假期之不務正業——Qt+FFmpeg+百度api進行視頻的語音識別
- 一、前言
- 二、FFmpeg進行音頻提取和重采樣
- 三、對音頻分段
- 四、百度api呼叫
- 五、Qt編程的一些補充
- 六、結語
一、前言
現在語音識別技術逐漸發展,先有siri開個好頭,現在有各種小度小愛什么的輪番上陣,王者榮耀有語音識別以后,祖安起來也省事多了,我看一些視頻教程的時候,對一些講的不錯的,也有記筆記的習慣,可是每次都是把視頻暫停,然后一句一句敲出word,說實話,也沒見學習效果有多好,反而效率變得低到不行,想來想去,咱也不能一直停留在這么笨比的方式,總是想整點活,
其實網上就有一些提取字幕的、或是語音識別的應用,應該效果也不錯(我沒試),但是要錢(emmmmm),所以暫時先放棄這個方案,而且如果自己做一個那不是快樂加倍?于是利用假期時間,自己找了一些資料借(chao)鑒(xi)了一下,也是算是自己從零開始做的垃圾,
先放一下目前做到的:
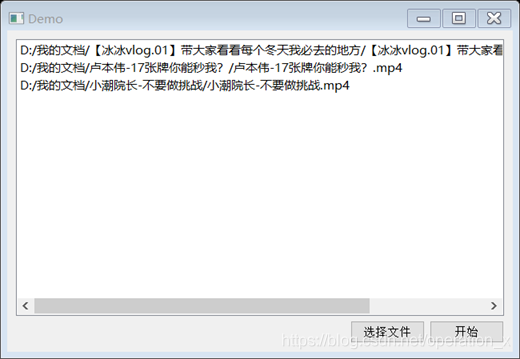
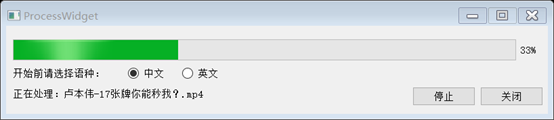
我主要選擇了4個B站的視頻來測驗運行結果,順便一提,B站用手機端下載視頻后,會在快取檔案里發現audio.m4s和vedio.m4s,實際上,FFmpeg可以直接打開m4s格式,因此如果僅僅是為了對音頻進行處理,不需要將兩個檔案合流為一個(合流的方法也很簡單,尤其是使用FFmpeg,可以直接百度),
