Open-Ended Multi-Modal Relational Reason for Video Question Answering
Abstract
視覺障礙者不僅在引導和檢索物件等基礎性任務上迫切需要幫助,而且在描繪新環境等先進性任務上也迫切需要幫助,比起導盲犬,它們可能更需要能夠提供語言互動的設備,在此基礎上,我們將研究機器人代理與視障人之間的互動,在我們的研究中,我們將開發一個機器人代理,它將能夠分析測驗環境,并回答參與者的問題,在本文中,我們將討論在人機互動中出現的問題,并找出相關的因素,
Index Terms
HRI, Video Question Answering, VQA, NLP
introduction
隨著機器人技術的發展,人們希望機器人能夠處理更多的日常生活任務,以人口老齡化的日本為例,機器人是用來照顧老年人的,同樣的需求也在視覺障礙人群中得到了推動,對他們來說,傳統的解決方法可能是導盲犬,然而,使用導盲犬有幾個缺點,作為一種動物,導盲犬有多種性情和個性,有時他們可能會做出不規范的行為,失去控制,通常,導盲犬需要較長時間的訓練,更重要的是,正如大家現在所接受的,狗不會說人類的語言,其他人可能認為狗可以通過吠叫與人交流,然而,對于這些人來說,他們不得不承認狗叫聲所傳遞的資訊遠遠少于直接的語言表達,因此,我們認為處理視頻的機器人代理可以通過交流提供更有效的互動,這種機器人代理一旦應用,將能夠改善視障人士的生活,在我們的實驗中,機器人代理將保持與人類用戶相同的視角,機器人代理將積極地探索周圍的環境,例如,一位盲人用戶去了一家新開的商場,想買衣服,機器人代理可以做幾件事來幫助這個構建用戶,首先,它可以詢問用戶想買什么型別的衣服,在過濾掉幾個候選選項后,機器人可以引導用戶找到每一個選項,然后,它可以告訴用戶衣服的形狀、顏色和尺寸,它還可以掃描每個商店,讓用戶知道商店里有多少人,這樣用戶就可以避開擁擠的商店,在本文中,我們將研究四個問題,首先,代理如何讓盲人用戶了解環境,一旦機器人代理掃描環境和處理拍攝的視頻,代理只生成一組結果,其中可能包括位置、顏色、形狀和協調,對于盲人來說,只有通過與agent的溝通,他們才能在腦海中描繪環境,這是我們要研究的問題,第二,agent是否理解盲人用戶的問題并提供適當的反饋?