作者|Masatoshi Nishimura
編譯|VK
來源|Towards Data Science

如果你想知道2020年檔案相似性任務的最佳演算法,你來對了地方,
在33914篇《紐約時報》文章中,我測驗了5種常見的檔案相似性演算法,從傳統的統計方法到現代的深度學習方法,
每個實作少于50行代碼,所有使用的模型都來自互聯網,因此,你可以在沒有資料科學知識的情況下,開箱即用,并且得到類似的結果,
在這篇文章中,你將學習如何實作每種演算法以及如何選擇最佳演算法,內容如下:
-
最佳的定義
-
實驗目標陳述
-
資料設定
-
比較標準
-
演算法設定
-
選出贏家
-
對初學者的建議
你想深入自然語言處理和人工智能,你想用相關的建議來增加用戶體驗,你想升級舊的現有演算法,那么你會喜歡這個文章的,
資料科學家主張絕對最好
你可能會搜索術語“最佳檔案相似性演算法”(best document similarity algorithms),
然后你將從學術論文,博客,問答中得到搜索結果,一些側重于特定演算法的教程,而另一些則側重于理論概述,
在學術論文中,一個標題說,這種演算法的準確率達到了80%,而其他演算法的準確率僅為75%,好啊,但是,這種差異是否足以讓我們的眼睛注意到它呢?增加2%怎么樣?實作這個演算法有多容易?科學家傾向于在給定的測驗集中追求最好,而忽略了實際意義,
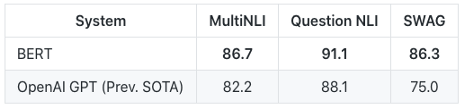
在相關的問題問答中,狂熱的支持者占據了整個話題,有人說現在最好的演算法是BERT,這個演算法概念是如此具有革命性,它打敗了一切,另一方面,憤世嫉俗者稱一切都取決于作業,有些答案早在深度學習之前就有了,看看這個Stackoverflow(https://stackoverflow.com/questions/8897593/how-to-compute-the-similarity-between-two-text-documents),2012年是投票最多的一年,很難判斷它對我們到底意味著什么,
谷歌會很樂意投入數百萬美元購買工程師的能力和最新的計算能力,僅僅是為了將他們的搜索能力提高1%,這對我們來說可能既不現實也沒有意義,
性能增益和實作所需的技術專業知識之間有什么權衡?它需要多少記憶體?它以最少的預處理可以運行多快?
你想知道的是一種演算法在實際意義上是如何優于另一種演算法的,
這篇文章將為你提供一個指導方針,指導你在檔案相似性問題應該實作哪種演算法,
各種演算法,通篇流行文章,預訓練模型
本實驗有4個目標:
-
通過在同一個資料集上運行多個演算法,你將看到演算法與另一個演算法的公平性以及公平程度,
-
通過使用來自流行媒體的全文文章作為我們的資料集,你將發現實際應用程式的有效性,
-
通過訪問文章url,你將能夠比較結果質量的差異,
-
通過只使用公開可用的預訓練模型,你將能夠設定自己的檔案相似性并得到類似的輸出,
“預訓練模型是你的朋友,-Cathal Horan”
資料設定-5篇基礎文章
本實驗選取了33914篇《紐約時報》的文章,從2018年到2020年6月,資料主要是從RSS中收集的,文章的平均長度是6500個字符,
從這些文章中選擇5個作為相似性搜索的基礎文章,每一個代表一個不同的類別,
在語意類別的基礎上,我們還將度量書面格式,更多的描述在下面,
- Lifestyle, Human Interest:How My Worst Date Ever Became My Best(https://www.nytimes.com/2020/02/14/style/modern-love-worst-date-of-my-life-became-best.html)
- Science, Informational:A Deep-Sea Magma Monster Gets a Body Scan(https://www.nytimes.com/2019/12/03/science/axial-volcano-mapping.html)
- Business, News:Renault and Nissan Try a New Way After Years When Carlos Ghosn Ruled(https://www.nytimes.com/2019/11/29/business/renault-nissan-mitsubishi-alliance.html)
- Sports, News:Dominic Thiem Beats Rafael Nadal in Australian Open Quarterfinal(https://www.nytimes.com/2020/01/29/sports/tennis/thiem-nadal-australian-open.html)
- Politics, News:2020 Democrats Seek Voters in an Unusual Spot: Fox News(https://www.nytimes.com/2019/04/17/us/politics/fox-news-democrats-2020.html)
判斷標準
我們將使用5個標準來判斷相似性的性質,如果你只想查看結果,請跳過此部分,
-
標簽的重疊
-
節
-
小節
-
文風
-
主題
標簽是最接近人類判斷內容相似性的工具,記者自己親手寫下標簽,你可以在HTML標題中的news_keywords meta標記處檢查它們,使用標簽最好的部分是我們可以客觀地測量兩個內容有多少重疊,每個標簽的大小從1到12不等,兩篇文章的標簽重疊越多,就越相似,
第二,我們看這個部分,這就是《紐約時報》在最高級別對文章進行分類的方式:科學、政治、體育等等,在網址的域名后面會進行顯示,例如nytimes.com/…
第二部分是小節,例如,一個版塊可以細分為world,或者world可以細分為Australia,并不是所有的文章都包含它,它不像以上那2個那么重要,
第四是文風,大多數檔案比較分析只關注語意,但是,由于我們是在實際用例中比較推薦,所以我們也需要類似的寫作風格,例如,你不想在學術期刊的“跑鞋和矯形術”之后,從商業角度閱讀“十大跑鞋”,我們將根據杰斐遜縣學校的寫作指導原則對文章進行分組,該串列包括人類興趣、個性、最佳(例如:產品評論)、新聞、操作方法、過去的事件和資訊,
5個候選演算法
這些是我們將要研究的演算法,
- Jaccard
- TF-IDF
- Doc2vec
- USE
- BERT
每一個演算法對33914篇文章運行,以找出得分最高的前3篇文章,對于每一篇基礎文章,都會重復這個程序,
輸入的是文章的全文內容,標題被忽略,