我選擇的4個視頻分別是冰冰vlog、盧本偉17張牌名場面、小潮院長的不要做挑戰和吳恩達老師的機器學習課程,鏈接放在下文,我這里就夾帶私貨安利一波,下面是識別結果:

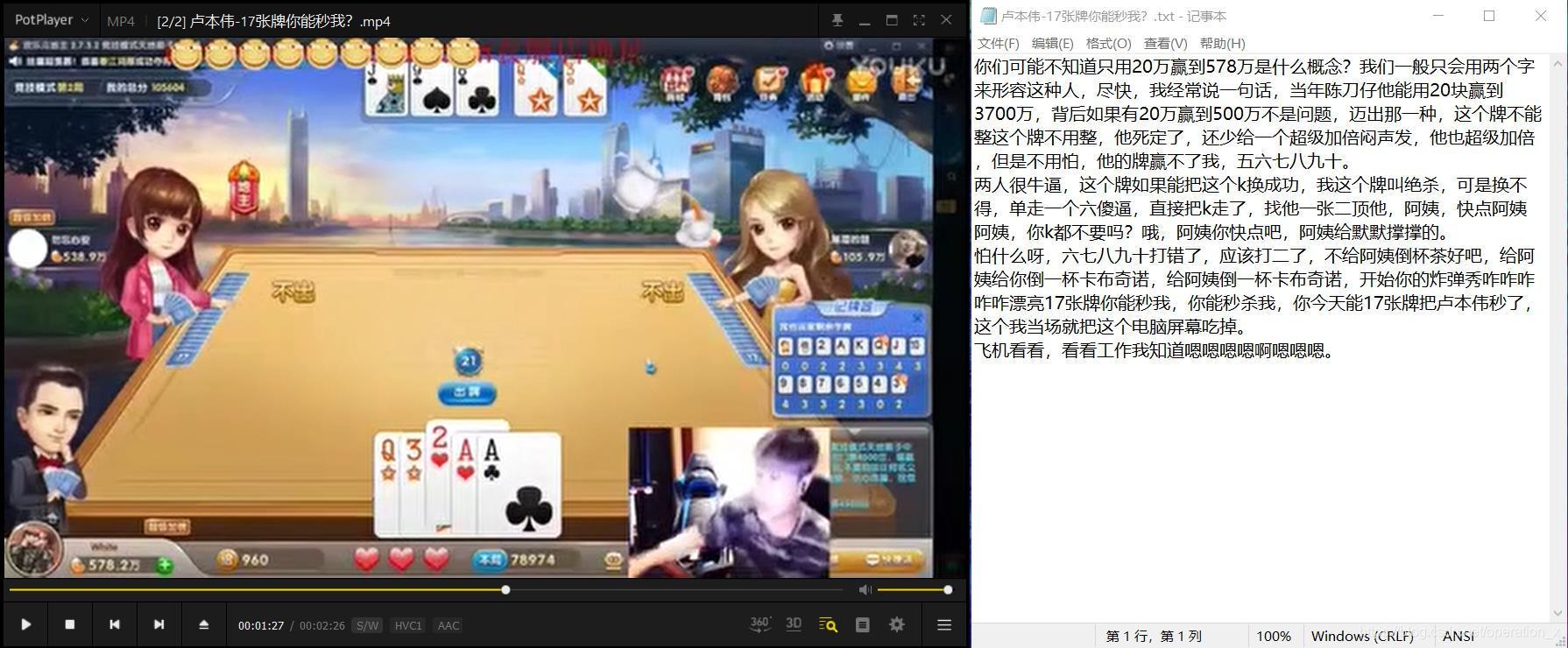
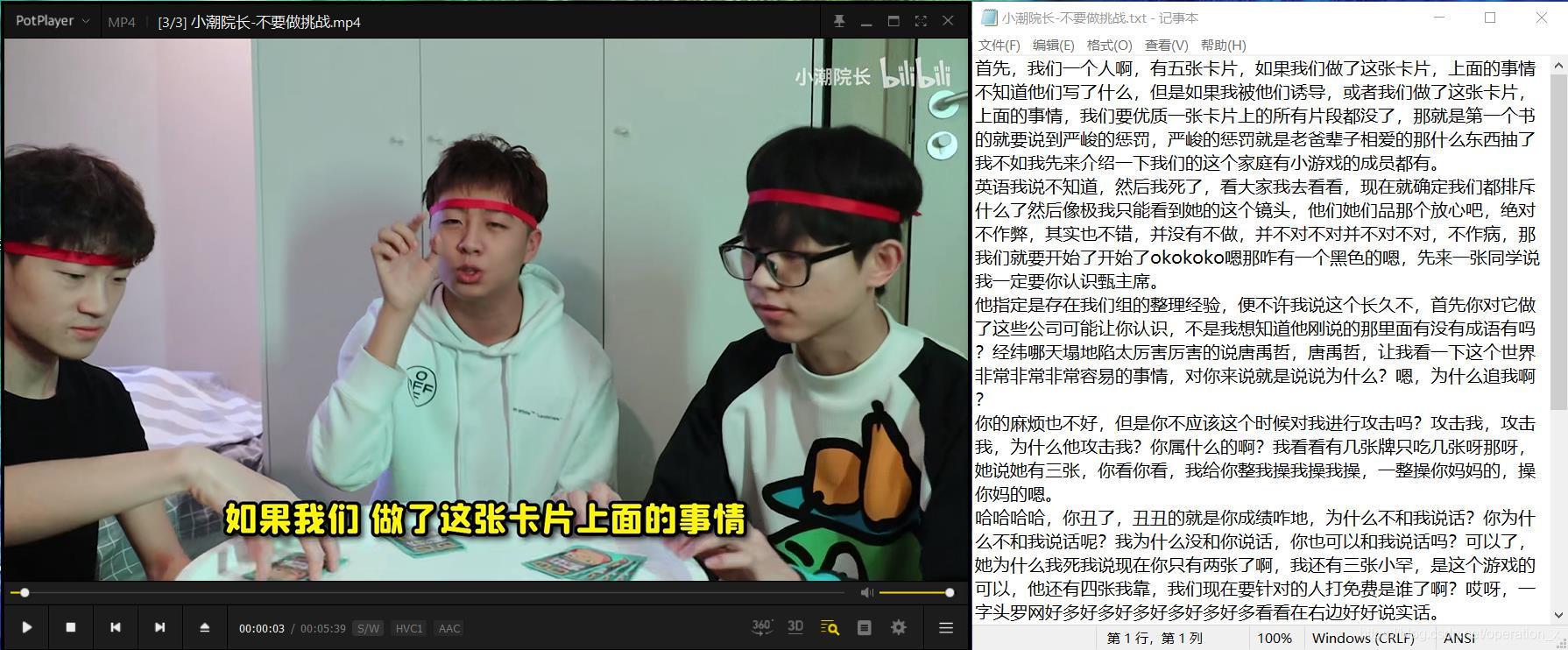
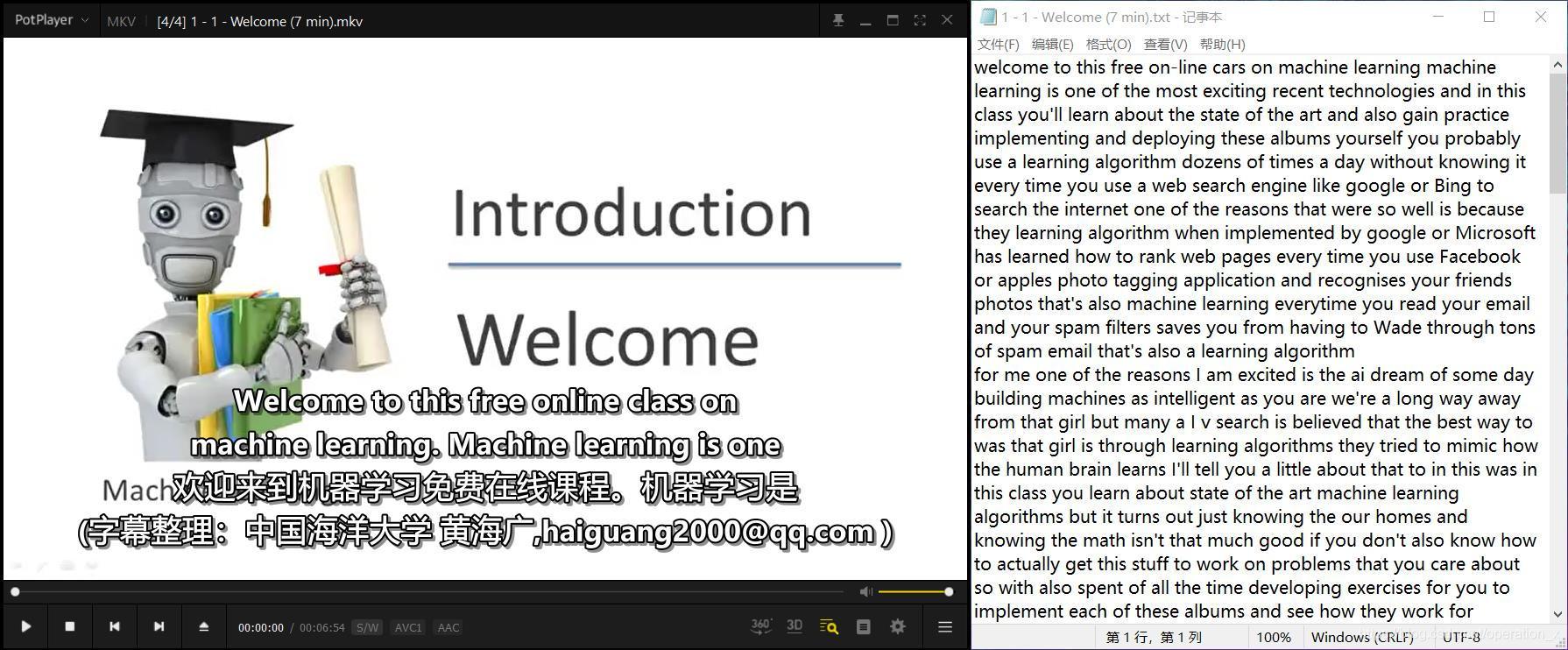
簡單復盤一下:識別結果也算還可以,與英文相比,中文能夠帶上標點符號看起來更利落一些,顯然,語速放慢,說話更標準時,識別效果更好(這不是廢話嗎),可以看到小潮的不要做挑戰的前面正經講游戲規則時,識別結果還能接受,到后面整活了,識別結果驢唇不對馬嘴,對于語速中規中矩的視頻(尤其對于目的:視頻教程),能有一些幫助;但如果是小視頻(尤其節奏比較快的),那還是算了吧,
總體思路就是:Qt做個外殼,FFmpeg提取視頻里的音頻,百度api進行語音識別,由于百度開放的免費介面要求時長在1分鐘以內,所以對于超過一分鐘時長的音頻,需要進行分段(順便一提,免費介面使用量是中文普通話5w次,英文2w次),下面對于各個部分的內容和遇到的(包括未處理完的)問題簡單做一下記錄,