用戶可能會問一些與當前環境無關的問題,例如,如果在家里,用戶會詢問機器人代理是否可以找到醫生,在這個例子中,“醫生”的概念與家里的任何物體都沒有聯系,來自機器人代理的適當反饋可能是撥打911電話,或請求他人的幫助,一般來說,類似的場景將在我們的實驗中研究,第三,人們對聲音反饋的感覺,在一個不存在噪聲因素的理想環境中,用戶可以聽到機器人代理的反饋,然而,這樣的環境在現實世界中相對少見,我們想知道盲人用戶和機器人代理之間的互動是否嚴重中斷,第四,人們對這種互動是否感到舒服,盲人用戶和機器人代理之間有多少信任,與機器人代理相比,人們可能更容易與導盲犬建立信任,潛在的原因可能來自文化,傳統(人類和狗在歷史上的長期關系),或者生物學(有機智能動物更可能信任彼此,而不是它們對酷酷的機器),在其他一些情況下,人們傾向于不信任[1]機器人,對機器人的不信任和過度信任都不會對人機互動產生負面影響,
Related Work
Pre-training for Natural Language Processing (NLP)
有趣的是,自然語言網路有一些訓練前的模型,在以往的研究中,NS-VQA[2]等模型采用序列到序列的方法進行模型構建,然而,在日常對話中,這種問答方式也可以運用大量的條件,如對話,在我們的研究作業中,我們的目標是建立一個能夠處理語言語境和理解語法的視覺障礙患者急需使用的模型,在對話對話中,很有可能出現句子后面沒有符號和[3]句中的多義條件的問題,已有關于改進[4]、[5]嵌入的研究,隨著[6]變換的出現,自然語言處理領域取得了新的進展,特別是對句子中的多義詞的處理,近年來,出現了許多新的預訓練模型,如BERT[7]、XLNet[8]、gpt-2[9]和ViLBERT[10]等,用于判斷問題并根據模型結果給出答案,其中,BERT可能是最受歡迎的,因為它的簡單和優越的性能,
Multi-Model for Visual Question Answering(VQA)
在之前的模型中,有許多最先進的ap方法正在研究視覺問答,如BUTD[11]、MFB[12]、BAN[13]、MMNasNet[14]等,然而,我們的研究不僅在計算源的使用上存在局限性,而且在視覺和語言任務的VQA訓練資料的原始方法上也存在局限性,它會失去機器的很多資源,我們提出了一個框架來利用這些軟體程式和場景圖,在神經符號VQA[2]的里程碑上,開發了Stack-NMN[15]、LXMERT[16]等在軟體程式和場景圖方面具有較高性能的模型,這些在軟體程式和場景圖中具有較高性能的框架為我們的建模提供了很多思路,
Visual Recognition
對于視頻識別的作業,我們使用的資料庫稱為CATER.