請注意,有些演算法并不是為檔案相似性而構建的,但是在互聯網上有如此不同的意見,我們將親眼看到結果,
我們將不關注概念理解,也不關注詳細的代碼審查,相反,其目的是展示問題的設定有多簡單,如果你不明白以下演算法的細節,不要擔心,你可以閱讀其他優秀博客進行理解
你可以在Github repo中找到整個代碼庫:https://github.com/massanishi/document_similarity_algorithms_experiments
如果你只想查看結果,請跳過此部分,
Jaccard
Jaccard 在一個多世紀前提出了這個公式,長期以來,這一概念一直是相似性任務的標準,
幸運的是,你會發現jaccard是最容易理解的演算法,數學很簡單,沒有向量化,它可以讓你從頭開始撰寫代碼,
而且,jaccard是少數不使用余弦相似性的演算法之一,它標記單詞并計算交集,
我們使用NLTK對文本進行預處理,
步驟:
-
小寫所有文本
-
標識化
-
洗掉停用詞
-
洗掉標點符號
-
詞根化
-
計算兩個檔案中的交集/并集
import string
import nltk
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('punkt')
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
base_document = "This is an example sentence for the document to be compared"
documents = ["This is the collection of documents to be compared against the base_document"]
def preprocess(text):
# 步驟:
# 1. 小寫字母
# 2. 詞根化
# 3. 洗掉停用詞
# 4. 洗掉標點符號
# 5. 洗掉長度為1的字符
lowered = str.lower(text)
stop_words = set(stopwords.words('english'))
word_tokens = word_tokenize(lowered)
words = []
for w in word_tokens:
if w not in stop_words:
if w not in string.punctuation:
if len(w) > 1:
lemmatized = lemmatizer.lemmatize(w)
words.append(lemmatized)
return words
def calculate_jaccard(word_tokens1, word_tokens2):
# 結合這兩個標識來找到并集,
both_tokens = word_tokens1 + word_tokens2
union = set(both_tokens)
# 計算交集
intersection = set()
for w in word_tokens1:
if w in word_tokens2:
intersection.add(w)
jaccard_score = len(intersection)/len(union)
return jaccard_score
def process_jaccard_similarity():
# 標記我們要比較的基本檔案,
base_tokens = preprocess(base_document)
# 標記每一篇檔案
all_tokens = []
for i, document in enumerate(documents):
tokens = preprocess(document)
all_tokens.append(tokens)
print("making word tokens at index:", i)
all_scores = []
for tokens in all_tokens:
score = calculate_jaccard(base_tokens, tokens)
all_scores.append(score)
highest_score = 0
highest_score_index = 0
for i, score in enumerate(all_scores):
if highest_score < score:
highest_score = score
highest_score_index = i
most_similar_document = documents[highest_score_index]
print("Most similar document by Jaccard with the score:", most_similar_document, highest_score)
process_jaccard_similarity()
TF-IDF
這是自1972年以來出現的另一種成熟演算法,經過幾十年的測驗,它是Elasticsearch的默認搜索實作,
Scikit learn提供了不錯的TF-IDF的實作,TfidfVectorizer允許任何人嘗試此操作,
利用scikit-learn的余弦相似度計算TF-IDF詞向量的結果,我們將在其余的例子中使用這種余弦相似性,余弦相似性是許多機器學習任務中使用的一個非常重要的概念,可能值得你花時間熟悉一下,
多虧了scikit learn,這個演算法產生了最短的代碼行,
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
base_document = "This is an example sentence for the document to be compared"
documents = ["This is the collection of documents to be compared against the base_document"]
def process_tfidf_similarity():
vectorizer = TfidfVectorizer()
# 要生成統一的向量,首先需要將兩個檔案合并,
documents.insert(0, base_document)
embeddings = vectorizer.fit_transform(documents)
cosine_similarities = cosine_similarity(embeddings[0:1], embeddings[1:]).flatten()