以下是本實作主要參考資料的相關鏈接:
1、提供FFmpeg相關操作流程:
《使用 FFmpeg 進行音視頻操作》,這個CSDN博客介紹了FFmpeg的主要模塊、音視頻解碼與重采樣等內容,主要都是文字介紹,具體代碼實作也有一部分,有一定的參考價值(后面的記錄僅寫一些我的作業和問題吧,這個博客的內容不會轉載的),放下鏈接:
https://gitchat.csdn.net/activity/5d08d7d44ea36e699ecac739
2、提供百度API相關操作流程:
《Qt語音識別 | 百度語音識別應用》,這個B站視頻介紹百度API的介面、使用Qt來呼叫百度API的方法,我的相關操作全部參考這個視頻(因此后面的記錄里代碼部分不會太多,參考也經過老師同意),有興趣的直接看視頻吧,放下鏈接:
https://www.bilibili.com/video/BV19K411V79h
以下是上面效果展示的原視頻鏈接:
1、【冰冰vlog.001】帶大家看看每個冬天我必去的地方
https://www.bilibili.com/video/BV1vy4y1i7bS
2、【名場面】17張牌你能秒我?你能秒殺我?你今天17張牌把盧本偉秒了,我當場就把這個電腦螢屏吃掉!
https://www.bilibili.com/video/BV1W4411r7ue
3、不要“做”挑戰 ?