[17],在CATER資料集中,由于格式是視頻,使用mask-rnn[18]進行場景決議時,不能很大程度上檢測出隨著時間變化的物體的動作,隨著3D-ConvNet[19]的思想,視頻動作識別的里程碑I3D[20]出現在了研究領域,I3D在模型中使用了兩流3D-ConvNet,其中一流是光流變化,另一流是影像變化,光流是運動場的關系,在I3D的基礎上,我們用Resnet實作I(2+1)D,也稱為R(2+1)D[21],其中,有二維空間卷積和一維時間卷積,原始的空間和時間3D卷積模型(如I3D)與明確分解3D卷積的模型(如I(2+1)D)之間有很多優勢,優點之一是在這兩個操作之間增加了一個非線性校正;而另一個問題是,顯式卷積比具有時空特征的原始三維卷積模型更容易優化,盡管R(2+1)D均勻地使用了單一型別的殘差塊,但它仍然導致了最先進的動作識別精度,
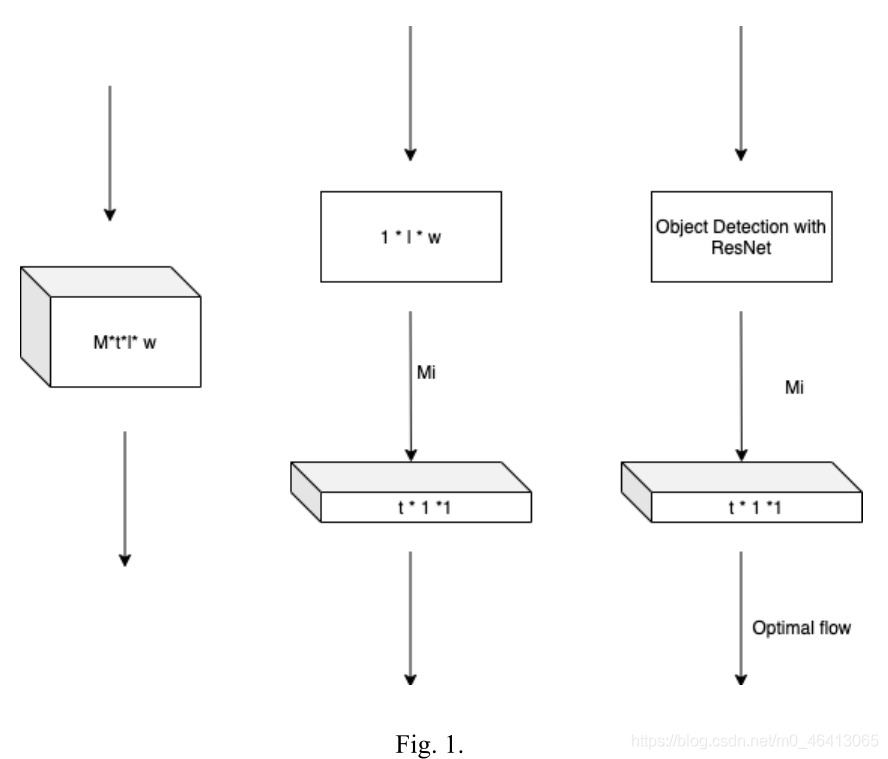
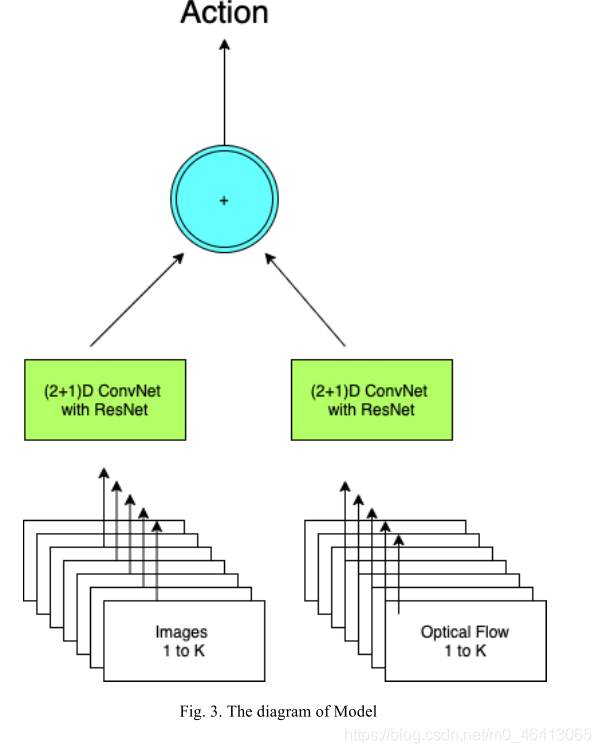
Model
在本節中,我們將討論在我們的研究中設計的模型,用x表示輸入的片段大小為3×F ×H×W,圖1所示,其中e是RGB中顏色的編號,F是視頻中幀的編號,H, W是幀的高和寬,我們首先將帶有R(2+1)D模型的幀的視頻放入,以檢測物體的動作和運動,然后利用帶有弱函式的VQA問題,利用改進的NLP演算法進行視頻問答,
A. Video Recognition
在這項作業中,我們考慮探測物體的動作和運動,在以往的研究中,有許多替代技術可以高精度地完成這一任務,同時,在現實生活中,有很多行為需要準確判斷時間,在考慮時間時,我們總是考慮LSTM模型,但是LSTM在訓練程序中缺乏物體隨旋轉而變化的經驗,在某些特殊情況下可能會導致巨大的誤差,隨著I3D和I(2+1)D模型的里程碑,我們可以利用這兩個模型來檢測從1到k的幀和從1到k的光流,然而,正如我們在相關作業中提到的,I(2+1)D模型很容易優化,這將幫助我們以近似高的精度減少模型中的資源的可能性,在我們的網路中,我們實作了基于兩個卷積層的空間和一個卷積層的時間網路的模型,因此,我們可以從Mi3D卷積層設計一個尺寸為Ni?1 × t × d × d的網路,二維空間層的尺寸為Ni?1 1d d,時間層的尺寸為Mi t11 1,這如圖1所示,在二維空間卷積層中,模型首先使用ResNet檢測包圍框,如圖2所示,從中間幀檢測每幀中的每個物件,為了提高目標檢測的準確性,我們在檢測作業中采用了地面真包圍框,對于光流檢測,我們使用了二維空間層和一維時間層之間的連接模型,該模型具有一個ReLU,使用最優流程,我們可以檢測到一些由物件的移動組成的動作,如包含、平移和縮放,同樣,我們可以通過陰影值的變化來判斷物體是否旋轉,如圖2所示,模型的輸出將給出隨著時間變化的視頻幻燈片中的物件的位置和動作

Visual Question Answering (VQA) with Soft Function