highest_score = 0
highest_score_index = 0
for i, score in enumerate(cosine_similarities):
if highest_score < score:
highest_score = score
highest_score_index = i
most_similar_document = documents[highest_score_index]
print("Most similar document by TF-IDF with the score:", most_similar_document, highest_score)
process_tfidf_similarity()
Doc2vec
Word2vec于2014年面世,這讓當時的開發者們刮目相看,你可能聽說過非常有名的一個例子:
國王 - 男性 = 女王
Word2vec非常擅長理解單個單詞,將整個句子向量化需要很長時間,更不用說整個檔案了,
相反,我們將使用Doc2vec,這是一種類似的嵌入演算法,將段落而不是每個單詞向量化,你可以看看這個博客的介紹:https://medium.com/wisio/a-gentle-introduction-to-doc2vec-db3e8c0cce5e
不幸的是,對于Doc2vec來說,沒有官方預訓練模型,我們將使用其他人的預訓練模型,它是在英文維基百科上訓練的(數字不詳,但模型大小相當于1.5gb):https://github.com/jhlau/doc2vec
Doc2vec的官方檔案指出,輸入可以是任意長度,一旦標識化,我們輸入整個檔案到gensim庫,
from gensim.models.doc2vec import Doc2Vec
from sklearn.metrics.pairwise import cosine_similarity
import string
import nltk
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('punkt')
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
base_document = "This is an example sentence for the document to be compared"
documents = ["This is the collection of documents to be compared against the base_document"]
def preprocess(text):
# 步驟:
# 1. 小寫字母
# 2. 詞根化
# 3. 洗掉停用詞
# 4. 洗掉標點符號
# 5. 洗掉長度為1的字符
lowered = str.lower(text)
stop_words = set(stopwords.words('english'))
word_tokens = word_tokenize(lowered)
words = []
for w in word_tokens:
if w not in stop_words:
if w not in string.punctuation:
if len(w) > 1:
lemmatized = lemmatizer.lemmatize(w)
words.append(lemmatized)
return words
def process_doc2vec_similarity():
# 這兩種預先訓練的模型都可以在jhlau的公開倉庫中獲得,
# URL: https://github.com/jhlau/doc2vec
# filename = './models/apnews_dbow/doc2vec.bin'
filename = './models/enwiki_dbow/doc2vec.bin'
model= Doc2Vec.load(filename)
tokens = preprocess(base_document)
# 只處理出現在doc2vec預訓練過的向量中的單詞,enwiki_ebow模型包含669549個詞匯,
tokens = list(filter(lambda x: x in model.wv.vocab.keys(), tokens))
base_vector = model.infer_vector(tokens)
vectors = []
for i, document in enumerate(documents):
tokens = preprocess(document)
tokens = list(filter(lambda x: x in model.wv.vocab.keys(), tokens))
vector = model.infer_vector(tokens)
vectors.append(vector)
print("making vector at index:", i)
scores = cosine_similarity([base_vector], vectors).flatten()
highest_score = 0
highest_score_index = 0
for i, score in enumerate(scores):
if highest_score < score:
highest_score = score
highest_score_index = i
most_similar_document = documents[highest_score_index]
print("Most similar document by Doc2vec with the score:", most_similar_document, highest_score)
process_doc2vec_similarity()
Universal Sentence Encoder (USE)
這是Google最近在2018年5月發布的一個流行演算法, 實作細節:https://www.tensorflow.org/hub/tutorials/semantic_similarity_with_tf_hub_universal_encoder,
我們將使用谷歌最新的官方預訓練模型:Universal Sentence Encoder 4(https://tfhub.dev/google/universal-sentence-encoder/4).