https://www.bilibili.com/video/BV1x7411Z7VA
4、[中英字幕]吳恩達機器學習系列課程
https://www.bilibili.com/video/BV164411b7dx
二、FFmpeg進行音頻提取和重采樣
關于FFmpeg的介紹、使用,可以直接看前言的鏈接,或者找其他教程,這里也直接梳理一下我們需要做的事情和以及整個程序:
1.對于視頻檔案,需要解封裝,即分離出音頻流或者視頻流或者其他亂七八糟的東西,得到音頻流引數,如聲道數、采樣率、采樣格式等等,
2.解封裝后的音頻流,再進行解碼,得到音頻的實際采樣資料,
3.設定重采樣引數,分配存盤重采樣的資料空間,對于重采樣引數,需要配合百度API的要求:單聲道、采樣率16000Hz、16bit量化,
4.讀取原資料,將重采樣后得到的資料,并將資料寫入檔案,建議直接pcm檔案,簡單粗暴,
5.釋放之前申請的資源,
對于這部分,我們可以考慮封裝成一個類ExtractAudio(請不要吐槽我的命名品味,真不會),方便呼叫和后續的查看,最開始除錯時我就是直接全寫在一個函式里面的,省事是省事,但是太長了會看得累,以下是代碼(.cpp)部分:
void ExtractAudio::init()
{
//初始化引數
in_nb_samples = 1024; //輸入采樣點數
out_channel_layout = AV_CH_LAYOUT_MONO; //輸出格式(聲道數)
out_sample_rate = SAMPLE_RATE; //輸出采樣率
out_sample_fmt = AV_SAMPLE_FMT_S16; //輸出樣本格式
}
//打開檔案函式,回傳值為解封裝背景關系
AVFormatContext *ExtractAudio::open(QString inpath)
{
av_register_all();//初始化封裝庫
AVDictionary *opts = NULL;//引數設定
AVFormatContext *format = avformat_alloc_context();//解封裝背景關系
//QString轉換為char陣列
QByteArray ba = inpath.toLocal8Bit();
char* cpath = ba.data();
//打開視頻檔案,引數3:0表示自動選擇解封器,引數4:引數設定(比如rtsp的延時時間)
int re = avformat_open_input(&format, (const char*)cpath, 0, &opts);
if (re != 0)//打開失敗
return NULL;
else
return format;
}
//解碼函式,回傳值為解碼器背景關系
AVCodecContext *ExtractAudio::decodec(AVFormatContext *format)
{
//獲取流資訊,不是所有的格式都需要呼叫
//但是即便頭已經獲取過,這里再獲取也沒有問題
//所以原則上每次都獲取一下
int re = avformat_find_stream_info(format, 0);//獲取流資訊
if (re < 0)
return NULL;
//使用遍歷的方法獲取音視頻流資訊
for (int i = 0; i < format->nb_streams; i++)
{
AVStream *as = format->streams[i];
//音頻
if (as->codecpar->codec_type == AVMEDIA_TYPE_AUDIO)
{
audioStream = i;
break;
}
}
//音頻解碼器打開
AVCodec *acodec = avcodec_find_decoder(format->streams[audioStream]->codecpar->codec_id); //找到音頻解碼器
if (!acodec) //沒有找到音頻解碼器
return false;
AVCodecContext *avctx = avcodec_alloc_context3(acodec); //創建解碼器背景關系
avcodec_parameters_to_context(avctx, format->streams[audioStream]->codecpar); //配置解碼器背景關系引數
avctx->thread_count = 8; //解碼執行緒數改為8
re = avcodec_open2(avctx, 0, 0); //打開解碼器背景關系
if (re != 0) //打開解碼器失敗
return NULL;
return avctx;
}
//音頻重采樣初始化函式,回傳值為音頻重采樣背景關系
SwrContext *ExtractAudio::initswr(AVCodecContext *avctx, uint8_t **out_data)
{
//設定音頻重采樣
SwrContext *swr = swr_alloc();
in_channel_layout = avctx->channel_layout;
in_sample_rate = avctx->sample_rate;
in_sample_fmt = avctx->sample_fmt;
av_opt_set_int(swr, "in_channel_layout", in_channel_layout, 0);
av_opt_set_int(swr, "out_channel_layout", out_channel_layout, 0);
av_opt_set_int(swr, "in_sample_rate", in_sample_rate, 0);
av_opt_set_int(swr, "out_sample_rate", out_sample_rate, 0);
av_opt_set_sample_fmt(swr, "in_sample_fmt", in_sample_fmt, 0);
av_opt_set_sample_fmt(swr, "out_sample_fmt", out_sample_fmt, 0);
swr_init(swr);
if (!swr_is_initialized(swr))
return NULL;
//計算轉換樣本的數量:避免快取
//確保輸出緩沖區至少包含所有轉換后的輸入樣本
out_nb_samples = av_rescale_rnd(in_nb_samples, out_sample_rate, in_sample_rate, AV_ROUND_UP);
//緩沖區將直接寫入原始音頻檔案,無需對齊
out_nb_channels = av_get_channel_layout_nb_channels(out_channel_layout);
int re = av_samples_alloc_array_and_samples(&out_data, &out_linesize, out_nb_channels,
out_nb_samples, out_sample_fmt, 0);