普通視覺問答(VQA)模型,如MFB[12],在從影像中檢測答案時,在場景部分重復訓練模型,在我們的研究中,作業應該用于機器人,有有限的資源可以使用,為了減少VQA的消耗,我們計劃用軟體程式和serene graph制作一個可以解決問題的程式,以端到端的方式訓練問題的答案,目前研究的主要模型有NS-VQA[2]、Stack-NMN[15]和LXMERT[16],所有這些作業都大大減少了記憶的使用和訓練時間的速度,基于堆疊- NMN建立了具有軟功能的VQA模型,在VQA的軟程式問題中具有較高的性能,
C. Natural Language Processing (NLP) In Pre-training Model
在考慮NLP模型對VQA問題進行推理時,在sequence to sequence中使用了NS-VQA[2]中的原始方法,它是一個基本的LSTM模型,只考慮問題的一個方向,然而,在現實生活中,人們的對話可以被視為對話,對話中的人物語法不如書面對話中的人物,有時在我們的談話中也存在著大量的俚語,這些俚語不能用書面文字來表達,此外,還存在一些多義詞的條件,在圖3中,在我們的演算法中,模型時間圖和一些能夠處理這些條件的模型是比較重要的,隨著ELMO[5]和轉換[6]的里程碑,開始存在許多需要進行微調的模型,這些微調模型使我們的演算法在不改變輸入引數的情況下,能夠快速推理出VQA中的問題,這會減少很多資源,在我們的研究中,我們發現BERT[7]和XLNet[7]組合在VQA問題的推理方面表現最好,伯特為每個單詞給出了句子的背景關系關系,但它缺乏隨時間變化而變化的記憶,XLNet同時考慮了BERT和LSTM的優點,使模型能夠以更好的性能處理多詞問題,然而,它需要比BERT更大的資源,同時,某些特殊條件也不能像伯特函式那樣作業,因此,在我們的研究中,我們將分別使用BERT和XLNet對VQA問題進行推理,并將兩種模型的推理結果進行比較,得到一個置信度較高的結果,
Experiment
在這一節中,我們將對假設進行說明和解釋,這些假設與緒論部分的四個問題相匹配,然后,我們將解釋我們如何建立實驗來驗證假設,
A. Hypothesis
假設1,將地點、顏色、形狀等單字組合在一起,可以讓人建立對環境的基本認識,
假設2,請求應該簡短明了,避免贅述,這樣的指令,更容易被機器人代理理解,
假設3,友好、禮貌、真誠的反饋更容易讓用戶接受,讓用戶感覺更舒服,
假設4,對機器人agent具有合理的信任水平,可以促進盲人用戶與機器人agent之間的互動,
B. Participants