顧名思義,它是用句子來構建的,但官方檔案并沒有限制投入規模,沒有什么能阻止我們將它用于檔案比較任務,
整個檔案按原樣插入到Tensorflow中,沒有進行標識化,
from sklearn.metrics.pairwise import cosine_similarity
import tensorflow as tf
import tensorflow_hub as hub
base_document = "This is an example sentence for the document to be compared"
documents = ["This is the collection of documents to be compared against the base_document"]
def process_use_similarity():
filename = "./models/universal-sentence-encoder_4"
model = hub.load(filename)
base_embeddings = model([base_document])
embeddings = model(documents)
scores = cosine_similarity(base_embeddings, embeddings).flatten()
highest_score = 0
highest_score_index = 0
for i, score in enumerate(scores):
if highest_score < score:
highest_score = score
highest_score_index = i
most_similar_document = documents[highest_score_index]
print("Most similar document by USE with the score:", most_similar_document, highest_score)
process_use_similarity()
BERT
這可是個重量級選手,2018年11月谷歌開源BERT演算法,第二年,谷歌搜索副總裁發表了一篇博文,稱BERT是他們過去5年來最大的飛躍,
它是專門為理解你的搜索查詢而構建的,當談到理解一個句子的背景關系時,BERT似乎比這里提到的所有其他技術都要出色,
最初的BERT任務并不打算處理大量的文本輸入,對于嵌入多個句子,我們將使用UKPLab(來自德國大學)出版的句子轉換器開源專案(https://github.com/UKPLab/sentence-transformers),其計算速度更快,它們還為我們提供了一個與原始模型相當的預訓練模型(https://github.com/UKPLab/sentence-transformers#performance)
所以每個檔案都被標記成句子,并對結果進行平均,以將檔案表示為一個向量,
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
from nltk import sent_tokenize
from sentence_transformers import SentenceTransformer
base_document = "This is an example sentence for the document to be compared"
documents = ["This is the collection of documents to be compared against the base_document"]
def process_bert_similarity():
# 這將下載和加載UKPLab提供的預訓練模型,
model = SentenceTransformer('bert-base-nli-mean-tokens')
# 雖然在句子轉換器的官方檔案中并沒有明確的說明,但是原來的BERT是指一個更短的句子,我們將通過句子而不是整個檔案來提供模型,
sentences = sent_tokenize(base_document)