if (re < 0)
return NULL;
return swr;
}
//音頻重采樣函式,回傳值為輸出緩沖區的位元組數
//回傳值為0時,未找到音頻流或暫無音頻流,可繼續執行函式
//回傳值為-1時,重采樣失敗,應中斷
int ExtractAudio::resample(AVFormatContext *format, AVCodecContext *avctx,
SwrContext *swr, uint8_t **out_data, AVFrame *frame, AVPacket *pkt)
{
if (pkt->stream_index != audioStream) //判斷是否為音頻流
return 0;
//解碼一幀音頻
int gotFrame;
if (avcodec_decode_audio4(avctx, frame, &gotFrame, pkt) < 0)
return -1;
if (!gotFrame)
return 0;
//重采樣
int frame_count = swr_convert(swr,
out_data, out_nb_samples, //輸出
(const uint8_t **)frame->data, in_nb_samples //輸入
);
if (frame_count < 0)
return -1;
out_bufsize = av_samples_get_buffer_size(&out_linesize, out_nb_channels, frame_count, out_sample_fmt, 1);
av_packet_unref(pkt);//釋放,參考計數-1,為0釋放空間
av_frame_unref(frame);
return out_bufsize;
}
// 釋放空間函式
void ExtractAudio::clear(AVFormatContext *format, AVCodecContext *avctx,
SwrContext *swr, AVFrame *frame, AVPacket *pkt)
{
//結束,釋放空間
avformat_close_input(&format);
avcodec_close(avctx);
swr_free(&swr);
av_frame_free(&frame);
av_packet_free(&pkt);
av_free(frame);
av_free(pkt);
}
但是這里雖然代碼上釋放了,占用空間并沒有釋放,我自己測驗如果打開了一個2G的視頻,即便將整個程序都跑完,參考計數也減了,free函式也用了,2G記憶體還是占著,吐血,所以每次感覺視頻大小差不多了,就可以把應用關了重開吧,
三、對音頻分段
得到重采樣完的資料之后,就可以進行分段處理了,對于短語音識別,時長不能超過1分鐘,我這里采用的方法就是,在從每段音頻第30s處開始,一直到第60s前,計算1s以內采樣值(絕對值)之和,和最小的地方,是我認為這個人聲說話的停頓處,有幾點補充就是,一是采樣率已經默認好是16000Hz;二是每兩次求和間的步進,我暫時默認為是0.01s,比如求完了第30s—第31s的和,下一次就求30.01s—31.01s的和,當然這個步進是可以進行變化的,但是個人認為沒有必要使步進太小,計算次數變多后很慢(我做過步進是一個采樣點的嘗試,速度非常非常的慢),
當然這個方法肯定并不是最優的,對于有BGM的視頻來說,可能人不在說話,背景音樂還是有的,從一句話中間給掐斷的可能性不是沒有,另一個是引數的設定,這里面有很多引數是需要根據視頻的情況的調整的,包括比如上面說的從第30s開始,可以換成別的數字;再比如計算1s以內的采樣值之和,如果視頻的節奏比較快(像小潮的一些視頻)或者說話人語速感人,也可以調整;或者是步進等其他引數,但是我覺得我這里設定的引數還算中規中矩,也可以不變,對于這一部分,我們封裝為SeparatePCM類,以下是代碼(.cpp)部分:
#include "SeparatePCM.h"
#include <qdir.h>
#define SAMPLE_RATE 16000
SeparatePCM::SeparatePCM()
{
//初始化
//創建一個新緩沖檔案夾,用于保存分段后的每一段音頻資料
QDir *folder = new QDir;
folderStr = "D:\\temp\\temp\\";
bool exist = folder->exists(folderStr);
if (!exist)
{
folder->mkdir(folderStr);
}
delete folder;
//音頻處理相關系數初始化
sample_rate = SAMPLE_RATE;
sample_amount = 60 * sample_rate; //60s內的樣點總數
start = 0; //每次分段時的第0s的位置
position = 0; //當前位置
best_position = 0; //判斷的最佳靜音段位置
now_sum = 0; //初始分段的采樣點值之和
number = 1; //初始分段序號
//下面的引數可以根據實際情況進行調整
step = 0.01 * sample_rate; //步進,這里設定為0.01s,可以根據實際情況調整
threshold_len_silence = 1 * sample_rate; //判斷為靜音段的默認時長,這里設定為1s,可以根據實際情況調整
start_position = (long)sample_amount / 6 * 3; //開始分段的位置,這里設定為第30s,可以根據實際情況調整
}
SeparatePCM::~SeparatePCM()
{
}
//打開檔案函式,回傳打開檔案是否成功
bool SeparatePCM::open(QString inpath)
{
filePath = inpath;
QByteArray ba = filePath.toLocal8Bit();
char* path = ba.data();
//獲取檔案的指標
FILE *file = fopen((const char*)path, "rb");
if (!file)
return false;
//把指標移動到檔案的結尾 ,獲取檔案長度
fseek(file, 0, SEEK_END);
//獲取檔案長度
fileLength = ftell(file);
//關閉檔案
fclose(file);
return true;
}
//音頻檔案分段處理函式
void SeparatePCM::execute()
{
// 打開檔案
QByteArray ba = filePath.toLocal8Bit();
char* path = ba.data();
FILE *file = fopen((const char*)path, "rb");
//定義陣列長度
long bufferSize = fileLength / 2;
//判斷音頻時長是否夠60s
if (bufferSize < sample_amount)
{