參與者是200名佐治亞理工學院的學生,他們都是CS專業的學生,對HRI相關知識和VQA技術都有很好的了解,200名參與者被分成4組,每組都將用來驗證一個假設,這樣,我們希望每個參與者在實驗程序中都有足夠的耐心和新鮮感,這樣個人的情緒(如沉悶、疲勞)就不會影響我們的實驗結果,在實驗之前,所有的參與者都將有一個合理的時間來熟悉他們的任務和設備,在實驗程序中,所有的參與者都將被蒙住眼睛,他們只能通過說和聽與實驗設備進行交流,
C. Robot Agent
在我們的實驗中,我們在計算機上設定了核心功能,包括處理語音并將音頻剪輯轉換成英語,一個VQA程式來分析視頻和問題,一個聲音來發出VQA程式的結果,測驗計算機將始終保持與參與者相同的視角,以獲得與參與者應該獲得的相同的視頻,
D. Four Experiments
H1實驗:
在這個實驗中,參與者需要通過向機器人agent提問來了解環境,我們使用包含不同物件的視頻剪輯,圖2展示了一個示例,視頻剪輯(測驗集)有幾個優點,它顯示了不同的形狀和顏色,物體的位置一直在變化,相對位置可以用簡單的詞來表達,比如“立方體附近,球體后面”,“它簡化了現實世界,而不會丟失關鍵資訊(位置、顏色、形狀、動作),對于視頻中物體的動作,我們會根據其他關鍵資訊的變化來判斷,參與者需要找出問題的答案:每種形狀有多少個物體,它們的顏色是什么,以及它們的位置和動作,他們最多有13分鐘來完成任務,然后,他們會被要求根據他們得到的資訊畫出一幅畫,
每一個人類的問題和機器人的回答都將被記錄在電腦日志中,
H2實驗:
我們分析先前實驗中的日志檔案,我們對問題進行了分類:1,正確答案后面的問題,2. 跟著錯誤答案而來的問題,例如,正確答案應該是“四個立方體”,但實際的答案是“一個立方體”,無效答案后面的問題,例如,正確的/可以接受的答案是“一個球體”,但實際答案是“一個三角形”,對于這組參與者,只會問一些簡單明了的問題,比如“多少個球體?”另一個只會問一些復雜的問題,比如“你能告訴我周圍的環境嗎?里面有多少物體看起來像一個回圈?”“同樣,會有日志,我們會分析準確性,
H3實驗:
在這個實驗中,參與者可以自由提問,他們的目標是解決環境問題,兩個參與者的機器人代理是不同的,一個機器人代理被編程為表現良好,另一個則相反,前機器人將以友好的談話開始,如“有多少我幫助你”或“有什么我可以為你做,如果這個機器人不能處理這個問題,它可能會回答“對不起,這個小機器人找不到答案,”你介意用一種不同的、更簡單的方式來回答你的問題嗎?不同的是,后者的機器人只回答“一個”或“沒有”,在提問后,參與者需要畫出圖畫,
H4實驗:
在兩百名參與者中,他們將接受一項調查,其中包括關于機器人信任的問題,我們將對調查進行評估,找出最信任機器人的參與者和最不信任機器人的參與者,他們會問“友好的”機器人代理并畫出圖片,

