企業財務系統資料庫表結構、表關系不同,需要大量時間整理不同系統之間關系,
(4)更新頻繁:進行常量表的全量抽取,為保證資料及時更新,需頻繁抽取更新資料,涉及資料表種類繁多,任務量大,
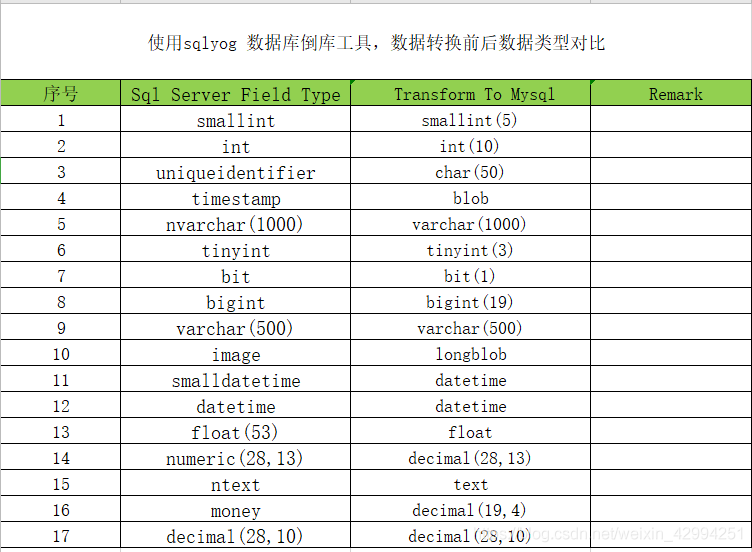
(5)資料型別轉換:需整理不同資料庫之間的資料型別,將不同資料型別轉換為同一資料型別,存盤到中間資料庫,為其他平臺存取資料提供基礎,
(6)歷史資料更新:資料表內沒有明顯的資料更新標識,需要長期與各企業財務人員保持聯系,當企業修改歷史資料時,及時進行系統資料更新維護,
1.3、經濟實用的工具軟體:
(1)ETL 使用開源的 kettle8.3 加以二次開發 (具體執行策略和實際操作,會在后續博客中推出,),kettle 的中文官網,
(2)資料庫管理工具: Navicat
(3)資料庫表結構倒庫工具:SQLyog 8.32破解版(百度云盤:鏈接:https://pan.baidu.com/s/1N4rvYCP_xLCMwIUqzHsHAw
提取碼:8668
復制這段內容后打開百度網盤手機App,操作更方便哦)
SQLyog 8.32 的使用教程
1.4、常見的財務軟體及資料庫型別如下
1.5、以金蝶為例,SQL SERVER中資料型別與 Mysql 中資料型別的對應關系:
1.6、當下預計會采取的抽取策略:
以最難處理的表為例:
由于資料量過大,類似 balance 這樣的收支平衡記錄表,基本資料量都在百萬以上,并且只有年區間 year 和會計區間 period 作為標識,并沒有任何自增欄位,抽取難度極大,實際案例資料高度機密,無法為大家展示,
實際執行步驟:
-
按照業務需求,進行展示維度的劃分
-
根據業務需求建立資料模型
-
重新構建全新的資料庫表結構
-
按照年份和會計區間進行分庫分表
(按年份進行垂直分表,因為歷史資料的更新概率遠低于近3年的資料,所以將2009 - 2018年的資料單獨存放,2019 - 2021年的資料單獨存放,另外可根據需求,按斬訓計區間進行二次拆分, ) -
根據需求,合理選取抽取策略,
1、近3年資料,每日一次增量抽取(只處理新增資料,不處理更新資料),每星期統一處理一次全部資料(包括新增和更新),
2、對于陳年資料,每次增量都壓力山大,我們知道從機械磁盤順序讀取1M資料理論上用時2毫秒,分時段更新后,每次更新至少也得64G的資料,理論用時(64 * 1024)* 2 /1000 = 131.072s ,但是實際去操作的時候,就直接呵呵呵了,kettle的配置,kettle 進行ETL 轉換的效率,服務器 配置等影響巨大,可能會使得一次更新的時間在10分鐘開外,這是不被允許的,所以只能聯系軟體方進行報備,按月定點更新,
由于專案進度的限制,目前僅僅碰到了上面的這些問題,大家有好的執行策略,或對數倉有獨到的見解,也歡迎在評論區留言討論哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/259438.html
標籤:其他
上一篇:Docker常用命令