base_embeddings_sentences = model.encode(sentences)
base_embeddings = np.mean(np.array(base_embeddings_sentences), axis=0)
vectors = []
for i, document in enumerate(documents):
sentences = sent_tokenize(document)
embeddings_sentences = model.encode(sentences)
embeddings = np.mean(np.array(embeddings_sentences), axis=0)
vectors.append(embeddings)
print("making vector at index:", i)
scores = cosine_similarity([base_embeddings], vectors).flatten()
highest_score = 0
highest_score_index = 0
for i, score in enumerate(scores):
if highest_score < score:
highest_score = score
highest_score_index = i
most_similar_document = documents[highest_score_index]
print("Most similar document by BERT with the score:", most_similar_document, highest_score)
process_bert_similarity()
演算法評估
讓我們看看每種演算法在我們的5篇不同型別的文章中的表現,我們根據得分最高的三篇文章進行比較,
在這篇博文中,我們將只介紹五種演算法中性能最好的演算法的結果,有關完整的結果以及個別文章鏈接,請參閱倉庫中的演算法目錄:https://github.com/massanishi/document_similarity_algorithms_experiments
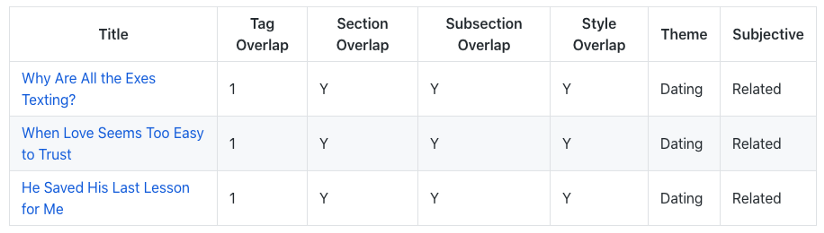
1. How My Worst Date Ever Became My Best
BERT勝利
這篇文章是一個人類感興趣的故事,涉及一個50年代離婚婦女的浪漫約會,
這種寫作風格沒有像名人名字這樣的特定名詞,它對時間也不敏感,2010年的一個關于人類興趣的故事在今天可能也同樣重要,在比較中沒有一個演算法性能特別差,
BERT和USE的比賽千鈞一發,USE把故事繞到了社會問題,BERT關注浪漫和約會,其他演算法則轉向了家庭和孩子的話題,可能是因為看到了“ex husband 前夫”這個詞,
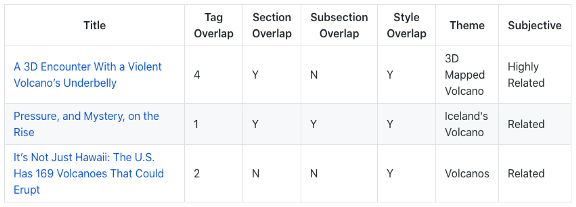
2. A Deep-Sea Magma Monster Gets a Body Scan
TF-IDF獲勝,
這篇科學文章是關于海洋中活火山的三維掃描,
3D掃描、火山和海洋是罕見的術語,所有演算法都很好地實作了公平,
TF-IDF正確地選擇了那些只談論地球海洋內火山的人,USE與它相比也是一個強大的競爭者,它的重點是火星上的火山而不是海洋,另一些演算法則選擇了有關俄羅斯軍用潛艇的文章,這些文章與科學無關,與主題無關,
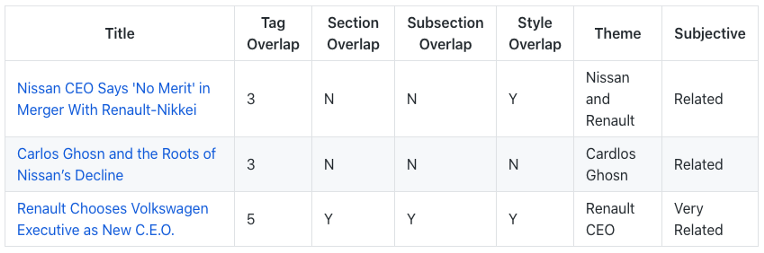
3. Renault and Nissan Try a New Way After Years When Carlos Ghosn Ruled
TF-IDF獲勝,
文章談到了前首席執行官卡洛斯·戈恩越獄后雷諾和日產的遭遇,
理想的匹配將討論這3個物體,與前兩篇相比,本文更具有事件驅動性和時間敏感性,相關新聞應與此日期或之后發生(從2019年11月開始),