E. Method of evaluation
我們將對精度進行分析,精度可以用:
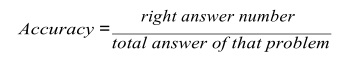
對于每種型別的物體(立方體、球體、圓錐),它們都有不同的量,我們將隨機選擇視頻從迎合資料集,并問他們問關于關鍵資訊(位置,顏色,形狀)的問題,參與者需要把他們引出來,對于每一種型別,我們將判斷答案是否與真理相同,并計算準確率分數,
最后一個特征是評價相對位置,我們會讓參與者問幾個關于每個物體在五個隨機時間點的位置的問題,我們會要求用戶畫出每個時間點物體的位置關系,同樣,我們會判斷答案是否與真理相同,并計算準確率分數,
Result And Discussion
實驗結束后,我們讓參與者畫了兩百張照片,這些圖片代表了參與者可以通過與機器人代理的交流在他們的腦海中建立,假設人們有相對平等的認知水平,我們認為視障人士應該能夠構建一些類似的影像,同時,我們用柱狀圖來表示實驗3和實驗4的調查結果,
A. Performance of Video Question Answering Model
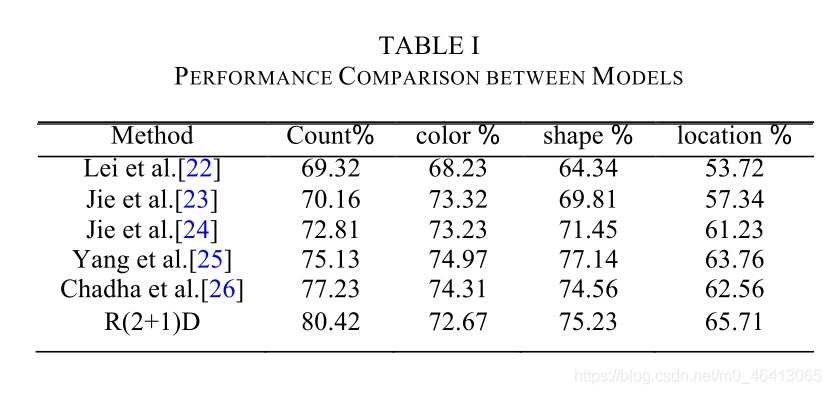
在實驗1和實驗2中,我們將我們的模型與其他幾種模型(表1)的分類精度進行了比較,對于在CATER和Chadha等人[26]中使用的方法,他們使用注意演算法來確保模型對任務具有競爭性,然而,它們的表現沒有我們的模型那么好,所有的模型及其變數都對每個參與者進行了一次實驗訓練,得出了結果的平均值,我們發現之前的演算法表現不如我們的模型,經測量,我們的模型在物體數量上比Chadha等人的方法好3.09%,在物體形狀上比Chadha等人的方法好0.67%,在物體數量上比Yang等人的方法好4.19%,在此基礎上的改進對其他模型具有重要意義,但是,在視頻答疑的某些功能上的表現仍然不如其他型號,例如,我們的模型對物體顏色的判斷就比Chadha等人的[26]差,精度較低的原因在于我們的模型更多地關注物體運動的關系,在我們的模型中,我們使用光流來測量物體的動作,當我們使用光流時,我們沒有使用RGB3這樣做,它會使我們的模型在某些情況下失去顏色值,在模型性能上造成很高的錯誤率,
B. Trust and interactivity of HRI
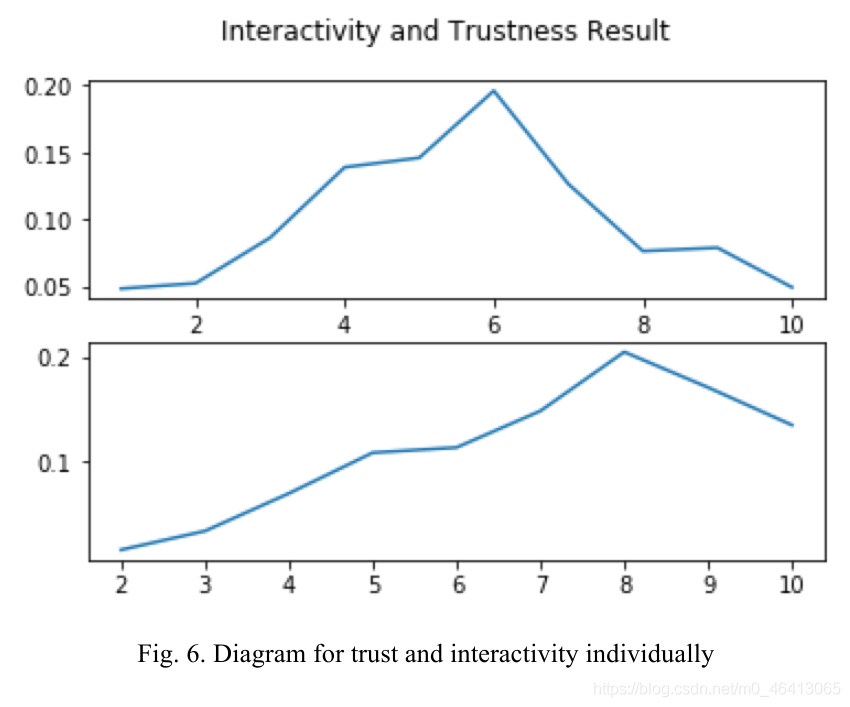
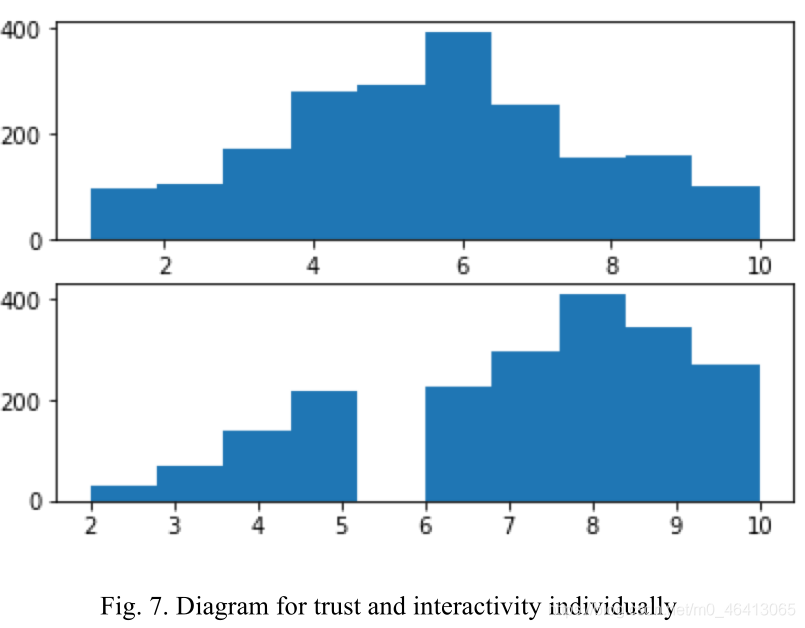
