演算法圖解
二分查找
1.對于有序的集合可以使用
2.從中間開始查找
def binary_search(list,item):
low = 0
high = len(list) - 1
while low <= high:
mid = (low+high)//2
guess = list[mid]
if guess == item:
return mid
if guess > item:
high = mid-1
else:
low = mid+1
return None
print(binary_search([1,3,4,5,6,7,8,9],4))
3.只適合有順序的集合
大O表示法
1.大O表示法指的并非以秒為單位的速度,大O表示法讓你能夠比較運算元,它指出了演算法運行時間的增速,
2.常見大O表示時間:
2.1 O(log n),也叫對數時間,這樣的演算法包括二分查找,
2.2 O(n),也叫線性時間,這樣的演算法包括簡單查找,
2.3 O(n * log n),這樣的演算法包括第4章將介紹的快速排序——一種速度較快的排序演算法,
2.4 O(n**2),這樣的演算法包括第2章將介紹的選擇排序——一種速度較慢的排序演算法,
2.5 O(n!),這樣的演算法包括接下來將介紹的旅行商問題的解決方案——一種非常慢的演算法
陣列和鏈表的區別
陣列:在記憶體中元素都是需要相連的,一旦添加的元素,超過獲取到的記憶體就需要擴充,然后重新分配空間,如果提前準備好大量的空間又會照成空間的浪費,所以陣列不適合添加元素O(n),陣列也有很大的優點,查找元素時可以直接查找出來,復雜度為O(1)
鏈表:不會照成空間的浪費,只要哪里有位置,都可以存盤,需要一個元素標記著下一個元素的位置O(1),但搜索的時候,只能從頭開始一步一步的查看,時間為O(n)
選擇排序
1.大O表示法:O(n**2)
1.假如給了一個無序陣列,對這個陣列進行排序,首先陣列回圈n次找出最小的,然后放到一個新的陣列中,然后繼續在回圈n次找到第二小的,一直回圈,直至拍好順序,所以時間復雜度O(n**2)
def findSmallest(arr):
smallest = arr[0]
smallest_index = 0
for i in range(1,len(arr)):
if arr[i] < smallest:
smallest = arr[i]
smallest_index = i
return smallest_index
def selectionSort(arr):
newArr = []
for i in range(len(arr)):
smallest = findSmallest(arr)
newArr.append(arr.pop(smallest))
return newArr
print(selectionSort([5,3,6,2,10]))
遞回
堆疊
和佇列的差別就在:佇列是先進先出,堆疊是先進后出,就像洗盤子,洗的第一個盤子放在最下面,用的時候是從最上面拿,也就是最后放進去的盤子,
函式中稱為呼叫堆疊,
遞回呼叫堆疊
例如求出某一個數的階乘,最簡單的遞回使用:
def fact(x):
if x == 1:
return x
else:
return x * fact(x-1)
快速排序(快排)
快排主要是把一個陣列,按照隨機的一個數字,分為大于這個數字的和小于這個數字的兩組,然后使用遞回,進行排序
快排簡要步驟:
(1) 選擇基準值,
(2) 將陣列分成兩個子陣列:小于基準值的元素和大于基準值的元素,
(3) 對這兩個子陣列進行快速排序,
例如對一個佇列進行排序:
def quicksort(array):
#基線條件必須設定,不然會出現無止盡的呼叫
if len(array) < 2:
return array
else:
pivot = array[0]
less = [i for i in array[1:] if i <= pivot]
greater = [i for i in array[1:] if i>= pivot]
return quicksort(less) + [pivot] + quicksort(greater)
散串列
1.在python中稱為字典,在ruby中稱為哈希,例:{‘name’:‘Lisi’}
散列函式
1.散列函式“將輸入映射到數字”,
2.散列函式并不是沒有規律的,相反散列函式必須要滿足一定的要求,才能稱得上合格的散列函式,簡單要求:
? ? 它必須是一致的,例如,假設你輸入apple時得到的是4,那么每次輸入apple時,得到的都
必須為4,如果不是這樣,散串列將毫無用處,
? ? 它應將不同的輸入映射到不同的數字,例如,如果一個散列函式不管輸入是什么都回傳1,它就不是好的散列函式,最理想的情況是,將不同的輸入映射到不同的數字,
廣度優先搜索
簡單介紹:
假如你要找一個賣水果的商人,你準備在你的朋友中尋找,
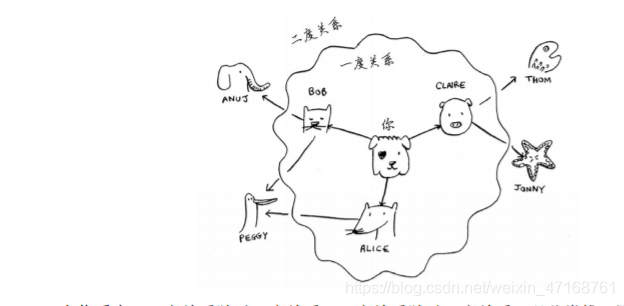
首先找自己的第一層朋友關系,如果沒有再尋找自己的的朋友的朋友,第一層朋友成為一度關系,往后一次累加,二層關系、三層關系等等,
一層關系權重最高,優先尋找,然后一層一層尋找,
這就被成為廣度優先搜索,
簡單實作這種案例:
#創建朋友關系
friend = {}
friend["you"] = ["alice", "bob", "claire"]
friend["bob"] = ["anuj", "peggy"]
friend["alice"] = ["peggy"]
friend["claire"] = ["thom", "jonny"]
friend["anuj"] = []
friend["peggy"] = []
friend["thom"] = []
friend["jonny"] = []
#創建一個佇列
from collections import deque
def search_shuiguo():
search_queue = deque()
search_queue += friend["you"]
while search_queue:
#拋出佇列左邊的值
person = search_queue.popleft()
if person_is_shuiguo(person):
print(person + "是水果銷售商")
return True
else:
search_queue += friend[person]
return False
def person_is_shuiguo(name):
return name[-1] == "m"
佇列是先進先出,很適合用于廣度優先搜索,
狄克斯特拉演算法
簡單介紹:
狄克斯特拉演算法簡單來說就是廣度優先搜索加上了權重,
例如:
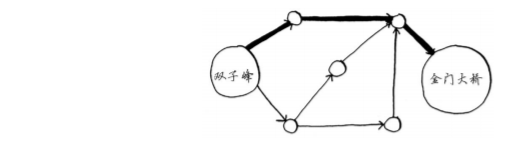
如圖,你要計算雙子峰到金門大橋的距離,可以使用廣度優先搜索,
先計算離自己第一步的,在計算離自己兩步的,在計算三步的,可以計算出最近距離,但是這種沒有考慮到,每個距離的長短不同,工具不同,時間也會有差距,這個時候就可以使用狄克斯特拉演算法,
例:
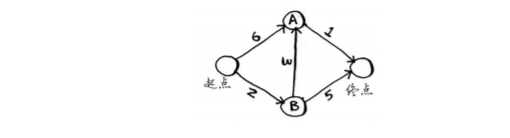
狄克斯特拉演算法包含四個步驟:
(1) 找出“最便宜”的節點,即可在最短時間內到達的節點,
(2) 更新該節點的鄰居的開銷,其含義將稍后介紹,
(3) 重復這個程序,直到對圖中的每個節點都這樣做了,
(4) 計算最終路徑,
創建三個hash表
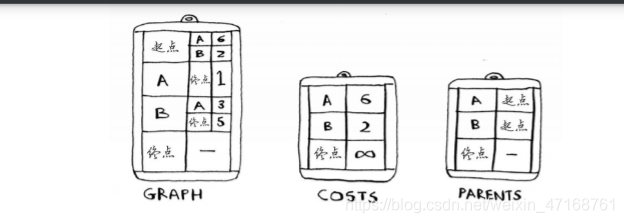
#創建與鄰居的距離hash
graph = {}
graph["start"] = {}
graph["start"]["a"] = 6
graph["start"]["b"] = 2
graph["a"] = {}
graph["a"]["fin"] = 1
graph["b"] = {}
graph["b"]["a"] = 3
graph["b"]["fin"] = 5
graph["fin"] = {}
#創建起點到各個地點的開銷表
#表示無窮大
infinity = float("inf")
costs = {}
costs["a"] = 6
costs["b"] = 2
#因為不是自己鄰居,不知道會有多遠,所以設定無窮大
costs["fin"] = infinity
#存盤父節點的哈希
parents = {}
parents["a"] = "start"
parents["b"] = "start"
parents["fin"] = None
#創建陣列用于記錄處理過的節點
processed = []
#找出開銷最小的節點
def find_lowest_cost_node(costs):
lowest_cost = float("inf")
lowest_cost_node = None
for node in costs:
cost = costs[node]
if cost < lowest_cost and node not in processed:
lowest_cost = cost
lowest_cost_node = node
return lowest_cost_node
#未處理的節點中尋找開銷最小的節點
node = find_lowest_cost_node(costs)
while node is not None:
cost = costs[node]
neighbors = graph[node]
for n in neighbors.keys():
new_cost = cost + neighbors[n]
if costs[n] > new_cost:
parents[n] = node
processed.append(node)
node = find_lowest_cost_node(costs)
貪婪演算法
貪婪演算法是一種非常簡單我的問題解決策略,它求出的很大可能不是最優解,但是也是一種解法,是一種很方便很快速的解法,它旨在求出一種解,不管是不是最優解
例:假設你辦了個廣播節目,要讓全美50個州的聽眾都收聽得到,為此,你需要決定在哪些廣播臺播出,在每個廣播臺播出都需要支付費用,因此你力圖在盡可能少的廣播臺播出,
貪婪演算法解法:
(1) 選出這樣一個廣播臺,即它覆寫了最多的未覆寫州,即便這個廣播臺覆寫了一些已覆寫
的州,也沒有關系,
(2) 重復第一步,直到覆寫了所有的州,
def find_states():
# 要覆寫的州
states_needed = set(["mt", "wa", "or", "id", "nv", "ut", "ca", "az"])
# 廣播臺清單
stations = {}
stations["kone"] = set(["id", "nv", "ut"])
stations["ktwo"] = set(["wa", "id", "mt"])
stations["kthree"] = set(["or", "nv", "ca"])
stations["kfour"] = set(["nv", "ut"])
stations["kfive"] = set(["ca", "az"])
final_stations = set()
while states_needed:
best_station = None
states_covered = set()
for station,states in stations.items():
covered = states & states_needed
if len(covered) > len(states_covered):
best_station = station
states_covered = covered
states_needed -= states_covered
final_stations.add(best_station)
return final_stations
print(find_states())
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/259728.html
標籤:其他