//音頻檔案時長不足60s,不需要分段
outpath = folderStr + pcmStr.arg(1);
QFile::copy(filePath, outpath);
fclose(file);
return;
}
//設定讀取檔案存盤區
short *fileBuffer = new short[bufferSize];
//讀檔案
fread(fileBuffer, sizeof(short), bufferSize, file);
//對超過60s音頻檔案進行分段
short max_value = 0; //音頻檔案采樣值的最大值(絕對值)
for (long i = 0; i < bufferSize; i++)
{
if (abs(fileBuffer[i]) > max_value)
max_value = abs(fileBuffer[i]);
}
//記錄分段中最小的采樣點值之和,初始值設定大一些方便后續更新
min_sum = (long)threshold_len_silence * max_value;
//分段資料緩沖區
short *cutfileBuffer = new short[sample_amount];
//回圈執行音頻分段,直到剩一段時長<60s
while (true)
{
//從分段的位置開始,間隔步長,遍歷尋找分段點
for (position = start_position + start; position < (long)sample_amount + start - 1; position += step)
{
//計算默認靜音時長下的采樣值的和
for (int i = 0; i < threshold_len_silence; i++)
{
now_sum = now_sum + (long)abs(fileBuffer[position - i]);
}
//判斷是否最小
if (now_sum < min_sum)
{
min_sum = now_sum;
//best_position = position - threshold_len_silence / 2;
best_position = position - (long)threshold_len_silence / 2;
}
now_sum = 0;
}
//復制資料并把結果寫入檔案
copyData_and_writeFile(fileBuffer, cutfileBuffer, best_position - start + 1);
//判斷剩下的資料是否還需要分段(若剩下的資料不足60s,直接匯出即可)
start = best_position + 1;
number++;
if (start > bufferSize - sample_amount)
{
//復制資料并把結果寫入檔案
copyData_and_writeFile(fileBuffer, cutfileBuffer, bufferSize - start + 1);
break;
}
//為下次分段初始化
now_sum = 0;
min_sum = (long)threshold_len_silence * max_value;
}
delete[] cutfileBuffer;
delete[] fileBuffer;
fclose(file);
//洗掉提取的音頻檔案
QFile fileTemp(filePath);
fileTemp.remove();
fileTemp.close();
}
//復制資料并將其寫入檔案
//引數:檔案存盤區指標、分段資料緩沖區指標、資料長度
void SeparatePCM::copyData_and_writeFile(short *fileBuffer, short *cutfileBuffer, int len_cut)
{
short *pfile = NULL; //設定原檔案讀取指標
//復制資料
pfile = fileBuffer + start;
memcpy(cutfileBuffer, pfile, len_cut * 2);
//把結果寫入檔案
outpath = folderStr + pcmStr.arg(number);
QByteArray qba = outpath.toLocal8Bit();
char *cpath = qba.data();
FILE *cfile = fopen((const char*)cpath, "wb");
fwrite(cutfileBuffer, sizeof(short), len_cut, cfile);
fclose(cfile);
}
四、百度api呼叫
這里也不再多說,請全部參考上文的B站視頻吧,代碼也不放了,基本是一模一樣的,唯一的區別是我加上了“中文”或者“英文”的判斷,在url里改變pid=1537或者1737,在這基礎上,封裝成了一個WriteText類,以下是代碼(.cpp)部分:
#include "WriteText.h"
#include "Speech.h"
#include <qdir.h>
#include <qfile.h>
#include <qiodevice.h>
WriteText::WriteText()
{
}
WriteText::~WriteText()
{
}
void WriteText::execute(QString fileName, int id)
{
QFile file(fileName);
file.open(QIODevice::WriteOnly | QIODevice::Text | QIODevice::Append);
//開始識別
//可以獲取檔案夾路徑下的所有檔案資訊
QStringList filter;
//檔案篩選,可以置為空,獲取所有檔案資訊
filter << QString("*.pcm");
//找到分段后的緩沖檔案夾
QString folderStr = "D:\\temp\\temp\\";
//獲取檔案夾資訊,并初始化需要識別的檔案
QDir dir(folderStr);
dir.setNameFilters(filter);
QFileInfoList fileInfoList = dir.entryInfoList(filter);
int dir_count = fileInfoList.count();
QString pcmFileName("%1.pcm");
QString fullFileName;
for (int i = 0; i < dir_count; i++)
{
//遍歷檔案夾內的所有檔案
fullFileName = folderStr + pcmFileName.arg(i + 1);
//利用百度api進行音頻識別
Speech m_speech;
QString str = m_speech.speechIdentify(fullFileName, id);
//將結果寫入檔案中
QTextStream txtStream(&file);
txtStream << str << "\n";