TF-IDF正確地選擇了關注日產CEO的文章,其他人則選擇了一些談論通用汽車行業新聞的文章,比如菲亞特克萊斯勒(Fiat Chrysler)和標致(Peugeot)的結盟,
值得一提的是,Doc2vec和USE生成了完全相同的結果,
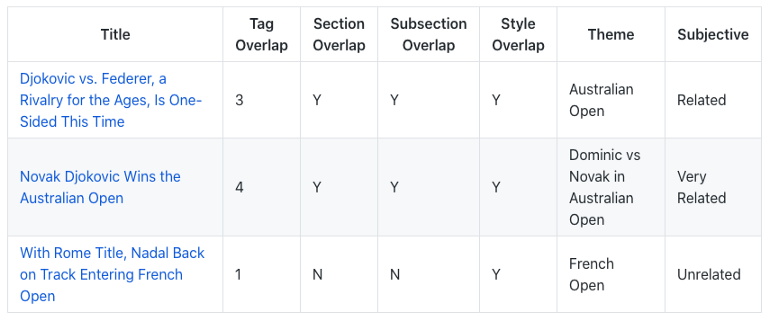
4. Dominic Thiem Beats Rafael Nadal in Australian Open Quarterfinal
Jaccard、TF-IDF和USE結果相似,
這篇文章是關于網球選手多米尼克·蒂姆在2020年澳大利亞網球公開賽(網球比賽)上的文章,
新聞是事件驅動的,對個人來說非常具體,所以理想的匹配是多米尼克和澳大利亞公開賽,
不幸的是,這個結果由于缺乏足夠的資料而受到影響,他們都談論網球,但有些比賽是在談論2018年法國網球公開賽的多米尼克,或者,在澳大利亞網球公開賽上對費德勒的看法,
結果是三種演算法的結果,這說明了關鍵的重要性:我們需要盡最大努力收集、多樣化和擴展資料池,以獲得最佳的相似性匹配結果,
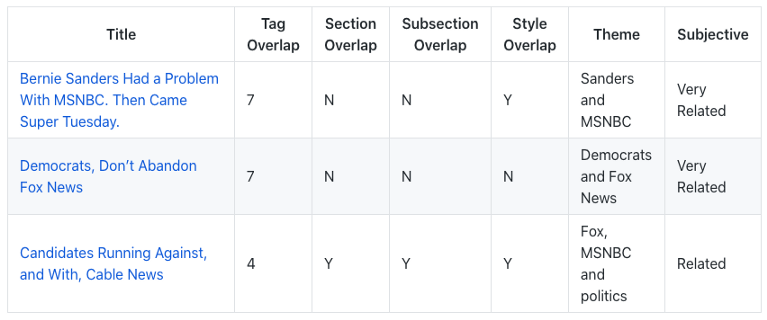
5. 2020 Democrats Seek Voters in an Unusual Spot: Fox News
USE勝利,
這篇文章是關于民主黨人的,特別關注伯尼·桑德斯在福克斯新聞(Fox News)上為2020年大選出鏡,
每一個話題都有自己的大問題,關于民主黨候選人和選舉的文章很多,因為這個故事的主旨是新穎的,所以我們優先討論民主黨候選人和福克斯的關系,
旁注:在實踐中,你要小心對待政治上的建議,把自由和保守的新聞混合在一起很容易讓讀者不安,既然我們是單獨和《紐約時報》打交道,那就不必擔心了,
USE找到了一些關于伯尼·桑德斯和福克斯、微軟全國廣播公司等電視頻道的文章,其他人則選擇了一些討論2020年大選中其他民主黨候選人的文章,
速度之王
在結束贏家之前,我們需要談談運行時間,每種演算法在速度方面表現得非常不同,
結果是,TF-IDF的實施比任何其他方法都快得多,要在單個CPU上從頭到尾計算33914個檔案(標識化、向量化和比較),需要:
-
TF-IDF:1.5分鐘,
-
Jaccard:13分鐘,
-
Doc2vec:43分鐘,
-
USE:62分鐘,
-
BERT:50多小時(每個句子都被向量化了),
TF-IDF只花了一分半鐘,這是USE的2.5%,當然,你可以合并多種效率增強,但潛在收益需要討論,這將使我們有另一個理由認真審視相關的利弊權衡,
以下是5篇文章中的每一篇的贏家演算法,
- BERT
- TF-IDF
- TF-IDF
- Jaccard, TF-IDF和USE
- USE
從結果可以看出,對于新聞報道中的檔案相似性,TF-IDF是最佳候選,如果你使用它的最小定制,這一點尤其正確,考慮到TF-IDF是發明的第二古老的演算法,這也令人驚訝,相反,你可能會失望的是,現代先進的人工智能深度學習在這項任務中沒有任何意義,
當然,每種深度學習技術都可以通過訓練自己的模型和更好地預處理資料來改進,但所有這些都伴隨著開發成本,你想好好想想,相對于TF-IDF方法,這種努力會帶來額外多大的好處,
最后,可以說我們應該完全忘記Jaccard和Doc2vec的檔案相似性,與今天的替代品相比,它們沒有帶來任何好處,
新手推薦
假設你決定從頭開始在應用程式中實作相似性演算法,下面是我的建議,
1.先實施TF-IDF
最快的檔案相似性匹配是TF-IDF,盡管有深度學習的各種宣傳,例如深度學習給你一個高質量的結果,但是TFIDF最棒的是,它是閃電般的快,
正如我們所看到的,將其升級到深度學習方法可能會或不會給你帶來更好的性能,在計算權衡時,必須事先考慮很多問題,
2.積累更好的資料
Andrew Ng給出了一個類似的建議,你不能指望你的車沒有油就跑,油必須是好的,
檔案相似性依賴于資料的多樣性,也依賴于特定的演算法,你應該盡你最大的努力找到唯一的資料來增強你的相似性結果,
3.升級到深度學習