我們使用調查來計算每個參與者的信任分數,信任分數越低,參與者對機器人的信任度就越低,1 ~ +1之間的信任是一個合理的分數范圍,即參與者既不過度信任也不不足信任,對于那些很少信任機器人的參與者來說,他們與機器人進行有效互動的可能性更小,例如,一個參與者要求機器人識別物體的位置,并依賴機器人的引導,他不信任機器人,在這種情況下,這個參與者花了更長的時間來描繪周圍的環境或到達他/她想去的地方,我們必須問,為什么信任不足會導致更糟糕的互動,在理想情況下,收到機器人反饋的參與者應該根據收到的資訊進行大膽的嘗試,但同時,參與者也要思考反饋是否在合理的范圍內,對于不信任機器人的參與者來說,他們可能會就單一情況問太多類似的問題,例如,任務是探索視頻中三角形的數量,正常的參與者可以問兩個問題:有多少個三角形和多少個錐,以確定三角形的數量,對于不被信任的參與者,他們會問10多個問題來確認答案,我們通過兩個因素來衡量互動性:探索的正確性和時間,對于圖6和圖7,它們以圖圖和直方圖的形式表示互動和信任結果,以圖6為例,上面的圖表示互動性,下面的圖表示可信度,在x軸,我們從1到10,這是我們用來評估參與者的分數,在y軸上,值表示調查中出現的得分的可能性,例如,在圖6(上圖)中,有20%的參與者在互動性評估中得到6分,從圖6和圖7可以看出,信任度與互動性之間存在正相關關系,這樣,我們將200名參與者的實驗結果投影到圖5中,
Conclusion And Future Work
我們開發了一個與盲人用戶進行高級互動的新模型,我們的研究主要集中在互動改進上,該模型使用了VQA技術,在不同場景下具有不同的性能,通過這種方式,前兩個假設被設計來驗證哪種設定可以產生最佳的互動結果,同時,我們在視頻問答區域將我們的模型與其他模型進行比較,實驗表明,該模型在很多方面都優于其他模型,我們還研究了信任的作用,并觀察信任是如何影響互動的,我們研究的核心思想是識別與我們的機器人代理和盲人互動呈正相關的特征,我們目前的實驗使用的是“物件視頻”,在未來的作業中,我們將在更加復雜和真實的情況下發揮我們的機器人代理,我們還可以在機器人代理身上安裝機械手臂,這樣它就能執行動作,而不僅僅是語言交流,在這種情況下,新的機器人代理與盲人之間的互動將會不同于當前的互動,我們將檢驗這種新型機器人代理能力的極限,看看是否有我們可以做的潛在改進,此外,在未來,我們計劃使用一種不同的注意力來構建我們的模型,比如分級注意力[27],我們將用RGB3來判斷我們的光流,以確保模型在顏色檢測方面變得更加敏感,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/259725.html
標籤:其他
上一篇:【語音識別】基于matlab GUI語音基頻識別【含Matlab原始碼 294期】
下一篇:對指標的詳細認識(一)