//洗掉快取的音頻分段檔案
QFile fileTemp(fullFileName);
fileTemp.remove();
fileTemp.close();
}
file.close();
//洗掉保存分段音頻的快取檔案夾
dir.removeRecursively();
}
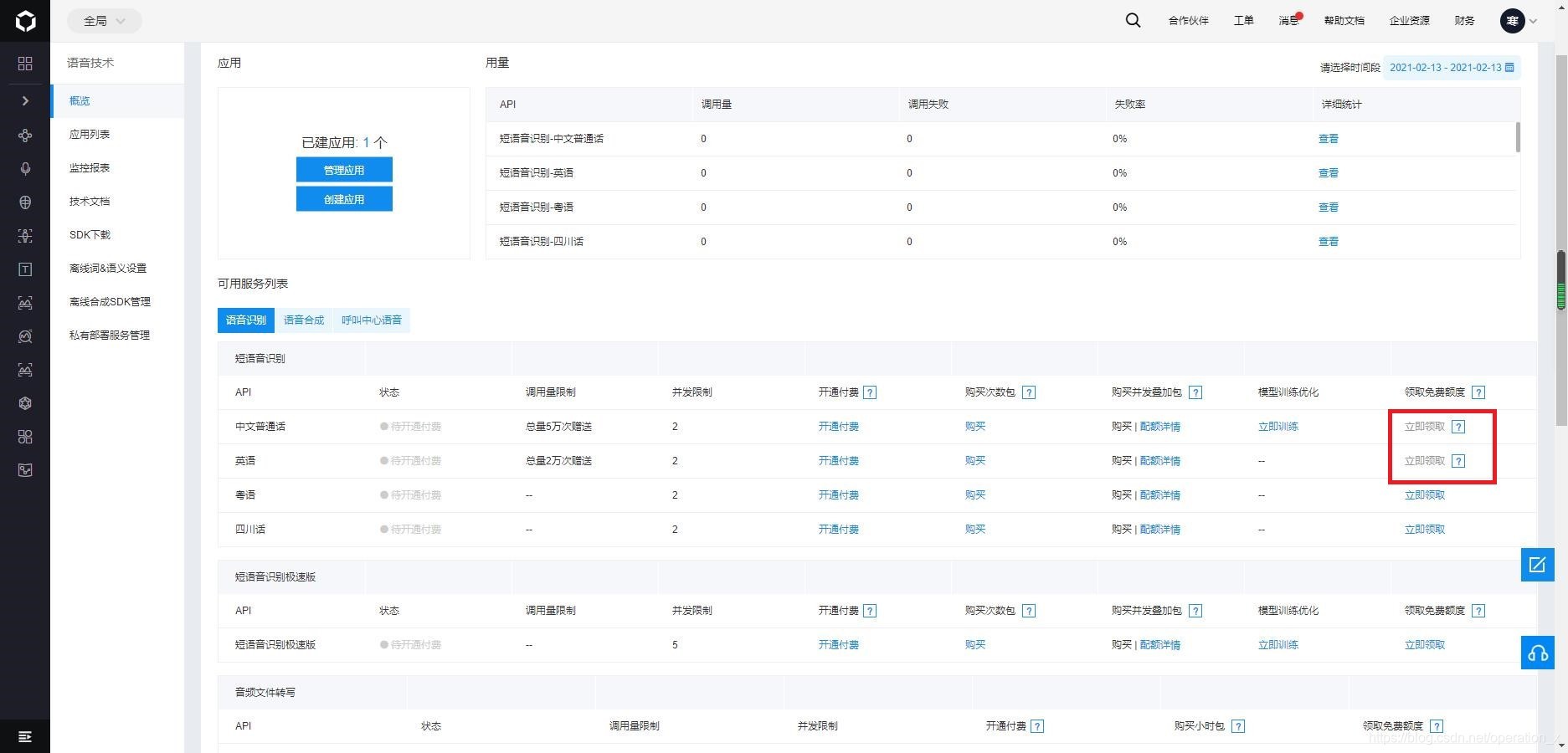
另外在提醒一點就是,呼叫api之前,一定要先確保自己的免費額度已經領取(如下圖),否則呼叫api失敗的同時貌似還占用了次數(我也不太清楚),反正就是算是個坑吧,我就找了半天錯誤,查了好久才發現是這里出錯了QAQ,錯誤碼3304,
五、Qt編程的一些補充
1、Qt在打開檔案時,可能面對一些帶有中文的字串,我的方法是在需要支持中文的cpp最開始進行以下宣告:
//設定UTF-8編碼以支持中文
#if defined(_MSC_VER) && (_MSC_VER >= 1600)
# pragma execution_character_set("utf-8")
#endif
然后在建構式里添加:
//設定中文編碼
QTextCodec *codec = QTextCodec::codecForName("GBK");
QTextCodec::setCodecForLocale(codec);
即可,
當然GBK是windows系統下的,如果跨平臺的話還需要找其他編碼,
2、整個流程執行下來速度不算慢,但是也需要等待,這個時候肯定是要把運算的流程放入運算執行緒里面防止界面卡死,創建自定義執行緒類MyThread,繼承于QThread,重寫run函式,并定義bool值判斷執行緒結束與否,先放代碼:
MyThread.h:
#ifndef MYTHREAD_H
#define MYTHREAD_H
#include <QThread>
#include <QFileInfo>
#include <QMessageBox>
#include <QTextCodec>
#include <QFile>
#include "ExtractAudio.h"
#include "SeparatePCM.h"
#include "WriteText.h"
class QString;
class MyThread : public QThread
{
Q_OBJECT
public:
MyThread();
void setMessage(const QStringList &message);
void setLanguage(int id);
void stop();
protected:
void run();
void extracrAudio(QString strInPath, QString strOutPath); //提取音頻并重采樣
QString separatePCM(QString strInPath); //音頻分段
void writeText(QString strInPath); //語音識別并將結果寫入txt
private:
QStringList str_path_list; //待處理的視頻檔案串列
int languageId; //傳入語種id
volatile bool m_Stopped;
signals:
void updateProgress(int);
void updateLabel(QString);
};
#endif // MYTHREAD_H
MyThread.cpp:
#include "mythread.h"
#include <iostream>
using namespace std;
//設定UTF-8編碼以支持中文
#if defined(_MSC_VER) && (_MSC_VER >= 1600)
# pragma execution_character_set("utf-8")
#endif
MyThread::MyThread()
{
m_Stopped = false;
//設定中文編碼
QTextCodec *codec = QTextCodec::codecForName("GBK");
QTextCodec::setCodecForLocale(codec);
}
void MyThread::setMessage(const QStringList &message)
{
str_path_list = message;
}
void MyThread::setLanguage(int id)
{
languageId = id;
}
void MyThread::stop()
{
m_Stopped = true;
}
void MyThread::run()
{
while (!m_Stopped)
{
//doSomething
QString strShowLabel;
for (int i = 0; i < str_path_list.size(); i++)
{
QString inPath = str_path_list[i]; //單個輸入檔案路徑
QFileInfo fileInfo = QFileInfo(inPath); //獲取輸入檔案資訊
QString file_name = fileInfo.fileName(); //輸入檔案名
QString fileSuffix = fileInfo.suffix(); //輸入檔案后綴
strShowLabel = "正在處理:" + file_name;
emit updateLabel(strShowLabel);
QString outPcmName = file_name.replace(fileSuffix, "pcm"); //輸出pcm檔案名
QString outPcmPath = "D:\\temp\\" + outPcmName; //輸出pcm路徑
QString outTextName = file_name.replace("pcm", "txt"); //輸出txt檔案名
QString outTextPath = "D:\\temp\\" + outTextName; //輸出txt路徑
//下面這一段是處理步驟
extracrAudio(inPath, outPcmPath); //提取音頻并重采樣
QString temppath = separatePCM(outPcmPath); //音頻分段,并獲取緩沖檔案夾
writeText(outTextPath); //音頻識別,并將結果寫入txt中
cout << endl;
int v = 100 * (i + 1) / str_path_list.size();
emit updateProgress(v);
}
str_path_list.clear();
strShowLabel = tr("處理結束!");
emit updateLabel(strShowLabel);
}
m_Stopped = false;
}
//提取音頻并重采樣
void MyThread::extracrAudio(QString strInPath, QString strOutPath)