僅當你對TF-IDF的結果不滿意時,才遷移到USE或BERT以升級模型,你需要考慮計算時間,你可能會預處理詞嵌入,因此你可以在運行時更快地處理相似性匹配,谷歌為此寫了一篇教程:https://cloud.google.com/solutions/machine-learning/building-real-time-embeddings-similarity-matching-system
4.調整深度學習演算法
你可以慢慢升級你的模型,訓練你自己的模型,將預訓練好的知識融入特定的領域,等等,今天也有許多不同的深度學習模式,你可以一個一個的來看看哪一個最適合你的具體要求,
檔案相似性是許多NLP任務之一
你可以使用各種演算法實作檔案的相似性:一些是傳統的統計方法,另一些是尖端的深度學習方法,我們已經在紐約時報的文章中看到了它們之間的比較,
使用TF-IDF,你可以在本地筆記本電腦上輕松啟動自己的檔案相似性,不需要昂貴的GPU,不需要大記憶體,你仍然可以得到高質量的資料,
誠然,如果你想做情緒分析或分類等其他任務,深入學習應該適合你的作業,但是,當研究人員試圖突破深度學習效率和成績界限時,我們要意識到生活在炒作的圈子里是不健康的,它給新來的人帶來巨大的焦慮和不安全感,
堅持經驗主義可以讓我們看到現實,
希望這個博客鼓勵你開始自己的NLP專案,
參考閱讀
- An article covering TF-IDF and Cosine similarity with examples: “Overview of Text Similarity Metrics in Python“:https://towardsdatascience.com/overview-of-text-similarity-metrics-3397c4601f50
- An academic paper discussing how cosine similarity is used in various NLP machine learning tasks: “Cosine Similarity”:https://www.sciencedirect.com/topics/computer-science/cosine-similarity
- Discussion of sentence similarity in different algorithms: “Text Similarities : Estimate the degree of similarity between two texts”:https://medium.com/@adriensieg/text-similarities-da019229c894
- An examination of various deep learning models in text analysis: “When Not to Choose the Best NLP Model”:https://blog.floydhub.com/when-the-best-nlp-model-is-not-the-best-choice/
- Conceptual dive into BERT model: “A review of BERT based models”:https://towardsdatascience.com/a-review-of-bert-based-models-4ffdc0f15d58
- A literature review on document embeddings: “Document Embedding Techniques”:https://towardsdatascience.com/document-embedding-techniques-fed3e7a6a25d
原文鏈接:https://towardsdatascience.com/the-best-document-similarity-algorithm-in-2020-a-beginners-guide-a01b9ef8cf05
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/25949.html
標籤:其他
上一篇:利用貝葉斯分類器檢測虛假新聞