{
//申請輸出空間,先按照最大需求量申請
uint8_t **out_data;
int GroupSize = 1; //外層size
int innerSize = 60 * 16000 * 2; //內層size,60s*16000Hz*2Bytes*1channel
int maxbufferSize = 0;
out_data = (uint8_t**)malloc(sizeof(uint8_t*)*GroupSize);
for (int i = 0; i < GroupSize; i++)
{
out_data[i] = (uint8_t*)malloc(sizeof(uint8_t)*innerSize);
}
ExtractAudio ea; //創建物件
ea.init(); //初始化
AVFormatContext *format = ea.open(strInPath); //打開檔案
if (!format)
{
QMessageBox::warning(NULL, "提示", "打開檔案失敗!");
return;
}
cout << "Open file successed!" << endl;
AVCodecContext *avctx = ea.decodec(format);; //解碼
if (!avctx)
{
QMessageBox::about(NULL, "提示", "解碼失敗!");
return;
}
cout << "Decodec successed!" << endl;
SwrContext *swr = ea.initswr(avctx, out_data); //音頻重采樣初始化
if (!swr)
{
QMessageBox::about(NULL, "提示", "音頻重采樣初始化失敗!");
return;
}
cout << "Initswr successed!" << endl;
AVFrame *frame = av_frame_alloc(); //malloc AVFrame 并初始化
AVPacket *pkt = av_packet_alloc(); //malloc AVPacket 并初始化
int bufferSize = 0; //輸出緩沖區的位元組數
//創建寫出的pcm檔案
QFile outFile(strOutPath);
outFile.open(QIODevice::WriteOnly);
//讀取資料
while (av_read_frame(format, pkt) >= 0)
{
// 重采樣并獲取輸出位元組數
bufferSize = ea.resample(format, avctx, swr, out_data, frame, pkt);
if (bufferSize > 0) //有重采樣的資料,寫入檔案中
outFile.write((const char*)out_data[0], bufferSize);
else if (bufferSize == 0) //暫無重采樣的資料,繼續執行
continue;
else //重采樣出現錯誤,停止執行
{
QMessageBox::about(NULL, "提示", "音頻重采樣失敗!");
break;
}
}
outFile.close();
ea.clear(format, avctx, swr, frame, pkt); //釋放空間
cout << "ExtracrAudio Finish!" << endl;
//釋放空間
for (int i = 0; i < GroupSize; i++)
{
free(out_data[i]);
}
free(out_data);
}
//音頻分段
QString MyThread::separatePCM(QString strInPath)
{
SeparatePCM sp; //創建物件
bool flag = sp.open(strInPath); //打開檔案
if (!flag)
{
QMessageBox::warning(NULL, "提示", "打開音頻檔案失敗!");
return NULL;
}
sp.execute(); //音頻分段
return sp.folderStr;
cout << "SeparatePCM Finish!" << endl;
}
//語音識別并將結果寫入txt
void MyThread::writeText(QString strInPath)
{
WriteText wt; //創建物件
wt.execute(strInPath, languageId); //執行
cout << "WriteText Finish!" << endl;
}
執行緒函式里,兩個信號void updateProgress(int)和void updateLabel(QString)用來更新界面的進度條和便簽,在MyThread里面發送信號后,在界面連接信號和槽:
connect(&m_thread, SIGNAL(updateProgress(int)), this, SLOT(updateProgress(int)));
connect(&m_thread, SIGNAL(updateLabel(QString)), this, SLOT(updateLabel(QString)));
其中信號是MyThread的信號(signals),槽是界面的槽(slots),
而如果界面向執行緒發送引數的話,直接呼叫執行緒里的函式,例如在界面中有兩個單選按鈕來提供選擇“中文”或是“英文”的功能,并且將這兩個合并成一個組合:
// 設定單選按鈕組合
groupButton = new QButtonGroup(this);
groupButton->addButton(ui.rbtn_Chinese, 0);
groupButton->addButton(ui.rbtn_English, 1);
ui.rbtn_Chinese->setChecked(true); //默認選擇中文
在點擊開始按鈕時,我們就需要判斷選擇了哪個單選按鈕,并把結果傳遞給運算執行緒:
int id = groupButton->checkedId();
m_thread.setLanguage(id);
上述的void setLanguage(int id)是執行緒類里的一個公共函式,直接在界面里面呼叫即可,把界面所確定的檔案串列傳遞給執行緒類也是同理,
六、結語
內容差不多就這些了,也都是一些很新手的東西,非常歡迎大佬們給出一些好的建議(尤其是FFmpeg釋放記憶體那里,能連帶解決方案就更好了),demo就不放出來了,弄了一個半成品再放出來就覺得很慚愧,
計劃以后每年都利用各種假期的時間集合起來,做個小東西,同時更新一下這個系列,做什么方向就看自己的腦洞和心情,反正是假期不務正業時間,如果有好的想法也歡迎一起學習一起做,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/259833.html
標籤:其他